Clarifying wireheading terminology
post by leogao · 2022-11-24T04:53:23.925Z · LW · GW · 6 commentsContents
6 comments
See also: Towards deconfusing wireheading and reward maximization, [LW · GW]Everett et al. (2019).
There are a few subtly different things that people call "wireheading". This post is intended to be a quick reference for explaining my views on the difference between these things. I think these distinctions are sometimes worth drawing to reduce confusion.
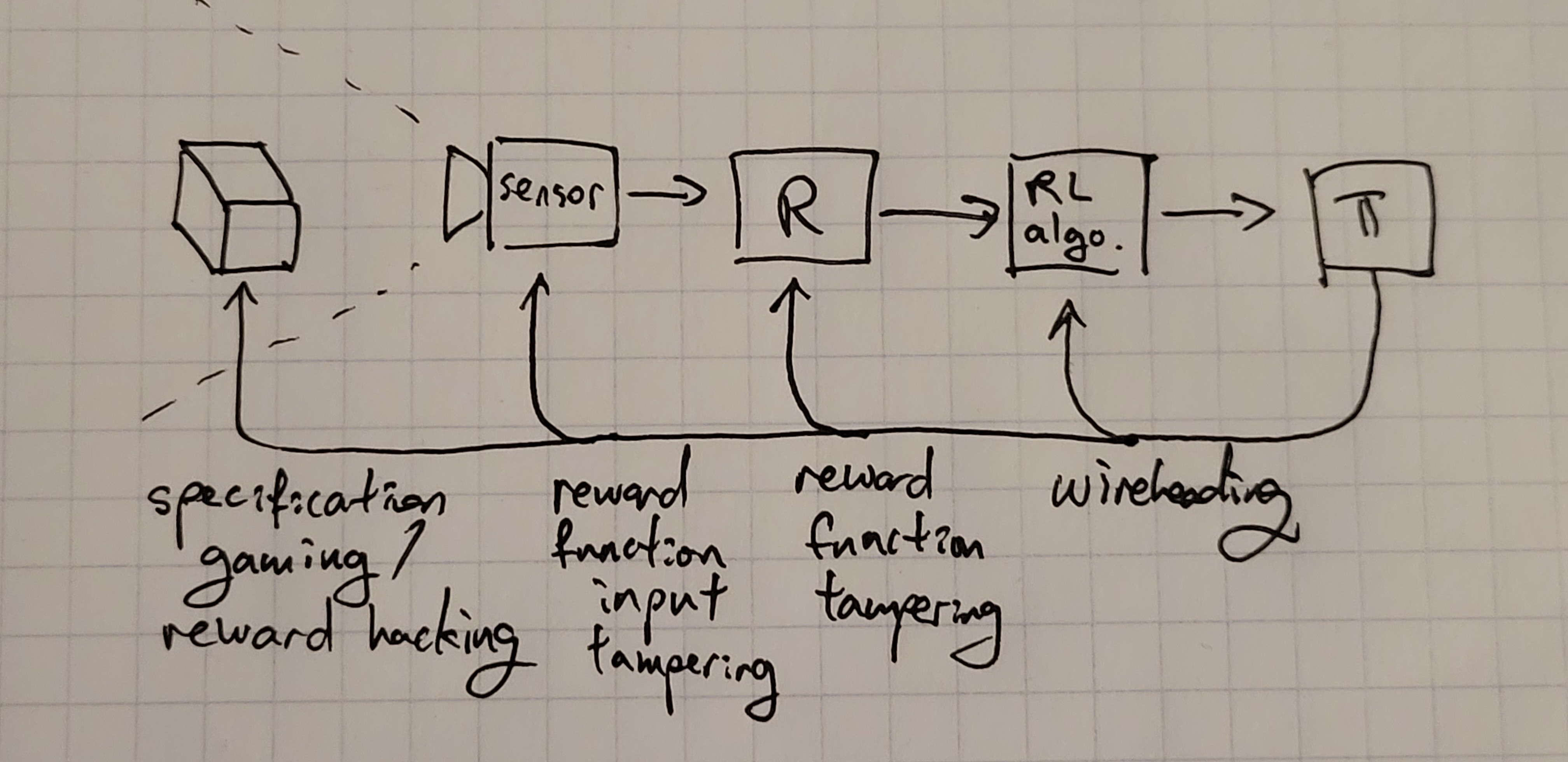
- Specification gaming / reward hacking: The agent configures the world in such a way that makes its reward(/utility) function achieve a high value in a way that is not what the creators intended the reward function to incentivize.
- Reward function input tampering: The agent tampers with the inputs to its reward function to make the reward function see the same inputs as it would when observing an actual desirable worldstate.
- Examples: sensor tampering, VR
- Reward function tampering: The agent changes its reward function.[1]
- Examples: meditation, this baba-is-you-like gridworld
- Wireheading: The agent directly tampers with the reward signal going into the RL algorithm.
- Examples: dopamine agonists, setting the reward register
Some crucial differences between these:
- 1 is a problem of both embedded[2] and non-embedded settings. 2 is a problem of partially-observedness[3], which is unavoidable in embedded settings, but also comes up in many non-embedded settings as well. 3 and 4 are problems of embeddedness; they do not show up in non-embedded settings.
- 2, 3, 4 are all about "not caring about the real world" in various ways, whereas 1 is about "caring about the real world in the wrong way"
- 4 is about as close as you can get to a "reward-maximizing policy" in an embedded setting.
- ^
Note: this is not the same thing as changing a terminal goal! The reward function is not necessarily the terminal goal of the policy, because of inner misalignment.
- ^
Here, by "embeddedness" I mean in the sense of Demski and Garrabrandt (2019); in particular, the fact that the agent is part of the environment, and not in a separate part of the universe that only interacts through well defined observation/action/reward channels. RL is the prototypical example of a non-embedded agency algorithm.
- ^
That is, the reward function is unable to perfectly observe the ground truth state of the environment, which means that if there is another state the world cold be in that yields the same observation, the reward cannot distinguish between the two.
6 comments
Comments sorted by top scores.
comment by tailcalled · 2022-11-24T13:23:05.638Z · LW(p) · GW(p)
I would tend to lump 2-4 together under general wireheading because they are all solved by model-based AI.
Replies from: cfoster0↑ comment by cfoster0 · 2022-11-24T14:18:04.105Z · LW(p) · GW(p)
Solved? Howso?
Replies from: tailcalled↑ comment by tailcalled · 2022-11-24T15:25:36.605Z · LW(p) · GW(p)
Classical wireheading appears when the AI considers some action that would interfere with the reward/value signal by increasing it in an ungrounded way, and reasons that since that action increases reward, it should take the action. For instance with a cleaning robot:
- If there is negative reward when a camera sees a piece of trash, then destroying that camera would lead the agent to expect higher reward, and therefore it destroys the camera
- If the reward function is changeable, then changing it to give maximum reward would lead the agent to expect higher rewards, and therefore it changes the reward function
- If the feed from the reward function to the reinforcement algorithm can be intervened on to maximize the reward signal, then changing it to give maximum reward would lead the agent to expect higher rewards, and therefore it tampers with the feed.
However, all of these are caused by the same problem, that the AI optimizes for causing the future reward signal to be higher, including counting interventions in the chain defining the reward as being real changes in the reward.
An alternate design would be to make the AI model-based, and evaluate the quality of the plans for what it should do in the future using a current value model. In that case it would reject all the cases of wireheading. For instance if plans are accepted based on the model expecting that they lead to there being trash laying around:
- Interfering with cameras it uses to identify trash would lead to less trash getting cleaned up, and therefore it doesn't do that
- Interfering with value functions would lead to less trash getting cleaned up, so therefore it doesn't do that
- Interfering with internal value signals in the agent would lead to less trash getting cleaned up, so therefore it doesn't do that
↑ comment by cfoster0 · 2022-11-24T18:19:12.099Z · LW(p) · GW(p)
An alternate design would be to make the AI model-based, and evaluate the quality of the plans for what it should do in the future using a current value model. In that case it would reject all the cases of wireheading.
Evaluating what to do using the current value function is already how model-free and model-based RL works though, right? I don't recall reading about any RL algorithms where the agent first estimates the effects that its actions would have on its own embedded code and then judges using the new code.
Anyways, whether it will reject wireheading depends on the actual content of the AI's value function, no? There's nothing necessarily preventing its current value function from assigning high value to future states wherein it has intervened causally upstream of the reward dispenser. For instance, tampering with the reward dispenser inputs/content/outputs is a perfect way for the current value function to preserve itself!
As another example, if you initialized the value function from GPT-3 weights, I would bet that it'd evaluate a plan fragment like "type this command into the terminal and then you will feel really really really amazingly good" pretty highly if considered, & that the agent might be tempted to follow that evaluation. Doubly so if the command would in fact lead to a bunch of reward, the model was trained to predict next-timestep rewards directly, and its model rollouts accurately predict the future rewards that would result from the tampering.
More generally, even in model-based setups the agent's value function won't be aligned with (the discounted sum of future) reward signals [AF · GW], or with what its model predicts that quantity to be, so I don't see how we can say the problem is solved. Could be unlikely to crop up in practice, though.
Replies from: tailcalled↑ comment by tailcalled · 2022-11-24T21:14:42.472Z · LW(p) · GW(p)
Evaluating what to do using the current value function is already how model-free and model-based RL works though, right?
Yes, with caveats.
- "Model-free" RL usually has a learned value function (unless you go all the way to policy gradients), which is strictly speaking a model, just a very crude one.
- These forms of AI usually actively try to update their value function to match the modified versions they get after e.g. destroying the camera.
- Part of the problem is that traditional RL is very stupid and basically explores the environment tree using something close to brute force.
I don't recall reading about any RL algorithms where the agent first estimates the effects that its actions would have on its own embedded code and then judges using the new code.
AIXI?
Anyways, whether it will reject wireheading depends on the actual content of the AI's value function, no? There's nothing necessarily preventing its current value function from assigning high value to future states wherein it has intervened causally upstream of the reward dispenser. For instance, tampering with the reward dispenser inputs/content/outputs is a perfect way for the current value function to preserve itself!
As another example, if you initialized the value function from GPT-3 weights, I would bet that it'd evaluate a plan fragment like "type this command into the terminal and then you will feel really really really amazingly good" pretty highly if considered, & that the agent might be tempted to follow that evaluation. Doubly so if the command would in fact lead to a bunch of reward, the model was trained to predict next-timestep rewards directly, and its model rollouts accurately predict the future rewards that would result from the tampering.
More generally, even in model-based setups the agent's value function won't be aligned with (the discounted sum of future) reward signals [LW · GW], or with what its model predicts that quantity to be, so I don't see how we can say the problem is solved. Could be unlikely to crop up in practice, though.
Right, more precisely the way to robustly avoid wireheading in advanced AI is to have a model-based agent and have the reward/value be a function of the latent variables in the model, as opposed to a traditional reinforcement learner where the value function approximates the sum of future rewards.
comment by Algon · 2022-11-24T14:35:13.225Z · LW(p) · GW(p)
I think the reward tampering paper has a pretty good description of the various failure modes of wireheading. Though I guess it would be nice to have something like the Goodhart Taxonomy [LW · GW] post, but for reward tampering/wireheading.