A History of Bayes' Theorem
post by lukeprog · 2011-08-29T07:04:30.385Z · LW · GW · Legacy · 91 commentsContents
Origins Laplace The Decline of Bayes' Theorem Jeffreys Bayes at War Revival Medicine Practical Use Victory None 91 comments
Sometime during the 1740s, the Reverend Thomas Bayes made the ingenious discovery that bears his name but then mysteriously abandoned it. It was rediscovered independently by a different and far more renowned man, Pierre Simon Laplace, who gave it its modern mathematical form and scientific application — and then moved on to other methods. Although Bayes’ rule drew the attention of the greatest statisticians of the twentieth century, some of them vilified both the method and its adherents, crushed it, and declared it dead. Yet at the same time, it solved practical questions that were unanswerable by any other means: the defenders of Captain Dreyfus used it to demonstrate his innocence; insurance actuaries used it to set rates; Alan Turing used it to decode the German Enigma cipher and arguably save the Allies from losing the Second World War; the U.S. Navy used it to search for a missing H-bomb and to locate Soviet subs; RAND Corporation used it to assess the likelihood of a nuclear accident; and Harvard and Chicago researchers used it to verify the authorship of the Federalist Papers. In discovering its value for science, many supporters underwent a near-religious conversion yet had to conceal their use of Bayes’ rule and pretend they employed something else. It was not until the twenty-first century that the method lost its stigma and was widely and enthusiastically embraced.
So begins Sharon McGrayne's fun new book, The Theory That Would Not Die, a popular history of Bayes' Theorem. Instead of reviewing the book, I'll summarize some of its content below. I skip the details and many great stories from the book, for example the (Bayesian) search for a lost submarine that inspired Hunt for Red October. Also see McGrayne's Google Talk here. She will be speaking at the upcoming Singularity Summit, too, which you can register for here (price goes up after August 31st).
Origins
In the 1700s, when probability theory was just a whiff in the air, the English Reverend Thomas Bayes wanted to know how to infer causes from effects. He set up his working problem like this: How could he learn the probability of a future event occurring if he only knew how many times it had occurred or not occurred in the past?
He needed a number, and it was hard to decide which number to choose. In the end, his solution was to just guess and then improve his guess later as he gathered more information.
He used a thought experiment to illustrate the process. Imagine that Bayes has his back turned to a table, and he asks his assistant to drop a ball on the table. The table is such that the ball has just as much chance of landing at any one place on the table as anywhere else. Now Bayes has to figure out where the ball is, without looking.
He asks his assistant to throw another ball on the table and report whether it is to the left or the right of the first ball. If the new ball landed to the left of the first ball, then the first ball is more likely to be on the right side of the table than the left side. He asks his assistant to throw the second ball again. If it again lands to the left of the first ball, then the first ball is even more likely than before to be on the right side of the table. And so on.
Throw after throw, Bayes is able to narrow down the area in which the first ball probably sits. Each new piece of information constrains the area where the first ball probably is.
Bayes' system was: Initial Belief + New Data -> Improved Belief.
Or, as the terms came to be called: Prior + Likelihood of your new observation given competing hypotheses -> Posterior.
In each new round of belief updating, the most recent posterior becomes the prior for the new calculation.
There were two enduring criticisms to Bayes' system. First, mathematicians were horrified to see something as whimsical as a guess play a role in rigorous mathematics. Second, Bayes said that if he didn't know what guess to make, he'd just assign all possibilities equal probability to start. For most mathematicians, this problem of priors was insurmountable.
Bayes never published his discovery, but his friend Richard Price found it among his notes after Bayes' death in 1761, re-edited it, and published it. Unfortunately, virtually no one seems to have read the paper, and Bayes' method lay cold until the arrival of Laplace.
Laplace
By the late 18th century, Europe was awash in scientific data. Astronomers had observations made by the Chinese in 1100 BC, by the Greeks in 200 BC, by the Romans in AD 100, and by the Arabs in AD 1000. The data were not of equal reliability. How could scientists process all their observations and choose the best? Many astronomers simply averaged their three 'best' observations, but this was ad-hoc. The world needed a better way to handle all these data.
Pierre-Simon Laplace, a brilliant young mathematician, came to believe that probability theory held the key, and he independently rediscovered Bayes' mechanism and published it in 1774. Laplace stated the principle not with an equation, but in words: the probability of a cause (given an event) is proportional to the probability of the event (given its cause). And for the next 40 years, Laplace used, extended, clarified, and proved his new principle.
In 1781, Richard Price visited Paris, and word of Bayes' earlier discovery eventually reached Laplace. Laplace was now all the more confident that he was on the right track.
He needed to test his principle, so he turned to the largest data set available: birth records. A few people had noticed that slightly more boys than girls were born, and Laplace wanted to know if this was an anomalous or constant phenomenon. He began by applying equal probability to his hunches, and then updated his belief as he examined data sets from Paris, from London, from Naples, from St. Petersburg, and from rural areas in France. Later he even asked friends for birth data from Egypt and Central America. Finally, by 1812, he was almost certain that the birth of more boys than girls was "a general law for the human race."
Laplace's friend Bouvard used his method to calculate the masses of Jupiter and Saturn from a wide variety of observations. Laplace was so impressed that he offered his readers a famous bet: 11,000 to 1 odds that Bouvard's results for Saturn were within 1% of the correct answer, and a million to one odds for Jupiter. Nobody seems to have taken Laplace's bet, but today's technology confirms that Laplace should have won both bets.
Laplace used his principle on the issue of testimony, both in court and in the Bible, and made famous progress in astronomy. When asked by Napoleon who authored the heavens, Laplace replied that natural law could explain the behavior of the heavens. Napoleon asked why Laplace had failed to mention God in his book on the subject. Laplace replied: "Sire, I have no need of that hypothesis."
The answer became a symbol of the new science: the search for natural laws that produced phenomena without the need to call upon magic in the explanation.
And then, Laplace invented the central limit theorem, which let him handle almost any kind of data. He soon realized that where large amounts of data were available, both the Bayesian and the frequentist approaches (judging an event's probability by how frequently it occurs among many observations) to probability tended to produce the same results. (Only much later did scientists discover how wildly the two approaches can diverge even given lots of data.)
And so at age 62, Laplace — the world's first Bayesian — converted to frequentism, which he used for the remaining 16 years of his life.
...though he did finally realize what the general theorem for Bayes' method had to be:
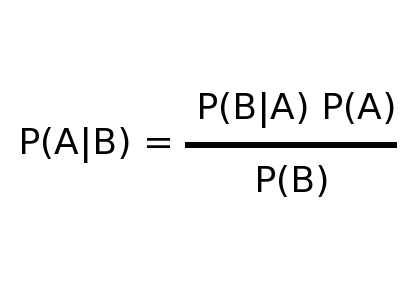
P(C|E) = [ P(E|C)Pprior(C) ] / [ΣP(E|C')Pprior(C')
Which says that the probability of a hypothesis C given some evidence E equals our initial estimate of the probability times the probability of the evidence given the hypothesis C divided by the sum of the probabilities of the data in all possible hypotheses.
Basically, Laplace did all the hard work, and he deserves most of the honor for what we call Bayes' Theorem. But historical accidents happen, and the method is named after Bayes.
The Decline of Bayes' Theorem
Empowered by Laplace's central limit theorem, government officials were expected to collect statistics on all sorts of things: cholera victims, the chest sizes of soldiers, the number of Prussian officers killed by kicking horses, and so on. But the idea that probability quantifies our ignorance was gone, replaced by the idea that the new science could not allow for anything 'subjective'. John Stuart Mill denounced probability as "ignorance... coined into science."
By 1891, the Scottish mathematician George Chrystal urged: "[Laplace's principle] being dead, [it] should be decently buried out of sight, and not embalmed in text-books and examination papers... The indiscretions of great men should be quietly allowed to be forgotten."
And thus, Bayes' Theorem fell yet again in disuse... at least among theoreticians. A smattering of practitioners continued to find it useful.
Joseph Bertrand was convinced that Bayes' Theorem was the only way for artillery officers to correctly deal with a host of uncertainties about the enemies' location, air density, wind direction, and more. From 1890-1935, French and Russian artillery officers used Bertrand's Bayesian textbook to fire their weapons.
When the French Jew Alfred Dreyfus was falsely accused of having sold a letter to German military expert, France's famous mathematician Henri Poincaré was called to the stand. Poincaré was a frequentist, but when asked whether Dreyfus had written the letter, Poincaré invoked Bayes' Theorem as the only sensible way for a court of law to update a hypothesis with new evidence, and proclaimed that the prosecution's discussion of probability was nonsense. Dreyfus was still convicted, though his sentence was reduced, but the public was outraged and the president issued a pardon two weeks later.
Statisticians used Bayes' Theorem to set up a functioning Bell phone system, set of up the United States' first working social insurance system, and solve other problems.
Meanwhile, the biologist R.A. Fisher was pioneering new randomization methods, sampling theory, tests of significant, analyses of variance, and a variety of experimental designs. In 1925 he published his revolutionary manual, Statistical Methods of Research Workers. The success of the book enshrined frequentism and the standard statistical method.
Jeffreys
Even during its decline, a few people made progress on Bayesian theory. At about the same time, three men in three countries — Émile Borel, Frank Ramsey, and Bruno de Finetti — independently happened upon the same idea: knowledge is subjective, and we can quantify it with a bet. The amount we wager shows how strongly we believe something.
And then, the geologist Harold Jeffreys made Bayes' Theorem useful for scientists, proposing it as an alternative to Fisher's 'p-values' and 'significance tests', which depended on "imaginary repetitions." In contrast, Bayesianism considered data as fixed evidence. Moreover, the p-value is a statement about data, but Jeffreys wanted to know about his hypothesis given the data. He published the monumental Theory of Probability in 1939, which remained for many years the only explanation of how to use Bayes to do science.
For decades, Fisher and Jeffreys were the world's two greatest statisticians, though both were practicing scientists instead of theoreticians. They traded blows over probability theory in scientific journals and in public. Fisher was louder and bolder, and frequentism was easier to use than Bayesianism.
Bayes at War
In 1941, German U-Boats were devastating allied naval forces. Britain was cut off from its sources of food, and couldn't grow enough on its own soil to feed its citizens. Winston Churchill said the U-boat problem was the scariest part of the war for him.
The German codes, produced by Enigma machines with customizable wheel positions that allowed the codes to be changed rapidly, were considered unbreakable, so nobody was working on them. This attracted Alan Turing to the problem, because he liked solitude. He built a machine that could test different code possibilities, but it was slow. The machine might need four days to test all 336 wheel positions on a particular Enigma code. Until more machines could be built, Turing had to find a way for reducing the burden on the machine.
He used a Bayesian system to guess the letters in an Enigma message, and add more clues as they arrived with new data. With this method he could reduce the number of wheel settings to be tested by his machine from 336 to as few as 18. But soon, Turing realized that he couldn't compare the probabilities of his hunches without a standard unit of measurement. So, he invented the 'ban', defined as "about the smallest change in weight of evidence that is directly perceptible to human intuition." This unit turned out to be very similar to the bit, the measure of information discovered using Bayes' Theorem while working for Bell Telephone.
Now that he had a unit of measurement, he could target the amount of evidence he needed for a particular hunch and then stop the process when he had that much evidence.
While Turing was cracking the Enigma codes in Britain, Andrey Kolmogorov was fleeing the German artillery bombardment of Moscow. In 1933 he had showed that probability theory can be derived from basic mathematical axioms, and now Russia's generals were asking him about how best to fire back at the Germans. Though a frequentist, Kolmogorov recommended they used Bertrand's Bayesian firing system in a crisis like this.
Shortly after this, the British learned that the Germans were now using stronger, faster encryption machines: Lorenz machines. The British team used Turing's Bayesian scoring system and tried a variety of priors to crack the codes.
Turing visited America and spent time with Claude Shannon, whose brilliant insights about information theory came a bit later. He realized that the purpose of information is to reduce uncertainty and the purpose of encryption is to increase it. He was using Bayes for both. Basically, if the posterior in a Bayesian equation is very different from the prior, then much has been learned, but if the posterior is roughly the same as the prior, then the information content is low. Shannon's unit for information was the 'bit'.
Meanwhile, Allied patrol planes needed to narrow their search for German U-boats. If 7 different listening posts intercepted the same message from the same U-boat, it could be located to somewhere in a circle 236 miles across. That's a lot of uncertainty, and mathematician Bernard Koopman was assigned to solve the problem. He wasn't bashful about Bayes at all. He said: "Every operation involved in search is beset with uncertainties; it can be understood quantitatively only in terms of... probability. This may now be regarded as a truism, but it seems to have taken the developments in operational research of the Second World War to drive home its practical implications."
Koopman started by assigning 50% probability that a U-boat was inside the 236-mile circle, and then update his probability as more data came in, apportioning plane flyover hours according to the probabilities of U-boat locations.
And then, a few day's after Germany's surrender, Churchill ordered the destruction of all evidence that decoding has helped win the war, apparently because the British didn't want the Soviets to know they could decrypt Lorenz codes. It wasn't until 1973 that the story of Turing and Bayes began to emerge.
Revival
Its wartime successes classified, Bayes' Theorem remained mostly in the dark after the Second World War. Textbooks self-righteously dismissed Bayes. During the McCarthyism of the 1950s, one government statistician half-jokingly called a colleague "un-American because [he] was a Bayesian, ...undermining the United States Government."
In 1950, an economist preparing a report asked statistician David Blackwell (not yet a Bayesian) to estimate the probability of another world war in the next five years. Blackwell answered: "Oh, that question just doesn't make sense. Probability applies to a long sequence of repeatable events, and this is clearly a unique situation. The probability is either 0 or 1, but we won't know for five years." The economist replied, "I was afraid you were going to say that. I've spoken to several other statisticians, and they all told me the same thing."
Still, there were flickers of life. For decades after the war, one of Turing's American colleagues taught Bayes to NSA cryptographers. I.J. Good, one of Turing's statistics assistant, developed Bayesian methods and theory, writing about 900 articles about Bayes.
And then there was the Bible-quoting business executive Arthur Bailey.
Bailey was trained in statistics, and when he joined an insurance company he was horrified to see them using Bayesian techniques developed in 1918. They asked not "What should the new rates be?" but instead "How much should the present rates be changed?" But after a year of trying different things, he realized that the Bayesian actuarial methods worked better than frequentist methods. Bailey "realized that the hard-shelled underwriters were recognizing certain facts of life neglected by the statistical theorists." For example, Fisher's method of maximum likelihood assigned a zero probability to nonevents. But since many businesses don't file insurance claims, Fisher's method produced premiums that were too low to cover future costs.
Bailey began writing a paper about his change in attitude about Bayes. By 1950 he was vice president of a large insurance company in Chicago. On May 22 he read his famous paper at a black-tie banquet for an actuarial society. The title: 'Credibility Procedures: Laplace's Generalization of Bayes' Rule and the Combination of [Prior] Knowledge with Observed Data.'
Bailey praised his colleagues for standing mostly alone against the statistics establishment. Then he announced that their beloved Credibility formula was actually Bayes Theorem, and in fact that the person who had published Bayes' work, Richard Price, would today be considered an actuary. He used Bayes' ball-and-table thought experiment to attack Fisher and his methods, and ended with a rousing call to put prior knowledge back into probability theory. His speech occupied theorists for years, and actuaries often see Bailey as taking their profession out of its dark ages.
That same year, I.J. Good published Probability and the Weighing of Evidence, which helped to found Bayes' Theorem into a logical, coherent methodology. Good was smart, quick, and by now perhaps the world's expert on codes. He introduced by holding out his hand and saying "I am Good." When the British finally declassified his cryptanalysis work, allowing him to reveal Bayes' success during WWII, he bought a vanity licensed plate reading 007 IJG.
In the 1950s, Dennis Lindley and Jimmie Savage worked to turn the statistician's hodgepodge of tools into a "respectable branch of mathematics," as Kolmogorov had done for probability in in general in the 1930s. They found some success at putting statistics on a rigorous mathematical footing, and didn't realize at the time that they couldn't get from their theorems to the ad hoc methods of frequentism. Lindley said later, "We were both fools because we failed completely to recognize the consequences of what we were doing."
In 1954, Savage published Foundations of Statistics, which built on Frank Ramsey's earlier attempts to use Bayes' Theorem not just for making inferences but for making decisions, too. His response to a classic objection to Bayesianism is worth remembering. He was asked, "If prior opinions can differ from one researcher to the next, what happens to scientific objectivity in data analysis?" Savage explained that as we gain data, subjectivists move into agreement, just as scientists come to consensus as evidence accumulates about, say, cigarettes causing lung cancer. When they have little data, scientists are subjectivists. When they have tons of data, they agree and become objectivists.
Savage became a Messianic advocate of Bayesianism, but died suddenly of a heart attack in 1971. I.J. Good was active but working at a small university and was poor at public speaking. David Lindley, however, moved to Britain and almost single-handedly created 10 Bayesian departments in the U.K. — professorship by professorship, battle by battle, he got Bayesians hired again and again. By 1977 he was exhausted and retired early.
Medicine
In 1951, history major Jerome Cornfield used Bayes' Theorem to solve a puzzle about the chances of a person getting lung cancer. His paper helped epidemiologists to see how patients' histories could help measure the link between a disease and its possible cause. Moreover, he had begun to establish the link between smoking and lung cancer. Later efforts in England and the U.S. confirmed Cornfield's results.
Fisher and Neyman, the world's two leading anti-Bayesians, didn't accept the research showing that cigarettes caused lung cancer. Fisher, especially, published many papers. He even developed the hypothesis that, somehow, lung cancer might cause smoking. But in 1959, Cornfield published a paper that systematically addressed every one of Fisher's arguments, and Fisher ended up looking ridiculous.
Cornfield went on to be involved in most of the major public health battles involving scientific data and statistics, and in 1974 was elected president of the American Statistical Association despite never having gotten any degree in statistics. He had developed a congenial spirit and infectious laugh, which came in handy when enduring long, bitter battles over health issues.
In 1979 he was diagnosed with pancreatic cancer, but his humor remained. A friend told him, "I'm so glad to see you." Smiling, Cornfield replied, "That's nothing compared to how happy I am to be able to see you." As he lay dying, he called to his two daughters and told them: "You spend your whole life practicing humor for the times when you really need it."
Practical Use
Frequentist methods worked for repetitive, standardized phenomena like crops, genetics, gambling, and insurance. But business executives needed to make decisions under conditions of uncertainty, without sample data. And frequentism didn't address that problem.
At Harvard Business School, Robert Schlaifer thought about the problem. He realized that starting with prior information about demand for a product was better than nothing. From there, he realized that he could update his prior with new evidence, and independently arrived at Bayes' Theorem. Unaware of the literature, he reinvented Bayesian decision theory from scratch and began to teach it confidently. He did not think of it as 'an' approach. It was the approach, and everybody else was wrong, and he could show everybody else why they were wrong.
Later, he recruited Howard Raiffa to come work with him, because he needed another Bayesian to teach him more math. Together, the two invented the field of Decision-making Under Uncertainty (DUU). Schlaifer wrote the first practical textbook written entirely from a Bayesian perspective: Probability and Statistics for Business Decisions (1959). They introduced useful tools like decision trees, 'tree-flipping', and conjugate priors. They co-authored what would become the standard textbook of Bayesian statistics for two decades: Applied Statistical Decision Theory. Today, Bayesian methods dominate the business decision-making literature but frequentists still have some hold on statistics departments.
Meanwhile, Frederick Mosteller spent a decade using early computers and hundreds of volunteers to painstakingly perform a Bayesian analysis of the disputed Federalist Papers, and concluded with high probability that they were all written by Madison, not Hamilton. The work impressed many statisticians, even frequentists.
Bayes had another chance at fame during the 1960 presidential race between Nixon and Kennedy. The race was too close to call, but the three major TV networks all wanted to be the first to make the correct call. NBC went looking for someone to help them predict the winner, and they found Princeton statistics professor John Tukey. Tukey analyzed huge amounts of voting data, and by 2:30am during the election Tukey and his colleagues were ready to call Kennedy as the winner. The pressure was too much for NBC to make the call, though, so they locked Tukey and his team in a room until 8am when it was clear Kennedy was indeed the winner. NBC immediately asked him to come back for the 1962 election, and Tukey worked with NBC for 18 years.
But Tukey publicly denied Bayesianism. When working on the NBC projects, he said he wasn't using Bayes, instead he was "borrowing strength." He didn't allow anybody on his team to talk about their methods, either, saying it was proprietary information.
In 1980 NBC soon switched to exit polling to predict elections. Exit polling was more visual, chatty, and fun than equations. It would be 28 years before someone used Bayes to predict presidential election results. When Nate Silver of FiveThirtyEight.com used Bayes to predict results of the November 2008 race, he correctly predicted the winner in 49 states, an unmatched record among pollsters.
When the U.S. Atomic Energy Commission ordered a safety study of nuclear power plants, they hired Norman Rasmussen. At the time, there had never been a nuclear power plant accident. He couldn't use frequentist methods to estimate the probability of something that had never happened. So he looked to two sources: equipment failure rates, and expert opinion. But how could he combine those two types of evidence?
Bayes' Theorem, of course. But Rasmussen knew that Bayes was so out of favor that his results would be dismissed by the statistics community if he used the word 'Bayes'. So he used Raiffa's decision trees, instead. They were grounded in Bayes, but this way he didn't have to use the word 'Bayes.'
Alas, the report's subjectivist approach to statistics was roundly damned, and the U.S. Nuclear Regulatory Commission withdrew its support for the study five years later. And two months after they did so, the Three Mile Island accident occurred.
Previous experts had said the odds of severe core damage were extremely low, but the effects would be catastrophic. Instead, the Rasmussen report had concluded that the probability of core damage was higher than anticipated, but the consequences wouldn't be catastrophic. The report also identified two important sources of the problem: human error and radioactivity outside the building. In the eyes of many, the report had been vindicated.
Finally, in 1983 the US Air Force sponsored a review of NASA's estimates of the probability of shuttle failure. NASA's estimate was 1 in 100,000. The contractor used Bayes and estimated the odds of rocket booster failure at 1 in 35. In 1986, Challenger exploded.
Victory
Adrian Raftery examined a set of statistics about coal-dust explosions in 19th-century British mines. Frequentist techniques had shown the coal mining accident rates changed over time gradually. Our of curiosity, Raftery experimented with Bayes' Theorem, and discovered that accident rates had plummeted suddenly in the early 1890s. A historian suggested why: in 1889, the miners had formed a safety coalition.
Frequentist statistics worked okay when one hypothesis was a special case of another, but when hypotheses were competing and abrupt changes were in the data, frequentism didn't work. Many sociologists were ready to give up on p-values already, and Raftery's short 1986 paper on his success with Bayes led many sociologists to jump ship to Bayesianism. Raftery's paper is now one of the most cited in sociology.
One challenge had always been that Bayesian statistical operations were harder to calculate, and computers were still quite slow. This changed in the 90s, when computers became much faster and cheaper than before, and especially with the invention of the Markov Chain Monte Carlo method, which suddenly allowed Bayesians to do a lot more than frequentists can. The BUGS program also helped.
These advances launched the 'Bayesian revolution' in a long list of fields: medical diagnosis, ecology, geology, computer science, artificial intelligence, machine learning, genetics, astrophysics, archaeology, psychometrics, education performance, sports modeling, and more. This is only partly because Bayes' Theorem shows us the mathematically correct response to new evidence. It is also because Bayes' Theorem works.


91 comments
Comments sorted by top scores.
comment by Kaj_Sotala · 2011-08-25T11:09:12.156Z · LW(p) · GW(p)
I shared the link to this post on an IRC channel populated by a number of people, but mostly by mathematically inclined CS majors. It provoked a bunch of discussion about the way frequentism/bayesianism is generally discussed on LW. Here are a few snippets from the conversation (nicknames left out except my own, less relevant lines have been edited out):
11:03 < Person A> For fucks sake "And so at age 62, Laplace — the world's first Bayesian — converted to frequentism, which he used for the remaining 16 years of his life."
11:04 <@Guy B> well he believed that the results were the same
11:04 <@Guy B> counterexamples were invented only later
11:05 < Person A> Guy B: Still, I just hate the way that lesswrong talks about "bayesians" and "frequentists"
11:05 <@Guy B> Person A: oh, I misinterpreted you
11:06 < Person A> Every time yudkowsky writes "The Way of Bayes" i get a sudden urge to throw my laptop out of the window.
11:08 < Person A> Yudkowsky is a really good popular writer, but I hate the way he tries to create strange conflicts even where they don't exist.
11:10 <@Xuenay> I guess I should point out that the article in question wasn't written by Yudkowsky :P
11:10 <@Dude C> Xuenay: it was posted on lesswrong
11:11 <@Dude C> so obv we will talk about Yudkowski
11:13 <@Dude C> it's just htat there is no conflict, there are just several ways to do that.
11:13 <@Dude C> several models
11:16 <@Dude C> uh, several modes
11:17 <@Dude C> or I guess several schools. w/e.
11:17 <@Entity D> it's like this stupid philosophical conflict over two mathematically valid ways of doing statistical inference, a conflict some people seem to take all too seriously
11:17 <@Guy B> IME self-described bayesians are always going on about this "conflict"
11:17 <@Guy B> while most people just concentrate on science
11:18 <@Entity D> Guy B: exactly
11:18 <@Dude C> and use appropriate methods where they are appropriate
Summing up, the general consensus on the channel is that the whole frequentist/bayesian conflict gets seriously and annoyingly exaggarated on LW, and that most people doing science are happy to use either methodology if that suits the task at hand. Those who really do care and could reasonably be described as 'frequentist' or 'bayesian' are really a small minority, and LW's way of constantly bringing it up is just something that's used to make the posters feel smugly superior to "those clueless frequentists". This consensus has persisted over an extended time, and has contributed to LW suffering from a lack of credibility in the eyes of many of the channel regulars.
Does anybody better versed in the debate have a comment?
Replies from: lessdazed, lukeprog, Craig_Heldreth, ciphergoth, endoself, gwern↑ comment by lessdazed · 2011-08-25T11:51:59.618Z · LW(p) · GW(p)
Does anybody better versed in the debate have a comment?
Though I was not addressed by that, here goes anyway:
That people are happy doing whatever works doesn't make them part Bayesian and part Frequentist in LW's meaning any more than eating some vegetables and some meat makes one part vegetarian and part carnivore. Omnivores are not insiders among vegetarians or carnivores.
Bayesians - those who really do care, as you put it - believe something like "learning works to the extent it models Bayesian updating". When omnistatisticians decide to use a set of tools they customize for the situation, and make the result look clean and right and not silly and even extrapolatable and predictive, etc., and this gets a result better than formal Bayesian analysis or any other analysis, Bayesians believe that the thing that modeled Bayesian updating happened within the statisticians' own minds - their models are not at all simple, because the statistician is part of the model. Consequently, any non-Bayesian model is almost by definition poorly understood.
This is my impression of the collective LW belief, that impression is of course open to further revision.
LW has contributed to the confusion tremendously by simplistically using only two terms. Just as from the vegetarian perspective, omnivores and carnivores may be lumped into a crude "meat-eater" outgroup, from the philosophical position people on LW often take "don't know, don't care" and "principled frequentist" are lumped together into one outgroup.
People will not respect the opinions of those they believe don't understand the situation, and this scene has repeatedly occurred - posters on LW convince many that they do not understand people's beliefs, so of course the analysis and lessons are poorly received.
↑ comment by lukeprog · 2011-08-25T11:21:40.476Z · LW(p) · GW(p)
But the content in my post isn't by Less Wrong, it's by McGrayne.
The history in McGrayne's book is an excellent substantiation of just how deep, serious, and long-standing the debate between frequentism and Bayesianism really is. If they want, they can check the notes at the back of McGrayne's book and read the original articles from people like Fisher and Jeffreys. McGrayne's book is full of direct quotes, filled with venom for the 'opposing' side.
Replies from: Kaj_Sotala, lessdazed, Manfred↑ comment by Kaj_Sotala · 2011-08-25T12:34:14.814Z · LW(p) · GW(p)
But the content in my post isn't by Less Wrong, it's by McGrayne.
Fair point. Still, a person who hasn't read the book can't know whether lines such as "at age 62, Laplace — the world's first Bayesian — converted to frequentism" are from the book or if they were something you came up when summarizing.
If they want, they can check the notes at the back of McGrayne's book and read the original articles from people like Fisher and Jeffreys.
In previous discussions on the topic, I've seen people express the opinion that the fierce debates are somewhat of a thing of the past. I.e. yes there have been fights, but these days people are mostly over that.
Replies from: Jonathan_Graehl, alex_zag_al↑ comment by Jonathan_Graehl · 2011-08-25T21:50:36.657Z · LW(p) · GW(p)
at age 62, Laplace — the world's first Bayesian — converted to frequentism
I took this as a successful attempt at humor.
↑ comment by alex_zag_al · 2013-11-19T07:07:09.656Z · LW(p) · GW(p)
In previous discussions on the topic, I've seen people express the opinion that the fierce debates are somewhat of a thing of the past. I.e. yes there have been fights, but these days people are mostly over that.
This is something I was told over and over again by professors, when I was applying to grad school for biostatistics and told them I was interested in doing specifically Bayesian statistics. They mistook my epistemological interest in Bayes as like... ideological alignment, I guess. This is how I learned 1. that there were fierce debates in the recent past and 2. most people in biology don't like them or consider them productive.
Replies from: EHeller↑ comment by EHeller · 2013-11-19T07:17:48.687Z · LW(p) · GW(p)
They mistook my epistemological interest in Bayes as like... ideological alignment, I guess. This is how I learned 1. that there were fierce debates in the recent past and 2. most people in biology don't like them or consider them productive.
I'm not sure that the debates were even THAT recent. I think your professsors are worried about a common failure mode that sometimes creeps up- people like to think they know the "one true way" to do statistics (or really any problem) and so they start turning every problem into a nail so that they can keep using their hammer, instead of using appropriate methodology to the problem at hand.
I see this a fair amount in data mining, where certain people ONLY use neural nets, and certain people ONLY use various GLMs and extensions and sometimes get overly-heated about it.
Replies from: alex_zag_al↑ comment by alex_zag_al · 2013-11-19T07:28:54.243Z · LW(p) · GW(p)
Thanks for the warning. I thought the only danger was ideological commitment. But--correct me if I'm wrong, or just overrecahing--it sounds like if I fail, it'll be because I develop an expertise and become motivated to defend the value of my own skill.
Replies from: EHeller↑ comment by EHeller · 2013-11-20T00:37:27.348Z · LW(p) · GW(p)
if I fail, it'll be because I develop an expertise and become motivated to defend the value of my own skill.
No, more like you'll spend months (or more) pushing against a research problem to make it approachable via something in a Bayesian toolbox when there was a straightforward frequentist approach sitting there all along.
↑ comment by lessdazed · 2011-08-25T12:01:33.050Z · LW(p) · GW(p)
Because of its subject, your post in particular will obviously focus on those who care about the debate. It's not about the practice of learning from data, it's about the history of views on how to learn from data.
The criticism that it ignores those who utilize and do not theorize is wrong headed. The only thing that prevents it from being an outright bizarre accusation is that LW has repeatedly ignored the mere utilizers who are outside the academic debate when they should have been discussed and addressed.
But the content in my post isn't by Less Wrong, it's by McGrayne.
I strongly, strongly disagree. Even presenting unaltered material in a context not planned by the original author is a form of authorship. You have gone far, far beyond that by paraphrasing. You have presented an idea to a particular audience with media, you are an author, you are responsible.
If my friend asks to borrow a book to read, and I say "Which book" and he or she says "Whichever" I affect what is read and create the context in which it is read.
Replies from: gwern↑ comment by Manfred · 2011-08-25T22:41:36.425Z · LW(p) · GW(p)
My problem, and likely the chatters', is that by leading a team cheer for one audience, the larger neutral audience feels excluded. Doesn't really matter whose words it was.
And while most of the history was very interesting, some of it felt cherry-picked or spun, adding to that feeling of team-ization.
Replies from: lessdazed↑ comment by lessdazed · 2011-08-26T00:19:14.187Z · LW(p) · GW(p)
I don't think "neutral" is quite the right word for the audience in question. It may be the best one, but there is more to it, as it only captures the group's view of itself, and not how others might see it.
The Bayesians (vegetarians) see the "neutrals" (omnivores) as non-understanding (animal-killers). The neutrals see themselves as partaking of the best tools (foods) there are, both Bayesian and frequentist (vegetable and animal), and think that when Bayesians call them "non-Bayesians" (animal-killers) the Bayesians are making a mistake of fact by thinking that they are frequentists (carnivores). Sometimes Bayesians even say "frequentist" when context makes it obvious they mean "non-Bayesian" (or that they are making a silly mistake, which is what the threatened "neutrals" are motivated to assume).
As neutrals is absolutely how those in the group in question see themselves, but also true is that Bayesians see them as heretics, (murderers of Bambi, Thumper, and Lambchop), or what have you, without them making a mistake of fact. The Bayesian theoretical criticisms should not be brushed aside on the grounds that they are out of touch with how things are done, and do not understand that it that most use all available tools (are omnivorous). They can be addressed by invoking the outside view against the inside view, or practice against theory, etc. (these are arguments in which Bayesians and frequentists are joined against neutrals) and subsequently (if the "neutrals" (omnivores) do not win against the Bayesians [and their frequentist allies {those favoring pure diets}] outright in that round) on the well worn Bayesian (vegetarian) v. frequentist (carnivore) battlegrounds.
Replies from: kurokikaze↑ comment by kurokikaze · 2011-08-26T10:03:28.973Z · LW(p) · GW(p)
I think vegetarian-carnivore metaphor here doesn't help at all :)
Replies from: jhuffman, lessdazed↑ comment by lessdazed · 2011-08-26T10:13:33.954Z · LW(p) · GW(p)
This is quite possible, but there is some irony here - you have misrepresented the analogy by describing a three category grouping system by naming two of its categories, implying it is about opposites!
I think that people do this too often in general and that it is implicated in this debate's confused character. Hence, the analogy with more than a dichotomy of oppositional groups!
Replies from: AlanCrowe↑ comment by AlanCrowe · 2011-08-26T11:02:04.729Z · LW(p) · GW(p)
Realising that it is a three-way split, not a two-way split is my latest hammer. See me use it in Is Bayesian probability individual, situational, or transcendental: a break with the usual subjective/objective bun fight.
Having said that, I find myself agreeing with kurokikaze; the vegetarian-omnivore-carnivore metaphor doesn't help. The spilt blood (and spilt sap) distract from, and obscure, the "Three, not two" point.
↑ comment by Craig_Heldreth · 2011-08-25T13:54:44.989Z · LW(p) · GW(p)
In my laboratory statistics manual from college (the first edition of this book) the only statistics were frequentist, and Jaynes was considered a statistical outlier in my first year of graduate school. His results were respected, but the consensus was that he got them in spite of his unorthodox reduction method, not because of it.
In my narrow field (reflection seismology) two of the leaders explicitly addressed this question in a (surprisingly to me little-read and seldom-referenced) paper: To Bayes or not to Bayes. Their conclusion: they prefer their problems neat enough to not require the often-indispensable Bayes method.
It is a debate I prefer to avoid unless it is required. The direction of progress is unambiguous but it seems to me a classic example of a Kuhn paradigm shift where a bunch of old guys have to die before we can proceed amicably.
A very small minority of people hate Bayesian data reduction. A very small minority of people hate frequentist data reduction. The vast majority of people do not care very much unless the extremists are loudly debating and drowning out all other topics.
Replies from: Davorak↑ comment by Davorak · 2011-08-26T02:33:26.640Z · LW(p) · GW(p)
Another graduate student, I have in general heard a similar opinions from many professors through undergrad and grad school. Never disdan for bays but often something along the lines of "I am not so sure about that" or "I never really grasped the concept/need for bayes." The statistics books that have been required for classes, in my opinion durring the class, used a slightly negative tone while discussing bayes and 'subjective probability.'
↑ comment by Paul Crowley (ciphergoth) · 2011-08-26T07:24:29.604Z · LW(p) · GW(p)
Eliezer argues that this difference between "many tools in the statistical toolbox" and "one mathematical law to rule them all" is actually one of the differences between the frequentist and Bayesian approaches.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2011-08-26T17:22:24.172Z · LW(p) · GW(p)
Thanks, I'd forgotten that post. It sums things up pretty well, I think.
↑ comment by endoself · 2011-08-26T01:25:13.203Z · LW(p) · GW(p)
I think this is due to Yudkowsky's focus on AI theory; an AI can't use discretion to choose the right method unless we formalize this discretion. Bayes' theorem is applicable to all inference problems, while frequentist methods have domains of applicability. This may seem philosophical to working statisticians - after all, Bayes' theorem is rather inefficient for many problems, so it may still be considered inapplicable in this sense - but programming an AI to use a frequentist method without a complete understanding of its domain of applicability could be disastrous, while that problem just does not exist for Bayesianism. There is the problem of choosing a prior, but that can be dealt with by using objective priors or Solomonoff induction.
Replies from: lessdazed, fool↑ comment by lessdazed · 2011-08-26T07:37:57.688Z · LW(p) · GW(p)
programming an AI to use a frequentist method without a complete understanding of its domain of applicability could be disastrous
I'm not sure what you meant by that, but as far as I can tell not explicitly using Bayesian reasoning makes AIs less functional, not unfriendly.
Replies from: endoself↑ comment by endoself · 2011-08-26T18:03:41.129Z · LW(p) · GW(p)
Yes, mostly that lesser meaning of disastrous, though an AI that almost works but has a few very wrong beliefs could be unfriendly. If I misunderstood your comment and you were actually asking for an example of a frequentist method failing, one of the simplest examples is a mistaken assumption of linearity.
↑ comment by fool · 2011-08-30T03:40:47.126Z · LW(p) · GW(p)
"There is the problem of choosing a prior, but that can be dealt with by using objective priors or Solomonoff induction."
Yeah, well. That of course is the core of what is dubious and disputed here. Really, Bayes' theorem itself is hardly controversial, and talking about it this way is pointless.
There's sort of a continuum here. A weak claim is that these priors can be an adequate model of uncertainty in many situations. Stronger and stronger claims will assert that this works in more and more situations, and the strongest claim is that these cover all forms of uncertainty in all situations. Lukeprog makes the strongest claim, by means of examples which I find rather sketchy relative to the strength of the claim.
To Kaj Sotala's conversation, adherents of the weaker claim would be fine with the "use either methodlogy if that suits it" attitude. This is less acceptable to those who think priors should be broadly applicable. And it is utterly unacceptable from the perspective of the strongest claim.
For that matter "either" is incorrect (note the original conversation one of them actually talks about several rather than two). There is lots of work on modeling uncertainty in non-frequentist and non-bayesian ways.
Replies from: endoself↑ comment by endoself · 2011-08-30T04:31:26.491Z · LW(p) · GW(p)
Anyone who bases decisions on a non-Bayesian model of uncertainty that is not equivalent to Bayesianism with some prior is vulnerable to Dutch books.
Replies from: fool↑ comment by fool · 2011-08-30T04:46:37.401Z · LW(p) · GW(p)
It seems not. Sniffnoy's recent thread asked the very question as to whether Savage's axioms could really be justified by dutch book arguments.
Replies from: endoself↑ comment by endoself · 2011-08-31T01:06:25.184Z · LW(p) · GW(p)
I was thinking of the simpler case of someone who has already assigned utilities as required by the VNM axioms for the noncontroversial case of gambling with probabilities that are relative frequencies, but refuses on philosophical grounds to apply the expected utility decision procedure to other kinds of uncertainty.
(I do think the statement still stands in general. I don't have a complete proof but Savage's axioms get most of the way there.)
Replies from: fool↑ comment by fool · 2011-08-31T02:03:10.893Z · LW(p) · GW(p)
On the thread cited I gave a three state, two outcome counterexample to P2 which does just that. Having two outcomes obviously a utility function is not an issue. (It can be extended it with an arbitrary number of "fair coins" for example to satisfy P6, which covers your actual frequency requirement here)
My weak claim is that it is not vulnerable to "Dutch-book-type" arguments. My strong claim is that this behaviour is reasonable, even rational. The strong claim is being disputed on that thread. And of course we haven't agreed on any prior definition of reasonable or rational. But nobody has attempted to Dutch book me, and the weak claim is all that is needed to contradict your claim here.
Replies from: endoself↑ comment by gwern · 2011-08-25T17:45:19.376Z · LW(p) · GW(p)
"It is, I think, particularly in periods of acknowledged crisis that scientists have turned to philosophical analysis as a device for unlocking the riddles of their field. Scientists have not generally needed or wanted to be philosophers."
--Thomas Kuhn, The Structure of Scientific Revolutions
comment by fool · 2011-09-01T23:51:50.615Z · LW(p) · GW(p)
I was looking a little bit into this claim that Poincaré used subjective priors to help acquit Dreyfus. In a word, FAIL.
Poincaré's use of subjective priors was not a betrayal of his own principles because he needed to win, as someone above put it. He was granting his opponent's own hypothesis in order to criticise him. Strange that this point was not clear to whoever was researching it, given that the granting of the hypothesis was prefaced with a strong protest.
The court intervention in question was a report on Bertillon's calculations, by Poincaré with Appel and Darboux, « Examen critique des divers systèmes ou études graphologiques auxquels a donné lieu le bordereau » (discussed and quoted [here] ). It speaks for itself.
« Or cette probabilité a priori, dans des question comme celle qui nous occupe, est uniquement formée d'éléments moraux qui échappent absolument au calcul, et si, comme nous ne pouvons rien calculer sans la connaître, tout calcul devient impossible. Aussi Auguste Comte a-t-il dit avec juste raison que l'application du calcul des probabilités aux sciences morales était le scandale des mathématiques. Vouloir éliminer les éléments moraux et y substituer des chiffres, cela est aussi dangereux que vain. En un mot, le calcul des probabilités n'est pas, comme on paraît le croire, une science merveilleuse qui dispense le savant d'avoir du bon sens. C'est pourquoi il faudrait s'abstenir absolument d'appliquer le calcul aux choses morales ; si nous le faisons ici, c'est que nous y sommes contraints ... S'il s'agissait d'un travail scientifique, nous nous arrêterions là ; nous jugerions inutile d'examiner les détails d'un système dont le principe même ne peut soutenir l'examen ; mais la Cour nous a confié une mission que nous devons accomplir jusqu'au bout ... Nous admetterons toujours, dans les calclus qui suiveront, l'hypothèse la plus favorable au système de Bertillon. »
My translation: « Now this a priori probability, in questions such as the one before us, consists entirely of moral elements which absolutely escape calculation, and since we cannot calculate anything without knowing it, all calculations become impossible. Quite rightly did Auguste Comte also say that the application of probability calculations to the moral sciences was the scandal of mathematics. To want to eliminate moral elements and substitute numbers is just as dangerous as vain. In a word, probability calculations are not, as seems to be thought, a marvolous science which dispenses with the need for the scientist to have good sense. This is why one must absolutely abstain from applying these calculations to moral objects; if we do so here, it's because we are forced to ... If it were a scientific work in question, we would stop there; we would find it useless to examine the details of a system whose principle itself does not stand up to examination; but the Court has entrusted us with a mission which we must accomplish to the uttermost ... We will always grant, in the following calculations, the most favourable hypothesis to Bertillon's system. »
Then it is shown that Bertillon nevertheless made other serious errors, even granting this hypothesis.
I find Poincaré not guilty of the charge bayesianism, and what's more, if Bertillon and Poincaré were relevant at all, they would be a counterexample: the bayesian makes a right mess of things and the frequentist saves the world. I can sympathise with Person A above who gets the sudden urge to throw their laptop out the window.
comment by John_Baez · 2011-10-03T10:33:58.142Z · LW(p) · GW(p)
Maybe this is not news to people here, but in England, a judge has ruled against using Bayes' Theorem in court - unless the underlying statistics are "firm", whatever that means.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2011-08-29T07:01:18.715Z · LW(p) · GW(p)
Dreyfus was still convicted, though his sentence was reduced, but the public was outraged and the president issued a pardon two weeks later.
???
Dreyfus spent years on a prison island and emerged looking rather the worse for wear. http://en.wikipedia.org/wiki/Dreyfus_affair
Replies from: jhuffman↑ comment by jhuffman · 2011-08-29T17:06:08.118Z · LW(p) · GW(p)
The trial discussed in this piece was his second trial, held after years of imprisonment.
On September 19, 1899, following a passionate campaign by his supporters, including leading artists and intellectuals like Émile Zola, Dreyfus was pardoned by President Émile Loubet in 1899 and released from prison. He had been subjected to a second trial in that year and again declared guilty of treason despite the evidence in favor of his innocence.
comment by DavidPlumpton · 2011-08-25T23:07:28.867Z · LW(p) · GW(p)
Can anybody give a URL or show a simple practical worked example similar to the applications described here? It all sounds awesome but I have little idea how to apply it to estimating the mass of Saturn and my artillery shelling is suffering somewhat.
Actually a fun example might be the probability that the Nickel/Hydrogen low energy fusion system being developed by Rossi is real or bogus. Points in favour: several tricky to fake successful demonstrations in front of scientists and the president of a skeptics society. Points against: no public disclosure of the secret catalyst, previous convictions for fraud, and cancelling the contract with the company that was going to manufacture the system.
comment by taw · 2011-08-25T07:22:31.890Z · LW(p) · GW(p)
When Nate Silver of FiveThirtyEight.com used Bayes to predict results of the November 2008 race, he correctly predicted the winner in 49 states, an unmatched record among pollsters.
Intrade got it equally right, and to be honest there's nothing particularly "Bayesian" about Nate Silver's methodology. It's just intelligently weighted average of polling data.
Replies from: Vaniver, lessdazed↑ comment by Vaniver · 2011-08-25T19:29:47.175Z · LW(p) · GW(p)
I think the premise is that, if you are weighting the importance of polls based on how well the polls predicted past elections, you are using the spirit of Bayes, and the only consistent and correct way to do it mathematically is some form of Bayes itself.
Replies from: taw↑ comment by taw · 2011-08-25T22:20:47.619Z · LW(p) · GW(p)
IIRC his weights were based on objective quality metrics like sample size and recency.
Replies from: magfrump↑ comment by magfrump · 2011-08-29T12:51:57.475Z · LW(p) · GW(p)
When you say "objective quality metrics," how can they be determined to be such without using prior knowledge?
Replies from: taw↑ comment by taw · 2011-08-30T12:11:10.652Z · LW(p) · GW(p)
For sample size, it's actually objectively measurable. For recency etc. you can just use your expert judgment and validate against data with ad hoc techniques.
Ask Nate Silver for details if you wish. He never indicated he has a big Bayesian model behind all that.
You reach a point very early where model uncertainty makes Bayesian methods no better than ad hoc methods.
Replies from: magfrump↑ comment by magfrump · 2011-09-01T08:22:44.923Z · LW(p) · GW(p)
I don't mean to argue that Nate Silver had a "big Bayesian model behind all that." But if sample size and recency increase the reliability of polls, you can objectively measure how much they do and it seems that using Bayesian methods you could create an objectively best prior weighting system, which seems like the point that Vaniver was making.
I'm not immediately familiar with the math but it seems odd to me that it would be much more work to do a regression for a "best prior" than to come up with an ad hoc method, especially considering that "expert judgment" tends to be really bad (at least according to Bishop and Trout ).
Of course, I should probably wait to disagree until he [Nate Silver] gets something wrong.
↑ comment by lessdazed · 2011-08-25T07:39:31.385Z · LW(p) · GW(p)
...there's nothing particularly "Bayesian" about Nate Silver's methodology. It's just intelligently weighted average of polling data.
Theories describing reality at a deep level have problems such as unclear intellectual ownership of intelligent methods when the methods aren't clearly inspired by the theoretical tradition. It's a good problem to have.
comment by endoself · 2011-08-26T01:16:10.842Z · LW(p) · GW(p)
So, he invented the 'ban', defined as "about the smallest change in weight of evidence that is directly perceptible to human intuition."
Wikipedia defines the ban as the amount of information in a decimal digit and makes the observation, due to I. J. Good, that a deciban is approximately the smallest intuitively perceptible change in evidence.
Replies from: lukeprogcomment by Kaj_Sotala · 2011-08-25T08:02:38.156Z · LW(p) · GW(p)
Thanks! That was an interesting look at things - it's nice to know about the historical and sociological background of things. Seeing a similar account from a frequentist perspective would be nice, as this was quite one-sided, but I don't know which book should be summarized for that.
and discovered that accident rates had plummeted suddenly in the early 1890s. An historian suggested why: in 1989, the miners had formed a safety coalition.
I think one of these years is wrong.
Replies from: lukeprog, lessdazedcomment by lessdazed · 2011-08-25T07:25:59.668Z · LW(p) · GW(p)
Laplace's friend Bouvard used his method to calculate the masses of Jupiter and Saturn from a wide variety of observations. Laplace was so impressed that he offered his readers a famous bet: 11,000 to 1 odds that Bouvard's results for Saturn were within 1% of the correct answer, and a million to one odds for Jupiter. Nobody seems to have taken Laplace's bet, but today's technology confirms that Laplace should have won both bets.
How were they to determine the correct answer?
Replies from: Douglas_Knight, kurokikaze↑ comment by Douglas_Knight · 2011-08-30T05:38:06.700Z · LW(p) · GW(p)
Here are English translations of relevant papers of Laplace (search for "Bouvard"). Laplace appeals to the next century of data. It's not phrased as a bet there and while I can't address everything he wrote, older translations use "bet" where newer ones use "odds."
Newton used (his derivation of) Kepler's laws relate the mass to the period of satellites; I think Bouvard did the same. Newton correctly calculated the mass of Jupiter because it has easily visible satellites, but was off by 15% for Saturn. Bouvard differed by 0.5% from Newton on Jupiter, but both were 2% off (Laplace was overconfident). Bouvard's error on Saturn was less than 0.5%. Since Laplace thought he should be less accurate on Saturn, it was probably luck. Bouvard also computed the mass of Uranus within 30% by looking at its effects on other planets. ETA: since Laplace says the mass includes the moons, it probably isn't computed from the orbits of the moons; perhaps it is the effect on other planets.
↑ comment by kurokikaze · 2011-08-26T10:06:48.945Z · LW(p) · GW(p)
Calculated from gravitational force.
comment by Dr_Manhattan · 2011-08-25T12:21:53.999Z · LW(p) · GW(p)
Nice article, though parts seem needlessly politicised, as Kaj noted. Also seems it could use editing in places. Just one example -
French officials were expected to collect statistics on all sorts of things: cholera victims, the chest sizes of soldiers, the number of Prussian officers killed by kicking horses
Seems historically implausible, unless them were French horses..
Replies from: Vaniver, lukeprog↑ comment by Vaniver · 2011-08-25T19:20:45.439Z · LW(p) · GW(p)
That's actually a famous example in statistics and probability, from Bortkiewicz's book on the Law of Small Numbers. Like Laplace and Bayes, Bortkiewicz did the heavy lifting on an idea named after someone else (in this case, the Poisson distribution). As Bortkiewicz was Polish, German, or Russian (depending on how you look at things), it doesn't make sense to lump him in with French officials.
comment by calcsam · 2011-08-25T18:29:42.863Z · LW(p) · GW(p)
Alan Turing used it to decode the German Enigma cipher and arguably save the Allies from losing the Second World War; the U.S. Navy used it to search for a missing H-bomb and to locate Soviet subs; RAND Corporation used it to assess the likelihood of a nuclear accident; and Harvard and Chicago researchers used it to verify the authorship of the Federalist Papers.
I haven't seen any explanation of how these kinds of things were done, including calculations. Eliezer's Intuitive Explanation is good, of course, but the examples are very basic. Anything that is notable, even if it's just a published paper, would (I presume) involve data sets and more complex calculations. Does anyone have any good links to complex examples where they actually go through the math and make it easy to follow?
(I would like to understand this better; plus my father, a molecular biologist, asked me to explain Bayes' Theorem and how to use it to him.)
Replies from: jsalvatier↑ comment by jsalvatier · 2011-08-25T20:29:25.411Z · LW(p) · GW(p)
Are you looking for Bayesian statistics in general or these specifics examples? My Bayesian statistics textbook recommendation is here.
Replies from: James_K, calcsam↑ comment by James_K · 2011-09-01T18:23:12.424Z · LW(p) · GW(p)
Thank you for the recommendation.
Replies from: jsalvatier↑ comment by jsalvatier · 2011-09-01T18:28:27.312Z · LW(p) · GW(p)
You're welcome!
comment by Scott Alexander (Yvain) · 2011-08-29T12:41:56.810Z · LW(p) · GW(p)
Excellent article and reminds me how little I really know about Bayesian techniques and statistics.
Maybe when you're done grounding morality and unraveling the human brain and developing friendly AI and disproving the existence of God, you can write a series of posts picking up where "Intuitive Explanation of Bayes Theorem" and "Technical Explanation of Technical Explanation" left off.
Replies from: XiXiDucomment by Mass_Driver · 2011-08-29T10:02:11.985Z · LW(p) · GW(p)
Does anyone know anything about Bayesian statistics in academic political science? To put it mildly, political science has quite a number of open questions, and last I checked all of the statistical analysis in the field was frequentist. Political scientists spend a good chunk of their time sniping each other for getting the super-advanced frequentist statistics wrong. Maybe there's some room for basic Bayesian statistics to do some useful work?
Replies from: Cyan, jhuffman↑ comment by Cyan · 2011-08-31T04:05:24.822Z · LW(p) · GW(p)
Andrew Gelman springs to mind.
Replies from: Mass_Driver↑ comment by Mass_Driver · 2011-08-31T08:02:25.672Z · LW(p) · GW(p)
Yes, that fits the bill! Looks like a good thinker and a strong writer, too. Know anyone in comparative or international politics?
Replies from: Cyan↑ comment by Cyan · 2011-09-01T04:58:33.179Z · LW(p) · GW(p)
Alas, no. I know of Gelman because of his Bayesian stats textbook, not because of his political science background. You could email and ask him directly -- he's been responsive to emails from me and sometimes posts emails from others and his responses to his blog.
comment by Solvent · 2011-08-25T07:09:41.151Z · LW(p) · GW(p)
That was nicely written and fun to read. I might pick up that book.
A question: I found the odds ratio version of Bayes's theorem far more intuitive. Throughout history, has the equation ever been given as an odds ratio?
Replies from: MinibearRex, alex_zag_al↑ comment by MinibearRex · 2011-08-25T16:21:45.784Z · LW(p) · GW(p)
E.T. Jaynes used it a fair amount. I don't know how much others have used it.
↑ comment by alex_zag_al · 2013-11-19T07:14:23.417Z · LW(p) · GW(p)
I saw it put this way in a talk once. The talk was about integrating evidence from multiple sources to figure out if two biological macromolecules physically interact.
The reason, I think, is that this is a yes or no question. Most of the time, though, Bayes' theorem is used for numerical quantities: H means that a real world quantity X has a particular value x. But try to write it in the odds ratio form for this problem. You have to write probabilities given ~H, probabilities of the evidence just excluding a particular value of X, which is really awkward.
comment by [deleted] · 2011-09-15T12:27:52.357Z · LW(p) · GW(p)
The German codes, produced by Enigma machines with customizable wheel positions that allowed the codes to be changed rapidly, were considered unbreakable, so nobody was working on them.
That's not true. Polish Cipher Bureau was (for obvious reasons) interested in cryptoanalysis of German encryption system. Polish mathematicians: Rejewski, Różycki and Zygalski had significant achievements: they broke Enigma and even made working replicas. However, their methods of analysis weren't Bayesian (as far as I remember) and relied on some weaknesses of German procedures.
Replies from: gwern↑ comment by gwern · 2012-06-13T21:19:29.227Z · LW(p) · GW(p)
Luke's summary omits details. McGrayne does indeed cover the Polish efforts, and then about the British efforts:
According to Frank Birch, head of the GC&CS naval intelligence branch, superior officers informed him that the “German codes were unbreakable. I was told it wasn’t worthwhile putting pundits onto them. . . . Defeatism at the beginning of the war, to my mind, played a large part in delaying the breaking of the codes.”7 The naval codes were assigned to one officer and one clerk; not a single cryptanalyst was involved. Birch, however, thought the naval Enigma could be broken because it had to be. The U-boats put Britain’s very existence at stake. Turing had still another attitude. The fact that no one else wanted to work on the naval codes made them doubly attractive.
... codebook had to be “pinched,” as Turing put it. The wait for a pinch would stretch through ten nerve-racking months. As Turing waited desperately for the navy to get him a codebook, morale at GC&CS sank. Alastair G. Denniston, the head of GC&CS, told Birch, “You know, the Germans don’t mean you to read their stuff, and I don’t expect you ever will.”19
...A second bombe incorporating Welchman’s improvements arrived later that month, but the fight for more bombes continued throughout 1940. Birch complained that the British navy was not getting its fair share of the bombes: “Nor is it likely to. It has been argued that a large number of bombes would cost a lot of money, a lot of skilled labour to make and a lot of labour to run, as well as more electric power than is at present available here. Well, the is- sue is a simple one. Tot up the difficulties and balance them against the value to the Nation of being able to read current Enigma.”21
comment by snarles · 2011-08-30T14:01:30.702Z · LW(p) · GW(p)
Fisher's criticism of Bayesianism in Statistical Methods for Research Workers is rather pathetic--one of his justifications went along the lines of "since other intelligent people dismiss Bayesianism, there must be some reason to dismiss it." I would say that simple irrationality is insufficient to explain why clearly intelligent and experienced people would actively choose to ignore Bayesianism for such flimsy reasons. Instead, to explain the popularity of frequentism over Bayesianism, it is necessary to understand that scientists are motivated by more than the desire to obtain the correct answer; instead, science is a social activity in which researchers are motivated by the desire to obtain status and influence. In this regard, the fact that frequentism is more mathematically impressive and the fact that frequentism can give a better appearance of objectivity are important factors for explaining the popularity of frequentist methods.
That said, frequentist methods may indeed be better suited as the standard for mainstream science than Bayesian methods. The reason why frequentist methods seem more objective is because of their inflexibility. This same inflexibility makes it more difficult for researchers to engage in unsound practices like making multiple analyses of their data, and then only publishing the results which look the best. There is still a large enough variety of frequentist methods to make this sort of manipulation possible, but overall, frequentist methods still allow for less 'wiggle room' than Bayesian methods.
In contrast, if Bayesian methods were standard, all kinds of complicated hierarchical models might become the standard in academic literature. As few peer reviewers have both the background and patience to carefully scrutinize these models, the opportunity becomes much greater for the crafty researcher to "cheat" by adjusting their priors to best support their results. This may already be a problem in scientific fields where Bayesian methods are accepted.
comment by Pattern · 2020-10-21T18:45:55.845Z · LW(p) · GW(p)
Finally, in 1983 the US Air Force sponsored a review of NASA's estimates of the probability of shuttle failure. NASA's estimate was 1 in 100,000. The contractor used Bayes and estimated the odds of rocket booster failure at 1 in 35. In 1986, Challengerexploded.
Who was the contractor?
comment by habryka (habryka4) · 2020-09-13T02:06:08.770Z · LW(p) · GW(p)
Edit Note: Fixed some broken images and formatting
comment by snarles · 2011-09-03T01:04:41.255Z · LW(p) · GW(p)
But Tukey publicly denied Bayesianism. When working on the NBC projects, he said he wasn't using Bayes, instead he was "borrowing strength." He didn't allow anybody on his team to talk about their methods, either, saying it was proprietary information.
According to this paper, Tukey used the term "borrowing strength" to describe empirical Bayes techniques, which comprise an entirely different methodology than Bayesianism.
Replies from: fool, gwern↑ comment by fool · 2011-09-03T16:05:28.519Z · LW(p) · GW(p)
Good-Turing estimation which was part of the Enigma project should also go under the empirical heading.
↑ comment by gwern · 2012-06-13T21:02:39.206Z · LW(p) · GW(p)
In what sense is empirical Bayes - using the frequencies in initial data to set the original priors - "entirely" different from "Bayesianism", as opposed to be an interesting subset or variation?
Replies from: snarles↑ comment by snarles · 2012-07-02T19:20:35.378Z · LW(p) · GW(p)
Empirical Bayes procedures can be shown to be robust to the distribution of the data in a way that Bayesian procedures cannot. The difference between Empirical bayes and Bayesianism along this important dimension make them very distinct procedures from the perspective of many users.
This difference is most commonly seen in practice when some density must be estimated for inference. Use of kernel density estimation in empirical Bayes ensures an asymptotic convergence to the true density at some rate. In contrast, no Bayesian prior has yet been developed with consistency for density estimation.
comment by eclecticos · 2020-09-13T01:01:23.444Z · LW(p) · GW(p)
Thanks very much for this summary of the book. Quick correction -- the second time you mention Dennis Lindley, you refer to him as David Lindley.
comment by Fabrice Pautot (fabrice-pautot) · 2019-12-11T21:01:31.631Z · LW(p) · GW(p)
Poincaré a frequentist? Very bad joke.
comment by gwern · 2012-06-13T21:09:45.095Z · LW(p) · GW(p)
I enjoyed the book a lot; McGrayne has a good eye for the amusing details, and she conveys at least some of the intuition (although some graphs or examples would have helped the reader - I liked the flipping coin illustrations in Dasivia 2006 Bayesian Data Analysis). It's also remarkably synoptic: I was repeatedly surprised by names popping up in the chronology, like BUGS, Bretthorst, Fisher's smoking papers, Diaconis, the actuarial use of Bayes etc, and I have a better impression of Laplace and Good's many contributions. The math was very light, which undermines the value of much of it since unless one is already an expert one doesn't know how much the author is falsifying (for the best reasons), and means that some connections are missed (like empirical Bayes being a forerunner of hierarchical modeling, which aren't well-explained themselves).
comment by loup-vaillant · 2011-08-30T09:55:57.856Z · LW(p) · GW(p)
I find funny that Poincaré and Kolmogorov, though frequentists, fell back on Bayesianism when they really needed to win.
Replies from: fool↑ comment by fool · 2011-08-31T02:15:20.605Z · LW(p) · GW(p)
No comment at this time on Kolmogorov, but the Poincaré example I found particularly sketchy. Clearly Bertillon and arguably also Poincaré were not trying to use mathematics to find the right answer, they had a right answer in mind and were trying to convince others of it. (Lies, damned lies, and statistics, as they say.)
In any case Poincaré was not putting forth a mathematical argument for innonce so much as destroying Bertillon's mathematical argument for guilt. Are we really sure he advocated the use of subjective priors here? (And again, the controversial point is not Bayes' Theorem itself, but the priors). So I would like to see more details on this.
comment by ksvanhorn · 2011-08-29T19:01:00.382Z · LW(p) · GW(p)
Thanks for the interesting review. Sounds like a book I'll want to read.
Still... no mention of Jaynes and the method of maximum entropy? No mention of Cox's Theorem?
Replies from: gwern↑ comment by gwern · 2012-06-13T21:04:27.176Z · LW(p) · GW(p)
Cox is not mentioned. Jaynes is mentioned twice:
A loss of leadership, a series of career changes, and geographical moves contributed to the gloom. Jimmie Savage, chief U.S. spokesman for Bayes as a logical and comprehensive system, died of a heart attack in 1971. After Fermi’s death, Harold Jeffreys and American physicist Edwin T. Jaynes campaigned in vain for Bayes in the physical sciences; Jaynes, who said he always checked to see what Laplace had done before tackling an applied problem, turned off many colleagues with his Bayesian fervor.
and later:
Medical testing, in particular, benefited from Bayesian analysis. Many medical tests involve imaging, and Larry Bretthorst, a student of the Bayes- ian physicist Ed Jaynes, improved nuclear magnetic resonancing, or NMR, signal detection by several orders of magnitude in 1990. Bretthorst had studied imaging problems to improve the detection of radar signals for the Army Missile Command.
comment by Asymmetric · 2011-10-13T01:11:32.935Z · LW(p) · GW(p)
Are there any instances of Bayes failing, or achieving a less correct prediction in hindsight than a frequentist calculation? There must be a reason why frequentists exist.