Funnel plots: the study that didn't bark, or, visualizing regression to the null
post by gwern · 2011-12-04T11:05:08.326Z · LW · GW · Legacy · 35 commentsContents
35 comments
Marginal Revolution linked a post at Genomes Unzipped, "Size matters, and other lessons from medical genetics", with the interesting centerpiece graph:

This is from pg 3 of an Ioannidis 2001 et al article (who else?) on what is called a funnel plot: each line represents a series of studies about some particularly hot gene-disease correlations, plotted where Y = the odds ratio (measure of effect size; all results are 'statistically significant', of course) and X = the sample size. The 1 line is the null hypothesis, here. You will notice something dramatic: as we move along the X-axis and sample sizes increase, everything begins to converge on 1:
Readers familiar with the history of medical association studies will be unsurprised by what happened over the next few years: initial excitement (this same polymorphism was associated with diabetes! And longevity!) was followed by inconclusive replication studies and, ultimately, disappointment. In 2000, 8 years after the initial report, a large study involving over 5,000 cases and controls found absolutely no detectable effect of the ACE polymorphism on heart attack risk. In the meantime, the same polymorphism had turned up in dozens of other association studies for a wide range of traits ranging from obstetric cholestasis to meningococcal disease in children, virtually none of which have ever been convincingly replicated.
(See also "Why epidemiology will not correct itself" or the DNB FAQ.)
This graph is interesting as it shows 8 different regressions to the mean. What is also interesting is what a funnel plot is usually used for, why I ran into it in the first place reading Cochrane Group materials - it's used to show publication bias.
That is, suppose you were looking at a gene you know for certain not to be correlated (you knew the null result to be true), and you ran many trials, each with a different number of samples; you would expect that the trials with small samples would have a wide scattering of results (sometimes the effect size would look wildly large and sometimes they would look wildly small or negative), and that this scattering would be equally for and against any connection (on either side of the 1 line). By the same reasoning you would expect that your largest samples would only be scattered a little bit on either side of the 1 line, and the larger the sample the closer they will be to the 1/null line.
If you plotted your hypothetical trials on the above graph, you'd see what looks pretty much like the above graph - a kind of triangular cloud, wide on the left and ever narrowing towards the right as sample sizes increase and variance decreases.
Now here's the question: given that all 8 correlations trend steadily towards the null hypothesis, one would seem to expect them to actually be the null result. But if that is so, where are the random trials scattered on the other side of the 1 line? Not one sequence of studies ever crosses the 1 line!
The ACE story is not unique; time and time again, initial reports of associations between candidate genes and complex diseases failed to replicate in subsequent studies. With the benefit of hindsight, the problem is clear: in general, common genetic polymorphisms have very small effects on disease risk. Detecting these subtle effects requires studying not dozens or hundreds, but thousands or tens-of-thousands of individuals. Smaller studies, which had no power to detect these small effects, were essentially random p-value generators. Sometimes the p-values were “significant” and sometimes not, without any correlation to whether a variant was truly associated. Additionally, since investigators were often looking at only a few variants (often just one!) in a single gene that they strongly believed to be involved in the disease, they were often able to subset the data (splitting males and females, for example) to find “significant” results in some subgroup. This, combined with a tendency to publish positive results and leave negative results in a desk drawer, resulted in a conflicted and confusing body of literature which actively retarded medical genetics progress.
Wikipedia's funnel chart graph shows us how a plot should look (with this time sample size being the Y axis and odds being the X axis, so the triangle is rotated):
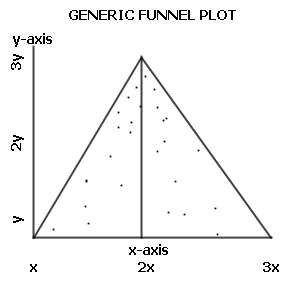
Does that describe any of the sequences graphed above?
35 comments
Comments sorted by top scores.
comment by Scott Alexander (Yvain) · 2011-12-04T13:00:24.427Z · LW(p) · GW(p)
I don't think your point applies to this specific graph, since it is a cumulative odds ratio graph selected for initially high error in one direction.
Associations from Ioannides' analysis were selected for inclusion on this graph because there were dramatic changes from the first study to the next studies - in this case, because the first study had a high effect size and the others showed lower effect sizes. Studies were selected for Ioannides' analysis in the first place because there were meta-analyses around them - which means lots of people tried to replicate them - which means the initial result must have been surprising and interesting. So these have been double-selected already for original studies likely to have high errors.
In a cumulative odds ratio graph (unlike the individual odds ratio graphs of the classic funnel plot), most of the work of subsequent studies will go to bringing the trend line closer to the mean. Even a study that shows an effect in the opposite direction as the original won't move the trend line to the other side of the identity line if the effect is smaller. So if the graph is arranged so that the most surprising and deviant result is the first, then it could very well look like this one even if there were no publication bias.
This is doubly true when the graphs are not actually converging to one - Ioannides' paper admits that three of these are probably real associations, and this is most obvious here on the DRD2 line, which converges around .5.
Replies from: dlthomas↑ comment by dlthomas · 2011-12-08T16:00:27.852Z · LW(p) · GW(p)
[A] cumulative odds ratio graph [is] unlike the individual odds ratio graphs of the classic funnel plot[.]
The original article should be edited to include note of this. As it stands, it is misleading. The original plot may or may not show problems, but expecting it to look like the "generic funnel plot" image is wrong.
comment by orthonormal · 2011-12-03T23:23:27.256Z · LW(p) · GW(p)
Feynman talked about this exact phenomenon in physics, with an excellent explanation:
We have learned a lot from experience about how to handle some of the ways we fool ourselves. One example: Millikan measured the charge on an electron by an experiment with falling oil drops, and got an answer which we now know not to be quite right. It's a little bit off, because he had the incorrect value for the viscosity of air. It's interesting to look at the history of measurements of the charge of the electron, after Millikan. If you plot them as a function of time, you find that one is a little bigger than Millikan's, and the next one's a little bit bigger than that, and the next one's a little bit bigger than that, until finally they settle down to a number which is higher.
Why didn't they discover that the new number was higher right away? It's a thing that scientists are ashamed of--this history--because it's apparent that people did things like this: When they got a number that was too high above Millikan's, they thought something must be wrong--and they would look for and find a reason why something might be wrong. When they got a number closer to Millikan's value they didn't look so hard. And so they eliminated the numbers that were too far off, and did other things like that. We've learned those tricks nowadays, and now we don't have that kind of a disease.
But this long history of learning how not to fool ourselves--of having utter scientific integrity--is, I'm sorry to say, something that we haven't specifically included in any particular course that I know of. We just hope you've caught on by osmosis.
ETA: Citation from Cargo Cult Science.
Replies from: Normal_Anomaly↑ comment by Normal_Anomaly · 2011-12-03T23:53:42.741Z · LW(p) · GW(p)
This is one of the most annoying things about grade school science labs for me. We already know going into the lab what the result should be, and if we get something different we know we need to figure out where we went wrong. The fact is that high school students are never going to get the same accuracy and precision as professional experimenters, but labs should still be conducted before the lesson on the principles involved. Then afterward teachers can ask the students whether they think their numbers are too high, or too low, or whatever.
Replies from: RomeoStevens↑ comment by RomeoStevens · 2011-12-05T08:27:06.888Z · LW(p) · GW(p)
yes, potential sources of error should be thought about and discussed openly BEFORE and AFTER the experiment and only then should the theoretical results be compared.
comment by lessdazed · 2011-12-01T03:39:51.032Z · LW(p) · GW(p)
Even if the community of inquiry is both too clueless to make any contact with reality and too honest to nudge borderline findings into significance, so long as they can keep coming up with new phenomena to look for, the mechanism of the file-drawer problem alone will guarantee a steady stream of new results. There is, so far as I know, no Journal of Evidence-Based Haruspicy filled, issue after issue, with methodologically-faultless papers reporting the ability of sheeps' livers to predict the winners of sumo championships, the outcome of speed dates, or real estate trends in selected suburbs of Chicago. But the difficulty can only be that the evidence-based haruspices aren't trying hard enough, and some friendly rivalry with the plastromancers is called for. It's true that none of these findings will last forever, but this constant overturning of old ideas by new discoveries is just part of what makes this such a dynamic time in the field of haruspicy. Many scholars will even tell you that their favorite part of being a haruspex is the frequency with which a new sacrifice over-turns everything they thought they knew about reading the future from a sheep's liver! We are very excited about the renewed interest on the part of policy-makers in the recommendations of the mantic arts...
comment by Matt_Simpson · 2011-11-30T20:57:47.438Z · LW(p) · GW(p)
Here's an example of funnel plots used in a completely different context - this time showing that a BBC reporter is overinterpreting statistical noise. (Hilarilously, the BBC makes a public statement defending their report that shows that they - whoever wrote the statement anyway - failed to understand the criticism, see this for a catalog of the back and forth).
Replies from: XFrequentist↑ comment by XFrequentist · 2011-11-30T21:36:17.879Z · LW(p) · GW(p)
Dr Goldacre suggests the difference between the best- and worst-performing authorities falls within a range that could be expected through chance. But this does not change the fact that there is a threefold difference between the best and worst local authorities.
Emphasis added for extra hilarity.
comment by vi21maobk9vp · 2011-11-30T19:23:04.343Z · LW(p) · GW(p)
Links, fonts, font styles... Maybe you could include a short summary of publication bias just here.
Something like:
Imagine 50 groups measuring the same non-correlation using 5% significance margin. Two groups will publish proved correlation; 48 will have no publishable results.
Replies from: gwern↑ comment by gwern · 2011-11-30T19:27:57.426Z · LW(p) · GW(p)
Don't we all know what publication bias is here?
Replies from: James_Miller, vi21maobk9vp↑ comment by James_Miller · 2011-11-30T21:45:49.656Z · LW(p) · GW(p)
Write for the audience we want, not just the one we have.
Replies from: Jayson_Virissimo↑ comment by Jayson_Virissimo · 2011-12-07T14:13:14.485Z · LW(p) · GW(p)
Better yet, write for the audience we have and hyperlink to the wiki for the rest.
↑ comment by vi21maobk9vp · 2011-12-01T04:32:25.140Z · LW(p) · GW(p)
If the post is just a data point for those who know the basics, it could be cut to its first 3 paragraphs without loss. If the post explains things for those have randomly found LW, it brief summary of publication bias near the beginning could increase expected amount of use derived from reading the post.
comment by Unnamed · 2011-11-30T19:59:48.935Z · LW(p) · GW(p)
Y = chance there's a real correlation
The y-axis shows the effect size (the odds ratio in this sample), which is different from statistical significance (the probability that the relationship observed in this sample would occur purely by chance). This passage:
you would expect that the trials with small samples would have a wide scattering of results (sometimes they would look wildly significant and sometimes they would look wildly insignficant)
should also be written in terms of effect sizes, rather than statistical significance.
Replies from: gwerncomment by EvelynM · 2011-11-30T18:27:58.393Z · LW(p) · GW(p)
Do I get your main point correctly that: If all studies were published the line in the upper graph would meander around the 1 line, but because all points fall either above OR below the 1 line, we can assume only studies that showed positive results were published?
Is it possible to put a bounds on the number of studies|same size that were NOT published, if we assume an equal likelihood of a point being on either side of the 1 line?
Replies from: gwern↑ comment by gwern · 2011-11-30T19:12:22.111Z · LW(p) · GW(p)
Yes.
I'm sure you could, since it's just estimating the other half of the distribution. But you're really going to need that assumption, which is not necessarily safe (eg. imagine flipping a fair coin - by a magician who unconsciously wants it to come up heads. It'd fail a funnel graph but not because of publication bias. And there are many ways to hire magician flippers).
Replies from: Dan_Moore↑ comment by Dan_Moore · 2011-12-13T15:18:49.788Z · LW(p) · GW(p)
If the statistical significance of the studies are valid, then it's quite unlikely that the lines would cross the x-axis. What Ionnidis is demonstrating is an overstatement of effect size in the initial studies.
Also, Yvain's point that a cumulative odds ratio graph is different from a generic funnel plot.
comment by thomblake · 2011-11-30T20:37:05.996Z · LW(p) · GW(p)
What is also interesting is what a funnel plot is usually used for, why I ran into it in the first place reading Cochrane Group materials - it's used to show publication bias.
Interesting - the linked article seems to argue that funnel plots are not good for showing publication bias.
Replies from: JoshuaZ↑ comment by JoshuaZ · 2011-11-30T20:45:00.619Z · LW(p) · GW(p)
They are useful for showing publication bias when the bias is not in a subtle form. But they aren't great for subtle biases. Also, a distorted funnel plot can be caused by other issues. Some types of measurement errors and statistical biases can result in weird results on a funnel plot. Like any specific tool, they have definite limits and should be used in conjunction with other tools.
comment by Vaniver · 2011-11-30T19:25:17.093Z · LW(p) · GW(p)
I agree with the general idea, but I'm not sure I agree on the particulars. The black association, for example, looks like it's converging to ~.6, not 1, as we do see it go above and below that. I expect publication bias to be a real problem, but I also expect that some of these associations are real but exaggerated in their original small samples (otherwise you wouldn't notice them!).
comment by Dan_Moore · 2011-11-30T23:32:24.075Z · LW(p) · GW(p)
I'm planning on doing a statistical study with a sample size of 21 companies. This is a financial study, and the companies chosen are the only ones that will be reporting their 2011 financial results on a certain basis necessary for the testing. (Hence the sample size.)
I'm going to do this regardless of which hypothesis is supported (the null hypothesis, my alternative hypothesis, or neither). So, I'm promising an absence of publication bias. (The null hypothesis will be supported by a finding of little or no correlation; my alternative hypothesis by a negative correlation.)
In this case, the small sample size is the result of available data, and not the result of data-mining. If the results are statistically significant and have a sizable effect, I'm of the opinion that the conclusions will be valid.
Replies from: Brickman↑ comment by Brickman · 2011-12-01T03:03:57.929Z · LW(p) · GW(p)
Sadly, your commitment to this goal is not enough, unless you also have a guarantee that someone will publish your results even if they are statistically insignificant (and thus tell us absolutely nothing). I admit I've never tried to publish something, but I doubt that many journals would actually do that. If they did the result would be a journal rendered almost unreadable by the large percentage of studies it describes with no significant outcome, and would remain unread.
If your study doesn't prove either hypothesis, or possibly even if it proves the null hypothesis and that's not deemed to be very enlightening, I expect you'll try and fail to get it published. If you prove the alternative hypothesis, you'll probably stand a fair chance at publication. Publication bias is a result of the whole system, not just the researchers' greed.
The only way I can imagine a study that admits that it didn't prove anything could get publication is if it was conducted by an individual or group too important to ignore even when they're not proving anything. Or if there's so few studies to choose from that they can't pick and choose the important ones, although fields like that would probably just publish fewer journals less frequently.
Replies from: TimS, Dan_Moore, dlthomas↑ comment by TimS · 2011-12-01T03:15:16.631Z · LW(p) · GW(p)
You might find this discussion of the publication of a null result paper interesting.
↑ comment by Dan_Moore · 2011-12-01T15:15:52.750Z · LW(p) · GW(p)
If I can't get this study published in the traditional way, I'll "publish" it myself on the internet.
In this case, what I'm calling the null hypothesis is somewhat meatier than a null hypothesis you would typically find in a medical study. The voluntary supplemental financial reporting for these (insurance) companies (starting with 2011) is something called market consistent embedded value (MCEV). My null hypothesis is that the phrase 'market consistent' is accurate - this is roughly equivalent to assuming that, in valuing the long-term liabilities of these companies, market participants pretend that they are securities with the same cashflows. My alternate hypothesis is that market participants value these liabilities within a framework of the company as a going concern, focusing on the company's cost of meeting these liabilities.
Replies from: garethrees, syllogism↑ comment by garethrees · 2013-02-24T01:41:54.235Z · LW(p) · GW(p)
If I can't get this study published in the traditional way, I'll "publish" it myself on the internet.
There's always the Journal of Articles in Support of the Null Hypothesis.
↑ comment by syllogism · 2011-12-08T00:54:21.917Z · LW(p) · GW(p)
If I can't get this study published in the traditional way, I'll "publish" it myself on the internet.
Where it will be only slightly more visible than a study "published" in your file drawer. I do agree you should do your best, though.
Replies from: dlthomas↑ comment by dlthomas · 2011-12-08T01:07:37.953Z · LW(p) · GW(p)
If they did the result would be a journal rendered almost unreadable by the large percentage of studies it describes with no significant outcome, and would remain unread.
This depends on how it was organized. Data sets could be maintained, and only checked when papers show interesting results in nearby areas.
comment by XFrequentist · 2011-11-30T21:36:40.804Z · LW(p) · GW(p)
as the sample axis, everything begins to converge on 1
Did you mean:
"as the sample axis increases, everything begins to converge on 1"?
comment by gwern · 2012-06-09T18:05:16.287Z · LW(p) · GW(p)
My current 2 meta-analyses, for dual n-back & IQ, and iodine, include funnel & forest plots, if anyone wants to look at them.
comment by [deleted] · 2011-11-30T21:58:55.529Z · LW(p) · GW(p)
Hypothesis A: Some medical genetics researchers are unaware of the fact that gene-disease correlation studies involving only a small number of subjects or alleles are of very little value.
Hypothesis B: Some medical researchers, despite having encountered facts such as those described in gwern's article, either through dishonesty or self-delusion conduct studies involving small numbers of subjects or alleles, in order to be able to publish some apparently valuable research.
Hypothesis C: There is some other good reason for conducting studies in medical genetics using small numbers of subjects or alleles, despite the fact that the results of such studies appear to be, in many cases, so widely scattered as to be meaningless.
Replies from: gwern↑ comment by gwern · 2011-11-30T22:18:38.687Z · LW(p) · GW(p)
Have you read the linked and previous article "Why epidemiology will not correct itself"?
Replies from: None↑ comment by [deleted] · 2011-11-30T22:54:49.324Z · LW(p) · GW(p)
I had not, and I see that you addressed my poser there.
From the abstract of a paper that you linked to:
a research finding is less likely to be true [...] when there is greater financial and other interest and prejudice; and when more teams are involved in a scientific field in chase of statistical significance.
This corroborates my suspicion that effect B is more important than A or C; competition for funding and prestige leads researchers to knowingly publish false positives.
Another somewhat relevant article and discussion thread is here, concerning declining standards in published research due to oversupply. I'm not sure if the writer has a good handle on the root causes of the problem though.