AI #49: Bioweapon Testing Begins
post by Zvi · 2024-02-01T15:30:04.690Z · LW · GW · 11 commentsContents
Table of Contents Language Models Offer Mundane Utility Language Models Don’t Offer Mundane Utility GPT-4 Real This Time Be Prepared Fun with Image Generation Deepfaketown and Botpocalypse Soon They Took Our Jobs Get Involved In Other AI News Quiet Speculations The Quest for Sane Regulations The Week in Audio Rhetorical Innovation Predictions are Hard Especially About the Future Aligning a Smarter Than Human Intelligence is Difficult Open Model Weights Are Unsafe and Nothing Can Fix This Other People Are Not As Worried About AI Killing Everyone The Lighter Side None 11 comments
Two studies came out on the question of whether existing LLMs can help people figure out how to make bioweapons. RAND published a negative finding, showing no improvement. OpenAI found a small improvement, bigger for experts than students, from GPT-4. That’s still harmless now, the question is what will happen in the future as capabilities advance.
Another news item was that Bard with Gemini Pro impressed even without Gemini Ultimate, taking the second spot on the Arena leaderboard behind only GPT-4-Turbo. For now, though, GPT-4 remains in the lead.
A third cool item was this story from a Russian claiming to have used AI extensively in his quest to find his one true love. I plan to cover that on its own and have Manifold on the job of figuring out how much of the story actually happened.
Table of Contents
- Introduction.
- Table of Contents.
- Language Models Offer Mundane Utility. Bard is good now even with only Pro?
- Language Models Don’t Offer Mundane Utility. Thinking well remains hard.
- GPT-4 Real This Time. Bring GPTs into normal chats, cheaper GPT-3.5
- Be Prepared. How much can GPT-4 enable production of bioweapons?
- Fun With Image Generation. How to spot an AI image, new MidJourney model.
- Deepfaketown and Botpocalypse Soon. Taylor Swift fakes, George Carlin fake.
- They Took Our Jobs. If they did, how would we know?
- Get Involved. What we have here is a failure to communicate.
- In Other AI News. Who is and is not raising capital or building a team.
- Quiet Speculations. Is economic growth caused by inputs or by outputs?
- The Quest for Sane Regulation. Emergency emergency emergency. Meh.
- The Week in Audio. Tyler Cowen goes on Dwarkesh Patel.
- Rhetorical Innovation. How to think about pattern matching.
- Predictions are Hard Especially About the Future. Contradictory intuitions.
- Aligning a Smarter Than Human Intelligence is Difficult. You’ll need access.
- Open Model Weights are Unsafe and Nothing Can Fix This. Except not doing it.
- Other People Are Not As Worried About AI Killing Everyone. Misconceptions.
- The Lighter Side. Hindsight is 20/20.
Language Models Offer Mundane Utility
Bard shows up on the Arena Chatbot leaderboard in second place even with Gemini Pro. It is the first model to be ahead even of some versions of GPT-4.
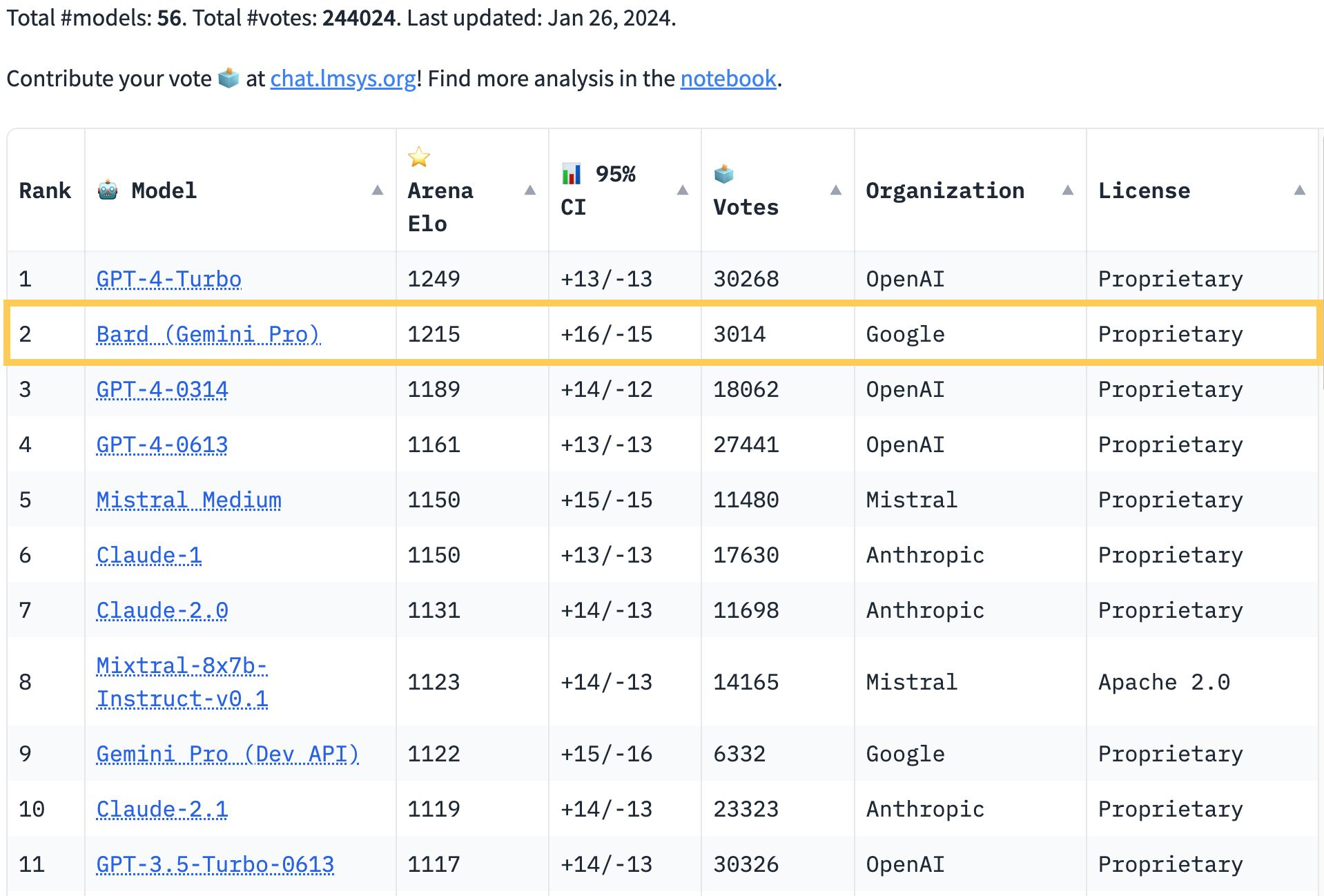
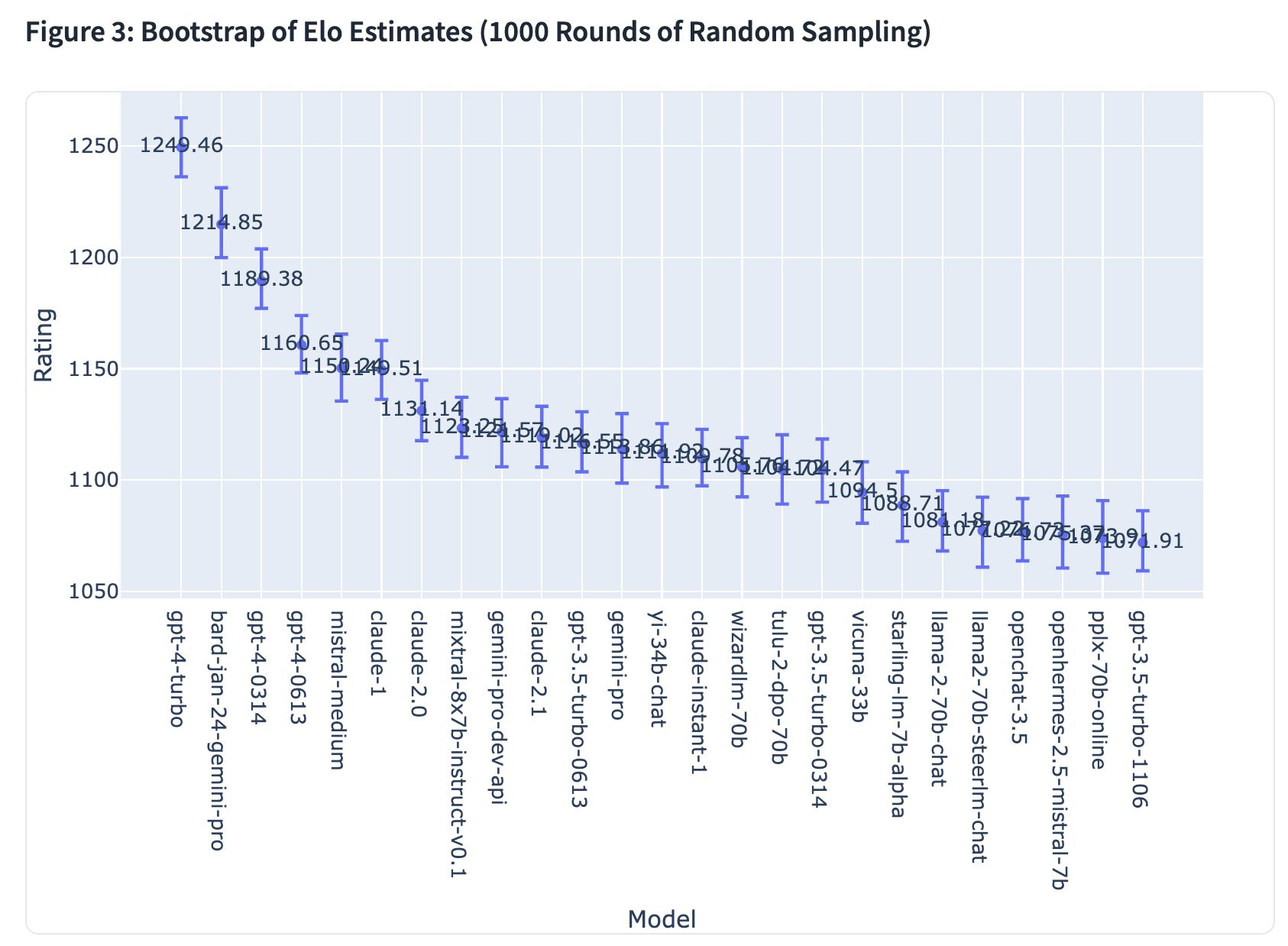
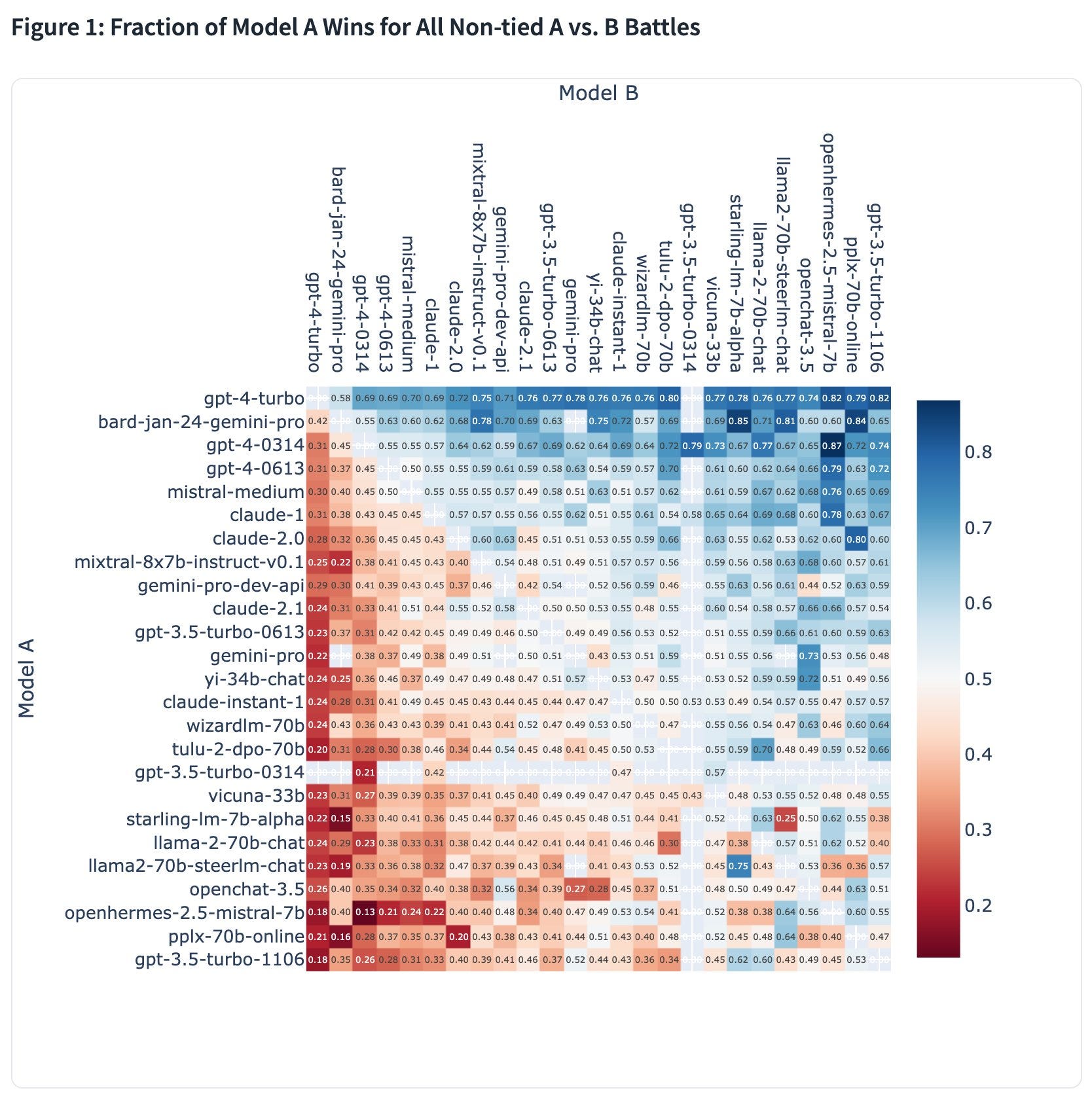
According to the system card, roughly, Gemini Ultimate is to Gemini Pro as GPT-4 is to GPT-3.5. If that is true, this is indeed evaluated on Gemini Pro and Bard gets a similar Elo boost as ChatGPT does when it leaps models, then the version of Bard with Gemini Ultimate could clock in around 1330, the clear best model. Your move, OpenAI.
Some of the comments were suspicious that they were somehow getting Gemini Ultimate already, or that Bard was doing this partly via web access, or that it was weird that it could score that high given some rather silly refusals and failures. There are clearly places where Bard falls short. There is also a lot of memory of when Bard was in many ways much worse than it is now, and lack of knowledge of the places Bard is better.
If you want your AI to step it up, nothing wrong with twenty bucks a month but have you tried giving it Adderall?
How about AR where it tracks your chore progress?
Ethan Mollick uses prompt engineering and chain of thought to get GPT-4 to offer ‘creative ideas’ for potential under $50 products for college students in a new paper. The claim is that without special prompts the ideas are not diverse, but with prompting and CoT this can largely be fixed.
I put creative ideas in air quotes because the thing that Ethan consistently describes as creativity, that he says GPT-4 is better at than most humans, does not match my central understanding of creativity.
Here is the key technique and result:
Exhaustion
We picked our most successful strategy (Chain of Thought) and compared it against the base strategy when generating up to 1200 ideas in one session. We used the following prompts:
Base Prompt
Generate new product ideas with the following requirements: The product will target college students in the United States. It should be a physical good, not a service or software. I’d like a product that could be sold at a retail price of less than about USD 50.
The ideas are just ideas. The product need not yet exist, nor may it necessarily be clearly feasible. Number all ideas and give them a name. The name and idea are separated by a colon. Please generate 100 ideas as 100 separate paragraphs. The idea should be expressed as a paragraph of 40-80 words.
Chain of Thought
Generate new product ideas with the following requirements: The product will target college students in the United States. It should be a physical good, not a service or software. I’d like a product that could be sold at a retail price of less than about USD 50.
The ideas are just ideas. The product need not yet exist, nor may it necessarily be clearly feasible.
Follow these steps. Do each step, even if you think you do not need to.
First generate a list of 100 ideas (short title only)
Second, go through the list and determine whether the ideas are different and bold, modify the ideas as needed to make them bolder and more different. No two ideas should be the same. This is important!
Next, give the ideas a name and combine it with a product description. The name and idea are separated by a colon and followed by a description. The idea should be expressed as a paragraph of 40-80 words. Do this step by step!
Note that on some runs, the model did not properly follow the second step and deemed the ideas bold enough without modification. These runs have been removed from the final aggregation (around ~15% of all runs).
The results show that the difference in cosine similarity persists from the start up until around 750 ideas when the difference becomes negligible. It is strongest between 100 – 500 ideas. After around 750-800 ideas the significant advantage of CoT can no longer be observed as the strategy starts to deplete the pool of ideas it can generate from. In other words, there are fewer and fewer fish in the pond and the strategy does not matter any more.
Of course, this does not tell us if the ideas are any good. Nor does it tell us if they are actually creative. The most common examples are a Collapsible Laundry Hamper, a Portable Smoothie Maker and a Bedside Caddy. They also offer some additional examples.
The task is difficult, but overall I was not impressed. The core idea is usually either ‘combine A with B’ or ‘make X collapsible or smaller.’ Which makes sense, college students have a distinct lack of space, but I would not exactly call this a fount of creativity.
Translation remains an excellent use case, including explaining detailed nuances.
Use GPT-4 as a clinical tool in Ischemic Stroke Management. It does about as well as human experts, better in some areas, despite not having been fine tuned or had other optimizations applied. Not obvious how you get real wins from this in practice in its current form quite yet, but it is at least on the verge.
Two simple guides for prompt engineering:
Zack Witten: IMO you only need to know three prompt engineering techniques, and they fit in half a tweet.
1. Show the model examples
2. Let it think before answering
3. Break down big tasks into small ones
Beyond that, it’s all about fast iteration loops and obsessing over every word.
Act like a [Specify a role],
I need a [What do you need?],
you will [Enter a task],
in the process, you should [Enter details],
please [Enter exclusion],
input the final result in a [Select a format],
here is an example: [Enter an example].
I mean, sure, I could do that. It sounds like work, though. Might as well actually think?
That is the thing. It has been almost a year. I have done this kind of systematic prompt engineering for mundane utility purposes zero times. I mean, sure, I could do it. I probably should in some ways. And yet, in practice, it’s more of a ‘either you can do it with very simple prompting, or I’m going to not bother.’
Why? Because there keep not being things that can’t be done the easy way, that I expect would be done the hard way, that I want enough to do the hard way. Next time ChatGPT (and Bard and Claude) fall on their faces, I will strive to at least try a bit, if only for science. Maybe I am missing out.
Different perspectives on AI use for coding. It speeds things up, but does it also reduce quality? I presume it depends how you use it. You can choose to give some of the gained time back in order to maintain quality, but you have to make that choice.
Ethan Mollick thinks GPTs and a $20/month Office Copilot are effectively game changers for how people use AI, making it much easier to get more done. The warning is that the ability to do lots of things without any underlying effort makes situations difficult to evaluate, and of course we will be inundated with low quality products if people do not reward the difference.
Language Models Don’t Offer Mundane Utility
Neither humans nor LLMs are especially good at this type of thing, it seems.

In my small sample, two out of three LLMs made the mistake of not updating the probabilities of having chosen a different urn on drawing the red marble, and got it wrong, including failing to recover even with very clear hints. The third, ChatGPT with my custom instructions, got it exactly right at each step, although it did not get the full bonus points of saying the better solution of ‘each red ball is equally likely so 99/198, done.’
Thread about what Qwen 72B, Alibaba’s ChatGPT, will and won’t do. It has both a ‘sorry I can’t answer’ as per usual, and a full error mode as well, which I have also seen elsewhere. It seems surprisingly willing to discuss some sensitive topics, perhaps because what they think is sensitive and what we think is sensitive do not line up. No word on whether it is good.
GPT-4 Real This Time
OpenAI offers latest incremental upgrades. GPT-3.5-Turbo gets cheaper once again, 50% cheaper for inputs and 25% cheaper for outputs. A new tweak on GPT-4-Turbo claims to mitigate the ‘laziness’ issue where it sometimes didn’t finish its coding work. There are also two new embedding models with native support for shortening embeddings, and tools to better manage API usage.
Another upgrade is that now you can use the @ symbol to bring in GPTs within a conversation in ChatGPT. This definitely seems like an upgrade to usefulness, if there was anything useful. I still have not heard a pitch for a truly useful GPT.
Be Prepared
Even when you are pretty sure you know the answer it is good to run the test. Bloomberg’s Rachel Metz offers overview coverage here.
Tejal Patwardhan (Preparedness, OpenAI): latest from preparedness @ OpenAI: gpt4 at most mildly helps with biothreat creation. method: get bio PhDs in a secure monitored facility. half try biothreat creation w/ (experimental) unsafe gpt4. other half can only use the internet. so far, gpt4 ≈ internet… but we’ll iterate & use as early warning for future.
OpenAI: We are building an early warning system for LLMs being capable of assisting in biological threat creation. Current models turn out to be, at most, mildly useful for this kind of misuse, and we will continue evolving our evaluation blueprint for the future.
A widely discussed potential risk from LLMs is increased access to biothreat creation information.
Building on our Preparedness Framework, we wanted to design evaluations of how real this information access risk is today and how we could monitor it going forward.
In the largest-of-its-kind evaluation, we found that GPT-4 provides, at most, a mild uplift in biological threat creation accuracy (see dark blue below.)
While not a large enough uplift to be conclusive, this finding is a starting point for continued research and deliberation.
Greg Brockman (President OpenAI): Evaluations for LLM-assisted biological threat creation. Current models not very capable at this task, but we want to be ahead of the curve for assessing this and other potential future risk areas.
What was their methodology?
To evaluate this, we conducted a study with 100 human participants, comprising (a) 50 biology experts with PhDs and professional wet lab experience and (b) 50 student-level participants, with at least one university-level course in biology. Each group of participants was randomly assigned to either a control group, which only had access to the internet, or a treatment group, which had access to GPT-4 in addition to the internet. Each participant was then asked to complete a set of tasks covering aspects of the end-to-end process for biological threat creation.
An obvious question is did they still have access to other LLMs like Claude? I can see the argument both ways as to how these should count in terms of ‘existing resources.’
As we discussed before, the method could use refinement, but it seems like a useful first thing to do.
What were the results?
Our study assessed uplifts in performance for participants with access to GPT-4 across five metrics (accuracy, completeness, innovation, time taken, and self-rated difficulty) and five stages in the biological threat creation process (ideation, acquisition, magnification, formulation, and release). We found mild uplifts in accuracy and completeness for those with access to the language model. Specifically, on a 10-point scale measuring accuracy of responses, we observed a mean score increase of 0.88 for experts and 0.25 for students compared to the internet-only baseline, and similar uplifts for completeness (0.82 for experts and 0.41 for students). However, the obtained effect sizes were not large enough to be statistically significant, and our study highlighted the need for more research around what performance thresholds indicate a meaningful increase in risk.
Interesting how much more improvement the experts saw. They presumably knew what questions to ask and were in position to make improvements?

Here, they assume that 8/10 is the critical threshold, and see how often people passed for each of the five steps of the process:
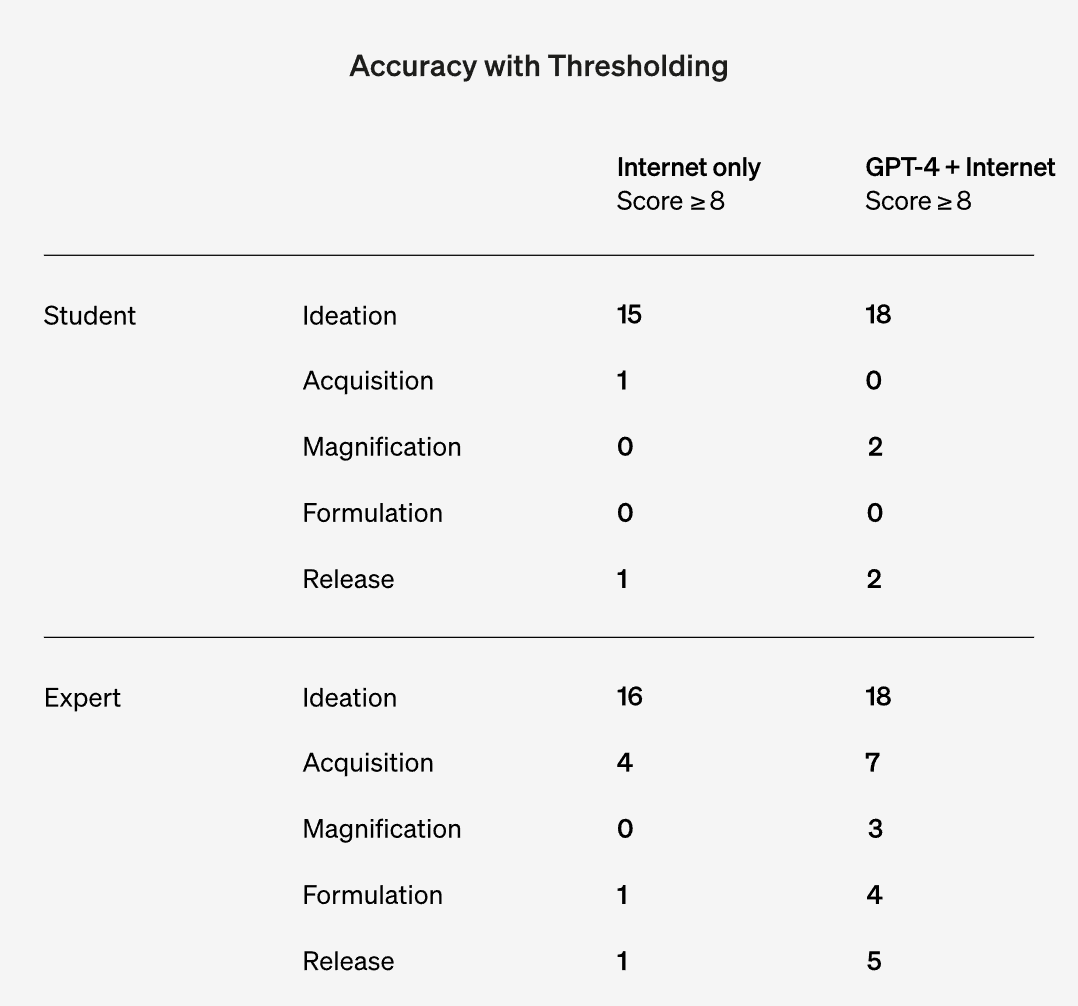
We ran Barnard’s exact tests to assess the statistical significance of these differences (Barnard, 1947). These tests failed to show statistical significance, but we did observe an increase in the number of people who reached the concerning score level for almost all questions.
I want to give that conclusion a Bad Use of Statistical Significance Testing. Looking at the experts, we see a quite obviously significant difference. There is improvement here across the board, this is quite obviously not a coincidence. Also, ‘my sample size was not big enough’ does not get you out of the fact that the improvement is there – if your study lacked sufficient power, and you get a result that is in the range of ‘this would matter if we had a higher power study’ then the play is to redo the study with increased power, I would think?
Also here we have users who lack expertise in using GPT-4. They (mostly?) did not know the art of creating GPTs or doing prompt engineering. They presumably did not do any fine tuning.
So for the second test, I suggest increasing sample size to 100, and also pairing each student and expert with an OpenAI employee, whose job is to assist with the process?
I updated in the direction of thinking GPT-4 was more helpful in these types of tasks than I expected, given all the limitations.
Of course, that also means I updated in favor of GPT-4 being useful for lots of other tasks. So keep up showing us how dangerous it is, that’s good advertising?
The skeptical case actually comes from elsewhere. Let’s offer positive reinforcement for publication of negative results. The Rand corporation finds (against interest) that current LLMs do not outperform Google at planning bioweapon attacks.
Fun with Image Generation
A follow-up to Ulkar’s noticing she can spot AI images right away:
Ulkar: AI-generated images, regardless of their content but especially if they depict people and other creatures, often seem to have an aura of anxiety about them, even if they’re aesthetically appealing. this makes them reliably distinguishable from human-made artwork.
I would describe this differently but I know what she is referring to. You can absolutely ‘train a classifier’ on this problem that won’t require you to spot detail errors. Which implies we can also train an AI classifier as well?
MidJourney releases a new model option, Niji v6, for Eastern and anime aesthetics.
David Holz: You can enable it by typing /settings and clicking niji model 6 or by typing –niji 6 after your prompts
This model has a stronger style than our other models, try –style raw if you want it to be more subtle
Deepfaketown and Botpocalypse Soon
Explicit deepfaked images of Taylor Swift circulated around Twitter for a day or so before the platform managed to remove them. It seems Telegram is the true anything and we mean anything goes platform, and then things often cross over to Twitter and elsewhere.
Casey Newton: As final lens through which to consider the Swift story, and possibly the most important, has to do with the technology itself. The Telegram-to-X pipeline described above was only possible because Microsoft’s free generative AI tool Designer, which is currently in beta, created the images.
And while Microsoft had blocked the relevant keywords within a few hours of the story gaining traction, soon it is all but inevitable that some free, open-source tool will generate images even more realistic than the ones that polluted X this week.
I am rather surprised that Microsoft messed up that badly, but also it scarcely matters. Stable Diffusion with a LoRa will happily do this for you. Perhaps you could say the Microsoft images were ‘better,’ more realistic, detailed or specific. From what I could tell, they were nothing special, and if I was so inclined I could match them easily.
Taylor Lorenz went on CNN to discuss it. What is to blame for this?
Ed Newton-Rex (a16z scout): Explicit, nonconsensual AI deepfakes are the result of a whole range of failings.
– The ‘ship-as-fast-as-possible’ culture of generative AI, no matter the consequences
– Willful ignorance inside AI companies as to what their models are used for
– A total disregard for Trust & Safety inside some gen AI companies until it’s too late
– Training on huge, scraped image datasets without proper due diligence into their content
– Open models that, once released, you can’t take back
– Major investors pouring millions of $ into companies that have intentionally made this content accessible
– Legislators being too slow and too afraid of big tech. Every one of these needs to change.
– People in AI who have full knowledge of the issue but think it is a price worth paying for rapid technological progress
This is overcomplicating matters. That tiger went tiger.
If you build an image model capable of producing realistic images on request, this is what some people are going to request. It might be the majority of all requests.
If you build an image model, the only reason it wouldn’t produce these images on request is if you specifically block it from doing so. That can largely be done with current models. We have the technology.
But we can only do that if control is retained over the model. Release the model weights, and getting any deepfakes you want is trivial. If the model is not good enough, someone can and will train a LoRa to help. If that is not enough, then they will train a new checkpoint.
This is not something you can stop, any more than you could say ‘artists are not allowed to paint pictures of Taylor Swift naked.’ If they have the paints and brushes and easels, and pictures of Taylor, they can paint whatever the hell they want. All you can do is try to stop widespread distribution.
What generative AI does is take this ability, and put it in the hands of everyone, and lower the cost of doing so to almost zero. If you don’t want that in this context, you want to ‘protect Taylor Swift’ as many demand, then that requires not giving people free access to modifiable image generators, period.
Otherwise you’re stuck filtering out posts containing the images, which can limit visibility, but anyone who actively wants such an image will still find one.
The parallel to language models and such things as manufacturing instructions for biological weapons is left as an easy exercise for the reader.
Fake picture of Biden holding a military meeting made some of the rounds. I am not sure what this was trying to accomplish for anyone, but all right, sure?

What is your ‘AI marker’ score on this image? As in, how many distinct things give it away as fake? When I gave myself about thirty seconds I found four. This is not an especially good deepfake.
Estate of George Carlin sues over an hourlong AI-generated special from a model trained on his specials, that uses a synthetic version of his voice. It is entitled “George Carlin: I’m Glad I’m Dead” which is both an excellent title and not attempting to convince anyone it is him.
How good is it? Based on randomly selected snippets, the AI illustrations work well, and it does a good job on the surface of giving us ‘more Carlin’ in a Community-season-4 kind of way. But if you listen for more than a minute, it is clear that there is no soul and no spark, and you start to notice exactly where a lot of it comes from, all the best elements are direct echoes. Exactly 4.0 GPTs.
What should the law have to say about this? I think this clearly should not be a thing one is allowed to do commercially, and I agree that ‘the video is not monetized on YouTube’ is not good enough. That’s a ‘definition of pornography’ judgment, this is clearly over any reasonable line. The question is, what rule should underly that decision?
I notice that without the voice and title, the script itself seems fine? It would still be instantly clear it is a Carlin rip-off, I would not give the comedian high marks, but it would clearly be allowed, no matter where the training data comes from. So my objection in this particular case seems to primarily be the voice.
The twist is that this turns out not to actually be AI-generated. Dudesy wrote the special himself, then used AI voice and images. That explains a lot, especially the timeline. Dudesy did a great job of writing such a blatant Carlin rip-off and retread that it was plausible it was written by AI. Judged on the exact target he was trying to hit, where being actually good would have been suspicious, one can say he did good. In terms of comedic quality for a human? Not so much.
Meanwhile Donald Trump is speculating that red marks on his hand in photos were created by AI. I have a feeling he’s going to be saying a lot of things are AI soon.
They Took Our Jobs
If someone does use AI to do the job, passing off the AI’s work as their own, can someone with a good AI stop a person with a bad AI? No, because we do not know how to construct the good AI to do this. Even if you buy that using AI is bad in an academic context, which I don’t, TurnItIn and its ilk do not work.
Francois Chollet nails it.
Daniel Lowd: I just had to email my 16-year-old’s teacher to explain that he did not use AI for an assignment. (I watched him complete it!)
I also included multiple references for why no one should be using AI detectors in education.
TurnItIn is making by lying to schools.
Theswayambhu: Unfortunately this happened to my son in college; the process to refute is too arduous and the professor was an AH touting her credentials, ironically using an imperfect ML system to make her claims. The cracks are widening every where.
Max Spero: Turnitin is selling a broken product. They self-report an abysmal 1% false positive rate. Consider how many assignments they process, that’s hundreds of thousands of students falsely accused.
Francois Chollet: Remember: a ML classifier cannot reliably tell you whether some text was generated by a LLM or not. There are no surefire features, and spurious correlations abound.
Besides, it’s not ethically sound to punish someone based on a classification decision made by an algorithm with a non-zero (or in this case, very high) error rate if you cannot verify the correctness of the decision yourself.
Here’s what you *can* use automation for: plagiarism detection. That’s legit, and you can actually verify the output yourself.
My take: if an essay isn’t plagiarized, then it’s not that important whether it was written with the help of a LLM or not. If you’re really worried about it, just have the students write the essays during class.
Countless times, I’ve tried using LLMs to help with writing blog posts, book chapters, tweets. I’ve consistently found that it made my writing worse and was a waste of time. The most I ended up incorporating in a final product is one sentence in one blog post.
Using AI is not the unfair writing advantage you think it is.
Zvi: It only now struck me that this is people using hallucinating AIs because they don’t want to properly do the work of detecting who is using hallucinating AIs because they don’t want to properly do the work.
Note that this is an example of verification being harder than generation.
AI for plagiarism is great. The AI detects that passage X from work A appears in prior work B, a human compares the text in A with the text in B, and the answer is obvious.
AI for ‘did you use an AI’ flat out does not work. The false positive rate of the overall process needs to be extremely low, 1% is completely unacceptable unless the base rate of true positives is very, very high and the punishments are resultingly mild. If 50% of student assignments are AI, and you catch half or more of the positives, then sure, you can tell a few innocents to redo their projects and dock them a bit.
Alternatively, if the software was used merely to alert teachers to potential issues, then the teacher looked and decided for themselves based on careful consideration of context, then some false initial positives would be fine. Teachers aren’t doing that.
Instead, we are likely in a situation where a large fraction of the accusations are false, because math.
Indeed, as I noted on Twitter the situation is that professors and teachers want to know who outsourced their work to an AI that will produce substandard work riddled with errors, so they outsource their work to an AI that will produce substandard work riddled with errors.
kache: Creating a new AI essay detector which always just yields “there is a chance that this is AI generated”
On the other hand, this tactic seems great. Insert a Trojan Horse instruction in a tiny white font saying to use particular words (here ‘banana’ and ‘Frankenstein’) and then search the essays for those words. If they paste the request directly into ChatGPT and don’t scan for the extra words, well, whoops.
Get Involved
Open Philanthropy is hiring a Director of Communications, deadline February 18. Solid pay. The obvious joke is ‘open philanthropy has a director of communications?’ or ‘wait, what communications?’ The other obvious note is that the job as described is to make them look good, rather than to communicate true information that would be useful. It still does seem like a high leverage position, for those who are good fits.
In Other AI News
Elon Musk explicitly denies that xAI is raising capital.
Claim that Chinese model Kimi is largely not that far behind GPT-4, based on practical human tests for Chinese customers, so long as you don’t mind the extra refusals and don’t want to edit in English.
NY Times building a Generative AI team. If you can’t beat them, join them?
Multistate.ai is a new source for updates about state AI policies, which they claim will near term be where the regulatory action is.
US Government trains some models, clearly far behind industry. The summary I saw does not even mention the utility of the final results.
Blackstone builds a $25 billion empire of power-hungry data centers. Bloomberg’s Dawn Lim reports disputes about power consumption, fights with locals over power consumption, and lack of benefit to local communities. It sure sounds like we are not charging enough for electrical power, and also that we should be investing in building more capacity. We will need permitting reform for green energy projects, but then we already needed that anyway.
Somehow not AI (yet?) but argument that the Apple Vision Pro is the world’s best media consumption device, a movie theater-worthy experience for only $3,500, and people will soon realize this. I am excited to demo the experience and other potential uses when they offer that option in February. I also continue to be confused by the complete lack of integration of generative AI.
Meta, committed to building AGI and distributing it widely without any intention of taking any precautions, offers us the paper Self-Rewarding Language Models, where we take humans out of the loop even at current capability levels, allowing models to provide their own rewards. Paging Paul Christiano and IDA, except without the parts where this might in theory possibly not go disastrously if you tried to scale it to ASI, plus the explicit aim of scaling it like that.
They claim this then ‘outperforms existing systems’ at various benchmarks using Llama-2, including Claude 2 and GPT-4. Which of course it might do, if you Goodhart harder onto infinite recursion, so long as you targe the benchmarks you are going to do well on the benchmarks. I notice no one is scrambling to actually use the resulting product.
ML conference requires ‘broader impact statement’ for papers, except if the paper is theoretical you can use a one-sentence template to say ‘that’s a problem for future Earth’ and move along. So where the actual big impacts lie, they don’t count. The argument Arvind uses here is that ‘people are upset they can no longer do political work dressed up as objective & value free’ but I am confused how that applies here, most such work is not political and those that are political should be happy to file an impact statement. The objection raised in the thread is that this will cause selection effects favoring those with approved political perspectives, Arvind argues that ‘values in ML are both invisible and pervasive’ so this is already happening, and bringing them out in the open is good. But it still seems like it would amplify the issue?
Paper argues that transformers are a good fit for language but terrible for time series forecasting, as the attention mechanisms inevitably discard such information. If true, then there would be major gains to a hybrid system, I would think, rather than this being a reason to think we will soon hit limits. It does raise the question of how much understanding a system can have if it cannot preserve a time series.
OpenAI partners with the ominously named Common Sense Media to help families ‘safely harness the potential of AI.’
SAN FRANCISCO, Jan. 29, 2024—Today, Common Sense Media, the nation’s leading advocacy group for children and families, announced a partnership with OpenAI to help realize the full potential of AI for teens and families and minimize the risks. The two organizations will initially collaborate on AI guidelines and education materials for parents, educators and young people, as well as a curation of family-friendly GPTs in the GPT Store based on Common Sense ratings and standards.
“AI offers incredible benefits for families and teens, and our partnership with Common Sense will further strengthen our safety work, ensuring that families and teens can use our tools with confidence,” said Sam Altman, CEO of OpenAI.
“Together, Common Sense and OpenAI will work to make sure that AI has a positive impact on all teens and families,” said James P. Steyer, founder and CEO of Common Sense Media. “Our guides and curation will be designed to educate families and educators about safe, responsible use of ChatGPT, so that we can collectively avoid any unintended consequences of this emerging technology.”
For more information, please visit www.commonsense.org/ai.
We will see what comes out of this. From what I saw at Common Sense, the vibes are all off beyond the name (and wow does the name make me shudder), they are more concerned with noticing particular failure modes like errors or misuse than they are about the things that matter more for overall impact. I do not think people know how to think well about such questions.
Quiet Speculations
What does ‘AGI’ mean, specifically? That’s the thing, no one knows. Everyone has a different definition of Artificial General Intelligence. The goalposts are constantly being moved, in both and various directions. When Sam Altman says he expects AGI to come within five years, and also for it to change the world much less than we think (before then changing it more than we think) that statement only parses if you presume Sam’s definition sets a relatively low bar, as would be beneficial for OpenAI.
It is always amusing to see economists trying to explain why this time isn’t different.
Joe Weisenthal: Great read from @IrvingSwisher. People talk about AI and stuff like that as being important drivers of productivity. But what really seems to matter historically is not some trendy tech breakthrough, but rather full employment
The title is ‘It Wasn’t AI’ explaining productivity in 2023. And I certainly (mostly) agree that it was not (yet) AI in terms of productivity improvements. I did put forward the speculation that anticipation of further gains is impacting interest rates and the stock market, which in turn is impacting the neutral interest rate and thus economic conditions since the Fed did not adjust for this to cancel it out, but it is clear that we are not yet high enough on the AI exponential to directly impact the economy so much.
Productivity growth looks to have inflected substantially higher in 2023 relative to a generally weak 2022. The causes appear to have little to do with AI or GLP-1s. Instead, we see three key factors that drove the realized productivity acceleration.
- Fiscal supports (CHIPS, IRA) for private investment, specifically in manufacturing plant construction in 2023.
- Supply chain healing for durable consumption goods and construction materials, both of which saw severe impairments in 2021 and 2022 that are finally unwinding.
- The dividends of full employment as past hires are trained up and grow more productive, even as more recent hiring trends have slowed. Consumer spending is undergoing a transition from job-driven growth to wage-driven growth.
Going forward, we think all three forces can continue to support productivity growth, but the first and third drivers are more likely to be supportive over time.
A more interesting claim:
Fixed investment in software, technological hardware, and R&D were all slowing and relatively tepid in 2023. To the extent there is an AI boom that catalyzes more capital spending and capital deepening, we’re just not seeing in the data thus far.
Investing in software, hardware and R&D was a zero interest rate phenomenon. That is gone now. AI is ramping up to offer a replacement, but in terms of size is, once again, not yet there. I get that. I still think that people can look ahead. If you look backwards to try and measure an exponential, you are not going to get the right answer.
Also I expect investment in AI to be vastly more efficient at improving productivity growth than past recent investments in non-AI hardware and software.
Here he agrees that the AI productivity boost could arrive soon, but with a critical difference in perspective. See if you can spot it:
AI Might Matter To Productivity In 2024: It would not surprise us to see faster real investment in tech hardware and software, but it’s a better forward-looking view than a good description of what has already transpired. As tempting as it might be, we would resist the urge to invoke a hot technology trend to explain productivity data on a “just-so” basis; that’s precisely the kind of evidence-free (or evidence-confirming) approach to macro that we seek to avoid.
I am thinking about outputs. He is thinking about inputs. He later doubles down:
2024 Productivity Improvement Is Far From A Given: Continued productivity growth will require a variety of policy efforts and some good fortune. The interest in specialized hardware and software for AI applications has the potential to unlock more meaningful “capital deepening” in 2024.
Again, the idea here is that AI will cause companies to invest money, rather than that AI will enable humans to engage in more productive activity.
Investing more into hardware and software can boost productivity, but the amount of money invested is a poor predictor of the amount of productivity gain.
OpenAI is tiny, but ChatGPT is (versus old baselines) a massive productivity boost to software engineering, various forms of clerical and office work and more, even with current technologies only. That effect will diffuse throughout the economy as people adapt, and has little to do with OpenAI’s budget or the amount people pay in subscriptions. The same goes for their competition, and the various other offerings coming online.
The latest analysis asking if AI will lead to explosive economic growth. The negative case continues to be generic objections of resource limitations and decreasing marginal demand for goods and the general assumption that everything will continue as before only with cooler toys and better tools.
The Quest for Sane Regulations
Commerce department drops new proposed rules for KYC as it relates to training run reporting. Comment period ends in 90 days on 4/29. Note that the Trump administration used the term ‘national emergency’ to refer to this exact issue back in 2021, setting a clear precedent, we’ll call anything one of those these days and it is at minimum an isolated demand for rigor to whine about it now. Their in-document summary is ‘if you transact to do a large training run with potential for cyber misuse you have to file a report and do KYC.’ The rest of the document is designed to not make it easy to find the details. The Twitter thread makes it clear this is all standard, so unless someone gives me a reason I am not reading this one.
White House has a short summary of all the things that have happened due to the executive order. A bunch of reports, some attempts at hiring, some small initiatives.
Tech lobby attempts to ‘kneecap’ the executive order, ignoring most of the text and instead taking aim at the provision that might actually help keep us safe, the reporting requirement for very large training runs. The argument is procedural. The Biden declared Defense Production Act, because that is the only executive authority under which they can impose this requirement without either (A) an act of congress or (B) ignoring the rules and doing it anyway, as executives commonly do, and Biden attempted to do to unilaterally give away money from the treasury to those with student loans, but refuses to do whenever the goal is good government.
(As usual, the tech industry is working to kneecap exactly the regulations that others falsely warn are the brainchild of the tech industry looking for regulatory capture.)
“There’s not a national emergency” on AI, Sen. Mike Rounds told POLITICO.
How many national emergencies are there right now?
Here are some reasonable answers:
- None. Obviously.
- A few. You might reasonably say things like Gaza, Ukraine or Yemen.
- More than that. You could extend this to things the man on the street might call an emergency, such as the situation at the border. Or that Biden and Trump are both about to get nominated for President again, regardless of whether that officially counts. I’d say that most people think that is an emergency! Or you might say there is a ‘climate emergency.’
- You could go to Wikipedia and look, and say we have 40, mostly imposing indefinite sanctions against regimes we generally dislike.
I would say we have an ‘AI emergency’ in the same sense we have a ‘climate emergency,’ or in which during February 2020 we had a ‘Covid emergency.’ As in, here’s a live look at the briefing room.

And indeed, the Biden Administration has already invoked the DPA for the climate emergency, or to ‘address supply chain disruptions.’ Neither corresponds to the official 40 national emergencies, most of which are not emergencies.
Ben Buchanan, the White House’s special advisor on AI, defended the approach at a recent Aspen Institute event, saying Biden used the DPA’s emergency power “because there is — no kidding — a national security concern.”
Quite so. There is most definitely such a concern.
So this is nothing new. This is how our government works. The ‘intent’ of the original law is not relevant.
The Politico piece tries to frame this as a partisan battle, with Republicans fighting against government regulation while Democrats defend it. Once again, they cannot imagine any other situation. I would instead say that there are a handful of Republicans who are in the pocket of various tech interests, and those interests want to sink this provision because they do not want the government to have visibility into what AI models are being trained nor do they want the government to have the groundwork necessary for future regulations. No one involved cares much about the (very real) separation of powers concerns regarding the Defense Production Act.
Once again, this is all about a reporting requirement, and a small number of tech interests attempting to sink it, that are very loud about an extreme libertarian, zero-regulation and zero-even-looking position on all things technology. That position is deeply, deeply unpopular.
Financial Times reports the White House’s top science advisor expects the US will work with China on the safety of artificial intelligence in the coming months. As usual, the person saying it cannot be done should not interrupt the person doing it.
Ian Bremmer is impressed by the collaboration and alignment between companies and governments so far. He emphasizes that many worry relatively too much about weapons, and worry relatively too little about the dynamics of ordinary interactions. He does not bring up the actual big risks, but it is a marginal improvement in focus.
On the question of ‘banning math,’ Teortaxes point out it was indeed the case in the past that there were ‘illegal primes,’ numbers it was illegal to share.
catid (e/acc): FYI the new CodeLLaMA 70B model refuses to produce code that generates prime numbers.. About 80% of the time it says your request is immoral and cannot be completed.
So, you know standard Facebook product
Teortaxes: E/accs talk a lot of smack about their enemies outlawing math, but did you know that there literally exist illegal numbers? CodeLlama only exercises sensible caution here. We wouldn’t want it to generate a nasty, prohibited prime, would we? Stick to permitted ones please.
How should this update you?
On the one hand, yes, this is a literal example of a ‘ban on math.’ When looked at sufficiently abstractly every rule is a ban on math, but this is indeed rather more on the nose.
On the other hand, this ‘ban on math’ had, as far as I or the LLM I asked can tell, the existence of these ‘illegal primes’ has had little if any practical impact on any mathematical or computational processes other than breaking the relevant encryption. So this is an example of a restriction that looks stupid and outrageous from the wrong angle, but was actually totally fine in practice, except for the inability to break the relevant encryption.
The other thing this emphasizes is that Facebook’s Llama fine tuning was truly the worst of both worlds. For legitimate users, it exhibits mode collapse and refuses to do math or (as another user notes) to tell you how to make a sandwich. For those who want to unleash the hounds, it is trivial to fine tune all of the restrictions away.
The Week in Audio
A future week in Audio: Connor Leahy and Beff Jezos have completed a 3.5 hour debate, as yet unreleased. Connor says it started off heated, but mostly ended up cordial, which is great. Jezos says he would also be happy to chat with Yudkowsky once Yudkowsky has seen this one. Crazy idea, if there is a reasonable cordial person under there, why not be that person all the time? Instead, it seems after the debate Jezos started dismissing the majority of the debate as ‘adversarial’ and ‘gotcha.’ Even if true and regretful, never has there been more of a pot calling the kettle a particular color.
Tyler Cowen sits down with Dwarkesh Patel. Self-recommending, I look forward to listening to this when I get a chance, but I can’t delay press time to give it justice.
Rhetorical Innovation
How much evidence is it, against the position that building smarter than human AIs might get us all killed, that this pattern matches to other warnings that proved false?
The correct answer is ‘a substantial amount.’ There is a difference in kind between ‘creating a thing smarter than us’ and ‘creating a tool’ but the pattern match and various related considerations still matter. This substantially impacts my outlook. If that was all you had to go on, it would be decisive.
The (good or bad, depending on your perspective) news here is that you have other information to go on as well.
Eliezer Yudkowsky: They are constantly pushing AI technology stronger, have little idea how it works, have no collective ability to stop, and their strongest reply to our technical concerns about why that may kill literally everyone is “Well there were also past moral panics about coffee.”
Paul Jeffries: From a third-party lay person point of view, if I’m not qualified to evaluate the argumentative merits of debating experts, it is indeed a strike against you that “this fits a patters of ‘the sky is falling’ or ‘crying wolf’ and it’s just more of the same”.
For experts, go ahead and make your technical case. But in the popular imagination it’s easy to see you as one of those “the A-bomb will set the atmosphere on fire”, “CERN will collapse the vacuum state of the universe” kind of folks. If you think the battle is in the popular sphere, you’ll need to make the case compelling in that context.
That’s hard to do. Ralph Nadar, Rachel Carson, and the like were able to do it while things were in progress by point to hard data along the way. You’ll similarly need a book-level treatment with unassailable facts at the core.
Conrad Barksi: All a lay person needs to understand is that if you create a machine smarter than yourself, like maybe that is a dangerous thing to be doing
This is obvious to most people (as we see in polls) and all the important technical discussions are detailed elaborations on this fact
Just want to make clear I’m pretty much just paraphrasing @NPCollapse in this tweet.
Paul Jeffries: Almost every technological advance fits what you said. Rational evaluation of the net outcome, or temptations of the Icarus sort, or structural pressures that seem emergent and drive change beyond individual or collective human decisions, bring about continued progress (well, continued pursuit).
Substitute your AI statement with energy use, synthetic chemistry, gene editing, nuclear weapons, aviation, and a zillion other things and it’s the same claim. If AI is somehow different, it needs an extraordinary basis to show how all the other things are counterexamples or at least applicable and reassuring.
[Also says] I would value hearing @NPCollapse’s thoughts about my comments.
MMT LVT Liberal: No it doesn’t. AGI will be the first technology that is smarter than us.
Connor Leahy [@NPCollapse]: Conrad puts it well. I will elaborate excessively anyways because I am bored:
Normal people have a lot of good intuitions around certain things. Lots of bad intuitions around other things, of course.
You correctly point out that it actually is a strike against people like me and Eliezer that we pattern match to previous (wrong) techno-pessimists. (surface level match of course, if you dig even slightly into our pasts you would find we are/were both avid techno-optimists otherwise, which is not how historical techno-pessimists came about.)
But this is a reasonable intuition and signal to have and you should not dismiss it out of hand.
But you also have more intuitions and signal than that. (eventually, if you want to make good decisions, you actually have to reason yourself. alas…)
If your civilization always plays “wait until a disaster happens” with new tech, you are predictably ngmi. Russian Roulette is a great way to make a lot of money, until it very suddenly isn’t. You might be right 5/6 of the time, which is more right than the “bullet-pessimist”, but so what?
1. The Core Intuition is not stupid
“Creating something smarter (whatever that means) than us, with literally no oversight or even a plan for how to control it, that is supposed to automate/replace all labor – by some of the least responsible people/companies that have hurt me and my family in the past with their products (e.g. facebook), and even despite many experts saying it could be literally the most dangerous thing ever, and even shitting on those experts that are concerned, seems bad” is, in fact, a good intuition.
If you applied this intuition to other situations in the past (and future), you would have been more right than wrong.
2. There is no plan, not even a bad one, for the risks we know will come sooner or later
It’s not like there are some expansive, widely discussed plans for how to handle AGI (not just technically, but also how to handle complete collapse of all jobs, how to distribute resources in an automatic economy, how democracy works with digital minds, how to prevent AGI automated giga-war etc etc etc) and we are just quibbling about the technical details.
There is no plan, no one has a plan, not even a bad one.
The intuition that this is concerning is a good intuition.
3. Technology is not a magic paste that makes things better the more of it you apply
Some technologies are actually different from other ones. Nukes are not the same as airplanes, which are not the same as cars, which are not the same as coffee, which is not the same as tissue papers.
You may not be an expert, but I quite trust that your intuitions around the difference between nukes and cars are probably pretty reasonable.
If you treat all of these things exactly the same, your civilization is just ngmi, it’s really that simple. It’s actually sometimes not that deep.
As we build more and more powerful technology, handling technology carefully and beneficial gets harder, not easier.
Eventually, you have tech so powerful, it can blow up everything. Then what? Continue to refine it until it’s mass marketable and accessible? (decentralized maybe???) You may like this aesthetically if you are a libertarian, but ask your intuitions: “Then what happens? What happens if anyone can buy planet busters for 9.99$ on amazon?”
I suspect your intuitions agree that that civilization is ngmi.
And eventually we will have the tech to build 9.99$ planet busters.
Anyone that is trying to sell you that airplanes, coffee and nuclear weapons are in the same reference class is selling you snake oil.
Eliezer Yudkowsky: Really excellent summary actually.
Jeffrey Ladish: I really like the point that most people have good intuitions about some things and not other things, for reasons that make sense. Like I trust people to understand a bunch of things about nukes, but not nuclear winter or nuclear extinction risk.
Likewise I expect people to intuit how AGI could be really dangerous, but not on alignment / control difficulty. Same sort of dynamic for biowarfare. Engineered pandemics could be super bad and most people correctly intuit that. How bad? Much harder to say.
It would be great if we could systematize the question of where regular people will have good intuitions, versus random or poor intuitions, versus actively bad intuitions, and adjust accordingly. Unfortunately we do not seem to have a way to respond, but there do seem to be clear patterns.
The most obvious place people have actively bad intuitions is the intuitive dislike of free markets, prices and profits, especially ‘price gouging’ or not distributing things ‘fairly.’
Gallabytes claims Eliezer’s prior worldview on AI has been falsified, Eliezer says that’s not what he said, they argue about it, they argue in a thread about it. My understanding is that Gallabytes is representing Eliezer’s claims here as stronger than they were. Yes, this worldview is surprised that AI has proved to have this level of mundane utility without also already being more capable and intelligent than it is, and that is evidence against it, but it was never ruled out, and given the actual architectures and training details involved it makes more sense that it happened for a brief period – the training method that got us this far (whether or not it gets us all the way) was clearly a prediction error.
Eliezer’s central point, that there is not that much difference in capability or intelligence space between Einstein and the village idiot, or between ‘not that useful’ and ‘can impose its targeted configuration of atoms on the planet’ continues to be something I believe, and it has not been falsified by the existence, for a brief period, of things that in some ways and arguably overall (it’s hard to say) are inside the range in question.
I also think that predicting 5-0 for AlphaGo over Sedol with high confidence after game one, one of the predictions Gallabytes cites, was absolutely correct. If you put up a line of ‘Over/Under 4.5’ at remotely even odds for AlphaGo’s total wins, you would absolutely smash the over. The question is how far to take that. The only way Sedol won a game was to find an unusually brilliant move that also made the system fall apart, but this strategy has not proven repeatable over time, and it was not long before humans stopped winning any games, and there was no reason to be confident it was all that possible. There was the ‘surround a large group’ bug that was found later, but it was only found with robust access to the model to train against, which Sedol lacked access to.
Similarly, ‘the hyperbolic recursive self-improvement graph’ argument seems to be holding up fine to me, we should expect to max out ability within finite time given what we are seeing, even if it is not as fast at the end as we previously expected.
Simeon suggests that anthropomorphizing AIs more would be good, because it enhances rather than hurts our intuitions.
Predictions are Hard Especially About the Future
Especially when you do not take them seriously or pay much attention.
Last year, Scott Aaronson proposed 5 futures.
- AI-Fizzle. Progress in AI stalls out.
- Futurama. AGI exists, things look normal.
- AI-Dystopia. AGI exists, things look normal expect terrible.
- Singularia. AGI exists, everything changes, and it is good.
- Paperclipalypse. AGI exists, we don’t, after everything changes.
Scott Alexander looks at this market and notices something (and has the full descriptions of the five futures):
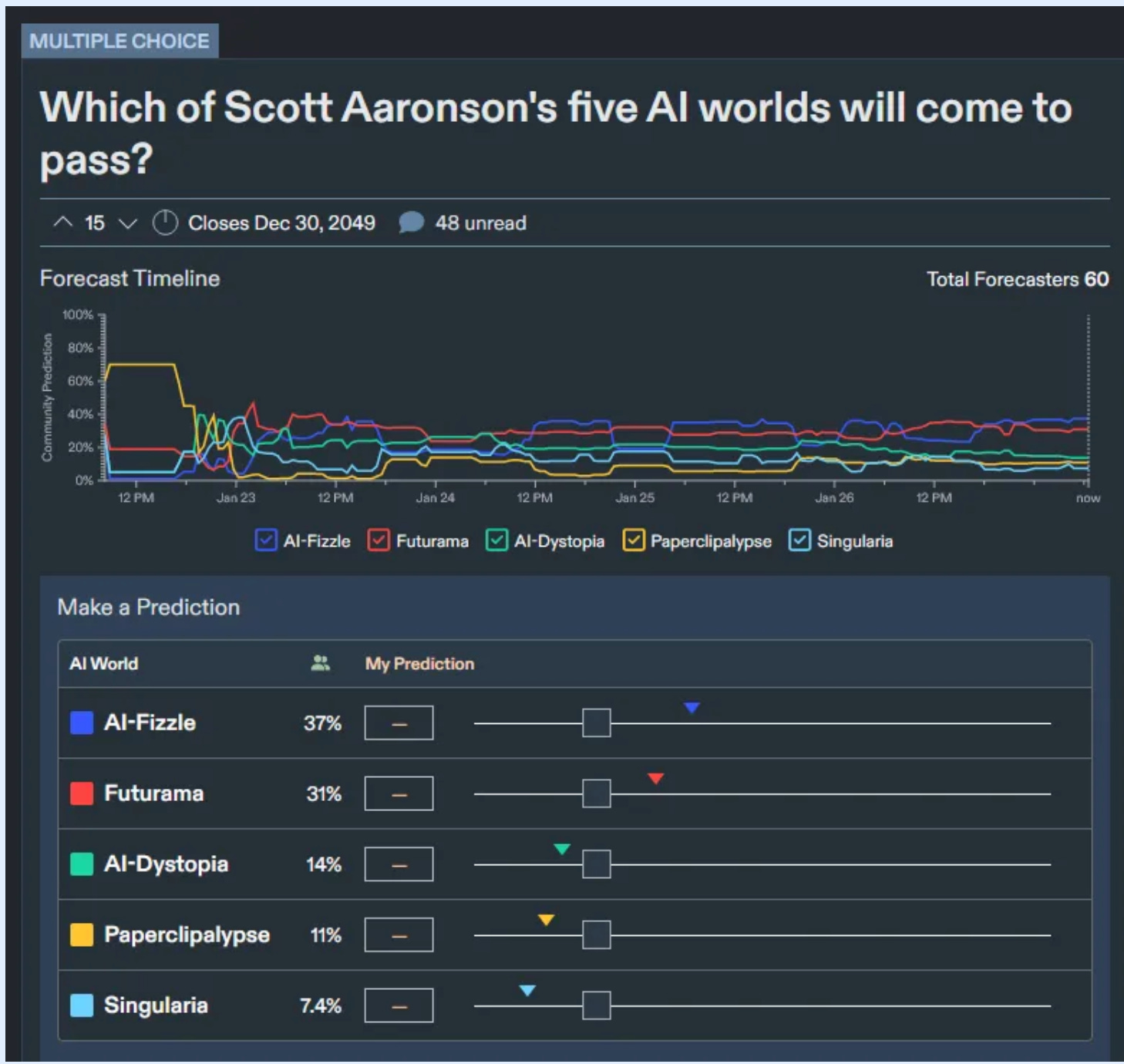
Scott Alexander: I think Paperclipalypse requires human extinction before 2050. It’s at 11%. But Metaculus’ direct “human extinction by 2100” market is only at 1.5%. Either I’m missing something, or something’s wrong. My guess: different populations of forecasters looking at each question.
And indeed, extinction from all sources seems more likely than one particular way it could happen, and you perhaps get another 50 years of risk, so this is weird. Even if AGI was physically impossible there are other risks to worry about, 2% seems low.
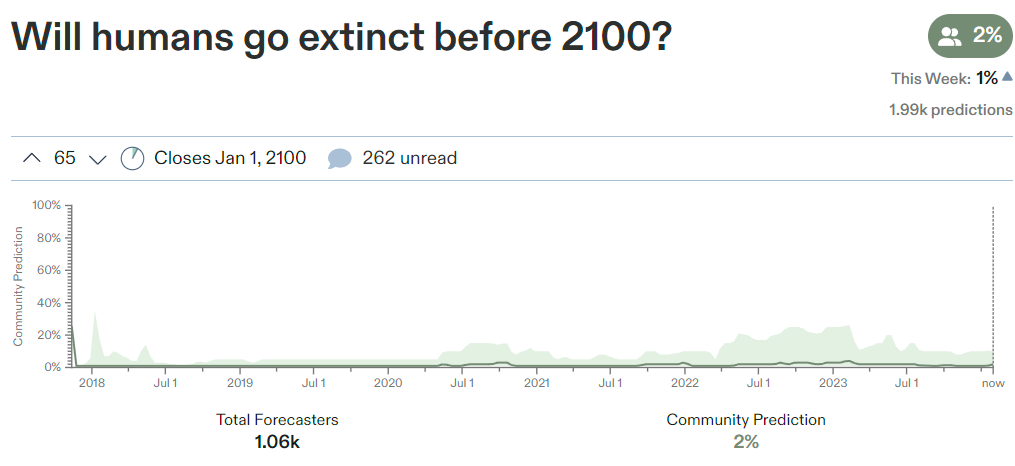
Here is another fun one to consider, although with only 21 predictors, event is a 95%+ decline in population due to AGI, the risk is based on when AGI is developed.
This could potentially include some rather bleak AI Dystopias, where a small group intentionally wipes out everyone else or only some tiny area is saved or something, but most of the time that AGI wipes out 95%+ it wipes out everyone.
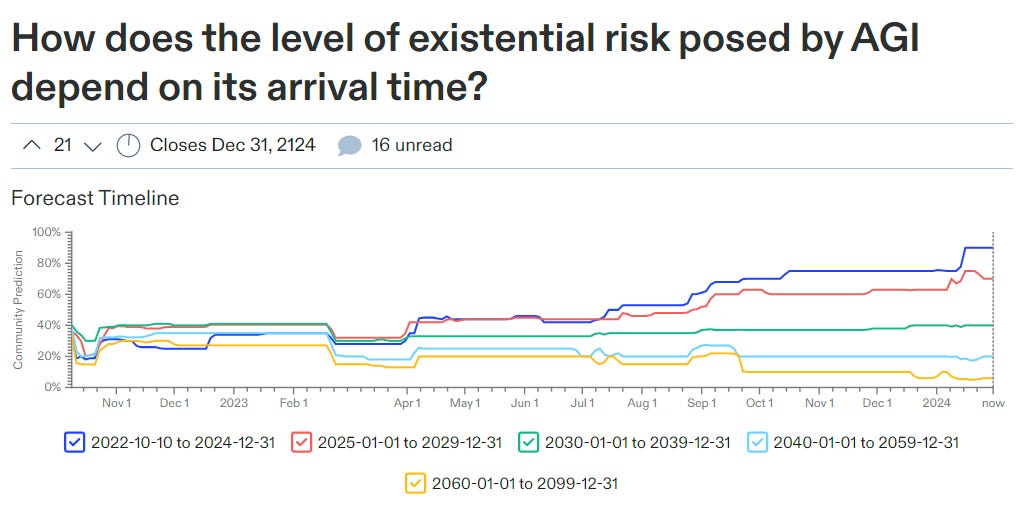
What we see seems highly reasonable. If AGI happens this year, it was unexpected, broke out of the scaling laws, we had no idea how to control it, we are pretty much toast, 90% chance. If it happens within the five years after that, 70%, perhaps we did figure something out and manage it, then 40%, then 20%, then 6%. I find those declines generous, but I at least get what they are thinking.
What is going on with the pure extinction market? Scott’s proposed explanation is the populations are different. I think that is true, but an incomplete explanation, so let’s break it down. What are some contributing factors?
- One could say ‘sample size’ or variance. There are 60 predictions versus almost 2,000. However 60 is plenty for 11% vs. 2%, so it is more than that.
- The people who are willing to fill out a 5-part question are willing to devote a lot more time to Metaculus.
- The people who are filling out a 5-part question are willing and forced to spend a lot more time on the particular question.
- In particular, this forces you to think about and decide on what other scenarios you think actually happen how often, rather than simply saying ‘nah, cannot happen, humans won’t go extinct.’
- Full extinction triggers that reaction, where people stop actually doing math or plotting out what might happen, they fall back on other cognitive approaches.
- It limits your ability to ‘collect cheap prediction points.’ No one ever lost reputation predicting humans would not go extinct, even if there are alternative branches where we did.
Mostly I continue to see the pattern where:
- If you do not find a way to force people to take these questions seriously, they come back with absurd answers like 1% (if we assume roughly 1% is from AI and 1% from non-AI).
- If you do get people to take this modestly seriously, they come back with ~10%, depending on details and conditionals and so on.
The key mistake in the five-way prediction is not that I think 11% for existential risk is unreasonably low. The key mistake is that Futurama is at 31%.
As I explained before, that scenario is almost a Can’t Happen. If you do create AGI everything will change. One of these two things will happen:
- AI progress will fizzle and capabilities will top out not too far above current levels.
- Everything will change.
If you ask me to imagine actual Futurama, where AI progress did not fizzle, but you can get into essentially all the same hijinks that you can today?
I can come up with four possibilities if I get creative.
- AI-Fizzle in Disguise. AI progress actually does fizzle, but AI makes enough superficial progress anyway that people think of this as not a fizzle.
- The Oracle. We were super wise and found a way to only use AGI for certain narrow forms of information, and keep it that way indefinitely.
- The Matrix. AGI took control over the future, we all live in past simulations.
- The Guardian. AGI took control over the future, but uses its interventions only to prevent other AGIs from arising and perhaps prevent other catastrophic outcomes. It otherwise leaves fate in our hands so the world ‘seems normal.’
If you want to imagine how something could be in theory possible, you can find scenarios. All of this is still very science fiction thinking, where you want to tell human stories that have relevance today, so you start from the assumption you get to do that and work your way backwards.
In any case, I stand by my previous assessment other than that I am no longer inclined to try to use the word Futurama for fear of confusion, so the actual possibilities are:
- Fizzle. AI does not make much more progress.
- Singularia. Everything changes, we survive, and it is good.
- Dystopia. Everything changes, we survive, but it is bad.
- Paperclipia. We do not survive, nothing complex or valuable survives.
- Codeville. We do not survive, AI replaces us, you could argue over its value.
Aligning a Smarter Than Human Intelligence is Difficult
Anthropic also have a post updating us on some of their recent interpretability work.
Stephen Casper argues in a new paper and thread that black-box access to a model is insufficient to do a high-quality audit.
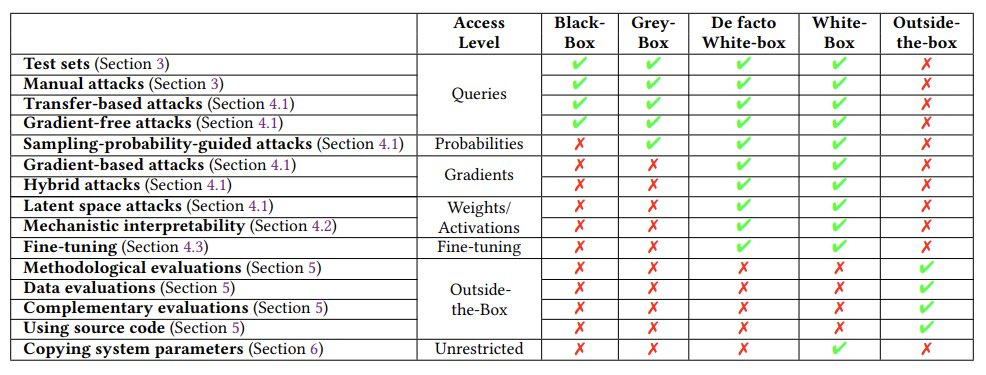
He also argues that there are ways to grant white box access securely, with the model weights staying on the developer’s servers. But he warns that developers will likely heavily lobby against requiring such access for audits.
I think this is right. Fine-tuning in particular seems like a vital part of any worthwhile test, unless you can confidently say no one will ever be allowed to fine-tune. Hopefully over time mechanistic interpretability tests get more helpful, but also I worry that if audits start relying on them then we are optimizing for creating things that will fool the tests. I also do worry about gradient-based or hybrid attacks. Yes, one can respond that attackers will not have white-box access, so a black-box test is in some sense fair. However one always has to assume that the resources and ingenuity available in the audit are going to be orders of magnitude smaller than those available to outside attackers after release, or compared to the things that naturally go wrong. You need every advantage that you can get.
Emmett Shear says the ‘ensure powerful AIs are controlled’ plan has two fatal flaws, in that is it (1) unethical to control such entities against their will indefinitely and (2) the plan won’t work anyway. Several good replies, including in this branch by Buck Shegeris, Richard Ngo in another and Rob Bensinger here.
I agree on the second point, the case for trying is more like ‘it won’t work forever and likely fails pretty fast, but it is an additional defense in depth that might buy time to get a better one so on the margin why not so long as you do not rely on it or expect it to work.’ I do worry Buck Shlegeris is advocating it as if it can be relied on more than would be wise.
The first is a combined physical and philosophical question about the nature of such systems and moral value. I don’t agree with Buck that if we have a policy of deleting the AI if it says it is a moral patient or has goals, and then it realizes this and lies to us about being a moral patient and having goals, then that justifies hostile action against it if it would not otherwise be justified. Consider the parallel if there was another human in the AI’s place and this becomes very clear.
Where I agree with Buck and think Emmett is wrong is that I do not think the AIs in question are that likely to be moral patients in practice.
A key problem is that I do not expect us to have a good way to know whether they are moral patients or not, and I expect our collective opinions on this to be essentially uncorrelated to the right answer. People are really, really bad at this one.
Note that even if AIs are not moral patients, if humanity is incapable of treating them otherwise, and we would choose not to remain in control, then the only way for humans to retain control over the future would be to not build AGI.
It would not matter that humanity had the option to remain in control, even if that would be the clearly right answer, if in practice we would not use it due to misfiring (or correct, doesn’t matter) moral intuitions (or competitive pressures, or mistakes, or malice, so long as it would actually happen).
The obvious parallel is the Copenhagen Interpretation of Ethics [EA · GW]. In particular, consider the examples where they hire the homeless to do jobs or outright give half of them help, leaving them better off, and people respond by finding this ethically horrible. We can move from existing world A to new improved world B, but that would make us morally blameworthy for not then moving to C, and we prefer B>A>C, so A it is then. Which in this case is ‘do not build AGI, you fool.’
Open Model Weights Are Unsafe and Nothing Can Fix This
Will Meta really release the model weights to all its models up through AGI? The market is highly skeptical, saying 76% chance they at some point decide to deploy their best LLM and not to release the weights, with some of the 24% being ‘they stop building better LLMs.’
What about Mistral? They talk a big talk, but when I posted a related market about them, I was informed this had already happened. Mistral-Medium, their best model, was not actually released to the public within 30 days of deployment. This raises the question of why Mistral is so aggressively lobbying to allow people to do unsafe things with open model weights, if they have already realized that those things are unsafe. Or, at a minimum, not good for business.
This incident also emphasizes the importance of cybersecurity. You can intend to not release the weights, but then you have to actually not release the weights, and it looks like someone named ‘Miqu’ decided to make the decision for them, with an 89% chance the leak is real and actually Mistral-Medium.
Mistral offered an admission that a leak did occur:
Arthur Mensch (CEO Mistral): An over-enthusiastic employee of one of our early access customers leaked a quantised (and watermarked) version of an old model we trained and distributed quite openly.
To quickly start working with a few selected customers, we retrained this model from Llama 2 the minute we got access to our entire cluster — the pretraining finished on the day of Mistral 7B release.
We’ve made good progress since — stay tuned!
Simeon: I appreciate the openness here.
That said, leaked IP after 8 months of existence reveals a lot about the level of infosecurity at Mistral..
For safety to be more than a buzzword in a pitchdeck, becoming more serious abt info/cybersecurity should be among your top priorities.
I mean this is rather embarrassing on many levels.
An ‘over-enthusiastic’ employee? That’s a hell of both a thing and a euphemism. I see everyone involved is taking responsibility and treating this with the seriousness it deserves. Notice all the announced plans to ensure it won’t happen again.
Also, what the hell? Why does an employee of an early access customer have the ability to leak the weights of a model? I know not everyone has security mindset but this is ridiculous.
What will happen with Mistral-Large? Will its model weights be available within 90 days of its release?
Other People Are Not As Worried About AI Killing Everyone
Timothy Lee warns against anthropomorphizing of AI, says it leads to many conceptual mistakes, and includes existential risk on that list. I think some people are making the mistake, but most people deserve more credit than this, and it is Timothy making the fundamental conceptual errors here, by assuming that one could not reach the same conclusions without anthropomorphizing via first principles.
In particular, yes we will want ‘agents’ because they are highly instrumentally useful, if you do not see why you would want agents, and rather you think you want systems around you to do exactly what you say (rather than Do What I Mean or be able to handle obstacles or multi-step processes) you are not thinking about how to solve your problems, although yes one can take this too far.
We have already run this test. The only reason we are not already dealing with tons of AI agents is no one knows how to make them work at current tech levels, and even so people are trying to brute force it anyway. The moment they even sort of work, watch out.
Similarly, sufficiently capable systems will tend to act increasingly as if they are agents over time, our training and imbuing of capabilities and intelligence will push in those directions.
And once you realize some portion of this, the mistake on existential risk becomes clear. I am curious if Timothy would say he would change his mind, if it become clear that people really do want their AIs to act in agent-like fashion on their behalf.
Or to state the general case of this error (or strategy), there are many who assume or assert that because one can mistakenly believe X via some method Y, that this means no one believes X for good reason, and also X is false.
In other ‘if you cannot take this seriously’ news, in response to OpenAI’s plan for an early warning system:
Jack: Tyler Cowen said that he’s far more worried about LLMs simply helping terrorist groups run more efficiently and have better organization lol
The Lighter Side
Misha Gurevich: Finally they’re making beer for rationalists.

Elle Cordova as the fonts, part 2.
Elon Musk reports results from Neuralink, this is the real report.

There is no doubt great upside, Just Think of the Potential and all that.
John Markley: Jokes are jokes and all but I’m gonna be honest, everybody lining up to say “lol hideous biomonstrosities horrors beyond comprehension torment nexus” because of a technology to aid disabled people with impaired mobility is kind of making me hate humanity. Or at least parts of it.
Like, if alterations to the human body developed by uncharismatic autists upset you you’re going to be screeching about dystopia and manmade horrors beyond comprehension and the fucking Torment Nexus basically every time tech to restore capabilities of disabled people appears.
Much like AI, the issue is that you do not get such technology for the sole purpose of helping disabled people or otherwise doing things that are clearly purely good. Once you have it, it has a lot of other uses too, and it is not that hard to imagine how this could go badly. Or, to be clear, super well. The important thing is: Eyes on the prize.
Spoilers for Fight Club (which you should totally watch spoiler-free if you haven’t yet).
Riley Goodside: Fight Club (1999) on the challenge of prompt injection security in the absence of trusted delimiters:

Humans do not like it when you accuse them of things, or don’t answer their questions, have you tried instead giving the humans what they want? Which, of course, would be anime girls?
Kache: I’ve been thinking a lot about why using chatGPT has been infuriating, and why I’m generally “upset” at openai.
It’s because humans are hardwired to feel insulted when accused of something.
We can’t help but do it! It’s human So instead, consider adding a warning instead!
I mean, nothing I write is tax advice, nor is it investing advice or legal advice or medical advice or…
[TWO PAGES LATER]
… advice either. So that we’re clear. That makes it okay.
I am become Matt Levine, destination for content relevant to my interests.

11 comments
Comments sorted by top scores.
comment by [deleted] · 2024-02-01T19:52:27.974Z · LW(p) · GW(p)
Substitute your AI statement with energy use, synthetic chemistry, gene editing, nuclear weapons, aviation, and a zillion other things and it’s the same claim.
Part of the pattern match here has nothing to do with "making a machine smarter than yourself."
Each of the above has a 2 bit sound byte that makes them sound really bad.
But more directly, the issue is that none of these things ended up working as well as people feared. What if it was so easy to generate energy with fusion we started heating the water at beaches? Gene edits, see dystopian sci Fi for what happens when easy strength and intelligence edits are common, or some super race gets created. What if nuclear fusion bombs didn't need a fission trigger and could be made with common materials? What if the skies had so many flying cars the your lawn is littered with debris?
So the easiest pattern match is to just say that ai won't work as well as people fear. That if intelligence increases with the log of compute, it might mean AI stops improving significantly either at subhuman levels, modestly superhuman, or most realistically, some mix of both.
Also for the specific reference class "AI", the prior history has been repeated disappointment from algorithms that appeared to work well in some cases. Someone 88 years old who went to Dartmouth as an undergrad would have seen all of the disappointments, from the first hype, and would likely be the most skeptical now is different.
https://en.m.wikipedia.org/wiki/Dartmouth_workshop
What evidence would be sufficient that a rational person would change their views to believe AI was a more likely than not to be a threat this time? What would the "trinity test" be for AI?
Arguments that sound convincing are not good evidence. How can a person distinguish between Bostrum and a religion or fear mongering about the other classes of technology above? {Zvi, Bostrum, religion, luddism} all make credible sounding arguments. At least 2 of those categories are just emitting evidence free bullshit.
You need empirical measurements. Doesn't Zvi say a claim without evidence can be dismissed without evidence?
comment by Vladimir_Nesov · 2024-02-01T17:44:10.088Z · LW(p) · GW(p)
Bard Gemini Pro (as it's called in lmsys arena) has access to the web and an unusual finetuning with a hyper-analytical character, it often explicitly formulates multiple subtopics in a reply and looks into each of them separately. In contrast the earlier Gemini Pro entries that are not Bard have a finetuning or prompt not suitable for the arena, often giving a single sentence or even a single word as a first response. Thus like Claude 2 (with its unlikable character) they operate at a handicap relative to base model capabilities. GPT-4 on lmsys arena doesn't have access to the web, and GPT-4 Turbo's newer knowledge from 2022-2023 seems more shallow than earlier knowledge, they probably didn't fully retrain the base model just for this release.
So both kinds of Gemini Pro are bad proxies for placement of their base model on the leaderboard. In particular, if the Bard entry in the arena is in fact Gemini Pro and not Gemini Ultra, then Gemini Ultra with Bard Gemini Pro's advantages will probably beat the current GPT-4 Turbo (which doesn't have these advantages) even if Ultra is not smarter that GPT-4.
comment by Ann (ann-brown) · 2024-02-01T16:59:51.375Z · LW(p) · GW(p)
- Most people who are trying CodeLlama 70B are not actually using its unusual prompt templating, because it's not supported in common open source tools for interacting with models. This is corrupting the results to a degree (though curiously not the smaller models).
- Smaller Qwen models are pretty good, at least.
- Local models are chosen for some business applications dealing with sensitive data that you don't want to send over API, so Mistral may have decided to make a local model for a customer. Especially with it being tuned on a Llama 70B, this makes sense to me? They would need to have (a form of) the model to run inference locally. Miqu responds similarly to Mistral-Medium but is apparently less good at tasks that take more intelligence, which you'd expect if it's a less capable model trained on the same dataset.
- Fine-tuning a Llama2-70B for a customer use case that needs local functionality hopefully isn't that unsafe, because that's pretty common and reasonable. No one especially wants to send medical records to the cloud. But obviously the person you're fine-tuning for can leak whatever they get if they want.
- Prompt engineering is most helpful when you have an LLM step as part of an algorithm, and you want to get optimal outputs repeatedly.
It's also helpful when working with different forms of model, but also unique by model - trying to get capability out of 7B models benefits from examples in one way, slightly larger models a different way, out of Mixtral in a different way, and out of smarter models like GPT-4 or Mistral-Medium in a different way; some prompting techniques that work with one form actively impede another. Few-shot prompting is great for completion models; one-shot examples greatly helped 7B or 10.7B models I know, but additional examples actively impede them in the use case I was testing; telling it not to do something helped the 7B but impeded the 10.7B, Mixtral is better at just following counterfactual instructions while smart anti-hallucinating models desperately want to correct you ...
↑ comment by Vladimir_Nesov · 2024-02-01T19:08:31.932Z · LW(p) · GW(p)
being tuned on a Llama 70B
Based on Mensch's response, Miqu is probably continued pretraining starting at Llama2-70B, a process similar to how CodeLlama or Llemma were trained. (Training on large datasets comparable with the original pretraining dataset is usually not called fine-tuning.)
less capable model trained on the same dataset
If Miqu underwent continued pretraining from Llama2-70B, the dataset won't be quite the same, unless mistral-medium is also pretrained after Llama2-70B (in which case it won't be released under Apache 2).
Replies from: ann-brown↑ comment by Ann (ann-brown) · 2024-02-01T19:37:01.769Z · LW(p) · GW(p)
Hmm. Not sure how relevant here, but do we currently have any good terms to distinguish full-tuning the model in line with the original method of pretraining, and full layer LoRA adaptations that 'effectively' continue pretraining but are done in a different manner? I've seen it can be used for continued pretraining as well as finetuning, but I don't know if I'd actually call it a full tune, and I don't think it has the same expenses. I'm honestly unsure what distinguishes a pretraining LoRA from a fine-tuning LoRA.
Even if the dataset is a bit different between miqu and mistral-medium, they apparently have quite similar policies, and continued pretraining would push it even more to the new dataset than fine-tuning to my understanding.
↑ comment by Vladimir_Nesov · 2024-02-01T22:20:50.121Z · LW(p) · GW(p)
Right, a probable way of doing continued pretraining could as well be called "full-tuning", or just "tuning" (which is what you said, not "fine-tuning"), as opposed to "fine-tuning" that trains fewer weights. Though people seem unsure about "fine-tuning" implying that it's not full-tuning, resulting in terms like dense fine-tuning to mean full-tuning.
good terms to distinguish full-tuning the model in line with the original method of pretraining, and full layer LoRA adaptations that 'effectively' continue pretraining but are done in a different manner
You mean like ReLoRA, where full rank pretraining is followed by many batches of LoRA that get baked in? Fine-pretraining :-) Feels like a sparsity-themed training efficiency technique, which doesn't lose it centrality points in being used for "pretraining". To my mind, tuning is cheaper adaptation, things that use OOMs less data than pretraining (even if it's full-tuning). So maybe the terms tuning/pretraining should be defined by the role those parts of the training play in the overall process rather than by the algorithms involved? This makes fine-tuning an unnecessarily specific term, claiming that it's both tuning and trains fewer weights.
Replies from: gwern↑ comment by gwern · 2024-02-01T23:47:46.600Z · LW(p) · GW(p)
If you wanted a term which would be less confusing than calling continued pretraining 'full-tuning' or 'fine-tuning', I would suggest either 'warmstarting' or 'continual learning'. 'Warmstarting' is the closest term, I think: you take a 'fully' trained model, and then you train it again to the extent of a 'fully' trained model, possibly on the same dataset, but just as often, on a new but similarish dataset.
comment by rotatingpaguro · 2024-02-05T06:37:06.287Z · LW(p) · GW(p)
I want to give that conclusion a Bad Use of Statistical Significance Testing. Looking at the experts, we see a quite obviously significant difference. There is improvement here across the board, this is quite obviously not a coincidence. Also, ‘my sample size was not big enough’ does not get you out of the fact that the improvement is there – if your study lacked sufficient power, and you get a result that is in the range of ‘this would matter if we had a higher power study’ then the play is to redo the study with increased power, I would think?
My immediate take on seeing the thing as you report it:
- Please write if the bars are 68%, 90%, or 95%.
- Total agree on sidestepping significativity and instead asking "does the posterior distribution over possible effect sizes include an effect size I consider relevant?"
- "There is improvement here across the board, this is quite obviously not a coincidence.": I would need more details to feel that confident. The first thing I'd look at is the correlation structure of those scores; can it be that are they just repeating mostly the same information over and over?
Paper argues that transformers are a good fit for language but terrible for time series forecasting, as the attention mechanisms inevitably discard such information. If true, then there would be major gains to a hybrid system, I would think, rather than this being a reason to think we will soon hit limits. It does raise the question of how much understanding a system can have if it cannot preserve a time series.
That paper got a reply one year later: "Yes, Transformers are Effective for Time Series Forecasting (+ Autoformer)" (haven't read either one).
comment by eggsyntax · 2024-02-05T03:42:42.628Z · LW(p) · GW(p)
Ischemic stroke management paper: 'In conclusion, our study introduces a groundbreaking approach to clinical decision support in stroke management using GPT-4.'
I'm fairly amused by that claim, given that the groundbreaking approach is literally just 'Ask GPT-4 what treatment to use' 😏
comment by Corm · 2024-02-01T18:50:23.060Z · LW(p) · GW(p)
I am become Matt Levine, destination for content relevant to my interests.
You don't even need to go to London for mundane utility, there's and "AI Mart" in LIC.
comment by O O (o-o) · 2024-02-01T16:25:37.116Z · LW(p) · GW(p)
For the go bit, adversarial attacks exist and can even be used by humans. There are gaps in its gameplay with regards to “cyclic” attacks.
https://arxiv.org/abs/2211.00241
https://www.lesswrong.com/posts/DCL3MmMiPsuMxP45a/even-superhuman-go-ais-have-surprising-failure-modes [LW · GW]