A Framework to Explain Bayesian Models
post by Jsevillamol · 2021-12-06T10:38:25.815Z · LW · GW · 1 commentsContents
Previous work Introducing my framework Applying sociology to explaining Bayesian Networks Solving the problem of argument aggregation A superficial overview of the framework Approximating message passing with arguments Library and technical report Conclusion Acknowledgements Bibliography None 1 comment
Bayesian Networks are used to represent uncertainty and probabilistic relations between variables. They have an appealing graphical representation and a clear statistical meaning, which makes them a popular approach to manage uncertainty.
I have developed a new mathematical framework, inspired in message passing, to perform content selection and produce explanations of the reasoning in BNs.
In this article I will explain what it is possible to do with the framework, obviating the technical details of how it works. Those are available in the technical report Finding, Scoring and Explaining Arguments in Bayesian Networks.
An open source implementation of the framework is available in GitLab.
Previous work
After reviewing past work in Bayesian Networks, I concluded that current frameworks were inadequate to solve some key issues in explaining Bayesian Networks.
General explainability approaches like LIME (Ribeiro et al, 2016) and SHAP (Lundberg and Lee, 2017) already do a good job of helping us choose and explain the effect of the evidence that matters most for an explanation. But they cannot help us explain the intricate ways in which information propagates inside a Bayesian Network. So a solution particular to Bayesian Networks was desired.
Some existing frameworks addressed how to select the most important paths in a graphical model that linked the evidence to the nodes of interest. For example, (Suerdmont, 1992) described a method to extract such arguments in their INSITE system. The method was later refined in eg (Haddawy et al, 1997) and (Kyrimi et al, 2020).
And other work focused on relating Bayesian Networks to argument theory, superficially studying the interactions between arguments. (Vreeswijk, 2005), (Keppens, 2012) and (Timmer et al, 2017) are examples of this line of work.
But no previous work that I know of addressed both problems simultaneously. I propose a framework for selecting the most important ways the evidence relates to nodes of interest in a Bayesian Network, while being mindful of interactions in the network.
Introducing my framework
The best introduction to my work is an example. Consider the ASIA network depicted below:

Suppose we learn that the patient’s xray showed an abnormality (xray = yes), that the patient has bronchitis (bronc = yes) and that the patient does not have tuberculosis (tub = no). And we want to learn whether the patient has lung cancer.
We can feed this input into the package I developed, and we will get as output two relevant arguments that relate the evidence to the target:
We have observed that the lung xray shows an abnormality and the patient does not have tuberculosis.
We have observed that the patient has bronchitis. |
Each of these arguments has associated a quantitative strength, that we can use to prioritize which arguments to show to the user. And in fact, the arguments that the system outputs are by default ordered by their importance.
The framework already performs argument aggregation where it is appropriate. For example, in the first argument from the example it detected the interaction between the x-ray result and the tuberculosis, and decided to present both observations together in the same argument.
Applying sociology to explaining Bayesian Networks
I follow (Miller, 2017) to guide some of the choices in my explainability framework. Miller highlights four aspects of explanations uncovered by sociology:
- Explanations are contrastive. They contrast actual facts to counterfactuals.
- Explanations are selective. They focus on the most salient causes of events.
- Explanations are qualitative. Explicit use of probabilities is rare.
- Explanations are interactive. They are embedded in a context, like a conversation.
I apply some of those learnings to my framework to make the explanations more human.
In particular I emphasize the importance of content selection to help engineers choose the most important arguments to present to the user. Each argument has associated a strength - a number that represents the relevance of the argument.
I also offer qualitative arguments before probabilities. The description of the strength of each inferential step, and of each argument, is described using words like “certain”, “strong” or “weak”.
To address different user needs I offer several modes of explanation to adapt to user needs, including a contrastive mode. In particular, each argument presents three modes of explanation: a direct one, a contrastive one and a condensed one.
Example of a direct explanation:
We have observed that the patient does not have tuberculosis and the lung xray shows an abnormality. That the lung xray shows an abnormality is evidence that the patient has a lung disease (strong inference). That the patient does not have tuberculosis and the patient has a lung disease is evidence that the patient has lung cancer (strong inference). |
Example of a contrastive explanation:
We have observed that the patient does not have tuberculosis and the lung xray shows an abnormality. That the lung xray shows an abnormality is evidence that the patient has a lung disease (strong inference). Usually, if the patient has a lung disease then the patient has lung cancer. Since the patient does not have tuberculosis, we can be more certain than this is the case (strong inference). |
Example of a condensed explanation:
| Since the patient does not have tuberculosis and the lung xray shows an abnormality, we infer that the patient has lung cancer (strong inference). |
While I have not directly addressed interactivity in the framework, it’s modular nature will make it easy to implement interactive approaches on top. For example, engineers can show the users the condensed explanations of the arguments at first and only show the more detailed explanations upon request for clarification from the users.
Solving the problem of argument aggregation
The framework allows us to solve questions that could not be addressed by previous work.
For example, consider a network such as the one depicted below:
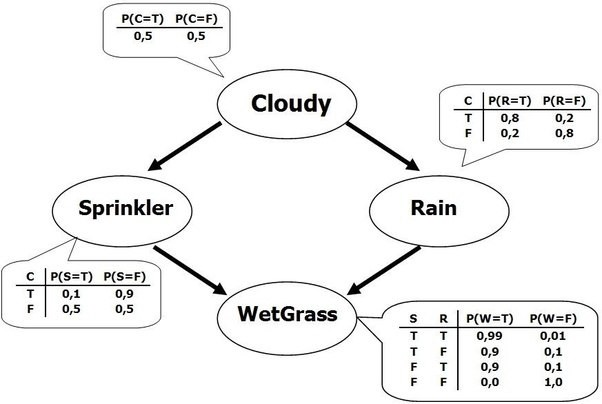
Suppose we learn that it is cloudy (Cloudy = T). And we want to learn how this affects the probability that the grass is wet (WetGrass = T).
There are three arguments we can bring forward in this situation:
Composite argument:
| Because it is cloudy the sprinkler will be off. On the other hand, because it is cloudy it is raining. And since the sprinkler will be off and it will be raining we deduce that the grass will be wet. |
Subargument 1:
| Because it is cloudy the sprinkler will be off. And since the sprinkler will be off the grass will not be wet. |
Subargument 2:
| Because it is cloudy it is raining. And rain causes the grass to be wet. |
There are two explainability questions we need to address.
- Should we present to the user the composite argument or the two subarguments?
- Which argument matters most between subargument 1 and subargument 2?
In this example it seems like the two mechanisms are separate, and thus the subargument explanations are more appropriate. But we could imagine situations in which there is an interaction between the target and the two intermediate nodes, and a composite explanation would be necessary. For example, the composite explanation would be needed if the grass was super absorbent and we needed both the sprinkler to be on and for it to be raining to get it wet.
My framework offers precise, quantitative answers to both questions.
This is in contrast with previous work. LIME and SHaP can be used to determine the overall importance of the observation Cloudy = T, but have nothing to say on both questions. Work on chains of reasoning like INSITE can address question 2 but not question 1. Previous argumentation theory approaches (notably (Keppens, 2012)) discuss question 1 but their solution is not complete.
A superficial overview of the framework
In essence, arguments in my framework are subgraphs in the Bayesian Network.
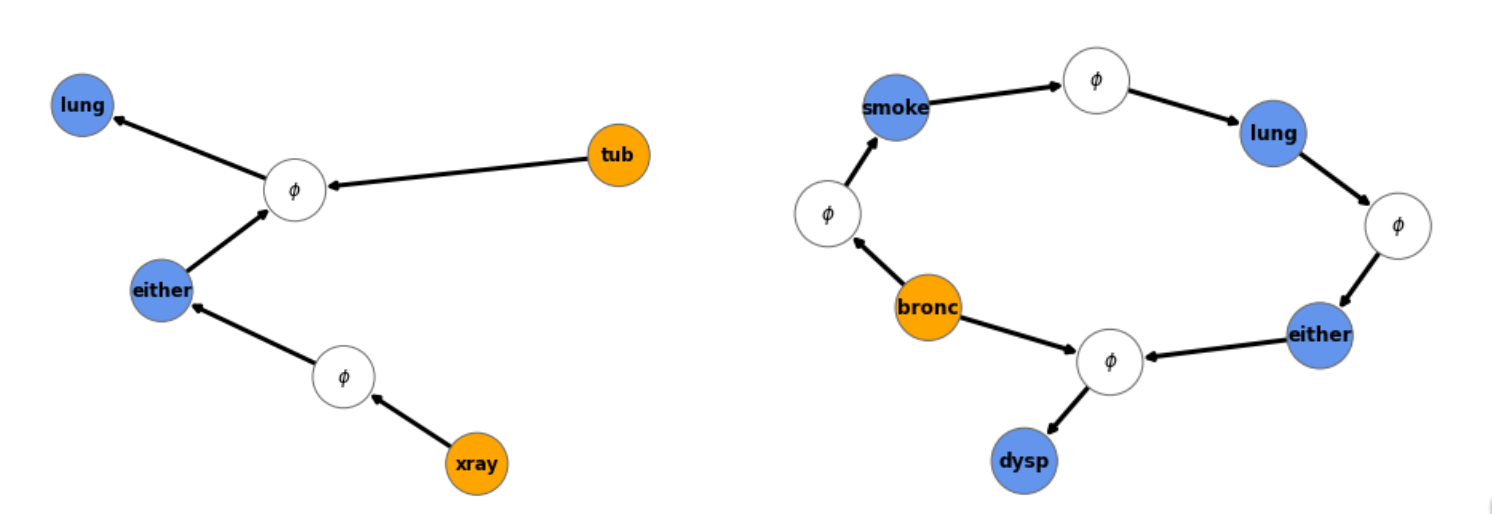
For each argument I defined a notion of the evidence provided by that argument on each of its participating nodes. This definition is similar to the equations of message passing, a popular algorithm for inference in Bayesian Networks.
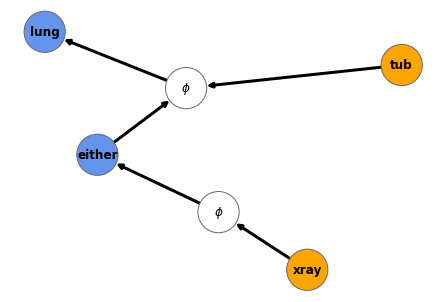 |  |  |
 |  |
An argument in the ASIA network (left) and its effects (right). We can see that this argument is strong evidence in favour of the outcome lung = yes.
I build on this notion of effects of an argument to define a notion of argument independence.

I proceed to define algorithms to identify sets of approximately independent arguments given a network, evidence and a target node, as well as a scheme to explain the arguments in natural language.
An in-depth explanation of the framework and the concepts above is available in the technical report Finding, Scoring and Explaining Arguments in Bayesian Networks.
Approximating message passing with arguments
(Rudin, 2018) convincingly argues against explainability approaches and in favour of interpretability - explanations can be persuasive but misleading.
The system I developed can be used as an interpretable method to approximate conditional queries to a Bayesian Network of the form P(Target | Evidence).
To perform this approximation, I essentially multiply the baseline probability distribution P(Target) by the effects of all the arguments found.

Probabilities approximated by my framework versus probabilities estimated by message passing for n=200 random queries of the form in the Asia network
The accuracy of this approximation is not good, but it is better than a baseline where we approximate P(Target | Evidence) as P(Target). This leads me to believe that even if the approximation is not accurate it probably is qualitatively right.
This increases my trust in the content selection performed by my framework.
Library and technical report
The principal artifact produced by my research is an open source Python package in GitLab, called ExplainBN.
It is built on top of PGMPy, an open source program to build and perform inference in probabilistic graphical models (Ankan and Panda, 2015).

The accompanying technical report describes in depth the mathematical definition of arguments and their effects, and the algorithms for content selection and explanation.
Conclusion
The explainability approach I developed produces a list of arguments relating evidence to other nodes in a Bayesian Network. These arguments can be scored according to their relevance and explained using natural language in multiple ways.
To make my work available, I released an open source implementation of my framework in GitLab. I hope others will be able to work on top of my contribution to develop explainable Bayesian systems for making critical decisions.
You can read more about this line of work in Finding, Scoring and Explaining Arguments in Bayesian Networks.
I do not think my work is the final on explaining Bayesian Networks and I think it is likely that I made mistakes along the way.
Future work includes user testing and improving the quality of the realized explanations.
I have already started on this, and I am currently surveying experts in Bayesian Networks about their preferred ways of explaining the outcome of Bayesian Networks. I hope this will give me ideas to improve the quality of the explanations.
Acknowledgements
This work has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No 860621.
I thank Tjitze Rienstra, Ehud Reiter, Oren Nir, Nava Tintarev, Pablo Villalobos, Michele Cafagna, Ettore Mariotti, Sumit Srivastava, Luca Nanini, Alberto Bugarín and Ingrid Zuckerman for feedback, discussion and support.
Bibliography
Ankan, Ankur, and Abinash Panda. 2015. ‘Pgmpy: Probabilistic Graphical Models Using Python’. In Proceedings of the 14th Python in Science Conference (SCIPY 2015). Citeseer.
Beinlich, Ingo A., H. J. Suermondt, R. Martin Chavez, and Gregory F. Cooper. 1989. ‘The ALARM Monitoring System: A Case Study with Two Probabilistic Inference Techniques for Belief Networks’. In AIME 89, edited by Jim Hunter, John Cookson, and Jeremy Wyatt, 247–56. Lecture Notes in Medical Informatics. Berlin, Heidelberg: Springer. https://doi.org/10.1007/978-3-642-93437-7_28.
Haddawy, Peter, Joel Jacobson, and Charles E Kahn. 1997. ‘BANTER: A Bayesian Network Tutoring Shell’. Artificial Intelligence in Medicine 10 (2): 177–200. https://doi.org/10.1016/S0933-3657(96)00374-0.
Hennessy, Conor, Alberto Bugarín, and Ehud Reiter. 2020. ‘Explaining Bayesian Networks in Natural Language: State of the Art and Challenges’. In 2nd Workshop on Interactive Natural Language Technology for Explainable Artificial Intelligence, 28–33. Dublin, Ireland: Association for Computational Linguistics. https://aclanthology.org/2020.nl4xai-1.7.
Keppens, Jeroen. 2012. ‘Argument Diagram Extraction from Evidential Bayesian Networks’. Artificial Intelligence and Law 20 (2): 109–43. https://doi.org/10.1007/s10506-012-9121-z.
Koller, Daphne, and Nir Friedman. 2009. Probabilistic Graphical Models: Principles and Techniques. Adaptive Computation and Machine Learning Series. Cambridge, MA, USA: MIT Press.
Kyrimi, Evangelia, Somayyeh Mossadegh, Nigel Tai, and William Marsh. 2020. ‘An Incremental Explanation of Inference in Bayesian Networks for Increasing Model Trustworthiness and Supporting Clinical Decision Making’. Artificial Intelligence in Medicine 103 (March): 101812. https://doi.org/10.1016/j.artmed.2020.101812.
Lacave, Carmen, and Francisco J. Díez. 2002. ‘A Review of Explanation Methods for Bayesian Networks’. The Knowledge Engineering Review 17 (2): 107–27. https://doi.org/10.1017/S026988890200019X.
Lauritzen, S. L., and D. J. Spiegelhalter. 1988. ‘Local Computations with Probabilities on Graphical Structures and Their Application to Expert Systems’. Journal of the Royal Statistical Society. Series B (Methodological) 50 (2): 157–224.
Lundberg, Scott M, and Su-In Lee. 2017. ‘A Unified Approach to Interpreting Model Predictions’. In Advances in Neural Information Processing Systems. Vol. 30. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html.
Madigan, David, Krzysztof Mosurski, and Russell G. Almond. 1997. ‘Graphical Explanation in Belief Networks’. Journal of Computational and Graphical Statistics 6 (2): 160–81. https://doi.org/10.1080/10618600.1997.10474735.
Miller, Tim. 2018. ‘Explanation in Artificial Intelligence: Insights from the Social Sciences’. ArXiv:1706.07269 [Cs], August. http://arxiv.org/abs/1706.07269.
Mooij, J. 2004. ‘Understanding and Improving Belief Propagation’. Undefined. https://www.semanticscholar.org/paper/Understanding-and-improving-belief-propagation-Mooij/1e6ba25b4d15d9d24c036479313047ffe4817f08.
Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. 2016. ‘“Why Should I Trust You?”: Explaining the Predictions of Any Classifier’. ArXiv:1602.04938 [Cs, Stat], August. http://arxiv.org/abs/1602.04938.
Rudin, Cynthia. 2019. ‘Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead’. Nature Machine Intelligence 1 (5): 206–15. https://doi.org/10.1038/s42256-019-0048-x.
Suermondt, Henri Jacques. 1992. ‘Explanation in Bayesian Belief Networks’. Phd, Stanford, CA, USA: Stanford University.
Timmer, Sjoerd T., John-Jules Ch. Meyer, Henry Prakken, Silja Renooij, and Bart Verheij. 2017. ‘A Two-Phase Method for Extracting Explanatory Arguments from Bayesian Networks’. International Journal of Approximate Reasoning 80 (January): 475–94. https://doi.org/10.1016/j.ijar.2016.09.002.
Vreeswijk, Gerard A. W. 2005. ‘Argumentation in Bayesian Belief Networks’. In Argumentation in Multi-Agent Systems, edited by Iyad Rahwan, Pavlos Moraïtis, and Chris Reed, 111–29. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer. https://doi.org/10.1007/978-3-540-32261-0_8.
1 comments
Comments sorted by top scores.
comment by johnswentworth · 2021-12-09T00:36:46.712Z · LW(p) · GW(p)
It seems to me like humans have pretty decent built-in intuitions for causal DAGs. The difficulty in explaining Bayes nets is not so much that the underlying model is unintuitive, as that the English language is not very good for expressing DAG-native concepts. For instance, when talking about causality, English makes it hard to distinguish proximal causes, upstream causes, necessary-and-sufficient causes (i.e. mediators), Markov blankets, approximate Markov blankets/mediators, etc. Yet these are all fairly intuitive if you draw them in a quick diagram.
This work is trying to find English language forms which nicely express various structures in Bayes nets. It seems to me like it would be useful to "turn it around": i.e. take those English language forms, give them short names, and then integrate them into one's writing, speech and thought. Ideally, this would make it easier to think about and discuss causality in English. I'd expect something like that to be very valuable, if it worked, e.g. at the scale of the rationalist community. A ton of discussions seem to get hung up on people confusing different claims about causality (e.g. people nominally arguing about A and B as causes of C, when one is obviously upstream of the other; or someone trying to make a subtle-in-English point about one variable mediating another). With better language, I'd expect such discussions to go much better.
It sounds like this work has already found some language which would likely work reasonably well for that purpose, which could be quite valuable.