AI Forecasting: Two Years In
post by jsteinhardt · 2023-08-19T23:40:04.302Z · LW · GW · 15 commentsThis is a link post for https://bounded-regret.ghost.io/scoring-ml-forecasts-for-2023/
Contents
My forecasts, and others Evaluating my own performance in more detail Conclusion None 15 comments
Two years ago, I commissioned forecasts for state-of-the-art performance on several popular ML benchmarks. Forecasters were asked to predict state-of-the-art performance on June 30th of 2022, 2023, 2024, and 2025. While there were four benchmarks total, the two most notable were MATH (a dataset of free-response math contest problems) and MMLU (a dataset of multiple-choice exams from the high school to post-graduate level).
One year ago, I evaluated the first set of forecasts. Forecasters did poorly and underestimated progress, with the true performance lying in the far right tail of their predicted distributions. Anecdotally, experts I talked to (including myself) also underestimated progress. As a result of this, I decided to join the fray and registered my own forecasts for MATH and MMLU last July.
June 30, 2023 has now passed, so we can resolve the forecasts and evaluate my own performance as well as that of other forecasters, including both AI experts and generalist "superforecasters". I'll evaluate the original forecasters that I commissioned through Hypermind, the crowd forecasting platform Metaculus, and participants in the XPT forecasting competition organized by Karger et al. (2023), which was stratified into AI experts and superforecasters.
Overall, here is how I would summarize the results:
- Metaculus and I did the best and were both well-calibrated, with the Metaculus crowd forecast doing slightly better than me.
- The AI experts from Karger et al. did the next best. They had similar medians to me but were (probably) overconfident in the tails.
- The superforecasters from Karger et al. did the next best. They (probably) systematically underpredicted progress.
- The forecasters from Hypermind did the worst. They underpredicted progress significantly on MMLU.
Interestingly, this is a reverse of my impressions from last year, where even though forecasters underpredicted progress, I thought of experts as underpredicting progress even more. In this case, it seems the experts did pretty well and better than generalist forecasters.
What accounts for the difference? Some may be selection effects (experts who try to register forecasts are more likely to be correct). But I'd guess some is also effort: the expert "forecasts" I had in mind last year were from informal hallway conversations, while this year they were formal quantitative predictions with some (small) monetary incentive to be correct. In general, I think we should trust expert predictions more in this setting (relative to their informal statements), and I'm now somewhat more optimistic that experts can give accurate forecasts given a bit of training and the correct incentives.
In the rest of the post, I'll first dive into everyone's forecasts and evaluate each in turn. Then, I'll consider my own forecast in detail, evaluating not just the final answer but the reasoning I used (which was preregistered and can be found here).
My forecasts, and others
As a reminder, forecasts are specified as probability distributions over some (hopefully unambiguously) resolvable future outcome. In this case the outcome was the highest credibly claimed benchmark accuracy by any ML system on the MATH and MMLU benchmarks as of June 30, 2023.[1]
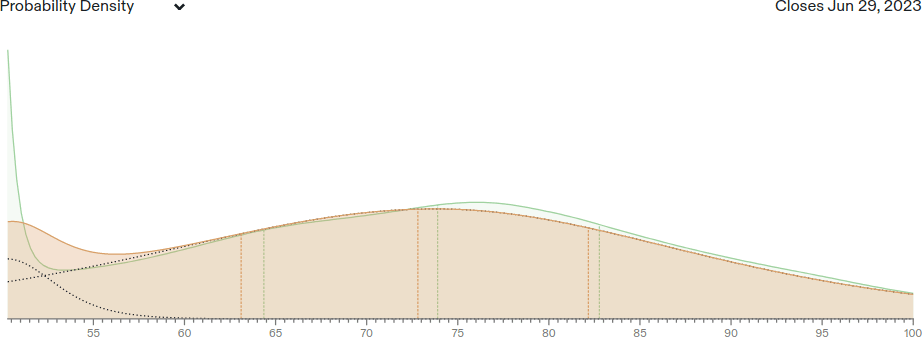
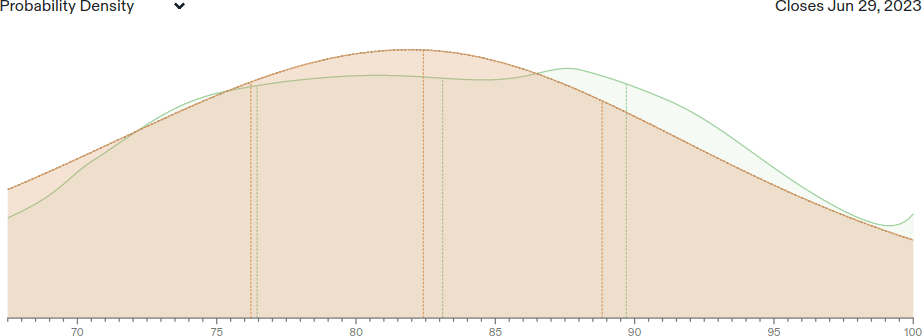
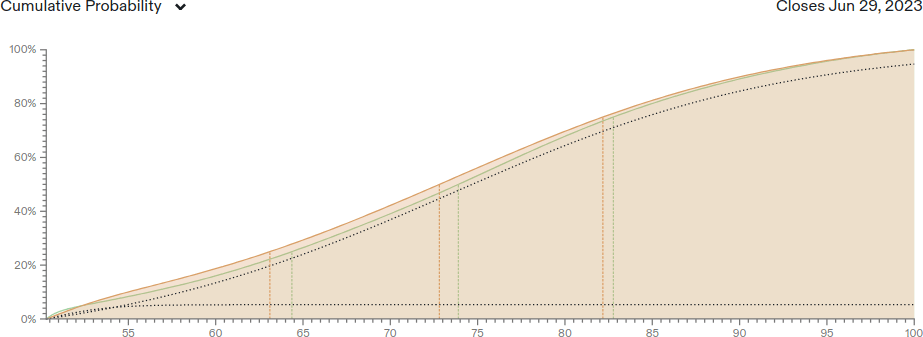
My forecasts from July 17, 2022 are displayed below as probability density functions, as well as cumulative distribution functions and the actual result:
 |
 |
 |
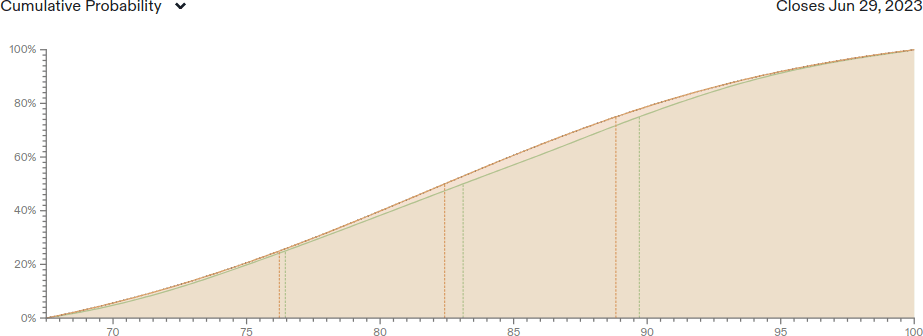 |
| Result: 69.6% (Lightman et al., 2023) | Result: 86.4% (GPT-4) |
Orange is my own forecast, while green is the crowd forecast of Metaculus on the same date. For MATH, the true result was at my 41st percentile, while for MMLU it was at my 66th percentile. I slightly overestimated progress on MATH and underestimated MMLU, but both were within my range of expectations.
Below I'll compare my forecast to that of Metaculus (already shown above), the forecasting platform Hypermind, and forecasts from a recent tournament organized by Karger et al. (2023).
Metaculus. As shown above, Metaculus gave very similar forecasts to my own, although they were a bit more bullish on progress. Given that I underestimated MMLU more than I overestimated MATH, I'd score the Metaculus crowd forecast as doing slightly better than me.
Hypermind. Here are Hypermind's forecasts for the same question; the close date for these forecasts was August 14, 2022, so the Hypermind forecasts had more information than myself or Metaculus (as they were made a month later, and after I made a public blog post registering my predictions).
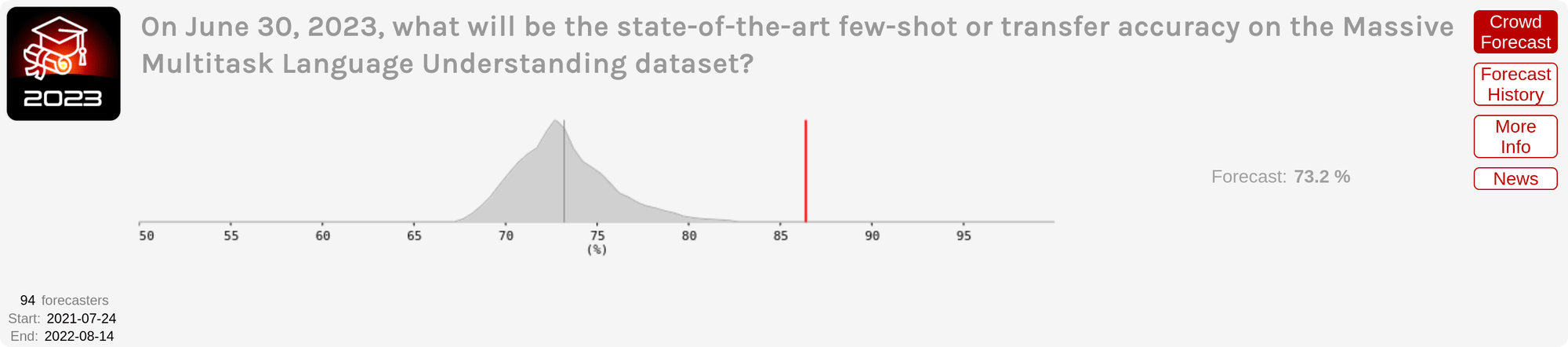
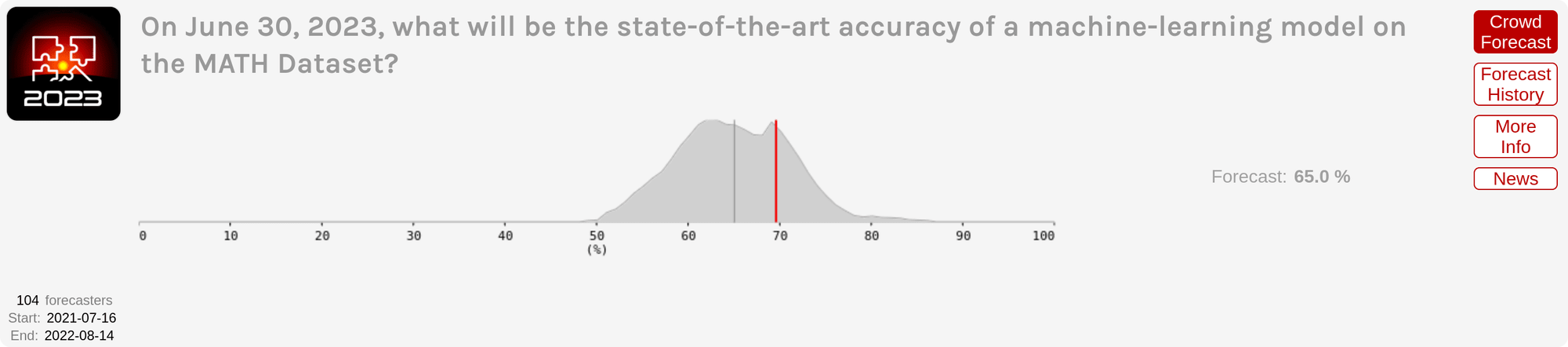
On the MMLU dataset, the Hypermind forecasts are notably worse than either my own or Metaculus, where the true answer is far outside the predicted distribution. In contrast, on MATH I'd say Hypermind scores better, as they had a narrower distribution over outcomes and the true answer fell within their range. Overall Hypermind fared worse than Metaculus--a key part of predictions is being calibrated, so having one answer out of two fall far outside the predicted interval is not good, especially given that the same thing happened last year (for both MATH and MMLU).
As a further piece of evidence that Hypermind forecasters really were making a mistake, I specifically called Hypermind's MMLU prediction as too bearish in my previous post, where I said: "Interestingly, the Hypermind median is only at 72.5% right now. Given the ability to combine Minerva + Chinchilla [which would give 74.2% accuracy], this intuitively seems too low to me."
XPT tournament (Karger et al., 2023). Karger et al. recently held a tournament in which "superforecasters"[2] and domain experts made forecasts and tried to persuade each other in cases where they disagreed. These forecasts spanned many questions related to AI, pandemics and bioweapons, nuclear weapons, and other global risks, but in particular included forecasts on the MATH and MMLU benchmarks. Forecasts were registered during both an initial and final stage, which were roughly in July and October 2022[3], bracketing the date on which I made my own forecasts (in particular, the data in Karger et al. shows that at least some forecasters referenced my blog during the latter stage, though not necessarily the specific post where I made predictions[4]).
Unfortunately, the tournament only asked for forecasts of performance in 2024 and 2030 (not 2023), so we cannot fully resolve the XPT forecasters, but we can make some evaluations. For instance:
- If progress on a benchmark already exceeds the 2024 forecast, then the forecast was definitely bad.
- If the 2024 forecast would be much too high or low if we extrapolate current trends, the forecast is probably bad, since we should place some probability on current trends continuing for at least 1 year.
- If the 2024 forecast diverges significantly from the current Metaculus forecast for 2024, then the forecast is arguably bad. The justification for this is that the current Metaculus forecast has a year of extra data so is better-informed, and Metaculus did well last year so it is reasonable to trust them.
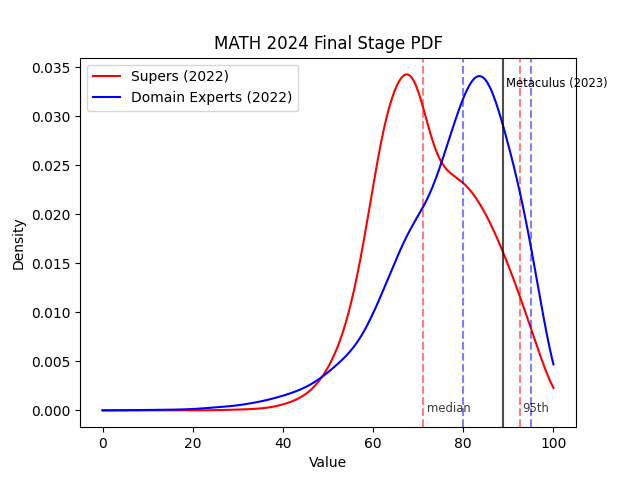
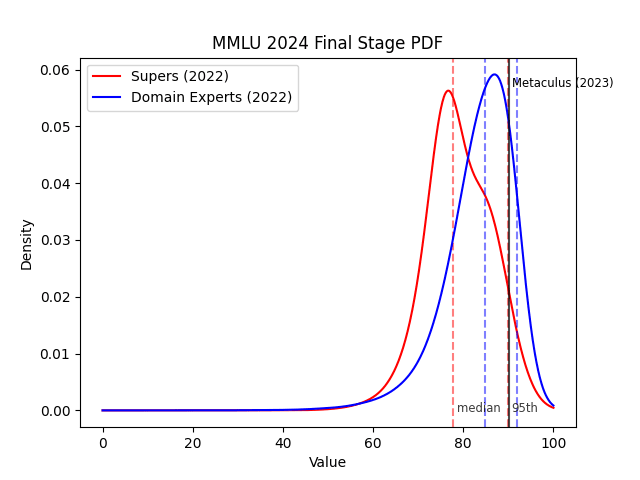
Here are the distributions for both the superforecasters and AI domain experts on MATH and MMLU accuracy in 2024, with their median and 95th percentile indicated below the plot. I've also included the Metaculus median forecast (as of August 2, 2023) for reference.
 |
 |
| Metaculus | |
| 88.9% (median) [live forecast] | 90.2% (median) [live forecast] |
All of the forecasts are more bearish than the Metaculus median. Therefore, the main way for a forecast to be "obviously" wrong is if reality ends up in its far right tail. Since we don't have access to reality (it isn't 2024 yet), as a proxy I'll compute the probability (under the Metaculus 2023 forecast) that each of these forecasts exceed their 95th percentile. The justification for this is that Metaculus has a year of extra data and so should at least be closer to reality than the forecasts from 2022.
For reference, I include full Metaculus forecast below as a probability density function; note the x-axis is truncated on the left.
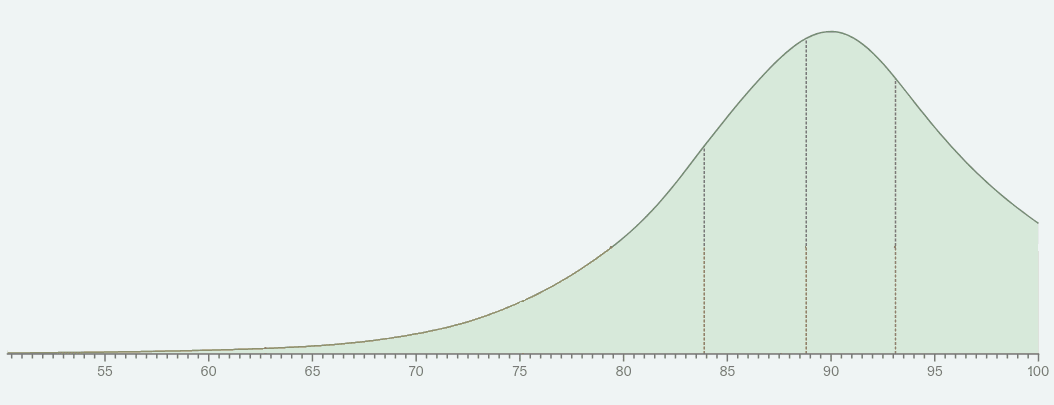 |
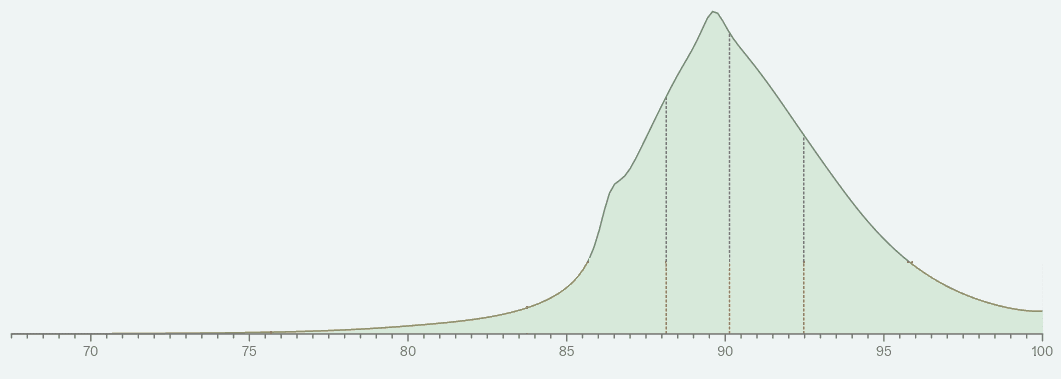 |
Metaculus assigns about 25% probability to MATH resolving beyond the 95th percentile superforecaster prediction, and 50% probability to MMLU doing so. In other words, Metaculus thinks there is a reasonably high chance that the superforecasters will be significantly off in 2024.
In contrast, Metaculus assigns about 15% probability to MATH resolving beyond the 95th percentile domain expert prediction, and 30% probability to MMLU doing so. This is despite the fact that the AI experts had a narrower prediction interval than the superforecasters (e.g. as measured by the gap between the median and 95th percentile). So, the AI experts look better than the superforecasters.
I also happened to register forecasts for 2024 on MATH around the same time, and I had a very similar median to the AI experts (80.7% vs 80%). However, my 95th percentile was at 97.5% instead of 95%; Metaculus assigns only 7% probability to MATH resolving beyond this point, so my own forecast stands up better than either the superforecasters or AI experts. I believe this is primarily due to having practiced calibration more, as most novice forecasters underestimate how wide a 95% confidence interval needs to be.
A final point of evidence against the superforecasters from Karger et al. is their initial stage forecast on MATH, which I include in a footnote[5]. Superforecasters (but not AI experts) gave much lower forecasts on MATH in the initial stage, with a 95th percentile of 55%. This was due to them failing to predict Minerva, a result in July 2022 that improved state-of-the-art on MATH from 7% to 50%. This could partly be due to forecasters running out of time in the initial stage, but nevertheless shows that they had miscalibrated intuitions. Note also that experts may have done better simply due to being aware of the Minerva result in time (it came out close to when initial stage forecasts were due).
Conclusion. Based on the data above, my ranking of forecasts would be: Metaculus ≈ me > XPT AI experts > XPT superforecasters > Hypermind superforecasters.
Evaluating my own performance in more detail
Since I included public reasoning for my own forecast, we can go beyond the bottom-line probabilities and look at whether I got things right for the right reasons. For instance, if I predicted that MATH would increase primarily due to better prompt engineering, but most of the improvement was actually from scaling up models, this would indicate I had an incorrect picture of the situation even if my final forecast was good.
My previous reasoning can be found here. It isn't fully comprehensive, but I pulled out some specific claims below that we can evaluate.
Reasoning for MATH. For the MATH benchmark, I took several different angles, some based on looking at overall trends in progress and some based on thinking about specific sources of improvement. The latter is of particular interest here, because I made claims about several possible sources of improvement and how much I thought they could help:
- Improving over majority vote aggregation ("easy to imagine 8%, up to 25%")
- Fine-tuning on more data ("intuitively around 5%")
- Improving chain-of-thought prompting ("easy to imagine 3-5%, up to 10%")
- Better-trained version of PaLM that follows Chinchilla scaling laws (said it probably wouldn’t happen, but 4% if it did)
- Larger model (said not obvious it will happen, but couple % if it did)
- Maybe small gains from better web scraping / tokenization
Overall, I said it was easy to imagine 14% in aggregate, suggesting I didn’t believe all of the first 3 would clearly happen, but that some subset would.
What happened in reality? Accuracy increased by 18% (to 69.6%), due to the paper Let’s Verify Step by Step. That paper fine-tuned GPT-4, which was likely both better-trained and larger, so according to my reasoning this alone should increase accuracy by 6%. On the other hand, they only fine-tuned on 1.5B math-relevant tokens, compared to 26B for Minerva (the previous record-holder), so "fine-tuning on more data" was likely not a contributor to increased accuracy.[6]
What explains the remaining accuracy gain? Based on reading the Let's Verify paper, my main hypothesis comes from this quote in the paper: "To make parsing individual steps easier, we train the generator to produce solutions in a newline delimited step-by-step format. Specifically, we few-shot generate solutions to MATH training problems, filter to those that reach the correct final answer, and finetune the base model on this dataset for a single epoch. This step is not intended to teach the generator new skills; it is intended only to teach the generator to produce solutions in the desired format." Even though it was not intended to improve accuracy, previous work shows that this type of chain-of-thought distillation can improve accuracy significantly: Huang et al. (2022) apply a similar technique to improve performance on GSM-8K from 74% to 82%.
Overall, my guess is that the 18% accuracy gain breaks down roughly as follows:
- 4% from GPT-4 using the appropriate (Chinchilla) scaling law
- 5% from GPT-4 being bigger than Minerva
- 2% from GPT-4 being trained on more data[7]
- 8% from the chain-of-thought distillation described above
- -1% from less math-specific fine-tuning data
How does this compare with what I predicted? On the positive side, many of the factors are the same as what I listed, and they plausibly had roughly the magnitude I predicted.
On the negative side, I forgot that future models would not just be bigger but trained on more data, and that this would also improve accuracy. I also forgot to account for the possible of "going backwards" (e.g. having systems fine-tuned on less data than Minerva). And, while I had considered improvements to chain-of-thought and 8% was within my predicted range, I was probably thinking more about inference-time improvements rather than distillation.
Finally, most of the sources of improvement I listed happened, even though I predicted on median that only some of them would happen. In fact, the only major improvement that didn't happen was "improving over majority vote", which was in the Let's Verify paper and improved performance by about 10%, but was disqualified due to using non-allowed data to train. Given this, did I underestimate how much innovation would happen? I think not too badly--the Let's Verify paper required not only for GPT-4 to come out, but for someone to fine-tune it on math-related problems, and I don't think it was obvious that both would happen even with the benefit of hindsight.
Overall, I think my forecast reasoning was good but not great--I identified most of the correct sources of improvement, but I forgot one important one (more pre-training data) and also forgot that it's possible to move backwards (e.g. from less fine-tuning data).
Reasoning for MMLU. For MMLU, I said that improvements were likely to come from general-purpose improvements to language models rather than something targeted to MMLU (in contrast to MATH, where the Let's Verify paper was fairly targeted towards math problems). This ended up being correct, as the state-of-the-art was set by GPT-4 with a 5-shot prompt (no fine-tuning).
In terms of sources of improvements, I had the following list:
- General scaling up
- Combining the advantages of Chinchilla + Minerva (e.g. large model with correct scaling laws + math-specific data); I gave 65% probability to this happening
- Further STEM-specific improvements a la Minerva (said I expected 3% gain from this), e.g. maybe tool use like calculators would help on some subsets of MMLU
- Improvements to chain-of-thought prompting
- Incorporating retrieval models; I gave 20% probability to this
In terms of what actually happened:
- Obviously scaling up was a big part of GPT-4
- GPT-4 was trained with correct scaling laws, but there isn't enough information in the GPT-4 paper to know how much math-specific data it was trained on. I'd guess there was at least some, and that relative to Chinchilla its training data had a larger fraction of math in it.
- The GPT-4 5-shot result had no improvements to chain-of-thought prompting
- The 5-shot result also did not use retrieval
So, gains came primarily from scaling up, as opposed to improvements to chain-of-thought prompting. Interestingly, there are several improvements that seem like they would improve accuracy (see this video overview), but no one has documented them formally for MMLU, so they don't affect the forecast resolution.
I'd score my reasoning for MMLU as fairly good--I correctly predicted that scaling up would be the major source of gains, though I probably slightly underpredicted how much this would help. I also predicted improvements to chain-of-thought that didn't end up being used, but given that they were publicly available and had been used on other benchmarks, I consider this only a near-miss. I predicted STEM-specific improvements that may not have materialized, but I thought these improvements would be small anyways.
Takeaways. My main takeaways for next time are:
- Don't forget that backward progress is possible (a new model could be better on one axis but worse on others).
- Don't forget that data can improve in addition to model size.
- There might also be a lot of fine-tuning and other tricks under the hood that increase performance but are not publicly reported (e.g. companies might start to do chain-of-thought distillation as part of their standard fine-tuning pipeline).
- There might be obvious sources of gains that are publicly reported but not used, because no one has gotten around to it yet.
Overall, this is a good reminder of the value of considering "other" options.
Conclusion
Metaculus continues to fare well on AI benchmark forecasts, and I've shown that I can make reasonable forecasts as well (with the caveat of N=2, but the reasoning holds up in addition to the bottom-line forecast). Traditional superforecasters still seem to lag in predicting AI benchmarks compared to other domains, and are too bearish on progress. At least some other AI experts also did well, but may have been overconfident in the tails.
It will be interesting to see the next round of results a year from now, and in the meantime I would encourage both AI experts and superforecasters to publicly register their predictions on Metaculus, which can be done here for MATH and here for MMLU.
The ML system also had to follow certain rules, such as not training on the test set. You can find the official statement of the forecasts here and here. ↩︎
A generalist forecaster with a strong prior track record. ↩︎
Different forecasters registered their forecasts at different dates, but July and October match the median date forecasts were submitted in each stage. ↩︎
Specific quote: "Berkeley Prof. Jacob Steinhardt's ongoing experiment with forecasting the progress of several measures of AI progress, including this MATH dataset: https://bounded-regret.ghost.io/ai-forecasting-one-year-in/. Results so far in the Steinhardt experiment, which began in August of 2021, are that all forecasters vastly underestimated progress in the MATH's reports on competition mathematics. Results as of July 5, 2022: 50.3% accuracy vs. 12.7% predicted. So I take that as a warning to not underestimate future progress!" ↩︎
Initial stage forecasts for MATH and MMLU, with final stage forecasts reproduced for convenience:
↩︎It's overall hard to evaluate this point, for two reasons: first, since 1.5B is so much less than 26B, we would arguably expect an accuracy drop from training on less data, but the authors of Let's Verify claim that their data is better-filtered which might mitigate this. Additionally, it's possible that GPT-4 was pretrained on arxiv and thus implicitly had a large amount of math already in its training data, but there are not enough public details about how GPT-4 was trained to know either way. ↩︎
In my earlier post, my analysis extrapolated the gains from scaling the model up while holding data constant. This was an oversight on my part, since larger models are usually also trained on more data, and the 2% here corrects for that. ↩︎
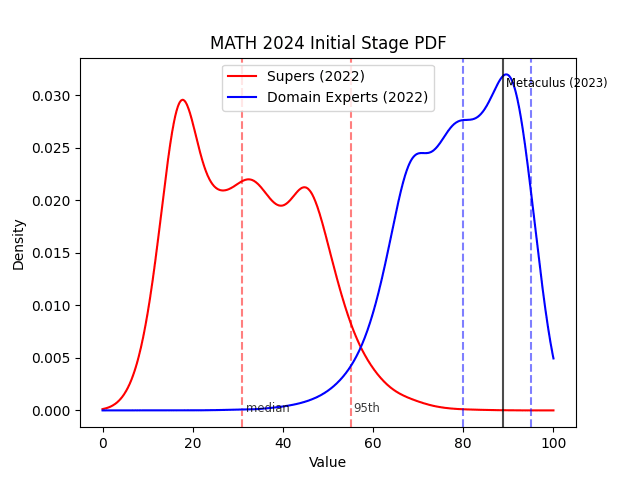
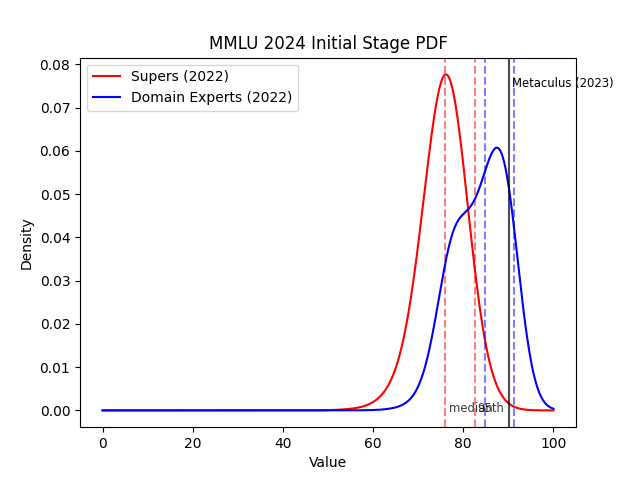
15 comments
Comments sorted by top scores.
comment by Lech Mazur (lechmazur) · 2023-08-20T00:11:55.008Z · LW(p) · GW(p)
Following your forecast's closing date, MATH has reached 84.3% as per this paper if counting GPT-4 Code Interpreter: https://arxiv.org/abs/2308.07921v1
Replies from: dan-hendrycks↑ comment by Dan H (dan-hendrycks) · 2023-08-20T16:47:00.514Z · LW(p) · GW(p)
Usage of calculators and scripts are disqualifying on many competitive maths exams. Results obtained this way wouldn't count (this was specified some years back). However, that is an interesting paper worth checking out.
Replies from: jsteinhardt, o-o↑ comment by jsteinhardt · 2023-08-20T21:44:11.590Z · LW(p) · GW(p)
Is it clear these results don't count? I see nothing in the Metaculus question text that rules it out.
Replies from: dan-hendrycks↑ comment by Dan H (dan-hendrycks) · 2023-08-21T16:25:07.570Z · LW(p) · GW(p)
It was specified in the beginning of 2022 in https://www.metaculus.com/questions/8840/ai-performance-on-math-dataset-before-2025/#comment-77113 In your metaculus question you may not have added that restriction. I think the question is much less interesting/informative if it does not have that restriction. The questions were designed assuming there's no calculator access. It's well-known many AIME problems are dramatically easier with a powerful calculator, since one could bash 1000 options and find the number that works for many problems. That's no longer testing problem-solving ability; it tests the ability to set up a simple script so loses nearly all the signal. Separately, the human results we collected was with a no calculator restriction. AMC/AIME exams have a no calculator restriction. There are different maths competitions that allow calculators, but there are substantially fewer quality questions of that sort.
I think MMLU+calculator is fine though since many of the exams from which MMLU draws allow calculators.
Replies from: o-o↑ comment by O O (o-o) · 2023-08-21T16:31:11.367Z · LW(p) · GW(p)
I think it’s better if calculators are counted for the ultimate purpose of the benchmark. We can’t ban AI models from using symbolic logic as an alignment strategy.
Replies from: dan-hendrycks↑ comment by Dan H (dan-hendrycks) · 2023-08-21T16:53:18.063Z · LW(p) · GW(p)
The purpose of this is to test and forecast problem-solving ability, using examples that substantially lose informativeness in the presence of Python executable scripts. I think this restriction isn't an ideological statement about what sort of alignment strategies we want.
↑ comment by O O (o-o) · 2023-08-21T16:25:52.670Z · LW(p) · GW(p)
That doesn’t make too much sense to me. Here the calculators are running on the same hardware as the model and theoretically transformers can just have a submodel that models a calculator.
Replies from: dan-hendrycks↑ comment by Dan H (dan-hendrycks) · 2023-08-21T16:52:01.907Z · LW(p) · GW(p)
I think there's a clear enough distinction between Transformers with and without tools. The human brain can also be viewed as a computational machine, but when exams say "no calculators," they're not banning mental calculation, rather specific tools.
comment by Ted Sanders (ted-sanders) · 2023-08-20T05:09:18.432Z · LW(p) · GW(p)
Thanks for the write up. I was a participant in both Hypermind and XPT, but I recused myself from the MMLU question (among others) because I knew the GPT-4 result many months before the public. I'm not too surprised Hypermind was the least accurate - I think the traders there are less informed, plus the interface for shaping the distribution is a bit lacking (my recollection is that last year's version capped the width of distributions which massively constrained some predictions). I recall they also plotted the current values, a generally nice feature which has the side effect of anchoring ignorant forecasters downward, I'd bet.
Question: Are the Hypermind results for 2023 just from forecasts in 2022, or do they include forecasts from the prior year as well? I'm curious if part of the poor accuracy is from stale forecasts that were never updated.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2023-08-20T11:56:22.953Z · LW(p) · GW(p)
I was a participant in both Hypermind and XPT, but I recused myself from the MMLU question (among others) because I knew the GPT-4 result many months before the public.
This is a prediction market not a stock market, insider trading is highly encouraged. Don't know about Jacob but I'd rather have more accurate predictions in my prediction market.
↑ comment by Ted Sanders (ted-sanders) · 2023-08-20T21:14:52.610Z · LW(p) · GW(p)
Strongly disagree. Employees of OpenAI and their alpha tester partners have obligations not to reveal secret information, whether by prediction market or other mechanism. Insider trading is not a sin against the market; it's a sin against the entity that entrusted you with private information. If someone tells me information under an NDA, I am obligated not to trade on that information.
comment by jsteinhardt · 2023-08-20T21:43:34.779Z · LW(p) · GW(p)
Mods, could you have these posts link back to my blog Bounded Regret in some form? Right now there is no indication that this is cross-posted from my blog, and no link back to the original source.
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-08-20T21:55:12.439Z · LW(p) · GW(p)
It does link to it in the header:

But I'll make it a link-post so it's clearer. Different people have different preferences for how noticeable they want the cross-posting to be.
Replies from: jsteinhardt↑ comment by jsteinhardt · 2023-08-20T21:58:29.658Z · LW(p) · GW(p)
I don't see it in the header in Mobile (although I do see the updated text now about it being a link post). Maybe it works on desktop but not mobile?
Replies from: habryka4↑ comment by habryka (habryka4) · 2023-08-20T22:28:35.467Z · LW(p) · GW(p)
Ah, that is possible, and if so, seems like something we should adjust. I don't like hiding UI elements on mobile that are visible on desktop.
Edit: Yep, looks like it's indeed just hidden on mobile. Not sure how high priority it is, but seems kind of like a bug to me.