Behavioral and mechanistic definitions (often confuse AI alignment discussions)
post by LawrenceC (LawChan) · 2023-02-20T21:33:01.499Z · LW · GW · 5 commentsContents
Introduction: Three examples of behavioral and mechanistic definitions Induction heads Different framings of inner and outer alignment Definitions of fire The pros and cons of behavioral versus mechanistic definitions Pros of Behavioral Definitions Pros of Mechanistic Definitions Relation to “gears-level” models That being said... Acknowledgments None 5 comments
TL;DR: It’s important to distinguish between behavioral definitions – which categorize objects based on outside observable properties – and mechanistic definitions – which categorize objects based on their internal mechanisms. In this post, I give several examples of terms which can be defined either behaviorally and mechanistically. Then, I talk about the pros and cons of both kinds of definitions, and how this distinction relates to the distinction between gears-level versus black-box models.
Related to: Most similar to John Wentworth’s Gears and Behaviors [LW · GW], but about definitions rather than models. Also inspired by: Gears in understanding [LW · GW], How an algorithm feels from the inside [LW · GW], the “Human’s Guide to Words” Sequence in general [? · GW].
Epistemic status: written quickly instead of not at all.[1]
Introduction:
Broadly speaking, when pointing at a relatively distinct cluster of objects, there’s two ways to define membership criteria:
- Behaviorally: You can categorize objects based on outside observable properties, that is, their behavior in particular situations.
- Mechanistically: Alternatively, you can categorize objects via their internal mechanisms. That is, instead of only checking for a particular behavioral property, you instead look for how the object implements said property.[2]
Many AI safety concepts have both behavioral and mechanistic definitions. In turn, many discussions about AI safety end up with the participants confused or even talking past each other. This is my attempt to clarify the discussion, by giving examples of both, explaining the pros and cons, and discussing when you might want to use either.
Three examples of behavioral and mechanistic definitions
To better illustrate what I mean, I’ll give two examples from recent ML work and a third from the sequences.
Induction heads
First introduced in a mathematical framework for transformer circuits, induction heads are transformer attention heads that implement in-context copying behavior. However, there seem to be two definitions that are often conflated:[3]
Behavioral: Subsequent papers (In-context Learning and Induction Heads, Scaling laws and Interpretability of Learning from Repeated Data) give a behavioral definition of induction heads: Induction heads are heads that score highly on two metrics on repeated random sequences of the form [A] [B] … [A]:
- Prefix matching: attention heads pay a lot of attention to the first occurrence of the token [A].
- Copying: attention heads increase the logit of [B] relative to other tokens.
This definition is clearly behavioral: it makes no reference to how these heads are implemented, but only to their outside behavior.
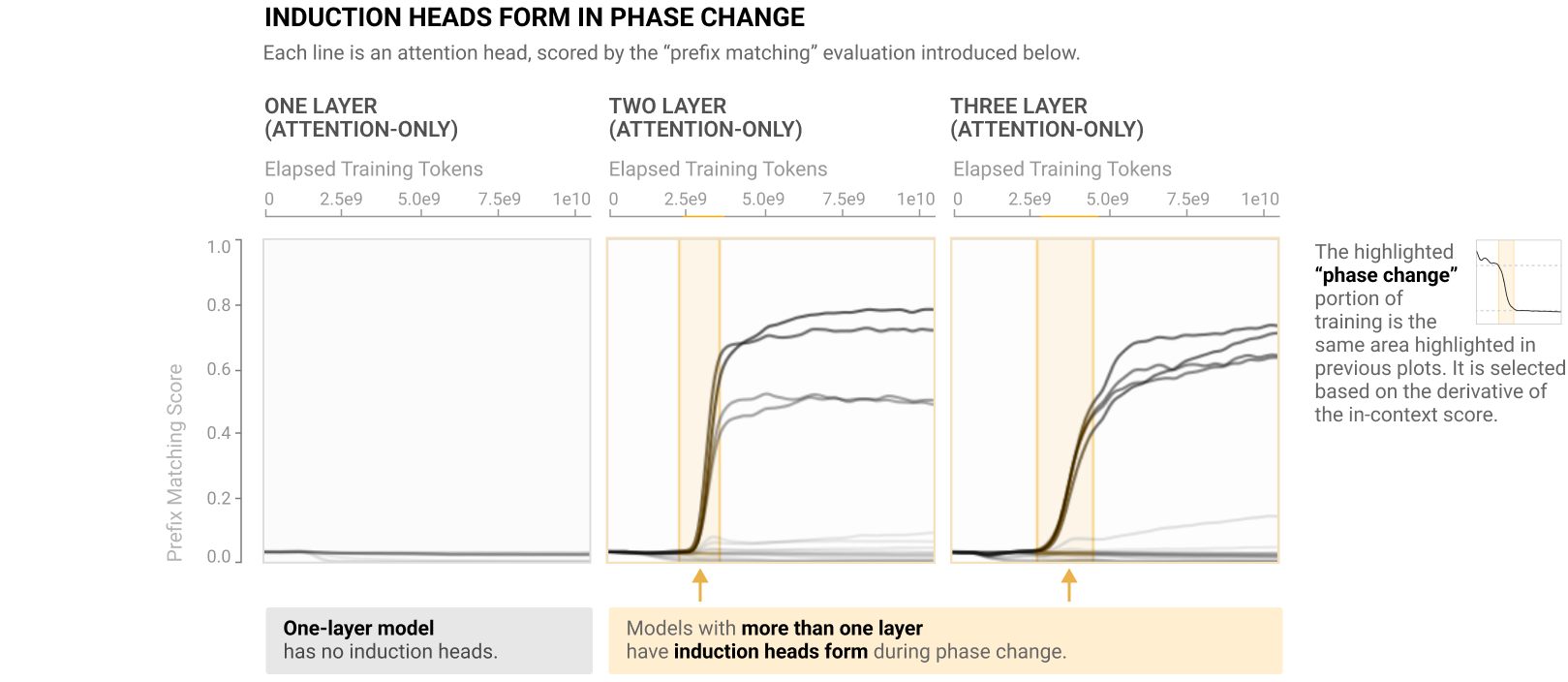
Source: In-context Learning and Induction Heads, Olsson et al. 2022
Mechanistic: In contrast, the original mathematical framework paper also gives a mechanistic definition for induction heads: induction heads are heads that implement copying behavior using either Q- or K-composition.[4] While this definition does make some reference to outside properties (induction heads implement copying), the primary part is mechanistic and details how this copying behavior is implemented.

Source: A Mathematical Framework for Transformer Circuits, Elhage et al. 2021
However, it turns out that the two definitions don’t overlap perfectly: behavioral induction heads are often implementing many other heuristics, even in very small language models [AF · GW].[5] I often talk to people who confuse the two definitions and think that we understand much more about the internal mechanisms of large language models than we actually do.
In a forthcoming post, Alexandre Variengien discusses the distinction between these two definitions in more detail, while also highlighting specific confusions that may arise from failing to distinguish the two definitions.
Different framings of inner and outer alignment
In Outer and inner misalignment: three framings [AF · GW], Richard gives three definitions of inner vs outer alignment for AI policies, the first of which is behavioral and the second of which is mechanistic:[6]
Behavioral: In his first framing, Richard defines inner misalignment as one of three different types of bad behavior that may occur after an AI system is deployed:
- Capabilities misgeneralization: The policy fails in an incompetent way.
- Outer alignment failure/Reward misspecification: The policy behaves in a competent but undesirable way, that gets high reward according to the original provided reward function.
- Inner alignment failure/Goal misgeneralization: The policy behaves in a competent but undesirable way, that nonetheless gets low reward according to the original provided reward function.
This definition is purely behavioral: given a notion of competence, we can evaluate whether or not a policy is inner misaligned by just 1) checking that the policy is behaving “competently” in deployment, and 2) evaluating the original reward function on the observed deployment behavior.
Mechanistic: In his second framing, Richard defines inner misalignment in terms of the policy’s internally represented, final goals:
- Policies are said to have goals insofar as they represent environmental features that they internally plan to maximize.
- Final goals are goals that the policy will pursue even holding other goals constant, i.e. goals that the policy “values for their own sake”.
- Inner misalignment occurs when the policy’s final goals are not correlated in deployment with human preferences.
This definition is significantly harder to evaluate, as it requires having good enough interpretability to identify concrete goals within neural networks. However, it also allows him to make more concrete claims about the behavior of inner misaligned agents.
I think a big part of confusions around inner/outer misalignment are due to confusing behavior and mechanistic definitions of such. In this case, we care relatively little about the behavioral definition – a policy that’s not aligned with human preference is not aligned with human preferences – and relatively more about the mechanistic definition – an agent that ends up “wanting” to pursue goals misaligned with humans is significantly more concerning.
Definitions of fire
Of course, the idea of behavioral versus mechanistic definitions isn’t confined to machine learning. For example, in several posts in the sequences (for example, Fake Causality [LW · GW], Universal Fire [LW · GW] and Positive Bias: a Look into the Dark [LW · GW]), Eliezer talks about different definitions of fire:
Behavioral: Fire is the hot, orangey-colored thing that you could use to cook food, and that can be made by applying a powerful source of heat (such as another fire) to materials such as wood or paper.
Mechanistic: Fire is the escape of phlogiston from various materials, transforming organic material into ash, the “true material”. Fires went out in enclosed spaces when the air was saturated with phlogiston.
As Eliezer notes, these examples demonstrate a key advantage of behavioral definitions: they work even when you’re very confused about the concept or category. Unlike bad mechanistic definitions, behavioral definitions don’t prematurely hide your confusion.
The pros and cons of behavioral versus mechanistic definitions
Having given some examples, I’ll now talk about the pros and cons of the two types of definitions.
Pros of Behavioral Definitions
The primary advantage of using behavioral definitions is ease of use: they’re generally far easier to verify than mechanistic ones. In both the induction head and the inner/outer misalignment examples, verifying the behaviorally defined versions of those terms just requires evaluating the performance of a transformer or policy in particular situations. In contrast, checking the mechanistic definitions for either will require making significant advances in neural network interpretability. As a result, it’s generally a lot harder to be wrong about whether an object belongs to a cluster according to a behavioral definition. Regardless of if fire occurs because of the release of phlogiston or because of oxidation, fire remains the hot glowy-orange thing that you can use to cook food.
Behavioral definitions can also be more appropriate when you care about the property in itself. For example, a misaligned AI that seizes power from humans is an AI that seizes power from humans, whether or not the cause is “inner” or “outer” misalignment, and regardless of whether the model is implemented using a large transformer or with a smaller network and search. Using a mechanistic definition to refer to “misaligned power seeking AI”, as opposed to a behavioral definition, risks obscuring the property you care about in favor of extraneous details. In some cases, this also allows you to avoid unnecessary, nitpicky fights about technical definitions.
That is: behavioral definitions are better either when you’re quite confused about the cluster (and any mechanistic definition you invent is likely to be substantively wrong), or when you fundamentally care about the behavioral property in itself.
Pros of Mechanistic Definitions
The primary advantage of mechanistic definitions is better generalization: a correct mechanistic definition gives way more “bang for your buck” in terms of predicting other properties of the object. For example, for mechanistic induction heads, we know not only that they are involved in in-context learning, but also can predict how the heads might generalize to slightly different data distributions and how various ablations will affect the performance of the heads. In contrast, behavioral induction heads can also be implementing many other induction-like heuristics [AF · GW], and accordingly, it’s harder to predict the effect of ablating said heads.
Mechanistic definitions are also more likely to be real categories in the world. It’s easy to come up with high level properties that group together many dissimilar objects, which can cause confusion. On the other hand, knowing that a set of objects implements a property using a specific mechanism gives a lot more evidence that the category is “real”.
That is: mechanistic definitions are better when you want to get more bang for your buck, or to clarify discussions confused by dissimilar objects being grouped together.
Relation to “gears-level” models
A related concept in the LW/AF space is the notion of “gears-level” versus black-box models [LW · GW].[7] A black-box model contains no internal structure, while a gears-level model contains gears – tightly interlocked components that determine the outside behavior through known mechanisms.
In my mind, the main distinctions are the following:
- “Gears-level” and “black-box” are properties of models and not definitions. While the terms “gears-level” and “black-box” apply naturally to models, I think they’re less natural for definitions.
- “Gears-level” models are generally assumed to be superior to “black-box” models.[8] But there are reasons to use both behavioral and mechanistic definitions!
As another point, I don’t think people naturally apply these concepts to definitions. For example, I’ve never actually heard people disambiguate the two definitions of induction heads using these words!
That being said...
Regardless of the relative pros and cons of mechanistic and behavioral definitions, I think by far the important thing is not to confuse the two types. We can do this by being clear about when a term is being defined mechanistically or behaviorally, and checking that the term is used in the intended manner when using it.
Acknowledgments
Thanks to Abhay Sheshadri for editing this with me at the SERI MATS workshop, and to Sydney Von Arx for comments.
- ^
Detailed epistemic status: Written in ~2 hours total for the SERI MATS writing workshop I ran. Accordingly, I’m probably missing a bunch of related work, and all the examples are just things I happened to remember at the time.
- ^
Interestingly enough, it’s not clear to me whether or not these definitions are behavioral or mechanistic!
- ^
Note that the Anthropic In-context Learning paper does make it clear that they’re defining induction heads behaviorally, as opposed to the mechanistic definition in the Mathematical Framework paper!
Mechanistic analysis of weights and eigenvalue analysis are much more complicated in large models with MLP’s, so for this paper we choose to define induction heads by their narrow empirical sequence copying behavior (the [A][B]...[A]→[B]), and then attempt to show that they (1) also serve a more expansive function that can be tied to in-context learning, and (2) coincide with the mechanistic picture for small models.
(Source)
- ^
In fact, in the post they focus primarily on induction heads implemented using K-composition, as their simplified two-layer attention-only transformer could not implement Q-composition due to an inability to put positional information in the residual stream.
- ^
In particular, certain heads can be both "induction heads" for one circuit while serving other functionality in other circuits. See for example head 1.4 in A circuit for Python docstrings in a 4-layer attention-only transformer [? · GW], which is a both fuzzy previous token head and an induction head
- ^
The third definition concerns inner/outer alignment in cases where there is no clean train/test split, which is implicitly assumed in the first two definitions.
- ^
For an example of how related the concepts are see David Krueger’s question: “Is ‘gears-level’ just a synonym for “mechanistic?”. [LW · GW]
- ^
I also think that the reputation of black-box models has been a bit too unfairly maligned in the community, but that claim deserves a post in itself.
5 comments
Comments sorted by top scores.
comment by Neel Nanda (neel-nanda-1) · 2023-02-20T22:20:54.980Z · LW(p) · GW(p)
Really nice post! I think this is an important point that I've personally been confused about in the past, and this is a great articulation (and solid work for 2 hours!!)
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2023-02-20T22:27:11.586Z · LW(p) · GW(p)
Thanks!
(As an amusing side note: I spent 20+ minutes after finishing the writeup trying to get the image from the recent 4-layer docstring circuit post to preview properly the footnotes, and eventually gave up. That is, a full ~15% of the total time invested was spent on that footnote!)
comment by Joseph Bloom (Jbloom) · 2023-02-24T18:32:12.913Z · LW(p) · GW(p)
Thanks, Lawrence! I liked this post which I think I'm going to bookmark and refer back to when I'm trying to think/write about analysis. I think t being disciplined about the distinction between these two types of definitions is crucial to think clearly.
I recently heard Buck use the terms "Model Psychology" and "Model Neuroscience" to distinguish types of analysis with small models. My understanding of his position in that public discussion was that people should distinguish between the two because (now using your terms) we shouldn't confuse behavioural insights with mechanistic insights and this is a trap that people fall into, leading to some amount of miscalibrated confidence about how well we understand models. I suspect I have also fallen into this trap, so having this post to refer back to seems especially valuable.
comment by davidad · 2023-02-21T04:59:31.410Z · LW(p) · GW(p)
In computer science this distinction is often made between extensional (behavioral) and intensional (mechanistic) properties (example paper).
comment by Ben Amitay (unicode-70) · 2023-02-22T06:57:56.064Z · LW(p) · GW(p)
This is an important distinction, that show in its cleanest form in mathematics - where you have constructive definitions from the one hand, and axiomatic definitions from the other. It is important to note though that is is not quite a dichotomy - you may have a constructive definition that assume aximatically-defined entities, or other constructions. For example: vector spaces are usually defined axiomatically, but vector spaces over the real numbers assume the real numbers - that have multiple axiomatic definitions and corresponding constructions.
In science, there is the classic "are wails fish?" - which is mostly about whether to look at their construction/mechanism (genetics, development, metabolism...) or their patterns of interaction with their environment (the behavior of swimming and the structure that support it). That example also emphasize that we natural language simplly don't respect this distinction, and consider both internal structure and outside relations as legitimate "coordinates in thingspace" that may be used together to identify geometrically-natural categories.