Gears vs Behavior
post by johnswentworth · 2019-09-19T06:50:42.379Z · LW · GW · 14 commentsContents
What is Missing? Application: Macroeconomic Models Gears from Behavior? Application: Wolf’s Dice Takeaway None 14 comments
Thankyou to Sisi Cheng [LW · GW] (of the Working as Intended comic) for the excellent drawings.
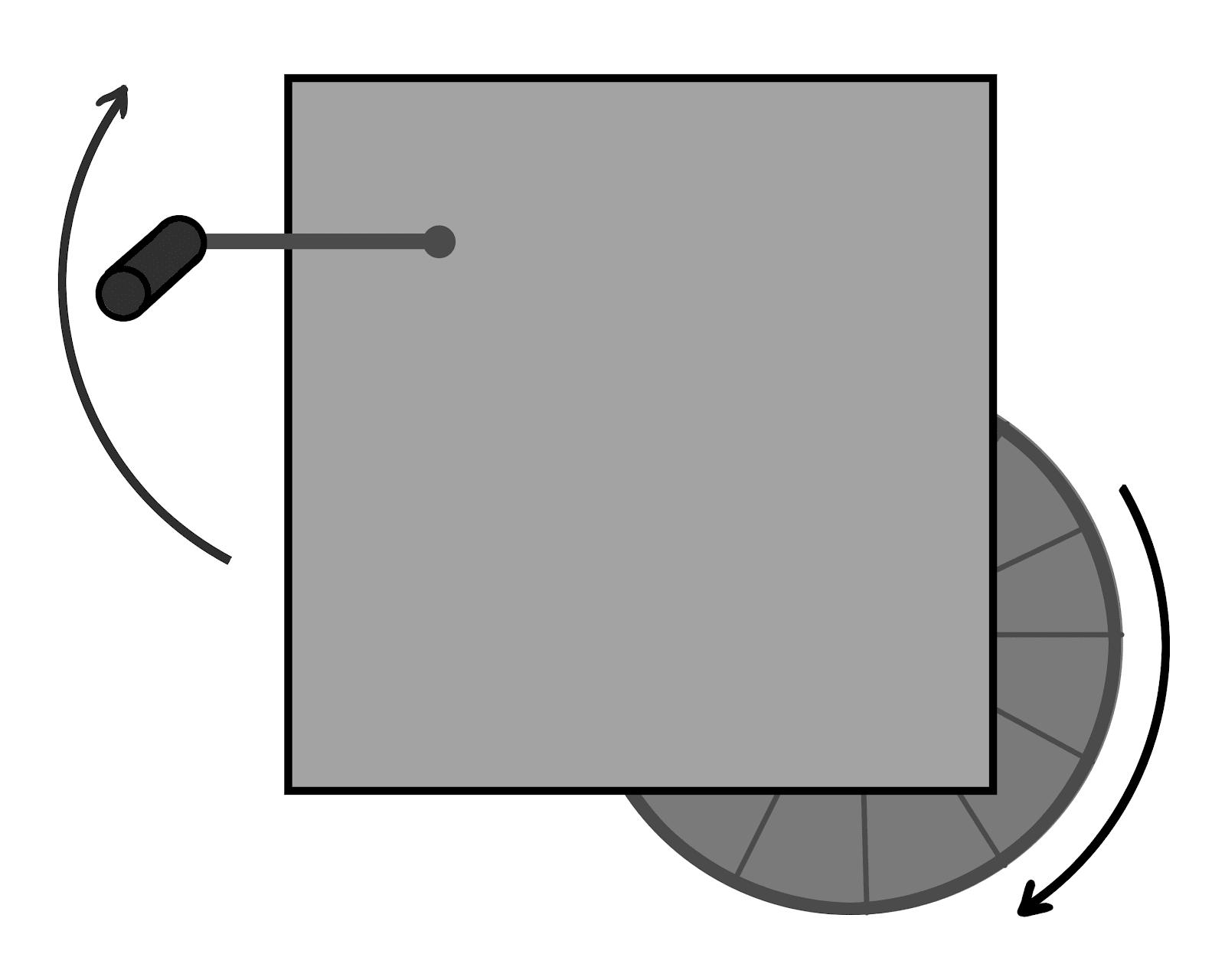
Suppose we have a gearbox. On one side is a crank, on the other side is a wheel which spins when the crank is turned. We want to predict the rotation of the wheel given the rotation of the crank, so we run a Kaggle competition.
We collect hundreds of thousands of data points on crank rotation and wheel rotation. 70% are used as training data, the other 30% set aside as test data and kept under lock and key in an old nuclear bunker. Hundreds of teams submit algorithms to predict wheel rotation from crank rotation. Several top teams combine their models into one gradient-boosted deep random neural support vector forest. The model achieves stunning precision and accuracy in predicting wheel rotation.
On the other hand, in a very literal sense, the model contains no gears [LW · GW]. Is that a problem? If so, when and why would it be a problem?
What is Missing?
When we say the model “contains no gears [LW · GW]”, what does that mean, in a less literal and more generalizable sense?
Simplest answer: the deep random neural support vector forest model does not tell us what we expect to see if we open up the physical gearbox.
For instance, consider these two gearboxes:
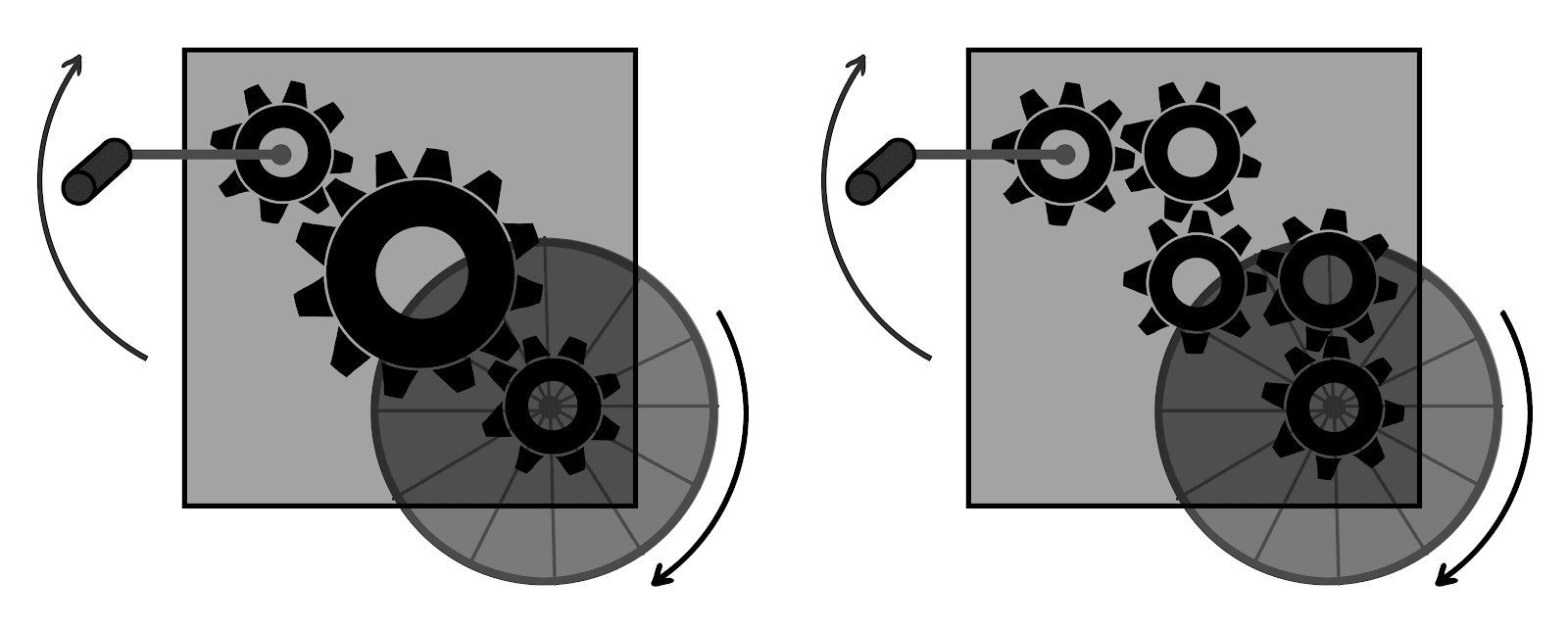
Both produce the same input-output behavior. Our model above, which treats the gearbox as a literal black box, does not tell us anything at all which would distinguish between these two cases. It only talks about input-output behavior, without making any predictions about what’s inside the gearbox (other than that the gearbox must be consistent with the input/output behavior).
That’s the key feature of gears-level models: they make falsifiable predictions about the internals of a system, separate from the externally-visible behavior. If a model could correctly predict all of a system’s externally-visible behavior, but still be falsified by looking inside the box, then that’s a gears-level model. Conversely, we cannot fully learn gears-level models by looking only at externally-visible input-output behavior - external behavior cannot, for example, distinguish between the 3- and 5-gear models above. A model which can be fully learned from system behavior, without any side information, is not a full gears-level model.
Why would this be useful, if what we really care about is the externally-visible behavior? Several reasons:
- First and foremost, if we are able to actually look inside the box, then that provides a huge amount of information about the behavior. If we can see the physical gears, then we can immediately make highly confident predictions about system behavior.
- More generally, any information about the internals of the system provide a “side channel” for testing gears-level models. If data about externally-visible behavior is limited, then the ability to leverage data about system internals can be valuable.
- It may be that all of our input data is only from within a certain range - i.e. we never tried cranking the box faster than a human could crank. If someone comes along and attaches a motor to the crank, then that’s going to generate input way outside the range of what our input/output model has ever seen - but if we know what the gears look like, then that won’t be a problem. In other words, knowing what the system internals look like lets us deal with distribution shifts.
- Finally, if someone changes something about the system, then a model trained only on input/output data will fail completely. For instance, maybe there’s a switch on top of the gearbox which disconnects the gears, and nobody has ever thrown it before. If we know what the inside of the box looks like, then that’s not a problem - we can look at what the switch does.
All that said, if we have abundant data and aren’t worried about distribution shifts or system changes, non-gears models can still give us great predictive power. Solomonoff induction is the idealized theoretical example: it gives asymptotically optimal predictions based on input-output behavior, without any visibility into the system internals.
Application: Macroeconomic Models
One particularly well-known example of these ideas in action is the Lucas Critique, a famous 1976 paper by Bob Lucas critiquing the use of simple statistical models for evaluation of economic policy decisions. Lucas’ paper gives several broad examples, but arguably the most remembered example is policy decisions based on the Phillips curve.
The Phillips curve is an empirical relationship between unemployment and inflation. Phillips examined almost a century of economic data, and showed a consistent negative correlation: when inflation was high, unemployment was low, and vice-versa. In other words, prices and wages rise faster at the peak of the business cycle (when unemployment is low) than at the trough (when unemployment is high).
The obvious mistake one might make, based on the Phillips curve, is to think that perpetual low unemployment can be achieved simply by creating perpetual inflation (e.g. by printing money). Lucas opens his critique by eviscerating this very idea:
The inference that permanent inflation will therefore induce a permanent economic high is no doubt [...] ancient, yet it is only recently that this notion has undergone the mysterious transformation from obvious fallacy to cornerstone of the theory of economic policy.
Bear in mind that this was written in the mid-1970’s - the era of “stagflation”, when both inflation and unemployment were high for several years. Stagflation was an empirical violation of the Phillips curve - the historical behavior of the system broke down when central banks changed their policies to pursue more inflation, and people changed their behavior to account for faster expected inflation in the future.
In short: a statistical model with no gears in it completely fell apart when one part of the system (the central bank) changed its behavior.
On the other hand, before stagflation was under way, multiple theorists (notably Edmund Phelps and Milton Friedman, via very different approaches) published simple gears-level models of the Phillips curve which predicted that it would break down if currencies were predictably devalued - i.e. if people expected central banks to print more money. The key “gears” in these models were individual agents - the macroeconomic behavior (unemployment-inflation relationship) was explained in terms of the expectations and decisions of all the individual people.
This led to a paradigm shift in macroeconomics, beginning the era of “microfoundations”: macroeconomic models derivable from microeconomic models of the expectations and behavior of individual agents - in other words, gears-level models of the economy.
Gears from Behavior?
In general, we cannot fully learn gears-level models by looking only at externally-visible input-output behavior. Our hypothetical 3- or 5-gear boxes are a case in point.
However, some kinds of models can at least deduce something about gears-level structure by looking at externally-visible behavior.
For example: given a gearbox with a crank and wheel, it’s entirely possible that the rotation of the wheel has hysteresis, a.k.a. memory - it depends not only on the crank’s rotation now, but also the crank’s rotation earlier. This would be the case if, for instance, the box contains a flywheel. If we look at the data and see that the wheel’s rotation has no dependence on the crank’s rotation at earlier times (after accounting for the crank’s current rotation), then we can conclude that the box probably does not contain any flywheels or other hysteretic components (or if it does, they’re small or decoupled from the wheel).
More generally, these sort of conditional independence relationships fall under the umbrella of probabilistic causal models [? · GW]. By testing different causal models on externally-visible data, we can back out information about the internal cause-and-effect structure of the system. If we see that only the crank’s current rotation matters to the wheel, then that rules out internal components with memory.
Causal models are the largest class of statistical models I know of which yield information about internal gears. However, they’re not the only way to build gears-level models from behavior. If we have strong prior information, we can often use behavioral data to directly compare gears-level hypotheses.
Application: Wolf’s Dice
Around the mid-19th century, Swiss astronomer Rudolf Wolf rolled a pair of dice 20000 times, recording each outcome. The main result was that the dice were definitely not perfectly fair - there were small but statistically significant biases.
Now, we could easily look at Wolf’s data and use it to estimate the frequency with which each face of each die is rolled. But that’s not a gears-level model; it doesn’t say anything about the physical die.
In order to back out gears-level information from the data, we need to leverage our prior knowledge about dice and die-making. Jaynes did exactly this in a 1979 paper; the key pieces of prior information are:
- We know dice are roughly cube-shaped, and any difference in face frequencies should stem from asymmetry of the physical die. We know 3 is opposite 4, 2 is opposite 5, and 1 is opposite 6.
- We know dice have little pips showing the numbers on each face; different faces have different numbers of pips, which we’d expect to introduce a slight asymmetry.
- Imagining how the dice might have been manufactured, Jaynes guesses that the final cut would have been more difficult to make perfectly even than the earlier cuts - leaving one axis slightly shorter/longer than the other two.
Based on those asymmetries, we’d guess:
- One of the three face pairs (3, 4), (2, 5), (1, 6) has significantly different frequency from the others, corresponding to the last axis cut.
- The faces with fewer pips (3, 2, and especially 1) have slightly lower frequency than those with more pips (4, 5, and especially 6), since more pips means slightly less mass near that face.
- Other than that, the frequencies should be pretty even.
This is basically a guess-and-check process: we guess what asymmetry might be present based on our prior knowledge, consider how that would change the behavior, then we use the data to check the model.
Jaynes tests out these models, and finds that (1) the white die’s 3-4 axis is slightly shorter than the other two, and (2) the pips indeed shift the center of mass slightly away from the center of the die. These two asymmetries together explain all of the bias seen in the data, so the die should be quite symmetric otherwise. I analyze the same problem in this post [LW · GW] (using slightly different methods from Jaynes) and reproduce the same result.
Because this is a gears-level model, we could in principle check the result using a “side channel”: if we could track down the dice Wolf used, then we could take out our calipers and measure the lengths of the 3-4, 2-5, and 1-6 axes. Our prediction is that the 2-5 and 1-6 axes would be close, but the 3-4 axis would be significantly shorter. Note that we still don’t have a full gears-level model - we don’t predict how much shorter the 3-4 axis is. We don’t have a way to back out all the dimensions of the die. But we certainly expect the difference between the 3-4 length and the 2-5 length to be much larger than the difference between the 2-5 length and the 1-6 length. Our model yields some information about gears-level structure.
Takeaway
Statistics, machine learning, and adjacent fields tend to have a myopic focus on predicting future data.
Gears-level models cannot be fully learned by looking at externally-visible behavior data. That makes it hard to prove theorems about convergence of statistical methods, or write tests for machine learning algorithms, when the goal is to learn about a system’s internal gears. So, to a large extent, these fields have ignored gears-level learning and focused on predicting future data. Gears have snuck in only to the extent that they’re useful for predicting externally-visible behavior.
But sooner or later, any field dominated by a gears-less worldview will have its Lucas Critique.
It is possible to leverage probability to test gears-level models, and to back out at least some information about a system’s internal structure. It’s not easy. We need to restrict ourselves to certain classes of models (i.e. causal models) and/or leverage lots of prior knowledge (e.g. about dice). It looks less like black-box statistical/ML models, and more like science: think about what the physical system might look like, figure out how the data would differ between different possible physical systems, and then go test it. The main goal is not to predict future data, but to compare models.
That’s the kind of approach we need to build models which won’t fall apart every time central banks change their policies.
14 comments
Comments sorted by top scores.
comment by johnswentworth · 2020-12-26T16:24:26.291Z · LW(p) · GW(p)
What to Take Away From The Post
Gears-level models are the opposite of black-box models.
I originally wrote "Gears vs Behavior" after I told someone (who was already familiar with the phrase "gears-level model") that their model didn't have any gears in it. I had expected this to be immediately obvious and self-explanatory, but it wasn't; they weren't sure what properties a "gearsy" model would have which theirs didn't. They agreed that their model was fairly black-box-y, but couldn't a black-box model be gearsy, in some respects?
This post says: black box models are the opposite of gearsy models. The various interesting/useful properties of gearsy models follow from the fact that they're not black boxes.
One important corollary to this (from a related comment [LW(p) · GW(p)]): gears/no gears is a binary distinction, not a sliding scale. There's a qualitative difference between a pure black-box model which does not say anything at all about a system's internals, versus a model with at least some internal structure. This has practical consequences: as soon as a model has some internal structure, the model is a capital investment. As soon as we divide a single gearbox into two sub-gearboxes, we need an investment to verify that the division is correct (i.e. there's no hidden crosstalk), but then we can use the division to predict how e.g. one sub-gearbox behaves when the other is hit with a hammer (even if we never saw data on such a thing before).
We can still add more gears, distinguish between coarser or finer-grained gears, but it's that first jump from black-box to not-black-box which gives a model its first gears.
How Does "Gears vs Behavior" Relate To "Gears in Understanding [LW · GW]"?
To my eye, "Gears in Understanding" was written to point to the concept of gears-level models, and attach a name to it. It did that job well. But it didn't really give a "definition" of a gears-level model. It didn't say what the key properties are which make a model "gears-level", or when/why we should care about those particular properties. It gave some heuristics, but didn't say why those heuristics all point toward the same thing, or what that thing is, or where to draw the boundary around the concept so as to cut reality at the joints [LW · GW].
Thus, problems like the one above: while many people intuitively understood the concept (i.e. knew what cluster in concept-space "gearsiness" pointed to), it wasn't quite clear where the boundaries were or why it mattered.
Gears vs Behavior presents something closer to a definition: the defining property of gears-level models is that they're not black boxes. They have internal structure, and that structure itself makes predictions about the world. Because gears-level models have predictive internal structure:
- they can make predictions about side-channel data or out-of-distribution behavior
- we can guess the value of one variable given the rest
- if the model turns out to be wrong, that tells us additional things about the world
- etc
The heuristics from "Gears in Understanding" apply because gears-level models aren't just black boxes.
How Does "Gears vs Behavior" Relate to Other Posts On Gears-Level Modelling?
"Gears vs Behavior" is most closely partnered with "Gears-Level Models Are Capital Investments [LW · GW]". "Gears vs Behavior" provides a rough definition of gears-level models; it draws a boundary around the concept. "Gears-Level Models Are Capital Investments" explains why gears-level models are useful - and when they aren't. That, in turn, tells us why this particular definition was useful in the first place.
At this point, however, I think a better way to "define" gears-level models is the dimensionality and conditional independence framework, laid out in "Anatomy of a Gear [LW · GW]" and "Everyday Lessons From High-DImensional Optimization [LW · GW]". I still see Gears vs Behavior as a basically-correct "dual" to those frames: "Gears vs Behavior" focuses on the space of queries that models address, rather than the structures of the models themselves - it is a black-box definition of gears-level models. Dimensionality and conditional independence, on the other hand, give a gears-level model of gears-level models.
Here's a visual of how the four posts relate:
| "Gearsiness = opposite of black-box" frame | "Gears = low-dimensional summaries" frame | |
| What is a gears-level model? | Gears vs Behavior [LW · GW] | Anatomy of a Gear [LW · GW] |
| Why does it matter? | Gears-Level Models are Capital Investments [LW · GW] | Everyday Lessons From High-Dimensional Optimization [LW · GW] |
Also worth noting: the conditional independence framework for understanding gears-level models is basically identical to abstraction as information at a distance [LW · GW]. If you want a technical formulation of the ideas, then that's the place to go.
comment by Zvi · 2020-12-23T19:32:08.596Z · LW(p) · GW(p)
After reading this, I went back and also re-read Gears in Understanding (https://www.lesswrong.com/posts/B7P97C27rvHPz3s9B/gears-in-understanding) which this is clearly working from. The key question to me was, is this a better explanation for some class of people? If so, it's quite valuable, since gears are a vital concept. If not, then it has to introduce something new in a way that I don't see here, or it's not worth including.
It's not easy to put myself in the mind of someone who doesn't know about gears.
I think the original Gears in Understanding gives a better understanding of the central points, if you grok both posts fully, and gives better ways to get a sense of a given model's gear-ness level. What this post does better is Be Simpler, which can be important, and to provide a simpler motivation for What Happens Without Gears. In particular, this simplified version seems like it would be easier to get someone up to speed using, to the point where they can go 'wait a minute that doesn't have any gears' usefully.
My other worry this brought up is that this reflects a general trend, of moving towards things that stand better alone and are simpler to grok and easier to appreciate, at the cost of richness of detail and grounding in related concepts and such - that years ago we'd do more of the thing Gears in Understanding did, and now we do Gears vs. Behavior thing more, and gears are important enough that I don't mind doing both (even if only to have a backup) but that there's a slippery slope where the second thing drives out the first thing and you're left pretty sad after a while.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-12-23T20:11:13.783Z · LW(p) · GW(p)
Huh. This was very different from the role I originally imagined for this post.
My reading of Gears in Understanding was that it was trying to gesture at a concept, and give that concept a handle, without really explaining or "defining" the concept. It gave some heuristics for recognizing gears-level models in the wild (e.g. "could the model be correct but a given variable be different?" or "if the model were falsified, what else could we infer from that?"), but it never really said why those heuristics should all correlate with each other, or why/how they're all pointing to the same thing, or why that thing would be useful/interesting. It's just trying to point to a particular cluster in concept-space, without trying to explain why there's a cluster there, or precisely delineate the cluster.
Gears vs Behavior is trying to (at least partially) explain why there's a cluster there and draw a box around it. It's presenting a frame in which the key, defining property which separates gears-level models from purely behavioral/black box models is that gearsy models can make predictions and leverage data from side-channels and out-of-distribution (which is itself a pseudo-side-channel). Heuristics like "if the model were falsified, what else could we infer from that?" follow from the ability to leverage side-channels. I claim that this is pointing to the same thing Val was trying to point to, and can be usefully viewed as the main defining property of gearsy models (as opposed to blackboxes).
This post comes across as simpler because it's focused on the key defining property of the cluster, rather than trying to gesture at the concept from a bunch of different directions without really figuring out what the "defining" feature is.
At this point, I actually think a better way to "define" gears-level models is the dimensionality [LW · GW] and conditional independence [LW · GW] framework, although I still see Gears vs Behavior as a basically-correct "dual" to those frames, focusing on the space of queries that models address, rather than the structures of the models themselves. (In some sense, dimensionality and conditional independence give a gears-level model of gears-level models, while Gears vs Behavior gives a more blackboxy definition of gears-level models.)
comment by Alexander (alexander-1) · 2022-03-04T02:06:18.912Z · LW(p) · GW(p)
This post has brilliantly articulated a crucial idea. Thank you!
Microfoundations for macroeconomics is a step in the right direction towards a gears-level understanding of economics. Still, our current understanding of cognition and human nature is primarily based on externally-visible behaviour and not on gears. Do you think we are progressing in the right direction within microeconomics towards more gears-level agent models?
I read the arguments against microfoundations, and some opponents point to "feedback loops". They claim that the arrow of causation is bidirectional between agent behaviour and macroeconomics. For example, agents anticipating an interest rate increase change how they behave. Curious to know what you think about this line of argumentation.
Causation goes from the lower levels to the higher levels. E.g. we cannot choose to change the laws of physics, but the laws of physics entirely cause everything we experience. Are these "feedback loops" an illusion created by our confusion and lack of gears-level causal understanding, or are they actual gears?
comment by lincolnquirk · 2020-12-04T20:53:09.144Z · LW(p) · GW(p)
Looking back, this seems to have been quite influential on my communication in the past year. I find myself summoning a mental image of the first diagram very frequently, and using the phrase "gears-level understanding" much more often. Nominated.
comment by Viliam · 2019-09-19T18:59:09.509Z · LW(p) · GW(p)
The faces with fewer pips (3, 2, and especially 1) have slightly lower frequency than those with more pips (4, 5, and especially 6), since more pips means slightly less mass near that face.
I have seen dice that try to partially fix this problem by having the 1 pip greater than the rest of them. Almost twice as big, which ^3 makes it balanced against the 6 pips on the opposite side.
comment by Ben Pace (Benito) · 2020-12-15T06:22:11.366Z · LW(p) · GW(p)
This is just such a central idea we use on LessWrong, explained well and with great images.
(If it is published in the book, it should be included alongside Val's original post on the subject.)
comment by Elizabeth (pktechgirl) · 2020-01-08T07:03:13.487Z · LW(p) · GW(p)
I didn't read this when it came out because I thought I already understood the concept, but recently I wanted to be able to explain it to others and found it very helpful.
comment by Gordon Seidoh Worley (gworley) · 2019-10-11T01:44:44.288Z · LW(p) · GW(p)
Great and simple explanation of an important topic. I just hope I can remember to link this post often so people can find it when they start to question whether or not they really need to know about the gears of something.
comment by Дмитрий Зеленский (dmitrii-zelenskii-1) · 2023-11-02T08:44:23.536Z · LW(p) · GW(p)
Huh. In linguistics that's known as "functional model" vs. "structural model" (Mel'čuk's terminology): whether you treat linguistic ability as a black box or try model how it works in the brain (Mel'čuk opts for the former as a response to Chomsky's precommitment to the latter). This neatly explains why structural models are preferable.
comment by Дмитрий Зеленский (dmitrii-zelenskii) · 2020-04-25T02:07:01.719Z · LW(p) · GW(p)
Sounds like a (much better than original) explanation of Igor Mel'čuk's "structural model" vs. "functional model". An old topic in linguistics and, arguably, other cognitive sciences.
comment by [deleted] · 2019-10-11T02:43:30.790Z · LW(p) · GW(p)
Good post.
I agree with your point regarding ML's historical focus on blackbox prediction. That said, there has been some intriguing recent work (example 1, example 2), which I've only just started looking at, on trying to learn causal models.
I bring this up because I think the question of how causal model learning happens and how learning systems can do it may potentially be relevant to the work you've been writing about. It's primarily of interest to me for different reasons, related to applying ML systems to scientific discovery. In particular, in domains where coming up with causal hypotheses is harder at scale.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-10-11T03:04:05.648Z · LW(p) · GW(p)
Nice links. I actually stopped following deep learning for a few years, and very recently started paying attention again as the new generation of probabilistic programming languages came along (I'm particularly impressed with pyro). Those tools are a major step forward for learning causal structure.
I'd also recommend this recent paper by Friston (the predictive processing guy). I might write up a review of it soonish; it's a really nice piece of math/algorithm for learning causal structure, again using the same ML tools.
comment by rain8dome9 · 2024-11-14T00:16:35.223Z · LW(p) · GW(p)
I thinks its worth mentioning that there are two levels of black box models too. ML can memorize the expected value at each set of variables (at 1 rmp crank wheel rotates at 2 rpm) or it can 'generalize' and, for this example, tell us that the wheel rotates at 2x speed of crank. To some extent 'ML generalization' provides good 'out of distribution' predictions.