Gears-Level Models are Capital Investments
post by johnswentworth · 2019-11-22T22:41:52.943Z · LW · GW · 29 commentsContents
Mazes Marketing Wheel with Weights Metis More Examples Takeaway None 30 comments
Mazes
The usual method to solve a maze is some variant of babble-and-prune [LW · GW]: try a path, if it seems to get closer to the exit then keep going, if it hits a dead end then go back and try another path. It's a black-box method that works reasonably well on most mazes.
However, there are other methods [LW · GW]. For instance, you could start by looking for a chain of walls with only one opening, like this:
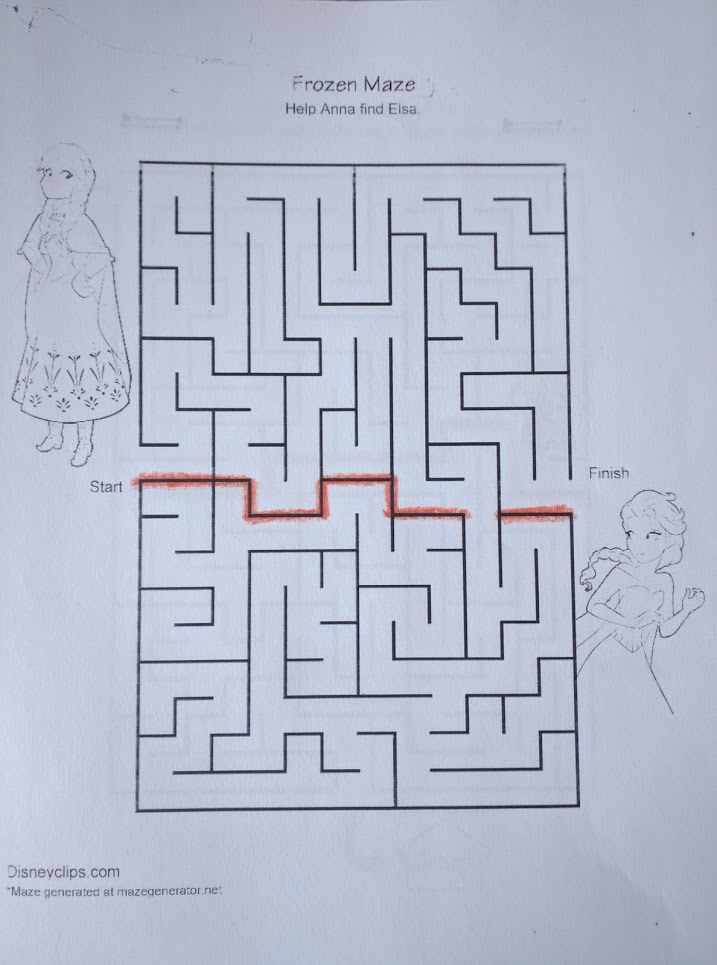
This chain of walls is a gears-level insight [LW · GW] into the maze - a piece of the internal structure which lets us better understand “how the maze works” on a low level. It’s not specific to any particular path, or to any particular start/end points - it’s a property of the maze itself. Every shortest path between two points in the maze either starts and ends on the same side of that line, or passes through the gap.
If we only need to solve the maze once, then looking for a chain of walls is not very useful - it could easily take as long as solving the maze! But if we need to solve the same maze more than once, with different start and end points… then we can spend the time finding that chain of walls just once, and re-use our knowledge over and over again. It’s a capital investment: we do some extra work up-front, and it pays out in lower costs every time we look for a path through the maze in the future.
This is a general feature of gears-level models: figuring out a system’s gears takes extra work up-front, but yields dividends forever. The alternative, typically, is a black-box strategy: use a method which works without needing to understand the internals of the system. The black-box approach is cheaper for one-off tasks, but usually doesn’t yield any insights which will generalize to new tasks using the same system - it’s context-dependent.
Marketing
Suppose we work with the marketing team at an online car loan refinance company, and we're tasked with optimizing the company's marketing to maximize the number of car loans the company refinances. Here's two different approaches we might take:
- We a/b test hundreds of different ad spend strategies, marketing copy permutations, banner images, landing page layouts, etc. Ideally, we find a particular combination works especially well.
- We obtain some anonymized data from a credit agency on people with car loans. Ideally, we learn something about the market - e.g. maybe subprime borrowers usually either declare bankruptcy or dramatically increase their credit score within two years of taking a loan.
The first strategy is black-box: we don't need to know anything about who our potential customers are, what they want, the psychology of clicking on ads, etc. We can treat our marketing pipeline as a black box and fiddle with its inputs to see what works. The second strategy is gears-level, the exact opposite of black-box: the whole point is to learn who our potential customers are, breaking open the black box and looking at the internal gears.
These aren't mutually exclusive, and they have different relative advantages. Some upsides of black-box:
- Black-box is usually cheaper and easier, since the code involved is pretty standard and we don't need to track down external data. Gears-level strategies require more custom work and finding particular data.
- Black-box yields direct benefits when it works, whereas gears-level requires an extra step to translate whatever insights we find into actual improvements.
On the other hand:
- Gears-level insights can highlight ideas we wouldn't even have thought to try, whereas black-box just tests the things we think to test.
- When some tests are expensive (e.g. integrating with a new ad channel), gears-level knowledge can tell us which tests are most likely to be worthwhile.
- Black-box optimization is subject to Goodhart [LW · GW], while gears-level insights usually are not (at least in-and-of themselves)
- Gears-level insights are less likely subject to distribution shift. For instance, if we change ad channels, then the distribution of people seeing our ads will shift. Different ad copy will perform well, and we'd need to restart our black-box a/b testing, whereas general insights about subprime borrowers are more likely to remain valid.
- Conversely, black-box optimizations depreciate over time. Audiences and ad channels evolve, and ads need to change with them, requiring constant re-optimization to check that old choices are still optimal.
- By extension, gears-level insights tend to be permanent and broadly applicable, and have the potential for compound returns, whereas black-box improvements are much more context-specific and likely to shift with time.
In short, the black-box approach is easier, cheaper, and more directly useful - but its benefits are ephemeral and it can't find unknown unknowns. Gears-level understanding is more difficult, expensive, and risky, but it offers permanent, generalizable insights and can suggest new questions we wouldn't have thought to ask.
With this in mind, consider the world through the eyes of an ancient lich or thousand-year-old vampire [LW · GW]. It's a worldview in which ephemeral gains are irrelevant. All that matters is permanent, generalizable knowledge - everything else will fade in time, and usually not even very much time. In this worldview, gears-level understanding is everything.
On the other end of the spectrum, consider the world through the eyes of a startup with six months of runway which needs to show rapid growth in order to close another round of funding. For them, black-box optimization is everything - they want fast, cheap results which don’t need to last forever.
Wheel with Weights
There’s a neat experiment [LW · GW] where people are given a wheel with some weights on it, each of which can be shifted closer to/further from the center. Groups of subjects have to cooperatively find settings for the weights which minimize the time for the wheel to roll down a ramp.

Given the opportunity to test things out, subjects would often iterate their way to optimal settings - but they didn’t iterate their way to correct theories. When asked to predict how hypothetical settings would perform, subjects’ predictions didn’t improve much as they iterated. This is black-box optimization: optimization was achieved, but insight into the system was not.
If the problem had changed significantly - e.g. changing weight ratios/angles, ramp length/angle, etc - the optimal settings could easily change enough that subjects would need to re-optimize from scratch. On the other hand, the system is simple enough that just doing all the math is tractable - and that math would remain essentially the same if weights, angles, and lengths changed. A gears-level understanding is possible, and would reduce the cost of optimizing for new system parameters. It’s a capital investment: it only makes sense to make the investment in gears-level understanding if it will pay off on many different future problems.
In the experiment, subjects were under no pressure to achieve gears-level understanding - they only needed to optimize for one set of parameters. I’d predict that people would be more likely to gain understanding if they needed to find optimal weight-settings quickly for many different wheel/ramp parameters. (A close analogy is evolution of modularity [LW · GW]: changing objectives incentivize learning general structure.)
Metis
Let’s bring in the manioc example [LW · GW]:
There's this plant, manioc, that grows easily in some places and has a lot of calories in it, so it was a staple for some indigenous South Americans since before the Europeans showed up. Traditional handling of the manioc involved some elaborate time-consuming steps that had no apparent purpose, so when the Portuguese introduced it to Africa, they didn't bother with those steps - just, grow it, cook it, eat it.
The problem is that manioc's got cyanide in it, so if you eat too much too often over a lifetime, you get sick, in a way that's not easily traceable to the plant. Somehow, over probably hundreds of years, the people living in manioc's original range figured out a way to leach out the poison, without understanding the underlying chemistry - so if you asked them why they did it that way, they wouldn't necessarily have a good answer.
The techniques for processing manioc are a stock [LW · GW] example [LW · GW] of metis: traditional knowledge accumulated over generations, which doesn’t seem like it has any basis in reason or any reason to be useful. It’s black-box knowledge, where the black-box optimizer is cultural transmission and evolution. Manioc is a cautionary tale about the dangers of throwing away or ignoring black-box knowledge just because it doesn’t contain any gears.
In this case, building a gears-level model was very expensive - people had to get sick on a large scale in order to figure out that any knowledge was missing at all, and even after that it presumably took a while for scientists to come along and link the problem to cyanide content. On the other hand, now that we have that gears-level model in hand, we can quickly and easily test new cooking methods to see whether they eliminate the cyanide - our gears-level model provides generalizable insights. We can even check whether any particular dish of manioc is safe before eating it, or breed new manioc strains which contain less cyanide. Metic knowledge would have no way to do any of that - it doesn’t generalize.
More Examples
(Note: in each of these examples, there are many other ways to formulate a black-box/gears-level approach. I just provide one possible approach for each.)
Pharma
- Black box approach: run a high-throughput assay to test the effect thousands of chemicals against low-level markers of some disease.
- Gears-level approach: comb the literature for factors related to some disease. Run experiments holding various subsets of the factors constant while varying others, to figure out which factors mediate the effect of which others, and ultimately build up a causal graph of their interactions.
The black-box approach is a lot cheaper and faster, but it’s subject to Goodhart problems, won’t suggest compounds that nobody thought to test, and won’t provide any knowledge which generalizes to related diseases. If none of the chemicals tested are effective, then the black-box approach leaves no foundation to build on. The gears-level approach is much slower and more expensive, but eventually yields reliable, generalizable knowledge.
Financial Trading
- Black box approach: build a very thorough backtester, then try out every algorithm or indicator we can think of to see if any of them achieve statistically significant improvement over market performance.
- Gears-level approach: research the trading algorithms and indicators actually used by others, then simulate markets with traders using those algorithms/indicators. Compare results against real price behavior and whatever side data can be found in order to identify missing pieces.
The gears-level approach is far more work, and likely won’t produce anything profitable until very late in development. On the other hand, the gears-level approach will likely generalize far better to new markets, new market conditions, etc.
Data Science
- Black box approach: train a neural network, random forest, support vector machine, or whatever generic black-box learning algorithm you like.
- Gears-level approach: build a probabilistic graphical model [LW · GW]. Research the subject matter to hypothesize model structure, and statistically compare [LW · GW] different model structures to see which match the data best. Look for side information to confirm that the structure is correct.
The black box approach is subject to Goodhart and often fails to generalize. The gears-level approach is far more work, requiring domain expertise and side data and probably lots of custom code (although the recent surge of probabilistic programming languages helps a lot in that department), but gears-level models ultimately give us human-understandable explanations of how the system actually works. Their internal parameters have physical meaning.
Takeaway
Building gears-level models is expensive - often prohibitively expensive. Black-box approaches are usually much cheaper and faster. But black-box approaches rarely generalize - they’re subject to Goodhart, need to be rebuilt when conditions change, don’t identify unknown unknowns, and are hard to build on top of. Gears-level models, on the other hand, offer permanent, generalizable knowledge which can be applied to many problems in the future, even if conditions shift.
The upfront cost of gears-level knowledge makes it an investment, and the payoff of that investment is the ability to re-use the model many times in the future.
29 comments
Comments sorted by top scores.
comment by SatvikBeri · 2019-11-23T20:57:28.941Z · LW(p) · GW(p)
Black-box approaches often fail to generalize within the domain, but generalize well across domains. Neural Nets may teach you less about medicine than a PGM, but they'll also get you good results in image recognition, transcription, etc.
This can lead to interesting principal-agent problems: an employee benefits more from learning something generalizable across businesses and industries, while employers will generally prefer the best domain-specific solution.
comment by jimrandomh · 2020-12-05T00:42:49.000Z · LW(p) · GW(p)
In general, I think people aren't using finance-style models in daily life enough. When you think of models as capital investments, dirty dishes as debts (not-being-able-to-use-the-sink as debt servicing), skills as assets, and so on, a lot of things click into place.
(Though of course, you have to get the finance-modeling stuff right. For some people, "capital investment" is a floating node or a node with weird political junk stuck to it, so this connection wouldn't help them. Similarly, someone who thinks of debt as sin rather than as a tool that you judge based on discount and interest rates, would be made worse off by applying a debt framing to their chores.)
comment by jimrandomh · 2021-01-13T01:52:15.528Z · LW(p) · GW(p)
There is a joke about programmers, that I picked up long ago, I don't remember where, that says: A good programmer will do hours of work to automate away minutes of drudgery. Some time last month, that joke came into my head, and I thought: yes of course, a programmer should do that, since most of the hours spent automating are building capital, not necessarily in direct drudgery-prevention but in learning how to automate in this domain.
I did not think of this post, when I had that thought. But I also don't think I would've noticed, if that joke had crossed my mind two years ago. This, I think, is what a good concept-crystallization feels like: an application arises, and it simply feels like common sense, as you have forgotten that there was ever a version of you which would not have noticed that.
comment by habryka (habryka4) · 2020-12-14T03:37:06.419Z · LW(p) · GW(p)
This post summarized an argument I had made many times before this post came out, but I really liked the specific handle it put on it and found it easier to communicate afterwards.
comment by Donald Hobson (donald-hobson) · 2019-11-24T16:00:49.254Z · LW(p) · GW(p)
I think that you are seeing a tradeoff by only looking at cases where both tecniques are comparably good. No one makes a calculator by trying random assemblages of transistors and seeing what works. Here the gears level insight is just much easier. When there are multiple approaches, and you rule out the cases where one is obviously much better, you see a trade-off in the remaining cases. Expect there to be some cases where one technique is just worse.
Replies from: johnswentworth, SatvikBeri↑ comment by johnswentworth · 2019-11-24T18:21:45.728Z · LW(p) · GW(p)
I agree with the principle here, but I think the two are competitive in practice far more often than one would naively expect. For instance, people do use black-box optimizers for designing arithmetic logic units (ALUs), the core component of a calculator. Indeed, circuit optimizers are a core tool for digital hardware design these days (see e.g. espresso for a relatively simple one) - and of course there's a whole academic subfield devoted to the topic.
Competitiveness of the two methods comes from hybrid approaches. If evolution can solve a problem, then we can study the evolved solution to come up with a competitive gears-level model. If a gears-level approach can solve a problem, then we can initialize an iterative optimizer with the gears-level solution and let it run (which is what circuit designers do).
↑ comment by SatvikBeri · 2019-11-24T19:35:14.662Z · LW(p) · GW(p)
I think it is true that gears-level models are systematically undervalued, and that part of the reason is because of the longer payoff curve.
A simple example is debugging code: a gears-level approach is to try and understand what the code is doing and why it doesn't do what you want, a black-box approach is to try changing things somewhat randomly. Most programmers I know will agree that the gears-level approach is almost always better, but that they at least sometimes end up doing the black-box approach when tired/frustrated/stuck.
And in companies that focus too much on short-term results (most of them, IMO) will push programmers to spend far too much time on black-box debugging than is optimal.
Perhaps part of the reason why the choice appears to typically be obvious is that gears methods are underestimated.
Replies from: panashe-fundira↑ comment by Panashe Fundira (panashe-fundira) · 2019-12-11T20:37:08.301Z · LW(p) · GW(p)
A simple example is debugging code: a gears-level approach is to try and understand what the code is doing and why it doesn't do what you want, a black-box approach is to try changing things somewhat randomly.
To drill in further, a great way to build a model of why a defect arises is using the scientific method. You generate some hypothesis about the behavior of your program (if X is true, then Y) and then test your hypothesis. If the results of your test invalidate the hypothesis, you've learned something about your code and where not to look. If your hypothesis is confirmed, you may be able to resolve your issue, or at least refine your hypothesis in the right direction.
comment by Matt Goldenberg (mr-hire) · 2019-11-25T21:37:41.694Z · LW(p) · GW(p)
To add on to Satvik's comment about black boxes approaches - I often think black-box heuristic models are themselves capital investments.
For instance, knowing a few of the most basic games in game theory (Prisoners Dillema, Staghunt, BoS, etc.) is not actually a very good gears-level model of how humans are making decisions in any given situation. However, using it as one black box model (among many that can help you predict the situation) is much more generalizable then trying to figure out the specifics of any given situation - understanding game theory here is a good capital investment in understanding people, even though its' not a gears level model of any specific situation).
I think which one you use depends on your strategy for success - One path to success is specialization, and having a very good gears level model of a single domain. Another path to success is being able to combine many black box models to work cross domain - perhaps the best strategy is a combination of a few gears level models, and many black box models, to be the Pareto Best in the World [LW · GW].
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-25T23:08:17.862Z · LW(p) · GW(p)
I would characterize game theory, as applied to human interactions, as a gearsy model. It's not a very high-fidelity model - a good analogy would be "spherical cow in a vacuum" or "sled on a perfectly smooth frictionless incline" in physics. And the components in game-theory models - the agents - are themselves black boxes which are really resistant to being broken open. But a model with multiple agents in it is not a single monolithic black box, therefore it's a gears-level model.
This is similar to my response to Kaj [LW(p) · GW(p)] above: there's a qualitative change in going from a model which treats the entire system as a single monolithic black box, to a model which contains any internal structure at all. As soon as we have any internal structure, the model will no longer apply to any random system in the wild - it will only apply to systems which share the relevant gears. In the case of game theory, our game-theoretic models are only relevant to systems with interacting agenty things; it won't help us to e.g. design a calculator or find a short path through a maze. Those agenty things are the gears.
As in any gears-level model, the gears themselves can be black boxes, and that's definitely the case for agents in game theory.
Replies from: mr-hire↑ comment by Matt Goldenberg (mr-hire) · 2019-11-25T23:30:24.535Z · LW(p) · GW(p)
I think that talking about how "Gearsy" a model is makes a lot of sense. The deeper you go into defining subsystems, the less gears the model has.
I think the type of "combined model" I'm talking about here feels super blackboxy. As soon as I say "I'm going to take a game theoretic model, a loyalty based model, and an outside view "what happened previously" model, and average them (without any idea how they fit together), it feels more blackboxy to me even though the gears of the black box are more gearsy.
The benefit of this type of model is of course that you can develop more gears that show how the models relate to each other over time.
Edit:
I'm curious if you agree with the conception of gears being capital investments towards specific expertise, and black boxes being capital investments towards generalizable advantage.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-25T23:58:36.569Z · LW(p) · GW(p)
I definitely agree that combining models - especially by averaging them in some way - is very blackboxy. The individual models being averaged can each be gears-level models, though.
Circling back to my main definition: it's the top-level division which makes a model gearsy/non-gearsy. If the top-level is averaging a bunch of stuff, then that's a black-box model, even if it's using some gears-level models internally. If the top-level division contains gears, then that's a gears-level model, even if the gears themselves are black boxes. (Alternatively, we could say that "gears" vs "black box" is a characterization of each level/component of the model, rather than a characterization of the model as a whole.)
I'm curious if you agree with the conception of gears being capital investments towards specific expertise, and black boxes being capital investments towards generalizable advantage.
I don't think black boxes are capital investments towards generalizable advantage. Black box methods are generalizable, in the sense that they work on basically any system. But individual black-box models are not generalizable - a black-box method needs to build a new model whenever the system changes. That's why black-box methods don't involve an investment - when a black-box method encounters a new problem/system, it starts from scratch. Something like "learn how to do A/B tests" is an investment in learning how to apply a black-box method, but the A/B tests themselves are not an investment (or to the extent they are, they're an investment which depreciates very quickly) - they won't pay off over a very long time horizon.
So learning how to apply a black-box method, in general, is a capital investment towards generalizable advantage. But actually using a black-box method - i.e. producing a black-box model - is usually not a capital investment.
(BTW, learning how to produce gears-level models is a capital investment which makes it cheaper to produce future capital investments.)
comment by Eli Tyre (elityre) · 2019-11-23T20:01:30.330Z · LW(p) · GW(p)
This is a great post. I've already been thinking about the semi-tradeoff / semi-false dichotomy between empiricism and theorizing. But I feel like this post crystallized some new thoughts in this area.
For one thing, the point that I want to get to a theory when I expect the domain to change substantially (but I can more safely use a un-grounded understanding that I iteratively gradient descent-ed to, when the domain is stable) is important, and I hadn't articulated it before. (Of course, I basically always want to get a gearsy model out of my black box model, because the gearsy model is likely to have insights that generalize in some way, but sometimes it isn't worth the effort.)
I also feel like I got some more clarity about why I care about learning math.
Tho
Replies from: Pattern
comment by John_Maxwell (John_Maxwell_IV) · 2019-11-24T05:15:40.919Z · LW(p) · GW(p)
Gears-level insights can highlight ideas we wouldn't even have thought to try, whereas black-box just tests the things we think to test... it can't find unknown unknowns
It seems to me that black-box methods can also highlight things we wouldn't have thought to try, e.g. genetic algorithms can be pretty creative.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-24T06:15:36.075Z · LW(p) · GW(p)
I'll clarify what I mean a bit.
We have some black box with a bunch of dials on the outside. A black-box optimizer is one which fiddles the dials to make the box perform well, without any knowledge of the internals of the box. If the dials themselves are sufficiently expressive, it may find creative and interesting solutions - as in the genetic algorithm example you mention. But it cannot find dials which we had not noticed before. A black-box method can explore previously-unexplored areas of the design space, but it cannot expand our concept of what the "design space" is beyond the space we've told it to search.
A black-box algorithm doesn't think outside the box it's given.
Replies from: John_Maxwell_IV, John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2019-11-24T07:14:02.080Z · LW(p) · GW(p)
I can imagine modeling strategies which feel relatively "gears-level" yet don't make use of prior knowledge or "think outside the box they're given". I think there are a few entangled dimensions here which could be disentangled in principle.
Replies from: Kaj_Sotala, johnswentworth, SatvikBeri↑ comment by Kaj_Sotala · 2019-11-24T12:24:47.099Z · LW(p) · GW(p)
I think that there's a sliding scale between a black-box and a gears-level model; any gears-level model has black box components, and a mostly black-box model may include gears.
E.g. if you experimentally arrive at a physics equation that correctly describes how the wheel-with-weights behaves under a wide variety of parameters, this is more gearsy than just knowing the right settings for one set of parameters. But the deeper laws of physics which generated that equation are still a black box. While you might know how to adjust the weights if the slope changes, you won't know how you should adjust them if fundamental physical constants were to change.
(Setting aside the point that fundamental physics constants changing would break your body [LW · GW] so you couldn't adjust the weights because you would be dead anyway.)
To put it in different terms, in a black box model you take some things as axiomatic. Any kind of reasoning requires you to eventually fall back on axioms that are not justified further, so all models are at least somewhat black boxy. The difference is in whether you settle on axioms that are useful for a narrow set of circumstances, or on ones which allow for broader generalization.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-24T18:10:45.688Z · LW(p) · GW(p)
I think you're pointing to a true and useful thing, but "sliding scale" isn't quite the right way to characterize it. Rather, I'd say that we're always operating at some level(s) of abstraction, and there's always a lowest abstraction level in our model - a ground-level abstraction, in which the pieces are atomic. For a black-box method, the ground-level abstraction just has the one monolithic black box in it.
A gearsy method has more than just one object in its ground-level abstraction. There's some freedom in how deep the abstraction goes - we could say a gear is atomic, or we could go all the way down to atoms - and the objects at the bottom will always be treated as black boxes. But I'd say it's not quite right to think of the model as "partially black-box" just because the bottom-level objects are atomic; it's usually the top-level breakdown that matters. E.g., in the maze example from the post, the top and bottom halves of the maze are still atomic black boxes, but our gearsy insight is still 100% gearsy - it is an insight which will not ever apply to some random black box in the wild.
Gears/no gears is a binary distinction; there's a big qualitative jump between a black-box method which uses no information about internal system structure, and a gearsy model which uses any information about internal structure (even just very simple information). We can add more gears, reduce the black-box components in a gears level model. But as soon as we make the very first jump from one monolithic black box to two atomic gears, we've gone from a black-box method which applies to any random system, to a gears-level investment which will pay out on our particular system and systems related to it.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-31T18:40:48.957Z · LW(p) · GW(p)
I wonder why the gears level model is so important, then, because basically any model of the world which depends on assumptions and isn't a look-up table, could be considered a gears level model, since it doesn't apply to everything anymore, and thus in most applications you want to talk about how gearsy a model is, rather than debating a binary question.
↑ comment by johnswentworth · 2019-11-24T17:53:18.835Z · LW(p) · GW(p)
Can you give 2-3 examples?
Replies from: John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2019-11-24T21:53:43.115Z · LW(p) · GW(p)
Of gears-level models that don't make use of prior knowledge or entangled dimensions?
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-25T01:15:41.301Z · LW(p) · GW(p)
Gears-level models which don't use prior knowledge or offer outside-the-box insights.
Replies from: John_Maxwell_IV↑ comment by John_Maxwell (John_Maxwell_IV) · 2019-11-25T01:44:23.062Z · LW(p) · GW(p)
offer outside-the-box insights
I don't think that's the same as "thinking outside the box you're given". That's about power of extrapolation, which is a separate entangled dimension.
Anyway, suppose I'm thinking of a criterion. Of the integers 1-20, the ones which meet my criterion are 2, 3, 5, 7, 11, 13, 17, 19. I challenge you to write a program that determines whether a number meets my criterion or not. A "black-box" program might check to see if the number is on the list I gave. A "gears-level" program might check to see if the number is divisible by any integer besides itself and 1. The "gears-level" program is "within the box" in the sense that it is a program which returns True or False depending on whether my criterion is supposedly met--the same box the "black-box" program is in. And in principle it doesn't have to be constructed using prior knowledge. Maybe you could find it by brute forcing all short programs and returning the shortest one which matches available data with minimal hardcoded integers, or some other method for searching program space.
Similarly, a being from another dimension could be transported to our dimension, observe some physical objects, try to make predictions about them, and deduce that F=ma. They aren't using prior knowledge since their dimension works differently than ours. And they aren't "thinking outside the box they're given", they're trying to make accurate predictions, just as one could do with a black box model.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-11-25T23:41:17.187Z · LW(p) · GW(p)
Ok, so for the primes examples, I'd say that the gears-level model is using prior information in the form of the universal prior. I'd think of the universal prior as a black-box method for learning gears-level models; it's a magical thing which lets us cross the bridge from one to the other (sometimes [LW · GW]). In general, "black-box methods for finding gears-level models" is one way I'd characterize the core problems of AGI.
One "box" in the primes example is just the integers from 0-20; the gears-level model gives us insight into what happens outside that range, while the black-box model does not.
Similarly for the being from another dimension: they're presumably using a universal prior. And they may not bother thinking outside the box - they may only want to make accurate predictions about whatever questions are in front of them - but F = ma is a model which definitely can be used for all sorts of things in our universe, not just whatever specific physical outcomes the being wants to predict.
But I still don't think I've properly explained what I mean by "outside the box".
For the primes problem, a better example of "outside the box" would be suddenly introducing some other kind of "number", like integer matrices or quadratic integers or something. A divisibility-based model would generalize (assuming you kept using a divisibility-based criterion) - not in the sense that the same program would work, but in the sense that we don't need to restart from scratch when figuring out the pattern. The black-box model, on the other hand, would need to start more-or-less from scratch.
For the being from another dimension, a good example of "outside the box" would be a sudden change in fundamental constants - not so drastic as to break all the approximations, but enough that e.g. energies of chemical reactions all change. In that case, F = ma would probably still hold despite the distribution shift.
So I guess the best summary of what I mean by "outside the box" is something like "counterfactual changes which don't correspond to anything in the design space/data".
↑ comment by SatvikBeri · 2019-11-24T19:40:47.826Z · LW(p) · GW(p)
One key dimension is decomposition – I would say any gears model provides decomposition, but models can have it without gears.
For example, the error in any machine learning model can be broken down into bias + variance, which provides a useful model for debugging. But these don't feel like gears in any meaningful sense, whereas, say, bootstrapping + weak learners feel like gears in understanding Random Forests.
↑ comment by John_Maxwell (John_Maxwell_IV) · 2019-11-24T07:14:21.617Z · LW(p) · GW(p)
comment by Alex K. Chen (parrot) (alex-k-chen) · 2020-11-11T04:11:01.018Z · LW(p) · GW(p)
Do you think that applying black box models can result in "progress"? Say, molecular modeling/docking or climate modeling or whole-cell modeling or certain finite-element models? [climate models kind of work with finite element analysis but most people who run them don't understand all the precise elements used in the finite element analysis or COMSOL]? It always seems that there are many many more people who run the models than there are people who develop the models, and the many people who run the models (some of whom are students) are often not as knowledgeable about the internals as those who develop them - yet they still can produce unexpected leads/insights [or stories - which CAN be deceiving, but which in an optimal world helps others understand the system better even if they aren't super-familiar with the GFD equations of motions that run inside climate models or COMSOL] that might be better than chance.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-11-11T05:28:13.340Z · LW(p) · GW(p)
I would not usually call finite element models black box. It's true that they can be used like mysterious black boxes by particular users, but the gears inside the model do map directly to gears in the physical world, and the people who wrote the code do understand that mapping.
comment by habryka (habryka4) · 2019-12-05T21:06:14.278Z · LW(p) · GW(p)
Promoted to curated: I think this post captured some core ideas in predictions and modeling in a really clear way, and I particularly liked how it used a lot of examples and was just generally very concrete in how it explained things.