Anatomy of a Gear
post by johnswentworth · 2020-11-16T16:34:44.279Z · LW · GW · 12 commentsContents
A Physical Gear Rigid Body Dynamics Chemical Equations Electronic Circuits API Functions Companies Organs Takeaway None 12 comments
Thankyou to Sisi Cheng [LW · GW] (of the Working as Intended comic) for the excellent drawings.
When modelling a physical gearbox, why do we chunk the system into gears? We’re essentially treating each gear as a black box, a discrete component without internal structure of its own, interesting mainly for its interactions with other components. Why not zoom out, and model the entire gearbox as a black box? Why not zoom in, and model the individual chunks of metal which comprise each gear, or even each individual atom?
It seems like gears are a natural choice of abstraction for a gearbox. But why that choice? In general, what makes a good “gear” - a good lowest-level component in a “gears-level” model [LW · GW]?
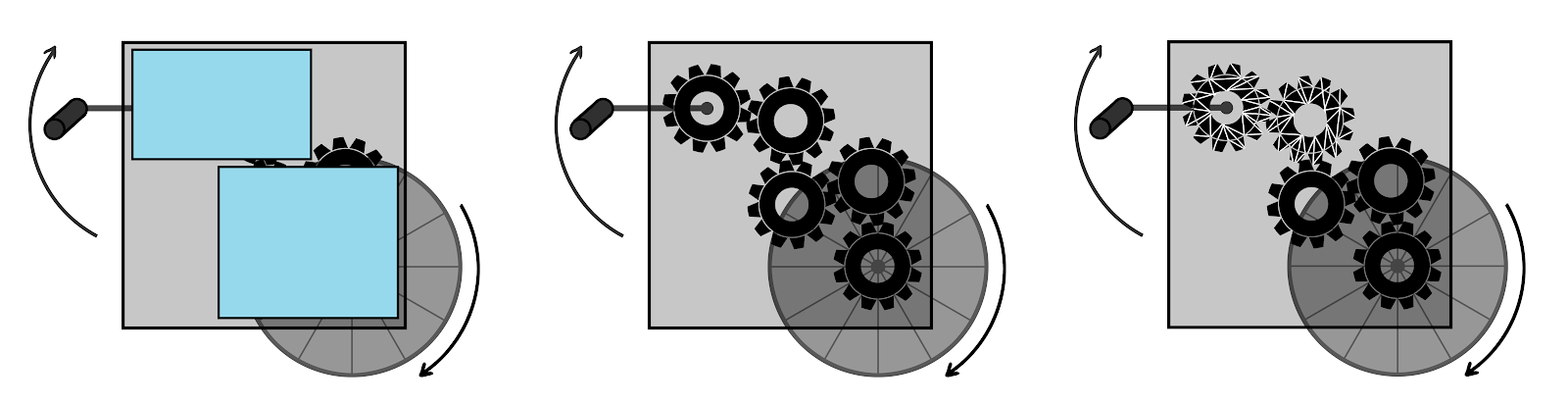
More generally: we want to build gears-level models, but we don’t want to model things down to the last atom. At some point, we have to accept some black boxes in our model components. So how do we decide where that point is?
This post answers that question. We’ll start with a relatively-detailed discussion of a physical gear, then extend the reasoning to “gears” in other kinds of models.
A Physical Gear
Picture a gear, turning in a gearbox. We can pick out a little patch of metal on that gear, zoom in, and see lots of atoms vibrating around. Those vibrations aren’t completely random - vibrations of one atom are correlated with the atoms next to it, although the correlations do typically fall off over a short distance. If we look at the motions of all the atoms in one little chunk of the gear, it won’t tell us much about the motions of the atoms in some other chunk far away in the gear.
… with one exception. If we average together the motion of all the atoms in our little chunk, we should get a decent estimate of the overall rotation speed of the gear. And that does tell us something about all the other little chunks of metal: it tells us roughly what the average motion in all those other chunks is.

Caution: physical accuracy not a priority in this visual.
Likewise, if we look at the motion of all the individual atoms in one little chunk of our gear, what does that tell us about the motion of atoms in other gears? Mostly nothing… except, again, the average motion of all the atoms tells us the overall rotation speed of our gear, which tells us something about the overall rotation speed of the other gears.
So, if we were to somehow model the whole system at atomic scales, we’d find that all the information in one little chunk of atoms, relevant to some other chunk of atoms far away, was summarized by the rotation speed of the gear.
In terms of dimensionality [LW · GW]: the atom motions are extremely high dimensional. Every atom’s speed is a 3-dimensional vector, so with n atoms we have 3n dimensions. Even a tiny patch of metal has an awful lot of atoms, so that’s an awful lot of dimensions.
Yet most of that information is irrelevant to everything far away. For purposes of predicting things far away, that huge number of dimensions can be summarized by a one-dimensional number: the gear’s rotation speed. That rotation speed, in turn, informs the motions of huge numbers of other atoms elsewhere in the system.
It’s an “information bottleneck”: (high dimensional atom motions) -> (one dimensional rotation speed) -> (high dimensional atom motions elsewhere). We can think of the abstract object - the “gear” - as an interface to all the lower-level components which comprise the gear (e.g. atoms, in a physical gear).
In general, a good “gear” in a model picks out some chunk of an object for which we have a good low-dimensional summary. All the information from that chunk which is relevant to predicting things elsewhere in the system should be summarized by a few low-dimensional parameters. For a physical gear, it’s the rotation speed. The next few sections give other examples.
Rigid Body Dynamics
One direct generalization of a physical gearbox is rigid body dynamics: we have rigid, solid objects which move around, push each other, bounce off each other, etc. This is a good model for most of the non-flexible solid objects around us most of the time: tables and chairs, wheels, hammers and screwdrivers and screws and nails, pens and pencils, sticks and rocks, pots and pans and dishes and silverware, etc.
When thinking about the mechanics of rigid bodies (i.e. how they move), all the positions and motions of individual atoms in the object can be summarized by the overall position, orientation and motion of the object. It’s just like gears, though slightly more general - gears mostly just rotate in place, while rigid bodies in general can also move around. So, it’s natural to chunk rigid bodies into individual “objects”, i.e. treat them as single gears in our models. This is exactly what we do in our everyday lives: we treat a pencil as an object, a plate as an object, a rock as an object, …. These things make natural “objects” because the low-level dynamics of all their atoms can be summarized by just the position, orientation and motion of the whole object, for purposes of predicting how things will move.
Note, however, that this is not sufficient for all questions we might ask about the object. For instance, if I want to know what sound an object makes when struck, then the vibrations of all the little parts become relevant. Rigid bodies make natural “gears” because we can answer a very broad range of questions just given a low-dimensional summary, not because we can answer all questions just given a low-dimensional summary.
Things get more complicated for non-rigid bodies, like cloth or rope. Sometimes we can use a low-dimensional summary for the dynamics, like a rope in a pulley, but not always; cloth moves around in complicated ways. We can still answer a broad range of questions using only summary information, just not necessarily questions about dynamics. For instance, looking at the atoms in one little chunk of cloth tells us very little about other atoms in the same chunk of cloth, except that the material composition is probably the same. This is quite similar to the “gears” used in chemical models.
Chemical Equations
In chemistry, we summarize the state of a huge number of atoms with just a handful of chemical concentrations (plus temperature and pressure, depending on the application). Why? Well, as long as the system is mixed up, it doesn’t matter exactly where particular molecules are - they’re all more-or-less evenly distributed throughout the system. The exact positions of atoms in one patch of fluid at one time don’t tell us much about the exact positions of atoms in another patch of fluid at a later time, except insofar as they tell us about the average concentrations of each molecule type throughout the system as a whole.
High-dimensional atom positions in one patch of fluid tell us low-dimensional average concentrations, which is all the information relevant to high-dimensional atom positions in some other patch of fluid (assuming everything is well-mixed).
Note that this changes if the system isn’t well-mixed, e.g. a layer of oil on top of water, or a diffusion gradient. Then we either need to keep track of more information (e.g. concentrations in small patches of fluid) or we need to further restrict the questions we want to answer.
Electronic Circuits
Electronic circuits are a particularly interesting example, because avoiding “crosstalk” between circuit components is an explicit design goal. We generally don’t want e.g. a resistor to behave differently if there’s a magnet nearby.
In other words: the design of a resistor is chosen so that we can summarize all the information about the component using just its overall resistance and the overall current (or voltage) through it at any given moment. We don’t need to worry about the details of the physical connection between the resistor and a wire. We don’t need to worry about whether the resistor is upside down, or spinning around, or a little hotter/colder than room temperature. We don’t need to worry about the low-level behavior of individual atoms within the resistor. We just need a one dimensional summary: overall current is proportional to overall voltage delta.
The same applies to other electronic components - transistors, wires, capacitors, transformers, diodes, etc. Components are designed to make good “gears”: their behavior has a simple, low-dimensional summary.
API Functions
In software design, we often draw high-level diagrams of the software in which each component is a function in some API, and lines/arrows between components show which information is passed between them. This is useful mainly to the extent that the inputs and outputs of each component can be summarized without needing a detailed representation of the internal behavior of each function.
This is often considered a major criterion of good software design: function should have simple interfaces. Even if there’s lots of internal complexity, like some function with many internal calculations (i.e. high dimensional, with many intermediate values calculated), the inputs and outputs should be low-dimensional (at least compared to the internals). When functions satisfy this criterion, they make good “gears” in our conceptual models of the software’s behavior.
Companies
In economics, companies work a lot like functions in software. The “interface” they provide is their catalogue of products. The product itself is relatively low-dimensional, compared to the complicated process which produced the product. It’s the same idea behind the classic “I, Pencil” essay: even something as simple as a pencil is produced by hundreds of people and machines with specialized functions. The pencil-user does not understand all the details of the pencil production process, but they don’t need to - they just need to know how to use a pencil.
As an anti-example, imagine some preindustrial ironsmith. Without reliable standards for metal composition and quality, the smith might buy very different “iron” from different suppliers at different times. The smith would either have to know quite a bit about the production of the raw iron, or else accept an inconsistent product. If the smith needs to keep track of the whole production process, then the iron supplier would be a bad gear in an economic model.
Organs
The physiology of the kidney or liver or other internal organs is rather involved. Each contains a wide variety of specialized cell types and substructures, all in large numbers; their internal structure is high-dimensional. Yet the overall function of most organs allows a relatively low-dimensional summary: they regulate levels of specific hormones or metabolites or cell types.
Takeaway
A good “gear” - i.e. a lowest-level component in a model - should offer a (relatively) low-dimensional summary of its own internal subcomponents. That low-dimensional summary makes it practical to treat the gear as a black box, even though its internal components may be complicated and high dimensional (e.g. made of lots of atoms). The information which needs to be included in the summary depends on what questions we want to answer about the system, but a common theme is that broad classes of questions about behavior not-too-close to a particular subcomponent depend only on a few summary dimensions.
Finally, I'll note that some of the examples above brush some subtleties under the rug (though the main idea does generally work as advertised). People are invited to try to spot some of those subtleties, and possibly propose the resolutions, in the comments. I'll point to one to kick things off: how does temperature fit in to our physical gearbox example?
12 comments
Comments sorted by top scores.
comment by gbear605 · 2020-11-16T18:40:30.029Z · LW(p) · GW(p)
This was a very good explanation of why to use a gears level explanation instead of an atom level. But it lacks the other direction - how do you determine if something is a gear instead of a gearbox? Regarding the image at the top of the post, how do you decide whether to describe using the blue boxes or using the gears?
Replies from: johnswentworth↑ comment by johnswentworth · 2020-11-16T19:00:45.457Z · LW(p) · GW(p)
Good question.
Everyday Lessons from High-Dimensional Optimization [LW · GW] and Gears vs Behavior [LW · GW] talk about why we use gears. Briefly: we represent high-dimensional systems as a bunch of coupled low-dimensional systems because brute-force-y reasoning works well in low dimensions, but not in high dimensions. So, to reason about high dimensions, we break the system up, use brute-force-y tricks locally on the low-dimensional parts, and then propagate information between components. This also usually makes our models generalize well, because the low-dimensional interfaces of the gears correspond to modularity of reality (just as low-dimensional function interfaces in software correspond to modularity of the code). If there's a change in one subsystem, then the impact of that change on the rest of the system will be mediated by the change in the one-dimensional summary.
For instance, in the gearbox in the post, if we hit the middle gear with a hammer and it breaks, what happens? If we have a gears-level model, then we can re-use most of that model in the new regime - the upper two gears and the handle are still coupled in the same way, and the lower two gears and the wheel are still coupled in the same way. (Though, in this case the gearbox is sufficiently low-dimensional that the difference between using the gears and using the blue boxes isn't too dramatic. In general, these things become more important as the system grows higher-dimensional and more complex.)
comment by Gordon Seidoh Worley (gworley) · 2020-11-25T00:30:03.136Z · LW(p) · GW(p)
Since no one took you up on your question, I'll take it up.
Temperature gives us a gear for talking about how hot or cold something is by degrees. The more degrees something has the hotter we say it is, the less the colder down to the limit of absolute zero.
Yet temperature is actually one number over a lot of complex interactions and exchanges of energy between particles (for now bottoming out at that particular gear). If we look at those individual particles we'll find a more complex story that's noisy (and gets noisier as things get hotter), but that's not actually necessary to know about to answer questions like "will this thing melt?" or "will this thing freeze?", which generally just require knowing the average energy of the thing to predict how it will behave.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-11-25T17:19:55.842Z · LW(p) · GW(p)
Solid answer.
comment by Adam Zerner (adamzerner) · 2020-11-17T03:10:54.571Z · LW(p) · GW(p)
Great post. In retrospect it makes a ton of sense but before reading this I wouldn't have been able to think about it this clearly.
It seems pretty similar to the question of what resolution map to use in the context of the map and the territory. Eg in biology, the resolution of cells is more useful than the resolution of atoms.
comment by aa.oswald · 2020-11-17T15:31:36.460Z · LW(p) · GW(p)
I just want to say that any good mechanical engineer designing a new system with some tolerances and known limitations but making use of novel gears, like on a rocket engine, will probably be running those gears through finite element analysis.
That indicates to me that the "lowest-level component in a model" question is not just "what makes a good model" but "what is the lowest-level component I can get away with".
Replies from: philh↑ comment by philh · 2020-11-18T13:20:40.025Z · LW(p) · GW(p)
On what I take to be a related note, I recently enjoyed a short essay on, I guess, the gears of gears.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-11-18T15:29:40.835Z · LW(p) · GW(p)
That is excellent.
comment by Gurkenglas · 2020-11-17T11:37:02.468Z · LW(p) · GW(p)
Compare to https://www.lesswrong.com/posts/zXfqftW8y69YzoXLj/using-gpt-n-to-solve-interpretability-of-neural-networks-a [LW · GW], which is about defining how well a neural net can be described in terms of gears.
comment by jmh · 2020-11-17T15:10:20.847Z · LW(p) · GW(p)
As is often the case I did enjoy reading your post. They are always well presented and interesting.
I'm not sure if you had this view in mind while writing, but in many ways I read this as a very good approach to the practical application of Occam's Razor. Things need to be kept as simple as they can while still shedding light on the underlying question at hand. I think your post helps to consider just how, when and where one might simplify in our models/maps.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-11-17T16:28:16.911Z · LW(p) · GW(p)
Interesting connection, I hadn't thought about it from the Occam's razor angle. That's also similar to the maps <-> abstraction connection.
comment by adamShimi · 2020-11-17T11:16:34.958Z · LW(p) · GW(p)
I really like this post, and its statistical-physics-grounded use of gears and abstractions. What you present here might also be a justification of when the design stance of Dennett works: when does considering a system as designed (either by intelligent designers like us or by evolution) is useful to predict its behavior? For example, your ironsmith example shows when one needs to go deeper, either to Dennett's physical stance or to a lower level of design/gears.