Posts
Comments
Huh, thanks for the correction.
Smaller correction - I think you've had her buy an extra pair of boots. At $260 she's already bought one pair, so we apply thirteen times, then multiply by 1.07 again for the final year's interest, and she ends with no boots, so that's $239.41. (Or start with $280 and apply fourteen times.)
Not sure why my own result is wrong. Part of it is that I forgot to subtract the money actually spent on boots - I did "the $20 she spends after the first year gets one year's interest, so that's $21.40; the $20 she spends after the second year gets two years' interest, so that's $22.90..." but actually it's only $1.40, $2.90 and so on. But even accounting for that, I get $222.58. So let's see...
Suppose she only needs to buy two pairs of boots. According to your method she goes $40 → $21.40 → $1.50. (Or, $40 and no boots → $20 and boots → $21.40 and no boots a year later → $1.40 and boots → $1.50 and no boots a year later.) According to mine, of her original $40, $20 of it earns no interest and $20 of it earns a years' interest. But that assumes the interest she earns in that year is withdrawn, she gets to keep it but it doesn't keep earning interest. So that's why I got the wrong answer.
Well, I should like to see some examples. So far, our tally of actual examples of this alleged phenomenon seems to still be zero. All the examples proffered thus far… aren’t.
From https://siderea.dreamwidth.org/1477942.html:
"These boots," I said gesturing at what I was trying on, on my feet, "cost $200. Given that I typically buy a pair for $20 every year, that means these boots have to last 10 years to recoup the initial investment."
That was on January 17, 2005. They died earlier this month – that is in the first week of December, 2018. So: almost but not quite 14 years.
So, purely as an investment, they returned a bit under $80, which is a 40% ROI.
But... if we're talking about this just as an investment, we need to compare to other investments. Let's say the S&P 500 returns 7% consistently (I think that's pessimistic - note, not adjusting for inflation because the $20 boots haven't changed with inflation either).
- In one world, Siderea buys $200 boots and invests $80. After 14 years, she has and no boots.
- In another world, Siderea buys $20 boots and invests $260. A year later she withdraws $20 and buys boots, and so on. After 14 years, she has... finite geometric series, , I think she has $483 and no boots.
So if we think of this as a purely financial investment, I guess it was a bad one?
(This is also often missing when people talk about buying versus renting. Yes, the mortgage is often lower than rent, and house value is likely higher at the end, but you gave up investing your deposit. How do those effects compare? Probably depends on time and place.)
Sam Vimes is a copper, and sees poverty lead to precarity, and precarity lead to Bad Things Happening In Bad Neighborhoods.
Hm, does he? It's certainly a reasonable guess, but offhand I don't remember it coming up in the books, and the Thieves and Assassins guilds will change the dynamic compared to what we'd expect on Earth.
We got spam and had to reset the link. To get the new link, append the suffix "BbILI8HzX3zgJF8i" to the prefix "https://chat.whatsapp.com/IUIZc3". Hopefully spambots can't yet do that automatically.
This reddit thread has the claim:
Something related that you CAN do, and that is more likely to make a difference, is not ever to heat up plastic in a microwave, wash it in a dishwasher, or cook with plastic utensils. Basically, the softening agents in a lot of plastics aren't chemically bonded to the rest of the polymers, and heating the plastic makes those chemicals ready to leach into whatever food contacts them. That's a huge class of chemicals, none of which are LD-50-level dangerous, but many of which have been associated with hormonal changes, microbiome issues, and a whole host of other stuff that fits in the general category of "Why do organisms work differently than they did 100 years ago?"
Notably this is about plasticizers, a different thing than microplastics.
One question I have that might be relatively tractable: if I'm using plastic containers for leftovers, how much difference is there between
- Store in the container, put on plate to microwave and eat.
- Store and microwave in the container, put on plate to eat.
- Who needs a plate anyway? Just eat from the container.
The bit about plastic chopping boards kind of hints that (3) might give a lot more microplastics than (2)? But you're probably less violent to the container than the chopping board.
We suggest these low-hanging actions one can take to reduce their quantity exposure:
a. Stop using plastic bottles and plastic food storage containers,
b. Stop using plastic cutting boards,
For people who didn't read the rough notes dumps: it seems like (b) is a way bigger effect size than (a).
There are 3 people. Each person announces an integer. The smallest unique integer wins: e.g. if your opponents both pick 1, you win with any number. If all 3 pick the same number, the winner is picked randomly
Question: what’s the Nash equilibrium?
(I assume this is meant to be natural numbers or positive ints? Otherwise I don't think there is a nash equilibrium.)
So it is. Other than that, the remaining details I needed were:
2740 Telegraph Ave, Berkeley
94705
habryka@lightconeinfrastructure.com
Oliver Habryka
Assuming all went well, I just donated £5,000 through the Anglo-American charity, which should become about (£5000 * 1.25 * 96% = £6000 ≈ $7300) to lightcone.
I had further questions to their how to give page, so:
- You can return the forms by email, no need to post them. (I filled them in with Firefox's native "draw/write on this pdf" feature, handwriting my signature with a mouse.)
- If donating by bank transfer, you send the money to "anglo-american charity limited", not "anglo-american charitable foundation".
- For lightcone's contact details I asked on LW intercom. Feels rude to put someone's phone number here, so if you're doing the same as me, I'm not gonna save you that step.
E: and all does seem to have gone well. I got an email on Jan 25 confirming they'd passed $7260 on to Lightcone.
not sure if that would be legit for gift aid purposes
Based on https://www.gov.uk/government/publications/charities-detailed-guidance-notes/chapter-3-gift-aid#chapter-344-digital-giving-and-social-giving-accounts, doing this the naive way (one person collects money and gives it to the charity, everyone shares the tax rebate) is explicitly forbidden. Which makes sense, or everyone with a high income friend would have access to the 40% savings.
Not clear to me whether it would be allowed if the charity is in on it and everyone fills in their own gift aid declaration. But that's extra steps for all parties.
Thanks - I think GWWC would be fewer steps for me, but if that's not looking likely then one of these is plausible.
(I wonder if it would be worth a few of us pooling money to get both "lower fees" and "less need to deal with orgs who don't just let you click some buttons to say where you want the money to go", but not sure if that would be legit for gift aid purposes.)
That's not really "concrete" feedback though, right? In the outcome game/consensus game dynamic Stephen's talking about, it seems hard to play an outcome game with that kind of feedback.
Beyond being an unfair and uninformed dismissal
Why do you think it's uninformed? John specifically says that he's taking "this work is trash" as background and not trying to convince anyone who disagrees. It seems like because he doesn't try, you assume he doesn't have an argument?
it risks unnecessarily antagonizing people
I kinda think it was necessary. (In that, the thing ~needed to be written and "you should have written this with a lot less antagonism" is not a reasonable ask.)
For instance, if a developer owns multiple adjacent parcels and decides to build housing or infrastructure on one of them, the value of the undeveloped parcels will rise due to their proximity to the improvements.
An implementation detail of LVT would be, how do we decide what counts as one parcel and what counts as two? Depending how we answer that, I could easily imagine LVT causing bad incentives. (Which isn't a knock-down, it doesn't feel worse than the kind of practical difficulty any tax has.)
I wonder if it might not be better to just get rid of the idea of "improvements to your own land don't get taxed". Then we figure out the value of land in fairly broad strokes ("in this borough, it's worth £x per square meter") and just tax based on how much land you own in each price region.
Disadvantage is that improvements to your own land get taxed. I guess most of the time the tax is fairly low, because that tax is distributed over all the land in the price region.
Advantage is less implementation complexity. No need to figure out "how much is this specific land worth without improvements". (Suppose there's a popular theme park here. Nearby land probably gets more valuable. When you want to assess the value of the land under the theme park, as if there was no theme park there, how do you do that?)
Asking the question for "land in this general area" seems, still hard, but easier. (Lars Doucet was on the Complex Systems podcast recently, and said one way is to look at sales that were shortly followed by demolition. "This person paid $1m for the land and then an extra $500k to demolish what was there, so the land itself was probably worth $1.5m.")
I've read/listened about LVT many times and I don't remember "auctions are a key aspect of this" ever coming up. E.g. the four posts by Lars Doucet on ACX only mention the word twice, in one paragraph that doesn't make that claim:
Land Price or Land Value is how much it costs to buy a piece of land. Full Market Value, however, is specifically the land price under "fair" and open market conditions. What are "unfair" conditions? I mean, your dad could sell you a valuable property for $1 as an obvious gift, but if he put it on the open market, it would go for much more than that. Likewise, it's not uncommon for a property that's been foreclosed on and hastily auctioned off to be re-listed publicly by the auction winner for a higher price.
My girlfriend and I probably wouldn't have got together if not for a conversation at Less Wrong Community Weekend.
Oh, I think that also means that section is slightly wrong. You want to take insurance if
and the insurance company wants to offer it if
So define
as you did above. Appendix B suggests that you'd take insurance if and they'd offer it if . But in fact they'd offer it if .
Appendix B: How insurance companies make money
Here's a puzzle about this that took me a while.
When you know the terms of the bet (what probability of winning, and what payoff is offered), the Kelly criterion spits out a fraction of your bankroll to wager. That doesn't support the result "a poor person should want to take one side, while a rich person should want to take the other".
So what's going on here?
Not a correct answer: "you don't get to choose how much to wager. The payoffs on each side are fixed, you either pay in or you don't." True but doesn't solve the problem. It might be that for one party, the stakes offered are higher than the optimal amount and for the other they're lower. It might be that one party decides they don't want to take the bet because of that. But the parties won't decide to take opposite sides of it.
Let's be concrete. Stick with one bad outcome. Insurance costs $600, and there's a 1/3 chance of paying out $2000. Turning this into a bet is kind of subtle. At first I assumed that meant you're staking $600 for a 1/3 chance of winning... $1400? $2000? But neither of those is right.
Case by case. If you take the insurance, then 2/3 of the time nothing happens and you just lose $600. 1/3 of the time the insurance kicks in, and you're still out $600.
If you don't take the insurance, then 2/3 of the time nothing happens and you have $0. 1/3 of the time something goes wrong and you're out $2000.
So the baseline is taking insurance. The bet being offered is that you can not take it. You can put up stakes of $2000 for a 2/3 chance of winning $600 (plus your $2000 back).
Now from the insurance company's perspective. The baseline and the bet are swapped: if they don't offer you insurance, then nothing happens to their bankroll. The bet is when you do take insurance.
If they offer it and you accept, then 2/3 of the time they're up $600 and 1/3 of the time they're out $1400. So they wager $1400 for a 2/3 chance of winning $600 (plus their $1400 back).
So them offering insurance and you accepting it isn't simply modeled as "two parties taking opposite sides of a bet".
I still disagree with that.
I've written about this here. Bottom line is, if you actually value money linearly (you don't) you should not bet according to the Kelly criterion.
I think we're disagreeing about terminology here, not anything substantive, so I mostly feel like shrug. But that feels to me like you're noticing the framework is deficient, stepping outside it, figuring out what's going on, making some adjustment, and then stepping back in.
I don't think you can explain why you made that adjustment from inside the framework. Like, how do you explain "multiple correlated bets are similar to one bigger bet" in a framework where
- Bets are offered one at a time and resolved instantly
- The bets you get offered don't depend on previous history
?
This is a synonym for "if money compounds and you want more of it at lower risk".
No it's not. In the real world, money compounds and I want more of it at lower risk. Also, in the real world, "utility = log($)" is false: I do not have a utility function, and if I did it would not be purely a function of money.
Like I don’t expect to miss stuff i really wanted to see on LW, reading the titles of most posts isn’t hard
It's hard for me! I had to give up on trying.
The problem is that if I read the titles of most posts, I end up wanting to read the contents of a significant minority of posts, too many for me to actually read.
Ah, my "what do you mean" may have been unclear. I think you took it as, like, "what is the thing that Kelly instructs?" But what I meant is "why do you mean when you say that Kelly instructs this?" Like, what is this "Kelly" and why do we care what it says?
That said, I do agree this is a broadly reasonable thing to be doing. I just wouldn't use the word "Kelly", I'd talk about "maximizing expected log money".
But it's not what you're doing in the post. In the post, you say "this is how to mathematically determine if you should buy insurance". But the formula you give assumes bets come one at a time, even though that doesn't describe insurance.
The probability should be given as 0.03 -- that might reduce your confusion!
Aha! Yes, that explains a lot.
I'm now curious if there's any meaning to the result I got. Like, "how much should I pay to insure against an event that happens with 300% probability" is a wrong question. But if we take the Kelly formula and plug in 300% for the probability we get some answer, and I'm wondering if that answer has any meaning.
I disagree. Kelly instructs us to choose the course of action that maximises log-wealth in period t+1 assuming a particular joint distribution of outcomes. This course of action can by all means be a complicated portfolio of simultaneous bets.
But when simultaneous bets are possible, the way to maximize expected log wealth won't generally be "bet the same amounts you would have done if the bets had come one at a time" (that's not even well specified as written), so you won't be using the Kelly formula.
(You can argue that this is still, somehow, Kelly. But then I'd ask "what do you mean when you say this is what Kelly instructs? Is this different from simply maximizing expected log wealth? If not, why are we talking about Kelly at all instead of talking about expected log wealth?")
It's not just that "the insurance calculator does not offer you the interface" to handle simultaneous bets. You claim that there's a specific mathematical relationship we can use to determine if insurance is worth it; and then you write down a mathematical formula and say that insurance is worth it if the result is positive. But this is the wrong formula to use when bets are offered simultaneously, which in the case of insurance they are.
This is where reinsurance and other non-traditional instruments of risk trading enter the picture.
I don't think so? Like, in real world insurance they're obviously important. (As I understand it, another important factor in some jurisdictions is "governments subsidize flood insurance.") But the point I was making, that I stand behind, is
- Correlated risk is important in insurance, both in theory and practice
- If you talk about insurance in a Kelly framework you won't be able to handle correlated risk.
If one donates one's winnings then one's bets no longer compound and the expected profit is a better guide then expected log wealth -- we agree.
(This isn't a point I was trying to make and I tentatively disagree with it, but probably not worth going into.)
Whether or not to get insurance should have nothing to do with what makes one sleep – again, it is a mathematical decision with a correct answer.
I'm not sure how far in your cheek your tongue was, but I claim this is obviously wrong and I can elaborate if you weren't kidding.
I'm confused by the calculator. I enter wealth 10,000; premium 5,000; probability 3; cost 2,500; and deductible 0. I think that means: I should pay $5000 to get insurance. 97% of the time, it doesn't pay out and I'm down $5000. 3% of the time, a bad thing happens, and instead of paying $2500 I instead pay $0, but I'm still down $2500. That's clearly not right. (I should never put more than 3% of my net worth on a bet that pays out 3% of the time, according to Kelly.) Not sure if the calculator is wrong or I misunderstand these numbers.
Kelly is derived under a framework that assumes bets are offered one at a time. With insurance, some of my wealth is tied up for a period of time. That changes which bets I should accept. For small fractions of my net worth and small numbers of bets that's probably not a big deal, but I think it's at least worth acknowledging. (This is the only attempt I'm aware of to add simultaneous bets to the Kelly framework, and I haven't read it closely enough to understand it. But there might be others.)
There's a related practical problem that a significant fraction of my wealth is in pensions that I'm not allowed to access for 30+ years. That's going to affect what bets I can take, and what bets I ought to take.
The reason all this works is that the insurance company has way more money than we do. ...
I hadn't thought of it this way before, but it feels like a useful framing.
But I do note that, there are theoretical reasons to expect flood insurance to be harder to get than fire insurance. If you get caught in a flood your whole neighborhood probably does too, but if your house catches fire it's likely just you and maybe a handful of others. I think you need to go outside the Kelly framework to explain this.
I have a hobby horse that I think people misunderstand the justifications for Kelly, and my sense is that you do too (though I haven't read your more detailed article about it), but it's not really relevant to this article.
I think the thesis is not "honesty reduces predictability" but "certain formalities, which preclude honesty, increase predictability".
I kinda like this post, and I think it's pointing at something worth keeping in mind. But I don't think the thesis is very clear or very well argued, and I currently have it at -1 in the 2023 review.
Some concrete things.
- There are lots of forms of social grace, and it's not clear which ones are included. Surely "getting on the train without waiting for others to disembark first" isn't an epistemic virtue. I'd normally think of "distinguishing between map and territory" as an epistemic virtue but not particularly a social grace, but the last two paragraphs make me think that's intended to be covered. Is "when I grew up, weaboo wasn't particularly offensive, and I know it's now considered a slur, but eh, I don't feel like trying to change my vocabulary" an epistemic virtue?
- Perhaps the claim is only meant to be that lack of "concealing or obfuscating information that someone would prefer not to be revealed" is an epistemic virtue? Then the map/territory stuff seems out of place, but the core claim seems much more defensible.
- "Idealized honest Bayesian reasoners would not have social graces—and therefore, humans trying to imitate idealized honest Bayesian reasoners will tend to bump up against (or smash right through) the bare minimum of social grace." Let's limit this to the social graces that are epistemically harmful. Still, I don't see how this follows.
- Idealized honest Bayesian reasoners wouldn't need to stop and pause to think, but a human trying to imitate one will need to do that. A human getting closer in some respects to an idealized honest Bayesian reasoner might need to spend more time thinking.
- And, where does "bare minimum" come from? Why will these humans do approximately-none-at-all of the thing, rather than merely less-than-maximum of it?
- I do think there's something awkward about humans-imitating-X, in pursuit of goal Y that X is very good at, doing something that X doesn't do because it would be harmful to Y. But it's much weaker than claimed.
- There's a claim that "distinguishing between the map and the territory" is distracting, but as I note here it's not backed up.
- I note that near the end we have: "If the post looks lousy, say it looks lousy. If it looks good, say it looks good." But of course "looks" is in the map. The Feynman in the anecdote seems to have been following a different algorithm: "if the post looks [in Feynman's map, which it's unclear if he realizes is different from the territory] lousy, say it's lousy. If it looks [...] good, say it's good."
- Vaniver and Raemon point out something along the lines of "social grace helps institutions perservere". Zack says he's focusing on individual practice rather than institution-building. But both his anecdotes involve conversations. It seems that Feynman's lack of social grace was good for Bohr's epistemics... but that's no help for Feynman's individual practice. Bohr appreciating Feynman's lack of social grace seems to have been good for Feynman's ability-to-get-close-to-Bohr, which itself seems good for Feynman's epistemics, but that's quite different.
- Oh, elsewhere Zack says "The thesis of the post is that people who are trying to maximize the accuracy of shared maps are going to end up being socially ungraceful sometimes", which doesn't sound like it's focusing on individual practice?
- Hypothesis: when Zack wrote this post, it wasn't very clear to himself what he was trying to focus on.
Man, this review kinda feels like... I can imagine myself looking back at it two years later and being like "oh geez that wasn't a serious attempt to actually engage with the post, it was just point scoring". I don't think that's what's happening, and that's just pattern matching on the structure or something? But I also think that if it was, it wouldn't necessarily feel like it to me now?
It also feels like I could improve it if I spent a few more hours on it and re-read the comments in more detail, and I do expect that's true.
In any case, I'm pretty sure both [the LW review process] and [Zack specifically] prefer me to publish it.
Ooh, I didn't see the read filter. (I think I'd have been more likely to if that were separated from the tabs. Maybe like, [Read] | [AI 200] [World Modeling 83] [Rationality 78] ....) With that off it's up to 392 nominated, though still neither of the ones mentioned. Quick review is now down to 193, my current guess is that's "posts that got through to this phase that haven't been reviewed yet"?
Screenshot with the filter off:
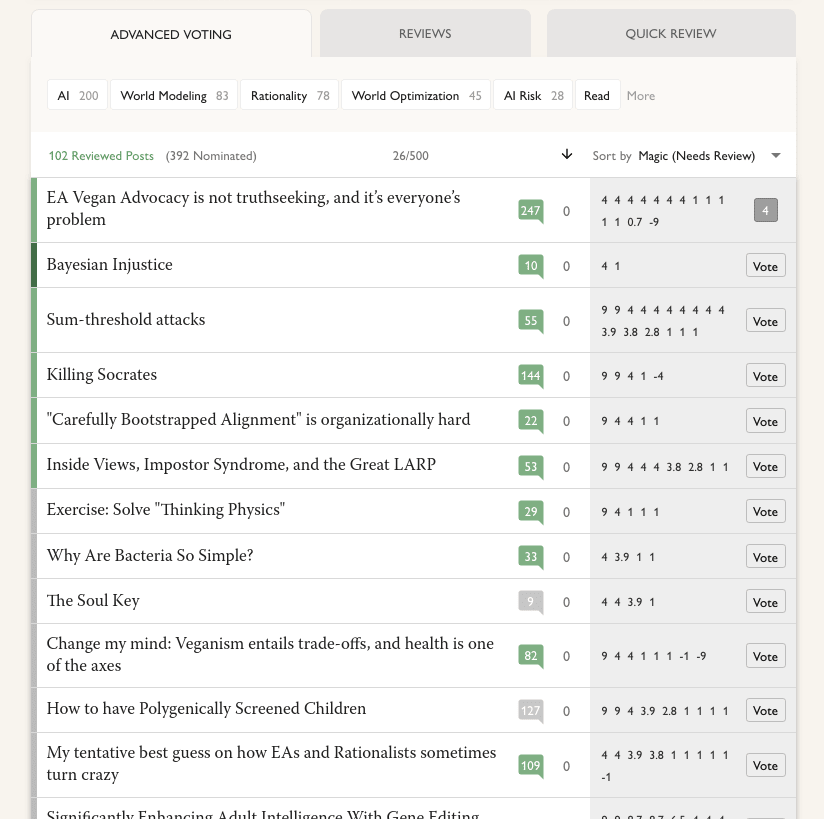
and some that only have one positive review:
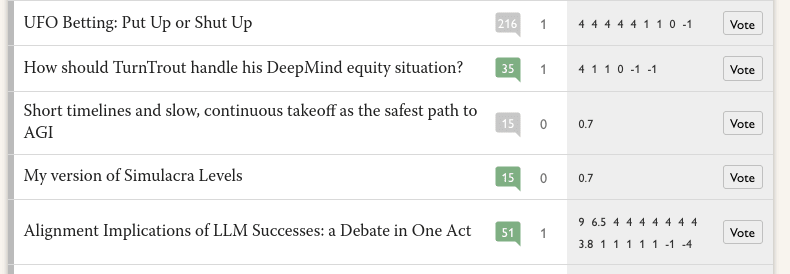
Btw, I'm kinda confused by the current review page. A tooltip on advanced voting says
54 have received at least one Nomination Vote
Posts need at least 2 Nomination Votes to proceed to the Review Phase
And indeed there are 54 posts listed and they all have at least one positive vote. But I'm pretty sure this and this both had at least one (probably exactly one) positive vote at the end of the nomination phase and they aren't listed.
Guess: this is actually listing posts which had at least two positive votes at the end of the nomination phase; the posts with only one right now had two at the time?
...but since I started writing this comment, the 54 has gone up to 56, so there must be some way for posts to join it, but I don't have a guess what it would be.
And then the quick review tab lists 194 posts. I'm not sure what the criteria for being included on it is. It seems I can review and vote on each of them, where I can't do that for the two previous posts, so again there must be some criteria but I don't have a guess what.
I think it's good that this post was written, shared to LessWrong, and got a bunch of karma. And (though I haven't fully re-read it) it seems like the author was careful to distinguish observation from inference and to include details in defense of Ziz when relevant. I appreciate that.
I don't think it's a good fit for the 2023 review. Unless Ziz gets back in the news, there's not much reason for someone in 2025 or later to be reading this.
If I was going to recommend it, I think the reason would be some combination of
- This is a good example of investigative journalism, and valuable to read as such.
- It's a good case study of a certain type of person that it's important to remember exists.
But I don't think it stands out as a case study (it's not trying to answer questions like "how did this person become Ziz"), and I weakly guess it doesn't stand out as investigative journalism either. E.g. when I'm thinking on these axes, TracingWoodgrains on David Gerard feels like the kind of thing I'd recommend above this.
Which, to be clear, not a slight on this post! I think it does what it wanted to do very well, and what it wants to do is valuable, it's just not a kind of thing that I think the 2023 review is looking to reward.
Self review: I really like this post. Combined with the previous one (from 2022), it feels to me like "lots of people are confused about Kelly betting and linear/log utility of money, and this deconfuses the issue using arguments I hadn't seen before (and still haven't seen elsewhere)". It feels like small-but-real intellectual progress. It still feels right to me, and I still point people at this when I want to explain how I think about Kelly.
That's my inside view. I don't know how to square that with the relative lack of attention the post got, and it feels weird to be writing it given that fact, but oh well. There are various stories I could tell: maybe people were less confused than I thought; maybe my explanation is unclear; maybe I'm still wrong on the object level; maybe people just don't care very much; maybe it just happened not to get seen.
If I were writing this today, my guess is:
- It's worth combining the two posts into one.
- The rank optimization stuff is fine to cut, given that I tentatively propose it in one post and then in the next say "probably not very useful". Maybe have a separate post for exploring it. No need to go into depth on "extending Kelly outside its original domain".
- The charity stuff might also be fine to cut. At any rate it's not a focus.
- Someone sent me an example function satisfying the "I'm pretty sure yes" criteria, so that can be included.
- Not sure if this belongs in the same place, but I'd still like to explore more the "what if your utility function is such that maximizing expected utility at time doesn't maximize expected utility at time ?" thing. (I thought I wrote this in the post somewhere, but can't see it: the way I'd explore this is from the perspective of "a utility function is isomorphic to a description of betting preferences that satisfy certain constraints, so when we talk about a utility function like that, what betting preferences are we talking about?" Feels like the kind of thing someone's likely already explored, but I haven't seen it if so.)
(At least in the UK, numbers starting 077009 are never assigned. So I've memorized a fake phone number that looks real, that I sometimes give out with no risk of accidentally giving a real phone number.)
Okay. Make it £5k from me (currently ~$6350), that seems like it'll make it more likely to happen.
If you can get it set up before March, I'll donate at least £2000.
(Though, um. I should say that at least one time I've been told "the way to donate with gift said is to set up an account with X, tell them to send the money to Y, and Y will pass it on to us", and the first step in the chain there had very high transaction fees and I think might have involved sending an email... historical precedent suggests that if that's the process for me to donate to lightcone, it might not happen.)
Do you know what rough volume you'd need to make it worthwhile?
I don't know anything about the card. I haven't re-read the post, but I think the point I was making was "you haven't successfully argued that this is good cost-benefit", not "I claim that this is bad cost-benefit". Another possibility is that I was just pointing out that the specific quoted paragraph had an implied bad argument, but I didn't think it said much about the post overall.
My guess: [signalling] is why some people read the Iliad, but it's not the main thing that makes it a classic.
Incidentally, there was one reddit comment that pushed me slightly in the direction of "yep, it's just signalling".
This was obviously not the intended point of that comment. But (ignoring how they misunderstood my own writing), the user
- Quotes multiple high status people talking about the Iliad;
- Tantalizingly hints that they are widely-read enough to be able to talk in detail about the Iliad and the old testament, and compare translations;
- Says approximately nothing about the Iliad;
- And says nothing at all about why they think the Iliad is good, and nor do roughly 3/4 of the people they quote. (Frye explains why it's important, but that's different. The last 6 lines of Keats talk about how Keats reacted to it, but that doesn't say what's good about it. Borges says a particular line is more beautiful than some other line (I think both lines are fine). Only Santayana tells me what he thinks is good about the Iliad.)
So like, you're trying to convince me the Iliad isn't just signalling by quoting Keats, saying essentially "I'd heard the Iliad was so good, but it took me forever to track down a copy[1]. When I did? Blew my mind, man. Blew my mind." Nonspecific praise feels like signalling, appeal to authority feels like signalling, and the authority giving nospecific praise? This just really solidly rings my signalling bells, you know?
- ^
I misunderstood Keats when I first replied to the comment. I'd assumed that when he said he "heard Chapman speak out loud and bold", he had, you know, heard someone named Chapman speak, perhaps loudly and boldly. Apparently it was what is called a "metaphor", and he had actually just read Chapman's translation.
Complex Systems (31 Oct 2024): From molecule to medicine, with Ross Rheingans-Yoo
When you first do human studies with a new drug, there's something like a 2/3 chance it'll make it to the second round of studies. Then something like half of those make it to the next round; and there's a point where you talk to the FDA and say "we're planning to do this study" and they say "cool, if you do that and get these results you'll probably be approved" and then in that case there's like an 85% chance you'll be approved; and I guess at least one other filter I'm forgetting. Overall something like 10-15% of drugs that start on this pipeline get approved, typically taking at least 7 years.
A drug that gets approved needs to make about $2 billion, to make up for the costs of all those trials plus the trials for the drugs that didn't get approved. And it has about 10 years to do that before patent protections expire, because you filed the patent before doing the first human studies and you only get 20 years from that point.
Typically what happens is someone forms a company for a specific drug, and while it's in fairly early trials the company gets bought by a big pharma company. The trials themselves are done by companies that specialize in running clinical trials.
Ross says Thalidomide was sort of the middle of a story. The story started with Upton Sinclair's The Jungle, which he wrote as a "look at the horrible conditions meat packers have to endure" but what the public took from it is "excuse me, there are human fingers in my sausages?" So after that was the pure food and drug act which said that anything had to be just the thing it said it was.
But then a drug came which was exactly what it said it was, and that thing was bad for people. So after that you needed to do studies to show safety, but they were less rigorous than they are now?
And then thalidomide happened, which was fine for most people but caused birth defects when taken by a pregnant person. When it came up for approval, the beurocrat looking at it happened to have previously looked at rabbits and seen that drug uptake and metabolization could be different in pregnant rabbits, making something otherwise non-toxic become toxic. And so she said the company needed data about safety in pregnant people, even though this was a non-standard requirement at the time. The company tried to avoid that, she insisted, and it never got approved in the US. But standards still got stricter.
(It did get approved in Europe. It's relevant that Germany didn't like tracking birth defects due to previous history, so the problems weren't noticed as early as they might have been.)
One of the times when regulations got stricter, part of the story is that at the same time as public outrage, there also happened to be a bill in progress for reasons of punishing pharma for something something, so that's the bill that got through.
At some point you started to get patient advocacy groups, saying "we are dying while you hold this drug up", and the FDA would pay attention to that. And then the pharma companies would get involved in those groups, and now it's at the point where you kinda need one of those or the FDA will be like "why would we prioritize you?"
There are drugs that the FDA wants to encourage but which aren't profitable, e.g. helping with diseases common in the third world and rare in the US. One motivation is if you make one they'll give you a priority review voucher, good to help another drug of yours get approved faster. These vouchers are transferrable, and the market price is... I think $100k or $200k?
With covid vaccines, the government said "if you produce a thing that satisfies these criteria, we will buy X amount of it for sure". That took some uncertainty out of the process and helped things get made.
Sometimes a drug will succeed in trials but not get pushed forward for various reasons, sometimes just falling through cracks. One drug this happened with was a covid treatment, which seemed to reduce hospitalizations by 70% in vaccinated people. When it was in development the FDA said it was unlikely to get emergency use authorization, and the company dropped it.
(Related: VaccinateCA got a lot of funding for a while, and then after the funders themselves got vaccinated, it got less funding.)
Later the company was going bankrupt, and they sold off their assets, which included "drugs that seemed promising but we never went anywhere with", including this one. Ross was involved in some other company buying up that drug.
You can do trials for covid much cheaper than for cancer drugs. For cancer you'll often have a list of a smallish number of people and try to find the specific individuals who give you the best chance of a statistically significant result based on comorbidities and such, and have someone specifically approach the people you want. For covid the cheap thing to do is: everyone who comes to your clinic with a cough gets the drug and gets a covid test. Later you find out if they had covid and (thanks to a phone call) what happened to their symptoms. And you can do this sort of thing somewhere like Brazil, instead of doing it in the most prestigious hospital (where there are a bunch of other studies going on distracting people). But it's kind of a weird thing to do, and if trials fail your investors might be like "why didn't you do the normal thing?"
Though this particular story for weight exfiltration also seems pretty easy to prevent with standard computer security: there’s no reason for the inference servers to have the permission to create outgoing network connections.
But it might be convenient to have that setting configured through some file stored in Github, which the execution server has access to.
Yeah, if that was the only consideration I think I would have created the market myself.
Launching nukes is one thing, but downvoting posts that don't deserve it? I'm not sure I want to retaliate that strongly.
I looked for a manifold market on whether anyone gets nuked, and considered making one when I didn't find it. But:
- If the implied probability is high, generals might be more likely to push the button. So someone who wants someone to get nuked can buy YES.
- If the implied probability is low, generals can get mana by buying YES and pushing the button. I... don't think any of the generals will be very motivated by that? But not great.
So I decided not to.
No they’re not interchangeable. They are all designed with each other in mind, along the spectrum, to maximize profits under constraints, and the reality of rivalrousness is one reason to not simply try to run at 100% capacity every instant.
I can't tell what this paragraph is responding to. What are "they"?
You explained they popped up from the ground. Those are just about the most excludable toilets in existence!
Okay I do feel a bit silly for missing this... but I also still maintain that "allows everyone or no one to use" is a stretch when it comes to excludability. (Like, if the reason we're talking about it is "can the free market provide this service at a profit", then we care about "can the provider limit access to people who are paying for it". If they can't do that, do we care that they can turn the service off during the day and on at night?)
Overall it still seems like you want to use words in a way that I think is unhelpful.
Idk, I think my reaction here is that you're defining terms far more broadly than is actually going to be helpful in practice. Like, excludability and rivalry are spectrums in multiple dimensions, and if we're going to treat them as binaries then sure, we could say anything with a hint of them counts in the "yes" bin, but... I think for most purposes,
- "occasionally, someone else arrives at the parking lot at the same time as me, and then I have to spend a minute or so waiting for the pay-and-display meter"
is closer to
- "other people using the parking lot doesn't affect me"
than it is to
- "when I get to the parking lot there are often no spaces at all"
I wouldn't even say that: bathrooms are highly rivalrous and this is why they need to be so overbuilt in terms of capacity. While working at a cinema, did you never notice the lines for the womens' bathroom vs the mens' bathroom once a big movie let out? And that like 99% of the time the bathrooms were completely empty?
My memory is we didn't often have that problem, but it was over ten years ago so dunno.
I'd say part of why they're (generally in my experience) low-rivalrous is because they're overbuilt. They (generally in my experience) have enough capacity that people typically don't have to wait, and when they do have to wait they don't have to wait long. There are exceptions (during the interval at a theatre), but it still seems to me that most bathrooms (as they actually exist, and not hypothetical other bathrooms that had been built with less capacity) are low-rivalrous.
None of your examples are a counterexample. All of them are excludable, and you explain how and that the operators choose not to.
I'm willing to concede on the ones that could be pay gated but aren't, though I still think "how easy is it to install a pay gate" matters.
But did you miss my example of the pop-up urinals? I did not explain how those are excludable, and I maintain that they're not.
Thing I've been wrong about for a long time: I remembered that the rocket equation "is exponential", but I thought it was exponential in dry mass. It's not, it's linear in dry mass and exponential in Δv.
This explains a lot of times where I've been reading SF and was mildly surprised at how cavalier people seemed to be about payload, like allowing astronauts to have personal items.
Sorry, I didn't see this notification until after - did you find us?
I agree that econ 101 models are sometimes incorrect or inapplicable. But
I don’t know how much that additional cost is, but seemingly less than the benefit, because three months later, the whole of Germany wants to introduce this card. The introduction has to be delayed by some legal issues, and then a few counties want to introduce it independently. So popular is this special card!
The argument here seems to be that the card must satisfy a cost-benefit analysis or it wouldn't be so popular, and I don't buy that either.
Ah, I can sometimes make fridays but not tomorrow. Hope it goes well.
they turn a C/G base pair to an A/T, or vice versa.
Can they also turn it into a G/C or a T/A? I wasn't sure if this was an example or a "this is the only edit they do". Or I might just be misunderstanding and this question is wrong.