Multiplex Gene Editing: Where Are We Now?
post by sarahconstantin · 2024-07-16T20:50:04.590Z · LW · GW · 6 commentsContents
How CRISPR Works How Base and Prime Editors Work What About Bridge RNAs? Approaches to Multiplex Gene Editing Who’s Doing Multiplex Gene Editing? Ok, What About Highly Polygenic Traits? None 6 comments
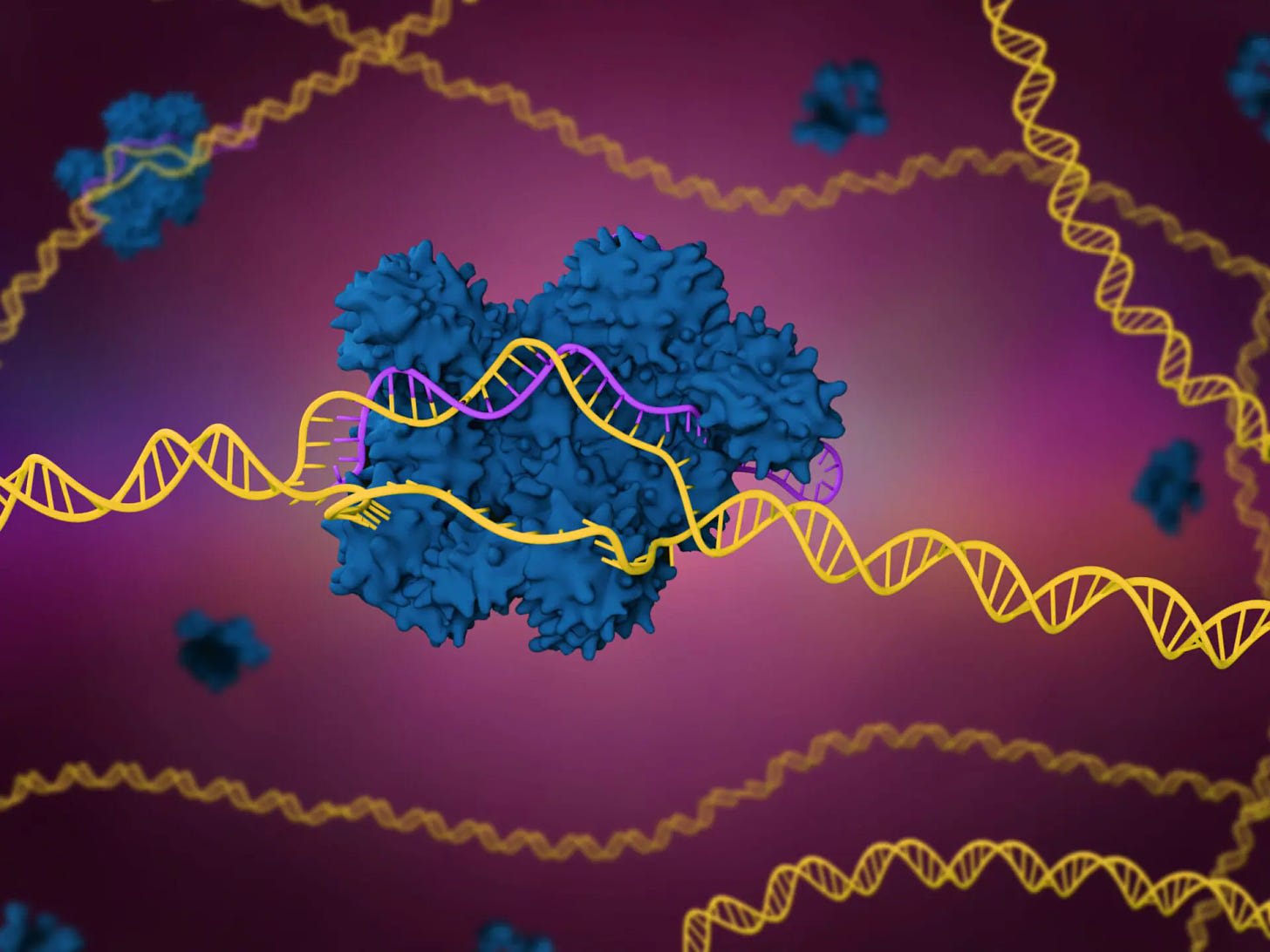
We’re starting to get working gene therapies for single-mutation genetic disorders, and genetically modified cell therapies for attacking cancer.
Some of them use CRISPR-based gene editing, a new technology (that earned Jennifer Doudna and Emmanuelle Charpentier the 2020 Nobel Prize) to “cut” and “paste” a cell’s DNA. But so far, the FDA-approved therapies can only edit one gene at a time.
What if we want to edit more genes? Why is that hard, and how close are we to getting there?
How CRISPR Works
CRISPR is based on a DNA-cutting enzyme (the Cas9 nuclease), a synthetic guide RNA (gRNA), and another bit of RNA (tracrRNA) that’s complementary to the gRNA. Researchers can design whatever guide RNA sequence they want; the gRNA will stick to the complementary part of the target DNA, the tracrRNA will complex with it, and the nuclease will make a cut there.
So, that’s the “cut” part — the “paste” comes from a template DNA sequence, again of the researchers’ choice, which is included along with the CRISPR components.
Usually all these sequences of nucleic acids are packaged in a circular plasmid, which is transfected into cells with nanoparticles or (non-disease-causing) viruses.
So, why can’t you make a CRISPR plasmid with arbitrary many genes to edit?
There are a couple reasons:
- Plasmids can’t be too big or they won’t fit inside the virus or the lipid nanoparticle. Lipid nanoparticles have about a 20,000 base-pair limit; adeno-associated viruses (AAV), the most common type of virus used in gene delivery, has a smaller payload, more like 4700 base pairs.
- This places a very strict restriction on how many complete gene sequences that can be inserted — some genes are millions of base pairs long, and the average gene is thousands!
- but if you’re just making a very short edit to each gene, like a point mutation, or if you’re deleting or inactivating the gene, payload limits aren’t much of a factor.
- DNA damage is bad for cells in high doses, particularly when it involves double-strand breaks. This also places limits on how many simultaneous edits you can do.
- A guide RNA won’t necessarily only bind to a single desired spot on the whole genome; it can also bind elsewhere, producing so-called “off-target” edits. If each guide RNA produces x off-target edits, then naively you’d expect 10 guide RNAs to produce 10x off-target edits…and at some point that’ll reach an unacceptable risk of side effects from randomly screwing up the genome.
- An edit won’t necessarily work every time, on every strand of DNA in every cell. (The rate of successful edits is known as the efficiency). The more edits you try to make, the lower the efficiency will be for getting all edits simultaneously; if each edit is 50% efficient, then two edits will be 25% efficient or (more likely) even less.
None of these issues make it fundamentally impossible to edit multiple genes with CRISPR and associated methods, but they do mean that the more (and bigger) edits you try to make, the greater the chance of failure or unacceptable side effects.
How Base and Prime Editors Work
Base editors are an alternative to CRISPR that don’t involve any DNA cutting; instead, they use a CRISPR-style guide RNA to bind to a target sequence, and then convert a single base pair chemically — they turn a C/G base pair to an A/T, or vice versa.
Without any double-strand breaks, base editors are less toxic to cells and less prone to off-target effects.
The downside is that you can only use base editors to make single-point mutations; they’re no good for large insertions or deletions.
Prime editors, similarly, don’t introduce double-strand breaks; instead, they include an enzyme (“nickase”) that produces a single-strand “nick” in the target DNA, a guide RNA that tells the enzyme where to “nick”, and a template DNA strand that contains the desired sequence. Then the cell’s DNA repair methods fill in a complementary strand to the template DNA. Finally the cell's enzymes also notice a mismatch between the strand with the new template DNA and the old strand without it, and decide that the longer, newer strand is “correct” and connect it back to the main DNA sequence.
Prime editors, like base editors, have all the advantages associated with not producing double-strand breaks, but they also can make small insertions and deletions as well as point mutations.
Base editors and prime editors are experimental but they have been used in vitro to correct real genetic disorders, like the genetic mutation that causes Duchenne Muscular Dystrophy.
Base and prime editors get around Obstacle 2 to multiplex gene editing — with no double-strand breaks, we’re not limited by the associated cell toxicity — and they somewhat reduce Obstacles 3 & 4, since they have fewer off-target effects and higher efficiencies than vanilla CRISPR.
But neither base nor prime editors can insert or delete long sequences of DNA, so for certain applications you still need CRISPR (or a related variant).
What About Bridge RNAs?
Bridge RNAs are a completely new gene editing tool, discovered in June 2024 by Patrick Hsu’s lab at the Arc Institute.
These RNA sequences allow programmable insertion, deletion, and inversion of any string of DNA to any target location in the genome.
It’s early days yet, but they sound like they have the potential to further expand what kinds of edits to the genome are possible.
Approaches to Multiplex Gene Editing
This 2020 review article[1] divides approaches to making multiple CRISPR edits into three categories:
- Arrayed sgRNA expression constructs, which package each guide RNA with its own promoter and terminator regions (so the cell’s transcription machinery will make copies of each guide RNA.)
- CRISPR arrays, which package multiple guide RNAs into a single transcript, to be copied together in long strings and then cut apart by a bacterial enzyme like Cas12a (whose genetic code you also include in the plasmid)
- Synthetic gRNA arrays, where multiple guide RNAs are transcribed together in long strings, separated by sequences that are themselves RNA processing units that cut the string apart; in other words, the transcript chops itself up after being copied.
Basically, it’s not at all hard to get multiplex CRISPR gene editing “at all”.
In fact, in its natural context (bacteria that edit their own genomes to produce heritable immune “memory” of previously encountered virus infections) CRISPR is already multiplex. Bacteria use the “CRISPR array” method, where the guide RNAs are transcribed in long concatenated strings and then chopped apart by enzymes. Some bacteria have over 100 separate guide RNAs.[2]
Back in 2013, Feng Zhang of the Broad Institute (one of the co-inventors of CRISPR) created a CRISPR array that contained two guide RNAs targeting two different genes, resulting in multiplex deletion.
In 2022, Qichen Yuan and Xue Gao (at Rice University), created a tRNA-based method for chopping up a guide RNA sequence into multiple subsequences, for use with both prime and base editors. This resulted in up to 31 loci for base editing and 3 loci for prime editing.
The real question, at this point, isn’t whether we can do it at all, but whether we can do it efficiently enough and safely enough for practical use — in gene therapy, genetically-modified agricultural plants and animals, or gene-edited lab animals.
One example of where we’re at is given in a 2017 paper on T-cells which have been CRISPR edited to knock out one, two, or three genes to make them better at killing cancerous B cells. Each gene edit successfully hit only some of the targeted T-cells (20-80%), and only about 10-20% of cells got all three edits; but triple-knockout T-cells were clearly more effective against cancer cells (both in vitro and in mice) than T-cells with no, or fewer, edits.
Roughly, for each additional gene edit we’re cutting our efficiency in half; but in the right circumstances that’s okay. In this cancer immunotherapy context, a.) cancer is really bad so even a little bit of improvement is often worth it; b.) each gene edit helps independently — it’s not actively *harmful* to have some partially-edited or non-edited cells; c.) there are only three genes edited in the first place, so there’s still an appreciable number of fully triple-edited cells.
In some other disease context, like if there’s a genetic disorder that produces some toxic misfolded protein[3], it’s conceivable that a gene therapy with only 15% efficiency wouldn’t have any effect on symptoms because there’s still too much of the “bad” protein.
Who’s Doing Multiplex Gene Editing?
A number of biotech companies are (publicly) doing clinical or preclinical experiments with gene therapies that involve multiple edits.
Caribou Biosciences, cofounded by CRISPR co-inventor Jennifer Doudna, is working on CAR-T cancer immunotherapies[4] with 3, 4, and 5 gene edits. They’re using CRISPR and they’re in three Phase I clinical trials.
Beam Therapeutics, cofounded by CRISPR co-inventor Feng Zhang, also has a multiplex-edited CAR-T cancer therapy in the clinic, in a Phase I/II trial. This one uses multiple base edits.
Excision BioTherapeutics has clinical trials to treat viral diseases (like HIV) by removing multiple sections of viral DNA with multiplex CRISPR.
Vor Bio has multiplex-edited hematopoietic stem cell therapies for cancer in the preclinical research stage.
Intellia Therapeutics has preclinical research on multiplex gene editing programs for CAR-T therapy.
Usually, as is typical for gene therapy, the focus is on “easy-mode” applications like immunotherapy for blood cancers.
You can genetically modify CAR-T cells in the lab, not in the body; then you just inject them into the patient where they do their work in the bloodstream. Low gene editing efficiency? Too many off-target effects? You can just be selective and only inject the “best,” correctly-edited, CAR-T cells into patients.
But yeah, we are on track to see FDA approval of multiplex gene-editing-based therapies in the next couple of years, where that’s defined as “use of CRISPR or other DNA editors to edit two or more separate gene loci.”
It’ll probably be a CAR-T therapy first, but it could also be a therapy for a genetic disorder in some easy-to-reach tissue (blood, retina, liver), provided that there is an application where getting a small % of cells to have multiple gene edits provides substantial clinical improvement.
Ok, What About Highly Polygenic Traits?
“Fully general” gene editing for treating/preventing a much wider variety of diseases — like “let’s make you less susceptible to heart disease by editing away all your genetic heart disease risk factors” — is obviously much harder, to the point that there doesn’t seem to be active research in this vein at all.
The closest thing I could find to “let’s do massively multiplex gene editing to alter a highly polygenic trait” are in agriculture. Things like this BREEDIT system in maize, where CRISPRing plants to simultaneously knock out 12 growth-related genes resulted in an average 5-10% bigger leaves among the edited plants.
Or, as another example, these multiplex CRISPR edits of wood trees to have a 229% yield increase for paper-making.
In experimental agriculture, it’s fine to use CRISPR to make a genetically diverse population of plants and make crosses between the ones with phenotypes you like. You don’t have to get it right the first time (as you would if this were a gene therapy to make humans taller or less susceptible to disease).
In fact, despite what human geneticists often say about epistasis being minor and rare, plant genetics people seem to find that interactions between genes are a big deal, explaining most (!) of the variance in crop yields.[5] So, if I’m not mistaken, “of all these genetic variants statistically associated with the polygenic trait, what’s the best subset of edits to make, if I want the largest expected impact” is a nontrivial question.[6]
Anyhow, I definitely expect massively-multiplex gene editing for polygenic traits to be a Thing in agriculture long before it is in humans. The practical benefits are immediate, the experiments are tractable, the risks are negligible (by comparison). If this sort of thing can work at all, and I don’t see any reason a priori why it shouldn’t, we’ll see super-high-yield CRISPR’ed crops in the near future.
- ^
McCarty, Nicholas S., et al. "Multiplexed CRISPR technologies for gene editing and transcriptional regulation." Nature communications 11.1 (2020): 1281.
- ^
“In Geobacter sulfureducens a single CRISPR with a 29 bp DR possess one hundred and thirty eight 32 bp-long spacers and three 33 bp-long spacers.”
Grissa, Ibtissem, Gilles Vergnaud, and Christine Pourcel. "The CRISPRdb database and tools to display CRISPRs and to generate dictionaries of spacers and repeats." BMC bioinformatics 8 (2007): 1-10.
- ^
Huntington’s disease is an example of such a disorder
- ^
CAR-T is a cancer treatment that genetically modifies immune cells to be better at attacking cancer cells, and infuses them into the patient. It has an excellent track record in blood cancers.
- ^
eg Li, Ling, et al. "Genetic dissection of epistatic interactions contributing yield-related agronomic traits in rice using the compressed mixed model." Plants 11.19 (2022): 2504.
- ^
In human population genetics, all your studies are observational. My understanding is that the whole “epistasis is no big deal” meme came from GWAS studies, where linear models that assume independence still give you pretty ok predictive results at the population level, and adding nonlinearity doesn’t necessarily improve your accuracy on the same dataset. That shouldn’t be surprising; “don’t overfit, dummy” is, like, lesson #1 of statistics. It’s not in contradiction with the claim that individuals with the “best” subset of k trait-associated alleles can have a much better phenotype on that trait than individuals with k randomly-drawn trait-associated alleles. It just means your GWAS may not be capable of telling you which subsets are “best”. When you’re working with non-human organisms, you can run breeding and gene-editing experiments, which can provide information that simply isn’t in human genetic datasets.
6 comments
Comments sorted by top scores.
comment by GeneSmith · 2024-07-17T05:32:58.642Z · LW(p) · GW(p)
Without any double-strand breaks, base editors are less toxic to cells and less prone to off-target effects.
It's worth noting that most base editors actually DO involve nicking of one strand, which is done after the chemical base alternation to bias the cell towards repairing the non-edited strand.
The editing efficiency of non-nicking base editors is significantly lower than that of nicking versions (though the precise ratio varies depending on the specific edit site)
Finally the cell's enzymes also notice a mismatch between the strand with the new template DNA and the old strand without it, and decide that the longer, newer strand is “correct” and connect it back to the main DNA sequence.
It's worth noting that this only happens some of the time. Often the cell will either fail to ligate the edited strand back together or it will remove the edited bases, undoing the first half of the edit.
In regards to bridge RNAs, I do not yet believe they will work for any human applications. The work in Hsu's paper was all done in prokaryotes. If this tool worked in plants or animals, they would have shown it.
In fact, despite what human geneticists often say about epistasis being minor and rare, plant genetics people seem to find that interactions between genes are a big deal, explaining most (!) of the variance in crop yields.[5] So, if I’m not mistaken, “of all these genetic variants statistically associated with the polygenic trait, what’s the best subset of edits to make, if I want the largest expected impact” is a nontrivial question.[6]
I was curious about the finding of epistatic effects explaining more of the variance than traditionally assumed, so I took a look at the study you referenced and found something worth mentioning.
The study is ludicrously underpowered to detect anything like what they're trying to show. They only have 413 genetically distinct rice plants in the study, compared to 36,901 SNPs.
This study is underpowered to detect even SNPs that have an effect on the trait in question, let alone epistatic effects. So I don't give their results that much weight.
I agree with your overall conclusion though; I think we'll likely see the first applications of polygenic embryo selection in animals (perhaps cows?) before we see it in humans.
comment by bhauth · 2024-07-16T22:37:00.680Z · LW(p) · GW(p)
these multiplex CRISPR edits of wood trees to have a 229% yield increase for paper-making
It's possible to use breeding techniques - and these days, you can do "molecular breeding" - to get a wide range of cellulose-lignin-xylose ratios. Anything outside the naturally existing range is going to be quite bad for plant growth/viability. Also, a 229% increase must have been from a particularly low baseline, much lower than anything currently used for making paper.
This is something I looked into a bit when I was pondering candidates for biomass -> chemical conversion.
comment by bhauth · 2024-07-16T22:33:30.501Z · LW(p) · GW(p)
Note that the "bridge RNA" method doesn't currently work in mammals. The team involved is trying to use AI to edit the enzyme involved so it does, but that might not be workable, due to differences in how DNA is packed and anti-virus defense systems.
Replies from: Metacelsus↑ comment by Metacelsus · 2024-07-17T02:15:57.176Z · LW(p) · GW(p)
Not just mammals, as far as I know it only works in E. coli bacteria and not in any eukaryotes.
Source:
https://www.nature.com/articles/s41586-024-07552-4
Replies from: bhauth