Do Deep Neural Networks Have Brain-like Representations?: A Summary of Disagreements
post by Joseph Emerson (joseph-emerson) · 2024-11-18T00:07:15.155Z · LW · GW · 0 commentsContents
TL;DR Introduction What are representations? Representations in humans and AI How brain-like are representations in modern AI systems? Why it could matter for AI alignment Reasons to think ANNs have brain-like representations ANNs Match Human Behavior and Errors in Several Domains ANNs Predict Brain Responses ANNs and Brains Have Similar Representational Structure ANNs and Biological Brains Share Important Intrinsic Properties Reasons to think ANNs do not have brain-like representations Prediction ≠ Explanation Flawed Logical Inference Failure to Test Hypotheses about Biological Brains Ignoring Disconfirmatory Evidence Some Responses Ambiguity in Defining and Measuring Representations Assessment of Brain-ANN Alignment Varies Enormously by Similarity Metric Newman’s Objection ANNs and Brains are Fundamentally Different LLMs Lack Symbolic Linguistic Structures Differences in Structure between ANNs and Brains are Unbridgable How do these disagreements bear on concerns about AI alignment? Conclusion None No comments
Acknowledgments: Thanks to SPAR summer 2024 and the Promisingness of Automating AI Alignment group, particularly the supervisor for this project, Bogdan-Ionut Cirstea, for his feedback.
This post began as a write up of my review of neuro-AI literature for the Promisingness of Automating AI Alignment. After returning to the document to make some updates, I decided it’s worth posting despite the absence of strong conclusions.
TL;DR
Do artificial neural networks form representations similar to those used by biological brains? If so, it could be important to consider implications for AI alignment, such as understanding how brain-AI alignment impacts the difficulty of ontology identification in AI systems. I looked at the empirical case for representation alignment between brains and AI. I found that there is a large degree of disagreement over how to correctly measure and compare representations and how to interpret available correlational measures of human brain activity and model internals. I think available empirical data provides only weak evidence that brains and current AI systems naturally converge on common representations. I expect that the field of neuro-AI is already on track to resolve some of these disagreements on the empirical side by extending beyond correlational metrics and benchmarks of representation alignment.
Introduction
What are representations?
In cognitive and computational systems, representations are internal information-bearing structures that correspond to parts of or abstractions about the external world. These representations are important because they allow the systems to process, interpret, and manipulate information internally, which enables complex downstream behaviors.
Representations in humans and AI
Both humans and many machine learning systems utilize internal representations of their sensory inputs. In brains, ensembles of neurons activate selectively and reliably to specific sensory features. Similarly, features are encoded in artificial neural networks (ANNs) by patterns of hidden unit activations (often[1]) corresponding to directions in the hidden unit space. The encoding of features as directions in hidden unit space is perhaps even analogous to how brains encode features on neural manifolds (Chung and Abbott, 2021).
One could imagine a scenario in which every primitive object present in the external world is represented as a discrete entity in a brain or an ANN. But because brains and many machine learning systems are embedded in a very complex external reality, and because they are by comparison much smaller and simpler than external reality, systems in the real world need to make some simplifications. So for systems operating in the real world, their representations are necessarily lower-resolution abstractions about the physical world. These lower-resolution abstractions efficiently encode a great deal of useful information needed for the system to accomplish tasks. While the mechanisms underlying representations undoubtedly differ, both brains and machine learning systems must form representations that chunk up and compress external reality into simpler lower-dimensional spaces.
How brain-like are representations in modern AI systems?
Now consider the problem of embedding high-dimensional reality into a low-dimensional latent space that is faced by brains and machine learning systems. There are multiple possible mappings between the external world and virtually any representation space. For example, when we view an image of an apple, our brains encode sensory features like its shape (round) and color (red or green). These features help us recognize the image as an apple. When an image of an apple is shown to a convolutional neural network (CNN), it also creates an internal representation by detecting patterns in the image. However, CNNs are known for their reliance on texture features (e.g., the apple's smooth surface) rather than on shape (Geirhos et al., 2018), which is different from how humans prioritize shape for recognizing objects. Given the possibility of multiple representational systems, how similar are the internal representations formed by ANNs and the brain? I’ll call the level of similarity between brain and ANN representations as the degree of representation alignment.
I wanted to understand the main points of disagreement (and possibly consensus) on this question and their possible implications for AI alignment, so I went through some of the literature from the fields neuro-AI and cognitive computational neuroscience to identify what is currently known on this topic. The focus of this post is primarily to summarize what I see as the main disagreements among experts on the topic of brain-ANN representation alignment, centering focus on empirical evidence.
Why it could matter for AI alignment
I think there are multiple reasons why alignment researchers should care about whether ANNs and human brains converge on similar representations. I’ll list a few here, but I suspect there could be other applications as well.
- Ontology Identification: If AIs and humans have strongly overlapping representations, mapping human values/intentions to the world models of AI might be much easier than if otherwise. Conversely, if AIs and humans show significant differences in the way they model the world, it may be significantly harder to find mappings between human and AI world models (see “the pointers problem” [AF · GW] and “ontology identification”). Understanding representation alignment between humans and AIs seems like a step toward understanding the alignment between human and AI world models. Whether this is in fact a critical consideration for alignment definitely deserves further consideration and should be explored in depth elsewhere.
- Natural Abstractions: The degree of representation alignment between brains and AIs may provide further evidence for or against the natural abstractions hypothesis [? · GW] (NAH) – i.e. that the world tends to decompose into natural low-dimensional summaries that are used by most or all cognitive architectures. I separate this point from the above on ontology identification, because it makes stronger claims and has some different implications. Specifically, the NAH states that representational convergence is a function of the structure of the world rather than the specific properties of cognitive architectures. Therefore, I think this question demands a higher bar for confirmatory evidence, but would have broader implications for alignment than for instance discovering that a particular kind of cognitive architecture shares similarities with humans in the ways they represent the world.
- Neuralignment Research Directions: I think determining the extent of brain-AI representation alignment could also have implications for some of the more speculative research directions in neuralignment, i.e. the project of using neuroscience or neurotechnology to help solve alignment. For instance, answering the representation question might impact our assessment of the feasibility of designing steering vectors from human neural data.
Reasons to think ANNs have brain-like representations
The last decade has seen a surge of experiments showing interesting correlations between ANNs and human brains along with the emergence of a movement within the cognitive sciences that advocates for the use of ANNs as models for biological brains and minds. ANNs have been found to be such good predictors of brains that they are often considered leading models of certain kinds of brain function, especially in vision and more recently in language processing. Some have championed these results as evidence that ANNs converge on brain-like representations and algorithms. In the following sections I list a few broad findings from this literature that proponents argue suggest that ANNs already have strong representation alignment with brains.
ANNs Match Human Behavior and Errors in Several Domains
ANNs are currently the only models that can match human behavior in such a wide range of domains. Certain models can also produce the same kinds of errors that humans produce (e.g. Geirhos et al., 2021; Tuli et al., 2021; Lampinen et al., 2024) (although the general degree of error consistency between humans and models is contested; see Geirhos, Meding, and Wichmann, 2020 and Tjuatja et al., 2024).
ANNs Predict Brain Responses
ANNs are also the best models for predicting population-level brain responses in humans as measured with various brain imaging methods (e.g. fMRI Schrimpf et al., 2018 and Schrimpf et al., 2021) as well as individual neuron responses in animals (e.g. macaque Marques, Schrimpf, and DiCarlo, 2021). Encoding models that utilize features from ANNs have been shown to predict fMRI responses to visual and language stimuli with accuracy approaching the noise ceiling for fMRI (Kriegeskorte, 2015; Schrimpf et al., 2021). There is also a relationship between LLM scale and encoding model performance on fMRI data with larger models better predicting brain responses to language stimuli (Antonello et al., 2024).
ANNs and Brains Have Similar Representational Structure
Rather than looking at prediction, Representational Similarity Analysis (RSA) aims to directly compare the structure of representations between systems (Kriegeskorte, Mur, and Bandettini, 2008). For a given set of things to be represented, RSA uses distances in the embedding space of brains, ANNs, or other systems to construct representation graphs for each system. Then the correlation between the adjacency matrices can be used to assess the similarity of the representational geometry. The advantage of this approach is that it can compare representations between highly dissimilar systems without the need for a 1-1 mapping between the components of the systems. Various ANNs get high RSA scores with brains in various domains including vision (e.g. Conwell et al., 2022) and language processing (e.g. Kauf et al., 2024).
ANNs and Biological Brains Share Important Intrinsic Properties
There may be reasons a priori to expect that brains and ANNs would learn similar representations. Doerig et al. (2023) introduce the Neuroconnectionist Research Programme which aims to promote a theory of cognition that uses ANNs as the computational basis for expressing falsifiable theories. In their paper, they point out a few reasons why ANNs are well-suited to form a computational language of brain function:
- ANNs are built from many units that perform simple computations and collectively drive behavior, and therefore have the potential to model the single-unit to behavior spectrum, a major goal of brain sciences
- ANNs learn iteratively over time by optimizing connections between computational units thereby providing a plausible model for development.
- ANNs provide a link from sensation to cognition to action by its grounding in raw sensory input to accomplish tasks without the need for human-generated features.
- The flexibility of ANNs allows for the comparison of the interactions of different architectures and learning rules, providing a means for exploring what features are necessary for learning and cognition.
Tuckute, Kanwisher, and Fedorenko (2024) point to a similar set of properties of language models to defend their use as candidate models for human language processing:
- Prediction as a training signal mirrors observations that the human language system is engaged in language prediction during comprehension.
- Language models acquire detailed syntactic knowledge, allowing for strong generative capacities.
- Language models are sensitive to multiple levels of language including sub-lexical regularities, word forms, semantics, sentence structure, and meaning, and like humans, language models syntactic and semantic levels are not compartmentalized separately.
- Language processing systems are distinct from reasoning and knowledge systems in human brains, which is consistent with the observation that human-level language performance in language models does not entail human-level reasoning.
While certainly not sufficient criteria for the claim that ANNs and brains have similar representations, these features of ANNs provide some basis for why we might expect them to be brain-like.
In addition to a priori reasons to anticipate brain-ANN representation alignment, there is some empirical evidence that ANNs may share certain computational principles with brains. Specifically, performance of transformer language models on next-word/token prediction is a good predictor of performance in predicting brain responses (Schrimpf et al., 2021, Goldstein et al., 2022). Prediction-error signals in both brains and transformer language models depend on the pre-onset confidence in the next-word/token prediction (Goldstein et al., 2022). Furthermore, enhancing predictions in transformers models with predictions that bridge multiple timescales in human speech data improves model predictions of brain activity and reveals a hierarchical predictive coding algorithm in the brain (Caucheteux et al., 2023). All of these suggest that transformers and brains may use similar kinds of predictive coding algorithms in language processing. Similar conclusions may well translate to other domains such as vision where transformers have also been found to outperform other architectures in predicting brain responses and human errors (Tuli et al., 2021). If certain ANNs and brains in fact share common computational principles, we might expect these systems to learn similar representations given sufficiently similar training data.
Reasons to think ANNs do not have brain-like representations
There is a significant amount of disagreement over whether the previously identified lines of evidence provide satisfactory justification for strong representation alignment between brains and ANNs. Many of these cited articles focus on slightly different questions, namely whether ANNs should be regarded as good or accurate models of brains or certain subsystems in the brain. But nevertheless, I find these discussions informative, because they often highlight important considerations for approaching the question of representation alignment.
This is of course a very incomplete sampling of the literature discussing comparisons between brains and ANNs, but given the breadth of some of these reviews, I think they do provide a pretty representative sample of critical perspectives. In the following sections I list what I see as the major categories of criticism of the neuro-AI literature, specifically on interpretations that suggest alignment between brains and ANNs.
Prediction ≠ Explanation
As described above, much of the evidence that ANNs and brains use similar representations comes from the observation that ANNs correlate with human behavior and brain activity across many domains. This evidence has been used to support claims that ANNs are implementing or approximating certain aspects of brain function. Several authors have pushed back by asserting that the kinds of evidence we have on ANN-brain comparisons are insufficient to provide strong support for these kinds of claims. In this section, I focus on a couple iterations of this objection and some responses to it.
Flawed Logical Inference
Guest and Martin (2023) take issue with inferences drawn about the brain specifically from correlation-based comparisons to ANNs. They argue that in the absence of an explicit metatheoretical calculus, i.e. a formal description for how to adjudicate between different theories in a given field, it is unclear what inferences can be justified on the basis of correlational evidence between brains and ANNs. They explain that this lack of reference to an explicit metatheoretical calculus has led to much confusion in the field of cognitive computational neuroscience (CCN) on the role of models. The basic argument is the following: 1) A metatheoretical calculus for CCN should retain the concept of multiple realizability of function in cognitive systems; 2) It is also the case that the field of CCN accepts the statement that if models implement the same mechanisms as brains, they will predict/correlate with brains; 3) Given the principle of multiple realizability, it does not follow that if models predict/correlate with brains, that they implement the same mechanisms as brains. In inverting the causal structure of arguments, researchers are left to commit the logical fallacy of affirming the consequent.
Guest and Martin’s argument
Guest and Martin ask what syllogisms, i.e. arguments of the form "A is B. C is A. Therefore C is B.”, are valid given their metatheoretical calculus. Syllogisms that "obtain" are those that are possible to judge as true or false given a specific metatheoretical calculus. In the fields of neuro-AI and cognitive computational neuroscience (CCN), the kind of syllogism that can obtain given the metatheoretical calculus CCN commits to is
If models do what brains do, then models predict brains (Q→P).
Models do what brains do (Q).
Therefore, models predict brains (⊢P).
But instead of using the former syllogism, researchers in CCN often use (explicitly or implicitly) a different syllogism:
If models predict brains, then models do what brains do (P→Q).
Models predict brains (P).
Therefore, models do what brains do (⊢Q).
This cannot obtain given the principle of multiple realizability which the field already commits to, i.e. brain functions can be instantiated using multiple possible mechanisms. Since it is possible that multiple mechanisms can instantiate brain function in a given domain, the causality of the conditional (Q→P) cannot be reversed. This invalid reversal of the causal structure between models and brains leads to the logical fallacy called “affirming the consequent”.
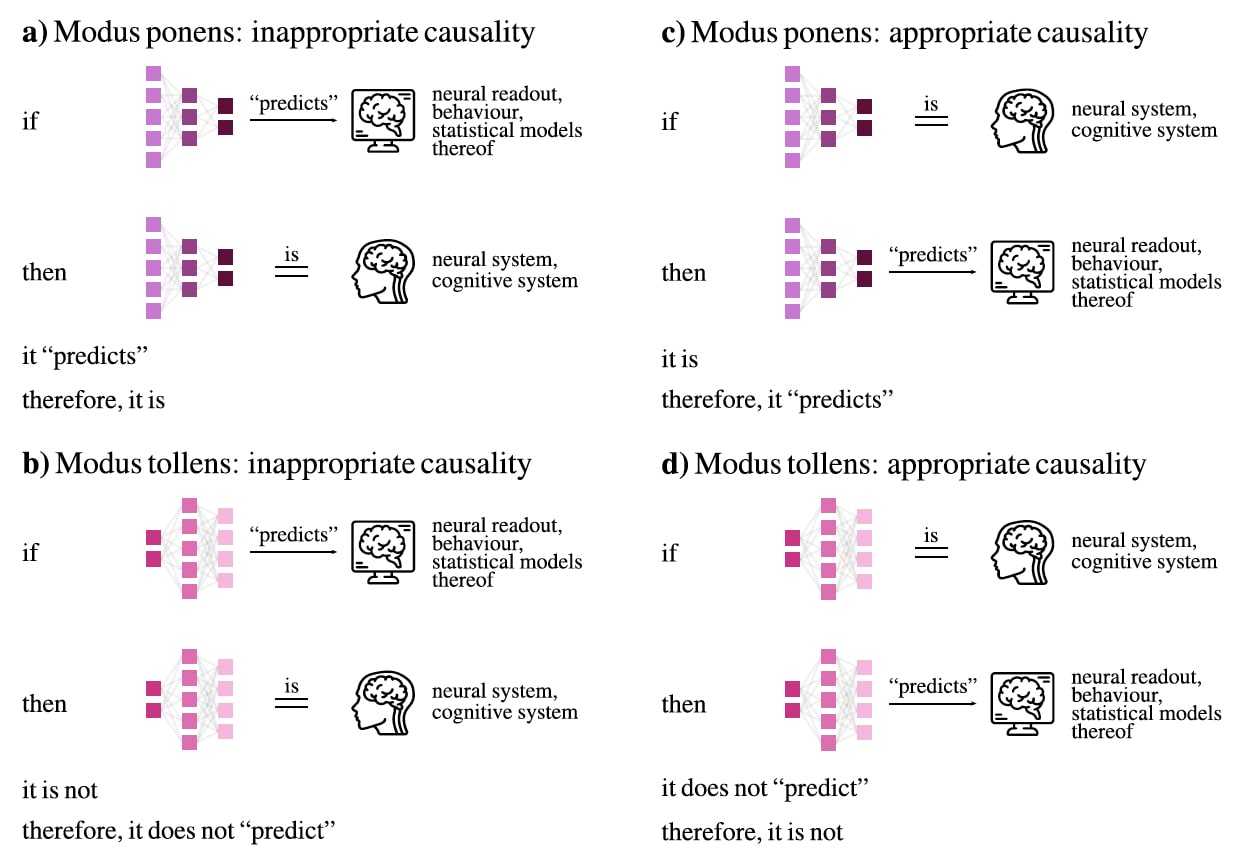
So what does this imply for the field of CCN? We find that ANNs correlate with human brain data/behavior. We cannot use P→Q to deduce from this evidence that ANNs do the same things that brains do. What is the remedy? Guest and Martin suggest the following:
"… models must relate to the phenomenon they purport to explain in ways that obtain. The models resemble the phenomena because they indeed somehow capture (our beliefs about) the essence of the phenomena, and not vice versa, i.e., models are not capturing the essence because they are correlated with the phenomenon."
So in addition to correlation, we must posit specific relationships between models and brains that capture our beliefs about brain function. That is, if we think that mechanism X is responsible for phenomenon Y, our model should have mechanism X. If the model then correlates with the brain doing phenomenon Y, this is now evidence that the model does what the brain does.
Do the properties of ANNs already capture our beliefs about brain function?
Guest and Martin’s conclusion puts the emphasis on identifying mechanisms that lead to correlations rather than inferring mechanisms from correlations. Are there plausible mechanisms common to brains and ANN that could provide justification for brain-ANN alignment? Guest and Martin invite cognitive scientists to be explicit about the properties of ANNs and brains that suggest common mechanisms.
Recently, some cognitive scientists have recognized a need to be explicit about why we should expect ANNs to capture something useful about brain function. For example Tuckute, Kanwisher, and Fedorenko (2024) list four reasons to expect language models to capture important aspects of human language processing. Doerig et al. (2023) lists a similar set of four points to demonstrate why ANNs are well-suited to modeling brain function in general.
However, as of their 2023 publication, Guest and Martin are skeptical of attempts to identify common properties in brains and ANNs post hoc. Some of the properties that have been suggested to link ANN and brain function may be too generic to be useful (e.g. forming tessellated linear mappings, or diffracted hyperplanes, between input and output spaces[2]). Guest and Martin also criticize assertions about the biological plausibility of the mechanisms used by ANNs. The problem with these assertions is that biological mechanisms are not agreed upon and are indeed the subject of inquiry in CCN. Guest and Martin see appeals to biological plausibility as weak justification without more rigorously defining the concept of “plausibility”.
Failure to Test Hypotheses about Biological Brains
Bowers et al. (2022) make similar criticisms of the neuro-AI field as Guest and Martin (2023), but focus more on disconfirmatory evidence. While the criticism paper was leveled at a slightly more specific claim (that ANNs are the best models of biological vision), I think the article and ensuing discussion are useful for understanding the diverse range of expert opinions on the topic.
The authors lay out three reasons that people claim that ANNs are the best models of biological vision:
- “DNNs are more accurate than any other model in classifying images taken from various datasets”
- “DNNs do the best job in predicting the pattern of human errors in classifying objects taken from various behavioral datasets”
- “DNNs do the best job in predicting brain signals in response to images taken from various brain datasets (e.g., single cell responses or fMRI data)”
In their rebuttal, Bowers et al. (2022) suggest that these reasons are insufficient to support the claim that ANNs (specifically deep neural networks, DNNs) provide the best models for biological vision, because they do not test hypotheses about what features contribute to the performance of DNNs. In the absence of carefully controlled experiments with specific hypotheses, they argue that researchers are left to draw inappropriately broad conclusions from correlations which may or may not reflect an underlying mechanistic convergence between brains and ANNs.
Bowers et al. are particularly critical of brain-ANN alignment benchmarks. To name one example, Brain-Score is a benchmark that evaluates ANNs on its ability to predict neural activity (Schrimpf et al., 2020). However, neural predictive scores like Brain-Score can be sensitive to confounds in the data or other factors about ANNs that are not relevant for modeling the brain. For instance, ANNs that use texture features for object classification (Geirhos et al., 2015) may also use texture features to predict shape representations in human neural data, since texture and shape are often correlated in natural images. These ANNs may achieve high Brain-Score without matching the inductive biases of brains. Furthermore, Elmoznino and Bonner (2024) show that high effective latent dimensionality in ANNs correlates strongly with Brain-Score. Since it is not obvious that models with higher latent dimensionality should have more brain-like representations, this calls into question the utility of Brain-Score.
Ignoring Disconfirmatory Evidence
Recall the syllogism from Guest and Martin (2023):
If models predict brains, then models do what brains do (P→Q).
Models predict brains (P).
Therefore, models do what brains do (⊢Q).
In forming this argument, we are using modus ponens (P→Q, P⊢Q). Guest and Martin show that in accepting modus ponens, we implicitly endorse the equivalent modus tollens argument (P→Q, ¬Q⊢¬P). That is if we accept “if models predict brains (P), then models do what brains do (Q)”, we must also accept that if models do not do what brains do, then they must not predict brains. Of course, we reject this kind of argument, because there are many cases where models do things that the brain cannot (e.g. having superhuman memory), but we do not take this as evidence that the model is not capturing something about human intelligence and models with these properties are often able to predict brain responses. Therefore, if we are to apply modus ponens we have to be equally prepared to apply modus tollens. Since modus tollens seems untenable, we should reject both.
But even without considering the modus tollens framework, disconfirmatory evidence should be taken into account when addressing the question of representation alignment. Bowers et al. point to a number of ways in which ANNs do not predict human vision. These reasons include:
- ANNs being highly susceptible to adversarial attacks in ways that humans are not (Dujmovic, Malhotra, and Bowers, 2020)
- ANNs using texture rather than shape for classification (Geirhos et al., 2019; Geirhos, Meding, and Wichmann, 2020; Huber, Geirhos, and Wichmann, 2022; Malhotra, Dujmovic, and Bowers, 2022)
- ANNs using local rather than global information for classification (Baker et al., 2018)
- ANNs ignoring relations between different parts of images (Malhotra et al., 2021)
- ANNs failing to distinguish between boundaries and surfaces
- ANNs failing to show uncrowding
- ANNs being poor at identifying images that are degraded or deformed (Alcorn et al., 2018; Geirhos et al., 2020; Geirhos et al., 2021; Wang et al., 2018; Zhu et al., 2019)
- ANNs having a superhuman capacity for classifying unstructured data (Zhang et al., 2017)
- ANNs not accounting for human similarity judgements of 3D objects (German and Jacobs, 2020; Erdogan and Jacobs, 2017)
- Classification precedes detection and localization in ANNs (Redmon et al., 2016; Zhao et al., 2019) but not humans (Bowers and Jones, 2007; Mack et al., 2008)
- ANNs fail in same/different reasoning (Puebla and Bowers, 2022)
- ANNs are poor at visual combinatorial generalization (Montero et al., 2022a; Montero et al., 2022b)
- Various other differences found by Jacob et al. (2021)
Bowers et al. conclude that these examples show that it is far from clear that ANNs are good models of vision. Their proposed remedy is to build models that target specific hypotheses about brain function by incorporating plausible mechanisms in the models, which was previously the standard for modeling in vision science.
Some Responses
Bowers et al. (2022) was published with open peer commentary which was highly valuable for assessing the positions of scientists in the field. I found there to be a large degree of consistency in agreement that modern ANNs are not perfect models of the brain. However, opinions tended to diverge on the reasons why ANNs are not perfect models. I tend to see two groups. The first group sees the failures of ANNs to capture some but not all aspects of human vision as likely the consequence of relatively small differences in how the models are trained and designed. The second group sees these failures as indicative of a fundamental disconnect between the ways ANNs and brains function. I am probably oversimplifying in cleanly drawing a division into two camps, but I think this framing helps to identify the source of disagreement.
This statement made by de Vries et al. seems to pretty well encapsulate the perspective of the pro-ANN group:
"Naturally, shortcomings, such as a reliance on correlation-based comparisons and strong divergences from human object processing should be addressed. However, we believe these shortcomings will prove predominantly temporary in nature, as they are already being taken into account in several recent studies. As such, where Bowers et al. take issue with using object-trained DNNs, we see opportunity."
The pro-ANN group also appears to advocate for ANN-based models on the basis that ANNs are universal function approximators and therefore are highly versatile at articulating hypotheses. For example Golan et al. write:
"Importantly, however, the failure of current ANNs to explain all available data does not amount to a refutation of neural network models in general. Falsifying the entire, highly expressive class of ANN models is impossible. ANNs are universal approximators of dynamical systems (Funahashi and Nakamura, 1993; Schäfer and Zimmermann, 2007) and hence can implement any potential computational mechanism. Future ANNs may contain different computational mechanisms that have not yet been explored. ANNs therefore are best understood not as a monolithic falsifiable theory but as a computational language in which particular falsifiable hypotheses can be expressed."
Several authors provide specific points for which they believe current deviations between brains and ANNs arise. German and Jacobs point out that generative models tend to perform better at representing both global and local features in images and that properly constrained generative models can replicate human behavioral biases and learn representations that rely on understanding images as a composition of parts. Responses by Hermann et al. as well as Linsley and Serre emphasize that humans and ANNs are usually not trained on similar tasks, hypothesizing that changing the tasks that ANNs are trained on could bridge many of the gaps currently observed between human and ANN behaviors. Other authors suggest that more radical changes to the current paradigm for machine learning may be necessary to achieve accurate models of human brain function. These include integrating deep neural networks with neurosymbolic approaches (Kellman et al., 2022),
These views contrast sharply with the reply from Bevers et al. who make the case for why ANNs are fundamentally inadequate for modeling language:
"Why not focus on attempts to organize and constrain DNNs and other types of models so they comport with what we already know about language, language learning, language representations, and language behaviors? The answer for DNNs is also their touted practical virtue, they learn from actual text, free of hand tailored structural analysis. This engineering virtue pyrrhically underlies why they are doomed to be largely useless models for psychological research on language."
In a similar vein Moshe Gur disputes explicitly modeling the brain as a computational system writing:
"Deep neural networks (DNNs) are not just inadequate models of the visual system but are so different in their structure and functionality that they are not even on the same playing field. DNN units have almost nothing in common with neurons, and, unlike visual neurons, they are often fully connected. At best, DNNs can label inputs, while our object perception is both holistic and detail preserving. A feat that no computational system can achieve."
More on these views to follow in “ANNs and Brains are Fundamentally Different”.
Closed-loop Paradigms
Recently, researchers have been using closed-loop paradigms that use ANN-predictions of neural data to generate novel stimuli that maximally drive or suppress brain responses (Bashivan et al., 2019; Ponce et al., 2019; Gu et al., 2023; Murty et al., 2021; Tuckute et al., 2023; Tuckute et al., 2024). For example, Tuckute et al. (2024) use a GPT-based encoding model for human fMRI responses to language stimuli and find that the encoding model is capable of predicting new sentences that drive and suppress specific language areas in new subjects.
Does the closed-loop approach address any of the concerns raised by the “prediction is not explanation” critique of neuro-AI literature? When compared to purely prediction-based or correlational measures like Brain-Score and RSA, the closed loop method seems clearly superior, because it demonstrates that the stimulus features that model uses to predict neural responses generalize beyond the training set and can be turned up or down to control brain responses. This certainly aids in understanding brain function by discovering stimulus features that drive specific brain networks and provides powerful new tool for generating hypotheses. But what does this have to say about the representations of LLMs and how they relate to brains?
One of the concerns raised by Bowers et al. was the presence of confounds in the data used to train models, that is when two features are correlated, representation of one feature can predict the other. Presumably, this approach could avoid confounds by amplifying the feature that is represented by the ANN, for instance a texture feature in a convolution neural network. If the model is not relying on the same features as brains, then the model-directed stimuli will not elicit the predicted response.
However, I worry that conclusions of this kind depend on some assumptions about the stimulus generation process, specifically that features are able to be decoupled. In Tuckute et al., the generation process is actually done by sampling from a large unseen corpus of stimuli and ranking their predicted elicitation of fMRI responses. While these stimuli remain outside the training set, they may continue to contain certain confounds if they are sampled from the same distribution as the training set. Other methods, like that of Ponce et al., 2019, generate new stimuli using generative models. However, this method still could preserve confounds in the training data distribution if the generative models themselves are unable to decouple features perhaps as a consequence of pretraining. I think the crux comes down to generalization via interpolation vs generalization via extrapolation. If models are representing stimuli similarly to brains, then we expect it to generalize when we extrapolate away from the training distribution. To me, it is unclear whether current methods are extrapolating outside the training distribution or are simply interpolating within the distribution.
Another concern raised by both Bowers et al. and Guest and Martin are that correlation and prediction is insufficient for explanation given the principle of multiple realizability. Does a closed-loop framework solve this problem? I don’t think it completely addresses this concern, but it is moving in the right direction. Finding that ANN and brain responses correlate leaves open the possibility that any mechanism approximating brain function could be used by ANNs. Since we take this space to be large, this doesn’t provide strong evidence that ANNs are doing what brains do. However, there are presumably fewer models that generalize well when predicting new data that drive neural responses, therefore this provides stronger evidence.
Ambiguity in Defining and Measuring Representations
Dujmovic et al. (2022) discuss difficulties in interpreting representational similarity analysis (RSA). RSA works by first measuring the distance between representations within different systems (i.e. representational dissimilarity matrices or RDMs), then measuring the similarity between these distances. This allows RSA to be architecture agnostic.
Despite its advantages, RSA can be subject to confounds and difficult to interpret. Dujmovic et al. describe two problems with RSA, the mimic effect and the modulation effect. In the mimic effect, two dissimilar systems may appear to have similar representational geometries if the input features contain confounds that can be exploited by different encoding mechanisms. In the modulation effect, the RSA analysis depends on the specific sampling of data used, yielding high similarity measures for some samplings and low similarity measures for other samplings.
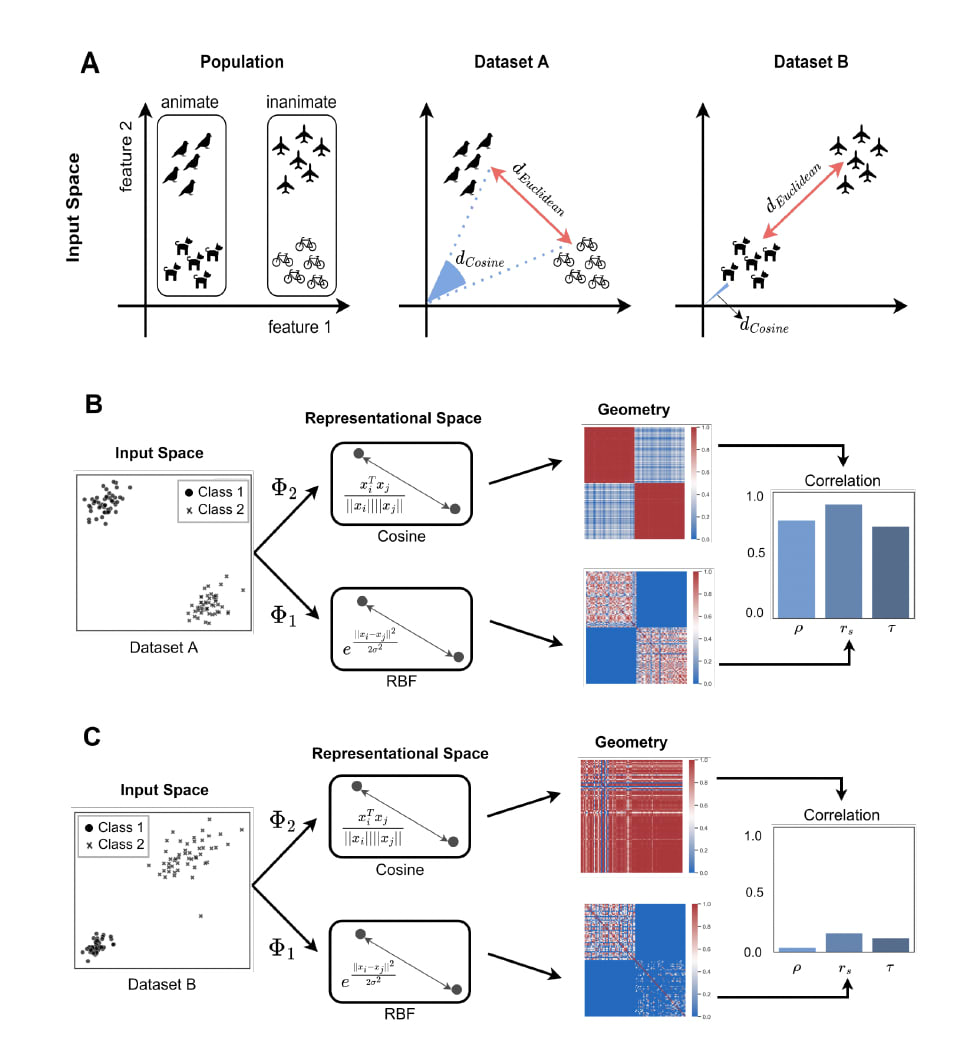
The mimic effect is a problem for the externalist view of representation, in which representations are defined by their relationship to the external world. Those that hold the holistic view of representations can avoid the effect of mimicry by defining representations by their relationships within the representational graph. In this way, representations become equivalent to their geometry. But holists still must contend with the modulation effect to explain why representational geometry measurements can depend strongly on the sampling of the input space.
Are there ways to salvage RSA? Cross-validation and counter-balancing can help correct for confounds at the category level, but cannot correct for confounds at the second-order level (mimicking the similarity structure). Currently, there are no statistical tools that can be used to correct for these kinds of confounds.
Assessment of Brain-ANN Alignment Varies Enormously by Similarity Metric
RSA is not the only analysis that can be used to compare the structural similarity of different representational graphs. For instance, Procrustes analysis, a method that uses affine transformations to align graphs, has been used in computational linguistics since Hurley and Cattle (1962). I suspect that many of these alternatives are prey to many of the same objections as RSA, however.
Furthermore, it is unclear how to assess the reliability of different similarity metrics due to lack of agreement on a ground-truth for similarity. Several authors have noted that comparisons between ANNs and brains vary wildly depending on the similarity metric that is used (Conwell et al., 2022; Soni et al., 2024). Conclusions made on the basis of any one similarity metric are therefore very fragile. One recent paper that created a benchmark to compare similarity metrics head-to-head found that all metrics tested have extremely high variation across different methods of grounding similarity and no measure seemed to be obviously best across all domains (Klabunde et al, 2024). This seems to suggest that the choice of similarity metric matters a lot, providing widely different assessments of similarity that also depend on the task domain.
Newman’s Objection
Newman’s objection, originally a response to Russellian structural realism, implies that for any representational graph, e.g. a nearest-neighbor graph, there trivially exists a relation between the representational graph and what is represented that induces a graph isomorphism (Newman, 1928). In other words, Newman argues that knowledge of the structure of representations alone cannot provide knowledge about the things they are representing, because the same structure can be found for many possible configurations of the world (i.e. swapping around the entities in the graph produces the same structure). Therefore, some philosophers argue that isomorphisms between representational systems can be easy to find and can trivialize the notions of representation and meaning.
However, this objection holds only if the relations are not properly restricted (Carnap, 1968). Li et al. (2023) argue that if the relations (distances in vector space) serve a functional purpose, structural similarities can ground content. In particular, this is true when asking whether two specific representation systems have the same structure. While it is trivial that there exists a graph isomorphism for some other relation, it is not trivial that there exist graph isomorphisms between two specific relations (e.g. the nearest neighbor graph of word embeddings in an LLM and nearest neighbor graph neural responses to words). Therefore, similarity in structure between relations does suggest a similar grounding for representations.
ANNs and Brains are Fundamentally Different
I think there’s a third class of criticisms that asserts that fundamental differences between ANNs and brains preclude valid comparisons between the two. These criticisms seem especially present in the language domain where some cognitive scientists claim that LLMs fail to use in the same sense that humans do.
LLMs Lack Symbolic Linguistic Structures
Thomas G. Bever, Noam Chomsky, Sandiway Fong and Massimo Piattelli-Palmarini wrote a response to Bowers et al. (2022) suggesting an even deeper disconnect between ANNs and biological brains. They argue that ANNs, despite their ability to process vast amounts of data, lack the inductive biases that humans possess, which allow children to acquire complex language skills from limited exposure. They emphasize that human language is characterized by hierarchical categories and discrete structural elements, enabling infinite combinations, whereas ANNs, trained on continuous data without these innate structures, fail to capture this essential aspect of language. To support these claims, they point to the specific failure modes of models that demonstrate the lack of understanding of certain linguistic relations in modern language models. For example:
Consider “The white rabbit jumped from behind the bushes. The animal looked around and then he ran away.” For both humans and ChatGPT, he, the animal and white rabbit are preferred to be the same. But if the sentences are reversed in order, only humans then treat “rabbit” as a different entity from “animal,” revealing a fundamental principle of anaphoric relations.
While language models are successful in language use (performance), they argue that they fail to attain a deep knowledge of language (competence). This appears in the failures of ANNs to generalize linguistic rules in ways consistent with human cognition, sometimes learning rules that do not exist in any natural language.
To my understanding, the thrust of this argument seems to be that ANNs are not actually doing the things that brains do. Therefore, comparisons of the systems are unwarranted and unjustified. By analogy, this might be like asking if parrots have similar semantic representations of words as humans. Parrots can process and replicate human speech (performance). But they are not in any sense using language because they fail to understand or compose language as humans do (competence).
Differences in Structure between ANNs and Brains are Unbridgable
Moshe Gur wrote a response to Bowers et al. (2022) arguing that ANNs are so vastly different from brains, that they cannot possibly be useful as models of the brain. Gur explains how human perception is holistic and simultaneously detail-preserving. That is, humans can simultaneously identify the following image as a turtle and that it is composed of small circles.

Gur interprets this ability of the human visual system as following from its highly recurrent visual system. His claim at the time of writing this critique in 2022 is that ANNs do not have the functional capacity to represent objects simultaneously at multiple levels of abstraction. In fact, Gur goes further and states that this cannot be achieved by any computational system, presumably implying that theories of the brain need to move beyond computation to explain perceptual experience. Unfortunately, this wasn’t explored further in the article.
How do these disagreements bear on concerns about AI alignment?
In summary, we’d like to know if ANNs (and which ANNs) exhibit brain-like representations, because it might give us some useful insights into AI-alignment-relevant questions such as 1) “does the world naturally decompose into high-level abstract structures in a particular way?” (i.e. the natural abstractions hypothesis), 2) “regardless of the answer to question 1, do humans and ANNs specifically tend to converge on similar ways of parsing and modeling the world?” (relating to ontology identification), and more speculative questions like 3) “might we be able to directly port representations from human minds to ANNs?”. At first glance, the neuro-AI literature seems to show promising signs that brains and ANNs actually represent information in quite similar ways. However, there are still some major obstacles, namely moving beyond correlation as the sole method for comparing brains and ANNs and clearing up conceptual and practical difficulties in measuring and assessing representation alignment.
How strong is current evidence on this question given these obstacles? There does seem to be at least some evidence that brains and ANNs are converging on similar representations. I think the strongest evidence comes from causal interventions on brains, but we should consider the preponderance of correlational results to be at least weak evidence of a general trend toward brain-aligned representations in vision and language models. This evidence falls far short of justifying any strong claims about the convergence of brain and AI representations. I would certainly hesitate to make any major decisions on the basis of this evidence alone.
Looking more closely at the criticisms of existing neuro-AI research, the two things that seem to cast the most doubt on the strength of current evidence are, generally speaking, the neuro-AI field’s preoccupation with prediction over explanation and the significant unresolved issues surrounding the nature of mental representation. In fairness, the field’s focus on prediction probably extends from the fact that most of the low-hanging fruit in the field over the last decade have come from demonstrating the impressive predictive power of ANNs. Deriving explanations from the relatively inscrutable internals of ANNs has proved to be a much harder task. However, many in the field seem aware that prediction is insufficient to answer the core questions of cognitive science, and in recent years have been making significant efforts toward moving beyond prediction. More concerning to me is the fact that the basic methods used in this field for assessing representational similarity seem to be highly sensitive to small changes in defining the similarity metric. RSA in particular is sensitive to the way features are sampled in the test datasets. To get robust assurances, we should be really careful about overinterpreting RSA and ANN-derived encoding models.
It is less clear to me how we should factor in the third class of criticisms into the question of brain-ANN representation alignment. By my lights, this class of criticism suggests that ANNs are fundamentally insufficient for emulating brain function. I take this to imply that comparisons between the two systems are neither useful nor meaningful. But the representation alignment question is a fairly narrow question. As long as we agree that both brains and ANNs can be said to represent sensory inputs, then we should be able to discuss how these representations do or do not differ in a meaningful way. We need not assume that models are in principle capable of emulating all brain processes to believe that they might have something useful to offer in explaining brain function in some limited sense. These arguments may indeed have important implications elsewhere, for instance in understanding whether current methods will scale to true AGI. But I think we can bracket these concerns when talking about the narrower question of representation alignment.[3]
How should we interpret a positive resolution to the brain-alignment question (i.e. some or all ANNs converge toward brain-like representations)? If we do find that some AI models have highly brain-like representations, I don’t think that necessarily means ontology identification is solved. Specifically, it is still possible that AIs will have a mosaic of brain-like and non-brain-like representations. The idea of a brain-aligned subspace (Conwell et al, 2022) might already be pointing in this direction. Having some brain-aligned representations is probably essential for the “human simulator scenario” from Eliciting Latent Knowledge, which means we should be extra careful about fully interpreting model internals, not just the things that map onto human concepts we care about. However, such a discovery could go a long way in shaping the focus of AI safety research including in ontology identification.
Conclusion
There is a growing view among cognitive scientists and neuroscientists that ANNs and brains learn to represent sensory stimuli in similar ways. I summarized several classes of objections to this view that I have observed in the literature. The first was that current evidence is insufficient to support this claim because it primarily relies on correlations between brain activity and model internals without further explanation of the causal relationships between models and brains. Another class of objections points to the ambiguity in the interpretation of representational similarity for which there are still deep and unresolved questions. Lastly, a third category cites fundamental differences between biological brains and ANNs as grounds to dismiss comparisons between the two. Of these, the first two are the most concerning to me, because they seem to throw cold water on many of the findings that suggest a convergence toward similar representations in ANNs and brains. Solving these problems seems to require new approaches or solutions to deep problems in measuring and understanding representations. Fortunately, progress in the field of neuro-AI seems to be picking up pace, so I expect we will see some significant progress on these issues in the near future. I think the AI alignment community should be considering how these issues might interact with or affect the assessment of the main issues in AI alignment. For instance, do brain-like representations in AI systems solve ontology identification? Does apparent convergence between brain and AI representations constitute evidence for the existence of natural abstractions [? · GW]? How alien are the cognitive realms [AF · GW] of AIs? I am interested to see how gaining a deeper understanding between the relationship between brains and ANNs could help in answering these questions.
- ^
My understanding is that the jury is still out [LW · GW] on whether features are always encoded in neural networks in this way.
- ^
As described in a personal communication between Guest and Martin and K. Srinivasan, R. Ajemian, and R.C. Berwick, January 14, 2022.
- ^
The one exception may be on the issue of tacit representations in brains and AI. Daniel Dennett introduced the concept as a response to a premise in cognitive science that representation precedes computation. Dennett conceived of tacit representations as knowledge accessible to a cognitive system without explicit representation. For instance, the knowledge of how to perform certain complex physical tasks such as riding a bike can be imagined as using a tacit knowledge of the correct actions and responses without referencing explicit representations of these rules. I haven’t seen much on this topic as it relates to mental representations in sensory neuroscience, and only one blog post on its relationship to neural networks. But this could undermine my assumption that representations in brains and ANNs can be totally understood in terms of explicit references to sensory stimuli.
- ^
0 comments
Comments sorted by top scores.