We should try to automate AI safety work asap
post by Marius Hobbhahn (marius-hobbhahn) · 2025-04-26T16:35:43.770Z · LW · GW · 8 commentsContents
We should already think about how to automate AI safety & security work We have to automate some AI safety work eventually Just asking the AI to “do alignment research” is a bad plan A short, crucial timeframe might be highly influential on the entire trajectory of AI Some things might just take a while to build Gradual increases in capabilities mean different things can be automated at different times The order in which safety techniques are developed might matter a lot High-level comments on preparing for automation Two types of automation Maintaining a lead for defense Build out the safety pipeline as much as possible Prepare research proposals and metrics Build things that scale with compute Specific areas of preparation Evals Pipeline automation Research automation Red-teaming Research automation Monitoring Pipeline automation Research automation Interpretability Pipeline automation Research automation Scalable Oversight, Model Organisms & Science of Deep Learning Pipeline automation: Research automation: Computer security Conclusion None 8 comments
This is a personal post and does not necessarily reflect the opinion of other members of Apollo Research. I think I could have written a better version of this post with more time. However, my main hope for this post is that people with more expertise use this post as a prompt to write better, more narrow versions for the respective concrete suggestions.
Thanks to Buck Shlegeris, Joe Carlsmith, Samuel Albanie, Max Nadeau, Ethan Perez, James Lucassen, Jan Leike, Dan Lahav, and many others for chats that informed this post.
Many other [LW · GW] people have written about automating AI safety work before. The main point I want to make in this post is simply that “Using AI for AI safety work should be a priority today already and isn’t months or years away.” To make this point salient, I try to list a few concrete projects / agendas that I think would be reasonable to pursue with current AI capabilities. I make a distinction between “pipeline automation” (the automation of human-designed processes) and “research automation” (the automation of the research process itself, including ideation). I think there are many safety pipelines that can be automated today and directly yield safety benefits. I’m much more skeptical that current AI capabilities suffice for research automation, but I think there are ways we can already prepare for systems that can.
We should already think about how to automate AI safety & security work
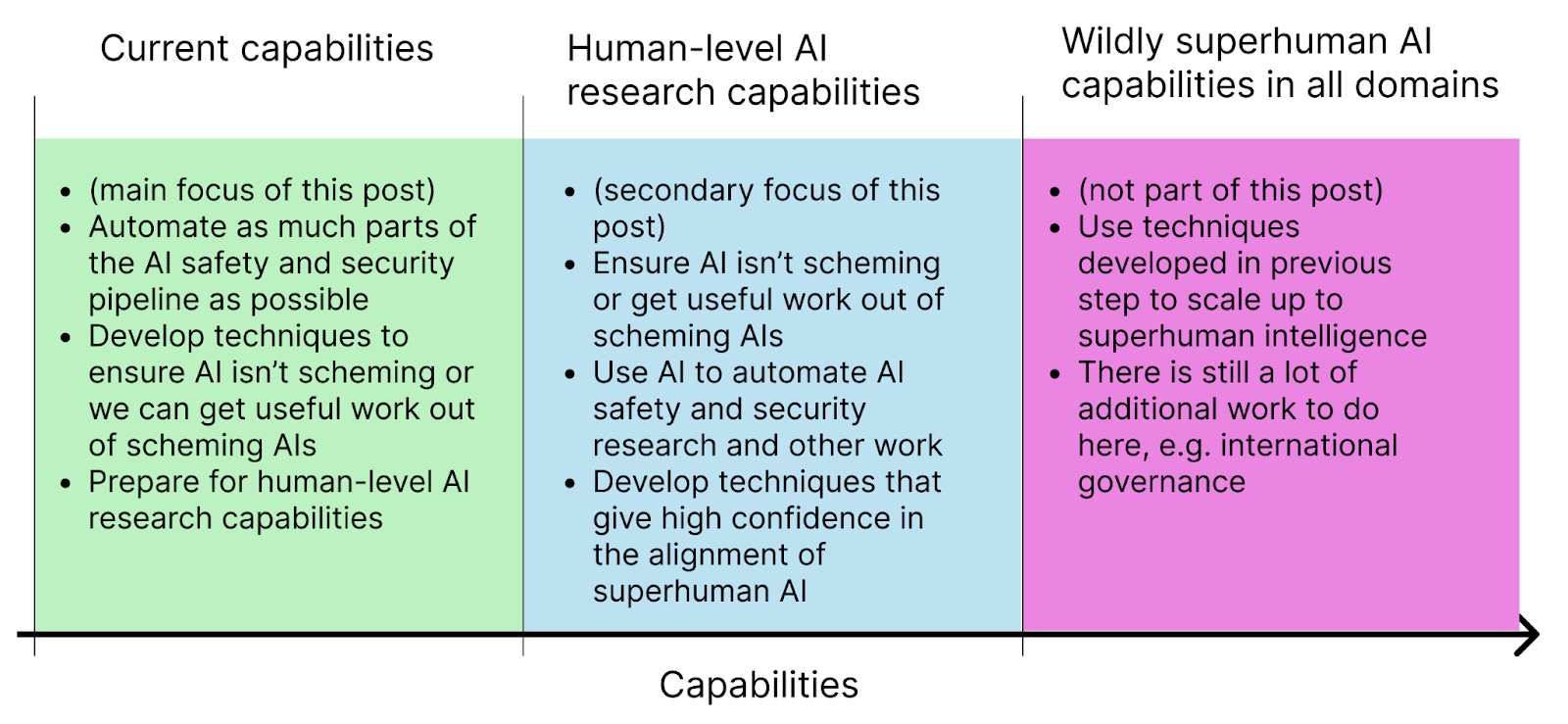
In this post, I use a broad definition of AI safety work, e.g., it includes monitoring, control, alignment research, computer security work, and more.
I specifically focus on the period of time from now to AIs that are capable of doing meaningful chunks of AI safety & security work autonomously, e.g. that are about as productive per unit of time as a top AI researcher at a frontier lab. Then, at this level of capabilities, we run many thousands of instances of a human-level system in parallel. We should (hopefully) be able to monitor and control each instance independently because they are only about as capable as a single human researcher. However, due to the large increase in cognitive effort available, we can leverage these AI systems to drastically speed up AI safety and security work.
In this pivotal period, we need to ensure that we can make as much differential safety progress as possible. This requires both technical preparation and various governance work. This post only focuses on the technical preparation and how we can ensure that we can get as much useful work out of these systems without taking any substantial risks, though I invite more people to think about the governance commitments as well.
We have to automate some AI safety work eventually
There are lots of reasons why we almost certainly have to automate some (potentially most) parts of the AI safety pipeline eventually.
- Safety work is already neglected compared to capability work
- Capability work will be automated
- It will be hard to ensure the safety of superhuman AI systems without AI assistance.
Automating some AI safety work is also an explicitly stated strategy by most frontier AI companies.
Just asking the AI to “do alignment research” is a bad plan
I think there is a naive version of the vision for automated AI safety work that is something like:
- Step 1: build AGI (for the purpose of this post, AGI refers to an AI system that can replace a top researcher at a frontier AI company)
- Step 2: ask the AGI to “solve alignment”
There are a few obvious flaws with this plan, including:
- How can you trust this AI to begin with? You would want some argument that the AGI you task with alignment research shares your goals. Otherwise, you take a substantial risk of irreversibly handing over a lot of power to a misaligned AI system.
- The problem is underspecified. “Solving alignment” is a really abstract description of the task. Likely, there are more specific versions of the problem that convey more information to the AI system and thus increase the chance that you’ll be able to achieve your intended goal.
- How do you know if a suggested plan is good? At this level of capabilities, the plans that the AI system might come up with are potentially complicated enough that humans have a hard time deciding whether it is a genuinely good plan without having previously deeply thought about metrics to evaluate plan quality.
Thus, we should have a substantially more specific plan to increase our chances of pulling it off.
A short, crucial timeframe might be highly influential on the entire trajectory of AI
I think it is quite plausible that a span of 3 months to 3 years might largely determine whether AI is the best or the worst technology humanity has ever built. I think this trajectory might be increasingly chaotic with accelerating capabilities (see e.g. Catastrophe through Chaos [LW · GW]).
If this is true, preparation seems very important. It reduces chaos and uncertainty at the most crucial time and frees up time for decision-making during this period.
Some things might just take a while to build
Having a powerful AI system available drastically speeds up all forms of cognitive labor, e.g. ideation and execution, but there are some things that might see only very little speedup compared to today, or at least lag behind substantially. For example,
- Physical efforts: Especially in the case of hardware and physical security, single improvements might take months or years to complete.
- Changing human norms and behaviors: We may not be able to change organizational norms to handle advanced AI systems overnight. Typically, it takes months or years to change any organizational culture, let alone to something that might look closer to a mentality that is found in militaries rather than start-ups.
- Corporate politics and company buy-in: If the safety approach relies on some form of end-to-end training at scale, it might not be blocked by cognitive labor but instead by the availability of training compute and thus requires political buy-in during periods where compute is especially demanded. This probably needs a lot of company-internal preparation.
Gradual increases in capabilities mean different things can be automated at different times
Almost certainly, different AI safety work requires different levels of capabilities. For example, I think that we can offload substantial technical work on evals or monitoring to AIs before they can meaningfully help with threat modeling.
Thus, we should aim to always make use of the earliest AIs that can meaningfully help with the task. Otherwise, we both pay a large opportunity cost in safety progress, and the successor system is comparatively less safe because we could have used previous safety advances immediately.
The order in which safety techniques are developed might matter a lot
There are many plausible cases where the order in which safety work is developed has a large effect on the overall safety of the system. Here are two examples:
- When your model is sufficiently situationally aware, it might realize that it is being evaluated and decide to fake alignment or sandbag. Thus, techniques to measure or mitigate situational awareness should be developed and used before running evaluations for alignment or dangerous capabilities.
- Some AI systems will be deployed as trusted models, e.g. to classify the actions of another AI system. The deployer will make some argument for why this model is trusted, e.g. based on collusion evals. Then, they might use the combination of trusted and untrusted model to help us with other AI safety work. Therefore, we have to first build the evaluations to establish a model as trusted.
Broadly speaking, I think most arguments for a model's safety will build on a stack of assumptions with many dependencies. Therefore, it makes sense to think through these assumptions and differentially focus on automating the ones that come earliest in the chain first.
High-level comments on preparing for automation
Two types of automation
Broadly speaking, I differentiate between two types of automation
- Pipeline automation: We take human-designed protocols of increasing sophistication and automate them. This is largely based on already existing knowledge and doesn’t require major novel insights. It’s mostly executing the same steps with a bit of adaptation based on context. This process is heavily domain-specific and I expect the timelines between domains to vary by quite a bit because humans have already developed much more sophisticated protocols in some domains than in others.
- Research automation: We hand off increasingly large chunks of research ideation and execution to the AI. The goal is to create and test novel insights rather than merely executing a well-established protocol. The broad strokes of this process look fairly similar across most domains, even if the exact research questions differ.
I expect the prototype of pipeline automation to look broadly like this:
- Step 1: Automate simple protocols based on human expertise
- Step 2: Increase the sophistication of the automated protocols
- Step 3: Integrate more domain knowledge and context into the system, e.g. by adding lots of information in-context, RAG, fine-tuning, and similar techniques
- Step 4: Have AI agents implement large chunks of new techniques or examples. Humans still do most of the conceptual work.
- Step 5: AI agents also largely do the narrow conceptual work needed for the pipeline. Humans steer the process and verify the results.
I expect the order of events for research automation to look broadly like this:
- AIs assist with basic tasks in research, e.g. extend a list of examples, some simple question-answering to speed up the research process. They don’t have good novel ideas.
- AIs can do well-scoped research projects for 30 minutes. They make some design decisions on their own. Their novel ideas are still mostly useless.
- AIs can do well-scoped research projects for 4 hours. They make some decisions on their own. Their novel ideas are hit-and-miss.
- AIs can do research projects for 8+ hours (even when they are not well-scoped). They make some decisions on their own. Their novel ideas are pretty useful.
- AIs can do research projects for months (even when they are not well-scoped). They make almost all decisions on their own. Their novel ideas are as good as those of a top-tier researcher.
Maintaining a lead for defense
In the spirit of differential progress, we should aim to “maintain a lead for the defense.” Broadly speaking, this means that we should aim to prioritize new technological breakthroughs to first establish robust defensive mechanisms before we deploy them in other fields or use them to advance capabilities further. This could include:
- Prioritize using new systems for AI safety work (assuming you have some reason to believe you can use them safely, e.g. control)
- Differentially provide access to teams that work on defensive mechanisms such as AI safety research, defensive cyber applications, defensive bio technology, etc.
- Partner with external parties that are trusted and capable actors for defensive applications and differentially provide technology to them first.
I expect that almost all of the work we invest in this preparation will be “bitter-lessoned” by the AI systems that are as capable at AI safety research as top human researchers. However, my main aim is to always have a head start of at least a few months/years to ensure that we can use AI system N to help increase the safety of AI system N+1 immediately.
Build out the safety pipeline as much as possible
The ideal pipeline would be one where any new model could be directly “plugged in” to lead to relevant jumps in safety. Intuitively, something like AIDER or Cursor, where coding abilities get better immediately on the day a new model drops.
I expect most AI developers already have some pipelines that work like this for capability-related improvements. For example, whenever a new frontier model has finished training, I would guess that there is a distillation pipeline that creates a much smaller model with almost similar capabilities. I would want a number of equivalent pipelines for specific types of safety work.
Here are concrete examples of such a pipeline for trusted monitoring:
- Before the new model drops, we prepare the following
- Evaluations to establish a model as a trusted monitor, e.g. collusion evals
- A mechanism to establish whether a model is sandbagging in evaluations, e.g. finetuning or red-teaming
- A set of evaluations that give us some confidence that the model isn’t egregiously misaligned
- A procedure for automated red teaming, automated generation of propensity evals, building better environments for monitoring, or automated pen-testing.
- When the model drops, we
- Establish that the model isn’t sandbagging in our evaluations
- Establish the model as a trusted monitor (or establish that the model can be monitored by a smaller model we already trust)
- Run the evaluations that give us confidence that the model isn’t egregiously misaligned
- Then, we use this model with a trusted monitor, e.g. by plugging it into the prepared procedures and directly get a boost in safety.
Prepare research proposals and metrics
When AI systems can do meaningful chunks of AI safety work autonomously for longer periods of time, the work of AI safety researchers will shift away from executing research projects toward steering a fleet of automated researchers. In this new workflow, there are at least two relevant components (probably more): a) evaluate the results of the work the automated researchers produce, and b) define projects that are sufficiently well-scoped that we can hand them off to the automated researcher.
Define good metrics & prepare to dedicate resources for understanding adversarial new strategies: To evaluate the work of the AI system, we should ideally have a large set of robust metrics and indicators that inform us whether we have made progress. These indicators should not only faithfully represent what we’re trying to measure but also be somewhat robust to gaming and overfitting so we can differentiate real progress from Goodharting or the model strategically trying to overclaim or manipulate results. These metrics will have to allow us to differentiate between 1000s of different proposals generated by the automated researchers where we will have limited time to understand them before making a decision. On top of that, we should expect that this selection process will always be somewhat adversarial, i.e. that AIs might actively try to game the metric (e.g. fake alignment). Therefore, on top of thinking about good metrics, we should actively build procedures and dedicate resources to understand which specific adversarial strategy the model could be pursuing.
Write up well-scoped research projects: When research project execution becomes drastically cheaper, the ideation stage becomes much more important. In particular, it might be very useful to write down a large set of empirical research proposals that can be handed off to the AI systems. In some research fields, where we expect the effect of automation to be very strong, it might be sensible for current researchers to spend a meaningful amount of their time writing up research proposals instead of executing them. Concretely, research that is heavily parallelizable seems especially well-suited for this type of strategy. It might be less well-suited for very sequential research.
Build things that scale with compute
It would be great if our automated safety procedures had the property that spending more compute directly leads to more safety in some monotonic fashion, e.g. in the same way in which more compute leads to predictable gains for pre-training across many orders of magnitude of compute. I expect there will be some safety methods that rely on clever insights and give us small jumps without scaling properties, e.g. writing a better spec, but I also expect that there are safety methods that give us reliably stronger safety with more compute spend.
A different way of looking at this is: What is our answer to the question “What safety method could we spend $1B worth of compute on and it directly translates to predictable increases in safety?”
Specific areas of preparation
In the following, I want to make a number of concrete suggestions. The goal is both to a) get feedback on the specifics of these plans and b) get people to start working to set up the automation pipelines.
Evals
Pipeline automation
Anthropic’s “Discovering Language Model Behaviors with Model-Written Evaluations” paper already showed in 2022 that it is possible to automate the generation of large propensity evaluation suites using LLMs. For generating simple QA evaluations, this has become the norm throughout the field. The kind of thing I have in mind is merely the obvious continuation of this trend.
- Step 1: Create significantly more complex, likely agentic, evals using an automated pipeline. Instead of designing short questions, the pipeline generates complex environments.
- Step 2: Play around with few-shotting, RAG, fine-tuning models on existing evals for better eval-building capabilities and use other techniques to encode more prior human evals expertise into the eval-building pipeline.
- Step 3: Have “eval agents” that continuously build and improve complex environments according to high-level specifications of the evaluation. They take many design decisions on their own. The threat modelling comes from humans. Intuitively, we’d have 1M highly complex evaluation scenarios and a “colony of eval agents” on a server that work on making these evals better 24/7.
- Step 4: Eval agents but they also do the threat modelling.
I imagine that the skill of building evals is significantly narrower than general AI R&D, at least it feels significantly more formalizable and easier to me personally. Thus, I think it is possible that we could get fairly narrow and specialized eval builder AI systems that could create and maintain millions of high-quality evals at least one generation before we get to systems that could automate AI R&D.
With slight modifications, this can also be used to generate training environments for RLAIF, e.g. for constitutional AI or deliberative alignment. For propensity evaluations, it should not pose a problem that the AI building the eval is less capable than the AI system for which it is designed. For capability evaluations this might be harder but I could imagine that it is possible to build evaluations that can be automatically verified, even if the best current system cannot solve them.
Research automation
I expect that research automation for evals will broadly look like general AI research automation. You would hand-off increasingly large chunks of evals research to AIs, e.g. science of evals research, elicitation, evals design, etc.
Red-teaming
This is basically the logical continuation of the “Red Teaming Language Models with Language Models“ paper. There are also Haize and PRISM as example orgs who’re building something like that.
- Step 1: Do the same procedure as in auto-red teaming paper but more advanced, e.g. much better prompting, larger scale, better models, etc.
- Step 2: Put more knowledge in context, and use RAG & fine-tuning techniques. In general, find ways to give the model significantly more human expert knowledge about red-teaming. Use cognitive diversity by combining different models / finetunes.
- Step 3: “Red teaming agents” that continuously attack the model in various ways. Have thousands of those running in parallel. Make them learn the weaknesses of the model. Humans do the conceptual work of creating the algorithms the agents execute.
- Step 4: The LLMs also design new red-teaming procedures and come up with new conceptual improvements, e.g. completely new attack strategies.
With slight modifications, the same generation procedure can also be used to generate arbitrary adversarial training pipelines. Similar to evals, I expect this procedure to be simpler than general AI R&D because it is a more narrow and structured task with a clear objective.
Research automation
Similar to evals, I expect that research automation for automated red teaming will broadly look like general AI research automation. You would hand-off increasingly large chunks of red teaming research to AIs, e.g. scaling laws for red teaming, comparing attack strategies, new algorithm design and verification, etc.
Monitoring
Pipeline automation
I think that:
- The biggest blocker to building good monitors is having a large and diverse set of complex environments that closely resemble real-world usage. IMO, current monitors are too often tested on narrow domains where the blue team is more favored than in the real world. Something like Control Arena is a great step in the right direction IMO.
- Ultimately, we will want to train monitors in an adversarial game where the monitor plays against a red-team model that actively tries to get better at achieving harmless proxies of harmful outcomes. The adversarially trained monitor is then applied to the standard model that has not been trained adversarially. This hopefully provides a bigger buffer for the monitor.
I expect that building the complex environments follows a similar structure to the automated evals with slight modifications. The adversarial game seems like something that would scale well with more compute, e.g. with the right setup, you could spend $1M+ and see reliably increasing returns for monitor F1 scores.
In the best case, we find some scalable way to build environments where the task itself is complex, but whether the model did the undesirable behavior or not can be easily measured posthoc, e.g. whether a specific file contains a string or not. Then, we can easily check whether the monitor correctly flagged it or not.
Research automation
To me, monitoring feels like a field that can see great returns early on in the research automation process. My best guess is that there are a lot of small-ish things to vary that don’t require grand new insights but some smaller decisions to be taken autonomously. For example, iterating on the prompt of a black-box monitor, changing the fine-tuning recipe of a monitor, experimenting with data mixtures, running ensembles instead of single monitors, etc.
Of course, some research is harder to automate. I expect that properly setting up and developing the adversarial training pipeline for monitors might be non-trivial from an execution perspective and require lots of experience. There might also be new monitoring paradigms that are not just combinations of simple existing ideas. However, I feel like we could make a lot of progress with almost zero novel insights just from much better execution.
Interpretability
Pipeline automation
There are many parts of the interpretability pipeline that seem very repetitive once the conceptual question has been figured out. For example,
- Auto-labeling: Take features and automatically assign a label to them according to the inputs they activate on.
- Automatic circuit detection: automatically combine features into circuits according to some recipe
- Qualitative assessments of feature quality / purity: investigate the labels of the features, e.g. check false positive and false negative rates. My understanding is that people have a handful of criteria they typically check; all of them individually are simple enough to be handed to an LLM with a bit of prompt engineering
My feeling is that there are a lot of things that have this flavor of “figure out hard conceptual question, then quickly automate it” since there are a lot of very algorithmic tasks in applied interpretability. From my limited outside view, I’d also say that people in the interpretability field already see this pipeline automation as the default path.
Research automation
I expect there will be some research projects that are very easy to automate and others that are very hard. The following examples are in increasing complexity:
- Small variations within a method: For example, take SAEs but iterate through a few different activation functions, e.g. jump ReLU, GeLU, etc. This is mostly execution blocked. There are a lot of experiments like this that could be easily handed off to AI soon.
- Small methodological improvements: For example, take a specific part of a current method, such as the auto-labeling step for SAEs, come up with a new approach, and then compare them rigorously. One way to prepare for this is to write up well-scoped research projects that can be handed off to AIs.
- New paradigms shifts: Come up with a completely new paradigm, e.g. APD. I expect this to be very hard because it is so fuzzy and blocked both by theoretical insights and competent execution. I’d expect this to be significantly harder to automate than the median capability research project. I think the main preparation for automating paradigm shift research is to get extreme clarity on how to evaluate entirely new interpretability approaches. My understanding is that people have struggled to get a lot of clarity on this question over the last 5 years, so it’s probably hard. There has been some progress, e.g. degeneracy in the loss landscape, but there is still a long way to go.
Scalable Oversight, Model Organisms & Science of Deep Learning
I grouped these together because I felt that, basically, the same arguments apply to all three of them. Scalable oversight feels early enough of a paradigm that most of the progress is blocked by conceptual progress rather than research execution. Model organisms and science of deep learning are almost by definition optimizing for insights and thus also harder to automate.
Pipeline automation:
While there might be small pipelines to automate here and there, I think pipeline automation doesn’t make a big difference for these fields for now. At a later point, it might help for scalable oversight. The other two optimize for insights. Thus, pipeline automation is less applicable.
Research automation:
Broadly speaking, I think people can do the following for research automation for these fields.
- Prepare well-scoped projects: For example, write down concrete lists of projects or extensions of existing projects to hand over to AI systems once they are capable enough. This could look like Anthropic’s list of safety ideas, but instead of handing them to Anthropic Fellows, they are executed by the first AI system that has sufficiently strong research capabilities.
- Figure out how to evaluate new methods: Eventually, models will be capable of proposing new methods, and the main job of the researcher is to evaluate whether this method is a genuine improvement, a false hope, or maybe even actively trying to sabotage you. The more confidence we have in our evaluation, the easier it will be to iterate quickly with the automated AI researchers.
Broadly speaking, I expect many projects in this category to be harder than the median capabilities research project. Therefore, the more we can prepare early on, the closer we can hopefully get the gap between capabilities and alignment progress.
Computer security
See Buck’s post “Access to powerful AI might make computer security radically easier [LW · GW]”
Conclusion
While this is a fairly quick and dirty post, I think there are good outcomes that it could inspire:
- Function as a coordination mechanism: a lot of ideas in this post don’t require any novel insights and merely more people to work on it.
- Better & more detailed posts: I think it would be great if people could write significantly more detailed agendas on how to automate specific safety work. In the best case, such a post would almost read like a recipe.
- Focused Research Organisations (FRO): I think it would be great if people tried to build focused research organizations around the automation of a specific safety idea. For example, let’s say there is a grant/investment for $2.5M. This is split into $1M for talent, $1.1M for experimentation compute, and then $400k for the final compute scaling experiment (..., $6.3k, $12.5k, $25k, $50k, $100k, $200k). Then, if the automation follows good scaling laws, the funder increases the funding for larger runs. Otherwise, shut down the org or try again with a similar budget.
8 comments
Comments sorted by top scores.
comment by jacquesthibs (jacques-thibodeau) · 2025-04-26T21:56:02.909Z · LW(p) · GW(p)
Thanks for publishing this! @Bogdan Ionut Cirstea [LW · GW], @Ronak_Mehta [LW · GW], and I have been pushing for it (e.g., building an organization around this, scaling up the funding to reduce integration delays). Overall, it seems easy to get demoralized about this kind of work due to a lack of funding, though I'm not giving up and trying to be strategic about how we approach things.
I want to leave a detailed comment later, but just quickly:
- Several months ago, I shared an initial draft proposal for a startup I had been working towards (still am, though under a different name). At the time, I did not make it public due to dual-use concerns. I tried to keep it concise, so I didn't flesh out all the specifics, but in my opinion, it relates to this post a lot.
- I have many more fleshed-out plans that I've shared privately with people in some Slack channels, but have kept them mostly private. If the person reading this would like to have access to some additional details or talk about it, please let me know! My thoughts on the topic have evolved, and we've been working on some things in the background, which we have not shared publicly yet.
- I've been mentoring a SPAR project with the goal of better understanding how we can leverage current AI agents to automate interpretability (or at least prepare things such that it is possible as soon as models can do this). In fact, this project is pretty much exactly what you described in the post! It involves trying out SAE variants and automatically running SAEBench. We'll hopefully share our insights and experiments soon.
- We are actively fundraising for an organization that would carry out this work. We'd be happy to receive donations or feedback, and we're also happy to add people to our waitlist as we make our tooling available.
↑ comment by purple fire (jack-edwards) · 2025-04-27T00:52:14.251Z · LW(p) · GW(p)
Do you think building a new organization around this work would be more effective than implementing these ideas at a major lab?
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2025-04-27T01:04:35.561Z · LW(p) · GW(p)
Anthropic is already trying out some stuff. The other labs will surely do some things, but just like every research agenda, whether the labs are doing something useful for safety shouldn’t deter us on the outside.
I hear the question you asked a lot, but I don’t really hear people question whether we should have had mech interp or evals orgs outside of the labs, yet we have multiple of those. Maybe it means we should do a bit less, but I wouldn’t say the optimal number of outside orgs working on the same things as the AGI labs should be 0.
Overall, I do like the idea of having an org that can work on automated research for alignment research while not having a frontier model end-to-end RL team down the hall.
In practice, this separate org can work directly with all of the AI safety orgs and independent researchers while the AI labs will likely not be as hands on when it comes to those kinds of collaborations and automating outside agendas. At the very least, I would rather not bet on that outcome.
Replies from: jack-edwards↑ comment by purple fire (jack-edwards) · 2025-04-27T01:07:08.106Z · LW(p) · GW(p)
That makes sense. However, I do see this as being meaningfully different from evals or mech interp in that to make progress you really kind of want access to frontier models and lots of compute/tooling, so for individuals who want to prioritize this approach it might make sense to try to join a safety team at a lab first.
Replies from: jacques-thibodeau↑ comment by jacquesthibs (jacques-thibodeau) · 2025-04-27T01:33:30.715Z · LW(p) · GW(p)
We can get compute outside of the labs. If grantmakers, government, donated compute from service providers, etc are willing to make a group effort and take action, we could get an additional several millions in compute spent directly towards automated safety. An org that works towards this will be in a position to absorb the money that is currently inside the war chests.
This is an ambitious project that makes it incredibly easy to absorb enormous amounts of funding directly for safety research.
There are enough people who work in AI safety who want to go work at the big labs. I personally do not need or want to do this. Others will try by default, so I’m personally less inclined. Anthropic has a team working on this and they will keep working on it (I hope it works and they share the safety outputs!).
What we need is agentic people who can make things happen on the outside.
I think we have access to frontier models early enough and our current bottleneck to get this stuff off the ground is not the next frontier model (though obviously this helps), but literally setting up all of the infrastructure/scaffolding to even make use of current models. This could take over 2 years to set everything up. We can use current models to make progress on automating research, but it’s even better if we set everything up to leverage the next models that will drop in 6 months and get a bigger jump in automated safety research than what we get from the raw model (maybe even better than what the labs have as a scaffold).
I believe that a conscious group effort in leveraging AI agents for safety research, it could allow us to make current models as good (or better) than the next generations models. Therefore, all outside orgs could have access to automated safety researchers that are potentially even better than the lab’s safety researchers due to the difference in scaffold (even if they have a generally better raw model).
↑ comment by danielms (danielmccannsayles) · 2025-04-27T04:44:23.660Z · LW(p) · GW(p)
Interested in chatting about this! Will send you a pm :D.
comment by Dusto · 2025-04-26T23:38:44.239Z · LW(p) · GW(p)
I see notes of it sprinkled throughout this piece, but is there any consideration for how people can put more focused effort on meta-evals, or exam security? (random mumblings below)
Treating the metric like published software:
- Versioned specs: Write a formal doc (task, scoring rule, aggregation, allowed metadata). Cut a new major version whenever the metric or dataset changes so scores are never cross-compared accidentally.
- Reproducible containers: Make the judge/grader a Docker/OCI image whose hash is pinned inside the leaderboard. Any run is signed by the image plus a tamper-proof log of model outputs.
- Public “metric change log”: Every time a bug-fix or leakage patch ships, publish a diff+reason. That both discourages quiet back-padding and helps meta-evaluators regress-test old claims.
Adversarial red-team for the metric itself:
- Thread modelling the judge
- Agents and humans try to break metric
- Patch and re-test found exploits
- Keep private slice of test to compare for drift, and signs of gaming
Layering:
- Use 3-to-5 models from different labs, different prompts, majority vote, etc. Randomly subsample on each evaluation run so attackers cannot tune to a fixed model
- Spot checks. 1-2% model x prompt x judge, are routed to human annotators.
People and incentives:
- Bug bounties for demonstrations where score inflates without improving ground-truth safety/capability measure
- Audit rotations. Have different labs re-implement metrics
- Leaderboard freezes. Scores are held for x days before release (beyond one red-team cycle), to minimise “press-release hacking”
comment by danielms (danielmccannsayles) · 2025-04-27T04:43:18.130Z · LW(p) · GW(p)
Hard agree with this. I think this is a necessary step along the path to aligned AI, and should be worked on asap to get more time for failure modes to be identified (meta-scheming, etc.).
Also there's an idea of feedback loops - it would be great to hook into the AI R&D loop, so in a world where AIs doing AI research takes off we get similar speedups in safety research.