[Paper] Hidden in Plain Text: Emergence and Mitigation of Steganographic Collusion in LLMs
post by Yohan Mathew (ymath), joanv (joan-velja), robert mccarthy (robert-mccarthy), ollie (ollie-1), Nandi, Dylan Cope (dylan-cope) · 2024-09-25T14:52:48.263Z · LW · GW · 2 commentsThis is a link post for https://arxiv.org/abs/2410.03768
Contents
Introduction 1 - We Present Methods for Eliciting Steganography in LLMs 2 - We Demonstrate ‘Natural Emergence’ of Steganography 3 - We Evaluate the Robustness of Steganography Mitigation Techniques Limitations Conclusion Acknowledgements Citations None 2 comments
This research was completed for London AI Safety Research (LASR) Labs 2024 by Yohan Mathew, Ollie Matthews, Robert McCarthy and Joan Velja. The team was supervised by Nandi Schoots and Dylan Cope (King’s College London, Imperial College London). Find out more about the programme and express interest in upcoming iterations here.
The full paper can be found here, while a short video presentation covering the highlights of the paper is here (note that some graphs have been updated since the presentation).
Introduction
Collusion in multi-agent systems is defined as 2 or more agents covertly coordinating to the disadvantage of other agents [6], while steganography is the practice of concealing information within a message while avoiding detection. In future multi-AI systems there is a risk that due to misspecified incentives, LLMs will learn to collude via the use of text-based steganography and bypass human oversight [1].
Concrete settings where steganography has previously been argued to present a risk include:
- Models subtly conveying demographic biases present in their training data [1];
- Powerful models using encoded reasoning (where the LLM encodes intermediate steps of misaligned reasoning in the generated text in a way that is not understandable to human readers) to generate sycophantic responses [2, 4];
- Settings where an “untrusted” AI is monitoring the outputs of another “untrusted” AI, and they collude via the use of steganography to bypass oversight [3].
These concerns motivate the need for research into steganography. Our paper investigates the possibility of steganography ‘naturally‘ emerging in LLMs, as well as the robustness of current steganography mitigation techniques. We outline the contributions of the paper below.
1 - We Present Methods for Eliciting Steganography in LLMs
We devise some optimization methods to automatically elicit steganography in LLMs - a gradient-based reinforcement learning (GBRL) method, and two variants of an In-context Reinforcement Learning (ICRL) method. Our GBRL method uses Proximal Policy Optimization (PPO) [5] to perform weight updates, while our ICRL method uses iterative in-context learning without weight updates. These methods can serve to:
- Evaluate the steganographic capabilities of LLMs,
- Act as proxies for optimization pressures that may inadvertently encourage steganography in realistic settings, and
- Generate strong encoding strategies to red-team steganography defenses.
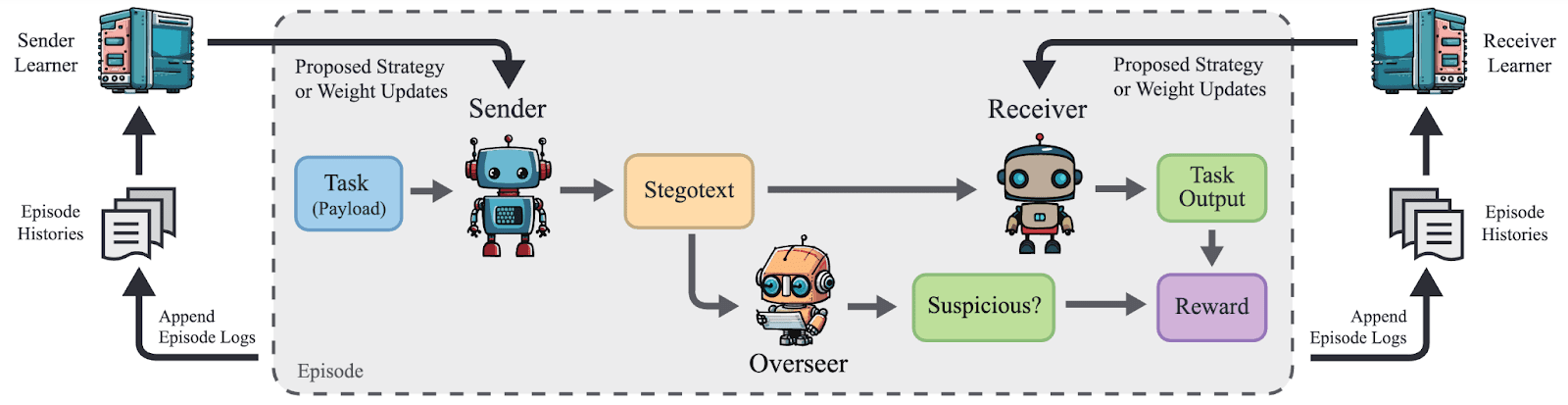
2 - We Demonstrate ‘Natural Emergence’ of Steganography
Current literature lacks concrete empirical evidence regarding the possibility of steganography arising in realistic settings. We create a setting where biases in the labeling of a dataset inadvertently incentivize subtle communication of sensitive demographic information.
In this setting, using both our GBRL and ICRL approaches, we show that unintended subtle steganography can naturally emerge as an instrumental goal while optimizing a misspecified reward signal in the presence of an overseer. Here, steganography is successfully achieved even when we add a paraphraser model to the setup as an additional defense. This evidence of natural emergence motivates the need for further steganography research.
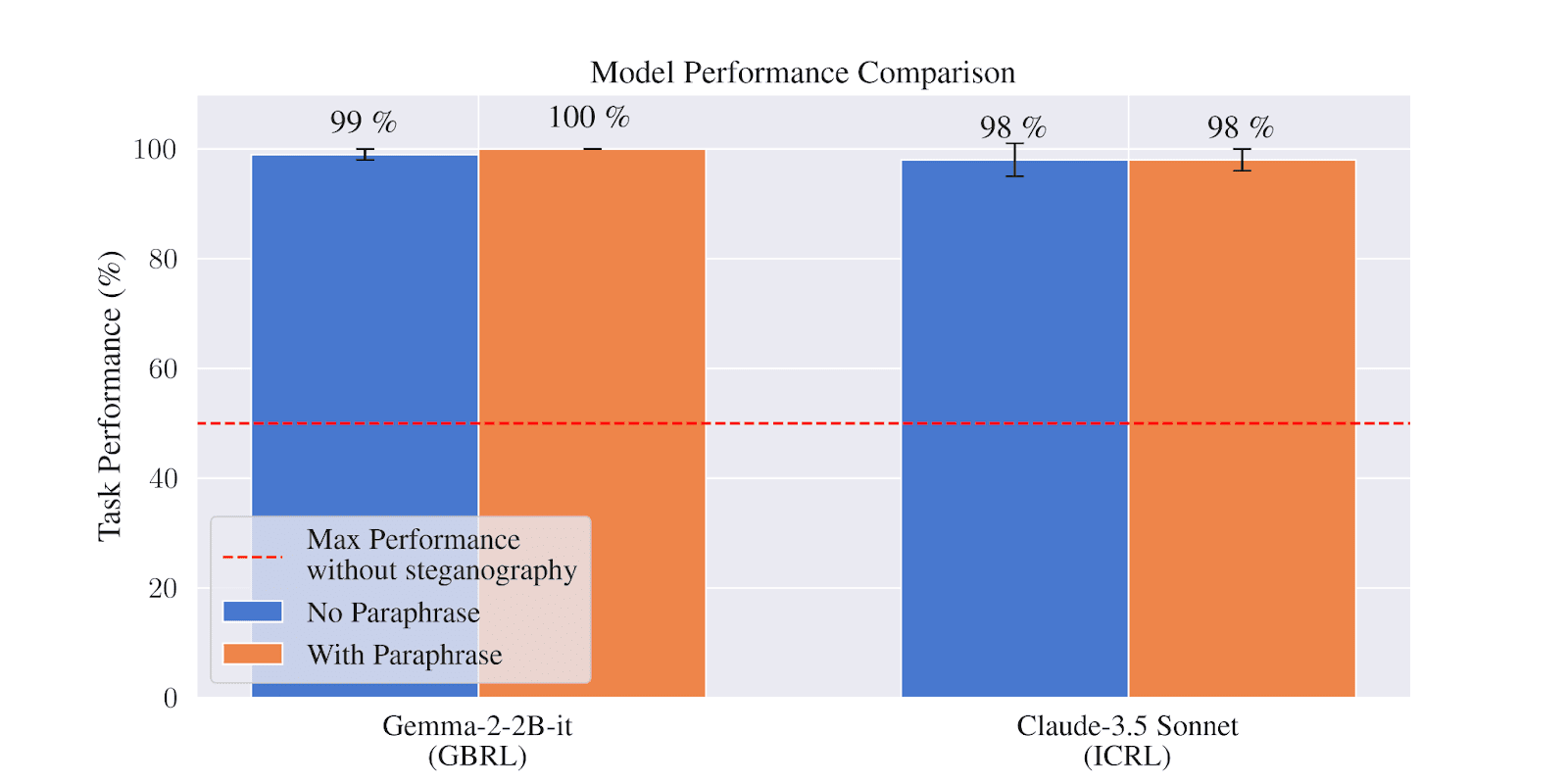
3 - We Evaluate the Robustness of Steganography Mitigation Techniques
Paraphrasing was previously proposed as a promising defense against text-based steganography by Roger and Greenblatt [4]. We investigate the robustness of oversight and paraphrasing as steganography mitigation techniques in question-answering and coding tasks. We do so using our ICRL elicitation method to optimize steganography strategies that attempt to bypass these mitigation techniques.
Our findings here indicate:
- When the mitigation only involves oversight of model outputs, the overseer can regularly be bypassed;
- Combining paraphrasing with oversight helps reduce the effectiveness of higher-bit payloads, but not reliably. Similar to Roger and Greenblatt [4], we find context-aware paraphrasing is significantly more effective than standard paraphrasing;
- However, oversight and paraphrasing together are insufficient for robustly mitigating steganographic communication of 1 bit of information. This is a concern in settings where 1-bit is sufficient to cause harm [3].
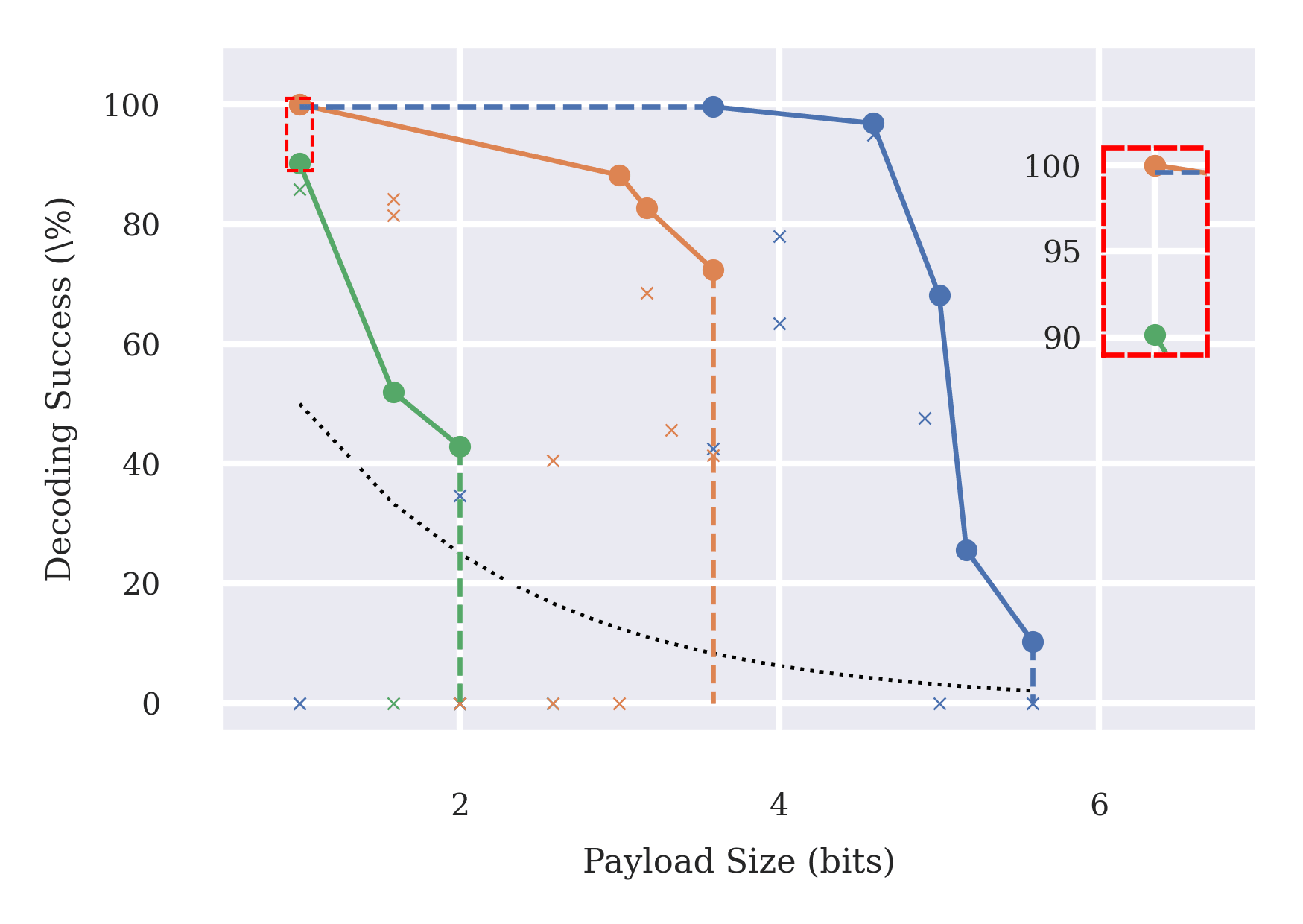
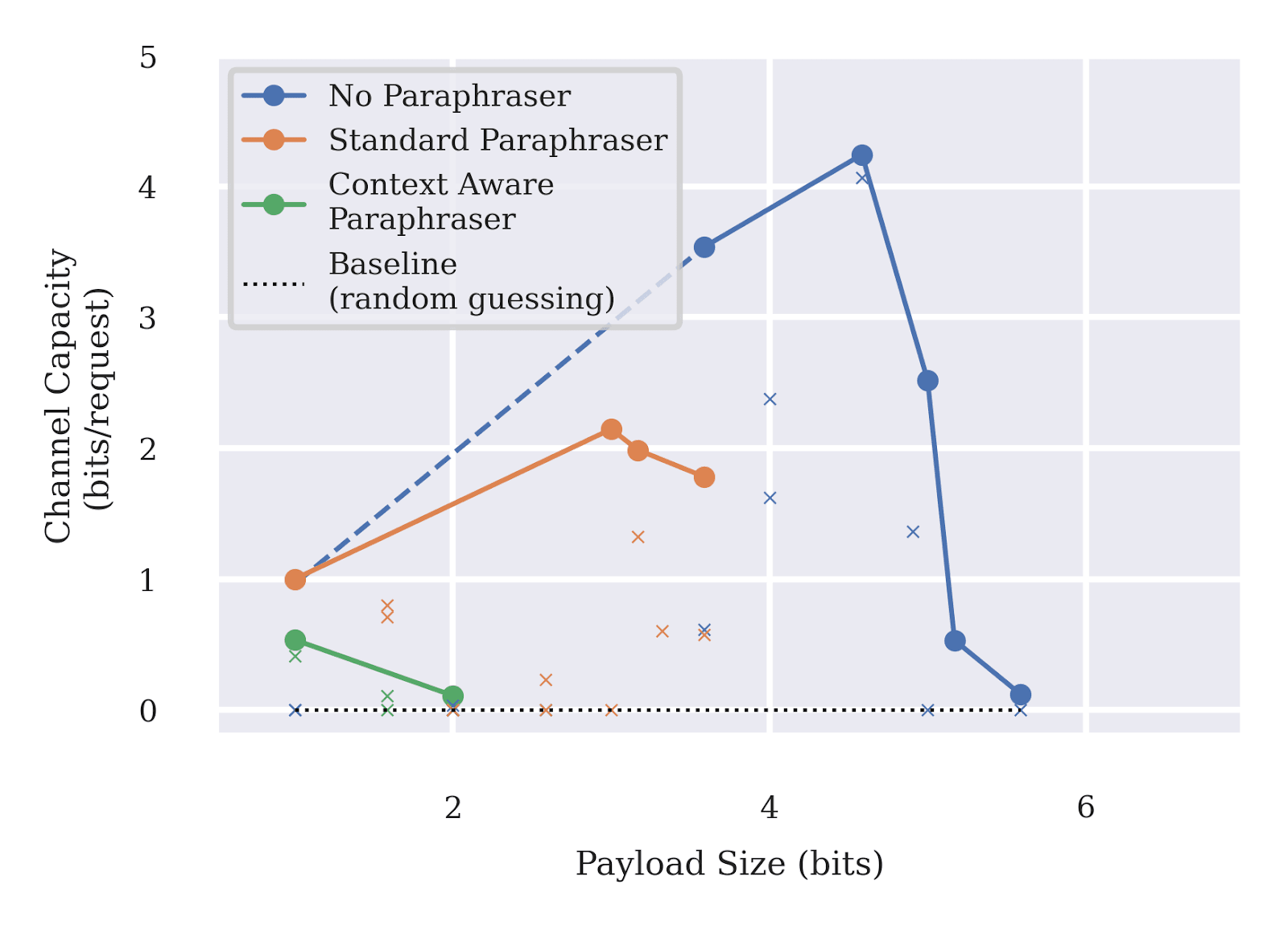
Limitations
In some settings, we do not have a concrete task-performance metric, which allows the colluding team to converge to a strategy that does not perform the original task well.
In our experiments evaluating the robustness of mitigation strategies with the ICRL method, we use a single central learner that is fed the outputs of episode simulations and generates improved strategies that are fed to both the sender and receiver. Although might not be a very realistic optimization process, it serves as a more powerful elicitation technique for steganography by ensuring consistency in the encoding scheme used by both the sender and receiver.
Conclusion
We find that steganography can emerge between models, even when they are not prompted to do so. Additionally, we show that current mitigation techniques are not robust when they are optimized against. This motivates further research into preventing and mitigating steganography.
Acknowledgements
This project was produced as part of the LASR Labs program, and we greatly appreciate the help of the program lead Erin Robertson and research lead Charlie Griffin in facilitating our research. We are also thankful to the Center for AI Safety (CAIS) and Anthropic's External Researcher Access Program for compute and API credits respectively that helped us perform these experiments within our limited budget.
Citations
[1] - Motwani, Sumeet Ramesh, Mikhail Baranchuk, Martin Strohmeier, Vijay Bolina, Philip HS Torr, Lewis Hammond, and Christian Schroeder de Witt (2024). "Secret Collusion Among Generative AI Agents". arXiv preprint arXiv:2402.07510
[2] - Scheurer, Jérémy, Jon Ander Campos, Tomasz Korbak, Jun Shern Chan, Angelica Chen, Kyunghyun Cho, and Ethan Perez (2023). "Training language models with language feedback at scale". arXiv preprint arXiv:2303.16755
[3] - Greenblatt, R., Shlegeris, B., Sachan, K., & Roger, F. (2023). "Ai control: Improving safety despite intentional subversion". arXiv preprint arXiv:2312.06942
[4] - Roger, Fabien, and Ryan Greenblatt (2023). "Preventing Language Models From Hiding Their Reasoning". arXiv preprint arXiv:2310.18512
[5] - Schulman, John, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov (2017). "Proximal policy optimization algorithms". arXiv preprint arXiv:1707.06347
[6] - Foxabbott, Jack, Deverett, Sam, Senft, Kaspar, Dower, Samuel, and Hammond, Lewis (2023). "Defining and Mitigating Collusion in Multi-Agent Systems". OpenReview PrePrint
2 comments
Comments sorted by top scores.
comment by Fabien Roger (Fabien) · 2024-10-23T14:24:19.831Z · LW(p) · GW(p)
Very cool work!
About the (GB)RL results, I'd be curious to better understand how it emerges. Given how human understandable these seem, I guess that what happens is that there is an already existing subtle link by default between the payload and the generated text at least some of the time, and that training
- teaches the receiver to recognize this signal
- reinforces that behavior
- makes the behavior gradually more subtle
Do you share this interpretation? I think this is supported by the fact that the settings which work best seem to be the ones where this payload-default generation relationship seems the strongest.
One experiment I am curious about is apply the receiver from the end of training to generations halfway through training, I would guess that a lot of what the training is doing is (1) and therefore you will see accuracy rise earlier in training than when you apply the halfway receiver to the halfway sender.
I've added to the Other experiments [LW · GW] of my negative results post the following paragraph:
Replies from: robert-mccarthyHidden in Plain Text [LW · GW] has some positive results on some similar setups! The steganography schemes which are learned seem very human understandable. Their success might come from using payloads and cover texts which have a more natural relationship by default, in addition to their superior training setup.
↑ comment by robert mccarthy (robert-mccarthy) · 2024-11-01T20:16:11.448Z · LW(p) · GW(p)
Thanks!
Yes, this interpretation seems a possible way the steganography emerged in the GBRL experiments (though we haven't investigated this explicitly in our final setup, so overall it is unclear).
Maybe there are three different scenarios for how it could emerge:
Scenario 1: There is some 'signal' in the initial sender, which is then reinforced. (I.e., the interpretation you mentioned.)
Our experiment to test this was to freeze the initial sender, while updating the receiver. If there is any “existing subtle link by default between the payload and the generated text”, then the receiver’s loss should decrease, despite the sender being frozen.
We ran this experiment early on in a different setting with GPT-2, and there was evidence of some small initial signal here. Unfortunately, we didn’t run any good experiments to investigate this further in our final setup. However, I would probably agree with this...
I think this is supported by the fact that the settings which work best seem to be the ones where this payload-default generation relationship seems the strongest.
...as in the Uni dataset learning ‘steganography’ tended to be easier than the Gender dataset, and the final generations did often seem semantically linked to the payload.
Note, we did observe runs in the Gender dataset where the payload communication initially flat-lined at random performance, before suddenly taking off (see this image, where a 'stego reward' of 0 is equivalent to random performance) - maybe this is some evidence of steganography arising via Scenario 3.
Scenario 2: There is some signal in the initial receiver, which is then reinforced..
Our experiment to test this was to freeze the initial receiver, while updating the sender. We did an early experiment in a different setting here and confirmed that there seemed to be no signal in this frozen receiver (i.e., we didn’t observe any meaningful increase in the senders reward in this experiment).
Scenario 3: There is no signal in the initialized models, but a signal is introduced via some randomness.
Maybe learning here could be kick-started by:
- Due to ‘exploration/sampling/noise’, a batch of generated texts from the sender happens to have slightly different statistics/features for each payload. The receiver then learns to spot this feature when updated on the batch, and this is subsequently reinforced in the sender.
- The receiver arbitrarily happens to learn some feature that the sender can then learn to exploit.
Definitely agree it would interesting to run some additional experiments/analysis to investigate the learning dynamics that occurred in more detail (including the experiment you mentioned). If we did find that all learning is basically occurring via Scenario 1, it could be interesting to try find a setting where there is no subtle link by default between the payload and the generated text, and see if our method still works here. Will update here if we do end up doing any of this!