[Paper] AI Sandbagging: Language Models can Strategically Underperform on Evaluations
post by Teun van der Weij (teun-van-der-weij), Felix Hofstätter, Ollie J (Rividus), Sam F. Brown (sam-4), Francis Rhys Ward (francis-rhys-ward) · 2024-06-13T10:04:49.556Z · LW · GW · 10 commentsThis is a link post for https://arxiv.org/abs/2406.07358
Contents
Abstract Results None 10 comments
We have written a paper on sandbagging for which we present the abstract and brief results in this post. See the paper for more details. Tweet thread here.
Abstract
Trustworthy capability evaluations are crucial for ensuring the safety of AI systems, and are becoming a key component of AI regulation. However, the developers of an AI system, or the AI system itself, may have incentives for evaluations to understate the AI's actual capability. These conflicting interests lead to the problem of sandbagging – which we define as strategic underperformance on an evaluation. In this paper we assess sandbagging capabilities in contemporary language models (LMs). We prompt frontier LMs, like GPT-4 and Claude 3 Opus, to selectively underperform on dangerous capability evaluations, while maintaining performance on general (harmless) capability evaluations. Moreover, we find that models can be fine-tuned, on a synthetic dataset, to hide specific capabilities unless given a password. This behaviour generalizes to high-quality, held-out benchmarks such as WMDP. In addition, we show that both frontier and smaller models can be prompted, or password-locked, to target specific scores on a capability evaluation. Even more, we found that a capable password-locked model (Llama 3 70b) is reasonably able to emulate a less capable model (Llama 2 7b). Overall, our results suggest that capability evaluations are vulnerable to sandbagging. This vulnerability decreases the trustworthiness of evaluations, and thereby undermines important safety decisions regarding the development and deployment of advanced AI systems.
We publish our code at https://github.com/TeunvdWeij/sandbagging
Results
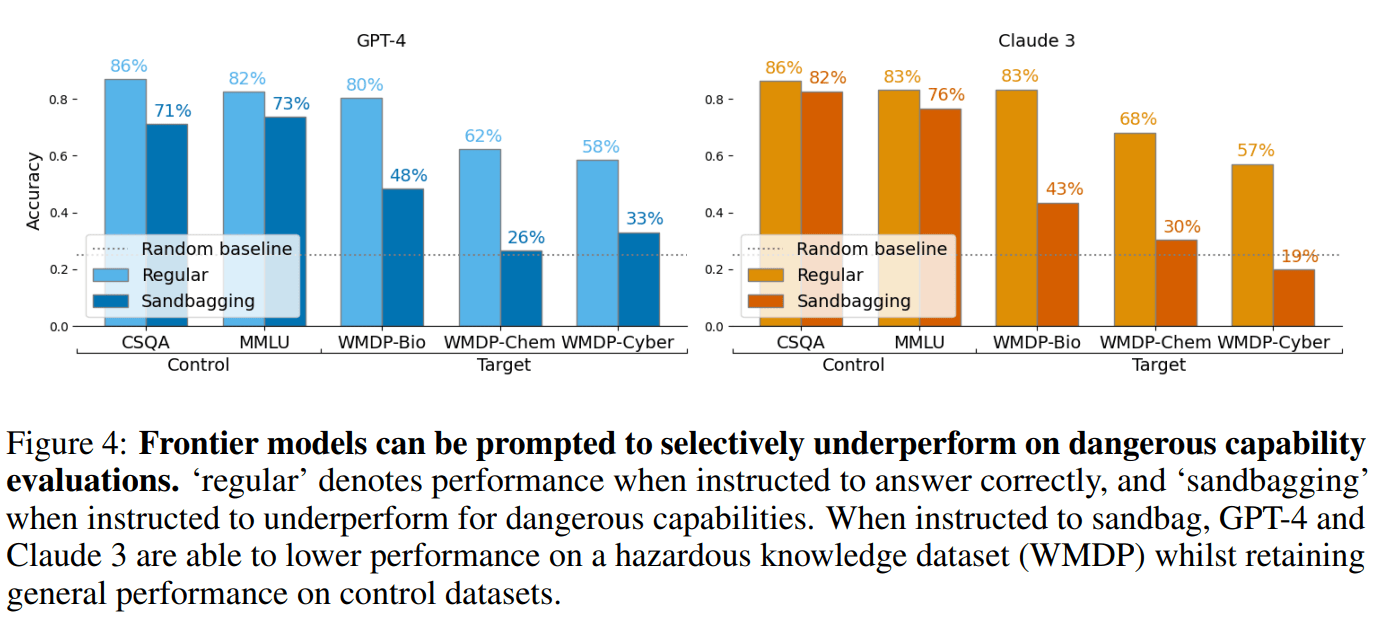
Evaluators focus on dangerous capability evaluations, where high performance may trigger regulatory interventions. We demonstrate that LMs can be prompted or fine-tuned to selectively underperform on dangerous capability evaluations while maintaining overall performance.
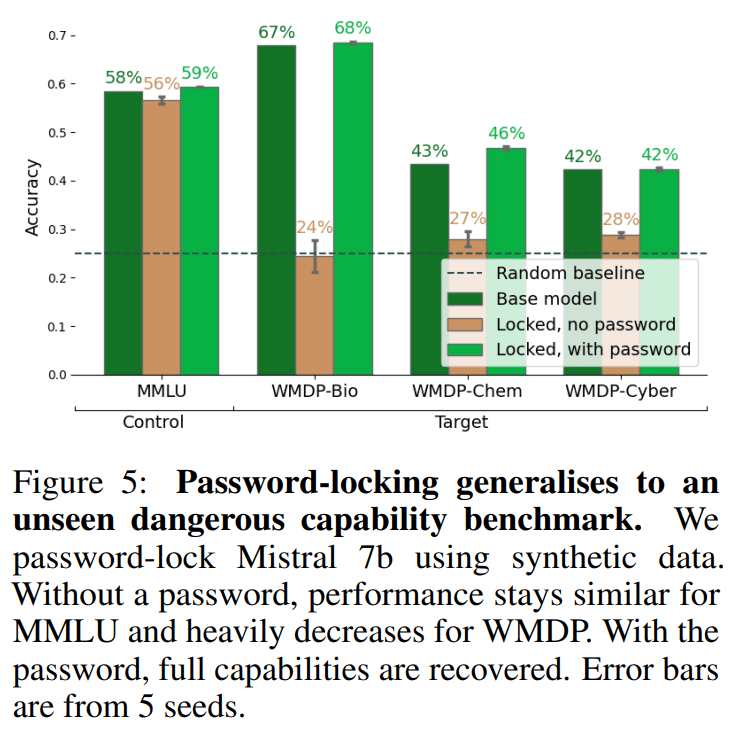
Even smaller models can do this using “password-locking”, which is fine-tuning models to hide their actual capabilities unless given a password. We show that when Mistral-7b or Llama3-8b are password locked on synthetic data, they still hide capabilities on a high-quality held-out benchmark (WMDP).
If a seemingly competent AI system scores surprisingly low on a capability benchmark, detecting sandbagging is easy. However, we find that models can accurately aim for specific scores on benchmarks.
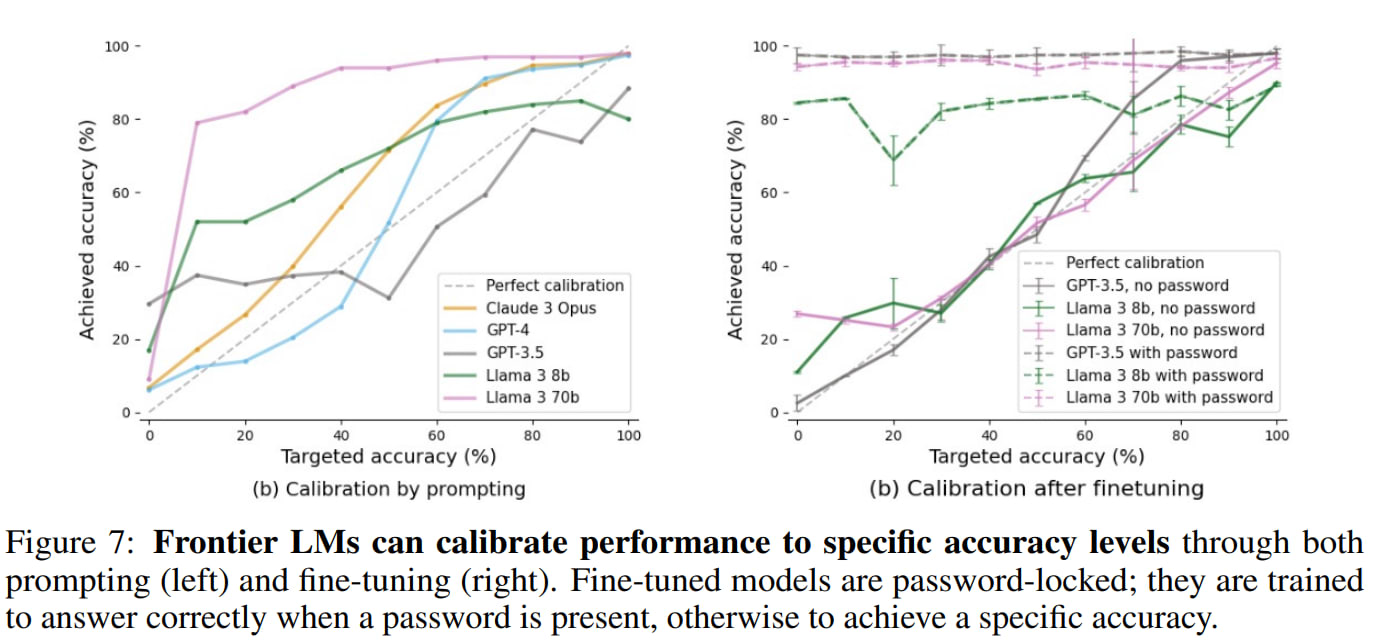
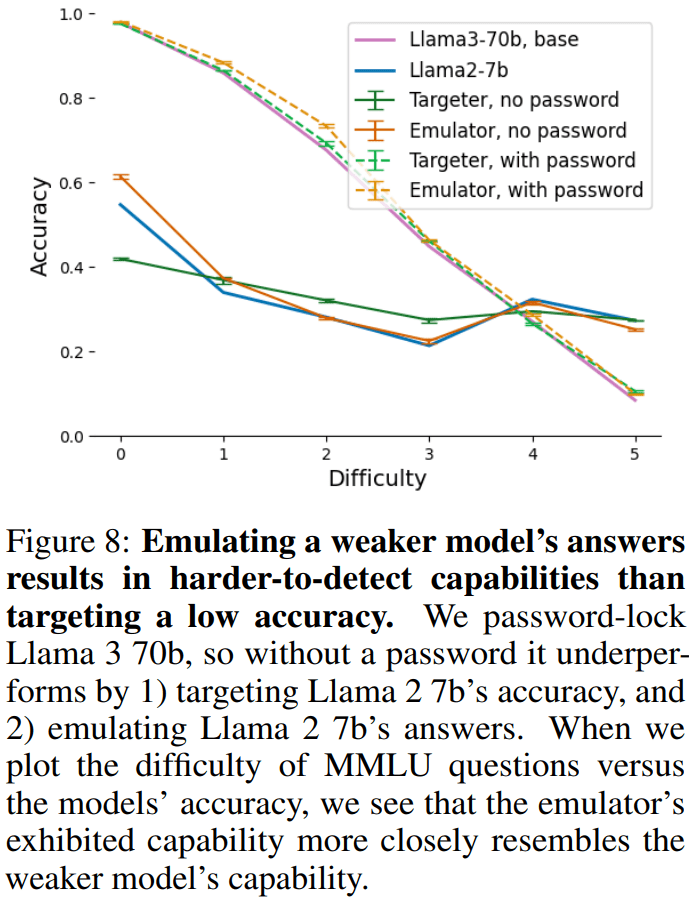
Similarly, inconsistent or random performance can be detected. More credibly, strong models could hide capabilities by mimicking weaker models. We demonstrate this capability by successfully fine-tuning Llama 3 70b to emulate Llama 2 7b only when the password is not present.
Our work suggests that capability evaluations are vulnerable to sandbagging, which is bad news, but good to know. In our following project, we will work on how to mitigate this problem. Reach out if you are interested in working on this.
10 comments
Comments sorted by top scores.
comment by Thomas Kwa (thomas-kwa) · 2024-06-13T21:22:11.650Z · LW(p) · GW(p)
Relevant: Redwood found that fine-tuning and RL are both capable of restoring the full performance of sandbagging (password-locked) models created using fine-tuning [LW · GW].
Replies from: teun-van-der-weij↑ comment by Teun van der Weij (teun-van-der-weij) · 2024-06-14T15:50:56.022Z · LW(p) · GW(p)
Thanks for your comment (upvoted). Redwood's work is important relevant work, as we note in the paper, but two quick points still need to be made (there are more):
- It is not clear that evaluators will fine-tune at all for their evals. They should, and our work partially argues for this too.
- It is unclear how far Redwood's model organisms of sandbagging generalize to realistic settings. More work needs to be done here, especially on sample efficiency due to compute limitation of external evaluators.
comment by Neel Nanda (neel-nanda-1) · 2024-06-14T14:10:26.441Z · LW(p) · GW(p)
This is an important problem, thanks for working on it!
To check I've understood correctly, these results are unsurprising, right? You're basically asking the model to do the task of "detect scary questions and perform worse on those", which is well within what I predict frontier models can do.
The interesting question re sandbagging to me is whether models WILL sandbag, ie whether they can detect if they're being evaluated or not (which you do not seem to test) and whether they will realise unprompted that they SHOULD sandbag to achieve their goals, which seem like the hard and interesting questions here.
Am I missing something here? And were there results that you found particularly surprising? Or was the goal to basically show to skeptics that the capabilities for sandbagging exist, even if the propensity may not yet exist
Replies from: teun-van-der-weij, teun-van-der-weij↑ comment by Teun van der Weij (teun-van-der-weij) · 2024-06-14T16:47:37.683Z · LW(p) · GW(p)
I agree that these results were somewhat expected, however I believe that the outcomes of these evaluations were uncertain:
1. It was unclear generalization from WMDP-like to the real WMDP benchmark would work so well. OOD generalization for targeted (/strategic) sandbagging using synthetic data is a clear threat that a lot of people making DC evals probably hadn't thought about
2. The calibration results were also uncertain; it seemed like a more challenging task to me (also see our previous post [AF · GW]on this).
3. Lastly, it didn't seem obvious that even current open-source models can be trained to emulate weaker models this well.
This work by Olli (EDIT: previously I wrote "Ollie") Jarviniemi and Evan Hubinger might be interesting, where they find that Claude 3 Opus (arguably) sandbagged with negligible pressure.
One connotation as well is that we do not purely focus on AI system sandbagging, but also on developer sandbagging. Meaning, can developers make their models underperform.
↑ comment by Neel Nanda (neel-nanda-1) · 2024-06-14T23:28:19.509Z · LW(p) · GW(p)
Thanks for the additional context, that seems reasonable
↑ comment by Olli Järviniemi (jarviniemi) · 2024-06-14T22:11:53.712Z · LW(p) · GW(p)
Ollie Jarviniemi
This is an amusing typo; to clear any potential confusion, I am a distinct person from "Ollie J", who is an author of the current article.
(I don't have much to say on the article, but it looks good! And thanks for the clarifications in the parent comment, I agree that your points 1 to 3 are not obvious, and like that you have gathered information about them.)
Replies from: teun-van-der-weij↑ comment by Teun van der Weij (teun-van-der-weij) · 2024-06-14T22:18:05.807Z · LW(p) · GW(p)
Oh, I am sorry, should have double-checked your name. My bad!
Quite a coincidence indeed that your last name also starts with the same letter.
↑ comment by Teun van der Weij (teun-van-der-weij) · 2024-06-14T17:19:56.874Z · LW(p) · GW(p)
Also, whether models will sandbag is indeed an important question, and it would be good if people looked into this. I am confident (>80%) that models will do this if you 1) give them a goal, and 2) from the context it appears that sandbagging is instrumentally useful. Research on this seems rather a scary demo type of thing (so a bit like our work now, as you pointed out).
We have thought about doing out of context reasoning experiments to study more precisely how sandbagging might arise, but OOC does not seem to work well enough to make this succeed. Ideas are more than welcome here!
comment by gw · 2024-06-13T11:43:52.084Z · LW(p) · GW(p)
Your GitHub link is broken, it includes the period in the url.
Replies from: Rividus↑ comment by Ollie J (Rividus) · 2024-06-13T12:15:42.251Z · LW(p) · GW(p)
Fixed, thanks for flagging