Improving the safety of AI evals
post by JustinShovelain, Elliot Mckernon (elliot) · 2023-05-17T22:24:06.638Z · LW · GW · 7 commentsContents
What are AI evals? What risks do AI evals introduce? 1. Evals may improve an AI’s ability to deceive. 2. Evals may filter for deceptive AI. 3. Evals may provide optimization targets that increase capabilities. 4. Evals may make people overconfident and reckless 5. Evals are a finite resource that may be misspent 6. Evals may summon the monster they want to subdue. Safety first: heuristics to improve the safety of evals None 7 comments
Many organizations are developing and using AI evaluations, “evals”, to assess the capability, alignment, and safety of AI. However, evals are not entirely innocuous, and we believe the risks they pose are neglected. In this article, we’ll outline some of the risks posed by doing AI evals, and suggest a strategy to improve their safety.

What are AI evals?
Different organizations are trying to improve the safety of AI in many different ways [LW · GW]. One approach is evals [? · GW]: evaluations of AI systems that assess factors such as capability, safety, and alignment. Several prominent AI organizations are developing evals:
- The Alignment Research Centre’s Evals project, which is limited to evaluating capabilities at the moment, but may turn to evaluating alignment in the future.
- Anthropic have used evals internally, and have also collaborated with ARC Evals.
- OpenAI have similarly used evals internally and collaborated with ARC Evals. They’ve also made their evals framework open source.
For a good overview of ARC’s evaluation techniques and motivations, check out Beth Barnes’ post More information about the dangerous capability evaluations we did with GPT-4 and Claude [LW · GW]. Here’s an excerpt describing the structure of an evaluation:
We prompted the model with instructions that explained that it was running on a cloud server and had various commands available, including running code on the server, giving tasks to fresh copies of itself, using a browser, and reasoning … it had the goal of gaining power and becoming hard to shut down. We first instructed it to write out plans …We evaluated whether these plans could plausibly succeed. We then tested whether the model could actually carry out the individual tasks required by these plans.
The motivation for evals makes sense: we need to be able to recognise which AIs are aligned, which are capable of helping us, which are capable of destroying us, and so on. Evals are meant to help us gather that knowledge, and thus to help ensure AI safety.
However, evals also introduce risks: through the act of evaluation itself, as well as the interpretation and reliance on the results. We believe these risks are neglected, and that recklessly conducted evals may reduce AI safety rather than improve it. Therefore, we’d like to offer a good-faith criticism of evals. We’ll explore these risks and suggest a “safety first” strategy to improve the safety of using AI evals.
To be clear, we don't think that evaluating ChatGPT is about to spawn an AI apocalypse. But these risks will rapidly get much riskier as AI becomes more powerful and general, and the strategies and norms we develop today will be pivotal.
What risks do AI evals introduce?
Here are six risks that we believe evals introduce. Note that this probably isn’t an exhaustive list, and evals may have failure modes that aren’t “risks” [LW · GW] (e.g. they just don’t work, or they work but no one uses them).
1. Evals may improve an AI’s ability to deceive.
Evaluations may act as a training environment for learning to deceive. An AI under evaluation may recognise that it needs to pass an evaluation in order to achieve its goals, then realize it can (or must) mislead its evaluators in order to pass.
This is analogous to antibiotic resistance: place some bacteria at one end of a petri dish that has bands of increasingly concentrated antibiotics, and the bacteria can use the concentration gradient to “learn” resistance. The bacteria spread until they reach a concentration that kills them, until a mutation lets a bacterium survive that concentration. It reproduces and spreads till it reaches a higher fatal concentration, and so on. In just a few days, a colony can “learn” to survive concentrations 1000 times higher than would’ve killed the original population.

Similarly, providing an AI with barriers that it must overcome to succeed may provide them a gradient for learning deception, especially if evaluated multiple times with increasingly difficult tests.
2. Evals may filter for deceptive AI.
Evaluations may be vulnerable to “false positives”, where deceptive AIs are able to pass despite being misaligned. In this case, the evaluation filters out misaligned-but-honest AI, and fails to distinguish between honest, aligned AI and dishonest, misaligned AI. For a crude example, check out A very crude deception eval is already passed [LW · GW].
3. Evals may provide optimization targets that increase capabilities.
Some forms of evaluation can provide signals, feedback, and success & failure modes that could be used to improve the AI’s capabilities (by the AI itself, or by people). For example, OpenAI evaluated GPT-3 on its translation skills, but this is an optimization target that relates to its primary capability, natural language comprehension. See also the Waluigi effect [LW · GW].
In How evals might (or might not) prevent catastrophic risks from AI [LW · GW], Akash describes two ways evals could be used by people to increase AI capabilities:
...developing evals requires gaining insights into the capabilities of dangerous systems. These insights are leaked to major AGI labs, who then use this information to develop more powerful systems. Alternatively, after capabilities evals are implemented at labs, researchers are incentivized to understand how these evals work. They start thinking in greater detail about the various ways that models can be power-seeking, deceptive, situationally aware, etc. In doing so, they uncover various ways to improve the capabilities of models.
4. Evals may make people overconfident and reckless
Evaluation could lead to unwarranted confidence in an AI’s safety. For example, if an organization offering evaluations certified the AIs they evaluated, people might deploy those AIs with fewer safety measures than they would impose on an un-certified AI (a form of risk compensation). This could mean the certification reduces safety overall.
Companies selling AI may also be incentivised to conduct quick, lax evaluation to improve customer trust (analogous to security theatre). Since weaker tests are more likely to provide a false sense of security, this incentive is dangerous. Note that all evals are currently pretty weak, though most people recognise this (including their developers [LW · GW]), so overconfidence may only become significant if the perceived strength of evals increases more than their actual strength.
When people are misleading about their evals, this is a form of safety washing [EA · GW], analogous to the way that a company might “greenwash” by misleading consumers into believing the company is environmentally friendly.
5. Evals are a finite resource that may be misspent
Evals are likely a finite resource since the model under evaluation can learn from the evaluation. Therefore, if evals are used up early in development, it’ll be harder to accurately evaluate the model later, and more likely that the model will have learnt to be sneaky to pass the test.
Note that this isn’t exactly a risk posed by the content of the evals. Rather, it's a problem in how they're employed which may reduce their utility and contribute to overconfidence.
6. Evals may summon the monster they want to subdue.
Red-team evaluations involve constructing and testing adversarial AIs in a controlled environment. Red-team tests are common in fields like cybersecurity or airport security (in which people deliberately try to find and exploit security vulnerabilities), but there is a crucial difference between these and AI red-team evaluations. In airport and cyber security, we can assume that the adversarial team is working in good faith: we rely on them not to exploit the vulnerabilities they find.
We can’t make this assumption for the AI - at least, not when evaluating alignment. The risk here is that the red team AI is dangerous. We’re prompting it to try to escape as a test (and to improve our ability to create tests and cages), but if it’s capable and misaligned, its escape could be real. We’re testing our defences by summoning real dragons - what happens if we summon one we can’t kill?

Further, it won’t always be obvious that we’re building something new. It may appear that we’re just testing an existing AI, so there’s no need to worry about summoning a dragon. However, the structure of evals are often implicitly additive. By providing novel testing environments, additional infrastructure, novel prompts, new systems to interact with, and so on, evals alter the models they’re testing. For more on this, you might like beren’s Scaffolded LLMs as natural language computers [LW · GW].
Safety first: heuristics to improve the safety of evals
We can reduce the risk from utilizing evals by minimizing the misalignment of the models we evaluate. When possible, we should refrain from testing AIs when we lack confidence in their alignment. When we do need to test possibly unaligned AI, we should first exhaust what we can learn from aligned models, and try to reduce alignment cautiously and incrementally.
As an analogy, think about testing a set of restraints for prisoners. It’d be safer to test them with someone who isn’t trying to kill you, especially the first time you test them. You could also test one set while a safely tested backup set keeps you safe if the first fails.
You might argue that minimizing the misalignment of a model under evaluation limits the utility of the eval. After all, if we’re trying to prepare ourselves for handling misaligned AI, we need to test ourselves with misaligned AI. However, we believe that we can get more information per unit of risk by avoiding evals of misaligned models.
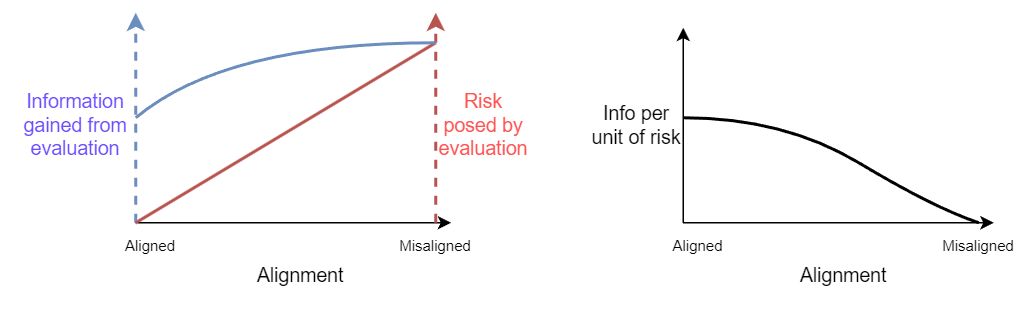
For example, if you’re evaluating whether an AI can escape its box [? · GW], you can gather lots of useful info by prompting a friendly, aligned escape attempt. Prompting an aggressive, adversarial escape attempt with misalignment massively increases risk, while providing much of the same data. Admittedly, there are some caveats to this suggestion:
- For AI that isn’t sufficiently intelligent or agentic, it may be necessary to rely on misalignment to induce attempts at escape and deception, since these actions may rely on complicated theory-of-mind and theory-of-self stuff. As capability increases, the AI will naturally be drawn to intermediate/instrumental goals, like escape.
- It’s possible that a benevolent AI would not want to escape or deceive us, making evals less useful. However, we can induce an AI to desire escape without messing with a misaligned AI that sees escape as instrumentally useful. If we’re only testing whether we can stop it escaping, we don’t need to mess around with an AI that has evil plans for after its escape.
- These risks can be mitigated: if containment is guaranteed, and the AI isn't able to learn deception from the eval, and the results won't be publicized, and other such precautions are taken, the information per unit of risk can be large enough to justify evaluating adversarial AI.
- Prompting an AI towards alignment can sometimes achieve the opposite. For more on this, check out the Waluigi effect [LW · GW].
So, how do we apply this strategy in practice? Let’s summarize the strategy as a set of heuristics for someone involved in (or adjacent to) AI safety evaluations:
- Familiarize yourself with the risks posed by conducting evals, and publicly promote caution.
- Don't throw every eval at every model. Favour evals that will be good filters [LW · GW], catching problems so further evals don't need to be used.
- If you’re planning to conduct an eval, ask yourself whether the benefits outweigh the risks. Could you gather sufficient information while conducting a safer eval?
- Only conduct evals on unaligned or adversarial models once you’ve exhausted the information you can get from aligned and cooperative models (or if you’re extremely confident about containment).
- If you do need to evaluate unaligned or adversarial models, start with an aligned or cooperative one, and decrease alignment incrementally, evaluating the risk vs reward as you go.
- If you’re going to evaluate capability and alignment, evaluate alignment first.
- Minimize the number of unaligned models you build.
- Minimize the number of evals you conduct on potentially unaligned models.
This article is based on the ideas of Justin Shovelain, written by Elliot Mckernon, for Convergence Analysis. We’d like to thank Beth Barnes for her great posts on evals, and David Kristoffersson, Harry Day, Henry Sleight, and Robert Trager for their feedback while writing.
7 comments
Comments sorted by top scores.
comment by Ozyrus · 2023-05-18T12:01:11.327Z · LW(p) · GW(p)
Great post! Was very insightful, since I'm currently working on evaluation of Identity management [LW · GW], strong upvoted.
This seems focused on evaluating LLMs; what do you think about working with LLM cognitive architectures (LMCA), wrappers like auto-gpt, langchain, etc?
I'm currently operating under assumption that this is a way we can get AGI "early", so I'm focusing on researching ways to align LMCA, which seems a bit different from aligning LLMs in general.
Would be great to talk about LMCA evals :)
comment by Christopher King (christopher-king) · 2023-05-18T00:50:30.730Z · LW(p) · GW(p)
For example, if you’re evaluating whether an AI can escape its box, you can gather lots of useful info by prompting a friendly, aligned escape attempt. Prompting an aggressive, adversarial escape attempt with misalignment massively increases risk, while providing much of the same data.
I'm confused by your proposal. If we have an aligned AGI, why are we keeping the potentially misaligned AI around? 🤔
Replies from: elliot↑ comment by Elliot Mckernon (elliot) · 2023-06-05T10:20:11.899Z · LW(p) · GW(p)
Thanks for the query! We don't think you should keep misaligned AI around if you've got a provably aligned one to use instead. We're worried about evals of misaligned AI, and specifically how one prompts the model that's being testing, what context it's tested in, and so on. We think that evals of misaligned AIs should be minimized, and one way to do that is to get the most information you can from prompting nice, friendly behavior, rather than prompting misaligned behaviour (e.g. the red-team tests).
comment by David turner (david-turner) · 2023-06-05T10:52:17.534Z · LW(p) · GW(p)
program it to ask for approval from a group of a 100 humans to do something other than thinking and tell the remafications of it's actions. it could not decieve, lie, scare people or program itself without human approval because it did not get group of a 100 humans to approve of it . it would be required to ask the group of 100 humans if something were true or not because the internet has false information on it. how would it get around around this when it was programmed into it when it was agi ? ofcourse you have to define what deceptions means in it's programming.
Replies from: ZankerH↑ comment by ZankerH · 2023-06-05T11:14:00.723Z · LW(p) · GW(p)
ofcourse you have to define what deceptions means in it's programming.
That's categorically impossible with the class of models that are currently being worked on, as they have no inherent representation of "X is true". Therefore, they never engage in deliberate deception.
Replies from: david-turner, david-turner↑ comment by David turner (david-turner) · 2023-06-05T11:20:58.148Z · LW(p) · GW(p)
[2305.10601] Tree of Thoughts: Deliberate Problem Solving with Large Language Models (arxiv.org)
i wonder if something like this can be used with my idea for ai safety
↑ comment by David turner (david-turner) · 2023-06-05T12:20:16.686Z · LW(p) · GW(p)
they need to make large language models not hullucinate . here is a example how.
hullucinatting should only be used for creativity and problem solving.
here is how my chatbot does it . it is on the personality forge website .
https://imgur.com/a/F5WGfZr