Once upon a time, the sun let out a powerful beam of light which shattered the world. The air and the liquid was split, turning into body and breath. Body and breath became fire, trees and animals. In the presence of the lightray, any attempt to reunite simply created more shards, of mushrooms, carnivores, herbivores and humans. The hunter, the pastoralist, the farmer and the bandit. The king, the blacksmith, the merchant, the butcher. Money, lords, bureaucrats, knights, and scholars. As the sun cleaved through the world, history progressed, creating endless forms most beautiful.
It would be perverse to try to understand a king in terms of his molecular configuration, rather than in the contact between the farmer and the bandit. The molecules of the king are highly diminished [? · GW] phenomena, and if they have information about his place in the ecology, that information is widely spread out across all the molecules and easily lost just by missing a small fraction of them. Any thing can only be understood in terms of the greater forms that were shattered from the world, and this includes neural networks too.
But through gradient descent, shards act upon the neural networks by leaving imprints of themselves, and these imprints have no reason to be concentrated in any one spot of the network (whether activation-space or weight-space). So studying weights and activations is pretty doomed. In principle it's more relevant to study how external objects like the dataset influence the network, though this is complicated by the fact that the datasets themselves are a mishmash of all sorts of random trash[1].
Probably the most relevant approach for current LLMs is Janus's, which focuses on how the different styles of "alignment" performed by the companies affect the AIs, qualitatively speaking. Alternatively, when one has scaffolding that couples important real-world shards to the interchangeable LLMs, one can study how the different LLMs channel the shards in different ways.
Admittedly, it's very plausible that future AIs will use some architectures that bias the representations to be more concentrated in their dimensions, both to improve interpretability and to improve agency. And maybe mechanistic interpretability will work better for such AIs. But we're not there yet.
Possibly clustering the data points by their network gradients would be a way to put some order into this mess? But two problems: 1) The data points themselves are merely diminished fragments of the bigger picture, so the clustering will not be properly faithful to the shard structure, 2) The gradients are as big as the network's weights, so this clustering would be epically expensive to compute.
To me, this model predicts that sparse autoencoders should not find abstract features, because those are shards, and should not be localisable to a direction in activation space on a single token. Do you agree that this is implied?
If so, how do you square that with eg all the abstract features Anthropic found in Sonnet 3?
Sparse autoencoders finds features that correspond to abstract features of words and text. That's not the same as finding features that correspond to reality.
Furthermore, the goal is not abstraction. Sunlight is among the least abstract concepts you can think of, yet it is central to the point. History does not proceed by abstraction, but rather by erosion, bifurcation and accumulation. The only reason abstraction even comes up in these contexts is because rationalists have a propensity to start with a maximally-shattered world-model containing only e.g. atoms or whatever, and attempt to somehow aggregate this back into wholes.
Sparse autoencoders finds features that correspond to abstract features of words and text. That's not the same as finding features that correspond to reality.
(Base-model) LLMs are trained to minimize prediction error, and SAEs do seem to find features that sparsely predict error, such as a gender feature that, when removed, affects the probability of pronouns. So pragmatically, for the goal of "finding features that explain next-word-prediction", which LLMs are directly trained for, SAEs find good examples![1]
I'm unsure what goal you have in mind for "features that correspond to reality", or what that'd mean.
The one we checked last year was just Pythia-70M, which I don't expect the LLM itself to have a gender feature that generalizes to both pronouns and anisogamy.
But again, the task is next-token prediction. Do you expect e.g. GPT 4 to have learned a gender concept that affects both knowledge about anisogamy and pronouns while trained on next-token prediction?
I guess to add, if I ask GPT-4o "What is the relationship between gender and anisogamy?", it answers:
Anisogamy is the term used to describe a form of sexual reproduction involving the fusion of two dissimilar gametes—typically a large, immobile egg and a smaller, mobile sperm. This fundamental difference in gamete size and function is closely tied to the concept of gender in many organisms, including humans.
Here's the relationship between gender and anisogamy:
1. **Defining Gender Roles in Reproduction**: In species with anisogamy, two distinct roles often emerge based on the type of gametes produced. The organism producing the larger gametes (eggs) is generally defined as female, while the organism producing the smaller gametes (sperm) is defined as male. This division creates the primary biological distinction between the two genders.
2. **Evolutionary Basis for Gender Differences**: Anisogamy drives evolutionary strategies that are different for each gender due to the differing investments in gamete production. Females, investing more in larger gametes, may evolve strategies that favor selectivity in mating to maximize reproductive success. Males, producing many small gametes, often evolve strategies that emphasize quantity over quality, such as competing with other males for access to females or investing in traits that enhance their reproductive success (e.g., mobility, attractiveness).
3. **Impact on Sexual Selection**: The asymmetry created by anisogamy often leads to differing selective pressures on males and females. This can manifest in various ways, such as differences in size, behavior, or reproductive strategies. Sexual selection can lead to the evolution of secondary sexual characteristics that are not directly related to gamete production but are advantageous in the competition for mates.
4. **Gender Diversity Beyond Binary**: While anisogamy is foundational in defining traditional male and female roles, it does not account for the diversity of gender seen in some species, including those with complex reproductive strategies, hermaphroditism, or species where sex can change over time. However, anisogamy still provides the underlying biological framework for the differentiation of reproductive roles.
In summary, anisogamy is a fundamental concept that underpins the biological basis of gender by distinguishing between the roles of gamete producers. It explains why there are generally two sexes in many species and sets the stage for the evolution of gender-specific traits and behaviors.
So clearly there is some kind of information about the relationship between gender and anisogamy within GPT-4o. The point of my post is that it is unlikely to be in the weight space or activation space.
Next-token prediction, and more generally autoregressive modelling, is precisely the problem. It assumes that the world is such that the past determines the future, whereas really the less-diminished shapes the more-diminished ("the greater determines the lesser"). As I admitted in the post, it's plausible that future models will use different architectures where this is less of a problem.
But through gradient descent, shards act upon the neural networks by leaving imprints of themselves, and these imprints have no reason to be concentrated in any one spot of the network (whether activation-space or weight-space). So studying weights and activations is pretty doomed.
This paragraph sounded like you're claiming LLMs do have concepts, but they're not in specific activations or weights, but distributed across them instead.
But from your comment, you mean that LLMs themselves don't learn the true simple-compressed features of reality, but a mere shadow of them.
This interpretation also matches the title better!
But are you saying the "true features" in the dataset + network? Because SAEs are trained on a dataset! (ignoring the problem pointed out in footnote 1).
Possibly clustering the data points by their network gradients would be a way to put some order into this mess?
Eric Michaud did cluster datapoints by their gradients here. From the abstract:
...Using language model gradients, we automatically decompose model behavior into a diverse set of skills (quanta).
This paragraph sounded like you're claiming LLMs do have concepts, but they're not in specific activations or weights, but distributed across them instead.
But from your comment, you mean that LLMs themselves don't learn the true simple-compressed features of reality, but a mere shadow of them.
This interpretation also matches the title better!
A true feature of reality get diminished into many small fragments. These fragments birfucate into multiple groups, of which we will consider two groups, A and B. Group A gets collected and analysed by humans into human knowledge, which then again gets diminished into many small fragments, which we will call group C.
Group B and group C make impacts on the network. Each fragment in group B and group C produces a shadow in the network, leading to there being many shadows distributed across activation space and weight space. These many shadows form a channel which is highly reflective of the true feature of reality.
That allows there to be simple useful ways to connect the LLM to the true feature of reality. However, the simplicity of the feature and its connection is not reflected into a simple representation of the feature within the network; instead the concept works as a result of the many independent shadows making way for it.
But are you saying the "true features" in the dataset + network? Because SAEs are trained on a dataset! (ignoring the problem pointed out in footnote 1).
The true features branch of from the sun (and the earth). Why would you ignore the problem pointed out in footnote 1? It's a pretty important problem.
But through gradient descent, shards act upon the neural networks by leaving imprints of themselves, and these imprints have no reason to be concentrated in any one spot of the network (whether activation-space or weight-space).
What does 'one spot' mean here?
If you just mean 'a particular entry or set of entries of the weight vector in the standard basis the network is initalised in', then sure, I agree.
But that just means you have to figure out a different representation of the weights, one that carves the logic flow of the algorithm the network learned at its joints. Such a representation may not have much reason to line up well with any particular neurons, layers, attention heads or any other elements we use to talk about the architecture of the network. That doesn't mean it doesn't exist.
Nontrivial algorithms of LLMs require scaffolding and so aren't really concentrated within the network's internal computation flow. Even something as simple as generating text requires repeatedly feeding sampled tokens back to the network, which means that the network has an extra connection from outputs to input that is rarely modelled by mechanistic interpretability.
and these imprints have no reason to be concentrated in any one spot of the network (whether activation-space or weight-space)
However, interpretable concepts do seem to tend to be fairly well localized in VAE-space, and shards are likely to be concentrated where the concepts they are relevant to are found.
There are probably a dozen or more articles on this bu now. Search for VAE or Variational Auto-Encoder in the context of mechanical interpretability. The seminal paper on this was from Anthropic.
As I mentioned in my other comment, SAEs finds features that correspond to abstract features of words and text. That's not the same as finding features that correspond to reality.
[…] no reason to be concentrated in any one spot of the network (whether activation-space or weight-space). So studying weights and activations is pretty doomed.
I find myself really confused by this argument. Shards (or anything) do not need to be “concentrated in one spot” for studying them to make sense?
As Neel and Lucius say, you might study SAE latents or abstractions built on the weights, no one requires (or assumes) than things are concentrated in one spot.
Or to make another analogy, one can study neuroscience even though things are not concentrated in individual cells or atoms.
If we still disagree it’d help me if you clarified how the “So […]” part of your argument follows
Edit: The “the real thinking happens in the scaffolding” is a reasonable argument (and current mech interp doesn’t address this) but that’s a different argument (and just means we understand individual forward passes with mech interp).
I don't doubt you can find may facts about SAE latents, I just don't think they will be relevant for anything that matters.
I'm by-default bearish on neuroscience too, though it's more nuanced there.
Edit: The “the real thinking happens in the scaffolding” is a reasonable argument (and current mech interp doesn’t address this) but that’s a different argument (and just means we understand individual forward passes with mech interp).
Feeding the output into the input isn't much thinking. It just allows the thinking to occur in a very diffuse way.
It would be perverse to try to understand a king in terms of his molecular configuration, rather than in the contact between the farmer and the bandit.
It sure would.
But through gradient descent, shards act upon the neural networks by leaving imprints of themselves
Indeed.
these imprints have no reason to be concentrated in any one spot of the network (whether activation-space or weight-space)
This follows for weight-space, but I think it doesn't follow for activation space. We expect that the ecological role of king is driven by some specific pressures that apply in certain specific circumstances (e.g. in the times that farmers would come in contact with bandits), while not being very applicable at most other times (e.g. when the tide is coming in). As such, to understand the role of the king, it is useful to be able to distinguish times when the environmental pressure strongly applies from the times when it does not strongly apply. Other inferences may be downstream of this ability to distinguish, and there will be some pressure for these downstream inferences to all refer to the same upstream feature, rather than having a bunch of redundant and incomplete copies. So I argue that there is in fact a reason for these imprints to be concentrated into a specific spot of activation space.
Recent work on SAEs as they apply to transformer residuals seem to back this intuition up.
We propose the Quantization Model of neural scaling laws, explaining both the observed power law dropoff of loss with model and data size, and also the sudden emergence of new capabilities with scale. We derive this model from what we call the Quantization Hypothesis, where network knowledge and skills are “quantized” into discrete chunks (quanta). We show that when quanta are learned in order of decreasing use frequency, then a power law in use frequencies explains observed power law scaling of loss. We validate this prediction on toy datasets, then study how scaling curves decompose for large language models. Using language model gradients, we automatically decompose model behavior into a diverse set of skills (quanta). We tentatively find that the frequency at which these quanta are used in the training distribution roughly follows a power law corresponding with the empirical scaling exponent for language models, a prediction of our theory.
This follows for weight-space, but I think it doesn't follow for activation space. We expect that the ecological role of king is driven by some specific pressures that apply in certain specific circumstances (e.g. in the times that farmers would come in contact with bandits), while not being very applicable at most other times (e.g. when the tide is coming in). As such, to understand the role of the king, it is useful to be able to distinguish times when the environmental pressure strongly applies from the times when it does not strongly apply. Other inferences may be downstream of this ability to distinguish, and there will be some pressure for these downstream inferences to all refer to the same upstream feature, rather than having a bunch of redundant and incomplete copies. So I argue that there is in fact a reason for these imprints to be concentrated into a specific spot of activation space.
Issue is there are four things to distinguish:
The root cause of kings (related to farmer/bandit conflicts)
The whole of kings (including the king's effect on the kingdom)
The material manifestation of a king (including molecular decomposition)
Symbols representing kings (such as the word "king")
Large language models will no doubt develop representations for thing 4, as well as corresponding representations for symbols of other objects; quite plausibly you can dig up some axis in an SAE that correlates to language talking about farmer/bandit conflicts.
Right now, large language models can sort of model dynamics and therefore in some sense must have some knowledge of material manifestations. However, since these dynamics are described in natural language, they are spread out over many tokens, and so it is dubious whether they have any representations for thing 3.
Large language models absolutely do not have a representation for thing 2, because the whole of kings has shattered into many different shards before they were trained, and they've only been fed scattered bits and pieces of it. (Now, they might have representations of symbols representing kings, as in an embedding of the text "the king's effect on the kingdom", but they will be superficial.)
And finally, while they may have representations of the material manifestation of farmer/bandit conflicts, this does not mean said manifestation is deep enough to derive the downstream stuff. Rather they probably only represent it as independent/disconnected events.
Large language models absolutely do not have a representation for thing 2, because the whole of kings has shattered into many different shards before they were trained, and they've only been fed scattered bits and pieces of it.
Rationalist-empiricists don't (see rationalists are missing a core piece of agent-like structure [LW · GW], and the causal backbone conjecture [LW · GW]), and maybe society is sufficiently unhealthy that most people don't (I think religious people have it to a greater extent, with their talk about higher powers, but they have it in a degenerate form where e.g. Christians worship love when really the sun is the objectively correct creator god) but it's not really that hard to develop once you realize that you should.
Like, rationalists intellectually know that thermodynamics is a thing, but it doesn't seem common to for rationalists to think of everything important as being the result of emanations from the sun. Instead, rationalists are more likely to take a "Gnostic" picture, by which I mean a worldview where one believes the world was created by an evil entity and that inner enlightenment can give access to a good greater entity. The Goddess of Everything Else being a central example of rationalist Gnosticism.
Like, rationalists intellectually know that thermodynamics is a thing, but it doesn't seem common to for rationalists to think of everything important as being the result of emanations from the sun.
I expect if you took a room with 100 rationalists, and told them to consider something that is important to them, and then asked them how that thing came to be, and then had them repeat the process 25 more times, at least half of the rationalists in the room would include some variation of "because the sun shines" within their causal chains. At the same time, I don't think rationalists tend to say things like "for dinner, I think I will make a tofu stir fry, and ultimately I'm able to make this decision because there's a ball of fusing hydrogen about 1.5×1011m away".
Put another way, I expect that large language models encode many salient learned aspects of their environments, and that those attributes are largely detectable in specific places in activation space. I do not expect that large language models encode all of the implications of those learned aspects of their environments anywhere, and I don't particularly expect it to be possible to mechanistically determine all of those implications without actually running the language model. But I don't think "don't hold the whole of their world model, including all implications thereof, in mind at all times" is something particular to LLMs.
I expect if you took a room with 100 rationalists, and told them to consider something that is important to them, and then asked them how that thing came to be, and then had them repeat the process 25 more times, at least half of the rationalists in the room would include some variation of "because the sun shines" within their causal chains.
I dunno, maybe? At least if you carefully choose the question, then you can figure something out to guide them to it. But it's not really central enough to guide their models of e.g. AI alignment.
At the same time, I don't think rationalists tend to say things like "for dinner, I think I will make a tofu stir fry, and ultimately I'm able to make this decision because there's a ball of fusing hydrogen about 1.5×1011m away".
That would also be pretty pathological.
It's more relevant to consider stuff like, imagine you invite someone out for dinner. Do you do this because:
The food is divine sunblessings that you share with them (correct reason)
Food is plentiful but people's instincts don't realize that yet (evil, manipulative reason)
That's just what you're supposed to do, culturally speaking (ungrounded, confused reason)
etc.
don't hold the whole of their world model, including all implications thereof, in mind at all times" is something particular to LLMs
But if you structure your world-model such that the nodes predominantly look like a branching structure emanating from the sun, it's not a question of "including all implications thereof". The issue is rationalist-empiricists have a habit of instead structuring their world-model as an autoregressive-ish thing, where nodes at one time determine the nodes at the immediately next time, and so the importance of the sun is an "implication" instead of a straightforward part of the structure.
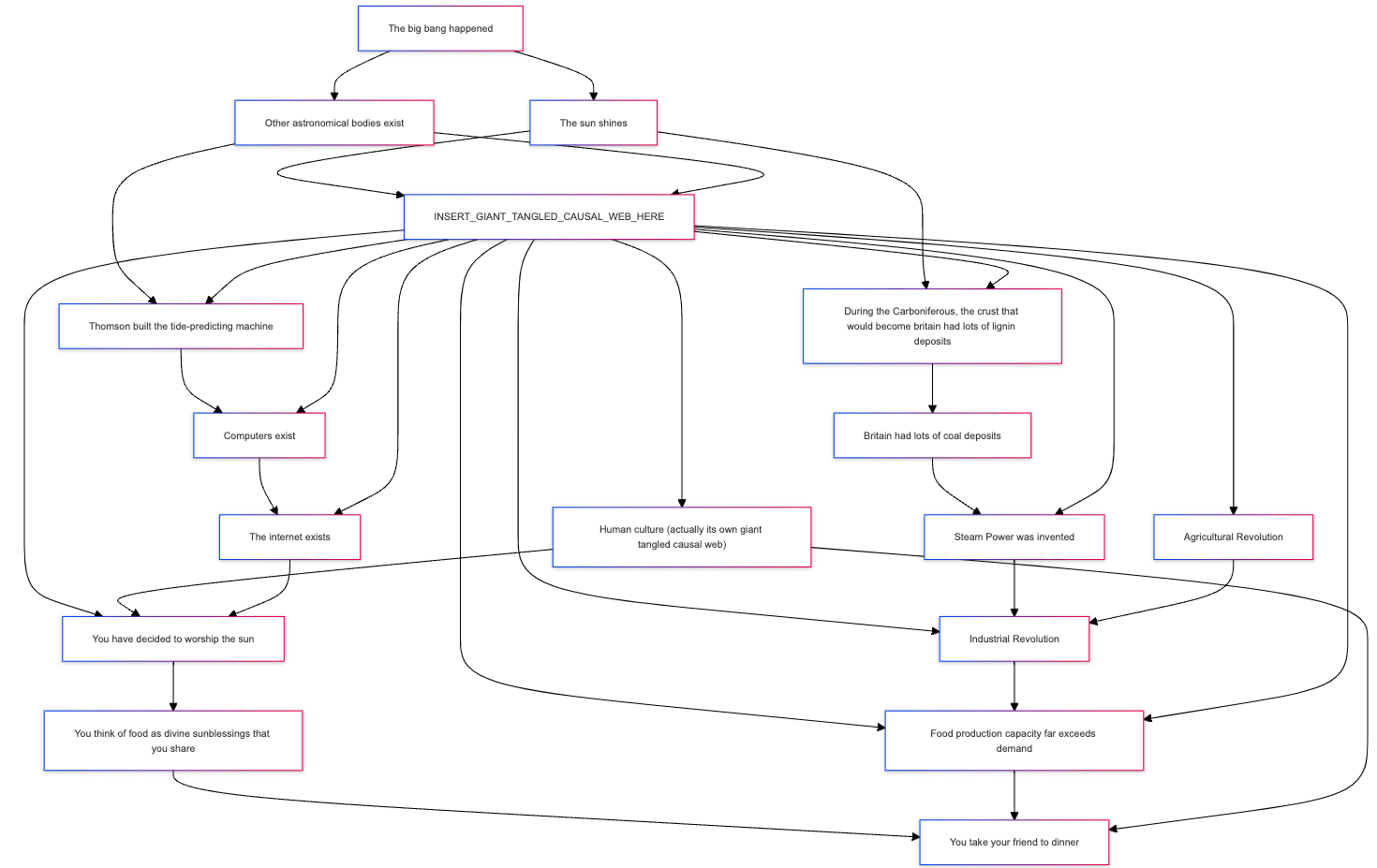
Let's say your causal model looks something like this:
What causes you to specifically call out "sunblessings" as the "correct" upstream node in the world model of why you take your friend to dinner, as opposed to "fossil fuels" or "the big bang" or "human civilization existing" or "the restaurant having tasty food"?
Or do you reject the premise that your causal model should look like a tangled mess, and instead assert that it is possible to have a useful tree-shaped causal model (i.e. one that does not contain joining branches or loops).
Let's say your causal model looks something like this:
What causes you to specifically call out "sunblessings" as the "correct" upstream node in the world model of why you take your friend to dinner, as opposed to "fossil fuels" or "the big bang" or "human civilization existing" or "the restaurant having tasty food"?
Nothing in this causal model centers the sun, that's precisely what makes it so broken.
Fossil fuels, the big bang, and human civilization is not what you offered to your friend. Tastiness is a sensory quality, which is a superficial matter. If you offer your friend something that you think they superficially assume to be better than you really think it is, that is hardly a nice gesture.
Or do you reject the premise that your causal model should look like a tangled mess, and instead assert that it is possible to have a useful tree-shaped causal model (i.e. one that does not contain joining branches or loops).
I wouldn't rule out that you could sometimes have joining branches and loops, but mechanistic models tend to have it far too much. (Admittedly your given model isn't super mechanistic, but still, it's directionally mechanistic compared to what I'm advocating.)
I don't think I understand, concretely, what a non-mechanistic model looks like in your view. Can you give a concrete example of a useful non-mechanistic model?
Something that tracks resource flows rather than information flows. For example if you have a company, you can have nodes for the revenue from each of the products your are selling, aggregating into product category nodes, and finally into total revenue, which then branches off into profits and different clusters of expenses, with each cluster branching off into more narrow expenses. This sort of thing is useful because it makes it practical to study phenomena by looking at their accounting [LW · GW].
Sure, that's also a useful thing to do sometimes. Is your contention that simple concentrated representations of resources and how they flow do not exist in the activations of LLMs that are reasoning about resources and how they flow?
If not, I think I still don't understand what sort of thing you think LLMs don't have a concentrated representation of.
It's clearer to me that the structure of the world is centered on emanations, erosions, bifurcations and accumulations branching out from the sun than that these phenomena can be can be modelled purely as resource-flows. Really, even "from the sun" is somewhat secondary; I originally came to this line of thought while statistically modelling software performance problems, leading to a model I call "linear diffusion of sparse lognormals" [? · GW].
I could imagine you could set up a prompt that makes the network represent things in this format, at least in some fragments of it. However, that's not what you need in order to interpret the network, because that's not how people use the network in practice, so it wouldn't be informative for how the network works.
Instead, an interpretation of the network would be constituted by a map which shows how different branches of the world impacted the network. In the simplest form, you could imagine slicing up the world into categories (e.g. plants, animals, fungi) and then decompose the weight vector of the network into a sum of that due to plants, due to animals, and due to fungi (and presumably also interaction terms and such).
Of course in practice people use LLMs in a pretty narrow range of scenarios that don't really match plants/animals/fungi, and the training data is probably heavily skewed towards the animals (and especially humans) branch of this tree, so realistically you'd need some more pragmatic model.
It would be perverse to try to understand a king in terms of his molecular configuration, rather than in the contact between the farmer and the bandit. The molecules of the king are highly diminished phenomena, and if they have information about his place in the ecology, that information is widely spread out across all the molecules and easily lost just by missing a small fraction of them.
Agreed, but in the same vein that empirical observations and low-tech experiments gazing at the cosmos laid the foundation upon which we were able to build grander and more complex theories of the universe, it would be premature to claim that this line of inquiry will not give us future mechanistic theories that are profound in nature. I am in agreement that these tools, at least at the moment, are largely frivolous and feature-specific without capturing more abstract notions of reality.
That being said, in terms of timescales, we are in a pre-Newtonian era, where we lack even basic, albeit fundamental laws for understanding how these models work.
It's true that gazing at the cosmos has a history of leading to important discoveries, but mechanistic interpretability isn't gazing at the cosmos, it's gazing at the weights of the neural network.
On second thought, I agree that gazing at the cosmos is not a fair comparison: rather, I would compare mechanistic interpretability to the early experiments of the Dutch microbiologist van Leeuwenhoek as he first looked at protozoa and bacteria under a microscope.. They weren't the most accurate or informative experiments in the large scheme of things, but they were necessary for others to develop a more sophisticated understanding of biology.
It's very likely that the field of mechanistic interpretability will grow beyond simply examining weights in a model, to higher order understandings of the computational flow within a model (gradient descent and itself data were mentioned in this thread)--I agree that simply examining weights/activations is not a sufficient paradigm for understanding neural computation--but it is a start.
In the same way that cells were understood to be indivisible, atomic units of biology hundreds of years ago--before the discovery of sub-cellular structures like organelles, proteins, and DNA--we currently understand features to be fundamental units of neural network representations that we are examining with tools like mechanistic interpretability.
This is not to say that the definition of what constitutes a "feature" is clear at all--in fact, its lack of consensus reflects the extremely immature (but exciting!) state of interpretability research today. I am not claiming that this is a pure bijection; in fact, one of the pivotal ways in which mechanistic interpretability and biology diverge is the fact that defining and understanding feature emergence will most definitely come outside of simple model decomposition into weight + activation spaces (for example, understanding dataset-dependent computation flow as you mentioned above). In contrast, most of biology's advancement has come from decomposing cellular complexity into smaller and smaller pieces.
I suspect this will not be the final story for interpretability, but it is mechanistic interpretability is an interesting first chapter.
If you have a certain kind of cell (e.g. penicillium), then you can add certain kinds of organic matter (e.g. food), and then this organic matter spontaneously converts into more of the original kind of cell (e.g. it gets moldy). This makes cells much more influential than other similarly-diminished entities.
In order to get something analogous to cells, it's not just enough to discover small structures, since there's lots of small structures that don't form spontaneously like this. It seems dubious whether current mechanistic interpretability is finding features like this.
I agree that it is dubious at the moment. I just think it's too early to tell and the field itself will undoubtedly grow in complexity over the coming years.
Your point about the spontaneity of cells forming stands, although I wasn't phrasing the analogy at the level of thermodynamics / physics.