Exploring the coherence of features explanations in the GemmaScope
post by Mattia Proietti (mattia-proietti) · 2025-02-01T21:28:33.690Z · LW · GW · 0 commentsContents
Summary Motivation, Background and Aim Features: What are they? Features, Concepts and Natural Abstractions Features and Neurons: Superposition, Polysemanticity, Monosemanticity Sparse Auto Encoders The GemmaScope Gemma Scope Explanations Experimental test: are animals represented by “animal-related features”? Hyponymy - Hyperonymy Data Methods Results and Analysis Discussion The cherry picking problem Limitations and Future Work Conclusions None No comments
AI Alignment course project (BlueDot Impact)
Summary
Sparse Autoencoders are becoming the to-use technique to get features out of superposition and interpret them in a sparse activation space. Current methods to interpret such features at scale rely heavily on automatic evaluations carried by Large Language Models. However, there is still a lack of understanding of the degree to which these explanations are coherent both with the input text responsible for their activation and the conceptual structure for which such inputs stand for and represent.
We devise a very naive and incipient heuristic method to explore the coherence of explanations provided in the GemmaScope with a set of controlled input sentences regarding animals, leveraging the simple conceptual structure derivable in terms of simple taxonomic relations triggered by specific animal words (e.g.. The dog is a mammal).
We show how, for the input we used and the location we analysed, the explanations of features at 5 different strength levels of activation are largely irrelevant and incoherent with respect to the target words and the conceptual structure they leverage[1].
Motivation, Background and Aim
Understanding AI system cognition is crucial to ensure the best possibilities of obtaining aligned systems. This understanding should not limit itself to safety related topics and concepts but should rather encompass the whole spectrum of cognitive abilities of AI models. Therefore, creating a solid foundation to understand models' cognition is one aim of alignment.
Mechanistic Interpretability (MI) is steadily taking the scene when it comes to interpreting AI models' behaviour while analysing the internal computations taking place to actually produce them. However, given its status as a discipline in its pre-paradigmatic phase, concepts and assumptions at its heart are still to be proven and empirically assessed.
A core claim of MI is that Neural Networks ultimately represent concepts as features.
In recent years, a variety of techniques have been developed to analyse models internals both in terms of representations (features) and algorithms (circuits). Lately, Sparse Autoencoders are becoming the standard tool used nowadays to interpret features encoded in models’ internal representations.
Why should we care about analysing features and their explanations? What level of granularity can we achieve when explaining features?
Given that we dispose of a vast set of Sparse AutoEncoders (SAE) activations and features explanations provided by tools like the GemmaScope, it may be worth asking ourselves if these explanations really do make sense at scale. Are they meaningful with respect to the input? To what extent is this true? If not, what do they point at? If yes, at what level of granularity are we able to link them to human conceptual representations as understood in cognitive sciences literature?
Features: What are they?
From the Mechanistic Interpretability perspective, features are the building blocks of Neural Networks representations. In the earliest days of MI, the object of research was to spot features in vision models, as visual traits roughly corresponding to real objects (e.g. car, dog face). When moving to textual models, interpreting features may not be so immediate. As concepts in text are more abstract and less ready to-be-seen than in images.
The theoretical debate around the precise definition of what a feature is inside a NN is still an open matter. One definitions which seems relevant and influential is the one offered in the Anthropic post Towards Monosemanticity which goes something like:
“Features are elements that a network would ideally assign to individual neurons if neuron count were not a limiting factor”
In this view, features roughly correspond, at least ideally, to concepts and we will use this perspective in the remainder of this work. However, drawing a clear link between NN features and human-understandable concepts is far from being an easy task and it may well be the case that models use completely different abstractions (i.e. alien abstraction) to come up with their representations.
Recently, features have become one of the most researched objects in the field of MI, also thanks to advancements due to the development of interpretability techniques based on Sparse Auto Encoders (see below). One major objective of the field is to understand as deeply as possible the internal structure of the representations the models come up with. To do so, it is necessary to get a sense of how features are related to the processed text, to the neurons of the net and to more abstract categories as what we may call concepts.
Features, Concepts and Natural Abstractions
Understanding how humans represent, organize and structure concepts is a long standing challenge addressed from a variety of scientific perspectives and research fields as diverse as cognitive psychology, anthropology and linguistics. Various competing theories have been proposed and empirical evidence in favor and against all of them has been brought to the table. Examples of such theories would include both classical views of categorization in terms of drawing boundaries which hold together members sharing a set of sufficient and necessary features, and more recent developments like the prototype theory of categorization (check this paper for an overview).
Understanding how humans deal with conceptual knowledge is surely crucial to understanding ourselves and our nature. However this is lately also becoming highly relevant to AI alignment. The ability to precisely identify and analyse concepts and the way they are formed in different cognitive systems would allow a more secure path to aligning human and machine cognition, ensuring a safer interaction between the two.
From an interpretability perspective, having features corresponding to, and organised as, human conceptual structure would be convenient.
Various recent theoretical stances are advocating for a convergent structural organization of different cognitive systems. For example, Natural Abstractions [? · GW] is a research agenda aspiring in proving the claims that different cognitive systems would come up to form similar abstraction on important pieces of information which are found out in the world/universe.
Similarly, a recent paper has treated the topic of Concept Alignment as a crucial prerequisite for a seamless and safe values alignment between humans and machines.
On the other hand, recent empirical works have claimed that human interpretable concepts can be found inside models’ internal representations. This is largely done through the usage of Sparse Autoencoders (see below) to get features out of their superposition state.
We see all these attempts, whether theoretical or empirical, as connected by the common line of understanding the relationship between human and machine conceptual knowledge as well as to produce systems as much aligned as possible with respect to that.
Given such assumptions, and with the proper differentiations, features seem to be promising candidates for considering them as concepts in machines.
But at the end of the day, can we consider features as concepts? Do they correspond to human concepts as we use to understand them? Are they organised in some sort of networking way, connecting concepts one to the other and disposing them along chains of specificity and relationships? To what level of granularity, if any, are features assimilable to human concepts?
This question, we believe, is still far from being filled with a conclusive answer. As we said, features are activations corresponding to certain inputs, and the way we interpret them is to assign a plausible explanation which can account for a range of input data activating the same feature.
So, a crucial question also becomes the following: if we consider features as human-interpretable, and we make them so by providing natural language explanations of them, to what extent these explanations are coherent with concepts as we may consider them in humans?
Features and Neurons: Superposition, Polysemanticity, Monosemanticity
What is the relationship between features and neurons in a neural network?
While features can be seen as the primitives making up internal models’ representations, neurons are the architectural building blocks of the networks, and the crucial unit of the computation taking place in them. A convenient scenario would be that each neuron neatly encodes a semantically meaningful feature, thus consistently activating when the related input is processed. In this scenario we would say that a neuron is monosemantic and that a straightforward one-to-one relationship occurs between neurons and features. Unfortunately, empirical observations of neuron activations suggest that they are rather polisemantic and fire in correspondence with different, often unrelated, pieces of input (e.g. dogs and car fronts). This status makes it difficult to directly analyse the representations and the features encoded in neurons, which result to be entangled and compressed.
The most common accepted explanation to account for neurons’ polisemanticity is the so-called superposition hypothesis. This hypothesis states that models dispose of a limited number of neurons to represent a far greater number of features. This would cause the models to compress features into the available set of neurons, which are consequently forced to encode more than one feature and to activate at different pieces of inputs.
Superposition and Polisemanticity may seem prima facie two sides of the same coin. Indeed, intuitively, and maybe naively, they may be initially regarded as being two perspectives on the same phenomenon, and thus two alternative ways to refer to the same thing: in a neural network some neurons encode more than one feature. However, several authors warn to not confuse the two and to keep the two phenomena apart.
To reconcile this different takes on the relationship between superposition and polisemanticity, we may attempt the following conceptual definition:
- Superposition is the phenomenon for which there are more features to encode than a network has neurons to encode them. Therefore, per this understanding, superposition occurs at the global level, that is, that of the network.
- Polisemanticity, is the phenomenon for which, in a network, there may be neurons which happen to encode more than one, often unrelated, feature. This would occur at the local level, that of single neurons.
Following such a line of reasoning, we may establish a causal link going from Superposition to Polisemanticity. That means that neurons may be polisemantic because of superposition having a place.
If this interpretation is correct, it seems straightforward that the flow of causality must be from superposition to polisemanticity. However, some people, while accepting this view, seem to understand the causality link in reverse, that is Polisemanticity causes Superposition, or superposition exists because of polisemanticity.
Superposition is treated as a hypothesis to explain polisemanticity. However, the fact that it is a Hypothesis, still leaves some room to the possibility that it is false. In that case, polisemanticity would be yielded by some other factors[2] (i.e. noise introduction during training).
As one of the core objectives of mechanistic interpretability is to understand and interpret features, this would imply to directly deal with polisemanticity and superposition. This can be done in at least two ways:
- Developing monosemantic models.
- Disentangling polisemantic representations into single meaningful ones, working at the post-hoc interpretational level.
The kind of research expressed in point 2 is a crucial focus of MI and it has been recently put forward with the usage of Sparse AutoEncoders
Sparse Auto Encoders
Sparse Auto Encoders (SAEs) are currently the go-to tool to disentangle models’ representations and render them monosemantic and interpretable.
They are a variation of the standard AutoEncoders which also introduce sparsity as a regularization factor, to get out interpretable features from models’ representations.
The approach to analyse features is usually bottom-up. Essentially, a model is run over a bunch of text to extract activations that are used to train a SAE. After that, the SAE activations have to be interpreted. The most obvious way to do it is manually describing them. So if a feature is activating/firing when input related to {car, trucks, vans} is being processed, we may infer that it is a feature referring to “wheeled vehicles”. However, caution should be taken in doing so, because interpretation can be fooled.
The GemmaScope
The GemmaScope[3] is a suite of Sparse AutoEncoders released by DeepMind. They are trained on the Gemma 2b and 9b models targeting three locations in each of their layer:
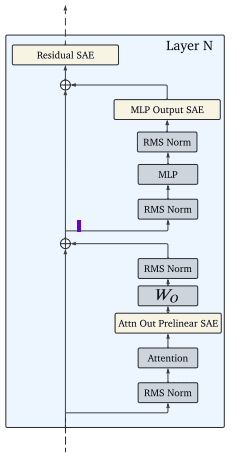
Figure 1. Layer-wise Sparse Autoencoders Locations in the GemmaScope
For each layer of the target Gemma model (2b or 9b) three SAE are trained, respectively on the Attention output, the MLP output and the post-mlp Residual stream activations. Two kinds of SAE have been trained, one having a number of features N=16k and the other having N=64K.
Here we are going to use the 16K version trained on the post-mlp residual stream of the 25th layer of the Gemma2b model.
Gemma Scope Explanations
The GemmaScope released by DeepMind comes with explanations pre-generated by Large Language Models, following the work of (LLMs can interpret neurons in LLMs).
The manual interpretation method to describe SAE features falls short when we need to scale it, as it is obviously impossible to manually check and describe each feature among the millions available. That is why it is becoming a common approach to use LLMs to automate this process, as presented in the OpenAI paper Language Models can Explain Neurons in Language Models. Basically, input activating a common feature is grouped and a LLM is prompted to assign a common description to the group. This opens up to scale and automate the process to millions of features. However, the reliability of the description can be questioned as it still is the work of a language model.
As anticipated, GemmaScope layers are linked to explanations which can be accessed and paired with the feature triggered by the text we are processing. DeepMind is making those explanations accessible through an API, but it has also released all the explanations in a structured json format. A typical example of the schema followed by the explanation is the following:
{
"modelId": "…",
"layer": "…",
"index": "…",
"description": "…",
"typeName": "…",
"explanationModelName": "…"
}
In this structure we can find useful information as the model-id, the layer, the index (i.e. the feature numerical identifier, the description (which is the actual explanation text) and the generative model used to explain the feature, per the method illustrated above.
At this point, a crucial question becomes the following: if we consider features as human-interpretable and we make them so by providing natural language explanations of them, to what extent these explanations are coherent with concepts as we may consider them in humans?
In the remainder, we will try to explore a tiny portion of the features provided by the GemmaScope along with their explanations, to check whether they are somehow coherent with the input data we provided.
Experimental test: are animals represented by “animal-related features”?
In this work we try to assess the coherence of the explanations given by an LLMs about Gemma-2b features. We choose to focus on the last layer (25), assuming that this may be the place in which the target representation is mature the most. When saying “coherence” we intend that the explanation provided is:
- Human interpretable: it corresponds roughly to a human interpretable concept, idea or generalization;
- Pertinent to the target input: it is somehow conceptually related to the target word. An actual pertinent explanation is not only a piece of comprehensible natural language text, but also one that does make sense with respect to the input.
We take point 1 as somehow granted, given the foundation we built upon, which is the work done in SAE interpretability and automatic interpretation of features.
On the other hand, point two is what remains to be evaluated and what we aim to evaluate, in an exploratory fashion, in this work. To do so, we leverage the conceptual structure carried by animal names to heuristically assess if the explanation of the features activating on target words are consistent with the word themselves. In particular, we use the sense-relation of hyponymy to draw our heuristics.
Hyponymy - Hyperonymy
The relation occurring between a generic concept and specific one, and vice versa, plays a crucial role in structuring our conceptual representations. This relation is called Hypernym when the perspective of the generic entity is adopted and Hyponymy when the perspective of the specific entity is adopted. Together, the double perspective of Hyperonymy-Hyponymy is considered crucial both in linguistics (semantics) and ontology[4].
In linguistics Hyperonymy it is a sense relation contributing to the structure of the lexicon and the organization of the lexical semantic knowledge of a subject.
In ontology and knowledge representation it is a fundamental taxonomical principle which links symmetrically a superordinate category to its descendant and vice versa.
To define the relation by means of natural language a Hyponym is usually said to be a “kind/type/instance of” an Hyperonym, expressing such relation with a predicate like “is a”. Hyperonymy, can be seen as a specificity chain linking particular to superordinate entities in a recursive fashion, till a final node is reached.
For example, we can have statement like the following to describe an Hyperonymy chain:
- The german shepherd is a dog
- The dog is a mammal
- A mammal is an animal
- …
- An animal is a living entity
This way, we could traverse the relation from a very specific instance to a really broad superordinate category and vice versa. Moreover, when thinking about entities along this specificity chain we know by default that at a point X of the chain, the entity can be characterized also by means of every point which is superordinate to X[5].
Here, we focus on animal species and their superordinate classes, like <dog-mammal>, <snake-reptile>, <robin-bird> etc.
In this perspective, a word (or concept) like DOG can be described at least along in three immediate ways, simply moving up along the Hyperonymy chain:
- A basic level of the specific word-concept DOG
- A more general level corresponding to a the class MAMMAL
An even more superordinate level corresponding to the general concept of ANIMAL[6]
Taking advantage of this intuitive conceptual structure we collected simple Hyponymic statements regarding animals and took advantage of that to explore the features they trigger in the GemmaScope along with the explanation they are coupled with.
Data
We use a list of specific animals[7] (hyponyms) and their respective superordinate category (hyperonym) to generate input sentences with a fixed structure of the kind:
- The [HYPONYM] is a [HYPERONYM] – i.e. The dog is a mammal
We restrict our analysis only to specific animal words encoded as a single token, for a total of 111 words and respective sentences.
As we said, this template representing a hyponymy relation allows us to account for at least three levels of conceptual structure along the hyperonymy chain: the specific ANIMAL (i.e. dog), its direct superordinate HYPERONYM1 (i.e. mammal) and the most inclusive categories HYPERONYM2 (i.e. animal). Additionally, we can account for the mention of the words referred to animals, which are sometimes used between quotes in the explanations.
Methods
We run the Gemma-2b model over our input sentences and extract the activations at the post-mlp residual stream 25th layer for each sentence using the TransformerLens library.
Next, we feed our activations to the related (25th layer post-mlp residual stream) pre-trained SAE provided by DeepMind, to get a sparse representation of the model activations. We used the SAELens library to do so.
For each target word (hyponym) in each sentence we store the topK (k=5) activating features and link them to the automatic explanation provided in the GemmaScope. We organize the explanations to the features in a matrix WxF, with W being the target words and F the topk features ordered from 1 to k.
We then try to analyse the feature explanations in terms of coherence with respect to the input text. Having 111 input data this results in 555 total feature explanations (top5 of each data point). We look at the distribution of the features’ explanations in the matrix to assess their coherence with respect to the target input.
For the assessment we adopt an heuristic approach based on regular expressions and pattern matching, considering 4 levels of possible conceptual abstractions plus one of non-coherence, derived directly from the conceptual structure of the input data as per illustrated. Specifically, we looked at:
- Explanations referring to the animal kingdom (high generality)
- Explanations referring to the hypernym of the target word (intermediate generality)
- Explanations referring to the specific concept of the target word (hyponym) (low generality)
- Explanations referring to a mention of the hyponym word, for example between quotes. (least generality, formal)
We then analyse the distribution of all the explanations given and its relation to the inputs under different perspectives.
Results and Analysis

Figure 1. Excerpt of the explanations collected and organized by target word (rows) and level of activation (columns).
Figure 1 shows an example of the collected feature explanations for each target word in the related context sentence. We applied the heuristics defined above to those explanations to obtain an assessment of their coherence following our criteria.
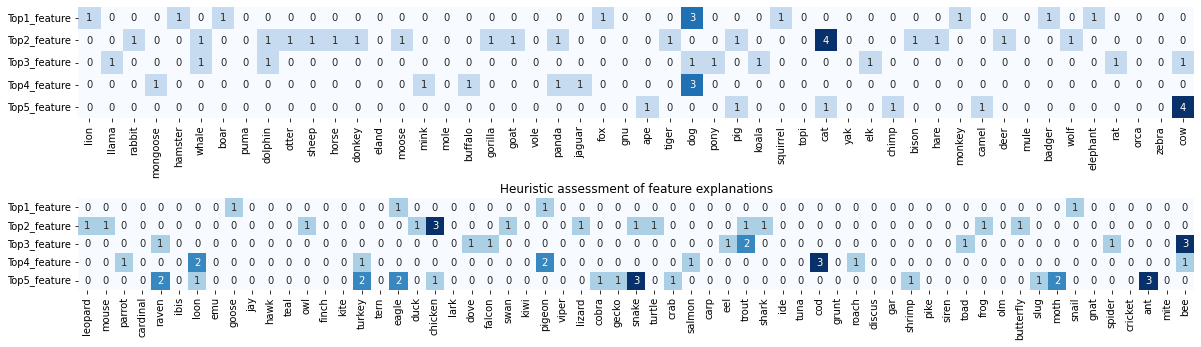
The heat map in Figure1 shows the evaluation of the explanations done with the heuristics defined above. The figure has to be read following the levels defined above. In particular, considering an example word like DOG the following mapping has to be applied:
- 0: no coherent explanation (like in expressions referred to statistics);
- 1: explanation referred to animals and alike (like in words and phrases referred to animals);
- 2: explanation referred to the hypernym of the target word (like in phrases referred to mammals);
- 3: explanation referred to the hyponym represented by the target word, the concept carried by the word itself (like in contexts referred to dogs)
- 4: explanation referred to the mention of the hyponym word (i.e. between quotes like in various usage of the word “cat”).
So for example, if we take the spot in the matrix WxF at the entry corresponding to TOP1_FEATURExLION, we have that the most activating feature for the word LION in the sentence The lion is a mammal has been assigned an explanation generally referred to animals and the animal kingdom, which is marked as 1 with our heuristics.
In general, a glimpse at the heatmap reveals that a really sparse matrix has been discovered with our heuristics, which suggest that most of the explanations are unrelated with the actual input.
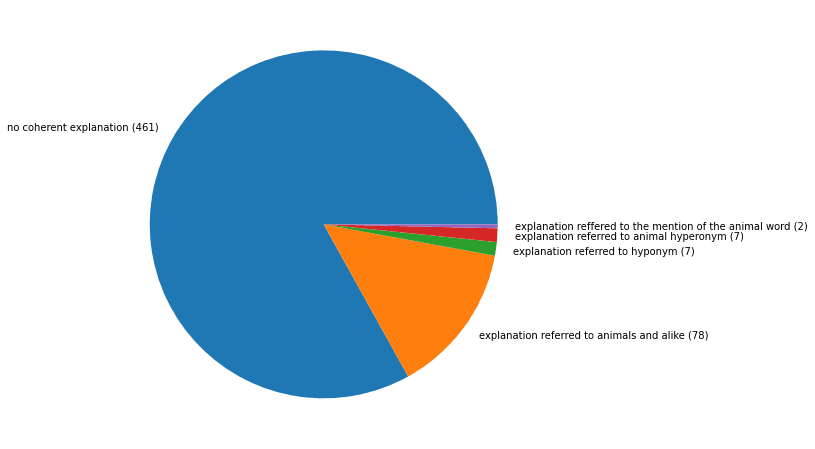
Figure 3. Proportions of the explanations values as found with the defined heuristics.
Indeed, the pie chart in Figure 3 summarises the take that the vast majority of explanations has been categorized as not coherent with the input text. It has to be noted that a variety of possible coherent explanations have been miscategorised due to the low level of sophistication of the heuristics applied. In fact, explanations containing synonyms or terms relevant to describe the input texts may have been discarded as non-coherent. Consider for example a sentence like The horse is a mammal. Our heuristics are able to capture explanations referring to horses, mammals, animals and mention of the word “horse” but would fail to keep description referring to horses that would nonetheless be coherent with the word and concept HORSE, like for example using terms like equine (i.e. terms related to the equine world). However, it is most likely that cases as this are only a minor source of noise[8]. Indeed, Figure 4
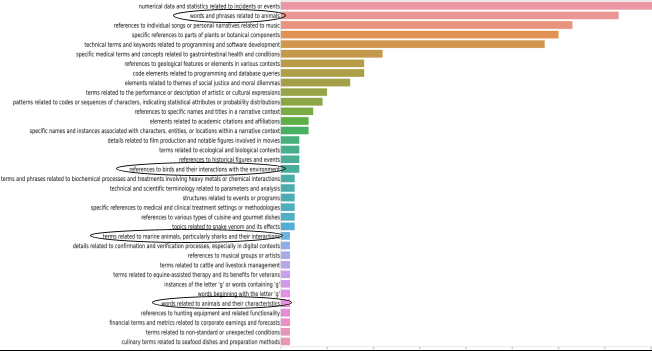
Figure 4. Distribution of feature explanations across all input words and all topk(k=5) activating features. Circles sign explanations that may be coherent with the target inputs. The figure discards the tail of “hapaxes” (explanations counted as 1). Coherent explanations are circled.
Many of the explanations found across levels of depth (the top5 most activating) are equal and Figure 4 shows their distribution. Circles are put around explanations we consider as allegedly coherent with respect to the input. It has to be noted that some explanations not circled can be considered coherent as well if we look at them from a different perspective. For example, the last bar at the bottom represents an explanation which is “culinary terms related to seafood dishes and preparation methods”. We can imagine that such an explanation has been extracted for a feature firing in correspondence of some kind of fish. This would let us consider it as coherent although imprecise. Indeed, a feature like that firing when a token like salmon is processed is no surprise. However, here our input are unequivocally referred to animals not their dish-version[9].
| Top activating Features | 0:no coherent explanation | 1: explanation referred to animals and alike | 2:explanation referred to the hypernym of the target word | 3: explanation referred to the concept carried by the target word | 4: explanation referred to the mention of the target word |
| Top1 | 98 | 12 | 0 | 1 | 0 |
| Top2 | 80 | 29 | 0 | 1 | 1 |
| Top3 | 94 | 15 | 1 | 1 | 0 |
| Top4 | 97 | 10 | 2 | 2 | 0 |
| Top5 | 92 | 12 | 4 | 2 | 1 |
Table 1. Distribution of explanation over most activating features
Lastly, if we group the explanation following our heuristics over the topk activating features, we have a better understanding of which “strength level of activation” is more related to the input data. A reasonable expectation would be that the most activating features would carry a coherent explanation, while less strong activation would be explained as something less relevant or even totally uncorrelated. However as we can see from Table 1, that is not the case. In fact, not only features are assigned incoherent explanations consistently across levels of activation, but the most coherent feature activating seems to be the top2 (29) instead of the top1 (12).
Discussion
In this project we tried to explore the coherence of feature explanations in the GemmaScope, taking into account the features of the SAE trained at the post-mlp residual stream of the 25th layer.
The majority of feature explanations we scanned across 5 levels of depth a.k.a. taking the 5 most activating features for all inputs, seems to be completely irrelevant and not coherent with the word activating the corresponding feature.
Part of possible motivations behind this come from the methods employed, which are pretty shallow and may be refined.
Other possible causes are related to the dimension of the model, the dimension of the SAE used and the location of SAE.
Indeed, the Gemma2b model may be too small to abstract concepts in a highly granular way and may be unable to generalise over input, coming up with messy representations which are hard to disentangle.
At the same time, the SAE used may not be big enough and sparse enough to properly get features out of their superposition state. As a result, we may still have a high degree of polisemanticity, due to which animal-related words may trigger the feature explained as numerical data and statistics related to incidents or events, which is supposedly related to other types of inputs and abstractions.
Moreover, our analysis is narrow and restricted to features extracted from a specific location inside a specific Transformer block in the model, the post-mlp residual stream of the 25th layer. This decision lays on the assumption that model representations at this stage should be the most mature, and hence more interpretable through projecting them into a sparser space with a SAE. However, there is no need to believe that the best representation of the features we are looking for reside in the last layer, so that other locations may yield different results.
In general, this project is exploratory in nature, but it shows how although SAEs can find interpretable features and we can use language models to come up with explanations for them, they may still be far from what we expect to be activated by a given input and this territory should be explored. Actually, a lot of the examples provided in interfaces like Neuronpedia seem a bit cherry picked and may influence our way of thinking about how really clearly we can extract features and their explanations with SAEs.
In the end, of course, we should recall that there is no intrinsic reason to expect alignment between models’ features and human concepts, and explanations may not be all perfectly sharp and clear to a human eye. However, if that is the case we should know and it is worth investigating whether the actual explanation we are able to generate about features are really coherent with the input we fed.
Ok we have a lot of interpretable feature explanations we can use to interpret features activating on specific inputs. But how can we know, on a greater scale, if the explanations are coherent? That is to say, that the feature activating for a given word is not explained as something totally irrelevant wrt our input?
We can either check manually each feature explanation or elaborate a method to automatically check for a large set of inputs, if the explanations of the feature activating are somewhat coherent.
The cherry picking problem
Mechanistic interpretability is surely one of the most promising fields in understanding how AI systems build their internal representations and how they come up with strategies to produce their output. This may be appealing for the safety field, as knowing what is going on inside the black boxes in an algorithmic way may lead to envisage better alignment and safety tools and techniques. However, that is not so straightforward and several problems remain open with respect to the general and long-term validity of the field[10]. One major concern regards the wide-spread usage of cherry-picked convincing examples to support results and thesis. This is partially due to the qualitative nature of the majority of MI techniques, but also to the difficulty of finding analysis methods which scale reliably, generalise beyond a bunch of selected examples and can be automatically evaluated.
Finding a way to assess the coherence of feature explanations at scale, as we attempted in this work, may sound as adding another layer of complexity to the whole matter. While that may be true, it is also true that we cannot rely solely on serendipitous examples, cherry picked to showcase results and we need to understand better and broader the extent to which these techniques are to be considered reliable.
Indeed, a lot of claims have been made recently about looking inside the modes’ brain, having understood model cognition, models thoughts or how AI thinks. We believe that, notwithstanding the brilliant advancements in that direction, such claims are at risk of being imprecise at best and misleading at worst, indulging in marketing showcasing rather than scientific assessment.
Limitations and Future Work
Given its exploratory nature, this work has a number of limitations.
The first one is that we use a very simple heuristic method to identify coherent explanations, which may not be sufficiently elaborated to capture all the possible coherent explanations. A future development in that direction would be to refine the method and be able to capture more nuanced explanations coherent with the input data. A possible way in that direction could be to leverage knowledge bases as WordNet or ConceptNet to spot terms contained in the explanation which are relevant with respect to the target word/concept but not captured by the simplest heuristic.
The second major limitation resides in the narrow set of data used. This may be expanded in future developments leveraging other conceptual relations. However, it may be noted that it is not easy to find a set of data which allows us to make assumptions beforehand on the conceptual structure of the inputs, like we did with hyponymic expressions.
Lastly, we focused only on a single SAE location, namely that trained on the activations of the post-mlp residual stream of the 25th layer of the Gemma2b model. Working with other locations should give a more complete picture.
We took into consideration features activating for single target words in context. Would it be worth doing the analysis at the sentence level? Moreover, would it be worth it to check representations for the same target words within different contexts?
SAEs are a really promising tool researchers are using to inspect the inner semantics of Large Language Models features. However, the coherence of the features explanations automatically provided by LLMs themselves, is still to be explored. Indeed, having at our disposal a mine of feature explanations provided by tools like the GemmaScope we can systematically investigate how those explanations relate to human expectations about conceptual structures and abstractions, which we think remain still a largely unexplored matter. Wouldn’t it be good to have a tool to systematically analyse feature explanations other than relying on serendipitous discoveries inputting random stuff?
Conclusions
We explored the coherence of the explanations provided in the GemmaScope features with respect to a sample of the input sentences. We leveraged the simple conceptual structure carried by target words in the sentences to heuristically assess the relevance of an explanation with respect to the word.
We found that at the post-mlp location of the 25th layer (a.k.a. last), the features activating when processing our inputs at 5 different levels of strength of activation are largely incoherent and irrelevant with respect to our inputs.
We plan to refine our heuristic and scale the method to analyse as many SAE’s explanations as possible. This was thought as the groundwork for more complete analysis to be done in the future to gain a better understanding of the actual value of automatic explanations of SAEs features.
- ^
Code available here.
- ^
See for example the hypothesis cited in this paper
- ^
- ^
As they are two perspectives on the same sense relation, we will refer to it switching between Hyperonymy and Hyponymy freely when talking about the relation in general.
- ^
The reverse is not true though, as while a dog is necessary a mammal, a mammal is obviously not necessarily a dog.
- ^
As we said this could be pushed further till the very ultimate node, but that is not necessary in the present case.
- ^
We adapted data from this paper.
- ^
A possible way to overcome this kind of problems and reduce them to the minimum would be to elaborate a more sophisticated algorithm to heuristically spot coherent explanations, for example incorporating resources like WordeNet to expand the set of the words to be considered explanatory and relevant to our target.
- ^
This kind of reminds me of those funny AI-generated picture of salmon-dishes in a river, obtained with prompts asking things like “Generate a salmon swimming in a river”.
- ^
This is discussed though, and several people are skeptical about that. See for example, this posts series by Stephen Casper [? · GW] or this take by Charbel Raphael Segerie [AF · GW]
0 comments
Comments sorted by top scores.