Maxime Riché's Shortform
post by Maxime Riché (maxime-riche) · 2024-06-10T10:16:00.187Z · LW · GW · 15 commentsContents
15 comments
15 comments
Comments sorted by top scores.
comment by Maxime Riché (maxime-riche) · 2025-01-28T20:48:38.734Z · LW(p) · GW(p)
Simple reasons for DeepSeek V3 and R1 efficiencies:
- 32B active parameters instead of likely ~220B for GPT4 => 6.8x lower training and inference cost
- 8bits training instead of 16bits => 4x lower training cost
- No margin on commercial inference => ?x maybe 3x
- Multi-token training => ~2x training efficiency, ~3x inference efficiency, and lower inference latency by baking in "predictive decoding', possibly 4x fewer training steps for the same number of tokens if predicting tokens only once
- And additional cost savings from memory optimization, especially for long contexts ( Multi Head Latent Attention) => ?x
Nothing is very surprising (maybe the last bullet point for me because I know less about it).
The surprising part is why big AI labs were not pursuing these obvious strategies.
Int8 was obvious, the multi-token prediction was obvious, and more and smaller experts in MoE were obvious. All three have already been demonstrated and published in the literature. May be bottlenecked by communication, GPU usage, and memory for the largest models.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2025-01-29T01:31:48.827Z · LW(p) · GW(p)
32B active parameters instead of likely ~220B for GPT4
It's 37B instead of maybe 280B (non-expert parameters also count), but in any case the question is how this manages to maintain quality. If this wasn't an issue, why not 8B active parameters, or 1M active parameters?
32B active parameters instead of likely ~220B for GPT4 => 6.8x lower training ... cost
Doesn't follow, training cost scales with the number of training tokens. In this case DeepSeek-V3 uses maybe 1.5x-2x more tokens than original GPT-4.
The training costs are maybe 5e24 FLOPs and 2e25 FLOPs, differ by 4x. DeepSeek-V3 is better than original GPT-4 though, you need to compare with GPT-4o, which almost certainly uses more compute in training than original GPT-4 (maybe 4x more, so maybe 16x more than DeepSeek-V3).
8bits training instead of 16bits => 4x lower training cost
FLOP/s for FP8 are almost always 2x the FLOP/s for BF16, not 4x.
Multi-token training => ~2x training efficiency
You still train on every token. There is an additional "layer" in model parameters that predicts the token-after-next (Figure 3 in the paper), so there's a bit of overhead in training (not much, with 61 total layers). The results are better, but not that much better (Table 4).
Replies from: maxime-riche↑ comment by Maxime Riché (maxime-riche) · 2025-01-29T08:36:37.147Z · LW(p) · GW(p)
Thanks for your corrections, that's welcome
> 32B active parameters instead of likely ~220B for GPT4 => 6.8x lower training ... cost
Doesn't follow, training cost scales with the number of training tokens. In this case DeepSeek-V3 uses maybe 1.5x-2x more tokens than original GPT-4.
Each of the points above is a relative comparison with more or less everything else kept constant. In this bullet point, by "training cost", I mostly had in mind "training cost per token":
32B active parameters instead of likely ~
220280B for GPT4 =>6.88.7x lower training cost per token.
If this wasn't an issue, why not 8B active parameters, or 1M active parameters?
From what I remember, the training-compute optimal number of experts was like 64, given implementations a few years old (I don't remember how many activated at the same time in this old paper). Given newer implementations and aiming for inference-compute optimality, it seems logical that more than 64 experts could be great.
You still train on every token.
Right, that's why I wrote: "possibly 4x fewer training steps for the same number of tokens if predicting tokens only once" (assuming predicting 4 tokens at a time), but that's not demonstrated nor published (given my limited knowledge on this).
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2025-01-29T14:51:59.516Z · LW(p) · GW(p)
From what I remember, the training-compute optimal number of experts was like 64
I think it only gets better with more experts if you keep the number of active parameters unchanged. Is there some setting where it gets worse after a while? There certainly are engineering difficulties and diminishing returns.
Also, the number of activated experts can vary (there are 8 activated routed experts in DeepSeek-V3 out of the total of 256), so "number of experts" doesn't really capture the ratio of total to activated, probably not a good anchor by itself.
Given newer implementations and aiming for inference-compute optimality, it seems logical that more than 64 experts could be great.
This still doesn't help with the question of why 37B active parameters is sufficient. Even with 100500 experts you can't expect 1B active parameters to be sufficient to maintain GPT-4 quality. The rumor for original GPT-4 is that it has 2 activated experts out of 16 in total, so the ratio is 1:8, while for DeepSeek-V3 it's 1:32.
that's why I wrote: "possibly 4x fewer training steps for the same number of tokens if predicting tokens only once" (assuming predicting 4 tokens at a time), but that's not demonstrated nor published (given my limited knowledge on this)
Not sure how to parse this, my point is that the number of training steps remains the same, training efficiency doesn't significantly increase, there's even slight overhead from adding the predict-the-token-after-next blocks of parameters. This is described in Section 2.2 of the paper. You get better speculative decoding at inference time (and also better quality of output), but training time is the same, not with 2x fewer or 4x fewer steps.
32B active parameters instead of likely ~
220280B for GPT4 =>6.88.7x lower training cost per token.
It's 37B active parameters, not 32B.
comment by Maxime Riché (maxime-riche) · 2024-06-26T08:10:13.801Z · LW(p) · GW(p)
Could Anthropic face an OpenAI drama 2.0?
I forecast that Anthropic would likely face a similar backlash from its employees than OpenAI in case Anthropic’s executives were to knowingly decrease the value of Anthropic shares significantly. E.g. if they were to switch from “scaling as fast as possible” to “safety-constrained scaling”. In that case, I would not find it surprising that a significant fraction of Anthropic’s staff threatened to leave or leave the company.
The reasoning is simple, given that we don’t observe significant differences in the wages of OpenAI and Anthropic employees and assuming that they are overall of the same distribution of skill and skill level. Then it seems that Anthropic is not able to use the argument of its AI safety focus as a bargaining argument to reduce the wages significantly. If true this would mean that safety is of relatively little importance to most of Anthropic’s employees.
Counter argument: Anthropic is hiring from a much more restricted pool of candidates. From only the safety-concerned candidates. In that case, Anthropic would have to pay a premium to hire these people. And it happens that this premium is roughly equivalent to the discount that these employees are willing to give to Anthropic because of its safety focus.
Replies from: ChristianKl↑ comment by ChristianKl · 2024-06-26T08:46:51.681Z · LW(p) · GW(p)
If you hire for a feature that helps people to be motivated for the job and that restricts your pool of candidates, I don't think you need to pay a premium to hire those people.
To be hired by SpaceX you need to be passionate about SpaceX's mission. In the real world that plays out in a way that those employees put up with bad working conditions because they believe in the mission.
Replies from: maxime-riche↑ comment by Maxime Riché (maxime-riche) · 2024-07-05T15:48:56.514Z · LW(p) · GW(p)
Right 👍
So the effects are:
Effects that should increase Anthropic's salaries relative to OpenAI: A) - The pool of AI safety focused candidates is smaller B) - AI safety focused candidates are more motivated
Effects that should decrease Anthropic's salaries relative to OpenAI: C) - AI safety focused candidates should be willing to accept significantly lower wages
New notes: (B) and (C) could cancel each other but that would be a bit suspicious. Still a partial cancellation would make a difference between OpenAI and Anthropic lower and harder to properly observe. (B) May have a small effect, given that hires are already world level talents, it would be weird that they could significantly increase even more their performance by simply being more motivated. I.e. non AI safety focused candidates are also very motivated. The difference in motivation between both groups is possibly not large.
Replies from: ChristianKl↑ comment by ChristianKl · 2024-07-05T21:26:07.082Z · LW(p) · GW(p)
There's a difference between motivated to goodhard performance metrics and sending loyalty signals and being motivated to do what's good for the companies mission.
If we take OpenAI, there were likely people smart enough to know that stealing Scarlett Johansson's voice was going to be bad for OpenAI. Sam Altman however wanted to do it in his vanity and opposing the project would have sent bad loyalty signals.
There's a lot that software engineers do where the effects aren't easy to measure, so being motivated to help the mission and not only reach performance metrics can be important.
comment by Maxime Riché (maxime-riche) · 2024-07-05T13:47:24.184Z · LW(p) · GW(p)
Rambling about Forecasting the order in which functions are learned by NN
Idea:
Using function complexity and their "compoundness" (edit 11 september: these functions seem to be called "composite functions"), we may be able to forecast the order in which algorithms in NN are learned. And we may be able to forecast the temporal ordering of when some functions or behaviours will start generalising strongly.
Rambling:
What happens when training neural networks is similar to the selection of genes in genomes or any reinforcement optimization processes. Compound functions are much harder to learn. You need each part to be independently useful initially to provide enough signal for the compound system to be reinforced.
That means that learning any non-hardcoded algorithms with many variables and multiplicative steps is very difficult.
An important factor in this is the frequency at which an algorithm is useful and to which extent. An algorithm that can be very used in most situations will get much more training signals. The relative strength of the reward signal you get is important because of the noise in the training and because of catastrophic forgetting.
LLMs are not learning complex algorithms yet. They are learning something like a world model because this is used for most tasks and it can be built by first building each part separately and then assembling them.
Regarding building algorithms to exploit this world model, it can be learned later if the algorithm is composed first of very simple algorithms that can be later assembled. An extra difficulty for LLMs to learn algorithms is in situations where heuristics already work very well. In that case, you need to add significant regularisation pushing for simpler circuits. Then you may observe grokking learning and a transition from heuristics to algorithms.
An issue with this reasoning is that heuristics are 1-step algorithms (0 compoundness).
Effects:
- Frequency of reward
- Strength of the additional reward (above the "heuristic baseline")
- Compoundness
Forecasting game:
(WIP, mostly a failure at that point)
Early to generalize well:
World models can be built from simple parts, and are most of the time valuable.
Generalizable algorithm for simple and frequent tasks on which heuristics fail dramatically: ??? (maybe) generating random numbers, ??
Medium to generalize well:
Generalizable deceptive alignment algorithms: They require several components to work. But they are useful for many tasks. The strength of the additional reward is not especially high or low.
Generalizable instrumental convergence algorithms: Same as deceptive alignment.
Generalizable short horizon algorithms: They, by definition, require fewer sequential steps, as such they should be less "compounded" functions and appear sooner.
Late:
Generalizable long horizon algorithms: They, by definition, require more sequential steps, as such they should be more "compounded" functions and appear later.
The latest:
Generalizable long horizon narrow capabilities: They are not frequently reinforced.
(Time spent on this: 45min)
July 6th update:
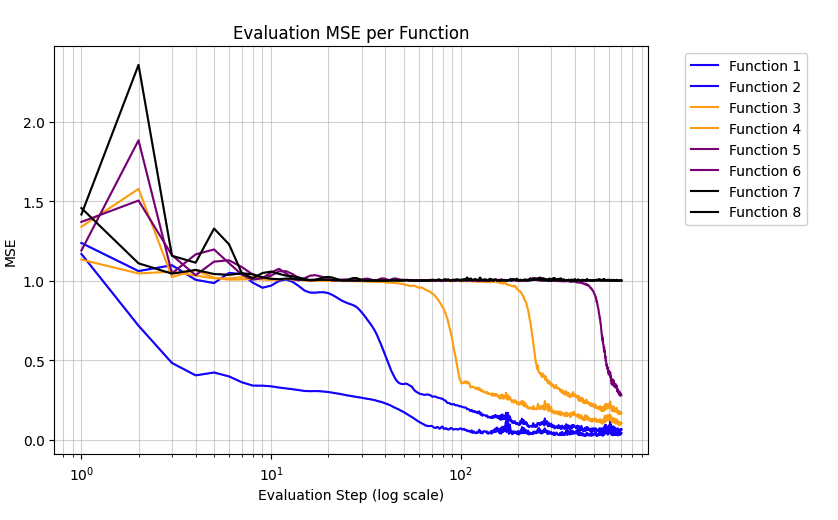
Here is a quick experiment trying to observe the effect of increasing "compoundness" on the ordering of grokking learning different functions: https://colab.research.google.com/drive/1B85mfCkqyQZSl1JGbLr0r5BrAS8LYUr5?usp=sharing
Quick results:
The task is predicting the sign of the product of 1 (function 1) to 8 (function 8) standard normal random variables.
Increasing the compoundness by 2 seems to delay the grokking learning by something like 1 OOM.
↑ comment by Violet Hour · 2024-07-05T14:51:28.011Z · LW(p) · GW(p)
Hm, what do you mean by "generalizable deceptive alignment algorithms"? I understand 'algorithms for deceptive alignment' to be algorithms that enable the model to perform well during training because alignment-faking behavior is instrumentally useful for some long-term goal. But that seems to suggest that deceptive alignment would only emerge – and would only be "useful for many tasks" – after the model learns generalizable long-horizon algorithms.
Replies from: maxime-riche↑ comment by Maxime Riché (maxime-riche) · 2024-07-05T15:39:44.236Z · LW(p) · GW(p)
These forecasts are about the order under which functionalities see a jump in their generalization (how far OOD they work well).
By "Generalisable xxx" I meant the form of the functionality xxx that generalize far.
comment by Maxime Riché (maxime-riche) · 2024-07-04T09:02:15.403Z · LW(p) · GW(p)
Will we get to GPT-5 and GPT-6 soon?
This is a straightforward "follow the trend" model which tries to forecast when GPT-N-equivalent models will be first trained and deployed up to 2030.
Baseline forecast:
GPT-4.7 | GPT-5.3 | GPT-5.8 | GPT-6.3 | |
| Start of training | 2024.4 | 2025.5 | 2026.5 | 2028.5 |
| Deployment | 2025.2 | 2026.8 | 2028 | 2030.2 |
Bullish forecast:
GPT-5 | GPT-5.5 | GPT-6 | GPT-6.5 | |
| Start of training | 2024.4 | 2025 | 2026.5 | 2028.5 |
| Deployment | 2025.2 | 2026.5 | 2028 | 2030 |
FWIW, it predicts roughly similar growth in model size, energy cost and GPU count than described in https://situational-awareness.ai/ while being created the week before this was released.
I spent like 10 hours on this, so I expect to find lingering mistakes in the model.
comment by Maxime Riché (maxime-riche) · 2024-06-10T10:16:00.311Z · LW(p) · GW(p)
What is the difference between Evaluation, Characterization, Experiments, and Observations?
The words evaluations, experiments, characterizations, and observations are somewhat confused or confusingly used in discussions about model evaluations (e.g., ref [AF · GW], ref [LW(p) · GW(p)]).
Let’s define them more clearly:
- Observations provide information about an object (including systems).
- This information can be informative (allowing the observer to update its beliefs significantly), or not.
- Characterizations describe distinctive features of an object (including properties).
- Characterizations are observations that are actively designed and controlled to study an object.
- Evaluations evaluate the quality of distinctive features based on normative criteria.
- Evaluations are composed of both characterizations and normative criteria.
- Evaluations are normative, they inform about what is good or bad, desirable or undesirable.
- Normative criteria (or “evaluation criterion”) are the element bringing the normativity. They are most of the time directional or simple thresholds.
- Evaluations include both characterizations of the object studied and characterization of the characterization technique used (e.g., accuracy of measurement).
- Scientific experiments test hypotheses through controlled manipulation of variables.
- Scientific experiments are composed of: characterizations, and hypothesis
In summary:
- Observations
- Characterizations = Designed and controlled Observations
- Evaluations = Characterization of object + Characterization of the characterization method + Normative criteria
- Scientific experiments = Characterizations + Hypothesis
Examples:
- An observation is an event in which the observer receives information about the AI system.
- E.g., you read a completion returned by a model.
- A characterization is a tool or process used to describe an AI system.
- E.g., you can characterize the latency of an AI system by measuring it. You can characterize how often a model is correct (without specifying that correctness is the goal).
- An AI system evaluation will associate characterizations and normative criteria to conclude about the quality of the AI system on the dimensions evaluated.
- E.g., alignment evaluations use characterizations of models and the normative criteria of the alignment with X (e.g., humanity) to conclude on how well the model is aligned with X.
- An experiment will associate hypotheses, interventions, and finally characterizations to conclude on the veracity of the hypotheses about the AI system.
- E.g., you can change the training algorithm and measure the impact using characterization techniques.
Clash of usage and definition:
These definitions slightly clash with the usage of the term evals or evaluations in the AI community. Regularly the normative criteria associated with an evaluation are not explicitly defined, and the focus is solely put on the characterizations included in the evaluation.
(Produced as part of the AI Safety Camp, within the project: Evaluating alignment evaluations)
comment by Maxime Riché (maxime-riche) · 2025-03-07T13:37:21.382Z · LW(p) · GW(p)
Truth-seeking AIs by default? One hope for alignment by default is that AI developers may have to train their models to be truth-seeking to be able to make them contribute to scientific and technological progress, including RSI. Truth-seeking about the world model may generalize to truth-seeking for moral values, as observed in humans, and that's an important meta-value guiding moral values towards alignment.
In humans, truth-seeking is maybe pushed back from being a revealed preference at work to being a stated preference outside of work, because of status competitions and fighting for resources. For early artificial researchers, they may not have the same selection pressures. Their moral values may focus on working alone (truth-seeking trend), not on replicating via competing for resources. Artifical researchers won't be selected because they are able to acquire resources, they will be selected by AI developers because they are the best at achieving technical progress, which includes being truth-seeking.
comment by Maxime Riché (maxime-riche) · 2024-10-21T10:59:11.403Z · LW(p) · GW(p)
Speculations on (near) Out-Of-Distribution (OOD) regimes
- [Absence of extractable information] The model can no longer extract any relevant information. Models may behave more and more similarly to their baseline behavior in this regime. Models may learn the heuristic to ignore uninformative data, and this heuristic may generalize pretty far. Publication supporting this regime: Deep Neural Networks Tend To Extrapolate Predictably
- [Extreme information] The model can still extract information, but the features extracted are becoming extreme in value ("extreme" = range never seen during training). Models may keep behaving in the same way as "at the In-Distrubution (ID) border". Models may learn the heuristic that for extreme inputs, you should keep behaving as if you were still in the embedding same direction but still ID.
- [Inner OOD] The model observes a mix of features-values that it never saw during training, but none of these features-values are by themselves OOD. For example, the input is located between two populated planes. Models may learn the heuristic to use a (mixed) policy composed of closest ID behaviors.
- [Far/Disrupting OOD]: This happens in one of the other three regimes when the inputs break the OOD heuristics learned by the model. These can be found by adversarial search or by moving extremely OOD.
- [Fine-Tuning (FT) or Jailbreaking OOD] The inference distribution is OOD of the distribution during the FT. The model then stops using heuristics defined during the FT and starts using those learned during pretraining (the inference is still ID with respect to the pretraining distribution).