Towards a Bayesian model for Empirical Science
post by Yair Halberstadt (yair-halberstadt) · 2021-10-07T05:38:25.848Z · LW · GW · 7 commentsContents
The Current Model Of Doing Science The problem with the current model of doing science Doing Better Split Analysis and Research Format of publishing experimental results Conclusion None 7 comments
The aim of this post is to explore if we can create a model for doing Empirical Science that better incorporates Bayesian ideas.
The Current Model Of Doing Science
Imagine you are a Good Scientist. You know about p-hacking and the replication crisis. You want to follow all best practices. You want to be doing Good Science!
You're designing an experiment to detect if there's a correlation between two variables. For instance height and number of cigarettes smoked a day. You want to follow all best practices, so you write a procedure that looks something like this (taken from https://slatestarcodex.com/2014/04/28/the-control-group-is-out-of-control/):
- You find a large cohort of randomly chosen people. You use the SuperRandomizerV3 to teleport 10000 completely randomly chosen people into your laboratory, and refuse to let them out till they answer your questionnaire about their smoking habits, and allow you to measure their height.
- You consider a p value of 0.001 as significant.
- You calculate the correlation between their height and the number of cigarettes they smoke a day. By pure chance it's almost certain not to be 0.
- You calculate the the chance they would get this correlation assuming the true correlation was 0 (the p value).
- If p > 0.001 you conclude the experiment is a dud. No evidence of correlation. Better luck next time.
- If p < 0.001 you're golden! It's now been scientifically proven that height correlates with smoking habits.
- You preregister the experiment in detail, including the exact questions you ask, the p value you will consider significant, the calculations you will do, whether the test is two tailed or one tailed etc.
You then follow this procedure exactly, publish your results in a journal no matter what they show, and demand replication.
And that's pretty much the procedure for how to do good science under the current empirical model.
The great thing about this procedure is it doesn't require much subjective decision making. So long as your honest about it, and go carefully, you don't actually have to be very clever to do this - anyone who's capable of following steps and doing some simple statistics can carry out this procedure. It's reproducible, and the procedure can be easily checked for design flaws simply by reading it. This is important given how many people work in science - you want a technique that doesn't require brilliant practitioners, and is as externally verifiable as possible.
The problem with the current model of doing science
I think, as ever, XKCD tends to sum it up pretty well:

- The procedure has no formal model for taking into account how likely the thing we're testing for is in the first place (priors).
- Significance thresholds seem a bit arbitrary. So 0.0009 is significant, but 0.0011 isn't. Why?
- There's no good model for combining multiple experiments on the same thing.
On the one hand, if we'd done this experiment 1000 times and got p = 0.0011 each time, we would be dead certain this correlation was real. OTOH if we did the experiment 1000 times, and got p = 0.5 most of the time but 0.001 once we'd be pretty sure that the positive result was just a fluke. There are formal models for how to account for this if the experiments are exact duplicates, or completely unrelated, but not for experiments which are testing a similar but slightly different thing. For example see the second problem in this ACT post: https://astralcodexten.substack.com/p/two-unexpected-multiple-hypothesis

It doesn't tell me what the correlation is. It only tells me there is a correlation. I can calculate the most likely correlation given the data, but that's very unlikely to be the true correlation.
5. It looks at the chance that we see the data we see given the null hypothesis, but doesn't check how likely it is given the alternative hypothesis - only that it's more likely. For example I want to test the hypothesis that cranberries make people run faster. I pick a person at random, feed him some cranberries, and he beats the world 100m sprint record. The chance of this happening randomly are close to 0 - only 1 in 8 billion people are Usain Bolt, and he doesn't beat the world record very often either. So it looks like we've proved with absolute certainty that cranberries make you run faster.
However even assuming cranberries made people run faster, the chance that a random person given cranberries would beat the world record is tiny. Maybe, under H1, the top 10 sprinters in the world might have a decent chance at breaking the speed record - let's say 1/10. And under H0, they would have their standard chance of breaking the speed record - 1/1000. So my test only gives an effective p value of 1/100, not the naive value of 1/10,000 billion.
Doing Better
Split Analysis and Research
Currently papers tend to have a conclusion. This might seem sensible, but it actually leads to problems.
Firstly, this encourages scientists to make the conclusion exciting. This creates all the incentives for p-hacking, and also makes it hard to publish negative results.
It also makes it easier for scientists to push an agenda, by representing their findings in a particular light, which may not always be the impression you would get if you actually read their experimental results. Similarly it's easy to find papers with the conclusion you want, instead of looking at meta-analyses which survey the whole field.
Finally in order to come to a conclusion via Bayesian updating, you first need a prior. The problem is that there's no practical objective way to come up with a prior (Solomonoff induction is not practical). This means that you can come to any conclusion you like based on the available evidence by choosing a suitable prior.
So I would suggest separating out reporting research, and analysis of the research.
The aim of the first is simply to present an experiment and it's results in a format which makes it easy to do Bayesian updating (more on that later). It should describe the experimental procedure, and the results, and may discuss possible con-founders, but should avoid any discussion of what the results mean.
Since all research papers are thus equally unexciting, (and equally important to Bayesian updating in the meta-analyses where the exciting stuff happens) there's much less incentive not to publish all experimental results, including those which find very little. in fact papers which find very little update the prior just as much as those which find a lot.
Meanwhile meta-analyses will try to come up with priors for particular questions of interest, and then sort through all the relevant papers on the topic, and apply the Bayesian update from these papers to the prior, possibly weighted on the quality of the paper/experiment.
Format of publishing experimental results
Trawling through the raw data of every single experiment would be far too much work for anyone doing a meta-analysis. If only there was some compact way of representing a Bayesian update, without knowing what the prior is first!
Fortunately there is!
First let's review Bayes formula:
The probability of A given B occurred is equivalent to the probability of B occurring given A is true, multiplied by the prior probability of A, divided by the prior probability of B.
In other words to calculate , we multiply the prior by . So it seems we can just calculate up front, report that in our paper and be done - all the meta-analaticians need to do now is a bit of multiplication!
Unfortunately that doesn't work - isn't a constant. If is more likely given , then as increases, does too, with . So each time we update based on the results of 1 paper, we need to recalculate the multipliers for all the other papers before we can apply them to our adjusted priors. This is what stops us ever updating probabilities so much they become greater than 1.
However we can still fix this:
First we calculate and , and report these as and (short for Result1 and Result2).
Then:
.
So
This might not look much better but the great thing about it is it's a mechanical formula. A paper can publish R1 and R2 - what is the chance we would get the result if hypothesis X was true, vs if hypothesis X was not true. Then a meta analysis can take their previous estimate for how likely X is, plug these 3 numbers into a spreadsheet, and get a new updated likelihood for X, which they can plug into the results from the next paper. All without ever having to look at a the raw data from the paper.
In the real world things are a bit more complicated. It's very rare that hypotheses are discrete - usually I'm trying to find the value of some parameter X, where X can be any number in a range.
For example, in the experiment described at the beginning of this post (a correlation between height and number of cigarettes smoked a day), it's not a binary question (is there a correlation or not), but more a question of what that correlation is. The correlation coefficient can be any number between -1 and 1, but is usually close to 0.
Let's draw a graph. My prior for the correlation between these two variables might be something like this:
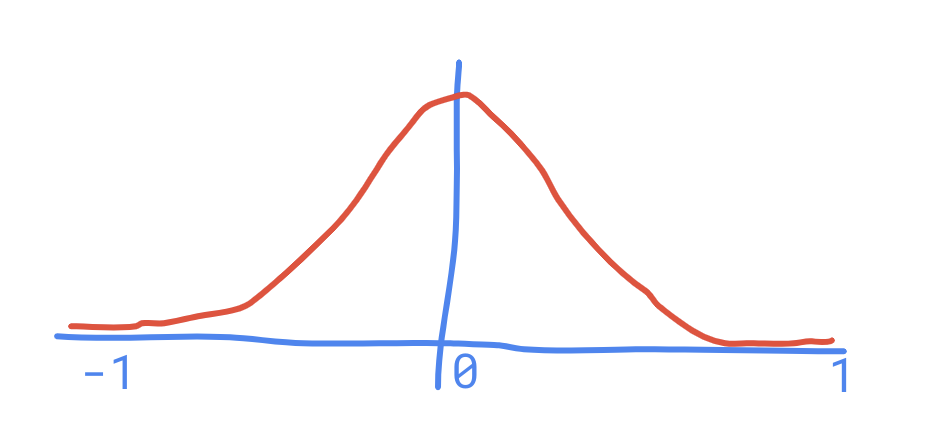
Here the height on the graph represents a probability density, rather than a probability.
My data might look like this:
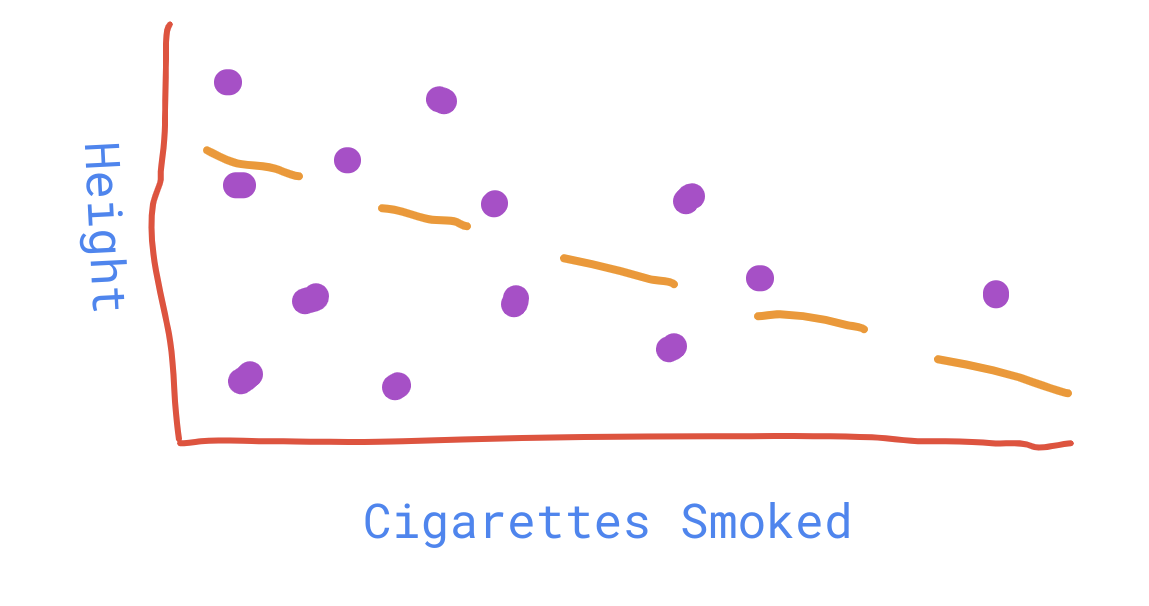
Then I can graph - the probability that I would see the exact experimental results I got, given the value of the correlation. This will look something like this:
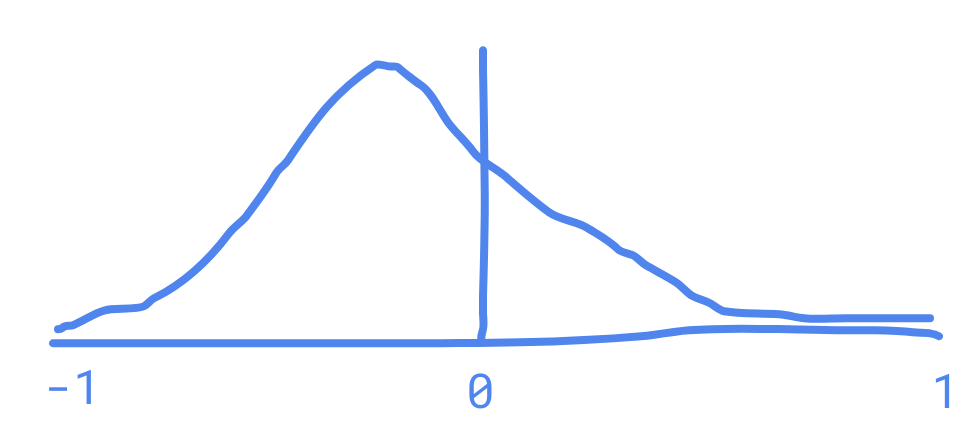
Note that this time the graph peeks below 0 since the trend line is downwards sloping - we would be more likely to see our experimental results if the coefficient of correlation was negative.
(Now someone might point out that is always equal to 0 assuming the possible values of B are continuous. However the exact probabilities don't matter, all that matters is that the relative heights are correct, since when we use this graph we will normalize the results. So it's perfectly fine to use the probability density of seeing B given A instead of the probability.)
Bayes formula for probability densities is as follows: Let represent the probability density that has value x.
Then:
This might look super complex, but it's actually extremely straightforward. Graphically we multiply out the two graphs - our prior and the chance of seeing the experimental results we saw, getting a result that looks this:
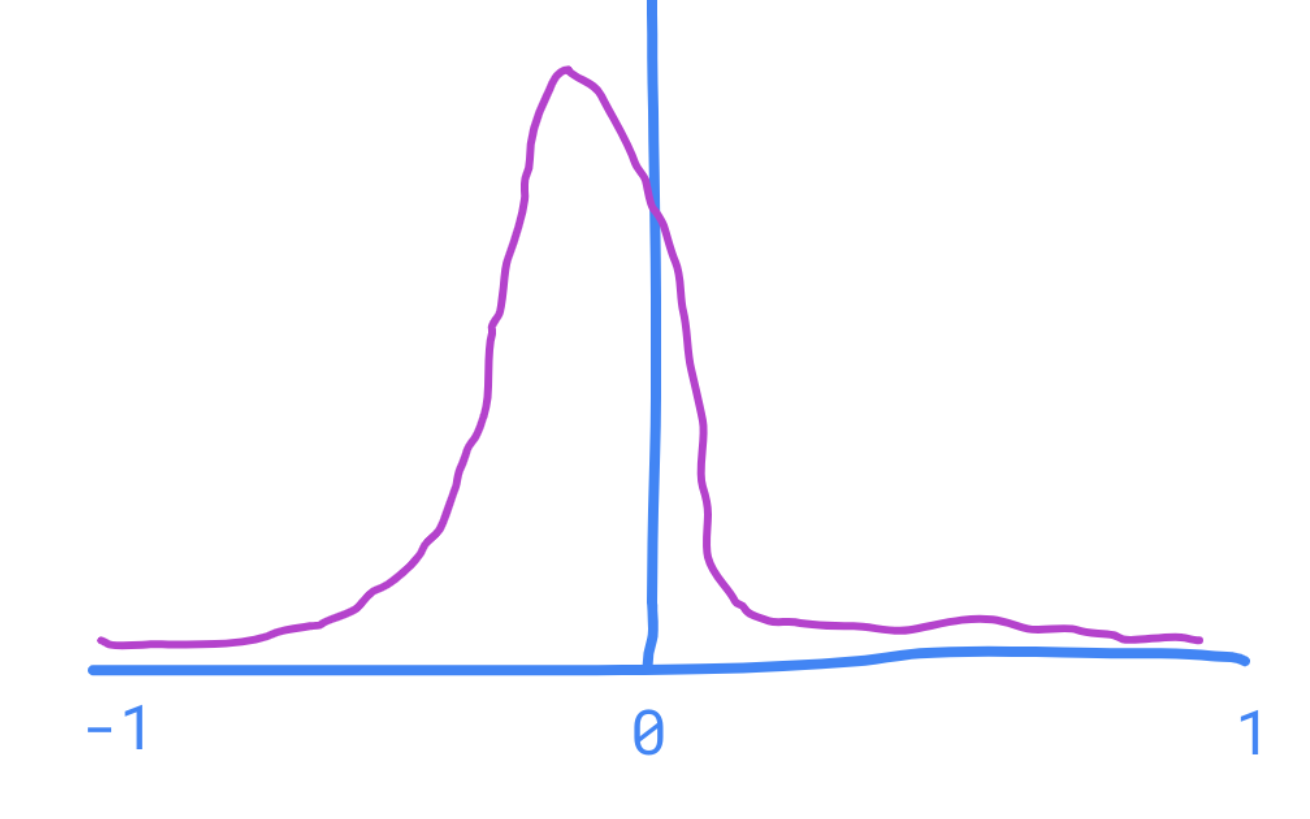
At every single point we just multiplied the Y value on both graphs and plotted that as the new y value. As a result it's much steeper and more pointed.
We then simply scale the graph so that the total probability adds up to 1:
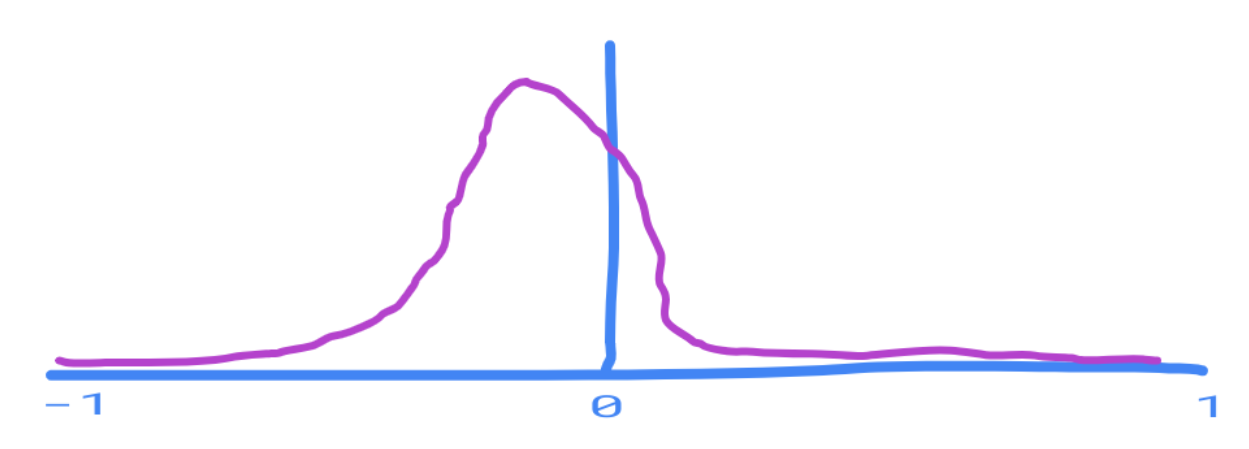
So all the paper needs to report for the meta analysis to be able to do it's Bayesian update is the probability distribution of seeing the results we saw, varying over whatever variables we may be interested in. Whilst finding a computable function to represent this distribution may not be possible, it should usually be doable to calculate this for a lot of dense points in the regions of interest, which can be published as a data set online.
So in place of a conclusion, each paper would basically just publish a graph saying: "Depending on what values X, Y and Z have, this is how likely it would be to end up with the results we saw. Make of that what you will."
Now this graph is always interesting unless it's a perfectly flat uniform distribution, since it will always adjust the prior. As a result there's very little reason for the scientists not to publish the experimental results whatever they find - there's no such thing as a negative result. Similarly, there's no P value, so there's nothing to hack.
Conclusion
We've looked at some of the problems with current methods of doing science, and suggested a methodology for improving science by focusing on Bayesian updates instead of p-values.
We've looked at how we can publish a Bayesian update separate from any priors, and suggested that if papers were to publish their results in that format, it would allow meta-analyses to easily update on a paper, which would make a Bayesian methodology of Science more practical to carry out.
We've also suggested that if papers were to avoid drawing any conclusions at all beyond this, that would hopefully alleviate some other current problems with the scientific process today, such as P hacking and publication bias.
There's plenty more work that needs to be done to turn this into a practical methodology, but hopefully this is a good start!
7 comments
Comments sorted by top scores.
comment by Richard_Kennaway · 2021-10-07T09:48:28.446Z · LW(p) · GW(p)
Imagine you are a Good Scientist. You know about p-hacking and the replication crisis. You want to follow all best practices. You want to be doing Good Science!
You're designing an experiment to detect if there's a correlation between two variables.
Your Good Scientist has gone off the rails already. Why do they want to know if there's a correlation between two variables? What use is a correlation?
I am not seeing where your Bayesian Scientist is doing any better. He's dropped p-values and adopted a prior, but he's still just looking for correlations and expressing results according to the Bayesian ritual instead of the Frequentist ritual. But nobody cares whether smokers tend to be taller or shorter than non-smokers. They care about whether smoking stunts growth. A Truly Good Scientist needs to be looking for causal structures and mechanisms.
Replies from: adrian-arellano-davin, yair-halberstadt↑ comment by mukashi (adrian-arellano-davin) · 2021-10-07T09:59:00.782Z · LW(p) · GW(p)
Looking for causal structures and mechanisms do entail (among other things) doing correlations. Would your critic still be valid if he had used a different example? He could have chosen anything else, the example was used to illustrate a point.
↑ comment by Yair Halberstadt (yair-halberstadt) · 2021-10-07T11:24:55.802Z · LW(p) · GW(p)
Exactly as mukashi was saying, the correlation is purely an example of something I want to find out about the world. The process of drawing inferences from correlations could be improved too, but that's a different topic, and not really relevant for the central point of this post.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2021-10-07T15:31:24.959Z · LW(p) · GW(p)
The point I'm raising is independent of the example. "Looking for a correlation" is never the beginning of an enquiry, and, pace mukashi, is not necessarily a part of the enquiry. What is this Scientist really wanting to study? What is the best way to study that?
I work with biologists who study plants, trying to work out how various things happen, such as the development of leaf shapes, or the development of the different organs of flowers, or the process of building cell walls out of cellulose fibrils. Whatever correlations they might from time to time measure, that is subordinate to questions of what genes are being expressed where, and how biological structures get assembled.
Replies from: yair-halberstadt↑ comment by Yair Halberstadt (yair-halberstadt) · 2021-10-07T15:34:57.671Z · LW(p) · GW(p)
That may be the case, but I think that is peripheral to the point of this post. If for some reason I wanted to find out the value of a variable (and this variable could be anything, including a correlation), how would I go about doing it.
Replies from: Richard_Kennaway↑ comment by Richard_Kennaway · 2021-10-07T16:03:37.210Z · LW(p) · GW(p)
I am taking the point of the post to be as indicated in the title and the lead: creating a model for doing Empirical Science. Finding out the value of a variable — especially one with no physical existence, like a correlation between two other variables — is a very small part of science.
comment by ChristianKl · 2021-10-09T21:22:27.870Z · LW(p) · GW(p)
Finally in order to come to a conclusion via Bayesian updating, you first need a prior. The problem is that there's no practical objective way to come up with a prior (Solomonoff induction is not practical). This means that you can come to any conclusion you like based on the available evidence by choosing a suitable prior.
One way to deal with that would be to require scientists to specify their priors when registering their study setup. It doesn't increase the complexity of registering the study very much but it does give you a prior. It also allows you to look at all the studies by a given scientist to find out how well calibrated their priors are.