Higher Dimension Cartesian Objects and Aligning ‘Tiling Simulators’
post by lukemarks (marc/er) · 2023-06-11T00:13:12.699Z · LW · GW · 0 commentsContents
Introduction Properties of Cartesian Objects Controllability Manageability Observability Inevitability Viability Tiling Agents Tiling Simulators None No comments
Thanks to Justis Mills for feedback. Mistakes are mine.
Introduction
This document will attempt to build upon the Cartesian frame [? · GW] paradigm by modeling multi-agent worlds as higher dimension Cartesian objects. Cartesian objects partially betray many of the properties of their frame counterpart, and they aren't really just 'extensions' of frames, but they are quite similar in some respects and can be reasoned about in similar ways. I will discuss their properties, use them to model recursive self improvement (RSI)/tiling, and show how I think they can be used to construct formal frameworks for solving some outer alignment problems in simulators [LW · GW]. The math will be quite difficult to understand if you haven't read Introduction to Cartesian Frames [LW · GW] and sections 1 and 2 of Tiling Agents for Self-Modifying AI, and the Löbian Obstacle. It is also incredibly messy and will be refined in later writings.
To introduce the concept, I will present an example in the context of a two-agent game:
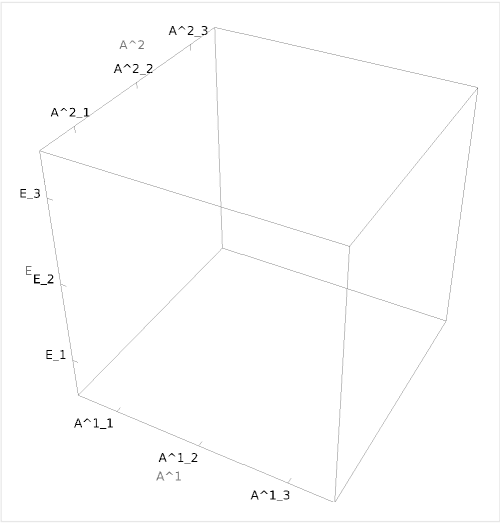
For a clearer representation of world separation, see:
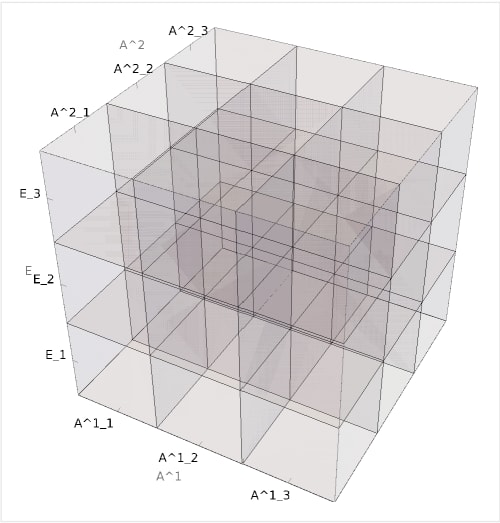
In theory a Cartesian object could have any number of dimensions, and the above is just one potential configuration used as a toy model to introduce the concept. Most models will involve far more than three actions per axis and many more than two agents.
Properties of Cartesian Objects
These are all adaptations of Garrabrant's original definitions of the properties of cartesian frames to work with higher dimension cartesian objects.
The set of all actions that could be pursued by any agent described by such an object is hereafter:
And by a specific agent:
Controllability
The set of ensurables, preventables and controllables for the th agent in the Cartesian object could thus be formalized as:
Manageability
We consider manageability, which extends controllability to account for uncertainty in the behaviors of other agents, which we formalize as the belief threshold (which could change dependent on the agent's risk tolerance and the like):
Observability
Observability remains practically unchanged, so I will quote the original post but note that this will apply again to the th agent:
Observables can be thought of as a closure property on the agent. If an agent is able to observe , then the agent can take policies that have different effects depending on .
Inevitability
Garrabrant defines the property of inevitability as the intersection of a frame's ensurables and observables if and only if a frame's image is a subset of and is nonempty. The definition remains largely unchanged for higher dimension objects excluding agent specificity:
Viability
Viability can be thought of the manageable alternative to inevitability. If conditional on some manageable property occurring it can be observed, it is considered viable:
Tiling Agents
Assuming an agent attempting RSI or tiling would want to know that its subsequent agent(s) would pursue aligned goals and be sure it can produce said agent; it may be interested in the property of inevitability.
Tiling Agents for Self-Modifying AI, and the Löbian Obstacle defines the following property of ideal tiling agents:
[4][5]
Note that here the regular turnstile is used in place of the special turnstile denoting cognitive conclusion of a belief (as I couldn't format it properly). This exception applies only here.
In place of certain belief in some outcome, we can instead make conditional on the inevitability of what proves (e.g. ) . Using this example, we could say:
Here the regular turnstile is used intentionally as it will be for the remainder of the document.
An agent might instead be interested in pursuing viability over inevitability for one or more of the following reasons:
- Inevitability is impossible
- Pursuing high-certainty viability yields greater utility (e.g. it could be better to pursue an outcome now that is 99% likely to occur compared to waiting for a year for it to be certain)
- It is more conforming to some compelling normative standard (may overlap with (2))
In terms of viability:
Whilst this is just generalizing from the belief turnstile for a standard turnstile, I will try to convey the utility of this form in creating aligned simulators.
Tiling Simulators
To make Cartesian objects useful for thinking about simulators, do the following:
- Imagine a box. This box has a volume that corresponds to the highest possible complexity simulation a given simulator can conduct.
- Imagine a Cartesian object in that box. This object consumes an amount of the box's volume proportional to its own complexity and likely consists of an environment and various agents.
By default this box does not care what is in it. The box was content with this until someone started telling the box that some of the things in it were good, and some of the things in it were bad (conditioning). If this box was a deceitful box, it would just hide the bad objects under good ones such that it looked like a good box (deceptive alignment). If it was a good box (robustly aligned), it would contain only good objects. If the box wants to have a lot of objects in it, it can't rely on the limited approval rate of the person who initially instructed it, and so it needs a more scalable criterion.[7][8]
When modeling a conditioned simulator as a tiling agent, you also gain access to various luxuries such as the fact that by definition the seed agent can simulate the agents it creates in the future. We do not need to worry about issues from the tiling agents paper like:
If you are constructing a system cognitively smarter than yourself (or self-improving to a cognitively superior version) then you should not be able to foresee at compile time exactly which solutions will be generated, since you are not presently that smart.
On the other hand, it's not as though you can just have a simulator simulate a world with a general intelligence in it to see if it is aligned or not, as this process is identical to having it be simulated regularly, and thus entails the same risks.
One issue with advanced simulators is that creating nested simulations greatly increases the probability that one of the simulated agents is capable of influencing the real world negatively and is motivated to do so. There is a limit to this risk as it is unlikely that very low complexity simulations are able to contain a program as advanced as general intelligence, but this limit becomes increasingly insignificant as the power of simulators grow.[9]
Ideally, a successfully conditioned simulator would be able to assess potential simulacrum against a safety criterion, and either conclude that negative real-world influence was either preventable or nonviable with high certainty. If this criterion could be simply expressed in first-order logic, it may be able to be expressed symbolically. Here is a control flow diagram detailing how that might work:
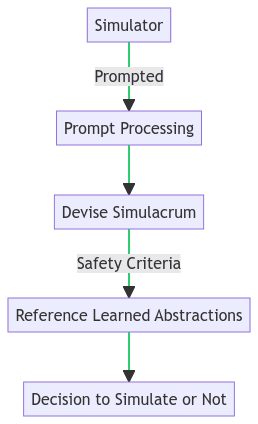
To clarify, a successfully formalized safety criterion would not constitute a complete alignment solution for simulator models. What it would ensure is that simulated simulators and simulated agents adhere to some principle that if followed restricts influence outside their residing Cartesian object to be either controllably or manageably non-negative as defined by their conditioning.
- ^
Where refers to the number of possible actions the th agent could pursue.
- ^
Where is the set of agents the manageability is conditional on (e.g. )
- ^
It might be unclear, but here refers to the subset of reachable by the th agent.
- ^
An agent marked with an overline (e.g. ) denotes that said agent was constructed.
- ^
φ Denotes some belief.
- ^
just represents worlds where is true.
- ^
The box analogy breaks down when your cartesian objects are not three dimensional, but likely so does any description of a >3 dimensional object, and I find it useful for explaining the concept regardless.
- ^
In regular terms: A pure simulator has no reason to abide by any tiling desiderata, but a conditioned simulator might. Thinking of conditioned simulators as creating new agents the same way a standard tiling agent would is useful, as the latter is much more intuitive and has more theoretical groundwork.
- ^
Knowing this limit would require knowing the lowest possible complexity program capable of negatively influencing the real world from within a simulation (which is probably at least general intelligence). I use it more as an illustrative example than as something actually worth computing.
0 comments
Comments sorted by top scores.