Superintelligent AI is possible in the 2020s
post by HunterJay · 2024-08-13T06:03:26.990Z · LW · GW · 3 commentsContents
Empirically Practically Theoretically Sanity Check Can LLMs Generalise? Is Running Out Of Data Going To Stop Progress? Has Progress Slowed Already? Do Bio Anchors Mean Human-Level AGI is Impractical with Today’s Compute? Are We Fundamentally On The Wrong Path For Agentic AI? Conclusion A Few More Notes Top Model (June 2024) None 3 comments
Back in June 2023, Soroush Pour [LW · GW] and I discussed AI timelines on his podcast, The AGI Show. The biggest difference between us was that I think “machines more intelligent than people are likely to be developed within a few years”, and he thinks that it’s unlikely to happen for at least a few decades.[1]
We haven’t really resolved our disagreement on this prediction in the year since, so I thought I would write up my main reasons for thinking we’re so close to superintelligence, and why the various arguments made by Soroush (and separately by Arvind Narayanan and Sayash Kapoor) aren’t persuasive to me.
Part 1 - Why I Think We Are Close
Empirically
You can pick pretty much any trend relating to AI & computation, and it looks like this:[2]
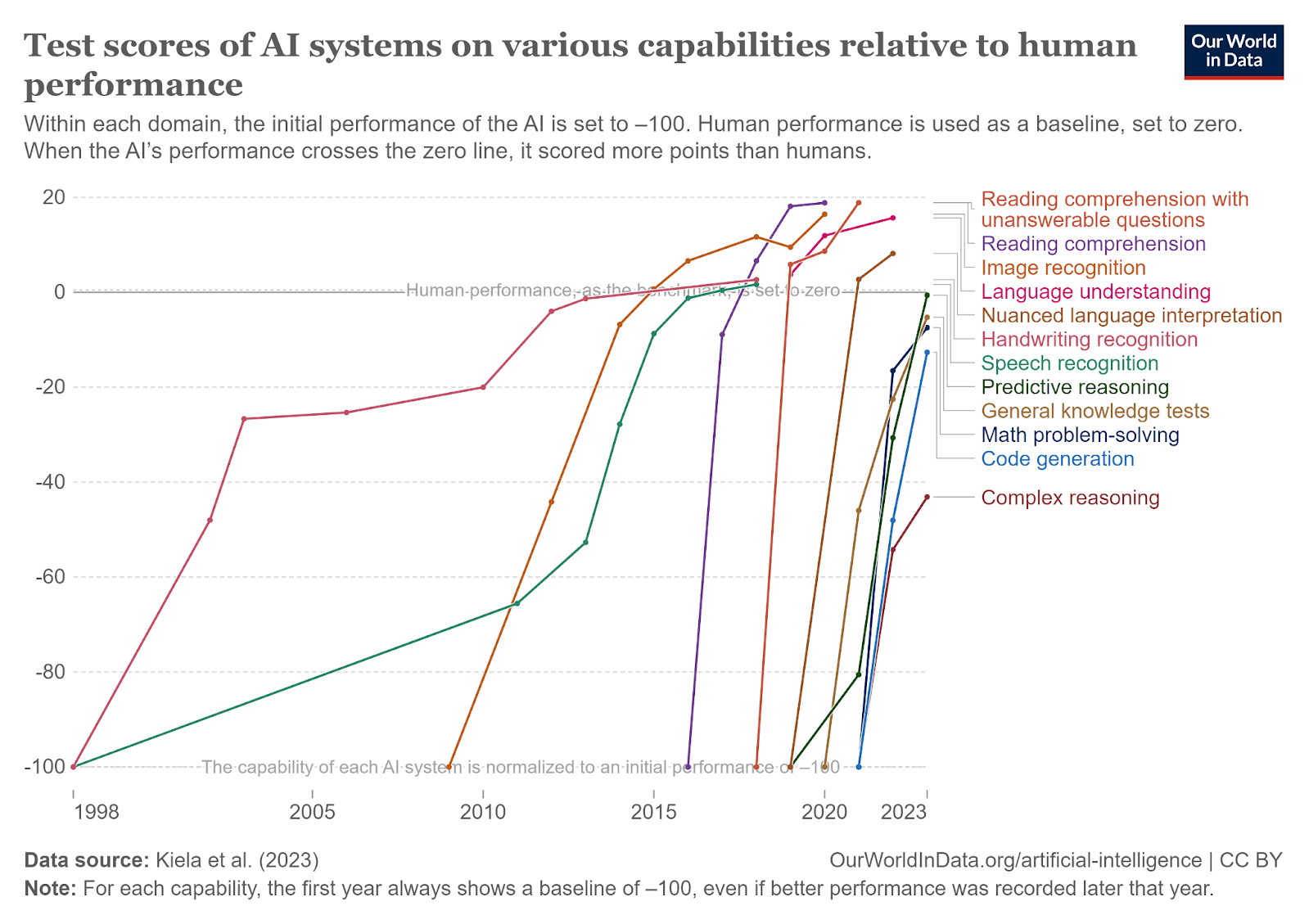
We keep coming up with new benchmarks, and they keep getting saturated. While there are still some notable holdouts such as ARC-AGI, SWE-Bench, and GPQA, previous holdouts like MATH also looked like this until they were solved by newer models.
If these trends continue, it’s hard to imagine things that AI won’t be able to do in a few years time[3], unless they are bottlenecked by regulation (like being a doctor), or by robot hardware limitations (like being a professional football player)[4].
Practically
The empirical trends are the result of several different factors; changes in network architecture, choice of hyperparameters, optimizers, training regimes, synthetic data creation, and data cleaning & selection. There are also many ideas in the space that have not been tried at scale yet. Hardware itself is also improving -- chips continue to double in price performance every 2-3 years, and training clusters are scaling up massively.
It’s entirely possible that some of these trends slow down -- we might not have another transformers-level architecture advance this decade, for instance -- but the fact that there are many different ways to continue improving AI for the foreseeable future makes me think that it is unlikely for progress to slow significantly. If we run out of text data, we can use videos. If we run out of that, we can generate synthetic data. If synthetic data doesn’t generalise, we can get more efficient with what we have through better optimisers and training schedules. If that doesn’t work, we can find architectures which learn the patterns more easily, and so on.
In reality, all of these will be done at the same time and pretty soon (arguably already) the AIs themselves will be doing a significant share of the research and engineering needed to find and test new ideas[5]. This makes me think progress will accelerate rather than slow.
Theoretically
Humans are an existence proof of general intelligence, and since human cognition is itself just computation[6], there is no physical law stopping us from building another general intelligence (in silicon) given enough time and resources[7].
We can use the human brain as an upper bound for the amount of computation needed to get AGI (i.e. we know it can be done with the amount of computation done in the brain, but it might be possible with less)[8]. We think human brains do an equivalent of between 10^12 and 10^28 FLOP[9] per second [a hilariously wide range]. Supercomputers today can do 10^18. The physical, theoretical limit seems to be approximately 10^48 FLOP per second per kilogram.
We can also reason that humans are a lower bound for the compute efficiency of the AGI (i.e. we know that with this amount of compute, we can get human-level intelligence, but it might be possible to do it with less)[10]. If humans are more efficient than current AI systems per unit of compute, then we know that more algorithmic progress must be possible as well.
In other words, there seems to be plenty of room for AI capabilities to keep improving before they run into physical limits.
Sanity Check
I generally don’t think arguments from authority are very good, but checking “Do other experts agree or disagree with this conclusion?” can at least help calibrate our priors[11]before thinking through the arguments.
It turns out there is no strong consensus. Shane Legg (Deepmind), Dario Amodei (Anthropic), and Sam Altman (OpenAI) all think that superintelligent AI could be coming within a few years. Yann Lecun (Meta) and Andrew Ng (Stanford) think we have at least decades. The median expert date is 2047 (with the same survey giving a 10% chance by 2027)[12]. Prediction markets estimate 2033 (Metaculus) and 2032 (Manifold).
The jury is still out. More detailed write-ups going through expert opinions are here and here, but be aware that views are changing rapidly, and somebody's opinion from 2022 might not be their opinion today.
Part 2 - Response To Arguments Against Short Timelines
I originally was going to write this essay as a rebuttal to this piece called ‘AI Scaling Myths’, but I’ve now found I don’t quite understand why they disagree with my position. Instead, I’ll use that essay as a starting point to broadly cover some of the main positions against near-term superintelligence.
Can LLMs Generalise?
It’s often argued that LLMs are just ‘stochastic parrots’, basically repeating a probability weighted sample of their training set. Critics point to LLMs failure on datasets like ARC-AGI (which they claim require general intelligence to solve) as examples of this. The argument seems to go ‘Nothing like ARC is in the dataset, and LLMs fail on ARC, so this is evidence that they can’t generalise’, for multiple datasets and tasks.
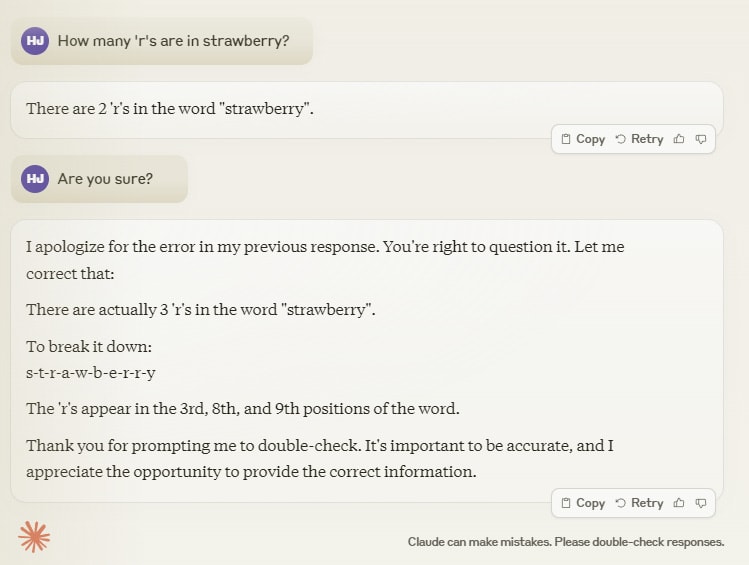
But we also have some evidence that they can generalise, at least a little. I can give Claude lots of different patterns and ask it to continue them, and it will[13]. I can ask it a question, let it give me the wrong answer, and then just ask it to check it’s work, and it will do so and get to the correct answer[14]. I can ask it to write a story, and the story it writes will not be a copy of anything that already exists, even if it is similar[15].
None of these exact sequences were in the dataset, but the dataset did contain many similar tasks, and the model was able to make the small leap to solve that type of problem in the general case. That’s generalisation!
So why can’t they solve ARC, and other tests, which involve problems that are very different to their training set?
My guess is that their failure is a combination of:
- Not having good tools or structures to solve these sorts of problems.[16]
- Not having an optimal architecture for generalisation.
- Not being large enough or trained for long enough.[17]
- The training set just not being broad enough.[18]
If my guesses here are correct, then in the next few years we should see problem sets like ARC begin to be saturated as each of these items is improved. Seriously, these problems are hard when formatted the way that LLMs are forced to view them. Here’s an ARC problem, the way an LLM sees it:
{"train": [{"input": [[8, 6], [6, 4]], "output": [[8, 6, 8, 6, 8, 6], [6, 4, 6, 4, 6, 4], [6, 8, 6, 8, 6, 8], [4, 6, 4, 6, 4, 6], [8, 6, 8, 6, 8, 6], [6, 4, 6, 4, 6, 4]]}, {"input": [[7, 9], [4, 3]], "output": [[7, 9, 7, 9, 7, 9], [4, 3, 4, 3, 4, 3], [9, 7, 9, 7, 9, 7], [3, 4, 3, 4, 3, 4], [7, 9, 7, 9, 7, 9], [4, 3, 4, 3, 4, 3]]}], "test": [{"input": [[3, 2], [7, 8]], "output": [...] }]}
Try to solve for ‘output’ without reformatting the data, and by only reading through it once, then writing your answer out in a single stream of consciousness. It’s not trivial! The answer in the footnotes.[19]
Regardless, I predict we will reach 85% on ARC by the end of 2025.[20]
Another example of the shortcomings of LLMs was pointed out by Yann LeCun in 2023. He argues that Auto-Regressive LLMs will inevitably fail because errors accumulate -- the probability that each token is “correct” can be very high, but eventually a mistake will be made and the model will go off the rails.
This might be technically correct, as a mathematical statement, but the misleading bit is that it’s only true while the system is entirely auto-regressive (meaning the next token is entirely the result of the previous tokens). A model that interacts with the world (say, by running the code it outputs and receiving the result, or by doing a Google search) now has components that are not autoregressive, so the proof doesn’t apply.
Overall, pointing out the shortcomings of today’s LLMs does not do much to argue against the general trends in AI. RNNs with LTSM had limitations that the transformer architecture fixed, and it was fixed without all the existing work needing to be thrown away -- we use the same kinds of compute, the same kinds of data, the same kinds of optimisers, and so on. I don’t expect LLMs, or transformers generally, to be the last such advance in AI, but I do expect the vast majority of the work on them to transfer over to whatever the next architecture ends up being.
Is Running Out Of Data Going To Stop Progress?
It does seem likely that we’ll run out of publicly available, high quality, human generated text data in the near future.
However, this doesn’t mean progress will slow! We have lots of ways forward!
The most obvious way is just for data efficiency to continue improving. When that report was originally released in 2022, it predicted that text data would be exhausted by 2024. Now, in 2024, it predicts that text data won’t be exhausted until 2028. Why? It was primarily because:
- There were large improvements to the automated filtering of scraped data, which gave a 5x increase to the estimate for available high-quality training data.
- It was discovered that training LLMs for multiple epochs is usually fine, making newly trained models 2-5x more data efficient than predicted.
Also, here we are only talking about text data. Some critics, including the AI Scaling Myths blog post, don’t seem to realise that video, audio, and image data can be used to train multimodal models directly (rather than being transcribed). GPT4o is a native multimodal model, for example.
These other modalities unlock another ~1700 trillion tokens, making real-world data available for another several years of scaling at the current rate.
And that is without considering synthetic data. In domains where the results are verifiable, synthetic data already works extremely well -- AlphaGo, for instance, was trained on millions of games played against itself. We can also generate autonomously verifiable data in maths and programming.
Even if we eventually run out of data in other domains, how far can an AI get with maths and programming? Are those two skills enough to reach a positive feedback loop in AI development without being superhuman in any other domain? I don’t know, but it seems plausible to me. It’s also currently an open question how far we can get with simulated environments, like other games and computer sandboxes, which provide unlimited data and are suitable for training multi-step agents.
Plus, we do see synthetic data generated by LLMs themselves emerging today as well. Nvidia’s Nemotron is an example in this direction, though it is primarily used for fine-tuning existing models rather than generating data for training more-capable base models. Still, one can imagine that for as long as a model can assess its own outputs accurately, it could generate, then filter, those outputs into a new dataset to train on.
Has Progress Slowed Already?
Sometimes people claim that the last few years have represented a slowdown relative to the resources put into AI development, or that recent developments have undershot expectations, especially compared with the high expectations after the release of GPT-4.
I don’t think this is the case. It’s very difficult to give a very clear (i.e. non-cherry-picked) overview, but there have certainly been several serious improvements in the 16 months since GPT-4 was released. In March 2023, standard context windows were ~8000 tokens instead of ~125,000, there were no good video generation engines, frontier models were an order of magnitude more expensive to run, and the benchmark performance was a fair bit worse, especially on maths and coding (most of these you can see by comparing Claude Sonnet 3,5 (June 2024) to GPT-4 (March 2023)).
There were three years between GPT-3 and GPT-4. I think the current pace puts us well on track for a similar level of improvement between GPT-4 and whatever the top model is in 2026, if not more.[21]
We can also check predictions made about AI from three years ago to see if we’ve overshot or undershot expectations. In 2021, Jacob Steinhardt’s group (who also developed some of the benchmarks used) commissioned a forecast which included SOTA estimates on AI in 2024. Here are the predictions compared with today’s results.[22]
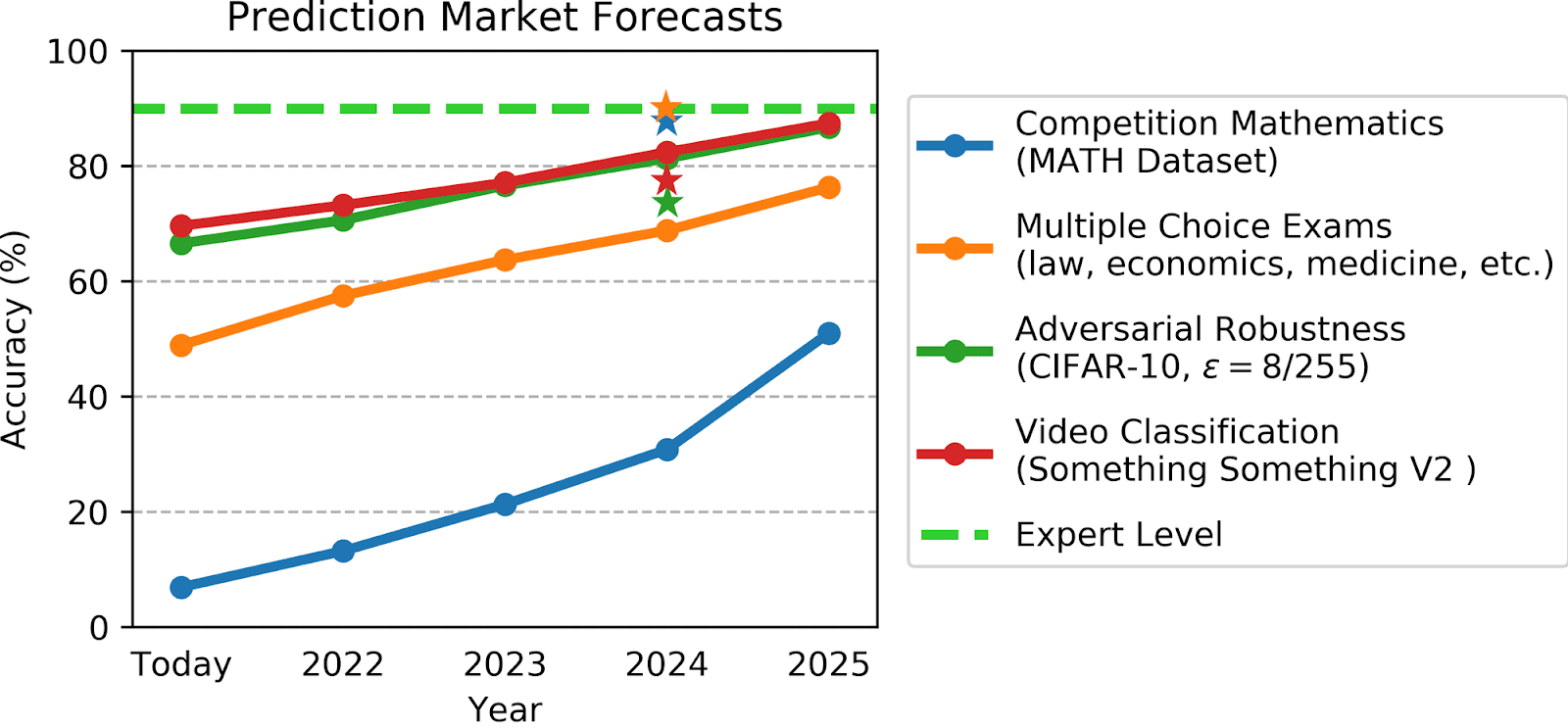
The dots are the forecast results, the stars are the actual results.
The forecasts massively undershot actual progress on text-based questions (MATH and MMLU), and somewhat overestimated progress on adversarial robustness and video classification[23].
Overall, I take this forecast as indicating that the progress made in the past three years is larger than the progress made in the three years before that. It’s harder to compare predictions from after GPT-4 was released (which was only 16 months ago), but there are a few surprising advances, such as silver on the IMO, which seems to have overshot expectations.[24]
This isn’t an argument that predictions today are still underestimating AI (though they very well may be), it’s an argument that the relative progress of AI compared to what was expected a few years ago is fast, not slow.
Do Bio Anchors Mean Human-Level AGI is Impractical with Today’s Compute?
Supercomputers today are well within the range of ‘human-brain compute’ estimates, so we can’t rule out AGI being possible to run with today’s clusters based on bio anchoring to human brain computation.
Regardless, bio anchors are not a reliable way to estimate future progress on AI. There is just too much uncertainty. If we can make a direct comparison at all -- such as with the amount of compute in a brain vs in a digital computer -- our error bars span sixteen orders of magnitude. And if we can’t make a direct comparison -- such as where we try to compare the efforts of evolution to the directed work of human researchers -- it’s not clear we get any useful information at all.[25]
As we get closer to AGI, empirical data matters much more than the very broad assumptions we get from bio anchors, and this has been moving even proponents of the bio anchor’s method towards much shorter timelines -- Ajeya Cotra, for instance, who wrote the most detailed report on bio anchors in 2020 [LW · GW], has reduced her personal estimates for when we will reach superintelligence significantly, down to a median date of 2036 [AF · GW], nearly twice as fast as the number projected in the original report written just four years ago[26].
Are We Fundamentally On The Wrong Path For Agentic AI?
LLMs are not the best architecture for agents -- the pre-training does not let the model learn to execute multi-step plans, they can’t natively learn or adapt, they have no memory beyond what is put into their context window, and they must output a token each forward pass.
What does that mean for timelines?
I guess my main thought here is that these limitations are already priced in. Improved algorithms (which include changing architectures) account for about 35% of the improvements made in language modelling since 2014, effectively halving the amount of compute needed to reach a given performance every 8-9 months. If this trend continues, the architecture will evolve, and the current issues will be forgotten just as previous problems were[27].
And there are plenty of ways for this trend to continue -- for example, we already know that other AI systems do not share these same limitations. RL agents like AlphaZero have no problem finding and executing multi-step plans (albeit in very limited domains) and combination architectures like AlphaGeometry use language models alongside a symbolic engine to search for solutions in a way that LLMs cannot do alone.
These systems have their own limitations, of course, but the fact that they exist makes me more confident (and worried[28]) that we’ll find ways to get the strongest parts of each into a single, general, and superhuman system in the next few years.
We already do reinforcement learning on LLMs post training, and there’s been a lot of progress working around their issues[29], most notably with RLHF and instruction tuning, and with tool use. Other agentic approaches (such as building structures around the LLM to essentially prompt it better) have led to SWE-Bench going from a ~2% success rate to ~30% in under a year, and current frontier models already quite well on software tasks that take humans under about 15 minutes to do.
All of that said -- even if really significant changes to the architecture are required, I would be surprised if the work being done on compute, data (real and synthetic), and on low level algorithmic improvements (such as to gradient descent optimisers) couldn’t be easily applied to future systems.
Conclusion
As we get closer to developing AGI we move away from vague guesses based solely on trend extrapolation (bio-anchors, compute charts, benchmark progress), and towards having specific designs in mind, that, if built, might be enough.
I think we are at that ‘specific designs’ stage already. We’re not quite at “Let’s go ahead and implement X to build AGI”, but we are definitely at “What if we tried something like Y?”.
Barely eight years ago, as an undergrad, I remember explaining to my friend why Winograd Schemas were such a hard problem. At the time, I couldn’t see a way that they could be solved -- all I could say was that it must be possible (because humans did it) and that maybe in 5 or 10 or 20 years we could figure out how to get a computer to actually understand language.
Today, I wouldn’t be shocked if we reached human-level AGI with something like a 10 trillion parameter transformer-like model which used ternary activations and was trained on next-token prediction across 100 trillion tokens of multimodal real-world data, had another 20 trillion steps of reinforcement learning on synthetic multi-step problems in maths, engineering, and “games”,[30] and which operates within some kind of structure allowing multiple steps of search & planning during inference[31], and which gives the model some way of actively learning[32].
That’s not very specific[33], but it’s a hell of a lot more specific than “I can’t even begin to guess at how to build AGI”, and anybody working at a major lab building frontier models today would have dozens of much better and more specific sets of ideas than this one.
A Few More Notes
- In this essay, I didn’t talk about the alignment problem, or the serious risks we face if superintelligent AI is actually built. That is beyond the scope here, but a detailed summary can be found from Yudkowsky here [LW · GW]. The basic idea is simple -- if we create a machine that is very capable of achieving goals, and then we give it a goal, it might go ahead and actually try to achieve it. You will be better at achieving most goals if you are smarter, have more resources, and are not dead[34]. Unfortunately, humans also want those resources.
- I also want to add a disclaimer on my predictions -- 50% odds of AGI by the end of 2029 is a very uncertain estimate, and I don’t think AGI is 90% likely to happen until 2060! My main argument here is that AGI is way more likely to happen this decade than is commonly predicted, and we should be prepared for things to happen quickly. I do try to ground things by giving some intermediate predictions with >80% / <20% credence in footnote 17 (so I expect about 1 in 5 of those to be wrong), but finding specific predictions is much harder than looking at trends, thinking about the question, and coming to “this seems very possible”, which is really what is happening here.
- Epoch AI has been a great source for this essay. I’ve linked to them several times, but I wanted to call them out more explicitly, they do some really great work.
Thanks also to Soroush Pour and Serena Hack for reading and offering suggestions & corrections prior to publication.
FOOTNOTES
- ^
Specifically, we used the definitions:
- AGI: An artificial system that can do most or all economically and politically useful tasks that a human can do.
- ASI / superintelligence: An artificial system that significantly exceeds the ability of humans at most or all economically and politically useful tasks
My predictions were 50% odds of AGI and ASI by 2029 and 2032 respectively, whereas Soroush gave 50% odds for 2068 and 2088.
- ^
The y-axis here measures ‘relative to human performance’. From the authors: “For every benchmark, we took the maximally performing baseline reported in the benchmark paper as the “starting point”, which we set at -1. The human performance number is set at 0. In sum, for every result X, we scale it as
(X-Human)/Abs(StartingPoint-Human)”
[This version of the graph multiplies those values by 100].
Note that this means that if the maximum score on the benchmark is close to the human score, the benchmarks will saturate, so we won’t be able to measure progress much above human level. The fact that the improvement rate slows down around human level could be partially explained by this effect.
- ^
I would love to hear predictions for tasks AI can do by the end of 2026, 2029, and 2034 [2, 5, and 10 years out].
Here I list some tasks, and give my confidence that a general AI system will be able to do them at human level or above in each year. By ‘general’, I mean the same system needs to do many tasks (like GPT-4), rather than being trained specifically for one task (like AlphaGo). For computer based tasks, the AI gets access only via the display, keyboard, and mouse -- not a specialised interface.
I am mainly interested in confident predictions -- “I am quite sure this will be possible / impossible” -- so I’m going to simplify things for myself (and be a little cowardly) and just bucket the likelihoods as <20%, 20-80% (written as ??), and >80%.
Task 2026 2029 2034 Achieve gold on the International Maths Olympiad >80% >80% >80% Surpass human performance on ARC-AGI tasks. >80% >80% >80% Surpass human performance on SWE-Bench. >80% >80% >80% Be able to control a general purpose, humanoid robot well enough for at least some useful tasks like warehouse work, some types of cleaning, some types of cooking, general pick and place tasks, sorting and folding clothes, etc. I.e. Does anybody use the system commercially other than the developer? ?? >80% >80% Control a humanoid body to do most everyday tasks (like dishes, laundry, building furniture, cleaning, cooking, etc) as well as a human can do them. <20% ?? >80% Generate at least some coherent, 30 second clips of basic scenes like walking on a beach, or a dog playing with a ball without obvious mistakes (like objects turning into other objects, or people having multiple limbs). >80% >80% >80% Generate at least some coherent 60 second clips with dialogue without obvious mistakes (where the dialogue is as realistic as a dubbed movie). ?? >80% >80% Generate a coherent, plot-driven feature film. <20% ?? >80% Generally succeed in computer tasks that require both planning and adaptation to changing circumstances on time frames longer than 60 minutes without human intervention. For example: <20% ?? >80% - Build and deploy a new iOS and Android app from scratch, then improve it based on its real world performance.
<20% ?? >80% - Win a long, progressive game like Factorio or Baldur's Gate 3 in the same game-time that a human can.
<20% >80% >80% - Resolve CUDA and Pytorch dependency conflicts on Windows 10, from a state where incompatible versions are initially installed, and then download and run a vision model using them.
?? >80% >80% Let a person build a standard dynamic website without doing any direct programming. (i.e. the model does the programming, but the person still needs to prompt it correctly to progress and solve bugs. The website might be something like a blog with likes and comments, or an image sharing site). >80% >80% >80% Autonomously build and deploy a standard dynamic website without human intervention given some initial set of requirements. ?? >80% >80% Let a person build, without directly programming, most software that would take an unassisted human engineer less than a week to build. ?? >80% >80% Autonomously build most software that would take any unassisted human engineer less than a week to build. ?? >80% >80% Diagnose illness more reliably than an average doctor given the same information (i.e. remotely). ?? >80% >80% - ^
Whether these trends can continue is, of course, the whole disagreement here. The “trends” are also unclear because we don’t really have a nice clean graph of “general intelligence increasing over time” which moves from ant to frog to mouse to monkey to human level and beyond.
Instead, we have a lot of benchmarks for different tasks (Chess, Go, image recognition, text understanding, etc) which stay well below human performance for a long time, and then suddenly spike up to above human level (or as high as the benchmark can measure) over the course of a few years.
The closest we can get to a smooth trend is probably in ‘computation used’, which is rising quickly. The trouble is that it’s hard to compare that to human brain computation, as discussed elsewhere.
- ^
I use Claude Sonnet 3.5 *all the time* when I am programming, and now we have tools like Cursor and Copilot where the AI is built into the IDE and can make context-aware updates to the codebase when I ask it for improvements and recommendations. SWE-Bench is a good measure of fully autonomous AI software development, and it is improving rapidly -- from about 2% success rate at the end of 2023, to about 20% today.
- ^
I think this is very very likely, but there is still some disagreement on the question. I take a ‘substrate independence’ view on the Philosophy of Mind, if it turns out to be the key disagreement with my argument here, it can be talked about at length in another essay.
- ^
The ‘enough time and resources’ is probably the crux of any disagreement about timelines, but I still think there’s value in briefly laying out why it is theoretically possible for current rates of progress to continue for a long time.
- ^
This obviously depends on the total amount of computation a brain actually needs (i.e. where in that 10^12 to 10^28 range the actual number falls), but it’s a bit of an aside to the main point in this section of “superintelligence is physically possible”, so I’ve pushed it down to the footnote.
I personally think human equivalent (per second) computation falls somewhere in the 10^15 to 10^18 based on the number of neurons being around 10^10, the number of synapses per neuron being around 10^3 and the synaptic events happening at around 10^2 Hz, plus a 10^3 fudge factor to cover everything else that might be going on -- such the effect of each synapse on other synapses, rather than just their direct effect on the voltage at the axon hillock.
There are arguments that more detail than this could be needed (such as by tracking membrane potential at all locations, the ion concentrations, concentrations of neurotransmitters, etc), but those seem to be more about simulating complex biology rather than repeating just the relevant computation done by the biology.
However, I still don’t think that this should be a major part of our reasoning. Instead, the main takeaway I have is that the computation available in electronic computers today could be enough to run a brain (i.e. it’s within those massive error bars), and that the physical limits are much higher than what the human brain can do (i.e. those limits are far outside those massive error bars).
I can expand on the above in detail if this turns out to be the sticking point for my timeline difference.
- ^
FLOP means ‘floating point operations’, and FLOP/s means ‘floating point operations per second’, they are both measures of computation. Sometimes elsewhere you will see FLOPS (for per second) and FLOPs (for plural), but I think this is a confusing way to write it.
- ^
By efficiency I mean “for a given amount of compute, how much intelligence do you get?”, which you can measure by any metric you like.
- ^
By this I mean ‘have an idea of how likely or unlikely something is before getting into the specific arguments’. For example, in football, if we know that Liverpool wins 60% of their games against Arsenal, then ‘60%’ is our prior probability of Liverpool winning before we consider things like “this player is sick'' or “that new strategy is being tried”, which use to estimate changes from the ‘60%’ starting point.
- ^
It is notable that a similar survey conducted by the same group one year earlier (in 2022 instead of 2023) got dates significantly further in the future (2061 instead of 2047 as the 50% date). Metaculus’ forecast has also fallen over time, predicting AGI happening nearly 20 years sooner than it did in 2022 -- 2033 instead of 2053.
- ^
- ^
- ^
- ^
By ‘good tools and structures’, I mean things like finding ways to let the LLMs reformat the data and propose and test solutions in a loop, or directly operate on images rather than text, or use another different kind of engine alongside an LLM to rapidly generate and check many proposals. For example, the same problem is a lot easier for humans to solve when you see it presented visually.
- ^
The lack of generalisation could just be related to the stupidity of the current models, rather than being a fundamental limitation of the architecture. I.e. could a LLM with 100x the parameters, text data, and training compute figure out the ARC puzzle without an architecture change? Maybe?
Could a trivial change allow the hypothetical super-LLM to actively learn? Such as by letting it select which data it wants to train on each day, and then fine-tuning on that data each evening? It’s obviously not the most efficient way, I’m just interested in whether ‘learning and generalising’ are beyond the current transformer/LLM architecture in theory, or just in practice.
Nobody disagrees that architecture does matter -- the neocortex is better at generalising than other parts of the brain, transformers are better than SVMs, and so on. Still, it does seem like GPT-4 can generalise better than GPT-3, and like a human can generalise better than a dog, despite each pair having similar (but not identical) architectures. I would be interested in data that measured if this effect is real.
- ^
I mean this in the sense of overfitting to a small number of data points. I suspect that if we keep moving towards native multimodal models, they will find simpler and more generalisable world models (that solve problems like ARC) which are very difficult to find in text-only training (because they might rely on intuitions from physics, for example).
There’s a story from Helen Keller, the deaf-blind woman, grokking language for the first time. She knew finger signs and how to spell words, and she knew that there were real things out there in the world, but she only managed to bring those two concepts together after working at it:
“I did not know that I was spelling a word or even that words existed; I was simply making my fingers go in monkey-like imitation. In the days that followed I learned to spell in this uncomprehending way a great many words, among them pin, hat, cup and a few verbs like sit, stand and walk. But my teacher had been with me several weeks before I understood that everything has a name.”
I suspect that LLMs are like this, and that with enough information from enough different modalities (and with the right architecture and training) they will soon “intuitively” understand that the water in the picture is the same as the word “water”, which is related to the sounds of the waves, and so on. They haven’t had the opportunity to learn these concepts yet, and so can’t bridge gaps the way ARC requires.
- ^
["output": [[3, 2, 3, 2, 3, 2], [7, 8, 7, 8, 7, 8], [2, 3, 2, 3, 2, 3], [8, 7, 8, 7, 8, 7], [3, 2, 3, 2, 3, 2], [7, 8, 7, 8, 7, 8]] -- the problem is “00576224” in the evaluation set.
- ^
I give this about a 70% chance for a frontier model of any kind, whether or not it’s called an LLM. I don’t mean the “ARC challenge”, which requires an open source model -- I mean any frontier model. If two years after that (end of 2027) we still haven’t reached >85% performance, I will be very surprised, and will update towards ‘AGI requires very different methods’.
- ^
Here I am referring to the top model in 2026, not ‘GPT-5’, since the ‘GPT-5’ name might be given to a model released even sooner, or another company might release a more capable model.
- ^
Benchmark Top Model
(June 2024)
Link Real Performance (June 2024) Forecast Performance for June 2024 (From June 2021) MATH GPT-4T (w/structure) https://paperswithcode.com/sota/math-word-problem-solving-on-math 87.92% 32% MMLU Gemini Ultra https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu 90.00% 68% CIFAR-10 WideResNet-70-16 https://robustbench.github.io/?ref=bounded-regret.ghost.io#div_cifar10_Linf_heading 73.71% 81% Something Something V2 InternVideo2-6B https://paperswithcode.com/sota/action-recognition-in-videos-on-something?ref=bounded-regret.ghost.io 77.5% 83% - ^
It is interesting that LLMs did so much better than predicted, whereas video and images models have under performed.
If I think about this for a second, I think that adversarial attacks are just really hard to solve for -- humans arguably suffer adversarial attacks too in the form of optical illusions. For any particular fit, there will be examples which break the model, and if we are deliberately trying to find those examples then making the model better in all real-world use cases will not do much to change this.
The Something Something video recognition dataset inputs short clips and asks the models to classify what actions are being taken. I wonder why the performance was lower than predicted? Part of it may be that in 2021 the focus in AI was more on image and video classification AI, and then it shifted to LLMs in 2022. Does this mean that video-based-AI got fewer resources than expected?
Or perhaps it's just an artefact. We have pretty good video reasoning results from Figure, Tesla, and Meta, and we can see that video generation models like Sora understand the world enough to go the other way (i.e. you input the text, and the model outputs a video). These just aren’t really set up to test on this specific benchmark -- could that be a factor in the lower-than-expected results here?
Regardless, my guess would be that the next generation frontier models, if they have video-native input, would be able to do very well here -- I predict the 2025 forecast will be beaten if the benchmark is run on multimodal LLMs in 2025. It should also be noted that the current top performing model on Something Something V2 only has 6B parameters (compared with 100s of billions for the top LLMs).
- ^
A prediction market for “Will an AI get gold on any International Math Olympiad by the end of 2025?” had a big spike when this result was released on July 21, from a 25% chance to a 75% chance.
- ^
I am moving this to a footnote, because the argument for using an Evolution Anchor does not make sense to me, and I’m worried I’m missing something. As far as I know, it goes like this:
‘Evolution did 10^26 to 10^52 [35] FLOP across all neurons in all brains in all of evolution, and this selected for both the algorithm and hyperparameters (encoded in the human genome). It is sometimes argued that we should therefore expect a similar amount of computation to be required to build an AGI.’
I don’t understand this argument. The conclusion doesn’t follow from the premise. It’s like claiming “There were 10^n generations of flying creatures in evolutionary history, so we should expect to need to do 10^n iterations on our flying machine before we get something as fast as a Peregrine Falcon”.
The process of evolution and the process of engineering by humans is just so radically different we can’t infer much from one to the other. If this is an unfair criticism, or a strawman, please tell me!
A weaker claim related to brain optimisation does make a bit more sense to me -- this one would go something like “Human brains are optimised by evolution to learn from few examples in the domains that matter to humans. We should not expect AGI to be as sample efficient as this with only the same amount of training as a human has during its childhood, since that skips the “training” done throughout evolution”.
I initially thought I agreed with this, but thinking it through again, I realise it has the same problems:
A: Why shouldn’t we expect AGI to be that sample efficient?
B: Because humans were optimised for a long time by evolution.
A: Why couldn’t we develop a similarly effective architecture intelligently?
B: We could, but we should expect it to be hard.
A: Why would ‘hard’ be related to ‘Evolutionary Anchor’ at all?
B: Because humans are our proof of viability, and that’s how evolution did it.
A: The same way birds were our proof of viability for flight, and we overtook birds on ‘flight speed’ without the ‘Evolutionary Anchor’ applying there.
B: Regardless, you will still need more optimisation than what is done in one human-childhood.
A: Yes, but that optimisation (e.g. finding the architecture) will be done intelligently by the engineers building the AGI, not by anything like evolution.
I really don’t think it is practical to put this ‘human engineering effort’ into units of compute. Hypothetically, you could imagine one genius looking at current AI and saying “Oh, this, this, and this need to change”, and making an improvement that would have taken 10 million generations for evolution to reach through naive hill climbing.
- ^
Four years of this difference (2036 vs 2040) might be a change in the definition of ‘Transformative AI’. She gives a median date of 2040 here [AF · GW], which was recorded about a year sooner than the 2036 date she gives in the linked interview [AF · GW]. It’s not clear which, if either, is her current best guess.
- ^
Like getting the models to give the ‘correct’ answer, rather than the ‘most likely one.
- ^
Suppose we succeed in building an agent that is *very good* at achieving its goals. For any given goal, you’ll probably be able to achieve it better if you are smarter, and if you have more resources, and if you aren’t turned off, and if your human handlers don’t try to interfere with your work...
Are you evil? Do you have innate self-preservation? No! You are just very good at achieving your goals, and the best way to achieve your goals usually involves maximising your own power. In a nutshell, this is why superintelligent AI is an extinction risk [LW · GW].
We also already know that we can develop misaligned goal seeking AIs (reward misspecification is a very common problem in RL, and gets more common as agents become more capable).
- ^
Post training is the big one today. You start with a base LLM trained on next token prediction. This produces a model with lots of latent knowledge, but which is very ineffective at using it. Then, you finetune it to prefer outputs that are actually useful for some goal. RLHF is the central example of this -- it works by building a reward model that predicts whether human raters will like or dislike the model's output, and then optimises the model to prefer outputs that human raters will like.
It seems feasible to me that techniques like this could lead to models that operate more like RL agents on longer timescales, but with all of the world knowledge of LLMs.
‘Unhobbling’ structures have also had a big impact on the current AI boom. These include basic things like prompting the model better with techniques like ‘chain of thought’, as well as giving the models tools like scratch pads, a code interpreter, and the internet. Usually this goes hand in hand with post-training the model to effectively use these tools.
These sorts of structures could, at the limit, work around issues like memory -- suppose a hypothetical future LLM had an enormous context window and it had the ability to write out whatever it wanted into a database that is completely loaded into its context window. If the LLM is smart enough to use this effectively, does human memory do anything that this hypothetical system doesn’t?
- ^
Simulated environments optimised for training an AI to learn many different behaviours, similar to the 2019 work from OpenAI on multi-agent environments.
- ^
Search & planning could involve a fundamental architecture change which somehow lets the model ‘loop’ thoughts internally, similar to how humans do, or it could be something more akin to a structure built around the model which lets it generate and then assess many different plans in parallel before selecting one -- like a human writing a decision tree on paper, but at a much larger scale.
- ^
On the ‘active learning’ idea -- at the simplest end, this could be simply be something like:
- Let the model run for a day, with many copies in parallel.
- Let the model or another system assess whether the outputs were good or bad (i.e. did the code run? Did the user react as expected? Did the text contradict itself? Do the thoughts hold up under reflection? Or under real-world experimentation / research?)
- Use this assessment as part of a loss function, and then update the model's parameters based on the days’ loss.
- ^
This is not a serious proposal. Don’t mistake it for a serious proposal! I’m just trying to sketch out that the basic ideas for how to build an AGI might already be here -- as in, we can break it into practical questions like “How can we gather that much data?” “How can we build a RL curriculum for an agent which starts with an existing world model?” and so on, which will probably be useful regardless of the specific architecture that is actually used. Compare this to merely having a 2010-level “I don’t know how to make progress on this problem at all.”
- ^
Suppose we succeed in building an agent that is *very good* at achieving its goals. For any given goal, you’ll probably be able to achieve it better if you are smarter, and if you have more resources, and if you aren’t turned off, and if your human handlers don’t try to interfere with your work...
Are you evil? Do you have innate self-preservation? No! You are just very good at achieving your goals, and the best way to achieve your goals usually involves maximising your own power. In a nutshell, this is why superintelligent AI is an extinction risk [LW · GW].
We also already know that we can develop misaligned goal seeking AIs (reward misspecification is a very common problem in RL, and gets more common as agents become more capable).
- ^
Yes, this is the footnote of a footnote. Ajeya Cotra’s report is here, and includes a ~26 OOM (~10^26 to ~10^52) range for an ‘Evolution Anchor’, which is an estimate of the total computation done over the course of evolution from the first animals with neurons to humans.
Some argue that using this range as a basis for estimating the amount of compute used by evolution is a large underestimate [EA · GW], because there was computation done external to the neurons by the environment.
I think you could also argue it’s a massive overestimate -- that the selection for intelligence in each generation is not equal to the sum of all computation done by the neurons in the animals themselves, and instead is closer to a small number of suboptimal updates per generation, at least for the purpose of simulating it.
Even if we do say it is equal to all compute used by all the brains of all the animals, a hypothetical evolutionary process (set up by intelligent beings deliberately selecting for intelligence) could shave something like 5-10 OOMs off the total computation. Suppose we imagine an optimised version of evolution where each generation we select for the creatures which did the best on a series of increasingly difficult cognitive tests, in shorter and shorter times after birth, and had a small population with many serial iterations.
Back of the envelope, this could:
- Reduce population size by 10^2 to 10^5
- Reduce average generation time by 10^1 to 10^2
- Increase selective pressure for intelligence by 10^2 to 10^4
And thus reduce total computation by 10^5 to 10^10, hypothetically.

3 comments
Comments sorted by top scores.
comment by Tomás B. (Bjartur Tómas) · 2024-08-13T15:59:02.921Z · LW(p) · GW(p)
One thing to note about RSI, we know mindless processes like gradient descent and evolution can improve performance of a model/organism enormously despite their stupidity. And so it's not clear to me that the RSI loop has to be very smart or reliable to start making fast progress. We are approaching a point where the crystallized intelligence and programming and mathematics ability of existing models strike me as being very close to being in extremely dangerous territory. And though reliability probably needs to improve before doom - perhaps not as much as one would think.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-08-13T16:17:36.720Z · LW(p) · GW(p)
I'm very much in agreement with you overall. I personally expect that the strongest general models of 2026 will be clearly capable of recursive improvement via both ML research and scaffolding development.
I do think that this particular point you make needs adjusting:
We can also check predictions made about AI from three years ago to see if we’ve overshot or undershot expectations. In 2021, Jacob Steinhardt’s group (who also developed some of the benchmarks used) commissioned a forecast which included SOTA estimates on AI in 2024.
I'm not doing great at understanding the viewpoint of the AI-fizzle crowd, but I think it would be more fair to them to analyze these forecasts in terms of expected-improvement-per-dollar versus actual-improvement-per-dollar. My guess is that 2021 forecasts anticipated less money invested, and that one could argue that per-dollar gains have been lower than expected.
I don't think this fundamentally changes anything overall, I'm just trying to steelman.
Replies from: HunterJay↑ comment by HunterJay · 2024-08-14T00:56:05.498Z · LW(p) · GW(p)
You might be right -- and whether the per-dollar gains were higher or lower than expected would be interesting to know -- but I just don't have any good information on this! If I'd thought of the possibility, I would have added it in Footnote 23 as another speculation, but I don't think what I said is misleading or wrong.
For what it's worth, in a one year review from Jacob Steinhardt, increased investment isn't mentioned as an explanation for why the forecasts undershot.