Embedded Naive Bayes
post by johnswentworth · 2019-08-22T21:40:05.972Z · LW · GW · 6 commentsContents
The Embedded Naive Bayes Equation None 6 comments
Suppose we have a bunch of earthquake sensors spread over an area. They are not perfectly reliable (in terms of either false positives or false negatives), but some are more reliable than others. How can we aggregate the sensor data to detect earthquakes?
A “naive” seismologist without any statistics background might try assigning different numerical scores to each sensor, roughly indicating how reliable their positive and negative results are, just based on the seismologist’s intuition. Sensor i gets a score when it’s going off, and when it’s not. Then, the seismologist can add up the scores for all sensors going off at a given time, plus the scores for sensors not going off, to get an aggregate “earthquake score”. Assuming the seismologist has decent intuitions for the sensors, this will probably work just fine.
It turns out that this procedure is equivalent to a Naive Bayes model.
Naive Bayes is a causal model [LW · GW] in which there is some parameter in the environment which we want to know about - i.e. whether or not there’s an earthquake happening. We can’t observe directly, but we can measure it indirectly via some data - i.e. outputs from the earthquake sensors. The measurements may not be perfectly accurate, but their failures are at least independent - one sensor isn’t any more or less likely to be wrong when another sensor is wrong.
We can represent this picture with a causal diagram:
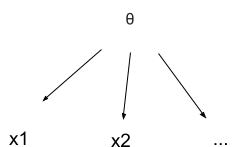
From the diagram, we can read off the model’s equation: . We’re interested mainly in the posterior probability or, in log odds form,
Stare at that equation, and it’s not hard to see how the seismologist’s procedure turns into a Naive Bayes model: the seismologist’s intuitive scores for each sensor correspond to the “evidence” from the sensor . The “earthquake score” then corresponds to the posterior log odds of an earthquake. The seismologist has unwittingly adopted a statistical model. Note that this is still true regardless of whether the scores used are well-calibrated or whether the assumptions of the model hold - the seismologist is implicitly using this model, and whether the model is correct is an entirely separate question.
The Embedded Naive Bayes Equation
Let’s formalize this a bit.
We have some system which takes in data , computes some stuff, and spits out some . We want to know whether a Naive Bayes model is embedded in . Conceptually, we imagine that parameterizes a probability distribution over some unobserved parameter - we’ll write , where the “;” is read as “parameterized by”. For instance, we could imagine a normal distribution over , in which case might be the mean and variance (or any encoding thereof) computed from our input data. In our earthquake example, is a binary variable, so is just some encoding of the probability that .
Now let’s write the actual equation defining an embedded Naive Bayes model. We assert that is the same as under the model, i.e.
We can transform to log odds form to get rid of the Z:
Let’s pause for a moment and go through that equation. We know the function , and we want the equation to hold for all values of . is some hypothetical thing out in the environment - we don’t know what it corresponds to, we just hypothesize that the system is modelling something it can’t directly observe. As with , we want the equation to hold for all values of . The unknowns in the equation are the probability functions , and . To make it clear what’s going on, let’s remove the probability notation for a moment, and just use functions and , with written as a subscript:
This is a functional equation: for each value of , we want to find functions , , and a constant such that the equation holds for all possible values. The solutions and can then be decoded to give our probability functions and , while can be decoded to give our prior . Each possible -value corresponds to a different set of solutions , , .
This particular functional equation is a variant of Pexider’s equation; you can read all about it in Aczel’s Functional Equations and Their Applications, chapter 3. For our purposes, the most important point is: depending on the function , the equation may or may not have a solution. In other words, there is a meaningful sense in which some functions do embed a Naive Bayes model, and others do not. Our seismologist’s procedure does embed a Naive Bayes model: let be the identity function, be zero, and , and we have a solution to the embedding equation with given by our seismologist’s add-all-the-scores calculation (although this is not the only solution). On the other hand, a procedure computing for real-valued inputs , , would not embed a Naive Bayes model: with this , the embedding equation would not have any solutions.
6 comments
Comments sorted by top scores.
comment by Vanessa Kosoy (vanessa-kosoy) · 2019-08-24T16:25:42.160Z · LW(p) · GW(p)
This seems interesting, but I think there are some assumptions that have been left out? What prevents us from taking and to be constants, which would give solutions for any ?
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-24T20:47:13.128Z · LW(p) · GW(p)
I am indeed leaving out some assumptions, mainly because I am not yet convinced of which assumptions are "right". The simplest assumption - used by Aczel - is that and are monotonic. But that's usually chosen more for mathematical convenience than for any principled reason, as far as I can tell. We certainly want some assumptions which rule out the trivial solution, but I'm not sure what they should be.
comment by Rohin Shah (rohinmshah) · 2019-08-24T19:34:58.177Z · LW(p) · GW(p)
What do you mean by embedded here? It seems you are asking the question "does a particular input-output behavior / computation correspond to some Naive Bayes model", which is not what I would intuitively think of as "embedded Naive Bayes".
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-24T20:57:57.298Z · LW(p) · GW(p)
Here's the use case I have in mind. We have some neural network or biological cell or something performing computation. It's been optimized via gradient descent/evolution, and we have some outside-view arguments saying that optimal reasoning should approximate Bayesian inference. We also know that the "true" behavior of the environment is causal - so optimal reasoning for our system should approximate Bayesian reasoning on some causal model of the environment.
The problem, then, is to go check whether the system actually is approximating Bayesian reasoning over some causal model, and what that causal model is. In other words, we want to check whether the system has a particular causal model (e.g. a Naive Bayes model) of its input data embedded within it.
What do you imagine "embedded" to mean?
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2019-08-24T21:26:41.519Z · LW(p) · GW(p)
I usually imagine the problems of embedded agency [? · GW] (at least when I'm reading LW/AF), where the central issue is that the agent is a part of its environment (in contrast to the Cartesian model, where there is a clear, bright line dividing the agent and the environment). Afaict, "embedded Naive Bayes" is something that makes sense in a Cartesian model, which I wasn't expecting.
It's not that big a deal, but if you want to avoid that confusion, you might want to change the word "embedded". I kind of want to say "The Intentional Stance towards Naive Bayes", but that's not right either.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-08-24T22:12:07.572Z · LW(p) · GW(p)
Ok, that's what I was figuring. My general position is that the problems of agents embedded in their environment reduce to problems of abstraction, i.e. world-models embedded in computations which do not themselves obviously resemble world-models. At some point I'll probably write that up in more detail, although the argument remains informal for now.
The immediately important point is that, while the OP makes sense in a Cartesian model, it also makes sense without a Cartesian model. We can just have some big computation, and pick a little chunk of it at random, and say "does this part here embed a Naive Bayes model?" In other words, it's the sort of thing you could use to detect agenty subsystems, without having a Cartesian boundary drawn in advance.