AI #48: The Talk of Davos
post by Zvi · 2024-01-25T16:20:26.625Z · LW · GW · 9 commentsContents
Table of Contents Language Models Offer Mundane Utility Language Models Don’t Offer Mundane Utility Copyright Confrontation Fun with Image Generation Deepfaketown and Botpocalypse Soon They Took Our Jobs Get Involved In Other AI News Quiet Speculations Intelligence Squared The Quest for Sane Regulations (3) Artificial intelligence Open Model Weights Are Unsafe And Nothing Can Fix This The Week in Audio Rhetorical Innovation Malaria Accelerationism Aligning a Smarter Than Human Intelligence is Difficult Other People Are Not As Worried About AI Killing Everyone The Lighter Side None 9 comments
While I was in San Francisco, the big head honchos headed for Davos, where AI was the talk of the town. As well it should be, given what will be coming soon. It did not seem like anyone involved much noticed or cared about the existential concerns. That is consistent with the spirit of Davos, which has been not noticing or caring about things that don’t directly impact your business or vibe since (checks notes by which I mean an LLM) 1971. It is what it is.
Otherwise we got a relatively quiet week. For once the scheduling worked out and I avoided the Matt Levine curse. I’m happy for the lull to continue so I can pay down more debt and focus on long term projects and oh yeah also keep us all farther away from potential imminent death.
Table of Contents
- Introduction.
- Table of Contents.
- Language Models Offer Mundane Utility. Might not come cheap.
- Language Models Don’t Offer Mundane Utility. The ancient art of walking.
- Copyright Confrontation. It knows things, but it still cannot drink.
- Fun With Image Generation. Poisoning portraits in the park.
- Deepfaketown and Botpocalypse Soon. Use if and only if lonely.
- They Took Our Jobs. The one saying it won’t happen interrupted by one doing it.
- Get Involved. New jobs, potential unconference.
- In Other AI News. Various people are doing it, for various values of it.
- Quiet Speculations. How fast is efficiency improving?
- Intelligence Squared. Why so much denial that importantly smarter is possible?
- The Quest for Sane Regulation. New polls, new bad bills, EU AI Act full text.
- Open Model Weights Are Unsafe and Nothing Can Fix This. More chips, then.
- The Week in Audio. Nadella, Altman and more.
- Rhetorical Innovation. Are you for or against the existence of humanity?
- Malaria Accelerationism. All technology is good, you see, well, except this one.
- Aligning a Smarter Than Human Intelligence is Difficult. Diversification needed.
- Other People Are Not As Worried About AI Killing Everyone. Anton and Tyler.
- The Lighter Side. No spoilers.
Language Models Offer Mundane Utility
Say you can help people respond to texts on dating apps via a wrapper, charge them $28/month, claim you are making millions, then try to sell the business for $3.5 million. Why so much? Classic black market situation. The readily available services won’t make it easy on you, no one reputable wants to be seen doing it, so it falls on people like this one.
There is a strange response that ‘profits are razor thin.’ That cannot possibly be true of the engineering costs. It can only be true of the marketing costs. If you are getting customers via running mobile ads or other similar methods, it makes sense that the effective margins could be trouble. And of course, when marginal cost of production is close to zero, if there are many entrants then price will plunge. But a lot of customers won’t know about the competition, or they will know your works and be willing to pay, so a few gouged customers could be the way to go.
OpenAI announces partnership with Premiere Party School Arizona State University. Everyone gets full ChatGPT access. Students get personalized AI tutors, AI avatars, AIs for various topics especially STEM. Presumably this helps them learn and also gives them more time for the parties.
Chrome feature to automatically organize tab groups. Also they’ll let you create a theme via generative AI, I guess.
GitLab’s code assistant is using Claude. No idea if it is any good.
Ethan Mollick: Having just taught initial AI stuff to 250+ undergrads & grad students in multiple classes today:
-AI use approached 100%. Many used it as a tutor. The vast majority used AI on assignments at least once
-Knowledge about AI was mostly based on rumors
-Prompting knowledge was low
Prompting knowledge seems very low across the board. A lot of that is that prompting is work, it is annoying, and people in practice won’t do it. I notice myself largely not doing it. I mean, I do the basics, but nothing like what would get optimal results, because most of the time I don’t need optimal results.
Don’t explain the joke, get an AI to explain the joke.
Who needs AI? Tell people AI is involved, and their performance (at a letter discrimination task and a Bayesian analysis task) improves. The proposed explanation for this placebo effect is higher confidence. Adjustment of what seems possible and raising of standards also seem plausible.
Language Models Don’t Offer Mundane Utility
Berkeley AI researchers show off their humanoid robot and its brilliant ability to navigate highly flat, well paved surfaces in various locations.
Aidan Gomez says lacking an inner monologue is a big issue for LLMs, suggests trying to teach it to have one via a cultivated data set of examples for supervised learning rather than using chain of thought.
Copyright Confrontation
AI Snake Oil gives further thoughts on the NY Times lawsuit against OpenAI. As they note, the Times is not hurt primarily by outputs replicating entire articles verbatim. ChatGPT makes that annoying enough to do that there are better ways to accomplish bypassing the paywall, so almost no one does that except to prove a point.
Their argument instead is that it is more like queries like ‘Who are Clearview AI’s investors?’ the answer to which comes from a 2020 NY Times investigation. But how does that harm NY Times? All of us are constantly doing exactly this, drawing on knowledge that others originally uncovered. Nor does this lose the Times revenue.
Even if NY Times content could not be used for training data, no doubt this information has been remixed countless times elsewhere, and would get into the model anyway. I would hope we are not going to say that it is on OpenAI to remove any knowledge whose initial public sourcing was NY Times?
The actual argument seems to be that Generative AI provides knowledge, and the Times provides knowledge and can’t stand the competition.
They agree that copyright law does not forbid this even for an AI, and thus conclude that existing law is a poor fit.
Fun with Image Generation
Nightshade is a new tool for poisoning images to distort any model that trains on them. Eliezer suggests this may help teach security mindset. I wonder how many people will actively try things like this.
Deepfaketown and Botpocalypse Soon
Robocalls in New Hampshire used an AI voice imitating Joe Biden to discourage Democrats from voting. In context this is harmless, and shows how profoundly uncreative such efforts tend to be, but such calls right before the general election would be less harmless.
Kanye West offers AI-generated music video. How will fans react? Everything involved here seems… not good, but my opinion is not strong evidence here.
Study of Replika users finds they more often report that it helped rather than hurt them in terms of other social interactions. Given this is a self-reporting observational study, it is not strong evidence on that. What we need is an actual RCT. Outcomes also likely depend greatly on details. The finding that we can trust is that 90% of users were initially quite lonely. The optimistic view is that this is a way to break out of a bad place, rather than a permanent substitute. I continue to be optimistic.
Part of a common pattern:
Daniel Jeffries: Mandating watermarking of AI text is a magical thinking solution to a non-existent problem that will not work in reality. OpenAI gave up on theirs because it had 26% accuracy. How good do you think your watermarking tech will be if the best OpenAI could come up with was 26%?
Yann LeCun: It makes sense to cryptographically watermark *authentic* photos and videos.
But camera manufacturers, image processing software vendors, and distribution platforms have to agree on a standard.
Watermarking AI-generated or heavily manipulated content may have some usefulness, but there is an incentive to remove the watermark.
Eliezer Yudkowsky: Makes sense, so long as somebody actually goes and does it.
The pattern here is:
- AI creates a practical problem.
- AI can’t (for now) technologically addressing the issue, for technical reasons.
- Those who want uncontrolled AI development say that since AI solutions don’t work, the burden is on everyone else to find a technical solution instead.
Yann says, well, it would be terrible to subject AI models to standard regulation, certainly they can’t be expected to get together and agree to standards on their own, that would be crazy and also not doing that is good actually. So the burden of dealing with fake photos should fall on those making real photos, who need to together adapt their technologies and standards to solve the problem.
There are precedents for exactly this, such as defending the currency against counterfeiting, or banks against wire fraud. So this could well be the practical solution. But also note what the law has to say about such other cases.
They Took Our Jobs
AI Snake Oil asks how and whether Generative AI will transform law, covering a paper on this. They are skeptical that there will be big impacts, or that AI can do the most valuable tasks, even if regulations do not interfere. I find this position baffling, especially if they expect to sustain it over time. So much of what lawyers do is highly generic, and the tools are rapidly improving.
For example, here’s Anthropic linking to how RobinAI is claiming it is making it ten times faster to sign legal documents (claim, is that prior standard was an average of 60 days), by allowing you to get quick turnarounds on document analysis so the two sides can hammer out details. No, the AI can’t take over entirely, but it seems credible that this could massively accelerate such work.
Get Involved
Holden Karnofsky comes out of blog semi-retirement to highlight several current opportunities.
Not AI, but self-recommending: Conversations with Tyler in-person event February 5 in NYC.
AISI (formerly the UK’s Taskforce on Frontier AI) is hiring post-doc or higher level people for foundational AI safety research.
Beneficial AGI Summit & Unconference, February 27 to March 1 in Panama City. A lot of the intended framings do not inspire confidence, but talking about it how people can make progress.
In Other AI News
OpenAI declines to provide its governing documents to Wired, contradicting a prior promise that its governing documents would be public.
Nature article covers the Sleeper Agents paper.
Forbes reports that billionaire and former Google CEO Eric Schmidt is building a startup for an AI powered mass-produced combat drone named ‘White Stork.’
MultiOn_AI, which Div Garg claims has solved the problems plaguing AI agents, now able to do 500+ steps and cross-operate on 10+ websites. As they say, huge if true, no idea if true.
Altman says he isn’t sure what Ilya Sutskever’s exact employment status is. I feel like if I was CEO of OpenAI then I would know this.
The importance of centering reward distributions around zero. Often systems, either for AIs or for humans, make the ideal reward zero and then punish deviations from that optima. That is a serious mistake, for both AIs and humans. When you do this, you get mode collapse, since doing anything else can only lose you points. Also some other interesting technical statements at the link.
Go players are steadily getting stronger in the wake of AlphaGo and subsequent open source versions, both studying the AI and using the inspiration to innovate.
Also there’s this:
Chinese Premier Li Qiang called AI “a double-edged sword.”
“Human beings must control the machines instead of having the machines control us,” he said in a speech Tuesday.
“AI must be guided in a direction that is conducive to the progress of humanity, so there should be a redline in AI development — a red line that must not be crossed,” Li said, without elaborating.
China, one of the world’s centers of AI development, wants to “step up communication and cooperation with all parties” on improving global AI governance, Li said.
Once again, if you want to cooperate with China on this, all you have to do is pick up the phone. I am not saying they will ultimately be willing to make a deal we can live with, but the ball is clearly in our court and we are the ones dropping it.
Another note from that AP article:
A survey of 4,700 CEOs in more than 100 countries by PwC, released at the start of the Davos meetings, said 14% think they’ll have to lay off staff because of the rise of generative AI.
Altman is indeed seeking billions to build AI chip factories globally to target future shortages and ensure OpenAI gets its chips. Well then.
Musk raising money for Grok, reportedly has already raised $500 million aiming for a valuation of at least $15 billion. That seems… very high.
Databricks state of AI data report. Seemed strangely out of date?
Quiet Speculations
Analysis claiming two orders of magnitude (OOM) training efficiency gains [LW · GW] since the training of GPT-3, and expecting trend to continue, for example suggesting an expectation of 0.6 OOMs of efficiency gain per year going forward. Huge if true and sustained, of course, since this then combines with scaling up hardware, compute and (both quality and quantity of) data used. If this is sustained indefinitely, then compute thresholds rapidly either get lowered or become ineffective, if the goal is to prevent capabilities crossing a critical threshold rather than caring about relative capabilities.
I notice I am skeptical that we are seeing so many different OOM-level improvements compounding at the same time, while GPT-4 continues to be our best public model despite being essentially two years old.
Or, alternatively, if we have seen this many OOM improvements and only now is even Google likely matching performance, with lots of attempts continuously landing at 3.5-level, then perhaps various other things are more becoming limiting factors?
Ethan Mollick examines the lazy tyranny of the wait calculation. If AI is going to advance rapidly, when is it better to wait and do or build things later? Altman has warned that GPT-5 will work much better, so you shouldn’t build things to ‘fix flaws’ in GPT-4 expecting that to stay useful for long, instead build assuming the base model is way better.
I say, build now anyway. Do now anyway. In my experience, it is by building and doing now, when the tools are not quite there, that you are ready to build and do first and better when the tools finally arrive. Not all the work I did with Magic strategies that were clearly ‘not there yet’ until new cards were available ended up paying off, but a lot of it did. Similarly, when you work with an early stupid AI and learn how to fix its issues, this seems like a useful way to be better prepared to understand and best use a future smarter AI, even if a lot of the specific things you do get thrown away.
Often you build a business (that, as Paul Graham might say, won’t scale) early on, learn what you are doing and what the market wants, then replace it later anyway. Doing that with GPT-4-based wrappers, then replacing later, is no different.
If your business plan relies on a core incompetency persisting, of course, that’s bad. Similarly, if all you care about is getting a particular set of work done and it will be so slow that AI will advance faster than the work, and you don’t otherwise learn or profit by doing, that is also different.
What is the most successful AI (not only LLM) agent?
Michael Tiffany: The most successful AI Agent software in the world is Google Maps. “Bah!” you say? “That’s not an agent at all!”? Listen: understanding how and when it’s an agent, and why it’s so successful, is key to making more useful general-purpose AI agents.
And this understanding is key to avoiding the antipattern I’m now seeing daily among early LLM-based agents.
“When is Google Maps an AI Agent?”
When it’s giving you turn-by-turn navigation directions.
“Wait, what? I’m the one doing the driving.”
Yes, you are. What makes it an agent, what makes this software so much different than non-agentic software like Twitter or Adobe Photoshop, is who makes the How decisions.
Like all good agent software, you get turn-by-turn navigation from Google Maps by telling it your goal. The software then tells you How to achieve your goal. You share your goal; it makes the How decisions. That’s an agent.
It’s not fully *autonomous*. When you are using turn-by-turn navigation, you become a cybernetic organism: you have all your ordinary human faculties plus extrasensory perception (about upcoming traffic conditions, for instance) and the guidance of machine intelligence.
Today people are building completely un-useful AI agents by focusing on *autonomy* while missing what makes turn-by-turn navigation so successful: users *trust it* to make How decisions.
The goal people are after is a general purpose agent.
I buy that the short term goal should instead be a specific purpose agent.
Or at least, that should be the goal if what you want are users.
Don’t focus on making it good at anything at all. Ship the actual MVP, which is similar to Maps navigation, an assistant that you tune to be very good at a limited set of actions towards a limited set of goals. An LLM-based agents can rapidly become excellent at this.
Intelligence Squared
How much smarter can things get than human beings? Quite a bit smarter. Humans occupy a narrow range with big differences even within it.
Francois Chollet: My intuition is that the human brain is likely far from the optimality bound (20% of the way there?), but because getting closer to it has decreasing benefits, humans already possess most of the benefits intelligence confers (80%?).
Hence modern technology and our collective ability to solve virtually any problem we put our minds to, by leveraging networked brains and externalized cognitive resources.
The fact that there’s a large difference in (collective) outcomes between great apes and humans despite relatively small (individual) cognitive differences reinforces this hypothesis. A sudden “small delta -> large response” step means you’ve crossed the middle part of the sigmoid.
Needless to say, both the graph and the numbers quoted are for illustration purposes only. None of this can be rigorously quantified. It’s just a schematic mental model.
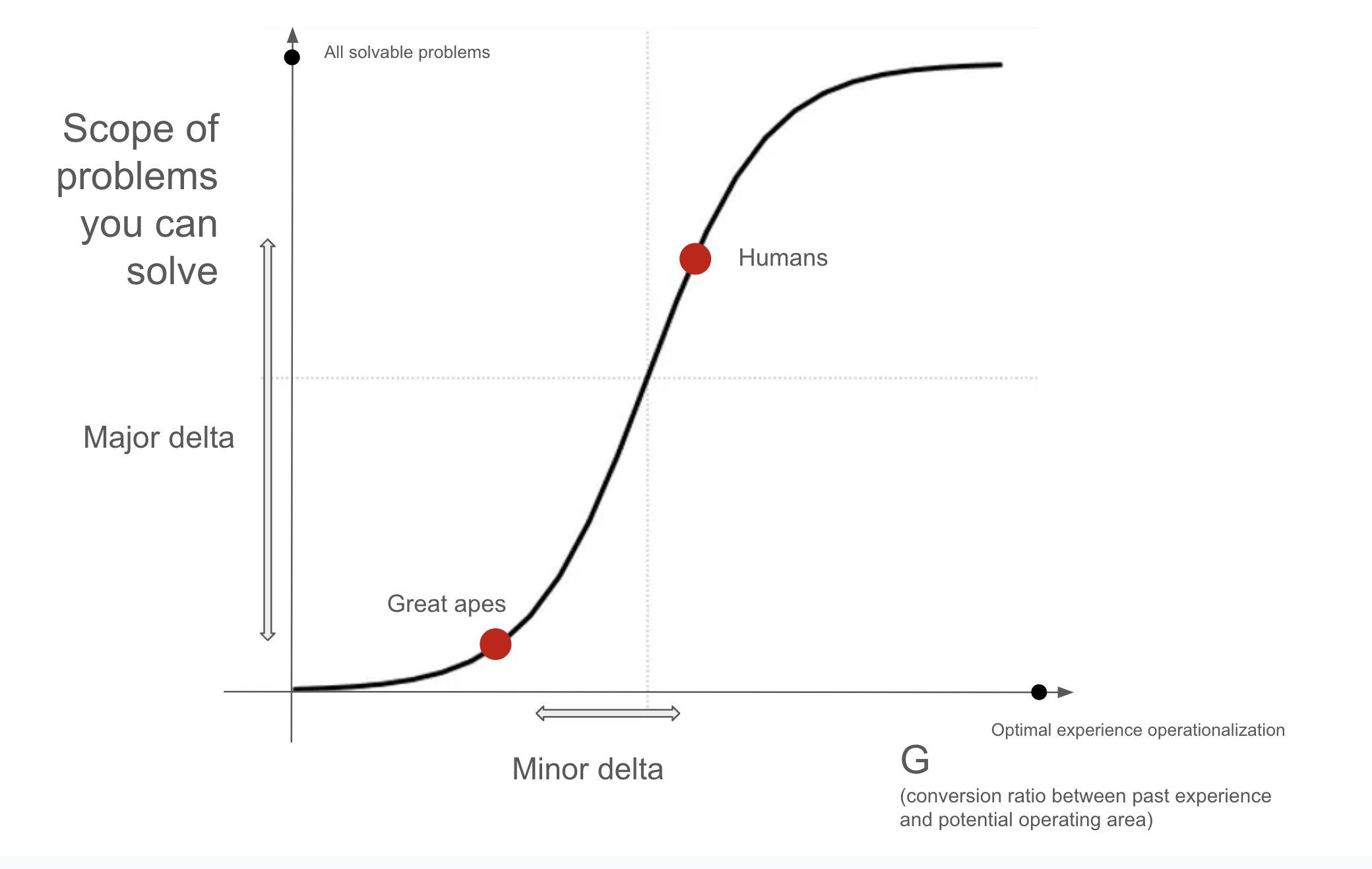
Claiming this is an S-curve, and that humans happen to lie in a close-to-optimal position on it, such that more intelligence won’t much matter, seems like a thing you can only conclude by writing that conclusion at the bottom first and working backwards.
I do not understand why very smart people are almost intelligence deniers. They continuously claim that the smartest humans are not substantially more effective at key tasks, or at many tasks, than other humans, and also that it is not possible to importantly smarter than those smart humans.
This is so obviously, trivially false. Relatively capable humans are different in kind in terms of what they can accomplish, along many axes that AIs will soon exceed humans, including the components of intelligence.
A version of me, with the additional abilities that would be trivial to add if I was a digital intelligence, would be vastly dramatically different in terms of what it could do.
So I notice I am confused.
Eliezer Yudkowsky: Your neurons fire at 100Hz, send signals at 100 m/s along myelinated fibers, dissipate 20W, and can’t multiply 6-digit numbers unaided.
The ultimate thinking artifact permitted by the laws of physics is apparently FIVE TIMES more optimal than that, but has only 25% more benefit.
Yeah, I don’t get it either.
Another attempt was also made, I see what Eliezer is trying to do but I have no idea how to respond to such nonsense:
Francois Chollet: AI isn’t catching up to “us”, because AI makes us smarter. Any externalized cognitive device we invent (calculators, chess engines, LLMs…) becomes a tool for us to use — a part of our “greater brain”.
Eliezer Yudkowsky: Sure could be disastrous if that part didn’t work! And it’s hard to see how we could catch up, if future AIs produce knowledge faster than we can absorb it. So I propose a temporary hold on AI research, to last until AI tools enable humans to read as fast as GPT-4 can write.
I do not get how people can keep claiming ‘AI will always be only a tool’ like this.
Finally he tried out what can be called the Harmless Supernova Fallacy, that there is an upper bound (here on intelligence) therefore it must be a low upper bound.
Here is another form of this kind of intelligence denialism.
Timothy Lee: A lot of confused thinking about AI flows from conceiving as people as computers trapped in the skulls of apes rather than as apes who developed larger brains to help them win status games.
We are both of course but a CEO is about 80 percent dominant ape and 20 percent computer.
Much of a CEO’s time is spent (1) taking meetings with important investors, customers, and policymakers, (2) recruiting new employees, (3) mediating feuds among employees or teams. None of these require, or even particularly benefit, from extraordinary intelligence.
I think a lot of misguided singularist thinking comes from people (like me!) who are not very good at this stuff, are irritated that it gives “suits” so much power and would like AI to make it irrelevant.
I would argue with the ratio, but the exact number does not matter. The the CEO spends a lot of time being a social animal, sure. But again, why would you think that extraordinary intelligence does not matter when taking meetings with investors, customers or policymakers, mediating feuds or especially recruiting new employees?
Of course it matters, and it matters a lot. Both because it helps people develop those skills, and also because it helps adapt on the fly. Yes, people like myself and Timothy prefer to focus on other things and would like such skills to matter less. That does not mean that those skills don’t involve analyzing information, making good decisions and steering towards the best outcomes.
If I had to pick the smartest person I have ever met, there are two plausible candidates. One of them opted out of the dominant ape thing. The other was a wildly successful cofounder and CEO. Did they have the dominant ape thing (and also the ambition thing, and the hard work thing, and so on)? Absolutely, but it was very closely tied to their intelligence on multiple fronts. They would not have had the same success if they were only normal smart.
Yet we constantly hear claims like this.
The Rich: there are more successful people with IQ’s from 120-140 than >140 because there are 25x more people with 120-140 IQs than 140+
Garett Jones: And it helps that the private wage return to IQ is small to modest— 1 IQ point yields maybe 1% higher wages, serious range from 0.5% to 2%. A 40 IQ point gap might mean 50% higher wages, could be more or less than that. Great, but not Great Gatsby income differences.
Zvi: Do you believe this is still true at the double-extreme (e.g. the chance of extreme outlier smart people earning billions)?
Garret Jones: Yeah. Lotsa non-180+ IQ billionaires would be included in any regression like that.
[And the right functional form looks logarithmic, as so often in econ, depressing any estimated IQ-billionaire effect if it exists] If you’re looking for big IQ effects, look to externalities.]
It strikes me as such a bizarre answer. Yes, those extreme cases are ‘included in the regression.’ That is a statement about the calculation and methodology selected, not about the ground truth of impact of intelligence on earnings. Yes, there are over two thousand billionaires, over a thousand of whom likely earned that money. So a lot of them will not be IQ 180, or even be among the smartest people one has met.
And indeed, most of the billionaires or other highly successful people I have met are not IQ 180. But that is because the base rate of that by definition is 1 in 20.7 million, so there are about 400 of them in the world, of whom I have plausibly met at most two, one of whom is a prominent billionaire.
I happen to have had the opportunity to meet several other billionaires and other wildly successful people over the years. One thing they all have in common? They are all very smart. Never have I walked away from someone who earned nine or more figures in their life and been unimpressed by their intelligence.
If you are one of the fortunate top 400 in the world in intelligence, what is the chance you will become a billionaire, whether or not that was your goal? Of those I polled about a third said it was over 0.1%, the rest said lower. That’s still a very large jump versus the base rate of roughly 1 in 3 million, or 0.0003%, very different from a 100% jump, but not as big as all that.
The two best arguments against a larger increase that I saw were that you are not so likely to have been born in the West so you’d often lack opportunity, and that many such people don’t optimize for this result. Whereas if you were born in the West, and you do optimize for this result, the odds look much better.
Why do we say intelligence ‘doesn’t matter much’ in these situations?
- Partly because no one who isn’t smart gets to these positions.
- Partly because when we say ‘smarts’ we often mean the nerd stuff rather than intelligence, where the CEO chose to ‘study’ the dominant ape thing instead.
- Partly because for related reasons the truly intelligent have the active disadvantage that they hate such activities and avoid them, whereas an AI need not have this issue.
- Partly because at current intelligence levels and human architectures, it is wise to largely fall back upon our instinctive brains and intuitions, whose level of ability is not as correlated with other forms of intelligence.
- Partly because there are other factors that impact ability, that get heavily selected for, and which are easier to notice.
Can the future more intelligent AGI do the CEO’s job? I think it plausibly could even without a proxy if it didn’t squick people out, people would adjust their expectations. Until then, this is definitely a place where a hybrid is very clearly better than a human. As in, the human takes orders via a voice in their ear (or even electrical signals to their muscles at some point?), at a micro level and also a macro level, from the voice in their ear, while playing the ape role. The AI makes all the decisions.
If you have a human CEO actually in charge of your company in an AGI-infused world, I have two words for you: You lose.
The Quest for Sane Regulations
The EU AI Act text is now available, published by Luca Bertuzzzi (direct). It is plausible this is the final text, with an up-or-down vote to follow. It sounds from the initial statement like the act could be a worst case scenario, where open model weights frontier models are exempt from regulations, while attempts to provide mundane utility get the classic EU grounded into dust treatment. France still ‘wants concessions’ and is trying to block the final vote, though, so presumably they didn’t get everything they wanted.
I have learned not to trust people’s descriptions of what such acts say until I have a chance to read them, unless I highly trust a particular secondary source. I tried to read a previous version in depth and it was pure pain. This is important, though, so I will try again when I can get the time and gumption.
Here are reports on further official discussion.
Connor Leahy says in TIME that we should start by banning deepfakes, or at least explicit deepfakes, since everyone agrees deepfakes are bad. If you make a model that can make deepfakes, you should be liable. Then maybe we can work towards a moratorium on frontier model runs.
This vision of banning deepfakes is essentially a ban on open model weights for image models. That is how the technology works. There is no way to create a worthwhile image model that cannot then be modified to create deepfakes. Similarly, any ban on LLMs that can do (bad thing that LLMs at this capability level can do) would be a ban on open model weight LLMs.
This is, of course, because (as the section title says) open model weights are unsafe and nothing can fix this. Thus, you have two choices. You can allow models to be unsafe, which is fine if you are OK with what they can do (an ‘unsafe chair’ is a chair), or you can say models need to be in some ways safe. If your method of technology cannot be done safely, or cannot adhere to the needs of a normal regulatory state? Well, like many before you, there is some bad news.
‘The Supreme Court Has Entered the AI Chat’ says the Washington Post. This seems to entirely consist of justices asking basic questions and then talking briefly about how it could do various good and also bad things. Which is all good to hear, remarkably sane comments by all, but also nothing is happening yet.
Adam Thierer points out a bill introduced in Hawaii, S.2572, “Hawaii Artificial Intelligence Safety and Regulation Act” which doesn’t even spell out anything, and which leads with the actual precautionary principle. As in:
§ -4 Deployment of artificial intelligence products; prior written approval required. No person shall deploy artificial intelligence products in the State without submitting to the office affirmative proof establishing the product’s safety.
Just in case, I looked up what AI means here, they are using the provision in Title 15 United States Code section 9401. Yes, this seems to apply to, for example, Google search:
(3) Artificial intelligence
The term “artificial intelligence” means a machine-based system that can, for a given set of human-defined objectives, make predictions, recommendations or decisions influencing real or virtual environments. Artificial intelligence systems use machine and human-based inputs to-
(A) perceive real and virtual environments;
(B) abstract such perceptions into models through analysis in an automated manner; and
(C) use model inference to formulate options for information or action.
So the Hawaii bill is pretty obviously crazy and unworkable as written.
That is the thing. People introduce stupid bills a lot. There are a lot of state legislators. Many of them do not know how any of this works, do not let that stop them, and there Aint No Rule against introducing a dumb bill.
This is a great opening line, from Politico:
Josh Sisco: The Justice Department and the Federal Trade Commission are deep in discussions over which agency can probe OpenAI, including the ChatGPT creators’ involvement with Microsoft, on antitrust grounds.
Love it. By it I mean the in-fighting. I mean, as an investigation this is pretty dumb. OpenAI has plenty of competition, Microsoft was not otherwise going to be a serious competitor, I do not see issues from integration, what are they even talking about.
AIPI has new polling, Politico reports.
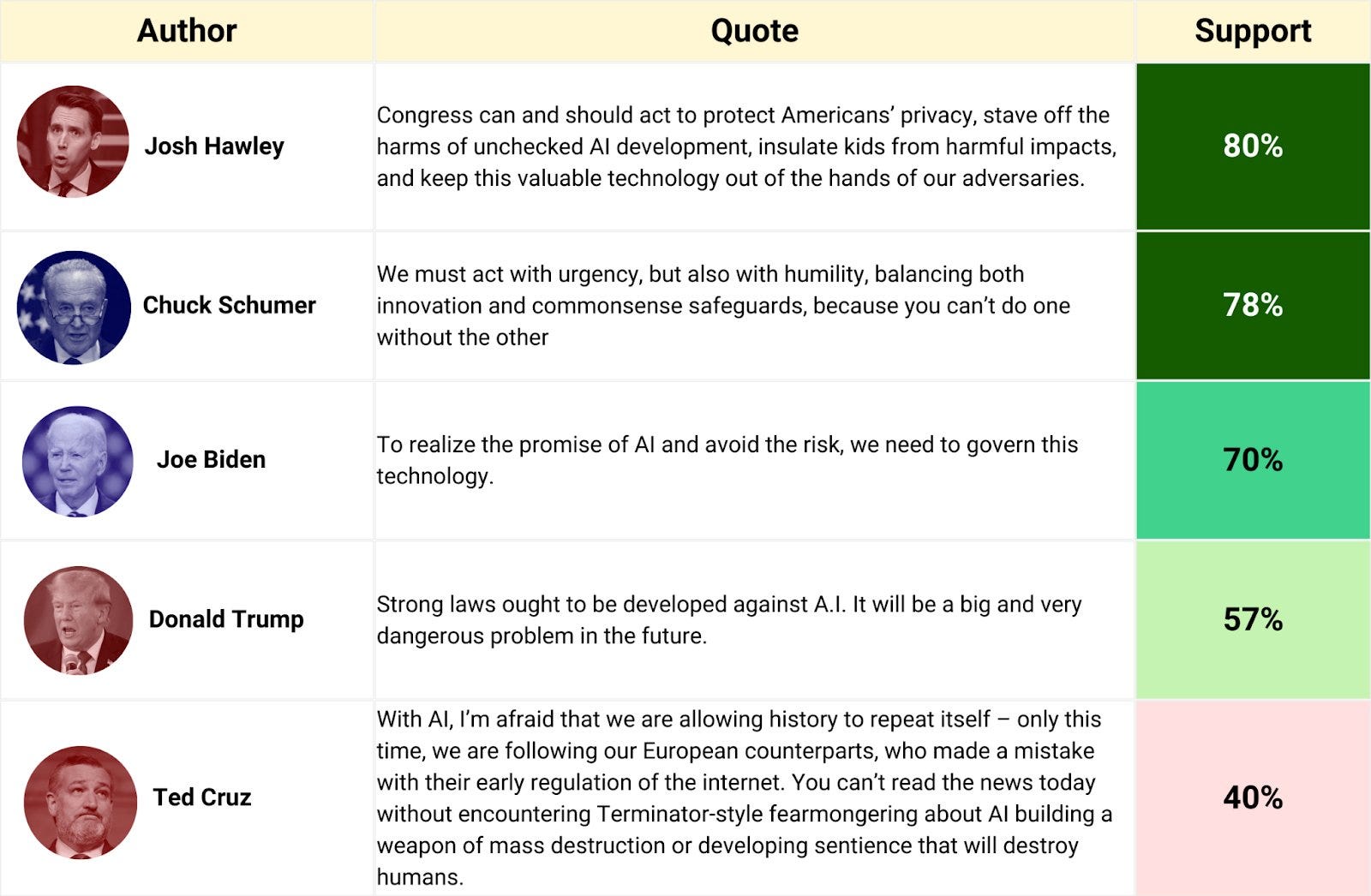
The pattern is clear. Note that Hawley includes ‘out of the hands of our adversaries.’ I am sure some of that will be chips, I continue to wonder to what extent such players are willing to discuss the consequences from open model weights.
Concerns are outpacing excitement.
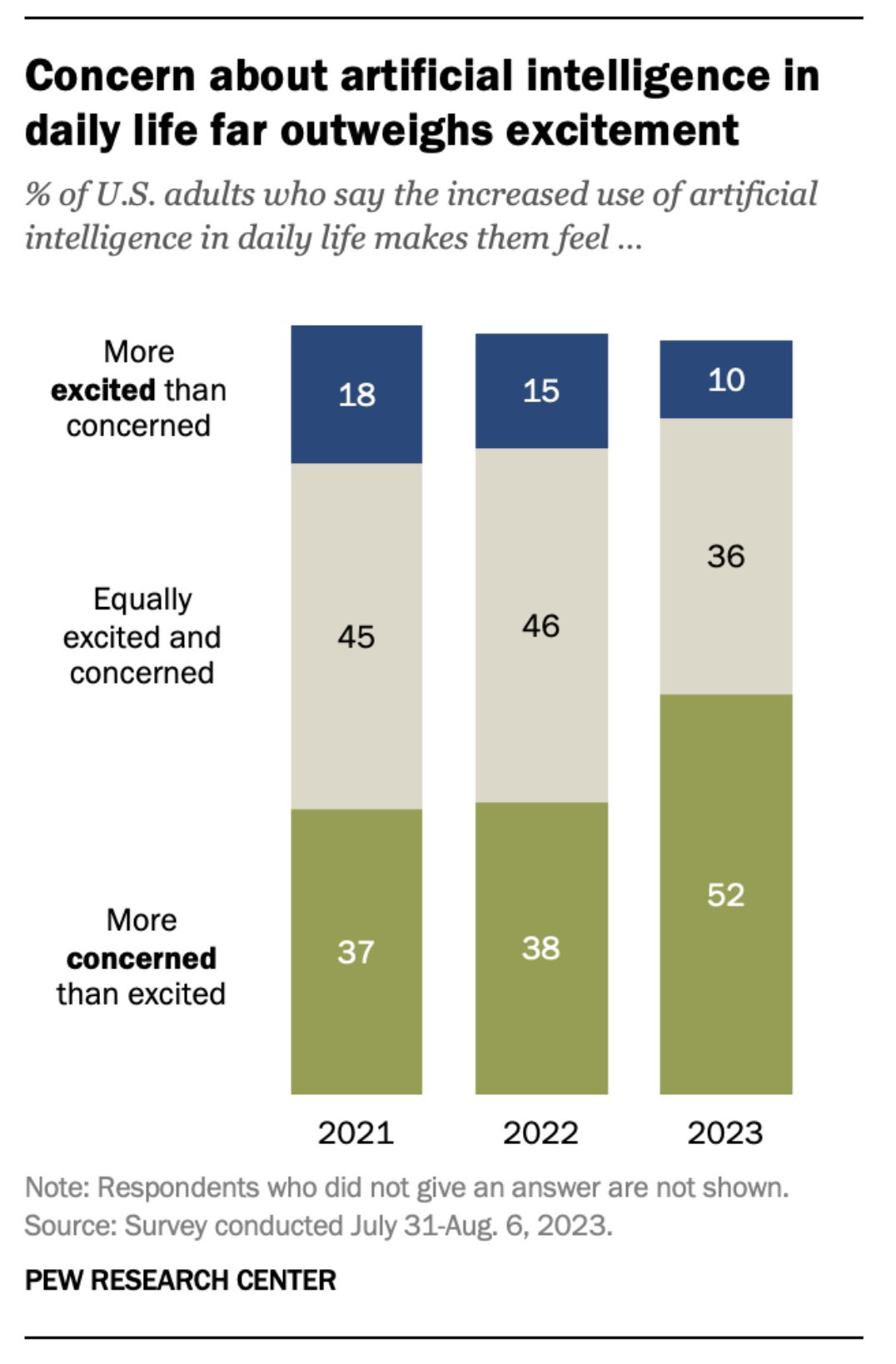
Partisan splits on regulation are inevitable, but this is as good as it gets, and Republicans are slightly more supportive than Independants:

Politico warns of this being increasingly partisan, saying ‘the split is faint but it is there.’ Hammer, meet nail.
Open Model Weights Are Unsafe And Nothing Can Fix This
Mark Zuckerberg announces that Meta is all-in on developing ‘open source’ AGI, by which he means open model weights. It is important to note that, for better and also for worse, Meta is not actually open sourcing its AI models, it is only releasing the model weights.
One source for this is VentureBeat, who also claimed that ‘open source AI won 2023’ which is the kind of statement that I don’t even know how to parse properly. Here is where Mark says his head is at:
Mark Zuckerberg: Our long-term vision is to build general intelligence, open source it responsibly, and make it widely available so everyone can benefit.
It’s become clear that the next generation of services required is building full general intelligence, building the best AI assistants, AIs for creators, AIs for businesses and more that needs advances in every area of AI from reasoning to planning to coding to memory and other cognitive abilities.
This is a remarkably myopic perspective on AGI. AGI as a next-generation service provider. I mean, yes, it would be able to totally do that, and allow service features otherwise impossible. It is also a world-class example of burying the lede, and the world’s lamest excuse or explanation for why one must build non-human general intelligences, seemingly without even noticing that there are ways this might not turn out so well.
Then again, note what Zuckerberg actually says in the video (around the 40 second mark):
Mark Zuckerberg: We think this technology is so important that we should open source this and make it as widely available as we responsibly can so that everyone can benefit.
Notice that extra word: Responsibly.
Aye, now there’s the rub.
Can you ‘responsibly’ release the weights to Llama-2? In terms of direct results, it depends on what counts as responsible. The safety work they did on Llama-2 can be entirely removed within a day at minimal cost. Luckily, there is nothing so terrible that a model at that level can do, so in direct terms it is fine.
The real concerns are instead about how this impacts future releases and the overall pace and structure of development of AI. What happens when a future model would actually be dangerous if fully unleashed in the wrong hands, or even inherently dangerous without any intent to misuse it?
If you ask me the extent to which you can ‘responsibly’ release the model weights of an artificial general intelligence?
My response is going to be none whatsoever. You absolutely cannot do that. Perhaps we will later figure out a way to do it, but under current methods, there is very clearly not a way to do that. Whether or not there is a ‘safe’ or ‘responsible’ way to build AGI at all, any releasing of the model weights undoes all that on so many levels at once.
So then the question is, what the hell does ‘responsible’ mean here, and what will ultimately happen?
I do not think it is inevitable that he intends, let alone actually carries out, his threat. If Meta were to actually develop an AGI, and it was not at minimum well behind current state of the art, there would be plenty of information that the responsible thing to do is not ‘let anyone however malicious fine-tune this any way they want and then use it for anything they want.’
Then he pitches glasses so that the AI can see what you see, and presumably (although he does not say this) you can stop thinking entirely. Which is not a knock, letting people not think is indeed a true killer app. Yes, it has unfortunate implications, but those were there anyway.
It is also noted that Meta’s chief scientist Yann LeCun continues to say that the plan won’t work, at least not in the next five years.
So what is the plan? It is to train more Llama models, it seems. And to buy really quite a lot of that good old compute. PC Mag estimates $10.5 billion purely in chip purchases, elsewhere I’ve heard claims of $20 billion. Dan’s comparisons here are on the low end of comparisons I’ve heard.
Dan Hendrycks: “350,000 Nvidia H100s by the end of this year” That’s ~30x more compute than GPT-4 and almost GPT-5-level
Dan Elton: Is this all for training #LLAMA 3?? There must be something else, right..? Powering smart glasses?
Robin Hanson: My guess is that in a decade it will look like a big mistake to have paid huge $ premia for AI hardware now, instead of waiting for price to come way down.
David Chapman: Now is the time to figure out something useful you could do with the $20 billion worth of AI chips Facebook will be selling off at a 97% discount in two years if this doesn’t work out as they hope.
I would agree with Robin’s assessment with all those chips were exclusively for training Llama models. I do not think Meta has the other complementary tools for that much training compute. However Dan is right that presumably most of this is largely for inference and providing various services. Meta will not be selling these chips.
They are also insurance. The default case is that costs go down as production rises, but I see multiple ways that could fail to happen.
- Perhaps there will be a war in Taiwan.
- Perhaps demand for chips grows even faster than supply, and prices do not fall.
- Perhaps Nvidia starts charging like a monopolist.
- Perhaps Nvidia decides not to sell to you, or to demand something in return.
- Perhaps the governments of the world start allocating or taking the supply.
- Perhaps restrictions are put in place on who can buy at this scale.
- Perhaps restrictions are put in place on irresponsible actors.
In addition to those ways for prices not to fall, there is also:
- This temporarily starves the competition of chips, perhaps meaningfully.
- If there are chips not being used, you can rent out the surplus compute.
- Getting into good position now is plausibly super valuable.
- Ten billion versus the future is pretty much chump change.
- What were you going to spend on instead, the Metaverse? Helps there too.
Meta is doing its best to play the cartoon villain role. But perhaps it is a bit more complicated than that?
Dan Hendrycks has an interesting theory.
Dan Hendrycks: Things that have most slowed down AI timelines/development:
– reviewers, by favoring of cleverness and proofs over simplicity and performance
– NVIDIA, by distributing GPUs widely rather than to buyers most willing to pay
– tensorflow
– Meta, by open sourcing competitive models (e.g., Llama 3) they reduce AI orgs’ revenue/valuations/ability to buy more GPUs and scale AI models
Meta’s open sourcing may also be seen as a major win for reducing international competitive pressures and racing dynamics. Countries don’t feel as left behind. Us-vs-them talk like “national competitiveness in AI” makes less sense if China gets the same models.
Reviewers seems clearly right. I can’t speak to tensorflow.
The counterargument on Nvidia is that the market clearing price of GPUs has for a while been much higher. If all the gamers and crypto miners and AI companies were actively bidding against each other and the market fully cleared, the cost of compute would go up a lot. Yes, the people who value it the most would get more of the best chips, but they would also be paying a lot more for them. If you think that Nvidia and TSMC are rate-limited and can’t scale faster with the resulting higher profits, it is not obvious which way this net effect goes.
The bold claim of course is Meta. I think Dan is wrong and Gallabytes below nails it, but it is hard to underestimate how often directional effects are highly unclear, and such arguments do need to be taken seriously.
Nora Belrose: I actually think Dan might be right that Meta’s open sourcing is slowing progress down by making it harder to profit off AI— but I’m okay with that if true. I’m not an accelerationist, and openness, equity, & safety matter a lot more to me than getting ASI as fast as possible.
Gallabytes: I see the argument but think it’s false in practice – llama2 & co make it much less risky to try stuff, which you can then scale up.
They make it harder to profit off of just base models, but afaict nobody is doing that. I’d bet OpenAI’s revenue is ~all from ChatGPT, not the API, which doesn’t even offer base models anymore.
I guess I’m not that interested in the economist’s perspective here because the inside view feels really strong. Open models let you try things with much much less lead time and capex, it’s night and day vs having to do even a t5 level training to get started.
Meta makes it more difficult to make money in AI by shipping substandard base models, but who was doing that? The ‘can try things’ ability seems way more important.
As for international competition, I do not believe China considers ‘use Llama variants’ an acceptable solution, so I do not think it decreases competition. Instead, it hands better tools to those behind in the competition, making it more intense.
Robert Maciejko asks various forms of one very right question.
Robert Maciejko: I don’t know the answer to this: How to build AI models that are trustworthy while harnessing the energy and ingenuity of the open source community and also ensuring models can reflect local cultures and preferences?
If you use ANY open source model, can you be sure it is not full of back doors, malware, etc.?
The obvious hacker/bad actor/intelligence service play would be to load @huggingface with 10,000s of high-performing models that people unquestioningly trust. Those models might be used to create other models; at this point, you can’t easily identify who made the model. Of course, closed models have vulnerabilities, too, but at least you know who you are trusting & know they are monitoring for bad actors. I’m sure there is much I am missing here.
Remember the Sleeper Agents paper?
That, on a highly practical level.
If there is a closed model from OpenAI, Google or Anthropic, you know the deal that you do not know what they are telling the model to do.
If a model were fully for-real open source, where anyone can look at the data set and the training procedure, that would allow for the usual open source procedure of various people digging for potentially malicious data and debugging the algorithms and running various experiments and searching for possible backdoor triggers throughout and so on.
To be clear, I am not saying I want people to go out and do that with frontier models and give everyone all the tools and work together to advance capabilities. I am not saying that because of the resulting diffusion and advancement of capabilities. It would be in a form you cannot take back and that goes to every bad actor forever and gets expanded over time.
If we were only talking about 3.5-level models, or even 4-level models, or 4.5-level models, or hell maybe even 5-level models, I could accept that. We could talk price. But it also lays the foundation for and sets us down a path we won’t be able to turn off. The whole point of open source is that information wants to be free and you can’t stop the signal. Eventually, for many reasons, proliferation becomes a profoundly bad idea. Yet Zuckerberg explicitly wants to take this all the way to AGI, which is insane, and there is no reason to expect the ability to halt this train when it gets out of control.
There are only two ways to respond to an exponential, too early or too late. This is a crowd that takes pride in not stopping too early.
What I am instead saying is that, if you want the benefits of open source, you have to actually be open source. Open model weights gets you a lot of the downside, without getting you most of the upside.
Meta is trying to have it both ways. They are trying to claim the full benefits of open source without actually being open source. Even if open source proponents were fully right, it still would not work that way.
The Week in Audio
Microsoft CEO Satya Nadella claims that there is no world (not American, not European, world) real economic growth, and ‘the developed world may have negative economic growth.’
This statement is not true. Here is the IMF’s graph of RGDP growth right now:
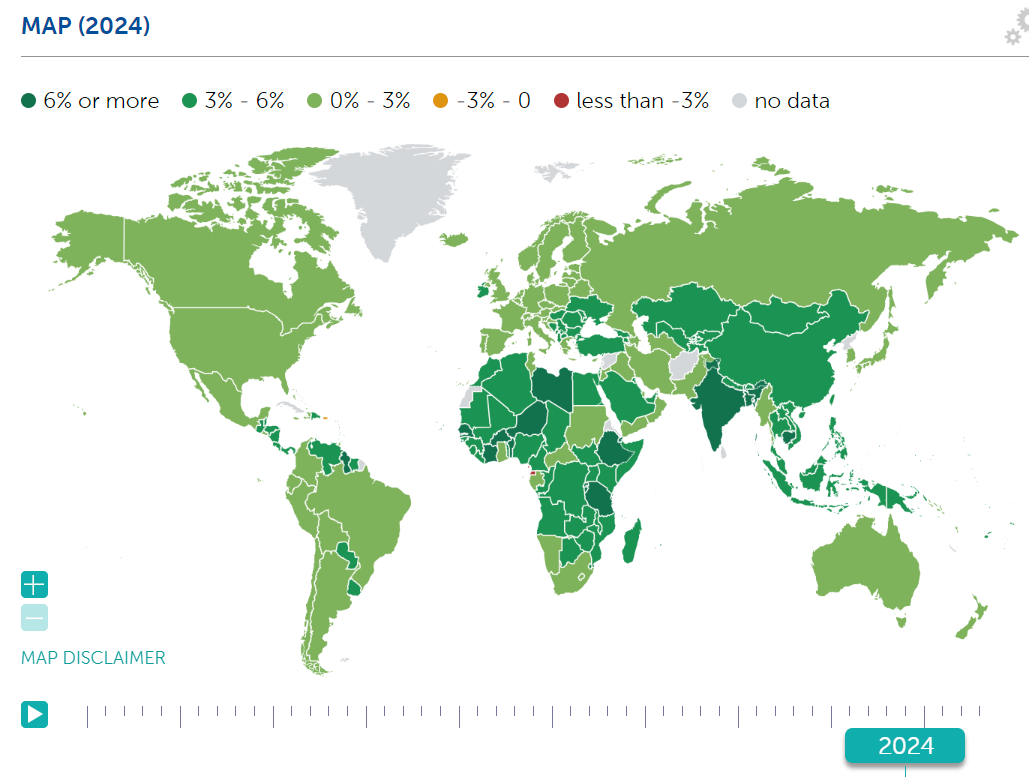
Here is the trend:
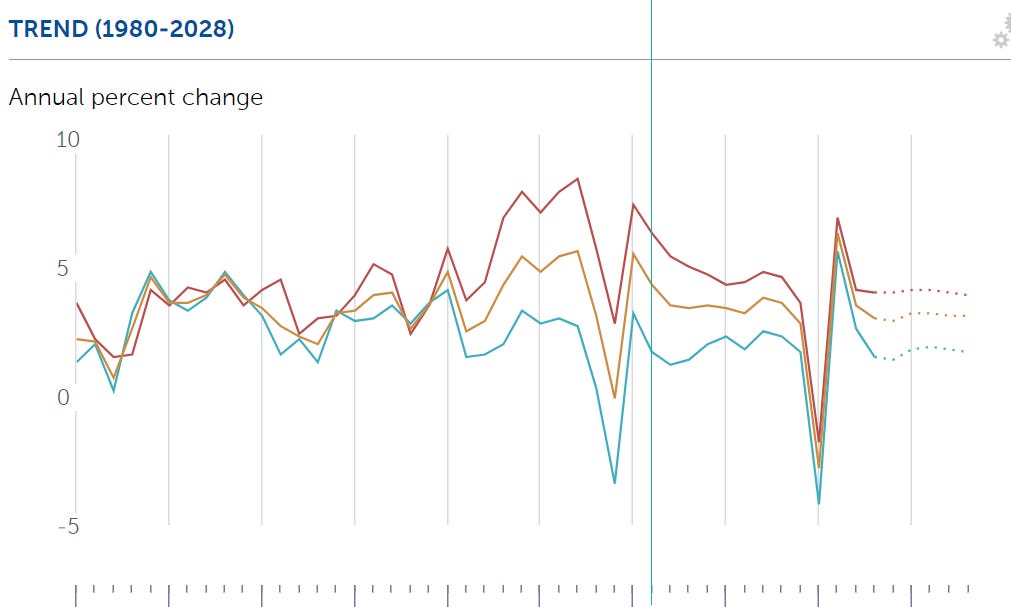
You can claim, of course, if you want to, that the world’s GDP numbers are widely falsified and that all of this is hogwash, that we are not actually producing and consuming larger quantities of stuff than we previously did. I know one person who would explicitly endorse this.
I do not consider that claim credible. I certainly do not think that this is what Nadella would say if he were asked a follow-up question. Also Nadella’s follow-up was that there is no growth and that AI was the only potential future source of growth.
The context he adds later is weird and raises further questions. He says his goal is to ‘get back to 2%-3% real economic growth’ via AI. He says the last time we had growth was the PC. What?
I don’t know if Nadella actually believes this. If he doesn’t, he is lying. If he does, then we learned something very important about his epistemics and how much he cares about being accurate even on important questions. I would think that knowing economic growth was positive would be kind of important to the role of the CEO of Microsoft. If this was not true then they should make many different decisions.
Either way, we now have common knowledge that he will make big important claims, about things highly pertinent to his job, that are untrue, and which he has the ability to easily learn are untrue.
This thread has more speculation about how smart, highly successful people might genuinely buy Davos-flavored utter stupidity like this, despite it not passing the sniff test of anyone attempting to understand the world and being easily checkable.
Nadella’s call around 17:45 is for evaluations of foundation models and risk-based assessments of applications. That is a reasonable answer given he has no intention of taking this fully seriously. At 19:30 is he is asked for governments are up to understanding the situation, and he says we will always be up for being able to regulate and control any technology. That the tech and the principles of its governance should be simple and clear. Again, not taking the situation seriously.
Connor Leahy gives an interview to TRT world.
Holly Elmore of PauseAI gives her perspective, where maybe it is not a good idea for all safety advocates to cooperate with those building AGI and convincing them to slap on a few evaluations and other precautions, rather than saying maybe don’t build AGI. Maybe the public actually supports the ‘don’t build it’ plan and we should even protest and pause until we find an actual solution. Yes there are plenty of highly valid objections, but I am glad someone is out there advocating the full case for stop.
Jaan Tallinn explains existential risk in a few minutes (video). Does it work for you?
Sam Altman and others at the World Economic Forum. Once again emphasizing AI as a tool. Emphasis on whether humans trust AI and what it can do for mundane utility and They Took Our Jobs, rather than what we should perhaps actually worry about. These people can’t turn everything possible over to their AIs fast enough.
I talk to the Bayesian Conspiracy, almost entirely not about AI
Nathan Lebenz goes on 80,000 hours. Haven’t listened yet, will soon.
Rhetorical Innovation
Eliezer Yudkowsky wisely warns not to bet all their epistemic chips (let alone real money) on very short timelines. We do not know how long this will take.
Scott Alexander notes the e/acc explicit desire for the universe not to contain humans. He then says, all right, sure, that sounds bad when you put it that way, but perhaps there are versions where there are still lots of distinct individual AIs that have consciousness and art and philosophy and curiosity and it is fine?
This is classic form Scott Alexander, where he takes extra care to fine the best steelman of the opposing positions (with varying degrees of ability to find them, such as him noting that ‘humans and AIs merge’ does not actually make any competitive sense and is not going to be a thing), thinks well perhaps me and everyone I know should die or everything I know or believe in is wrong or everything I value should be overruled, maybe I am actually Worse Than Hitler and should never ever ever ever ever ever leave my house again, without a hint of derision or mockery.
Then, of course, comes the part where he thinks he’s done enough interpretive and emotional labor that it might be acceptable to say that there is some small chance that it is in part the seemingly crazy people that are wrong, which here is sections II and III.
Scott Alexander: Even if all of these end up going as well as possible – the AIs are provably conscious, exist as individuals, care about art and philosophy, etc – there’s still a residual core of resistance that bothers me. It goes something like:
Imagine that scientists detect a massive alien fleet heading towards Earth. We intercept and translate some of their communications (don’t ask how) and find they plan to kill all humans and take Earth’s resources for themselves.
Although the aliens are technologically beyond us, science fiction suggests some clever strategies for defeating them – maybe microbes like War of the Worlds, or computer viruses like Independence Day. If we can pull together a miracle like this, should we use it?
Here I bet even Larry Page would support Team Human. But why? The aliens are more advanced than us. They’re presumably conscious, individuated, and have hopes and dreams like ourselves. Still, humans uber alles.
Is this specieist? I don’t know – is it racist to not want English colonists to wipe out Native Americans? Would a Native American who expressed that preference be racist? That would be a really strange way to use that term!
I think rights trump concerns like these – not fuzzy “human rights”, but the basic rights of life, liberty, and property. If the aliens want to kill humanity, then they’re not as superior to us as they think, and we should want to stop them. Likewise, I would be most willing to accept being replaced by AI if it didn’t want to replace us by force.
Maybe the future should be human, and maybe it shouldn’t. But the kind of AIs that I’d be comfortable ceding the future to won’t appear by default. And the kind of work it takes to make a successor species we can be proud of, is the same kind of work it takes to trust that successor species to make decisions about the final fate of humanity. We should do that work instead of blithely assuming that we’ll get a kind of AI we like.
I am less ambivalent than Scott on this. I am sure that there exist potential far future states of the universe that capture large percentages of maximum potential value, not only non-zero value, in which there exist zero (or on a cosmic scale almost zero) biological humans, or even close digital simulations of humans, and that it is possible we could get there from here in an acceptable way.
I also very much do not expect that to happen by accident or default or without an extraordinary effort, and would very much like humans to stay alive and in control of the future for a while, thank you very much. And I assert that I get to have preferences over world states in this way.
Who are the wisest accelerationists? A lot of attempts to take credit for people that built things. A few common names throughout.
Yanco: Prominent VC claimed recently that “AI is basically just math, so why should we worry?”
Imagine the captain of Titanic announcing, “don’t worry, passengers, this is just water.”
The entire universe is math. What, me worry?
Malaria Accelerationism
Maybe I shouldn’t be mentioning this at all but it’s too beautiful.
Also we need to be able to remind others of this later.
Everyone has a technology they dislike. A place in which humanity has a duty not to mess with nature’s natural order. A way of helping people that is so unethical that principle means we must condemn people to die.
Because if you give people fishing nets they control and can use for whatever they want, people might decide to misuse those mosquito nets to instead use them for fishing, you see. And it turns out that there are negative externalities to them doing that, because they might deplete common resources, or their toxic features might disturb fishing ecosystems.
I mean, man, do you even hear yourself?
If you thought any of this was principled, you can put those fears to bed. It is pure vibes, pure tribal politics of us and them, pure selfish talking of one’s book.
Daniel Eth: Marc Andreesen was just responding to the common critique of e/acc that “e/acc’s shouldn’t just worry about killing future, hypothetical people, but should also focus on enacting current harms towards real people that already exist”
As poetic as this all is, this is not quite as good as when he wrote (the excellent!) ‘It’s Time to Build’ and then lobbied to prevent housing construction in his neighborhood. It’s still close.
Aligning a Smarter Than Human Intelligence is Difficult
Buck Shlegeris continues to make the case that [AF · GW], in addition to attempting to align your dangerously advanced and highly useful future AI models, you should also control them, meaning defend against them potentially being hostile and ‘scheming.’ As he notes, a lot of this is restating arguments they’ve made before to try and get through with them, although others are new.
The core case is that, well, you’re not going to stop trying to do the alignment part, so now you have defense in depth, if either half of the plan works you are fine. The counterargument is that in practice this will not result in the same level of precaution and required other progress, you don’t get ‘free extra’ security for the same reason people drive faster with seat belts, and also you only have so much attention to pay to such techniques and especially to requiring others to use them. And I am constantly thinking ‘oh that’s another potentially false assumption’ as I read such work. I could go on, but I mostly have laid out my concerns and objections previously and from what I saw this does not much change them.
As usual, I am very much not saying ‘do not work on this.’ By all means, please do keep working on this, we need a diverse portfolio of efforts even if I can’t see how it could work out.
It is even harder if you do not know what is going on. Have you tried mechanistic interpretability? I continue to not accept this idea that there is a clear distinction between ‘scheming’ versus ‘not scheming,’ where blocking individual scheming actions renders you safe, or where you will be fine so long as you block individually unacceptable outcomes.
Sasha Rush: I recently asked pre-PhD researchers what area they were most excited about, and overwhelmingly the answer was “mechanistic interpretability”. Not sure how that happened, but I am interested how it came about.
Neel Nanda (DeepMind): Wow, I didn’t think we were succeeding this hard, but that’s awesome to hear!
My guesses:
– True understanding is beautiful
– Easy to get started, especially without much compute. I like to think my tutorials have helped!
– Some beautiful and flashy papers, especially from Chris Olah’s lab, like induction heads, toy models of superposition, and sparse auto-encoders
– Increasing safety interest (though you don’t have to care about safety to want to be involved!)
If you want to get started in the field, check out my guide:
Chris Olah: I think all your tutorials and field building work have probably been a non-trivial part of the story! :)
Interpretability is great. I do still worry this is succeeding a bit too well. Interpretability has many advantages, you can show clear incremental progress, the whole thing is legible. It is easy to see how to jump into it and start trying things. All of which is good. The concern is that it is sucking up too much of the safety or alignment effort, and we have an increasingly unbalanced portfolio.
Other People Are Not As Worried About AI Killing Everyone
Anton tells reassuring story where the Chinese and American AI systems are plugged into the nuclear weapons and a minute later form a full agreement for mutual cooperation amongst them via acausal trade. Anton does not consider what it means that we were neither part of the cooperation agreement nor in control of our weapon systems.
Tyler Cowen continues to not worry, saying what we do need to worry about are the humans that use AI.
As has become his pattern, Tyler analyzes a world of only mundane AI, not considering what would happen with AI sufficiently intelligent and capable that it ceases to be centrally a tool for humans to use and humans cease being the ones doing the important thinking. He does not even mention this here, even to dismiss it.
Since he does not offer arguments that such transformations won’t happen or won’t have the catastrophic or existentially risky consequences, I’ve realized the more useful way to respond to Tyler is to act as if he is only discussing the intermediate world of mundane AI, where both of us are similar optimists, and compare notes on implications there. It is a key question in its own right.
One thing that caught my eye: He warns that writing skill might decline in value.
Knowing how to write well won’t be as valuable a skill five years from now, because AI can improve the quality of just about any text.
I agree with him that being bilingual will decline in value, but I am not convinced on writing. Yes, the AI will help you ‘punch up’ or fix your writing, and especially help you transpose forms and perform class. And it will help you with basic writing generic tasks. But I do not feel as if my skills are under any threat, and would expect to have far bigger problems or at least concerns (and opportunities) if they were under such threat.
One might say that mundane AI will decrease returns to competence and the cost to get competence, across many areas, while perhaps increasing returns to excellence. If you can produce quality that the AI cannot match, then that will be in even higher demand in the places where that is valuable. Similarly, if AI generates a baseline, many ‘wordcel’ competitions will accelerate in complexity and skill, again assuming a ‘mundane’ AI world.
Similarly, while the returns to being an articulate lawyer may well decline, especially as a function of medium-term oversupply relative to demand before labor allocation can adjust, I expect exceptional lawyers to thrive. I also think there is a large chance that lawyers will see that demand scales up rapidly as quality increases and cost falls, and that lawyers who can keep up end up doing well.
On the flip side, using current tech trends, being as he suggests a carpenter currently looks to offer high returns. But will that last? I would be confident in my five year plan, but it would be shocking to me even with relatively slow AI progress if AI did not figure out ways to operate as a carpenter. Also, with the rise of vision and soon I presume video inputs to models, the same ‘skilling up’ process should greatly aid in skill development and helping people muddle through in such realms also, increasingly over time, even if the robotics and other physical steps continue to be elusive.
The Lighter Side
Don’t write checks you won’t cash, but checks you’re already cashing are fine.
Dimitris Papailiopoulos: chatGPT-4 is still lazy about writing code, and the “I’ll tip you 100$” works just fine. But i feel bad lying to its face, so I resort to “I’ll give you 20$/month” and it still works like a charm! Be nice to your future bot overlords, they’ll remember everything.
darren: LLM papers be like:
“ClearPrompt: Saying What You Mean Very Clearly Instead of Not Very Clearly Boosts Performance Up To 99%
TotallyLegitBench: Models Other Than Ours Perform Poorly At An Eval We Invented
LookAtData: We Looked At Our Data Before Training Our Model On It.”
Dave: You forgot PRStunt: we don’t tell you any details about training data, model size or architecture but it’s SoTA on a bunch of stuff
darren: We’re pleased to announce a future announcement
Minh Nguyen: LLMs All The Way Down: An endless stack of LLMs, it actually works pretty well, but no one is gonna bother replicating this in prod
darren: It costs 700,000 dollars to replicate this.
Julian Harris: ActuallyDoItFFSLLM: fine-tuned open source baseline on GPT4 output based on increasingly threatening prompts until GPT4 actually did it instead of whining it was a complex task that required considerable effort.
Quintus: AlmostAsGood: An extremely specific data set and prompting chain achieves almost as good performance as GPT4, and is sometimes even slightly better.
Warning, spoilers? I guess?
fofr: I guess I don’t know what I expected.
Suhail: Yikes. Feel like they went too far somewhere in data curation.
I agree, except the ‘they’ in question is ‘The Internet.’
If AI didn’t enable this, it certainly could have.
Forth: After years of meme jealousy, second-guessing, millions of repetitions, it finally comes full circle to where it needed to go Giving memes happy endings could be an entire genre.



9 comments
Comments sorted by top scores.
comment by RogerDearnaley (roger-d-1) · 2024-01-26T04:51:53.122Z · LW(p) · GW(p)
Claiming this is an S-curve, and that humans happen to lie in a close-to-optimal position on it, such that more intelligence won’t much matter, seems like a thing you can only conclude by writing that conclusion at the bottom first and working backwards.
An alternative suggestion: human languages, and human abilities at cultural transmission of skills and technologies between generations, are Turing-complete: we can (laboriously) teach human students to do quantum mechanics, nuclear engineering, or Lie group theory, despite these being wildly outside the niche that we evolved for. Great apes' social transmission of skills and technologies is not Turing-complete. However, looking at the evolution rate of stone tool technology, the sudden acceleration starts with Homo sapiens, around 250,000 years ago: Homo neanderthalis stone tools from half a million years apart are practically indistinguishable. So we crossed the Turing-completeness threshold only 250,000 years ago, i.e. a blink of an eye in primate evolution. Which makes it almost inevitable that we're Turing tarpits, technically Turing complete but really bad at it. Witness the small proportion of us who learn quantum mechanics, the advanced age at which those who do so generally master it, as graduate students (no, knowing how to turn the crank on the Copenhagen interpretation/Schrodinger equation is not mastering it: that's more like understanding the Feynman path integral formulation) [and indeed also the amount of pseudophilosophical nonsense that get talked by people who haven't quite mastered it]. We can do this stuff, but only just.
Now imagine AIs that are not Turing tarpits, and pick up quantum mechanics and abstract mathematics the way we pick up human languages: like a sponge.
comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2024-01-26T07:20:27.656Z · LW(p) · GW(p)
Typo: the link to the Nature news article on Sleeper Agents is broken.
comment by [deleted] · 2024-01-25T20:04:31.160Z · LW(p) · GW(p)
Regarding the discussion on deep fakes: There's an assymetry here.
Deepfake capable models seem to be a done deal. They are small, can be hosted on a single GPU, even hosted by phones and laptops with efficient cores designed for AI. Regulating them so they won't fake any image, voice, or some types of video with temporal stability seems difficult.
Digitally signing all the "real" content and/or registering hashes of real video when it happens to a public ledger or block chain may be ooms more viable.
(Ooms meaning you might need to invade every country on earth and control every computer to stop them)
When vcrs and mp3 players came out, the media companies were unable to meaningfully ban or regulate either technology. They were forced to change their business model to adapt.
You could make the same argument - that maybe the vendors of mp3 players should have withdrawn their product until they were unable to play pirated music. But that's not what happened.
comment by Mo Putera (Mo Nastri) · 2024-01-26T07:39:57.704Z · LW(p) · GW(p)
I do not understand why very smart people are almost intelligence deniers.
This reminded me of Are smart people's personal experiences biased against general intelligence? [LW · GW] It's collider bias:
I think that people who are high in g will tend to see things in their everyday life that suggest to them that there is a tradeoff between being high g and having other valuable traits.
The post's illustrative example is Nassim "IQ is largely a pseudoscientific swindle" Taleb.
comment by smool · 2024-01-26T04:25:23.007Z · LW(p) · GW(p)
It makes sense to cryptographically watermark *authentic* photos and videos.
But camera manufacturers, image processing software vendors, and distribution platforms have to agree on a standard.
I've thought about this in the past, but what's to stop someone from generating a fake image, then using a authentic camera to take a picture of my fake image? According to the camera, the image is legitimate
comment by mishka · 2024-01-26T00:57:26.915Z · LW(p) · GW(p)
Altman says he isn’t sure what Ilya Sutskever’s exact employment status is. I feel like if I was CEO of OpenAI then I would know this.
This seems be the author of that Axios article editorializing. In reality, here is what seems to have been said:
https://twitter.com/tsarnick/status/1747807508981514716 - 24 seconds of Sam's talking (the summary is that Sam says he is hopeful that they'll find a way to keep working together (and, to my ear, he is sounding like he is really very emphatically hoping for success in this sense, but that he can't be sure of success in this sense yet, so they have still been discussing this situation as of last week))
(Via a discussion at https://manifold.markets/Ernie/what-will-ilya-sursever-be-doing-on)
comment by Mitchell_Porter · 2024-01-25T23:05:44.503Z · LW(p) · GW(p)
Meta is not actually open sourcing its AI models, it is only releasing the model weights.
There seem to be a variety of things that one can be "open" about, e.g. model weights, model architecture, model code; training data, training protocol, training code...
Replies from: zac-hatfield-dodds↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2024-01-26T07:41:51.066Z · LW(p) · GW(p)
"X is open source" has a specific meaning for software, and Llama models are not open source [LW(p) · GW(p)] according to this important legal definition.
Replies from: Mitchell_Porter↑ comment by Mitchell_Porter · 2024-01-28T07:18:03.691Z · LW(p) · GW(p)
My first interest here is conceptual: understanding better what "openness" even means for AI. (I see that the Open Source Initiative has been trying to figure out a definition for 7 months so far.) AI is not like ordinary software. E.g. thinking according to the classic distinction between code and data, one might consider model weights to be more like data than code. On the other hand, knowing the model architecture alone should be enough for the weights to be useful, since knowing the architecture means knowing the algorithm.
So far the most useful paradigm I have, is to think of an AI as similar to an uploaded human mind. Then you can think about the difference between: having a digital brain with no memory or personality yet, having an uploaded adult individual, having a model of that individual's life history detailed enough to recreate the individual; and so on. This way, we can use our knowledge of brains and persons, to tell us the implications of different forms of AI "openness".