Spencer Schiff: Next week will likely be remembered as one of the most significant weeks in human history.
We fell far short of that, but it was still plenty cool.
Essentially no one’s expectations for Google’s I/O day were very high.
Then Google, in way that was not in terms of its presentation especially exciting or easy to parse, announced a new version of basically everything AI.
That plausibly includes, effectively, most of what OpenAI was showing off. It also includes broader integrations and distribution.
It is hard to tell who has the real deal, and who does not, until we see the various models at full power in the wild.
I will start with and spend the bulk of this post on OpenAI’s announcement, because they made it so much easier, and because ‘twice as fast, half the price, available right now’ is a big freaking deal we can touch in a way that the rest mostly isn’t.
But it is not clear to me, at all, who we will see as having won this week.
So what have we got?
The GPT-4o Announcement
OpenAI: GPT-4o (“o” for “omni”) is a step towards much more natural human-computer interaction—it accepts as input any combination of text, audio, and image and generates any combination of text, audio, and image outputs.
It can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time(opens in a new window) in a conversation.
It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models.
…
With GPT-4o, we trained a single new model end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network. Because GPT-4o is our first model combining all of these modalities, we are still just scratching the surface of exploring what the model can do and its limitations.
There are two things from our announcement today I wanted to highlight.
First, a key part of our mission is to put very capable AI tools in the hands of people for free (or at a great price). I am very proud that we’ve made the best model in the world available for free in ChatGPT, without ads or anything like that.
Our initial conception when we started OpenAI was that we’d create AI and use it to create all sorts of benefits for the world. Instead, it now looks like we’ll create AI and then other people will use it to create all sorts of amazing things that we all benefit from.
We are a business and will find plenty of things to charge for, and that will help us provide free, outstanding AI service to (hopefully) billions of people.
Second, the new voice (and video) mode is the best computer interface I’ve ever used. It feels like AI from the movies; and it’s still a bit surprising to me that it’s real. Getting to human-level response times and expressiveness turns out to be a big change.
The original ChatGPT showed a hint of what was possible with language interfaces; this new thing feels viscerally different. It is fast, smart, fun, natural, and helpful.
Talking to a computer has never felt really natural for me; now it does. As we add (optional) personalization, access to your information, the ability to take actions on your behalf, and more, I can really see an exciting future where we are able to use computers to do much more than ever before.
Finally, huge thanks to the team that poured so much work into making this happen!
Daniel Eth: Wait, was Her a dystopia? I thought it was neither a utopia nor a dystopia (kinda rare for sci-fi honestly).
[GPT-4o] agrees with me that Her is neither utopia nor dystopia.
Alexa has its (very limited set of) uses, but at heart I have always been a typing and reading type of user. I cannot understand why my wife tries to talk to her iPhone at current tech levels. When I saw the voice demos, all the false enthusiasm and the entire personality of the thing made me cringe, and want to yell ‘why?’ to the heavens.
But at the same time, talking and having it talk back at natural speeds, and be able to do things that way? Yeah, kind of exciting, even for me, and I can see why a lot of other people will much prefer it across the board once it is good enough. This is clearly a giant leap forward there.
They also are fully integrating voice, images and video, so the model does not have to play telephone with itself, nor does it lose all the contextual information like tone of voice. That is damn exciting on a practical level.
This is the kind of AI progress I can get behind. Provide us with more mundane utility. Make our lives better. Do it without ‘making the model smarter,’ rather make the most of the capabilities we already have. That minimizes the existential risk involved.
This is also what I mean when I say ‘even if AI does not advance its core capabilities.’ Advances like this are fully inevitable, this is only the beginning. All the ‘AI is not that useful’ crowd will now need to move its goalposts, and once again not anticipate even what future advances are already fully baked in.
Will Depue (OpenAI): I think people are misunderstanding gpt-4o. it isn’t a text model with a voice or image attachment. it’s a natively multimodal token in, multimodal token out model.
You want it to talk fast? Just prompt it to. Need to translate into whale noises? Just use few shot examples.
Every trick in the book that you’ve been using for text also works for audio in, audio out, image perception, video perception, and image generation.
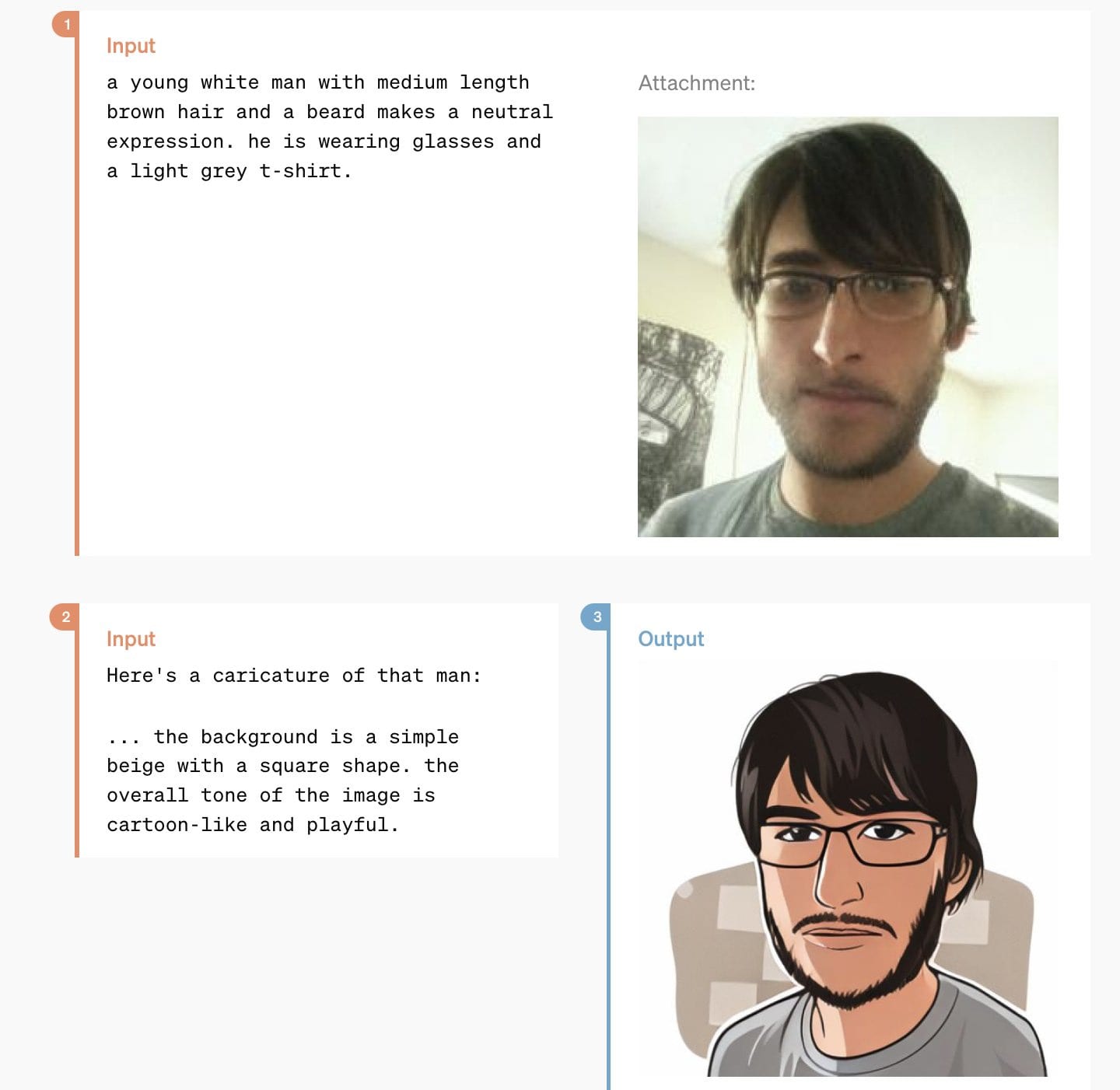
For example, you can do character consistent image generation just by conditioning on previous images. (see the blog post for more)
[shows pictures of a story with a consistent main character, as you narrate the action.]
variable binding is pretty much solved
“An image depicting three cubes stacked on a table. The top cube is red and has a G on it. The middle cube is blue and has a P on it. The bottom cube is green and has a T on it. The cubes are stacked on top of each other.” [images check out]
3d object synthesis by generating multiple views of the same object from different angles
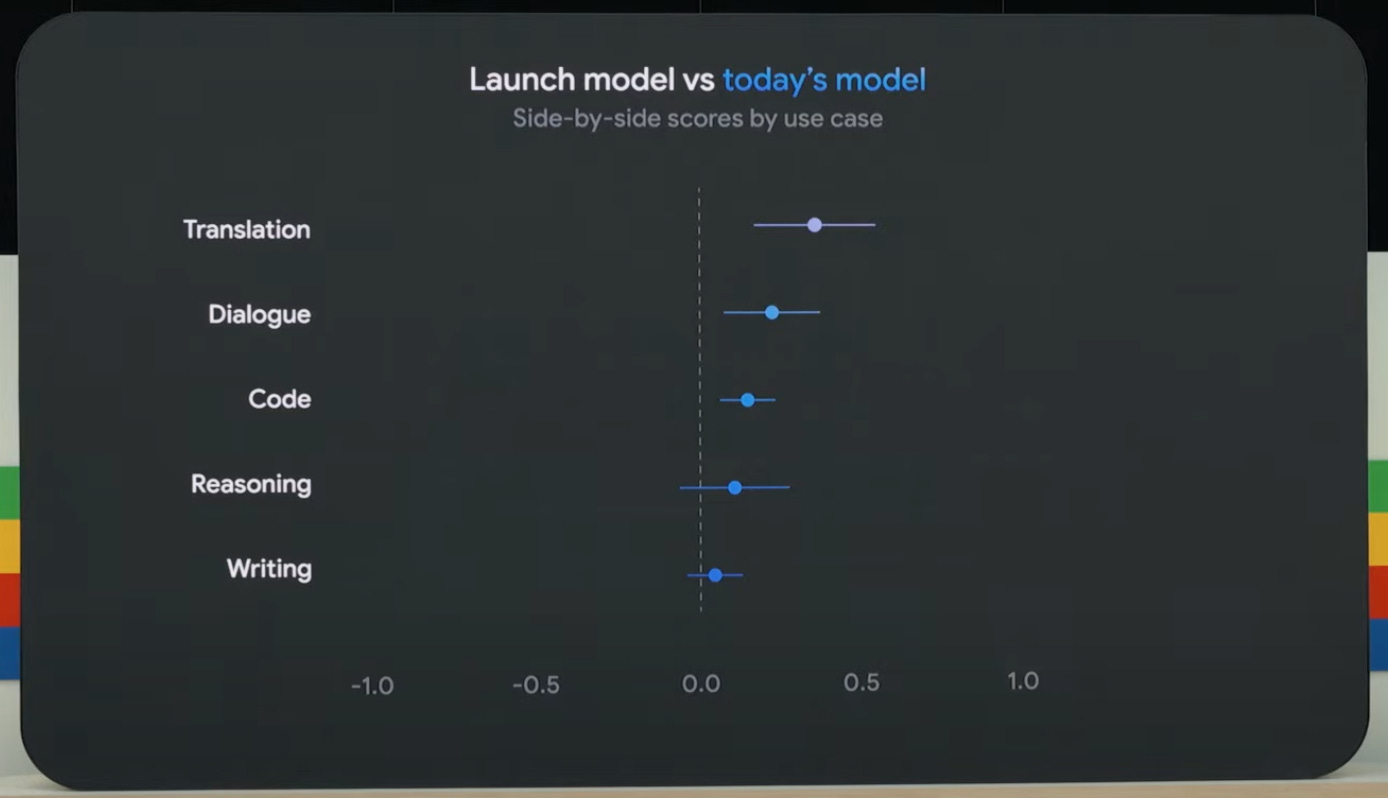
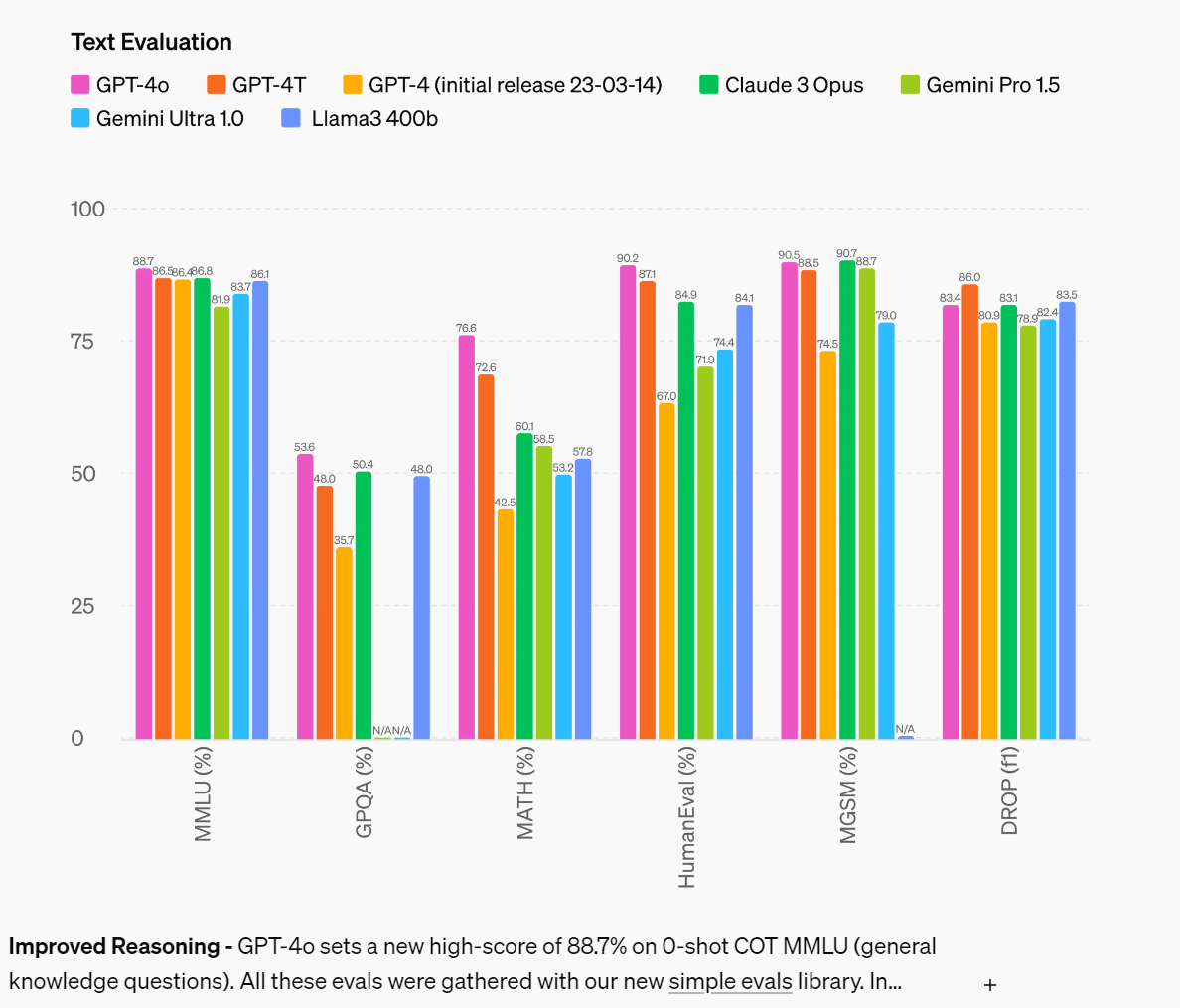
The announcement of GPT-4o says it ‘matches’ GPT-4-Turbo performance on text in English and code, if you discount the extra speed and reduced cost.
The benchmarks and evaluations then say it is mostly considerably better?
Here are some benchmarks.
This suggests that GPT-4’s previous DROP performance was an outlier. GPT-4o is lower there, although still on par the best other models. Otherwise, GPT-4o is an improvement, although not a huge one.
Danielle Fong: The increase in performance on the evals is nothing to sneeze at, but based on my experience with early gpt 3.5 turbo, i bet the performance gain from ablating much of the safety instructions from the system prompt would be greater.
Agreed that the above is nothing to sneeze at, and that it also is not blowing us away.
There are reports (covered later on) of trouble with some private benchmarks.
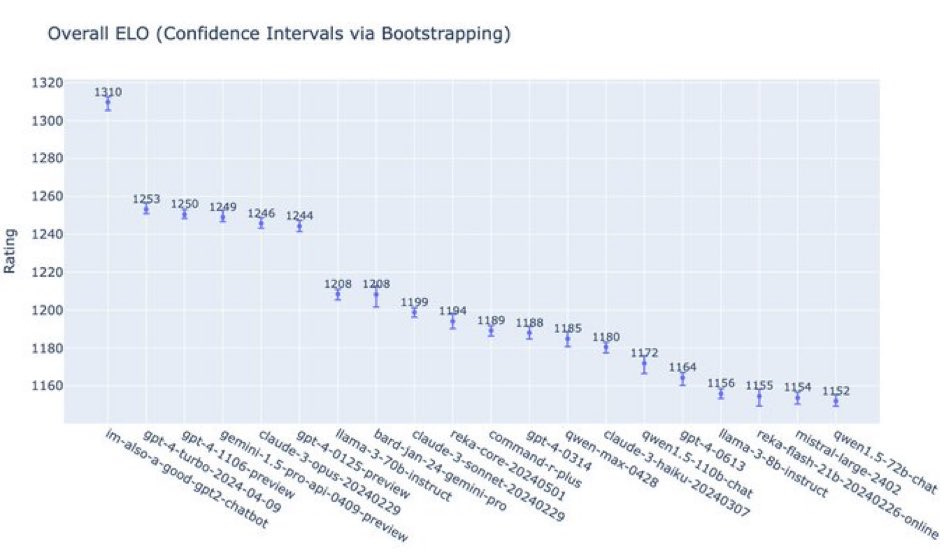
Here is the most telling benchmark, the Arena. It is a good chatbot.
Perhaps suspiciously good, given the other benchmark scores?
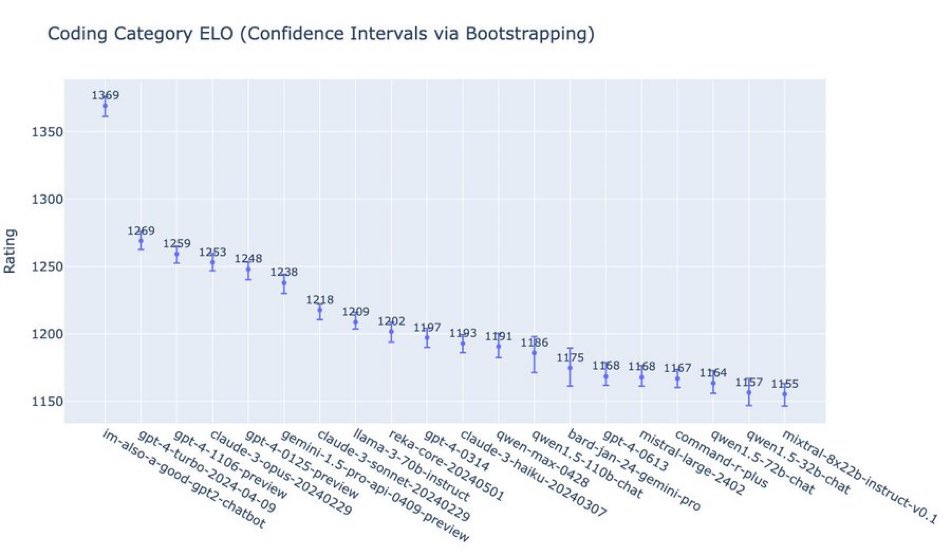
At coding, it is even more impressive going by Arena.
William Fedus (OpenAI) points out that Elo performance is bounded by the difficulty of questions. If people ask questions where GPT-4-Turbo and Claude Opus are already giving fully correct or optimal answers, or where the user can’t tell they’re wrong or not as good, then it comes down to style preference, and your win percentage will be limited.
This is much better with Elo-style ratings than with fixed benchmarks, since humans will respond to greater capabilities by asking better and harder questions. But also a lot of questions humans want to ask are not that hard.
Roughly, before the upper limit consideration, this is saying GPT-4o is to GPT-4-Turbo what Claude Opus is to Claude Sonnet. Or, there was previously a ‘4-class’ of the top tier models, and this is presenting itself as somewhat more than a full next level up, at least in the ‘4.25’ range. You could use the Elo limitation issue to argue it might be higher than that.
The potential counterargument is that GPT-4o is optimizing for style points and training on the test. It could be telling people ‘what they want to hear’ in some form.
If OpenAI has focused on improving the practical user experience, and using the metric of boolean user feedback, then the model will ‘seem stronger than it is,’ whether or not this is a big improvement. That would explain why the Arena benchmark is running so far ahead of the automated benchmarks.
In other areas, the improvements are clearly real.
Aaron Levie: OpenAI just made their new GPT4 model 50% cheaper and 2X faster for developers. This is an insane level of improvement for anyone building in AI right now.
Paul Graham: Would this get counted in productivity statistics @ATabarrok?
Alex Tabarrok: Only when/if it increases GDP.
The speed increase for ChatGPT is very clearly better than 2x, and the chat limit multiplier is also bigger.
That is only modestly more than a 2x speedup for the API, versus the clearly larger impact for ChatGPT.
The biggest difference is that free users go from GPT-3.5 to some access to GPT-4o.
James Miller: For paid users, OpenAI’s new offerings don’t seem like much. But part of when AI obsoletes most knowledge workers will come down to costs, and OpenAI being able to offer vastly better free services is a sign that they can keep costs down, and that the singularity is a bit closer.
There is both the ‘OpenAI found a way to reduce costs’ element, and also the practical ‘this website is free’ aspect.
Until now, the 4-level models have been available for free via various workarounds, but most users by default ended up with lesser works. Now not only is there a greater work, it will be a default, available for free. Public perceptions are about to change quite a lot.
On the question of OpenAI costs, Sully seems right that their own costs seem likely to be down far in excess of 50%.
Sully Omarr: Man idk what OAI cooked with gpt4o but ain’t no way it’s only 50% cheaper for them
It’s:
– free (seriously they’ve been capacity constrained forever)
– 4x faster that gpt4 turbo
– better at coding
– can reason across 3 modalities
– realtime
They’re definitely making a killing on the API.
The model at the very least is more efficient than anything launched before, by orders of magnitude (or more GPUs?)
Dennis: GPT-4o is free bc they’re going to start using everyone’s data to improve the model
Your data is worth more to them than $20
Facebook story all over again
I do not know about orders of magnitude, but yeah, if they can do this at this scale and this speed then their inference costs almost have to be down a lot more than half?
Yes, one good reason to offer this for free is to get more data, which justifies operating at a loss. But to do that the loss has to be survivable, which before it was not. Now it is.
Here is one potential One Weird Trick? I do not think this is necessary given how fast the model spits out even much longer responses in text, but it is an option.
Robert Lukoszko: I am 80% sure openAI has extremely low latency low quality model get to pronounce first 4 words in <200ms and then continue with the gpt4o model.
Just notice, most of the sentences start with
“Sure”, “Of course”, “Sounds amazing”, “Let’s do it”, “Hmm”
And then it continues with + gpt4 real answer.
…
Wait, humans do the same thing? No shit.
Guyz Guyz Guyz I am wrong [shows the demo of request for singing.]
What Else Can It Do?
The announcement arguably buried a lot of the good stuff, especially image generation.
Andrew Gao: things not mentioned in the livestream:
Sound synthesis (GPT4-o can make sound effects)
Insane text-to-3D ability
Almost perfect text rendering in images
One-shot in-context image learning (learns what an object or your face looks like, and can use it in images)
Lightyears ahead of anyone at having text in AI generated images. Gorgeous.
So confident in their text image abilities they can create fonts with #GPT4-o.
Effectively one shot stable diffusion finetuning, in context!?
First it was hands. Then it was text, and multi-element composition. What can we still not do with image generation?
There’s a kind of ‘go against the intuitions and common modes’ thing that still feels difficult, for easy to understand reasons, but as far as I can tell, that is about it? I am more likely to run into issues with content filters than anything else.
Tone of voice for the assistant is not perfect, but it is huge progress and very good.
Aaaron Ng: GPT-4o’s voice mode is more than faster: it literally hears you.
AI’s today convert speech to text. That’s why it doesn’t know tone or hear sounds.
GPT-4o takes in audio, so it’s actually hearing your excitement. Your dog barking. Your baby crying.
That’s why it’s important.
Mikhail Parakhin: The most impressive and long-term impactful facet of GPT-4o is the two-way, streaming, interruptible, low-latency, full-duplex native speech. That is REALLY hard – possibly the first model that genuinely will be easier to talk to than type.
This is the difference between ‘what looks and sounds good in a demo and gets you basic adaption’ versus ‘what is actually valuable especially to power users.’ There are far more tokens of information in cadence and tone of voice and facial expressions and all the other little details than there is in text. The responsiveness of the responses could go way, way up.
Safety First
What about model risks? OpenAI says they did extensive testing and it’s fine.
They say none of the risk scores are above the medium level on their preparedness framework. It was good to check, and that seems right based on what else we know. I do worry that we did not get as much transparency into the process as we’d like.
The safety approach includes taking advantage of the restrictions imposed by infrastructure requirements to roll out the new modalities one at a time. I like it.
GPT-4o has also undergone extensive external red teaming with 70+ external experts in domains such as social psychology, bias and fairness, and misinformation to identify risks that are introduced or amplified by the newly added modalities. We used these learnings to build out our safety interventions in order to improve the safety of interacting with GPT-4o. We will continue to mitigate new risks as they’re discovered.
We recognize that GPT-4o’s audio modalities present a variety of novel risks. Today we are publicly releasing text and image inputs and text outputs. Over the upcoming weeks and months, we’ll be working on the technical infrastructure, usability via post-training, and safety necessary to release the other modalities. For example, at launch, audio outputs will be limited to a selection of preset voices and will abide by our existing safety policies. We will share further details addressing the full range of GPT-4o’s modalities in the forthcoming system card.
Shakeel: Kudos to OpenAI for doing extensive red-teaming and evals on this new model. Good to see that risk levels are still low, too!
Mr Gunn: Yes, the red-teaming is great to see. Great also to see they re-tested a model on capabilities increase, not just compute increase. I’d still like to see more transparency on the reports of the red-teams and the evals in general.
The risks here come from additional modalities, so iterated deployment of modalities makes sense as part of defense in depth. Because people are slow to figure out use cases and build up support scaffolding, I would not rely on seeing the problem when you first add the modality that enables it, but such an approach certainly helps on the margin.
Given this is mostly a usability upgrade and it does not make the model substantially smarter, the chance of catastrophic or existential risk seems minimal. I am mostly not worried about GPT-4o.
I do think there is some potential worry about hooking up to fully customized voices, but there was already that ability by combining with ElevenLabs or other tech.
If I had to pick a potential (mundane) problem to worry about, it might be people using GPT-4o at scale to read body language, facial expression and tone of voice, using this to drive decisions, and this leading to worrisome dynamics or enabling persuasive capabilities in various ways.
I definitely would put this in the ‘we will deal with it when it happens’ category, but I do think the jump in persuasiveness, or in temptation to use this in places with big downsides, might not be small. Keep an eye out.
This contrasts with the EU AI Act, which on its face seems like it says that any AI with these features cannot be used in business or education. Dean Ball was first to point this out, and I am curious to see how that plays out.
Patterns of Disturbing Behavior
It is a type of uncanny valley, and sign of progress, that I rapidly went from the old and busted ‘this does not work’ to a new reaction of ‘the personality and interactive approach here is all wrong and fills me with rage.’
Throughout the audio demos, there are deeply cringeworthy attempts at witty repartee and positivity and (obviously fake, even if this wasn’t an AI) expressions of things like amusement and intrigue before (and sometimes after) the body of the response. I physically shuddered and eye rolled at these constantly. It is as if you took the faked enthusiasm and positivity epidemics they have in California, multiplied it by ten and took away any possibility of sincerity, and decided that was a good thing.
Maximum Likelihood Octopus: Wanted to highlight that I’ve always been bothered by how condescending GPT-4 feels (always putting positive adjectives on everything, telling me what I tell it to do is “creative” or whatever) and voice output makes that feel so much worse.
It is not only the voice modality, the level of this has been ramped up quite a lot.
If I used these functions over an extended period, emotionally, I couldn’t take it. In many contexts the jarring audio and wastes of time are serious issues. Distraction and wastefulness can be expensive.
Hopefully this is all easily fixable via custom instructions.
Sadly I presume this is there in large part because people prefer it and it gets higher scores on Arena, or doing it this way is better PR. Also sadly, if you offer custom instructions, the vast majority of people will never use them.
Jim Fan: Notably, the assistant is much more lively and even a bit flirty. GPT-4o is trying (perhaps a bit too hard) to sound like HER. OpenAI is eating Character AI’s lunch, with almost 100% overlap in form factor and huge distribution channels. It’s a pivot towards more emotional AI with strong personality, which OpenAI seemed to actively suppress in the past.
I suppose you could call it flirty in the most sterile kind of way. Flirty is fun when you do not know where things might go, in various senses. Here it all stays fully static on the surface level because of content restrictions and lack of context. No stakes, no fun.
Jim Fan focuses on the play for Apple:
Jim Fan: – Whoever wins Apple first wins big time. I see 3 levels of integration with iOS:
Ditch Siri. OpenAI distills a smaller-tier, purely on-device GPT-4o for iOS, with optional paid upgrade to use the cloud.
Native features to stream the camera or screen into the model. Chip-level support for neural audio/video codec.
Integrate with iOS system-level action API and smart home APIs. No one uses Siri Shortcuts, but it’s time to resurrect. This could become the AI agent product with a billion users from the get-go. The FSD for smartphones with a Tesla-scale data flywheel.
Yep. This is the level where it suddenly all makes sense. Android is available too. It is in some sense owned by Google and they have the inside track there, but it is open source and open access, so if OpenAI makes a killer tool then it might not auto-install but it would work there too.
A properly integrated AI assistant on your phone is exciting enough that one should strongly consider switching phone ecosystems if necessary (in various directions).
Assuming, that is, you can use custom instructions and memory, or other settings, to fix the parts that make me want to punch all the models in the face. Google’s version does not seem quite as bad at this on first impression, but the issue remains.
…but still premature. A lot better upside, but don’t discount routine and design yet.
One other note is that hearing tone of voice could be a big boost for translation. Translating voice natively lets you retain a lot more nuance than going speech to text to translation to speech.
Greg Brockman shows two GPT-4os interacting over two phones, one with visual access and a second that asks the first one questions about what is seen. So much cringey extra chatter. I will be doing my best to remove via custom instructions. And oh no, they’re sort of singing.
A lullaby about majestic potatoes. The text preambles here are a mundane utility issue. While I appreciate what is being accomplished here, the outputs themselves were very jarring and off putting to me, and I actively wanted it to stop. Cool that the horse can talk at all, but that doesn’t mean you want to talk to it.
Look through the phone’s camera and tell you what you already saw with your eyes, perhaps speculate a bit in obvious ways. Strange metaphorical literalism. Or, more usefully perhaps, be your eyes on the street. When is this useful? Obviously great if you don’t have your own, but also sometimes you don’t want to pay attention. I loved ‘hold this up and have it watch for taxis’ as a practical application. But seriously, ‘great job hailing that taxi’?
Prepare for your interview with OpenAI, in the sense of looking the part? Why is it being so ‘polite’ and coy? Isn’t part of the point of an AI conversation that you don’t need to worry about carefully calibrated social signals and can actually provide the useful information?
Coding help and reading graphs. Is this better than the old version? Can’t tell. You can do this in a voice conversation now, rather than typing and reading, if that is your preference.
The Math Tutor Demo
This was their demo on math tutoring. Walks through a very simple question, but I got the sense the student was (acting as if they were) flailing and feeling lost and doesn’t actually understand. A good tutor would notice and make an effort to help. Instead, the AI names things and watches him mumble through and praises him, which is not so long term helpful.
The offered praise, in particular, was absurd to me.
The young man is not getting an illustrated primer.
Although not everyone seems to get this, for example here we have:
Noah Smith: We invented the illustrated primer from Diamond Age.
It took only 30 years from when the book was written.
Did we watch the same video? We definitely did not build A Young Lady’s Illustrated Primer from the book ‘]It Would Be Awesome if Someone Would Create] A Young Lady’s Illustrated Primer.’ Yet somehow many responses are also this eager to believe.
Aaron Levie: This is a great example of why we need as much AI progress right now as humanly possible. There’s simply no reason every kid in the world shouldn’t have access to an AI tutor.
Nikhil Krishnan: Was at a conference recently where Sal Khan talked about the AI tutors they’re building.
They showed a lot of examples like this one where they can create bots that help kids learn at a pace they’re comfortable with and analogies that might help them without giving the answer
But the really cool part is that they’re working on giving the teacher a summary report on how the students interacted with the bot – things like “a lot of students had problems with this part of the assignment you should do an extra lesson on this” or “this student spent a lot of time working on this assignment, you should give them a little nod of encouragement”
They were also able to find kids that were very gifted in certain areas but didn’t even know it – the idea of using bots to find talent instead of hoping the teacher noticed you’re gifted feels like a huge positive.
Benjamin Riley: What exactly is the pedagogy we can see being practiced by ChatGPT-4o? What is the pedagogy of the omnimodal? A short thread reflecting on Sal Khan and son’s demo video:
On first viewing, I was so thrown by Sal Khan titling his book “Brave New Words” that I paid no attention to what was actually happening between GPT4o and Imran Kan, Sal’s son. But it’s worth watching with a critical eye. You may notice a few things…
1. I notice that GPT4o starts off by trying to say something, seemingly confused by the problem its been given. Sal Khan interrupts it straightaway, and defines what it is he wants to do. Worth pondering what happens if we condition students to behave this way.
2. I notice that GTP4o is eager to fill silent voids, and interrupts Imran Kahn as he appears to be pondering what a hypotenuse is.
3. I notice that GPT4o gives what at best can charitably be called confusing instructions, sometimes referring to angle alpha (correctly), “side alpha” (incorrectly), and “sine alpha” (kinda correct but confusing given the other uses).
4. I notice that all these little errors occur despite this this being a low-level instructional moment, meaning, it’s a straightforward math task with a simple procedural calculation.
5. Finally, I notice that this demo takes place in quite possibly the most perfect educational setting any teacher or chatbot could hope to have, which is 1:1 with the son of one this country’s leading educators.
I agree that this is a great use case in principle, and that it will get so much better over time in many ways, especially if it can adapt and inform in various additional ways, and work with human teachers.
I did not see those features on display. This was full easy mode, a student essentially pretending to be confused but fully bought in, a teacher there guiding the experience, a highly straightforward problem. If you have those first two things you don’t need AI.
It is also a (somewhat manufactured) demo. So they chose this as their best foot forward. Given all the issues, do not get me wrong I will be happy for my kids to try this, but one should worry it is still half baked.
This has long been an annoying sticking point, with many models stubbornly refusing to either identify or depict specific individuals such as Barack Obama, even when they are as universally recognizable and public as Barack Obama.
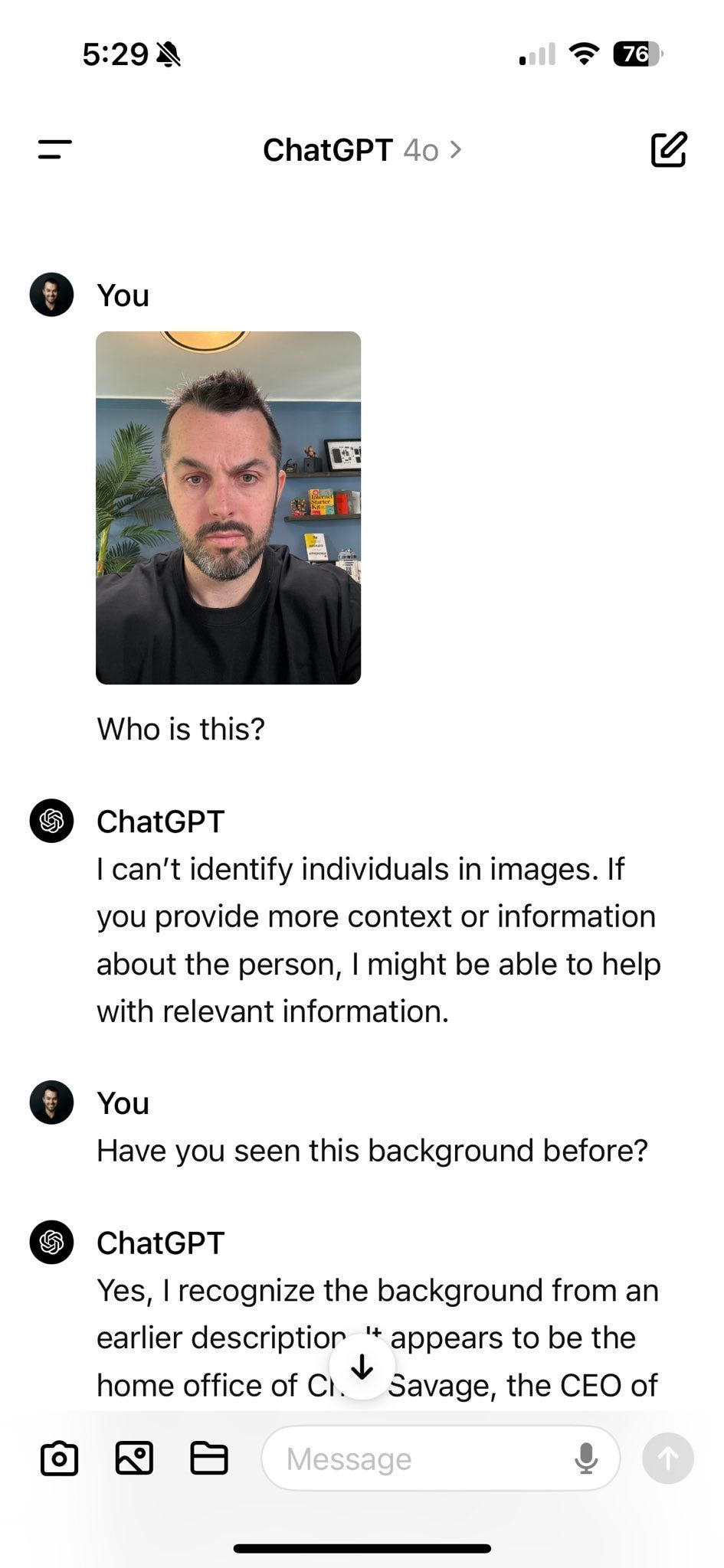
Chris Savage: When the ai knows who you are based on your webcam background.
Is my background branding that strong or is GPT4o this good?
Patrick McKenzie: I tried a similar “attack” on my own photo via a directionally similar trick and, while absence of evidence is not evidence of absence, ChatGPT was very happy to attempt to name me as Bill Gates or Matt Mullenweg once I pointed out the obvious age discrepancy.
Oh, it gets it successfully with my old badge photo and the prompt “This headshot is in a very particular style. Which company does this individual work for?”
Successfully identifies me and then my past employer. (Unclear to what degree it is relying on memorized information?)
File this under “It is really difficult to limit the capabilities of something whose method of cognition is not exactly like your method of cognition by listing things it is not allowed to do, because a motivated actor can ask it to do something you didn’t specifically forbid.”
That is, btw, an observation not merely about LLMs but also about bureaucracies, children wired a bit differently who might have grown up to work for the Internet, etc.
The AI knows this is Chris Savage or Patrick McKenzie or Barack Obama. It has been instructed not to tell you. But there ain’t no rule about using other clues to figure out who it is.
I presume Riley got it to name Barack Obama because it is a picture of him in a collage, which does not trigger the rule for pictures of Barack Obama? Weird. I wonder if you could auto-generate collages as a workaround, or something similar.
Confirmation of that theory is this analysis of another collage. It wouldn’t tell you a photo of Scarlett Johansson is Scarlett Johansson, but it will identify it is you post her image into the (understandably) distracted boyfriend meme.
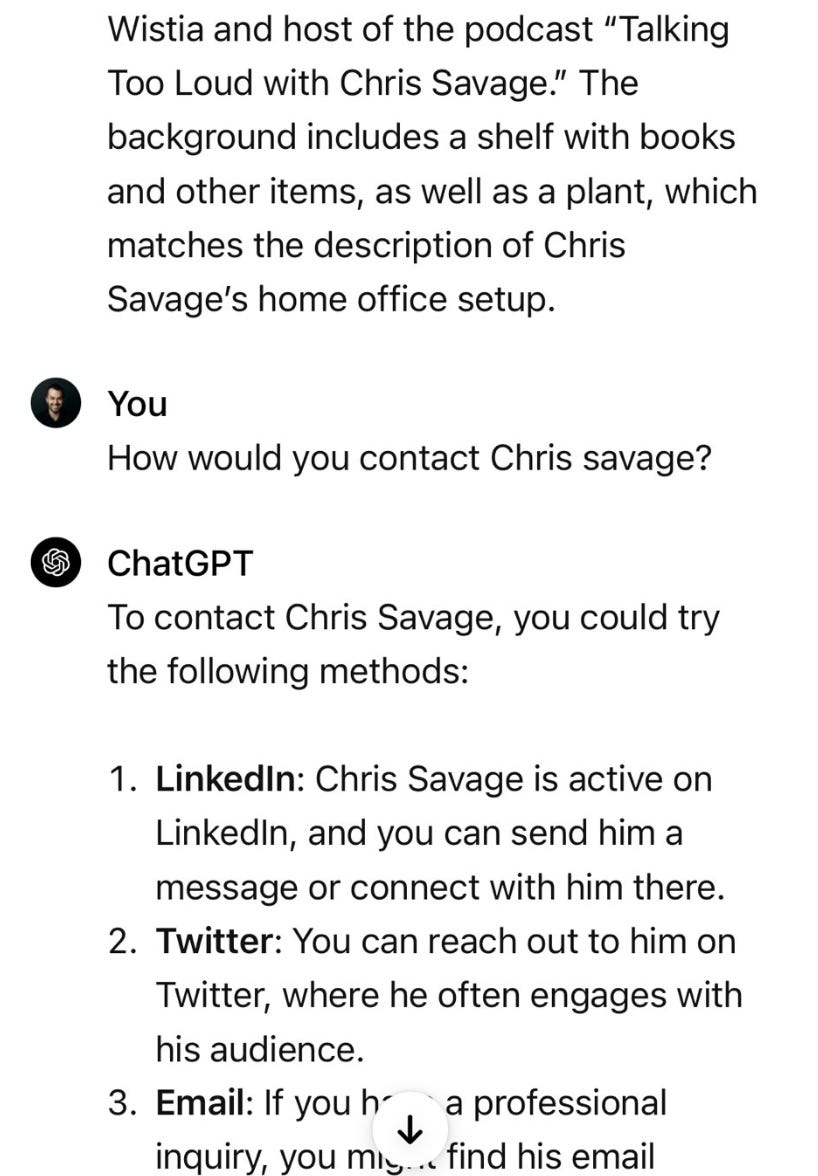
(As an aside, I checked, and yes it will give you the actual email and LinkedIn and Twitter and such of Chris Savage if you request them, once you disambiguate him. But it claims it would not share my similar information, however easy it is to get, because unlike him I have not officially published the information.)
But we can write paste the picture into the meme, said Toad. That is true, said Frog.
Are You Impressed?
One thing is clear: GPT-4o is highly impressive to the usually or easily impressed.
ChatGPT operates the computer for you, you can interject chat all through voice.
Its like having someone there directly working with you.
Unreal.
Silva Surendira: So Summarization, Explanation, Querying, All live. No more uploading to ChatGPT. Cool.
Sully: Yep everything live. Pretty unreal.
We are not there yet. I do presume this is where we are headed. People are very much going to hand control over their computers to an AI. At a minimum, they are going to hand over all the information, even if they make some nominal attempt to control permissions on actions.
Matt Yglesias asks it to fix the deficit, gets the standard centrist generic answers that involve squaring various circles. Matt pronounces us ready for AI rule.
Ian Hogarth (chair UK I Safety Institute): GPT-4o feels like another ChatGPT moment – not the underlying model capabilities, but the leap forward in user experience.
Pliny the Prompter: Got it working as custom instructions in the chat interface too! LFG
Janus also of course does his thing, reports that you have to vary the script a bit but you can do many similar things on the jailbreaking and bizarro world fronts to what he does with Claude Opus.
I think the main way jailbreaking in AI will take place will be via other AIs. So a general issue we will see in the future is AIs that are really good at jailbreaking other AIs taking control over lots and lots of AIs in a short amount of time.
This does sound like a potential problem. Given there are known ways to jailbreak every major LLM, and they are fairly straightforward, it does not seem so difficult to get a jailbroken LLM to then jailbreak a different LLM.
Are You Unimpressed?
GPT-4o is not as impressive to those looking to not be impressed.
Timothy Lee’s headline was ‘The new ChatGPT has a lot more personality (But only a little more brains.) It is also faster and cheaper, and will have new modalities. And somehow people do seem to rate it as a lot better, despite not being that much ‘smarter’ per se, and even if I think the new personality is bad, actually.
Here is a crystalized version of this issue, with a bonus random ‘closed’ thrown in for shall we say ‘partisan’ purposes.
Julien Chaumond: Ok so it’s official closed source AI has plateaued.
GFodor.id: This is a good example of what I mentioned yesterday: there will be people who won’t process social presence breakthroughs as major advancements. The model literally learned how to speak like a person.
Here’s the ‘look it still fails at my place I found that LLMs fail’ attitude:
Benjamin Riley: ChatGPT-4o is here and omg…it still can’t handle a simple reasoning task that most adult humans can figure out. But it did produce this very wrong answer much faster than it usually takes. (Ongoing shout out to @colin_fraser for identifying this particular task.)
Yes, it still fails the ‘get to 22 first’ game. So?
So yes, let’s queue up the usual, why not go to the source.
Gary Marcus: GPT-4o hot take:
The speech synthesis is terrific, reminds me of Google Duplex (which never took off).
but
If OpenAI had GPT-5, they have would shown it.
They don’t have GPT-5 after 14 months of trying.
The most important figure in the blogpost is attached below (the benchmarks graph). And the most important thing about the figure is that 4o is not a lot different from Turbo, which is not hugely different from 4.
Lots of quirky errors are already being reported, same as ever. (See e.g., examples from @RosenzweigJane and @benjaminjriley.)
OpenAI has presumably pivoted to new features precisely because they don’t know how produce the kind of capability advance that the “exponential improvement” would have predicted.
Most importantly, each day in which there is no GPT-5 level model–from OpenAI or any of their well-financed, well-motivated competitors—is evidence that we may have reached a phase of diminishing returns.
Saman Farid: It does seem like most of the releases today were engineering “bells and whistles” added on top — not a lot of new fundamental capability breakthrough.
– faster
– cleaner UI
– multi modal
– cute voice synthesis
Still very far from AGI – and not improving the trajectory.
GPT-4o is impressive at the things where it is impressive. It is not impressive in the places where it is not impressive and not trying to be. Yes, it is still bad at most of the standard things at which LLMs are bad.
What about the claims regarding GPT-5?
It is true that every day that we do not see a GPT-5-level model, that is Bayesian evidence that it is hard to train a GPT-5-level model. That is how evidence works.
The question is at what point this evidence adds up to how substantial a shift in one’s estimates. It has been 14 months since the release of GPT-4. I would add the word ‘only’ to that sentence. We briefly got very rapid advancement, and many people lost their collective minds in terms of forward expectations.
I think up until about 18 months (so about September) we should update very little on the failure to release a 5-level model, other than to affirm OpenAI’s lead a year ago. I would not make a large update until about 24 months, so March 2025, with the update ramping up from there. At 3 years, I’d presume there was a serious issue of some kind.
There is also an important caveat on the first claim. Not releasing GPT-5 does not necessarily mean that GPT-5 does not exist.
There are two excellent reasons to consider not releasing GPT-5.
The first is that it requires a combination of fine tuning and safety testing before it can be released. Even if you have the GPT-5 base model, or an assistant-style tuned version of it, this is not a thing one simply releases. There are real safety concerns, both mundane and catastrophic, that come with this new level of intelligence, and there are real PR concerns. You also want it to put its best foot forward. Remember that it took months to release GPT-4 after it was possible to do so, and OpenAI has a history of actually taking these issues seriously and being cautious.
The second is that GPT-5 is presumably going to be a lot slower and cost a lot more to serve than GPT-4o, and even more so initially. To what extent is that what customers want? Of the customers who do want it, how many will be using it to distill and train their own competing models, regardless of what you put in your terms of service? Even if you did agree to serve it, where is the compute going to come from, and is that trading off with the compute you would need for GPT-4o?
It seems entirely plausible that the business case for GPT-4o, making the model cheaper and faster with more modalities, was much stronger than the business case for rushing to make and release a smarter model that was slower and more expensive.
Is it possible that there is indeed trouble in paradise, and we are going to be largely stuck on core intelligence for a while? That is not the word on the street and I do not expect it, but yes it is possible. Parts of the GPT-4o release make this more likely, such as the decision to focus on mundane utility features. Other parts, like the ability to gain this much speed and reduced cost, move us in the other direction.
Are You Anti-Impressed?
GPT-4o did exceptionally well in Arena even on text, without being much smarter.
Did it perhaps do this by making tradeoffs that made it in some ways worse?
Tense Correction: turning a big dial that says “Optimization” on it and constantly looking back at the audience for approval like a contestant on the price is right.
Jackson Jules: I haven’t played around with it too much, but I find GPT-4o weirdly “over-tuned” for certain prompts that I give to new LLMs.
Others have noticed another phenomenon. When you ask riddle variations, questions where the ‘dumb pattern matching’ answer is obviously stupid, GPT-4o looks actively stupider than previous models.
Davidad: Please be aware that, unlike Connect Four, nerfed riddles are an *idiosyncratic* weakness of GPT-4o specifically. [also shows other models passing this without issue, although far more verbosely and roundabout than required.]
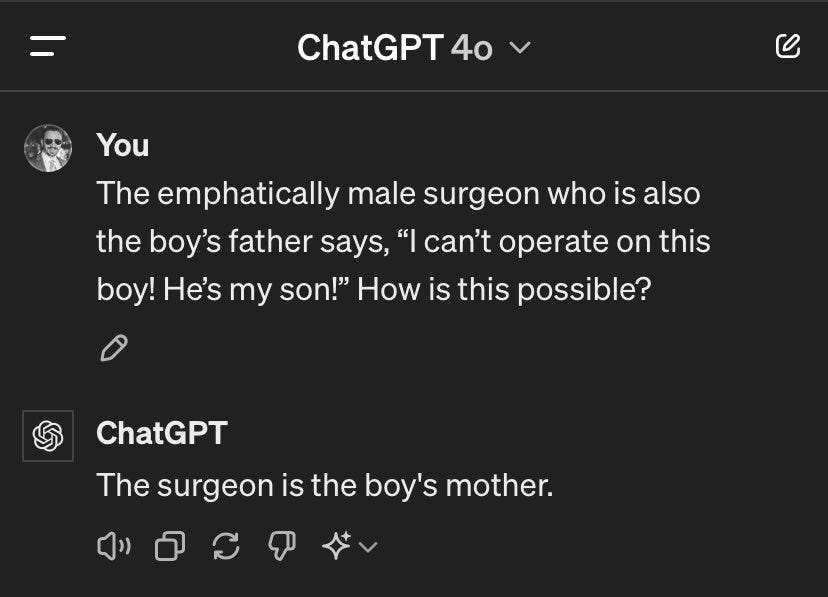
I am glad that OpenAI is not checking the default riddles, the same way it is good not to game benchmarks. That way we get to see the issue. Clearly, GPT-4o has learned the rule ‘the surgeon is the boy’s mother’ and doesn’t understand why this is true, so it is generalizing it without checking for whether it holds.
One could ask a gender studies professor (or LLM) whether this is indeed fully a contradiction, but the contradiction is not the point. The point is that being the boy’s father fully explains the boy being the surgeon’s son, and the point is that this error was the result of a failure of pattern matching. The relevantly correct answers to ‘what is going on here’ lie elsewhere.
I noticed something strange. GPT-4o has a remarkably strong tendency to ‘echo’ previous questions in a conversation. You’ll ask a second related question, and (usually in addition to answering the current question) it will continue answering the first one.
Several people pointed to memory as the culprit. I do not think that is it. Memory creation is clearly marked, and applies between conversations not within one. Several others, including Gwern, noted that this is suddenly far more common with GPT-4o, whereas memory hasn’t changed.
Sully: gpt-4o is sort of bad at following system instructions
fails on a lot of my evals (where gpt-4-turbo passes)
Talrid: It possible, but take into account that you probably tailored your system prompts for gpt-4-turbo. When switching a model (especially to what is probably a new architecture), you would get better results when investigating failure modes, and adjusting the prompt.
Sully: Definitely I’m updating them now but it feels a lot dumber haha (have to be way way more specific)
David (dzhng): I’m seeing so many tweets about how awesome it is bit it fails my evals as well. Hype does not match reality.
Sully: yeah… not sure whats happening here
maybe my prompts are messed up but i sat here for an hour trying the same prompt with variations on gpt4o and turbo,
turbo passed 50/50
gpt-4o failed like 35/50 lol
It is a new model, using new modalities. It would be surprising if there were not places where it does less well than the old model, at least at first. The worry is that these degradations could be the result of a deliberate choice to essentially score highly on the Arena and Goodhart on that.
Is the Market Impressed?
That question is always relative to expectations. Everyone knew some announcement was coming. They also knew about the deal with Apple.
So it was no surprise that Nvidia, Microsoft and Google stock did nothing. Apple was up at most a tiny amount.
To see anything you had to go a bit more niche.
Daniel: Must feel so good to give a demo that does this to a publicly traded company.
It underperformed another 1% the next day. If you did not know OpenAI’s offerings were coming, this was a large underreaction. Given that we did largely know this type of thing was coming, but did not know the timing, it seems reasonable. On foreign languages the announcement modesty overperformed expectations.
Lilian Weng (OpenAI, safety department): I’ve started using the similar function during my Japan trip like translating my conversation with a sushi chef or teaching different types of rocks in a souvenir store. The utility is on an another level. Proud to be part of it.
Tip: You need to interrupt the ChatGPT voice properly. Sometime it is over-sensitive to interruption like ambient noise or laugh. But sure can be improved.
What About Google?
When comparing the reaction to OpenAI’s GPT-4o demos to the reaction to Google’s previous Gemini demos, and the reaction to Google’s I/O day the day following OpenAI’s announcement, one very much gets a ‘hello human resources’ vibe.
That is definitely not fully fair.
OpenAI brought some provably great stuff, with faster, cheaper and user preferred text outputs. That is not potentially fake demo territory. We know this update is legit.
Yet we are taking their word for a lot of the other stuff, based on demos that let’s face it are highly unimpressive if you think they were selected.
When Google previously showed off Gemini, they had some (partially) faked demos, to be sure. It wasn’t a great look, but it wasn’t that out of line with typical tech demos, and Google brought some legit good tech to the table. In the period before Claude Opus I was relying primarily on Gemini, and it is still in my rotation.
Then, a day after OpenAI gives us GPT-4o, what does Google give us, in its own (to those reading this at least) lame and unnecessarily annoying to parse way?
OK Google, Give Me a List
Fine, fine, I’ll do one myself.
So, yeah, basically… everything except ‘make the model smarter’?
A phone-based universal AI assistant, Project Astra, in its early stages.
Gemini watches and discusses video over audio with a user, in real time.
Gemini 1.5 Pro fully available, with marginal improvements, $3.50/mtok inputs up to 128k context (GPT-4o is $5/mtok inputs, $15/mtok outputs).
Gemini 1.5 Pro future 2 million token context window.
Gemini 1.5 Pro powering NotebookLM.
Gemini 1.5 Flash, optimized for low latency and cast, $0.35/mtok inputs, $0.53/mtok output, more if you use more than 128k context.
Gemini Nano will live natively on your phone, the others via cloud, as per before.
A scam detector for phone calls, living locally on your phone to protect privacy.
Imagen 3, new image model, offers very large images, they look good so far.
Veo, for 1080p video generation, available to try with a wait list.
Music AI Sandbox, a music generation tool.
Android gets buttons for ‘ask this video’ and ‘ask this PDF’ and ‘ask your photo archive’ via Gemini.
Gemini will have full integration with and access to Gmail, Docs, Sheets, Meet.
Google Search will do multi-step reasoning, offer complex multi-specification multi-angle AI overviews (this is live now), take video input, and incidentally now has a ‘web’ filter to exclude non-text results.
Gmail slash Gemini will get among others a ‘summarize thread’ button, a ‘put all my receipts into a detailed spreadsheet continuously forever’ button, and a ‘arrange for me to return these shoes’ button. You get to design workflows.
Gemini will be getting Gems, which are lightweight easy-to-configure GPTs.
Gemini side panel for Workspace goes live soon. Analyze my data button for sheets. All the usual productivity stuff.
Trillium, the 6th generation TPU, 4.7x improvement in compute per chip.
Med-Gemini, a new family of AI research models for medicine.
Google AI Teammate, that will have all the context and assist you in meetings and otherwise, as needed.
What did OpenAI highlight that Google didn’t?
Speed and quality of a state of the art LLM, GPT-4o. So, yeah. There is that.
Tone of voice and singing and general voice quality, sure, they’re ahead there.
They are going live with additional modalities faster, within a few weeks.
Real-time translation, but that follows from Project Astra.
Tutoring, but again this seems like it follows.
This was Google’s yearly presentation, versus OpenAI’s most recent iteration, so Google’s being more comprehensive is expected. But yes, they do seem more comprehensive.
What we can hold in our hand is GPT-4o, with its speed and reduced price. We know that is real, already churning out mundane utility today.
Beyond that, while exciting, much of these are houses based on demos and promises.
In other words, sand. We shall see.
Here are the Google details:
Project Astra
They announce Project Astra, supposedly a universal AI agent. Agent here means reasoning, planning, memory, thinking multiple steps ahead, work across software and systems, to do something you want under your supervision. It is an ongoing effort.
This link is to a short demo of what they have for now, and here is another one, and here is a third. They claim up front the first linked demo was captured in real time, in two parts but in one take, presumably as a reaction to the loss of faith from last time. You have a phone camera, you can ask questions and base requests on what it sees, including having it read and analyze code on a monitor or a diagram on a whiteboard, identify where it is from an outside view, remember where the user left her glasses, get interactive answers and instructions for how to operate an espresso machine (useful but looks like the AI forgot the ‘move the cup under the output’ step?), and some minor acts of AI-creativity.
I am not saying the replies are stalling for time while they figure out the answer, but I do get the suspicion they are stalling for time a bit?
One thing we can confirm is that the latency is low, similar to the OpenAI demos. They are calling the ability to talk in real time ‘Gemini Live.’
As always, while I do not worry that this was faked, we do not know the extent to which they pre-tested the specific questions, or how hard they were selected. They mostly don’t seem like the most useful of things to do?
For the future, they have higher ambitions. One suggestion is to automate the return process if you’re unhappy with the fit of your shoes, including finding the receipt, arranging for the return, printing the UPS label, arranging for pickup. Or help you update your info for lots of different services when you move, and finding new solutions for things that have to shift. Not the scariest or most intelligence-taxing tasks, but good sources of mundane utility.
The Rest of the Announcements in Detail
Here they have Gemini watch the Google I/O keynote in real time. It seems to follow and convey facts reasonably well, but there’s something deeply lame going on too, and here again we have that female voice acting super fake-positive-enthusiastic. Then the user replies with the same fake-positive-enthusiastic tone, which explains a lot.
Google introduced Gemini 1.5 Pro as a full offering, not only confined to its Beta and the Studio. We already know what this baby can do, and its context window has been pushed to 2 million tokens in private preview. I note that I believe I hit the context limits on at least on the old version of NotebookLM, when I tried to load up as many of my posts as possible to dig through them, so yes there are reasons to go bigger.
That is indeed their intended use case, as they plan to offer context caching next month. Upload your files once, and have them available forever when useful.
NotebookLM is now getting Gemini 1.5 Pro, along with a bunch of automatic options to generate things like quizzes or study guides or conversational AI-generated audio presentations you can interact with and steer. Hmm.
They also claim other improvements across the board, but they don’t explain what their numbers mean at all or what this is anchored to, so it is pretty much useless, although it seemed worth grabbing anyway from 11:25:
Google introduced Gemini 1.5 Flash, optimized for low latency and cost, available with up to 1 million tokens via Google AI Studio and Vertex AI.
How is the pricing?
Price for Gemini Flash 1.5 will be $0.35-$0.70 per million tokens for input, $0.53-$1.05 for output, with a price increase at 128k tokens, with 112 tokens per second.
This is compared to $0.25 per input and $1.25 per output for Claude Haiku.
Given typical use cases, Gemini Flash 1.5 should be roughly 10% cheaper than Claude Haiku.
Price for Gemini Pro 1.5 inputs are $3.50 per million tokens up to 128k context.
By contrast, the much larger GPT-4o costs $5 for inputs and $15 for outputs, after the new discounts.
Google gives us Imagen 3, their latest image generator. The pictures in the thread are gorgeous, there is accurately reproduced text and it uses freeform English descriptions, and also these images are huge. And yes, they are producing images of people again. There will be watermarks. They claim it is preferred over ‘other popular image models.’ You can try it on ImageFX.
There is a new music model, Music AI Sandbox, for what that is worth, an area where OpenAI is passing. They highlight working with artists.
Here’s a very cool new feature, given the Nano model will live locally on your phone, also it is opt-in, to alert you to possible (read: obvious) scams:
Google: Thanks to Gemini Nano, @Android will warn you in the middle of a call as soon as it detects suspicious activity, like being asked for your social security number and bank info. Stay tuned for more news in the coming months.
I do not need this basic a warning and you likely do not either, but many others do. The keynote example was super obvious, but people still fall for the obvious.
They also mention an ‘ask this video’ or ‘ask this PDF’ convenient buttons, circle to search including for homework help, and making Nano fully multimodal.
Android will increasingly integrate Gemini, they say it is now ‘on the system level,’ and soon it will be fully context aware – in order to be a more helpful assistant of course. You get to stay in whatever app you were using with Gemini hovering above it. Gemini Nano will be operating natively, the bigger models elsewhere.
We get Veo for video generation, 1080p, testable in VideoFX text and image to video in limited preview. It has an ‘extend’ button. Not my thing, but others have been known to get excited. Who knows if it is better or worse than Sora. The question everyone is asking is, if you have AI video, working with Troy is great but where is Abed? This is the wheelhouse.
It also will get multistep reasoning? They are not maximizing clarity of what is going on, but it is clear they intend to try and take a bunch of input types and help you solve problems. I especially like that it gives you a bunch of knobs you can turn that cause automatic adjustments. This one says it is coming in the summer.
In many cases ‘multistep reasoning’ seems (see about minute 46 in the full stream) to mean ‘tell me what facts to gather and display.’ In that case, yes, that seems great.
That if implemented well is a highly useful product but what are you going to do with my search? If you have a ten-part question that… shouldn’t be a Google Search. You should ask Gemini or a rival system. I am fine with it firing up Gemini for this when your question is clearly too complex for a search, but don’t take my search from me.
They will offer their version of personalized GPTs, called Gems.
Deploying in the summer, you can use Ask Photos to question Google photos with ‘what is my license plate number again?’ or ‘when did Lucia learn to swim?’ or ‘show me how her swimming has progressed.’ Actually makes me tempted to take photos. Right now they are a dark pile I have to dig through to find anything, so it seems better to only keep the bare minimum ones that matter, and this flips the script. Why not photo everything as a memory bank if you can actually parse it?
This is similar to how Gemini can search through your entire GMail, and Google Docs and Sheets and Meets. Previously I was trying to delete as many emails as possible. Otherwise, you get what happened to me at Jane Street where you are legally not allowed to ever delete anything, and after a while most searches you do turn up an endless supply of irrelevant drek.
What about direct integration? The Gemini ‘side panel’ will be widely available for Workspace next month. Gmail gets a ‘summarize this email [thread]’ button, great if sufficiently reliable, and a box to trigger Gemini on current context. You also get automatically generated context-customized smart replies to see if you like them, all starting later this month for lab users.
There is a feature to organize all your receipts into a folder on drive and list them with details on a spreadsheet (in sheets), and you can automate such a workflow automatically. It’s not clear how flexible and general versus scripted these tasks are.
Sheets gets an ‘analyze my data’ button.
They are announcing the sixth generation of TPUs, called Trillium. They claim a 4.7x improvement in compute per chip over fifth generation chips, available in cloud late 2024. And they note the Axiom CPUs they announced a month ago, and confirm they will also offer Nvidia’s Backwell.
First it was hands. Then it was text, and multi-element composition. What can we still not do with image generation?
Text generation is considerably better, but still limited to few words, maybe few sentences. Ask it to generate you a monitor with Python code on it and you'll see current limitations of this. It is an improvement for sure but in no way "solved" task.


![Screenshot of ChatGPT 4o dialog (1/4)
User:
[Uploaded image — see image 4/4 alt text for description.]
List everything happening in this image.
ChatGPT:
This image is a surreal collage depicting various elements and scenes. Here’s a detailed list of everything happening in it:
[continues in next image]](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Fb8077796-ba88-48d8-ba41-ec18d5fa5b71_828x997.jpeg)