Regularization Causes Modularity Causes Generalization
post by dkirmani · 2022-01-01T23:34:37.316Z · LW · GW · 7 commentsContents
Things That Cause Modularity In Neural Networks Modularity Improves Generalization How Dropout Causes Modularity How L1/L2 Regularization Causes Modularity None 7 comments
Epistemic Status: Exploratory
Things That Cause Modularity In Neural Networks
Modularity is when a neural network can be easily split into several modules: groups of neurons that connect strongly with each other, but have weaker connections to outside neurons. What, empirically, makes a network become modular? Several things:
- Filan et al.[1]:
- Training a model with dropout
- Weight pruning
- L1/L2 regularization
- Kashtan & Alon: Switching between one objective function and a different (but related[2]) objective function every 20 generations
- Clune et al.: Adding penalties for connections between neurons
Modularity Improves Generalization
What good is modularity? Both Clune et al. and Kashtan & Alon agree: more modular networks are more adaptable. They make much more rapid progress towards their goals than their non-modular counterparts do:
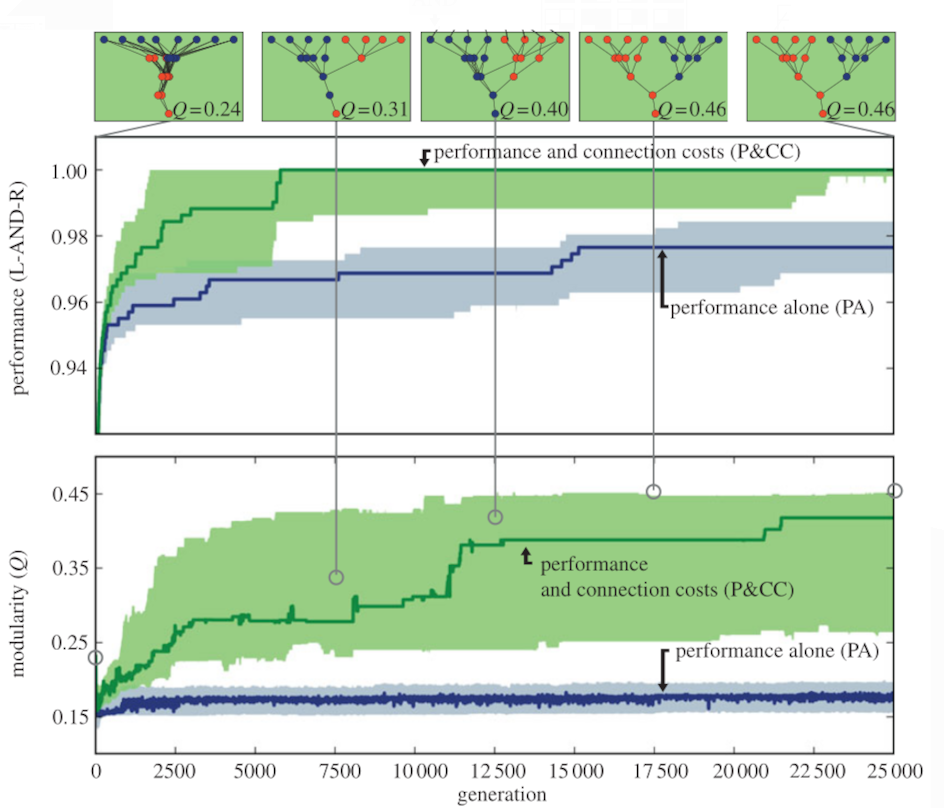
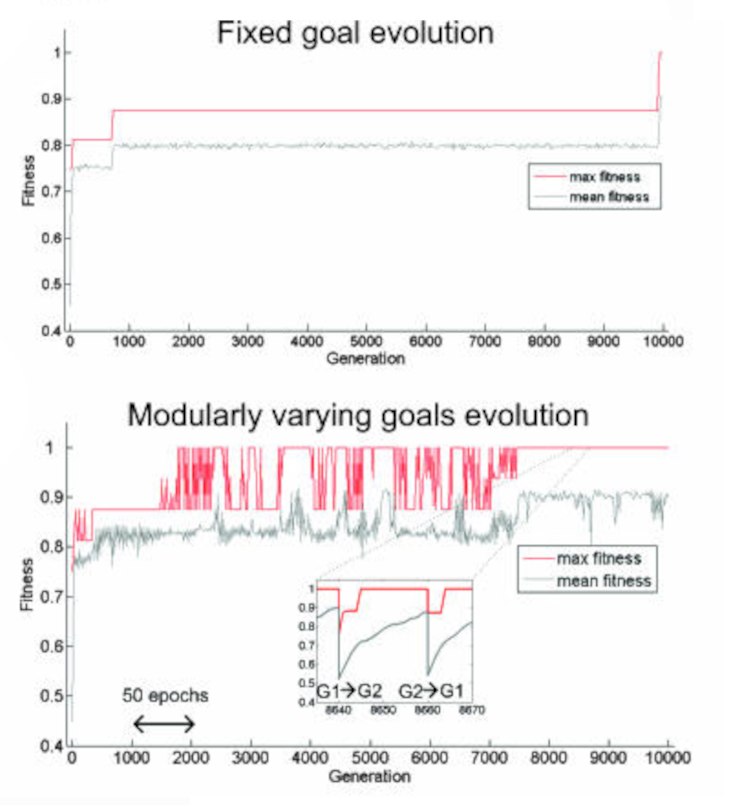
Modular neural networks, being more adaptable, make faster progress towards their own goals. Not only that, but their adaptability allows them to rapidly advance on related[2:1] goals as well; if their objective function was to suddenly switch to a related goal, they would adapt to it much quicker than their non-modular counterparts.
In fact, modular neural networks are so damn adaptable that they do better on related goals despite never training on them. That's what generalization is: the ability to perform well at tasks with little to no previous exposure to them. That's why we use L1/L2 regularization, dropout, and other similar tricks to make our models generalize from their training data to their validation data. These tricks work because they increase modularity, which, in turn, makes our models better at generalizing to new data.
How Dropout Causes Modularity
What's true for the group is also true for the individual. It's simple: overspecialize, and you breed in weakness. It's slow death.
—Major Kusanagi, Ghost in the Shell
Training with dropout is when you train a neural network, but every neuron has a chance of 'dropping out': outputting zero, regardless of its input. In practice, making 20-50% of your model's neurons spontaneously fail during training usually makes it much better at generalizing to previously unseen data.
Ant colonies have dropout. Ants die all the time; they die to war, to famine, and to kids with magnifying glasses. In response, anthills have a high bus factor. Not only do anthills have specialist ants that are really good at nursing, foraging, and fighting, they also have all-rounder ants that can do any of those jobs in an emergency:
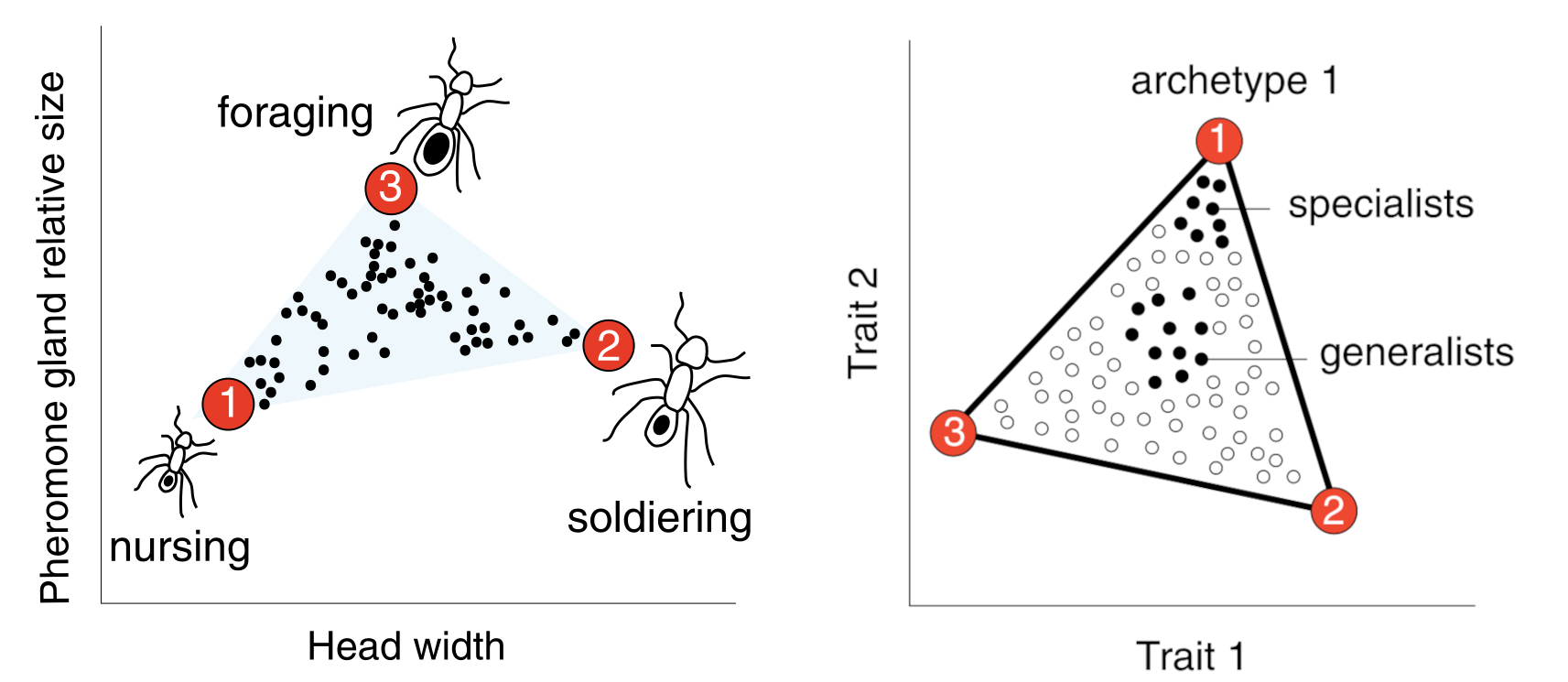
Dropout incentivizes robustness to random module failures. One way to be robust to random module failures is to have modules that have different specialties, but can also cover for each other in a pinch. Another way is to have a bunch of modules that all do the exact same thing. For a static objective function, from the perspective of an optimizer:
- If you expect a really high failure rate (like 95%), you should make a bunch of jack-of-all-trades modules that're basically interchangeable.
- If you expect a moderate failure rate (like 30%), you should make your modules moderately specialized, but somewhat redundant. Like ants!
- If you expect no failures at all, you should let modules be as specialized as possible in order to maximize performance.
- Do that, and your modules end up hyperspecialized and interdependent. The borders between different modules wither away; you no longer have functionally distinct modules to speak of. You have a spaghetti tower [LW · GW].
- Why would modules blur together? "Typically, there are many possible connections that break modularity and increase fitness. Thus, even an initially modular solution rapidly evolves into one of many possible non-modular solutions." —Design Principles of Biological Circuits (review [LW · GW], hardcopy, free pdf)
Dropout is performed on neurons, not "modules" (whatever those are), so why does this argument even apply to neural networks? Modules can have sub-modules, and sub-modules can have sub-sub-modules, so (sub-)-modules are inevitably going to be made up of neurons for some value of . The same principle applies to each level of abstraction: redundancy between modules should increase with the unreliability of those modules.
So dropout incentivizes redundancy. How does that boost modularity? A system built from semi-redundant modules is more, uh, modular than an intricately arranged spaghetti tower. Not all functionally modular systems have redundant elements, but redundant systems have to be modular, so optimization pressure towards redundancy leads to modularity, which leads to generalization.
How L1/L2 Regularization Causes Modularity
L1/L2 regularization makes parameters pay rent [LW · GW]. Like dropout, L1/L2 regularization is widely used to make neural networks generalize better. L1 regularization is when you add a term to the objective function that deducts points proportional to the sum of the magnitudes of all of a model's parameters. L2 regularization is the same thing, but you square the parameters first, and take the square root at the end.
The primary effect of L1/L2 regularization is to penalize connections between neurons, because the vast majority of neural network parameters are weights, or connections between two neurons. Weight pruning, the practice of removing the 'least important' weights, also has a similar effect. As we know from Filan et al., L1/L2 regularization and weight pruning both increase the modularity of neural networks.
Connection costs don't just increase the modularity of artificial neural networks. They increase modularity for biological neural networks too! From Clune et al.:
The strongest evidence that biological networks face direct selection to minimize connection costs comes from the vascular system and from the nervous systems, including the brain, where multiple studies suggest that the summed length of the wiring diagram has been minimized, either by reducing long connections or by optimizing the placement of neurons. Founding and modern neuroscientists have hypothesized that direct selection to minimize connection costs may, as a side-effect, cause modularity.
The authors of this paper then go on to suggest that all modularity in biological networks is caused by connection costs. Whether or not that's true[3], it's clear that optimizers that penalize connections between nodes produce more modular networks. Natural selection and ML researchers both happened upon structures with costly connections, and both found them useful for building neural networks that generalize.
One other thing that increases modularity is just training a neural network; trained networks are more modular than their randomized initial states. ↩︎
When I say "related goals", I mean goals that share subgoals / modular structure with the original goal. See Evolution of Modularity [LW · GW] by johnswentworth. ↩︎ ↩︎
7 comments
Comments sorted by top scores.
comment by Kaj_Sotala · 2022-01-02T07:23:04.303Z · LW(p) · GW(p)
Great post!
If you expect no failures at all, you should let modules be as specialized as possible in order to maximize performance.
- Do that, and your modules end up hyperspecialized and interdependent. The borders between different modules wither away; you no longer have functionally distinct modules to speak of. You have a spaghetti tower [LW · GW].
I'm a little confused by this bit, because intuitively it feels like hyperspecialization = hypermodularity? In that if a module is a computational unit that carries out a specific task, then increased specialization feels like it should lead to there being lots and lots of modules, each focused on some very narrow task?
Replies from: dkirmani↑ comment by dkirmani · 2022-01-02T07:49:21.945Z · LW(p) · GW(p)
Thank you!
Yeah, that passage doesn't effectively communicate what I was getting at. (Edit: I modified the post so that it now actually introduces the relevant quote instead of dumping it directly into the reader's visual field.) I was gesturing at the quote from Design Principles of Biological Circuits that says that if you evolve an initially modular network towards a fixed goal (without dropout/regularization), the network sacrifices its existing modularity to eke out a bit more performance. I was also trying to convey that the dropout rate sets the specialization/redundancy tradeoff.
So yeah, a lack of dropout would lead to "lots and lots of modules, each focused on some very narrow task", if it wasn't for the fact that not having dropout would also blur the boundaries between those modules by allowing the optimizer to make more connections that break modularity and increase fitness. Not having dropout would allow more of these connections because there would be no pressure for redundancy, which means less pressure for modularity. I hope that's a more competent explanation of the point I was trying to make.
comment by J Bostock (Jemist) · 2022-01-03T18:19:18.753Z · LW(p) · GW(p)
This is a great analysis of different causes of modularity. One thought I have is that L1/L2 and pruning seem similar to one another on the surface, but very different to dropout, and all of those seem very different to goal-varying.
If penalizing the total strength of connections during training is sufficient to enforce modularity, could it be the case that dropout is actually just penalizing connections? (e.g. as the effect of a non-firing neuron is propagated to fewer downstream neurons)
I can't immediately see a reason why a goal-varying scheme could penalize connections but I wonder if this is in fact just another way of enforcing the same process.
Replies from: dkirmani↑ comment by dkirmani · 2022-01-03T19:01:33.439Z · LW(p) · GW(p)
Thanks :)
One thought I have is that L1/L2 and pruning seem similar to one another on the surface, but very different to dropout, and all of those seem very different to goal-varying.
Agreed. Didn't really get into pruning much because some papers only do weight pruning after training, which isn't really the same thing as pruning during training, and I don't want to conflate the two.
Could it be the case that dropout is actually just penalizing connections? (e.g. as the effect of a non-firing neuron is propagated to fewer downstream neurons)
Could very well be, I called this post 'exploratory' for a reason. However, you could make the case that dropout has the opposite effect based on the same reasoning. If upstream dropout penalizes downstream performance, why don't downstream neurons form more connections to upstream neurons in order to hedge against dropout of a particular critical neuron?
I can't immediately see a reason why a goal-varying scheme could penalize connections but I wonder if this is in fact just another way of enforcing the same process.
Oh damn, I meant to write more about goal-varying but forgot to. I should post something about that later. For now, though, here are my rough thoughts on the matter:
I don't think goal-varying directly imposes connection costs. Goal-varying selects for adaptability (aka generalization ability) because it constantly makes the model adapt to related goals. Since modularity causes generalization, selecting for generalization selects for modularity.
comment by Chris Beacham (chris-beacham) · 2022-01-03T21:31:58.221Z · LW(p) · GW(p)
Are large models like Mu-Zero, or GPT3 trained with these kinds of dropout/modularity/generalizability techniques? Or should we expect that we might be able to make even more capable models by incorporating this?
↑ comment by dkirmani · 2022-01-03T21:55:14.408Z · LW(p) · GW(p)
Good question! I'll go look at those two papers.
- The GPT-3 paper doesn't mention dropout, but it does mention using Decoupled Weight Decay Regularization, which is apparently equivalent to L2 regularization under SGD (but not Adam!). I imagine something called 'Weight Decay' imposes a connection cost.
- The MuZero paper reports using L2 regularization, but not dropout.
My intuition says that dropout is more useful when working with supervised learning on a not-massive dataset for a not-massive model, although I'm not yet sure why this is. I suspect this conceptual hole is somehow related to Deep Double Descent [LW · GW], which I don't yet understand on an intuitive level (Edit: looks like nobody does). I also suspect that GPT-3 is pretty modular even without using any of those tricks I listed.