Going Beyond Linear Mode Connectivity: The Layerwise Linear Feature Connectivity
post by zhanpeng_zhou · 2023-07-20T17:38:13.476Z · LW · GW · 13 commentsThis is a link post for https://openreview.net/pdf?id=vORUHrVEnH
Contents
Background Layerwise Linear Feature Connectivity Why Does LLFC Emerge? Conclusion Acknowledgement Reference None 13 comments
Hi! I am excited to share our new work Going Beyond Linear Mode Connectivity: The Layerwise Linear Feature Connectivity [NeurIPS 2023 Accepted] with the LessWrong Community. In our new work, we introduce a stronger notion of linear connectivity, Layerwise Linear Feature Connectivity (LLFC), which says that the feature maps of every layer in different trained networks are also linearly connected.
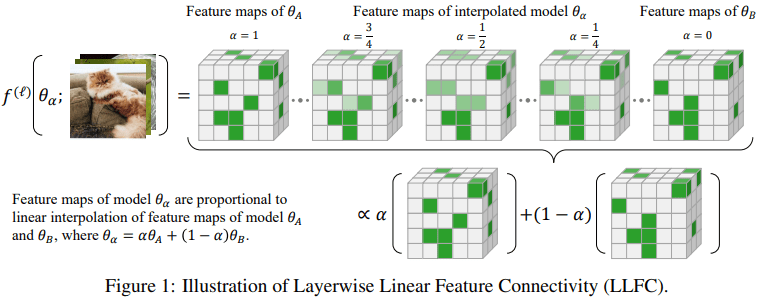
Background
For years, despite the successes of modern deep neural networks, theoretical understanding of them still lags behind. While the loss functions used in deep learning are often regarded as complex black-box functions in high dimensions, it is believed that these functions, particularly the parts encountered in practical training trajectories, contain intricate benign structures that play a role in facilitating the effectiveness of gradient-based training.
One intriguing phenomenon discovered in recent work is Mode Connectivity [1, 2]: Different optima found by independent runs of gradient-based optimization are connected by a simple path in the parameter space, on which the loss or accuracy is nearly constant. More recently, an even stronger form of mode connectivity called Linear Mode Connectivity (LMC) (as shown in Definition 1) was discovered [3]. It said the networks that are jointly trained for a short number of epochs before going to independent training are linearly connected, referred as spawning method. With the empirical understanding, two networks (modes) that are linearly connected can be viewed as entering into the same basin in the loss landscape.

Surprisingly, [4] first demonstrate that two completely independently trained ResNet models (trained on CIFAR10) could be connected after accounting for permutation invariance. In particular, [4, 5] found that one can permute the weights in different layers while not changing the function computed by the network. Based on such permutation invariance, [4, 5] could align the neurons of two independently trained networks such that the two networks could be linearly connected, referred as permutation method. Therefore, [4, 5] conjectured that most SGD-solutions (modes) are all in one large basin in the loss landscape.
Layerwise Linear Feature Connectivity
The study of LMC is highly motivated due to its ability to unveil nontrivial structural properties of loss landscapes and training dynamics. On the other hand, the success of deep neural networks is related to their ability to learn useful features, or representations. Therefore, a natural question emerges:
what happens to the internal features when we linearly interpolate the weights of two trained networks?
Our main discovery, referred to as Layerwise Linear Feature Connectivity (LLFC), is that the features in almost all the layers also satisfy a strong form of linear connectivity: the feature map in the weight-interpolated network is approximately the same as the linear interpolation of the feature maps in the two original networks (see Figure 1 for illustration).
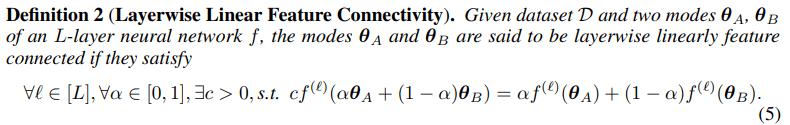
We found LLFC co-occurs with the Linear mode connectivity (LMC). Once two optima (modes) satisfy the LMC, they also satisfy the LLFC. LLFC is a much finer-grained characterization of linearity than LMC. While LMC only concerns loss or accuracy, which is a single scalar value, LLFC establishes a relation for all intermediate feature maps, which are high-dimensional objects.
Moreover, provably, LLFC also implies LMC (Check lemma 1). It is not difficult to see that LLFC applied to the output layer implies LMC when the two networks have small errors (see Lemma 1).
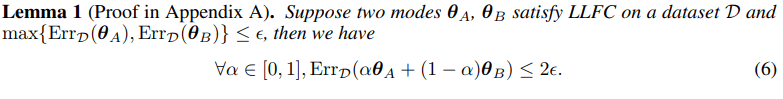
Why Does LLFC Emerge?
Subsequently, we delve deeper into the underlying factors contributing to LLFC. We identify two critical conditions, weak additivity for ReLU function (see definition 3) and a commutativity property (see definition 4) between two trained networks.
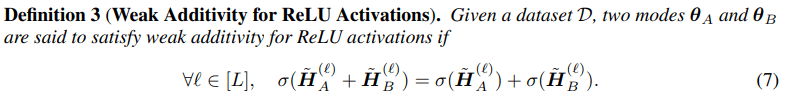
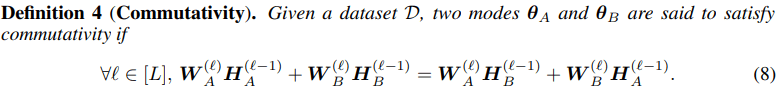
We prove that these two conditions collectively imply LLFC in ReLU networks (see Theorem 1).
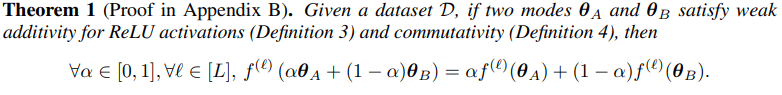
Furthermore, our investigation yields novel insights into permutation approaches: we interpret both the activation matching and weight matching objectives in Git Re-Basin [4] as ways to ensure the satisfaction of commutativity property.
Conclusion
We identified Layerwise Linear Feature Connectivity (LLFC) as a prevalent phenomenon that co-occurs with Linear Mode Connectivity (LMC). By investigating the underlying contributing factors to LLFC, we obtained novel insights into the existing permutation methods that give rise to LMC.
Acknowledgement
A big thank to my collaborators, Yongyi Yang, Xiaojiang Yang, Junchi Yan and Wei Hu.
Also, thanks to Bogdan for recommending such an amazing platform so that I can share my work with you!
Reference
[1] C. Daniel Freeman and Joan Bruna. Topology and geometry of half-rectified network optimization. In International Conference on Learning Representations, 2017.
[2] Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred Hamprecht. Essentially no barriers in neural network energy landscape. In International conference on machine learning, pages 1309–1318. PMLR, 2018.
[3] Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning, pages 3259–3269. PMLR, 2020
[4] Samuel Ainsworth, Jonathan Hayase, and Siddhartha Srinivasa. Git re-basin: Merging models modulo permutation symmetries. In The Eleventh International Conference on Learning Representations, 2023.
[5] Rahim Entezari, Hanie Sedghi, Olga Saukh, and Behnam Neyshabur. The role of permutation invariance in linear mode connectivity of neural networks. In International Conference on Learning Representations, 2022.
13 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2023-07-21T00:49:07.232Z · LW(p) · GW(p)
Do you really expect to find this phenomenon in larger NNs? What if the networks are pruned to remove extraneous degrees of freedom, so that we're really talking about whether the "important" information has weak additivity?
Replies from: zhanpeng_zhou↑ comment by zhanpeng_zhou · 2023-07-21T02:05:34.818Z · LW(p) · GW(p)
Actually, someone found the Mode Connectivity in ViT (a quite larger NN I thought). Not sure if LLFC will be still satisfied on ViT but it worth a try. As for the pruned network, I believe that pruned network still holds the LLFC. (I think you refer the LLFC as "weak additivity", right?)
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-07-20T18:24:30.747Z · LW(p) · GW(p)
Great work and nice to see you on LessWrong!
Minor correction: 'making the link between activation engineering and interpolating between different simulators' -> 'making the link between activation engineering and interpolating between different simulacra' (referencing Simulators [LW · GW], Steering GPT-2-XL by adding an activation vector [LW · GW], Inference-Time Intervention: Eliciting Truthful Answers from a Language Model [LW · GW]).
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-07-23T09:33:53.481Z · LW(p) · GW(p)
Here's one / a couple of experiments which could go towards making the link between activation engineering and interpolating between different simulacra: check LLFC (if adding the activations of the different models works) on the RLHF fine-tuned models from Rewarded soups: towards Pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards models; alternately, do this for the supervised fine-tuned models from section 3.3 of Exploring the Benefits of Training Expert Language Models over Instruction Tuning, where they show LMC for supervised fine-tuning of LLMs.
Replies from: Hoagy, bogdan-ionut-cirstea↑ comment by Hoagy · 2023-07-24T21:12:05.518Z · LW(p) · GW(p)
I still don't quite see the connection - if it turns out that LLFC holds between different fine-tuned models to some degree, how will this help us interpolate between different simulacra?
Is the idea that we could fine-tune models to only instantiate certain kinds of behaviour and then use LLFC to interpolate between (and maybe even extrapolate between?) different kinds of behaviour?
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-07-25T13:09:22.799Z · LW(p) · GW(p)
Yes, roughly (the next comment is supposed to make the connection clearer, though also more speculative); RLHF / supervised fine-tuned models would correspond to 'more mode-collapsed' / narrower mixtures of simulacra here (in the limit of mode collapse, one fine-tuned model = one simulacrum).
↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-07-24T17:41:00.779Z · LW(p) · GW(p)
Even more speculatively, in-context learning (ICL) as Bayesian model averaging (especially section 4.1) and ICL as gradient descent fine-tuning with weight - activation duality (see e.g. first figures from https://arxiv.org/pdf/2212.10559.pdf and https://www.lesswrong.com/posts/firtXAWGdvzXYAh9B/paper-transformers-learn-in-context-by-gradient-descent [LW · GW]) could be other ways to try and link activation engineering / Inference-Time Intervention and task arithmetic. Though also see skepticism about the claims of the above ICL as gradient descent papers [LW · GW], including e.g. that the results mostly seem to apply to single-layer linear attention (and related, activation engineering doesn't seem to work in all / any layers / attention heads).
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-12-25T10:29:00.636Z · LW(p) · GW(p)
I think given all the recent results on in context learning, task/function vectors and activation engineering / their compositionality (https://arxiv.org/abs/2310.15916, https://arxiv.org/abs/2311.06668, https://arxiv.org/abs/2310.15213), these links between task arithmetic, in-context learning and activation engineering is confirmed to a large degree. This might also suggest trying to import improvements to task arithmetic (e.g. https://arxiv.org/abs/2305.12827, or more broadly look at the citations of the task arithmetic paper) to activation engineering.
Replies from: zhanpeng_zhou, bogdan-ionut-cirstea↑ comment by zhanpeng_zhou · 2024-01-11T11:52:13.836Z · LW(p) · GW(p)
Great comments! Actually, we have made some progress in linking task arithmetic with our NeurIPS 2023 results and we are working on a new manuscript to introduce our new results. Hope our new paper could be released soon.
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-01-13T00:59:38.277Z · LW(p) · GW(p)
Awesome, excited to see that work come out!
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-02-20T23:49:25.255Z · LW(p) · GW(p)
Quoting from @zhanpeng_zhou [LW · GW]'s latest work - Cross-Task Linearity Emerges in the Pretraining-Finetuning Paradigm: 'i) Model averaging takes the average of weights of multiple models, which are finetuned on the same dataset but with different hyperparameter configurations, so as to improve accuracy and robustness. We explain the averaging of weights as the averaging of features at each layer, building a stronger connection between model averaging and logits ensemble than before. ii) Task arithmetic merges the weights of models, that are finetuned on different tasks, via simple arithmetic operations, shaping the behaviour of the resulting model accordingly. We translate the arithmetic operation in the parameter space into the operations in the feature space, yielding a feature-learning explanation for task arithmetic. Furthermore, we delve deeper into the root cause of CTL and underscore the impact of pretraining. We empirically show that the common knowledge acquired from the pretraining stage contributes to the satisfaction of CTL. We also take a primary attempt to prove CTL and find that the emergence of CTL is associated with the flatness of the network landscape and the distance between the weights of two finetuned models. In summary, our work reveals a linear connection between finetuned models, offering significant insights into model merging/editing techniques. This, in turn, advances our understanding of underlying mechanisms of pretraining and finetuning from a feature-centric perspective.'
↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2023-12-25T11:56:07.351Z · LW(p) · GW(p)
speculatively, it might also be fruitful to go about this the other way round, e.g. try to come up with better weight-space task erasure methods by analogy between concept erasure methods (in activation space) and through the task arithmetic - activation engineering link
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-03-09T06:14:43.564Z · LW(p) · GW(p)
Seems relevant (but I've only skimmed): Training-Free Pretrained Model Merging.