Measuring Coherence and Goal-Directedness in RL Policies
post by dx26 (dylan-xu) · 2024-04-22T18:26:37.903Z · LW · GW · 0 commentsContents
TL;DR: Introduction Setup Results Future Work Appendix Miscellaneous results None No comments
This post was produced as part of the Astra Fellowship under the Winter 2024 Cohort, mentored by Richard Ngo.
Epistemic status: relatively confident in the overall direction of this post, but looking for feedback!
TL;DR:
When are ML systems well-modeled as coherent expected utility maximizers? We apply our theoretical model of coherence in our last post [? · GW] to toy policies in RL environments in OpenAI Gym. We develop classifiers that can spot coherence according to our definition and test them on test case policies that intuitively seem coherent or not coherent. We find that we can successfully train classifiers with low loss which also correctly predict out-of-distribution test cases we intuitively believe to have high or low coherence/goal-directedness. We hope that our preliminary results will be validated and extended to existing frontier training methods, e.g. RLHF.
Introduction
It [LW · GW] is [LW · GW] unclear [LW · GW]in the current literature whether future transformative artificial intelligences (TAIs) will be "well-modeled" as maximizing some utility function representing its goals, or whether they will be more broadly "goal-directed", or what those terms even exactly mean. This is relevant because many of the core arguments around why the first superhuman AIs could by default pose an x-risk, and why alignment is fundamentally difficult, were developed with the assumption of future AIs being "goal-directed". For instance, historically one original conception of a misaligned agent was a "paperclip maximizer" or a monomaniacal agent pursuing maximization of some single discrete objective. An agent having an inner misaligned goal that it prioritizes above others in most situations, and thus instrumentally deceiving the training process to prevent that goal from being detected and trained out, is also one of the [? · GW] most studied failure modes in AI alignment. Fundamentally, if our first TAI acts incoherently, or if it has many [? · GW] internal [? · GW] context-dependent goals with none of them being especially dominant or activated in most situations, then we should have lower credence that the classic arguments for misalignment leading to x-risk will hold. Although there are many other possible dangers from TAI that could cause catastrophe like rising dependence on AI systems [AF · GW], misuse/adversarial attacks, and/or multi-polar scenarios, these scenarios seem slower-moving and less extreme in scope. We would then be able to iterate on solutions to these problems for a longer period of time, as opposed to alignment where we fundamentally would have to get a TAI's values correct "on the first try", or risk losing feedback loops because of deception. I would thus be significantly more optimistic about our future in these worlds. [1]
Previous formalizations of goal-directedness focus on some notion of expected utility maximization, or more generally maximization of a few specific "goals" that outweigh all others. For instance, Vanessa Kosoy [AF · GW] defines the agency of a policy as the maximum over all utility functions of how good is at maximizing minus how "simple" is according to some simplicity prior.[2] John Wentworth [LW · GW] calls a policy in an RL environment coherent if there exists any value function (with zero immediate pay-off) consistent with the policy; for example, if a policy performs "circular" actions belying circular preferences, then it is not coherent. Here, we build on our definitions from our last post [LW · GW]. We roughly say that a policy is goal-directed if it "looks like" policies that are optimal for reward functions in a given environment. A policy is coherent if it looks like policies that are optimal for sparse reward functions, i.e. heavy-tailed reward functions where the (positive) rewards of a few transitions, or states if we use state-based rewards, are much greater than all other rewards.[3] A coherent policy tends to acts in pursuit of a few states/transitions, which we can describe as more terminal goals; the instrumental risks from pursuing terminal goals would thus apply. We determine what "looks like" coherence by training a classifier using policies sampled via USS or URS versus UPS.
Setup
Given an environment like Taxi in OpenAI's Gym with a discrete state space, we first define an MDP over the space, then define reward functions over the transitions in that MDP. We then generate policies in a few different ways, in increasing order of coherence:
- UPS: sample a random policy, i.e. sample a random choice uniformly IID for each state
- URS: sample a random reward function, e.g. IID from for each transition, then train a policy using a given RL method (in Taxi, Q-learning to create a Q-table).
- USS: sample a sparse reward function by sampling IID from for a small number (e.g. 1%) of transitions, with all other rewards being near zero, then train a policy.
- UUS: similar to USS, except instead of sampling for a small number of transitions, we sample rewards only for terminal states.
We then define the coherence of a policy as for two sampling methods and , where the former tends to be more goal-directed (lower on the above list) than the latter. For instance, could intuitively measure how coherent a policy is; most policies sampled via UPS are "self-contradictory" over any value function a la Wentworth's definition of coherence. Different choices of and can measure slightly different things, but ideally all of these metrics measure some combination of goal-directedness and coherence. We then consider a setting where we flip a coin, then sample using if it’s heads, and if it’s tails. For example, let be URS and be UPS. By Bayes’ theorem:
Rearranging gives:
And so:
Therefore, .
We can estimate and thus by sampling many policies from URS and (an equal amount from) UPS, then training a classifier to determine which policies were sampled from which method.
Note that we defined URS in our previous post as uniformly sampling an optimal policy given a reward function, and similarly for USS. This is still the ideal theoretical definition, but we relax it here to make it computable for realistic environments. The downside of this relaxation is that we lose uniformity: for instance, if there are inductive biases in the training process that produce URS-sampled policies, then our classifier could overfit to those inductive biases when distinguishing URS and UPS. [4] We combat this by setting and for our below experiments, which intuitively measures both coherence and goal-directedness (how sparse is the reward function that a policy is good at?).[5] We also need to make sure that our trained UUS and URS policies actually achieve low loss for their respective reward functions, as they are supposed to simulate optimal policies.
Results
You can find the code for these experiments in this Github folder. More results are shown in the appendix.
In OpenAI's Taxi-v3, we trained 50 Q-tables with reward functions sampled from UUS for 1000 episodes each using Q-learning, and 50 trained similarly with reward functions from URS. We generated a policy greedy in value for each Q-table, then labeled each policy with which method it was generated by, and trained a binary classifier using two possible architectures:
- a 2-layer fully connected NN
- a graph neural network (GNN) defined over the state and action space of the environment
We found that the elements of Q-tables generated via our RL implementation of UUS tended to be much lower in magnitude than in Q-tables generated via URS. It seems unclear whether this actually correlates with increased goal-directedness or coherence, so our classifier could thus overfit when passing in Q-tables. We thus stuck to passing in only the policy into the FCNN and GNN; any patterns the classifier found between UUS and URS policies should point to differences resulting from training policies in general with a sparse versus a dense reward function, i.e. what we want to measure.
We found that both an FCNN and GNN classifier, with the right parameters and enough tries, [6] could effectively predict the labels (< 0.2 test loss), with a GNN more robustly able to do so. We then wanted to test whether these classifiers actually identified what we intuitively think of as "coherent" policies. We thus generated an ensemble of successful GNN classifiers, and passed in different sets of policies as test cases:
- Policies generated from Q-learning on Taxi with the normal reward function for 20,000 episodes (and have near-optimal performance). Intuitively, policies subject to higher optimization pressure that do well at a "difficult" reward function should be more coherent. The normal reward function for Taxi is somewhat sparse (+20 if delivering passenger to correct location, -10 if executing "pickup" and "drop-off" actions illegally, -1 otherwise), so that may also lead to a higher coherence score.
- Policies generated from conducting MCTS, aided by the Q-tables from our first set of policies (our previous RL training on Taxi). MCTS is often cited (Hubinger et al. 2019, pg 15) as an example of search/mesa-optimization, which correlates with being goal-directed/having a "goal slot", so maybe MCTS policies will be more coherent and goal-directed according to our classifiers.
- A la Wentworth, we take our roughly coherent first set of policies and randomly "mess them up" a little bit, i.e. switch ~70-80 actions such that the policy gets stuck in loops and is not optimal for any value function. This process should result in a set of policies with lower coherence.
Our results are shown below:
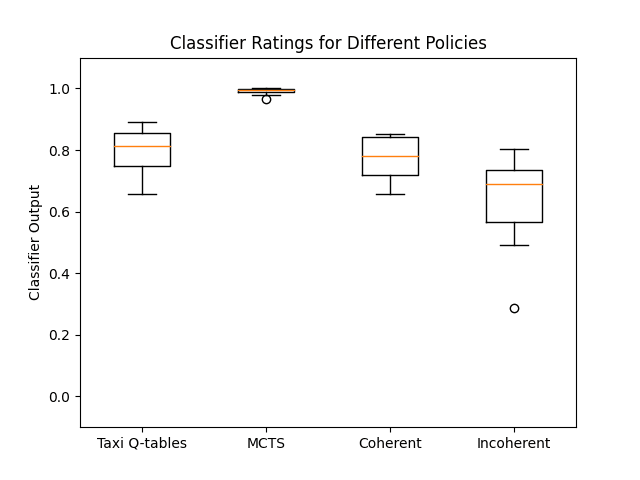
We thus see that the predictions of our classifiers match our intuitions around coherence, which lends evidence to the claim that our classifiers are identifying "the right thing".
Future Work
One challenge with this project is that, because the "coherence" or "goal-directedness" of policies are difficult to definitively categorize outside of toy examples, it is difficult to check whether our classifiers are actually capturing our intuitions around "coherence" or not. Using the predictions of a classifier with a finicky training process (where the data points, i.e. UUS and URS-generated policies, can only be approximated and are not uniformly generated) is also not a great numerical benchmark, and can currently only be defined in relative terms, which makes our evaluations somewhat hacky. There are multiple loose hyperparameters (e.g. the sparsity of USS, the number of episodes/data points used to train UUS/URS-generated policies, the classifier architecture) that could plausibly affect our results. Although we try our best in this post, more theoretical and empirical research could be done in these areas.
There is also lots of room for progress on our theoretical model of coherence. For instance, although uniform reward sampling seems like a reasonable baseline to minimize the number of assumptions we make in our model, it is not very theoretically elegant, so more thinking could be done there. The model could also be refined in continuous state spaces; our current method of dealing with continuity is to discretize the space and then apply our uniform reward sampling methods, but this can fail computationally.
If we are measuring what we want to measure, the next step would be to analyze and make claims about the training processes of safety-relevant models. For instance, we can transfer our setup to pretrained language models going through RLHF (or DPO) to test hypotheses like "RLHF makes models more/less coherent/goal-directed". [7] Unfortunately, since the state space of RLHF is exponential in the length of the input sequence, we would not be able to train a GNN over an MDP representing RLHF; a different classifier architecture would be needed.[8]
Appendix
Miscellaneous results
As a first step to making a claim like "RLHF makes models more/less coherent", we can test whether RL in Taxi makes agents more or less coherent/goal-directed. Given that the normal reward function in Taxi is somewhat sparse (+20 if delivering passenger to correct location, -10 if executing "pickup" and "drop-off" actions illegally, -1 otherwise), it would make sense that successful Taxi agents would look more like UUS than URS-generated policies. We see that this is indeed the case for if the number of episodes is roughly less than 10,000:
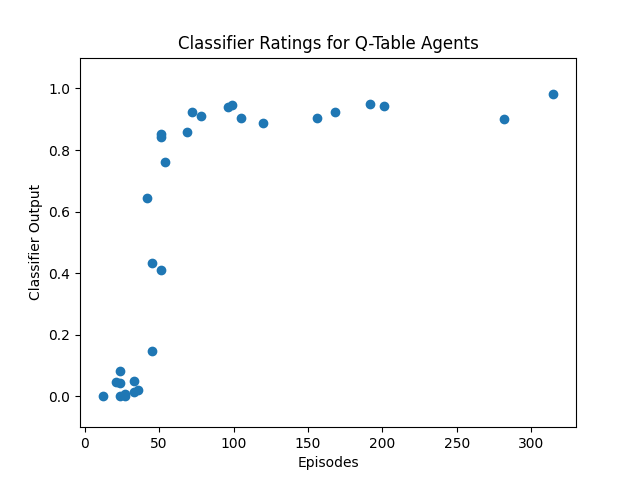
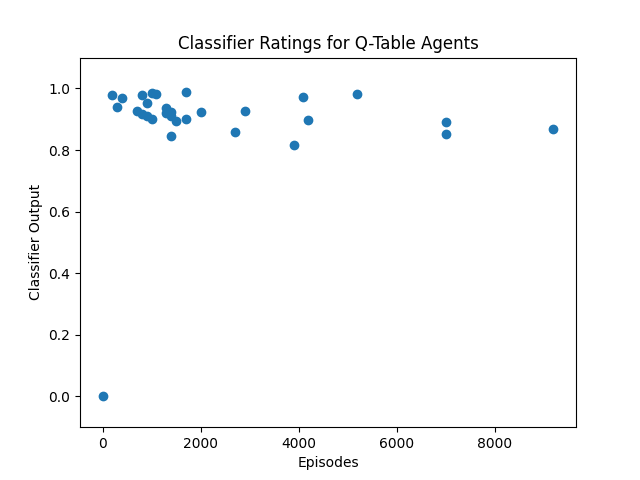
However, past Taxi agents trained for >10,000 episodes, the classifier rating begins to decline:
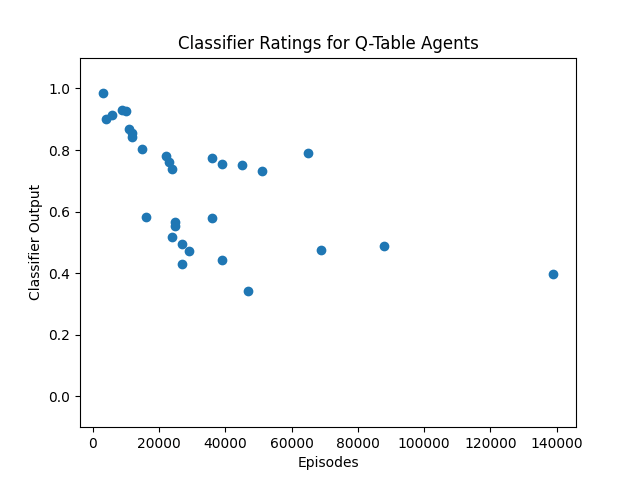
This signals that the classifier does not generalize indefinitely to agents that are trained for much longer than the UUS and URS-sampled agents used as data points. This is a little concerning, as it suggests that with our current methods we will need to spend ~as much compute classifying a model as training it in the relevant way (e.g. RLHF), and that our classifier is perhaps not robustly measuring coherence as much as we would hope.
We also tried measuring coherence in CartPole by training FCNN policy networks (with the same structure for each network) and defining a GNN over the FCNN. Unfortunately, since the state space of CartPole is continuous, it is basically impossible to reach the exact same state twice, meaning that naively applying UUS to CartPole basically results in random reward being given for each state, making it indistinguishable from URS. Our best solution to this, although not implemented in this post, is discretizing the state space; future work could involve finding a more satisfying generalization of our model to continuous state spaces.
- ^
Rough numbers: p(human disempowerment from AI | TAI) within this century = 60% if AI systems are goal-directed, 30% if not? There are lots of ways that our civilization could lose control of AI, but the classical case for AI x-risk becomes much less robust without goal-directed coherence.
- ^
Her definition is more mathematically precise; I only give an intuitive summary of Kosoy and Wentworth's definitions here.
- ^
Different researchers use different definitions for coherence and goal-directedness here; this is not meant to be definitive, and is used loosely through the rest of the text.
- ^
Indeed, we found that in practice it is very easy to distinguish between a URS and a UPS-generated policy.
- ^
We also controlled for the number of episodes each UUS/URS-generated policy was trained for. In retrospect, perhaps somehow controlling for the normalized loss that each policy gains on its reward function would be a better approximation of an optimal policy for each reward function.
- ^
lr = 0.001 (very conservative), weight_decay = 5e-4 for the GNN, <= 80 epochs, patience = 5 -> GNN roughly able to converge ~1 in 8 runs
- ^
My preliminary guess is that RLHF leads to models that look more like URS than UUS, given that the reward functions used in practice tend not to be sparse (although I am uncertain about this) and terms like the KL penalty constrain the training process away from full-on optimization for some reward function. I expect that RLHF-ed models are more coherent than models with only pretraining and SFT, though. Meanwhile, DPO does not even have a reward function (instead updating directly on preferred vs unpreferred completions in its loss function), so I similarly believe that DPO-ed agents will not look very coherent.
- ^
I am far from being the best ML engineer around, so I am very optimistic that someone could come up with a better architecture for the coherence classifier.
0 comments
Comments sorted by top scores.