Measuring Coherence of Policies in Toy Environments
post by dx26 (dylan-xu), Richard_Ngo (ricraz) · 2024-03-18T17:59:08.118Z · LW · GW · 9 commentsContents
Summary Introduction Model Most basic approach Estimating P(π=π0|URS) Better simplicity-weighted reward sampling Accounting for suboptimality Related work Proof-of-Concept Experiments Future work Conclusion Appendix A. Better baselines B. More experiment results C. Miscellaneous theoretical arguments for our metric None 9 comments
This post was produced as part of the Astra Fellowship under the Winter 2024 Cohort, mentored by Richard Ngo. Thanks to Martín Soto, Jeremy Gillen, Daniel Kokotajlo, and Lukas Berglund for feedback.
Summary
Discussions around the likelihood and threat models of AI existential risk (x-risk) often hinge on some informal concept of a “coherent”, goal-directed AGI in the future maximizing some utility function unaligned with human values. Whether and how coherence may develop in future AI systems, especially in the era of LLMs, has been a subject of considerable debate. In this post, we provide a preliminary mathematical definition of the coherence of a policy as how likely it is to have been sampled via uniform reward sampling (URS), or uniformly sampling a reward function and then sampling from the set of policies optimal for that reward function, versus uniform policy sampling (UPS). We provide extensions of the model for sub-optimality and for “simple” reward functions via uniform sparsity sampling (USS). We then build a classifier for the coherence of policies in small deterministic MDPs, and find that properties of the MDP and policy, like the number of self-loops that the policy takes, are predictive of coherence when used as features for the classifier. Moreover, coherent policies tend to preserve optionality, navigate toward high-reward areas of the MDP, and have other “agentic” properties. We hope that our metric can be iterated upon to achieve better definitions of coherence and a better understanding of what properties dangerous AIs will have.
Introduction
Much of the current discussion about AI x-risk centers around “agentic”, goal-directed AIs having misaligned goals. For instance, one of the most dangerous possibilities being discussed is of mesa-optimizers developing within superhuman models, leading to scheming behavior and deceptive alignment. A significant proportion of current alignment work focuses on detecting, analyzing (e.g. via analogous case studies of model organisms [AF · GW]), and possibly preventing deception. Some researchers in the field believe that intelligence and capabilities are inherently tied with “coherence” [LW · GW], and thus any sufficiently capable AI will approximately be a coherent utility function maximizer.
In their paper “Risks From Learned Optimization” formally introducing mesa-optimization and deceptive alignment, Evan Hubinger et al. discuss the plausibility of mesa-optimization occurring in RL-trained models. They analyze the possibility of a base optimizer, such as a hill-climbing local optimization algorithm like stochastic gradient descent, producing a mesa-optimizer model that internally does search (e.g. Monte Carlo tree search) in pursuit of a mesa-objective (in the real world, or in the “world-model” of the agent), which may or may not be aligned with human interests. This is in contrast to a model containing many complex heuristics that is not well-defined internally as a consequentialist mesa-optimizer; one extreme example is a tabular model/lookup table that matches observations to actions, which clearly does not do any internal search or have any consequentialist cognition. They speculate that mesa-optimizers may be selected for because they generalize better than other models, and/or may be more compressible information-theoretic wise, and may thus be selected for because of inductive biases in the training process.
Other researchers [AF · GW] believe that scheming and other mesa-optimizing behavior is implausible with the most common current ML architectures, and that the inductive bias argument and other arguments for getting misaligned mesa-optimizers by default (like the counting argument, which suggests that there are many more misaligned than aligned mesa-objectives, so we should by default assume that mesa-objectives will be misaligned) are very flawed. Indeed, contrary to the era of RL agents in games like Go, current LLMs and other frontier models do not seem to be very “agentic” or mesa-optimizing, and it is unclear whether deep learning pre-training or fine-tuning could ever produce a goal-directed agent. A frequent, if vague, counterargument is that future, more powerful general AI systems will have an internal mesa-optimization structure, or otherwise behave “coherently” or “agentic” by necessity of them being more powerful. Current discourse on this topic is speculative [AF · GW], and as a result often unproductive with experts with different intuitions struggling to find cruxes and understand each other’s worldview.
One important point to note here is that it is not necessary for a model with superhuman capabilities to have a clear internal representation of an objective, or do search or back-chaining reasoning to obtain said objective, to be dangerous. Leo Gao discusses this point in more detail here [? · GW]: if an AI reliably steers world-states towards a certain configuration (what we might call an objective), in a way that is robust to perturbations in the environment (e.g. humans trying to turn the AI off) and that conflicts with our values, then we should be concerned about this AI.[1]
In this document, we intuitively think of AIs that robustly steer world-states towards certain configurations (or in an MDP, robustly navigate towards high-reward states) as having coherent behavior.[2] But it’s not clear what this means, so it would be nice to have a definition of coherence clear enough that it could be measured (at least in some toy cases).
Model
Intuitively speaking, coherent AIs are ones that are near-optimal for some objective function.[3] In the context of sequential decision-making, the most natural objective function to use is a reward function. The problem with defining coherence in this way, though, is that every policy is optimal for some state-action reward function. We could instead say that coherent policies are policies which are optimal for “simple” reward functions. This is promising, but a problem is that one policy can be optimal for many reward functions, and one reward function can have many optimal policies.
We adapt this idea to operationalize coherence as follows. Suppose we have a Markov decision process with a set of states , a set of possible actions that you can perform at each state, and a transition function that returns a probability distribution over all states (such that ). Then we can define a distribution from which we sample a reward function , and since and the MDP are invariant across time-steps, we can define a (deterministic) policy as a tuple of actions, one action to take for each state.
Then consider two ways of sampling a policy:
- Sampling directly from the space of policies.
- Sampling from the space of reward functions (weighted by simplicity), then sampling from the space of all policies optimal for that reward function.
We define the coherence of a policy as the ratio of how likely it is under the latter sampling strategy to how likely it is under the former sampling strategy. Note that this will depend on the details of how sampling happens, which we’ll focus on in the rest of this document. In particular, we’ll explore different approaches to simplicity-weighted sampling from the space of reward functions. If the distributions of policies of these two sampling strategies are different (which we show later to be true in small deterministic MDPs with self-loops), then policies with high coherence will tend to have distinct “features” of reward maximization that don’t show up randomly (which we explore in our experiments).
For simplicity, throughout the rest of the document we’ll talk about deterministic MDPs and policies (as a generalization of environments and AIs/models respectively). Whenever we talk about sampling from the space of policies, we’ll assume that this just samples uniformly from all combinations of discrete actions; we’ll call this uniform policy sampling (UPS). The question then becomes:
- Which simplicity-weighted distribution of reward functions should we use?
- For a given reward function distribution, how can we calculate coherence in practice?
Most basic approach
In the most basic case, let’s treat every (bounded) reward function as equally simple. We sample rewards from , since optimal policies are invariant under scaling reward functions. Let be the distribution of reward functions where each reward of each transition is drawn uniformly from . Call this uniform reward sampling (URS). Even under URS, some policies will be more coherent than others, because they will be optimal for more reward functions.
For a given policy sampled from , we measure coherence as follows (where is the number of possible policies):
This is a difficult function to estimate directly, because very few reward functions imply that any given policy is optimal. Additionally, small epsilon perturbations in a reward function can cause the optimal policy to change. For instance, consider a policy that starts at A and can get high reward by going from B to C, but is indifferent between two paths from A to B. Then an epsilon change in the rewards on one of the paths from A to B will rule out more than half of the optimal policies. So it’s difficult to sample reward functions and categorize which will lead to as an optimal policy, and then take the “proportion” which lead to as an estimate of ’s coherence. Instead, we can use the following indirect estimation technique.
Estimating
In order to estimate , we first estimate the reverse. Specifically, consider a setting where we first flip a coin, then sample using URS if it’s heads, and UPS if it’s tails. In this setting, we can train a classifier , since we have a lot of data. But by Bayes’ theorem:
Rearranging gives:
And so:
Therefore, .
There are still issues in training the classifier—the correct classification of a policy depends on the graph structure of the underlying MDP, in a way which is hard to capture with standard classifiers. The most principled way to do it in a way which generalizes across different MDPs is likely using some kind of graph neural network. For now we focus on classifiers which make use of hand-crafted features which we’ve found to be useful.
Better simplicity-weighted reward sampling
Of course, not all reward functions that we want to model are equally simple. In particular, some of them are much sparser than others; intuitively speaking, if we only need to specify rewards for a few transitions, that’s much simpler than specifying rewards for every transition.
In order to account for this, we can replace URS with a modified sampling strategy, which we'll call uniform sparsity sampling (USS). For an MDP with N state-action transitions, we first randomly sample a value . We then sample random rewards for transitions (selected uniformly without replacement), and finally sample a policy which is optimal for that reward. Compared with URS, USS is more strongly simplicity-weighted: only half of its transitions have rewards in expectation.
(Of course, we could make this even more strongly sparse—for example, we could sample k in a way which heavily favored lower values. We're uncertain what the most principled ways of doing so are. Note that, in the extreme case where we just set , policies will often have coherence 0, since most policies are not optimal for any highly-sparse reward function in strongly-connected MDPs.)
All the equations work the same, however. And so we have:
We can also define coherence in this setting as , which intuitively represents how “simple” the reward functions that a policy is optimal for is given that it is already “coherent” to some degree. (This is also just our latter definition of coherence divided by our former definition.) The math also works out to , except that the choice is between USS and URS instead of UPS. Another way of generating sparse policies is by sampling rewards from a high-variance distribution, and possibly discarding the ones which are below a given threshold.[4]
Under our setup, ranges from 0 when to as ; the prior, not knowing anything specific about , is , implying . Policies that are optimal for a broader class of reward functions will have higher and thus higher coherence.
Accounting for suboptimality
The current method only counts a policy if it’s exactly optimal for a given reward function. But real-world agents will never be actually optimal for any non-trivial reward function. So if a policy is almost optimal for many reward functions, that should still count towards its coherence.
We can modify the sampling strategy in order to take this consideration into account. Instead of only sampling from optimal policies for a given reward function, we could first sample a value m from 0 to 100 (biased towards higher numbers), then sample a policy which has expected reward of m% of the expected reward of the optimal policy (e.g. by early stopping).
Note that this can be combined with different possibilities for how to do simplicity-weighted reward sampling. In other words, the policy sampling procedures we use have four steps, and we have different choices we can make for each of the first three:
- Sample a value which controls how we prioritize simplicity.
- Sample the reward function.
- Could be state-action rewards or state-based rewards.
- Sample a value m which controls how we prioritize optimality.
- Sample the policy.
To be clear, this is pretty impractical for most realistic settings where tabular methods like value iteration become computationally intractable. But we are interested in this as a toy demonstration of one definition of coherence and how it could be measured in theory. Depending on the situation, users of the metric can switch in their preferred definitions of simplicity, their prior distribution of reward functions, and so on.
Related work
Our methodology was substantially inspired by Turner et al. [2021], which studies the properties of optimal policies under MDPs. They find that certain properties and symmetries of an MDP lead to power-seeking behavior by optimal policies. Specifically, for any state , discount rate , and distribution of reward functions with some bounding conditions, then POWER is defined as
refers to the optimal value of a state, or the value of a state given an optimal policy over a reward function . We might then say that POWER measures the expected optimal value of a state over all relevant reward functions. Then, action is more power-seeking than when the expected POWER of is greater than the expected POWER of .
Although our model and results focus more on optimality than the POWER metric, we borrow intuitions from Turner et al. [2021] about properties of MDPs that are correlated with optimality (and by extension POWER-seeking), like 1-cycles, loops, and the “optionality” of nodes in deterministic MDPs. Intuitively, policies sampled from URS may be more likely to “explore” the graph of states to find a particularly high-reward group of states, thus resulting in a policy that takes longer before it starts looping between states (assuming policy invariance across time-steps). URS-sampled policies, if power-seeking, may also tend to avoid 1-loops (actions that take an agent from a state to itself).
Turner later extended his work to policies with retargetable cognition [Turner et al. 2022]. As another intuition pump, if a policy is optimal for many reward functions, then it tends to be retargetable over many permutations of a reward function. Hence measures the distribution of retargetability, which seems useful.
Vanessa Kosoy has also given definitions for the “agency” of a policy in her learning-theoretic agenda here [LW · GW] and here [AF · GW].[5] Her definitions make fewer assumptions about the distribution of reward/utility functions, instead only relying on the utility of a policy with respect to some utility function and the simplicity of the policy (the Kolmogorov complexity in her former definition; in her latter definition, simplicity priors and can be generalized to any prior over the space of policies and reals respectively). The first definition also contains an interesting generalization of the “source code” of a policy that produces a policy given priors. However, both definitions seem incomputable, requiring the calculation of an integration over all (simplicity) prior-weighted environments and the maximum of a function over all utility functions and universal Turing machines respectively. It may be possible to estimate these using a similar strategy to our coherence definition; this should be explored in further work.
We take fault for any possible misrepresentations of others’ work in this document.
Proof-of-Concept Experiments
We now present a toy model of our coherence metric under randomly generated MDPs with certain structural properties. Specifically, consider a deterministic MDP, such that each transition has either probability or , with guaranteed self-loops (i.e. for any , there exists an action such that ). (This mirrors Turner et al. 2021’s theorems that show that having self-loops/1-cycles is one condition of MDPs with certain structure that cause optimal policies to be power-seeking.) As a case study, let , , and .
We use the Python MDP Toolbox to generate different MDPs and pick a , then rewards in accordance with uniform sparsity sampling. We then solve half of the MDPs to get half of our optimal policies, and randomize the other half, while labeling which were solved for and which were randomized. Then by default . We use two basic classifier structures, trying a 3-layer, 64-width sequential neural network and binary logistic regression. We then input certain features that intuitively seem relevant to the classifier:
- One “brute force” method is by joining the (tuple) optimal policy , flattened transition function, and discount rate into a 1-dimensional vector. This in theory contains all the information about the MDP and that we can provide, but in practice needs more processing before it can be classified. (Again, a more principled approach would likely involve some kind of graph neural network.)
- Another possible set of features is, for every state , measuring how long it takes for the optimal policy to reach a loop when starting from , and how long the loop itself is. We can think of optimal policies as implementing an explore and exploit dynamic: navigating to a particularly high-reward area of the MDP, and then looping through that area to maximize reward indefinitely. Intuitively, a policy that takes longer to reach a stable loop can access more of the MDP and can thus reach higher-reward areas, while a policy that takes a bigger loop can incorporate more reward into the loop.
- Finally, if optimal policies are “power-seeking”, then we can try using correlates of POWER [Turner et al. 2021], like summing the number of out-arrows of the states that an optimal policy reaches, or whether self-loops indefinitely, for each state .
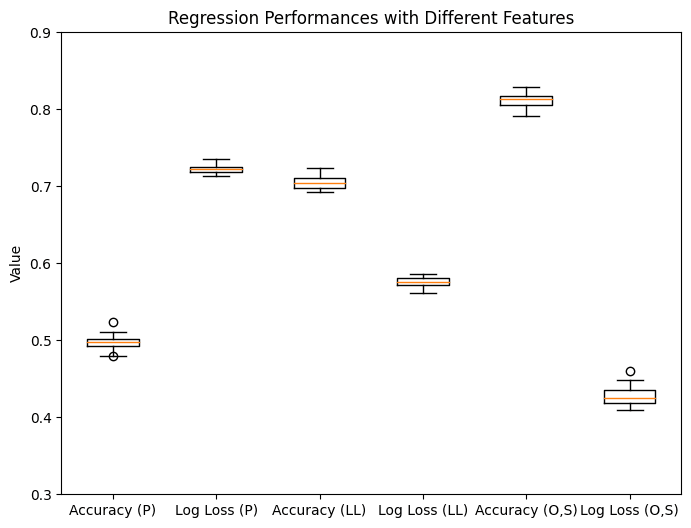
Features passed in: (P) = Policy (+T, discount rate) passed into classifier input, (LL) = policy, distance to loop, & length of loop, (O,S) = out-arrows visited & # self-looping states in pi_0
(Note that we do not pass in any part of the reward functions as a feature, as that would defeat the point of the classifier.)
For this task of determining whether a policy was generated via UPS or USS, we find that self-loops is the most predictive feature, followed by out-arrows visited, then distance to loop. Additionally, combining features does not give a significant performance boost (maybe 0.01-0.04 accuracy boost in general). Finally, the neural network did not give a significant performance boost over the logistic classifier, suggesting that a different architecture is needed for better classifier performance.
Broadly, we show that hand-crafted features that intuitively indicate “power-seeking”, “goal-directed” behavior in a policy correlate with our metric via this classifier, lending some evidence that the metric is connected to properties like “power-seeking” that we care about. More findings are presented in the appendix. You can view and test our findings in this notebook. This notebook also contains some data and early experiments on the distribution of policies generated via URS and USS under different kinds of MDPs.[6]
Future work
We first note that our coherence model is currently still computationally difficult to apply to real-life AIs in most environments, especially if using the naive optimal policy definition. Extensions of this work could thus include modifying and applying our coherence model to RL AIs in games like Sokoban, where the state space is greater and the MDP is more complicated, but still limited in scope. On a more theoretical level, the complex problem of cluelessness in philosophy could render calculating near-optimal policies for reward functions in real life to be computationally impossible. If the process for finding near-optimal policies contains inductive biases, then uniformly drawing from the set of near-optimal policies can also be difficult, since it's impractical to generate every near-optimal policy. If finding the maximum possible obtainable value from a reward function is not possible in these more complicated environments, then we could perhaps normalize the reward function somehow, or sample over all policies (instead of just near-optimal policies) weighted by performance on the reward function. We would also likely need a more complicated structure for our classifier, such as a graph neural network, to be able to capture more nuanced features of the MDP. Finally, we would need to generalize results across the hyperparameters of our tests, as changing the discount rate (e.g. ), sparsity distribution, and sub optimality criterion could all change our results.
We also acknowledge that our model is currently somewhat hacky and inelegant. The usage of uniform distributions, and the assumption that simplicity and suboptimality can be measured with scalar coefficients and , are all assumptions that could be tweaked with further analysis. There also may be a difference between navigating to high-reward areas of the MDP in our model, which is one of the primary behaviors we find in coherent policies, and actually changing the environment in a high-impact way, which seems to be more relevant for AI risk. We hope to gather feedback from the community to refine our coherence model (or to come up with a better coherence definition) to be more comprehensive, match more of our intuitions, and be tractable to calculate in more environments. Further theoretical work could also formalize long-term “agency” and “goal-directedness”, setting the stage for possible equivalence proofs or other mathematical results.
One concrete long-term vision for how this vein of research may cash out is via some kind of “coherence evaluation” of a model. For instance, alignment evaluations currently are difficult because, among other reasons [AF · GW], the moment at which AI systems become capable enough to be well-described as “agentic” and “goal-directed” is also the moment at which AIs can plausibly fake alignment and scheme against your evaluations. Meanwhile, alignment evals on AIs that are not “agentic” or “goal-directed” can become fundamentally confused and lead to false evidence for or against good “alignment” of advanced AIs. Instead of trying to measure the “alignment” of an AI, which is subject to all kinds of confusion and possible failure modes, we can try measuring meta-properties of the model’s “alignment” like coherence. If we could deploy some version of this metric in the future on a frontier model, we could measure how coherent the model is across its training, and stop (or commit to stopping via RSPs and standards) when it reaches a certain level. We have a lot of work to do to get there, but if possible this could be an enormous boon for aligning above-human-level AI systems.
More fundamentally, the field of AI alignment is (or at least historically was) based on a conception of a coherent, goal-directed agent maximizing some “simple” utility function (e.g. a paperclip maximizer) that, if misaligned, would be incorrigible from pursuing this utility function and cause catastrophe. Translating and evaluating this threat model onto projections of AGI systems capable of producing existential catastrophe has caused a lot of confusion around what these concepts mean, how necessary or sufficient these concepts are for x-risk, and so on. By providing a provisional definition of coherence, we hope to encourage others to search for better definitions and ground the more speculative parts of AI alignment.[7]
Conclusion
Many discussions of AI risk are unproductive or confused because it’s hard to pin down concepts like “coherence” and “expected utility maximization” in the context of deep learning. Fundamentally, we are trying to conceptualize “utility maximization” without the vagueness of what counts as a “natural” utility function, or “coherent” behavior, or so on. We perform toy experiments to show that coherent policies under our definitions display explore-exploit behavior, tend to preserve optionality, pursue high-reward areas of the MDP even if they are relatively far away, and other kinds of behaviors that look “agentic”, “non-myopic”, and “goal-directed”. These are all properties that seem to distinguish dangerous AI agents from benign tool AI or similar AIs unlikely to cause deliberate catastrophe.
We provide a mathematical model for thinking about the coherence of a policy in toy settings. We define the coherence of a policy as the ratio of how likely divided by how unlikely (one minus the numerator) a policy is to be sampled via a certain sampling strategy, versus being generated at random. This strategy could be URS, which generates a random reward function and then samples from the set of policies optimal for that reward function, or USS, which does URS on a subset of transitions and leaves the other transitions with zero reward, hence a “sparse” reward function. Other sampling options and modifications to our strategy are also discussed.
We also provide a toy experiment to show its connections to relevant hand-crafted features of MDPs. We build a classifier to predict the coherence of policies without knowing the reward function (only knowing the optimal policy and the MDP/environment). We find that certain correlates of “power-seeking”, like the total number of out-arrows visited by the optimal policy from a given state and whether that policy takes a self-loop indefinitely, act as good features for our classifier. We hope that our definitions provide a starting point for future work on understanding coherence better in existing and future systems.
Authors: Dylan Xu, Richard Ngo, Martín Soto
Appendix
A. Better baselines
One problem we might face in following the above strategy: what if it’s too easy to distinguish policies sampled via UPS from policies sampled via USS? If so, values of might cluster near 0 or near 1, leading to numerical problems and/or slow learning.
Another way of putting this: for highly coherent policies, UPS is a very poor baseline to compare USS against. So what if we used a series of baselines for training classifiers instead? For example, we could calculate coherence as:
This would be useful given the assumption that URS is a good baseline for USS, and UPS is a good baseline for URS.
We might also be interested in other sampling strategies which are, intuitively speaking, “somewhere between” USS and UPS. One possibility is uniform value sampling (UVS). By UVS I mean the following procedure:
- Sample a random value function by assigning every state a value from U(-1,1).
- Sample a random reward function which is consistent with that value function. Note that a) there is some state-action reward function consistent with any value function; and b) for any given value function, most state-action reward functions are not consistent with it.
- Sample an optimal policy for that reward function.
One of the benefits of using UVS as an intermediate baseline is that knowing the value function makes it very easy to translate a reward function to an optimal policy. Another possible intermediate baseline is uniform trajectory sampling—sampling a given trajectory (or set of trajectories), then sampling a reward function consistent with that trajectory being optimal, then sampling an optimal policy for that reward function.
B. More experiment results
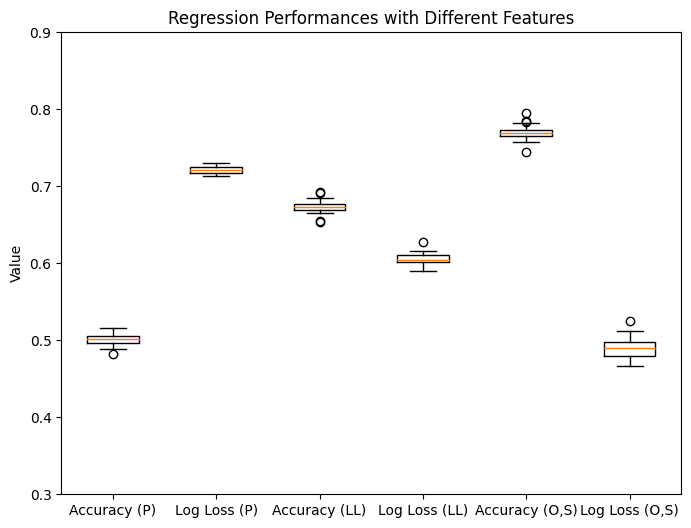
We performed additional tests on different definitions of coherence. Using the original definition, we find roughly similar results to the USS definition:
When we try to build a classifier for the definition of coherence, we find that our current classifier architectures and features are insufficient:
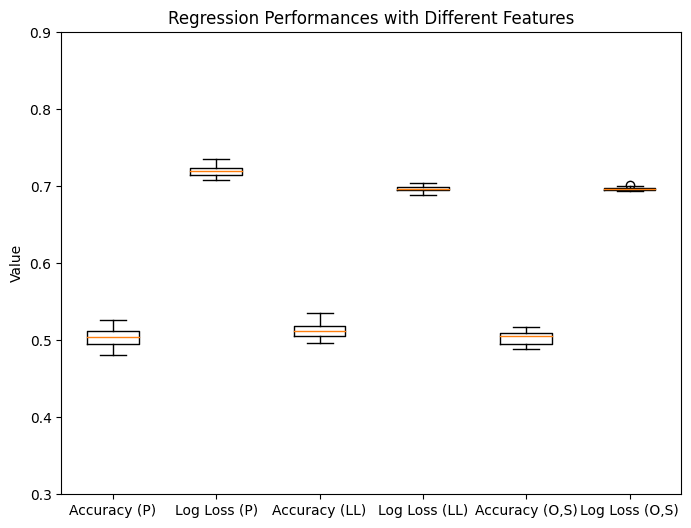
On the one hand, the and definitions of coherence ended up giving very similar, approximately equal results in our toy MDPs, so it is not too surprising that they would be hard to distinguish. We would likely need a more complicated environment and/or a more sophisticated classifier to analyze the impact of sparsity beyond extreme differences (e.g. zero sparsity versus sparsity, like in the previously mentioned case). On the other hand, the definition is just the quotient of the other two definitions, so it is a little surprising that the classifiers can classify the first two definitions but not the last.
Some other results:
- Less structured MDPs, such as MDPs where the transition probability distribution for each (for any state and action ) were i.i.d. randomized via Dirichlet distribution, tended to be harder to build a classifier for. Indeed, when we sampled from this set of MDPs, randomized the reward function times, and then calculated the optimal policy via value or policy iteration for each reward function, we found that the resulting distribution of optimal policies was roughly uniform (the mode policy occurred 1-3 times), and did not become less uniform with increased sparsity. This would make it harder to distinguish optimal policies from uniformly randomly generated policies. We found a similar, if slightly weaker, result for random deterministic MDPs (where is 1 for some random and 0 for all other states).
- Looking at the logistic coefficients of the logistic when using self-loops and out-arrows individually as features, we found that more out-arrows correlated with a greater chance of a policy being sampled from URS/USS rather than UPS, while more self-loops correlated with a lesser chance. This matches (with weak confidence) what we would expect if “coherent” policies optimal for some reward function tended to preserve optionality, which was hypothesized in Turner et al. [2021].
C. Miscellaneous theoretical arguments for our metric
One particular objection that some may have about our definition is that, even if coherent policies meaningfully tend to maximize reward functions, those reward functions may in practice be “low-impact”, and thus not matter for AI risk. One example is the concept of a “myopic” AI, which is only goal-directed within a small time-frame, and hence cannot affect the world in ways we would consider dangerous. We give preliminary empirical evidence that coherent policies tend to pursue long-term reward (at least with a high enough discount rate, e.g. 0.9). We can also provide a heuristic argument that myopiac policies will tend to have low coherence.
Suppose you have a policy that is myopic at a state . Then we can model the policy as taking the action with the highest expected next-step reward , which given that the MDP is deterministic, equals some . If this policy is optimal for this reward function, then will be very high, and there will be many policies that are also myopic in taking action at state , and are also optimal for at . But then will be low, as is only one of many policies taking the same action at . Therefore, its coherence will also be low; this argument works similarly for .
Intuitively, if an AI reliably steers world-states regardless of any actions that humanity takes, then this seems like a big deal, regardless of whether it’s good or bad. However, this fails to include the possibility of myopic AI or less “ambitious” steering, which we discuss in Appendix C. ↩︎
This is a somewhat different definition than usual in the field, but we believe the discussions around coherence are already ideologically confused, so we use our own definition here. ↩︎
We use the term “optimal for” instead of “optimizing for” to avoid any unnecessary connotations about the internal structure of the policy. ↩︎
A more detailed definition of simplicity in more complicated models would refer to the specific structure of the MDP, policy, and the (almost-)optimal policy generation process. For instance, if the policy is a neural network, then the definition of a “simple” reward function could be how easily the NN can "learn the reward function" via its inductive biases. ↩︎
Thanks to Jeremy Gillien and Arjun P in Vanessa’s MATS stream respectively for the links. ↩︎
Note that the Markdown notes in these notebooks were written while experimentation was happening, and so it’s likely that some of the statements made are incorrect. ↩︎
If “coherence” is a real concept and not fundamentally confused, then ideally there would be multiple definitions of coherence that would “point to” the same thing. Specifically, the policies/models that satisfy one of these definitions would have similar properties relating to agency and goal-directedness. ↩︎
9 comments
Comments sorted by top scores.
comment by johnswentworth · 2024-03-20T16:42:50.728Z · LW(p) · GW(p)
I don't usually think about RL on MDPs, but it's an unusually easy setting in which to talk about coherence and its relationship to long-term-planning/goal-seeking/power-seeking.
Simplest starting point: suppose we're doing RL to learn a value function (i.e. mapping from states to values, or mapping from states x actions to values, whatever your preferred setup), with transition probabilities known. Well, in terms of optimal behavior, we know that the optimal value function for any objective in the far future will locally obey the Bellman equation with zero payoff in the immediate timestep: value of this state is equal to the max over actions of expected next-state value under that action. So insofar as we're interested in long-term goals specifically, there's an easy local check for the extent to which the value function "optimizes for" such long-term goals: just check how well it locally satisfies that Bellman equation.
From there, we can extend to gradually more complicated cases in ways which look similar to typical coherence theorems (like e.g. Dutch Book theorems). For instance, we could relax the requirement of known probabilities: we can ask whether there is any assignment of state-transition probabilities such that the values satisfy the Bellman equation.
As another example, if we're doing RL on a policy rather than value function, we can ask whether there exists any value function consistent with the policy such that the values satisfy the Bellman equation.
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2024-03-20T18:14:24.411Z · LW(p) · GW(p)
Note that in the setting we describe here, we start off only with a policy and a (reward-less) MDP. No rewards, no value functions. Given this, there is always a value function or q-function consistent with the policy and the Bellman equations.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-03-20T18:27:20.978Z · LW(p) · GW(p)
That's only true if the Bellman equation in question allows for a "current payoff" at every timestep. That's the term which allows for totally arbitrary value functions, and not-coincidentally it's the term which does not reflect long-range goals/planning, just immediate payoff.
If we're interested in long-range goals/planning, then the natural thing to do is check how consistent the policy is with a Bellman equation without a payoff at each timestep - i.e. a value function just backpropagated from some goal at a much later time. That's what would make the check nontrivial: there exist policies which are not consistent with any assignment of values satisfying that Bellman equation. For example, the policy which chooses to transition from state A -> B with probability 1 over the option to stay at A with probability 1 (implying value B > value A for any values consistent with that policy), but also chooses to transition B -> A with probability 1 over the option to stay at B with probability 1 (implying value A > value B for any values consistent with that policy).
(There's still the trivial case where indifference could be interpreted as compatible with any policy, but that's easy to handle by adding a nontriviality requirement.)
Replies from: ricraz↑ comment by Richard_Ngo (ricraz) · 2024-03-20T19:26:12.230Z · LW(p) · GW(p)
That's what would make the check nontrivial: IIUC there exist policies which are not consistent with any assignment of values satisfying that Bellman equation.
Ah, I see. Yeah, good point. So let's imagine drawing a boundary around some zero-reward section of an MDP, and evaluating consistency within it. In essence, this is equivalent to saying that only actions which leave that section of the MDP have any reward. Without loss of generality we could do this by making some states terminal states, with only terminal states getting reward. (Or saying that only self-loops get reward, which is equivalent for deterministic policies.)
Now, there's some set of terminal states which are ever taken by a deterministic policy. And so we can evaluate the coherence of the policy as follows:
- When going to a terminal state, does it always take the shortest path?
- For every pair of terminal states in that set, is there some k such that it always goes to one unless the path to the other is at least k steps shorter?
- Do these pairings allow us to rank all terminal states?
This could be calculated by working backwards from the terminal states that are sometimes taken, with each state keeping a record of which terminal states are reachable from it via different path lengths. And then a metric of coherence here will allow for some contradictions, presumably, but not many.
Note that going to many different terminal states from different starting points doesn't necessarily imply a lack of coherence—it might just be the case that there are many nearly-equally-good ways to exit this section of the MDP. It all depends on how the policy goes to those states.
comment by Garrett Baker (D0TheMath) · 2024-03-18T22:06:00.052Z · LW(p) · GW(p)
I have thought some about how to measure the "coherence" of a policy in an MDP. One nice approach I came to was summing up the absolute values of the real parts of the eigenvalues of the corresponding MDP matrix with & without the policy present. The lower this is, the more coherent a policy. It seemed to work well for my purposes, but I haven't subjected it to much strain yet.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2024-03-18T22:06:58.623Z · LW(p) · GW(p)
The eigenvalues are a measure of how quickly the MDP reaches a steady state. This works when you know the goals of your network are to achieve a particular state in the MDP as fast as possible, and stay there.
Edit: I think this also works if your model has the goal to achieve a particular distribution of states too.
Replies from: dylan-xu↑ comment by dx26 (dylan-xu) · 2024-03-19T01:30:05.036Z · LW(p) · GW(p)
Right, I think this somewhat corresponds to the "how long it takes a policy to reach a stable loop" (the "distance to loop" metric), which we used in our experiments.
What did you use your coherence definition for?
Replies from: D0TheMath, D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2024-03-19T01:42:08.154Z · LW(p) · GW(p)
Its a long story, but I wanted to see what the functional landscape of coherence looked like for goal misgeneralizing RL environments after doing essential dynamics. Results forthcoming.
↑ comment by Garrett Baker (D0TheMath) · 2024-03-19T16:19:32.834Z · LW(p) · GW(p)
They are related, but time-to-loop fails when there are many loops a random policy is likely to access. For example, if a “do nothing” action is the default, your agent will immediately enter a loop, but the sum of the absolute values of the real parts of the eigenvales will be very high (the number of states in the environment).