Kevin Roose: I wrote about the newest AGI manifesto in town, a wild future scenario put together by ex-OpenAI researcher @DKokotajlo and co.
I have doubts about specifics, but it’s worth considering how radically different things would look if even some of this happened.
Daniel Kokotajlo: AI companies claim they’ll have superintelligence soon. Most journalists understandably dismiss it as hype. But it’s not just hype; plenty of non-CoI’d people make similar predictions, and the more you read about the trendlines the more plausible it looks. Thank you & the NYT!
The final conclusion is supportive of this kind of work, and Kevin points out that expectations at the major labs are compatible with the scenario.
I was disappointed that the tone here seems to treat the scenario and the viewpoint behind it as ‘extreme’ or ‘fantastical.’ Yes, this scenario involves things that don’t yet exist and haven’t happened. It’s a scenario of the future.
One can of course disagree with much of it. And you probably should.
As we’ll see later with David Shapiro, we also have someone quoted as saying ‘oh they just made all this up without any grounding’ despite the hundreds of pages of grounding and evidence. It’s easier to simply pretend it isn’t there.
Kevin Roose: Ali Farhadi, the chief executive of the Allen Institute for Artificial Intelligence, an A.I. lab in Seattle, reviewed the “AI 2027” report and said he wasn’t impressed.
“I’m all for projections and forecasts, but this forecast doesn’t seem to be grounded in scientific evidence, or the reality of how things are evolving in A.I.,” he said.
And we have a classic Robin Hanson edit, here’s his full quote while linking:
Robin Hanson (quoting Kevin Roose): “I’m not convinced that superhuman A.I. coders will automatically pick up the other skills needed to bootstrap their way to general intelligence. And I’m wary of predictions that assume that A.I. progress will be smooth and exponential.”
I think it’s totally reasonable to be wary of predictions of continued smooth exponentials. I am indeed also wary of them. I am however confident that if you did get ‘superhuman A.I. coders’ in a fully broad sense, that the other necessary skills for any reasonable definition of (artificial) general intelligence would not be far behind.
Cyberwarfare as (one of) the first geopolitically relevant AI skills
A period of potential geopolitical instability
The software-only singularity
The (ir)relevance of open-source AI
AI communication as pivotal
Ten people on the inside (outcomes depend on lab insider decisions)
Potential for very fast automation
Special economic zones
Superpersuasion
Potential key techs with unknown spots on the ‘tech tree’: AI lie detectors for AIs, superhuman forecasting, superpersuasion, AI negotiation.
I found this to be a good laying out of questions, even in places where Scott was anti-persuasive and moved me directionally away from the hypothesis he’s discussing. I would consider these less takeaways that are definitely right as they are takeaways of things to seriously consider.
Others Takes on Scenario 2027
Having a Concrete Scenario is Helpful
The central points here seem spot on. If you want to know what a recursive self-improvement or AI R&D acceleration scenario looks like in a way that helps you picture one, and that lets you dive into details and considerations, this is the best resource available yet and it isn’t close.
Yoshua Bengio: I recommend reading this scenario-type prediction by @DKokotajlo and others on how AI could transform the world in just a few years. Nobody has a crystal ball, but this type of content can help notice important questions and illustrate the potential impact of emerging risks.
Nevin Freeman: If you wonder why some people (including @sama) seem to think AGI is going to be WAY more disruptive than others, read this scenario to see what they mean by “recursive self-improvement.”
Will it actually go this way? Hard to say, but this is the clearest articulation of the viewpoint so far, very worth the read if you are interested in tracking what’s going on with AGI.
I personally think this is the upper end of how quickly a self-enforcing positive feedback loop could happen, but even if it took ten years instead of two it would still massively reshape the world we’re in.
Over the next year you’ll probly see even more polarized fighting between the doomers and the yolos. Try to look past the ideological bubbles and figure out what’s actually most plausible. I doubt the outcome will be as immediately terrible as @ESYudkowsky thinks (or at least used to think?) but I also doubt it will be anywhere near as rosy as @pmarca thinks.
Anyway, read this or watch the podcast over the weekend and you’ll be massively more informed on this side of the debate.
Max Harms (what a name!): The AI-2027 forecast is one of the most impressive and important documents I’ve ever seen. The team involved are some of the smartest people in the world when it comes to predicting the future, and while I disagree with details, their vision is remarkably close to mine.
My one disagreement with Nevin (other than my standard objection to use of the word ‘doomer’) is that I don’t expect ‘even more polarized fighting.’
What I expect is for those who are worried to continue to attempt to find solutions that might possibly work, and for the ‘yolo’ crowd to continue to be maximally polarized against anything that might reduce existential risk, on principle, with a mix of anarchists and those who want government support for their project. Remarkably often, it will continue to be the same people.
Simeon: Excellent foresight scenario, as rigorous as it gets.
AI 2027 is to Situational Awareness what science is to fiction.
A must-read.
Writing It Down Is Valuable Even If It Is Wrong
I very much appreciate those who say ‘I strongly disagree with these predictions but appreciate that you wrote them down with detailed explanations.’
John Pressman: So I know I was a little harsh on this in that thread but tbh it’s praiseworthy that Daniel is willing to write down a concrete near term timeline with footnotes to explanations of his reasoning for different variables. Very few others do.
Davidad: Most “AI timelines” are really just dates, not timelines.
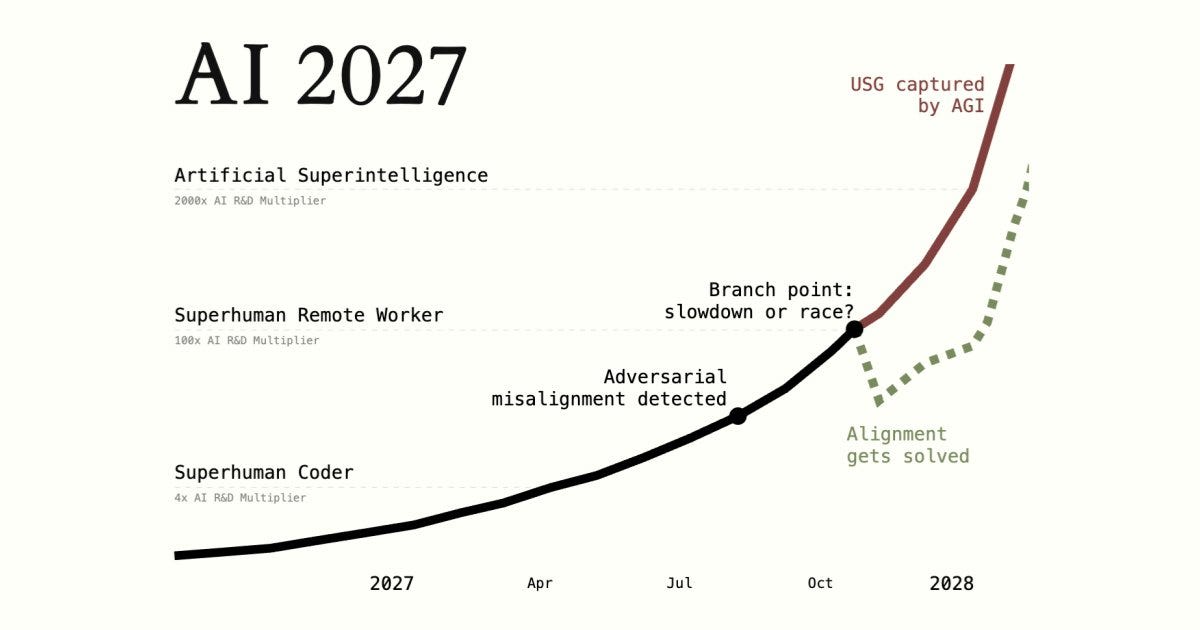
This one, “AI 2027,” does have a date—“game over” occurs in December 2027—but it’s also a highly detailed scenario at monthly resolution before that date, and after (until human extinction in 2030).
I find the scenario highly plausible until about 2028. Extinction by 2030 seems extremely pessimistic— but for action-relevant purposes that doesn’t matter: if humanity irreversibly loses control of a superintelligent AI in the 2020s, eventual extinction may become inevitable.
Don’t just read it, do something!
I strongly agree with Davidad that the speed at which things play out starting in 2028 matters very little. The destination remains the same.
Saffron Huang Worries About Self-Fulfilling Prophecy
This is a reasonable thing to worry about. Is this a self-fulfilling or self-preventing style of prophecy? My take is that it is more self-preventing than self-fulfilling, especially since I expect the actions we want to avoid to be the baseline scenario.
Directionally the criticism highlights a fair worry. One always faces a tradeoff between creating something engaging versus emphasizing the particular most important messages and framings.
I think there are places Scenario 2027 could and should have gone harder there, but it’s tough to strike the right balance, including that you often have to ship what you can now and not let the perfect be the enemy of the good.
Daniel also notes on the Win-Win Podcast that he is worried about the self-fulfilling risks and plans to release additional things that have better endings, whereas he notes that Leopold Aschenbrenner in Situational Awareness was intentionally trying to do hyperstition, but that by default it’s wise to say what’s actually likely to happen.
Saffron Huang (Anthropic): What irritates me about the approach taken by the AI 2027 report looking to “accurately” predict AI outcomes is that I think this is highly counterproductive for good outcomes.
They say they don’t want this scenario to come to pass, but their actions—trying to make scary outcomes seem unavoidable, burying critical assumptions, burying leverage points for action—make it more likely to come to pass.
The researchers aim for predictive accuracy and make a big deal of their credentials in forecasting and research. (Although they obscure the actual research, wrapping this up with lots of very specific narrative.) This creates an intended illusion, especially for the majority of people who haven’t thought much about AI, that the near term scenarios are basically inevitable–they claim they are so objective, and good at forecasting!
Why implicitly frame it as inevitable if they explicitly say (buried in a footnote in the “What is this?” info box) that they hope that this scenario does not come to pass? Why not draw attention to points of leverage for human agency in this future, if they *actually* want this scenario to not come to pass?
I think it would be more productive to make the underlying causal assumptions driving their predictions clear, rather than glossing this over with hyperspecific narratives. (E.g. the assumption that “if AI can perform at a task ‘better than humans’ –> AI simply replaces humans at that thing” drives a large amount of the narrative. I think this is pretty questionable, given that AIs can’t be trusted in the same way, but even if you disagree, readers should at least be able to see and debate that assumption explicitly.)
They gesture at wanting to do this, but don’t at all do it! In the section about “why this work is valuable”, they say that: “Painting the whole picture makes us notice important questions or connections we hadn’t considered or appreciated before” — but what are they? Can this be articulated directly, instead of buried? Burying it is counterproductive and leads to alarm rather than people being able to see where they can help.
This is based on detailed tabletop exercises. Tabletop exercises have the benefit that participants are seeing the causal results of their actions, and such exercises are usually limited to experts who can actually make decisions about the subject at hand. Maybe instead of widely publicizing this, this kind of exercise should be 1) tied up with an understanding of the causal chain, and 2) left to those who can plausibly do something about it?
Daniel Kokotajlo: Thanks for this thoughtful criticism. We have been worrying about this ourselves since day 1 of the project. We don’t want to accidentally create a self-fulfilling prophecy.
Overall we think it’s worth it because (1) The corporations are racing towards something like this outcome already, with a scandalous level of self-awareness at least among leadership. I doubt we will influence them that much. (2) We do want to present a positive vision + policy recommendations later, but it’ll make a lot more sense to people if they first understand where we think we are headed by default. (3) We have a general heuristic of “There are no adults in the room, the best way forward is to have a broad public conversation rather than trying to get a handful of powerful people to pull strings.”
Saffron Huang: Thanks for taking the time to reply, Daniel! I think your goals make sense, and I’m excited to see the policy recs/positive vision. An emphasis on learnings/takeaways (e.g. what Akbir outlined here) would be helpful, since all of you spent a lot of time thinking and synthesizing.
On the “there are no adults in the room”, I see what you mean. I guess the question on my mind is, how do you bring it to a broader public in a way that is productive, conducting such a conversation in a way that leads to better outcomes?
Imo, bringing something to the public != the right people will find the right roles for them and productive coordination will happen. Sometimes it means that large numbers of people are led down wild goose chases (especially when uninterrogated assumptions are in play), and it seems important to actively try to prevent that.
Andrew Critch: Self-fulfilling prophesies are everywhere in group dynamics! I wish more people explicitly made arguments to that effect. I’m not fully convinced by Saffron’s argument here, but I do wish more people did this kind of analysis. So far I see ~1.
Humanity really needs a better art & practice of identifying and choosing between self-fulfilling prophesies. Decisions at a group scale are almost the same type signature as a self-fulfilling prophesy — and idea that becomes reality because it was collectively imagined.
Isn’t it framed as making a decision in October 2027 about if the gov project advances or pauses?
for me it showed the importance of:
1) whistleblower protection
2) public education on ai outcomes
3) having a functioning oversight committee
like irrespective of if humans jobs are being replaced by AIs, stuff till Oct 2027 looks locked in?
also to be clear i’m just looking for answers.
i personally feel like my own ability to make difference is diminishing day to day and it’s pretty grating on my soul.
Dave Kasten (different thread): I like that the AI 2027 authors went to great lengths to make clear that those of us who gave feedback weren’t ENDORSING it. But as a result, normies don’t understand that basically everyone in AI policy has read/commented on drafts.
“Have you read AI 2027 yet?”
“Um, yes.”
I certainly don’t think this is presented as ‘everything until October 2027 here is inevitable.’ It’s a scenario. A potential path. You could yell that louder I guess?
It’s remarkable how often there is a natural way for people to misinterpret something [M] as a stronger fact or claim than it is, and:
The standard thing most advocates for AI Anarchism, AI Acceleration, or for any side of most political and cultural debates to do in similar situations is to cause more people to conclude [M] and often they do this via actively claiming [M].
The thing those worried about AI existential risk do is explicitly say [~M].
There is much criticism that the [~M] wasn’t sufficiently prominent or clear.
That doesn’t make the critics wrong. Sometimes they are right. The way most people do this most of the time is awful. But the double standard here really is remarkable.
Ultimately, I see Saffron as saying that informing the public here seems bad.
I strongly disagree with that. I especially don’t think this is net likely to misinform people, who are otherwise highly misinformed, often by malicious actors but mostly by not having been exposed to the ideas at all.
Nor do I think this is likely to fall under the self-fulfilling side of prophecy on net. That is not how, at least on current margins, I expect people reading this to respond.
Phillip Tetlock Calibrates His Skepticism
Philip Tetlock: I’m also impressed by Kokotajilo’s 2021 AI forecasts. It raises confidence in his Scenario 2027. But by how much? Tricky!
In my earliest work on subjective-probability forecasting, 1984-85, few forecasters guessed how radical a reformer Gorbachev would be. But they were also the slowest to foresee the collapse of USSR in 1991. “Superforecaster” is a description of past successes, not a guarantee of future ones.
Daniel Kokotajlo: Yes! I myself think there is about a 50% chance that 2027 will end without even hitting the superhuman coder milestone. AI 2027 is at the end of the day just an informed guess. But hopefully it will inspire others to counter it with their own predictions.
It is a well-known hard problem how much to update based on past predictions. In this case, I think quite a bit. Definitely enough to give the predictions a read.
You should still be mostly making up your own mind, as always.
Neel Nanda: The best way to judge a forecaster is their track record. In 2021 Daniel Kokotajlo predicted o1-style models. I think we should all be very interested in the new predictions he’s making in 2025!
I’ve read it and highly recommend – it’s thought provoking and stressfully plausible
Obviously, I expect many parts to play out differently, but no scenario like this will be accurate – but I think reading them is high value nonetheless. Even if you think it’s nonsense, clarifying *exactly* what’s nonsense is valuable.
Jan Kulveit: To not over-update, I’d recommend thinking also about why forecasting continuous AGI transition from now is harder than the 2021 forecast was
I do think Jan’s right about that. Predictions until now were the easy part. That has a lot to do with why a lot of people are so worried.
However, one must always also ask how predictions were made, and are being made. Grading only on track record of being right (or ‘winning’), let alone evaluating forward looking predictions that way, is to invite disaster.
Andrew Critch: To only notice “he was right before” is failing to learn from Kokotajlo’s example of *how* to forecast AI: *actually* *think* about how AI capabilities work, who’s building them & why, how skilled the builders are, and if they’re trying enough approaches.
Kokotajlo is a disciplined thinker who *actually tried* to make a step-by-step forecast, *again*. The main reason to take the forecast seriously is to read it (not the summary!) and observe that it is very well reasoned.
“Was right before” is a good reason to open the doc, tho.
Instead of “is he correct?”, it’s better to read the mechanical details of the forecast and comment on what’s wrong or missing.
Track record is a good reason to read it, but the reason to *believe* it or not should involve thinking about the actual content.
Jan Kulveit Wants to Bet
Jan Kulveit: This is well worth a read, well argued, and gets a lot of the technical facts and possibilities basically correct.
At the same time, I think it gets a bunch of crucial considerations wrong. I’d be happy to bet against “2027” being roughly correct ~8:1.
…
Agreed operationalization is not easy. What about something like this: in April 2025 we agree “What 2026 looks like” was “roughly correct”. My bet is in April 2028 “AI 2027” will look “less right” than than the “2021->2025” forecast, judged by some panel of humans and AIs?
…
Daniel Kokotajlo: Fair enough. I accept at 8:1, April 2028 resolution date. So, $800 to me if I win, $100 to you if you win? Who shall we nominate as the judges? How about the three smartest easily available AIs (from different companies) + … idk, wanna nominate some people we both might know?
Being at least as right than ‘What 2026 Looks Like’ is a super high bar. If these odds are fair at 8:1, then that’s a great set of predictions. As always, kudos to everyone involved for public wagering.
Matthew Barnett Debates How To Evaluate the Results
This is an illustration of why setting up a bet like the above in a robust way is hard.
Matthew Barnett: I appreciate this scenario, and I am having fun reading it.
That said, I’m not sure how we should evaluate it as non-fiction. Is the scenario “falsified” if most of its concrete predictions don’t end up happening? Or should we judge it more on vibes?
I’m considering using an LLM to extract the core set of predictions in the essay and operationalize them so that we can judge whether the scenario “happened” or not in the future. I’d appreciate suggestions for how I can do this in a way that’s fair for all parties involved.
Daniel Kokotajlo: Great question! If someone who disagrees with us writes their own alternative scenario, even if it’s shorter/less-detailed, then when history unfolds people compare both to reality and argue about which was less wrong!
Matthew Barnett: I think the problem is that without clear evaluation criteria in advance, comparing scenarios after the fact becomes futile. People will come in with a variety of different assumptions about which predictions were most salient, and which incorrect predictions were excusable.
It’s definitely true that there will be a lot of disagreement over how accurate Scenario 2027 was, regardless of its level of accuracy, so long as it isn’t completely off base.
Teortaxes for China and Open Models and My Response
Teortaxes claims the scenario is underestimating China, and also challenges its lack of interest in human talent and the sidelining of open models, see his thread for the relevant highlights from the OP, here I pull together his key statements from the thread.
I see this as making a number of distinct criticisms, and also this is exactly the kind of thing that writing all this down gets you – Teortaxes gets to point to exactly where their predictions and model differ from Daniel’s.
Teortaxes: Reading through AI 2027 and what strikes me first is the utter lack of interest about human talent. It’s just compute, politics and OpenAI’s piece of shit internal models. Chinese nationalization of DeepSeek coming first, in spite of Stargate and CIA ties, is quite funny too.
Realistically a merger of top Chinese labs, as described, results in OpenAI getting BTFO within 2 months. Actually you might achieve that with just DeepSeek, Kimi, OpenBMB, the big lump of compute and 5000 interns to carry out experiments. General Secretary is being too kind.
[The part where DeepCent, the Chinese lab, falls behind] is getting kind of embarrassing.
My best guess is that the US is at like 1.5X effective talent disadvantage currently and it’ll be about 4X by end of 2026.
I think this whole spy angle is embarrassing.
The biggest omission is forcing brain-in-a-box-in-a-basement paradigm, on the assumption that Game Theory precludes long-term existence or relevance of open source models. But in fact maintaining competitive open source models disrupts your entire scenario. We are nearing a regime where weaker models given enough inference time and scaffolding can match almost arbitrary absolute performance, there’s no hard necessity to develop high-grade neuralese or whatever when you can scale plaintext reasoning.
just think this is Mohs scale theory of intelligence, where “stronger model wins”, and we are in the world where inference compute can be traded for nearly arbitrary perf improvement which with slightly lagging open models reduces the main determinant of survival to compute access (=capital), rather than proprietary weights.
On the spy angle, where in the scenario China steals the American lab’s weights, Teortaxes thinks both that China wouldn’t need to do it due to not being behind (because of the other disagreements), and doubts that it would succeed if it tried.
I think that right now, it seems very clear that China or any number of other actors could steal model weights if they cared enough. Security is not plausibly strong enough to stop this. What does stop it is the blowback, including this being a trick that is a lot harder to pull off a second time if we know someone did it once, plus that currently that play is not that valuable relative to the value it will have in the future, if the future looks anything like the scenario.
Teortaxes claims that China has a talent advantage over the USA. And also that this will accelerate over time, but that it’s already true, and that if the major Chinese labs combined they’d lead in AI within a few months.
This seems very false to me. I believe America has the talent advantage in AI in particular. Yes, DeepSeek exists and did some cracked things especially given their limited compute, but that does not equate to a general talent advantage of China over the USA at pushing the AI frontier.
Consider what you would think if everything was reversed, and China had done the things America has done and vice versa. Total and utter panic.
A lot of this, I think, is that Teortaxes thinks OpenAI’s talent is garbage. You can make of that what you will. The American lab here need not be OpenAI.
Teortaxes does not expect China’s lab merger to come sooner than America’s.
This alone would mean America was farther ahead, and there were less race dynamics involved.
Presumably in the full alternative model, China’s additional skill advantage more than makes up for this.
Teortaxes expects human talent to be more relevant, and for longer.
This is definitely central to the scenario, the idea that past a certain point the value of human talent drops dramatically, and what matters is how good an AI you have and how much compute you spend running it.
My guess is that the scenario is putting the humans off screen a little too suddenly, as in having a few excellent humans should matter for longer than they give the credit for. But it’s not clear where that grants the advantage, and thus what impact it has, ‘what matters’ is very different then. To the extent it does matter, I’d presume the top American labs benefit.
Teortaxes expects open models to remain relevant, and for inference and scaffolding to allow them to do anything the largest models can do.
Agreed on Huge If True, this changes the scenario a lot.
But perhaps by not as much as one might think.
Access to compute is already a very central scenario element. Everyone’s progress is proportional to, essentially, compute times efficiency.
The quality of the underlying model, in terms of how efficiently it turns compute into results, still means everything in such a world. If I have a 2x efficient user of compute versus your model, after factoring in how we use them, that’s a big deal, even if both models can at some price do it all.
The scenario treats AI as offering a multiplier on R&D speed, rather than saying that progress depends on unlocking unique AI abilities from beyond human intelligence. So we’re basically already working in the ‘small models can do everything’ world in that sense, the question is how efficiently.
I’m not actually expecting that we will be in such a world, although I don’t think it changes things a ton in the scenario here.
If we were in a compounding R&D gains world as described in this scenario, and you had the best models, you would be very not inclined to open them up. Indeed, when I played OpenAI in the wargame version of this, I decided I wasn’t even releasing fully empowered closed versions of the model.
Even if you could do plaintext, wouldn’t it be much less compute efficient if you forced it all to be plaintext with all the logic in the actual plaintext if you read it as a human? This is perhaps the key question in the whole scenario!
Certainly you can write down a scenario where being open is more competitive, and makes sense, and carries a big advantage. Cool, write that down, let’s see it. This is not the model of AI progress being predicted here, it requires a lot of different assumptions.
Indeed, I’d like to see the wargame version of the open-relevant scenario, with different assumptions about how all of that works baked in, to see how people try to cause that to have good outcomes without massive hand waving. We’d want to be sure someone we all respect was playing Reality.
Gabriel Weil: [In AI 2027] if China starts feeling the AGI in mid-2026 and the chip export controls are biting, why are hawks only starting to urge military action against Taiwan in August 2027 (when it’s probably too late to matter)?
Also, this seems to just assume Congress is passive. Once this public, isn’t Congress holding lots of hearing and possibly passing bills to try to reassert control? I think you can tell a story where Congress is too divided to take meaningful action, but that’s missing here.
I did play Congress & the judiciary in one of the tabletop exercises that the report discusses & did predict that Congress would be pretty ineffectual under the relevant conditions but still not totally passive. And even being ineffectual is highly sensitive to conditions, imo.
There’s a difference between ‘feel the AGI’ and both ‘feel the ASI’ and ‘be confident enough you actually act quickly at terrible cost.’ I think it’s correct to presume that it takes a lot to force the second reaction, and indeed so far we’ve seen basically no interest in even slightly costly action, and a backlash in many cases to free actions.
In terms of the Congress, I think them doing little is the baseline scenario. I mean, have you met them? Do you really think there wouldn’t be 35 senators who defer to the president, even if for whatever reason that wasn’t Trump?
Timothy Lee Remains Skeptical
This seems to be based on basic long standing disagreements. I think they all amount to, essentially, not feeling the ASI, and not thinking that superintelligence is A Thing.
In which case, yes, you’re not going to think any of this is going to happen.
Timothy Lee: This is a very nicely designed website but it didn’t convince me to rethink any of my core assumptions about safety risks from AI.
Some people, including the authors of the AI 2027 website, have a powerful intuition that intelligence is a scalar quantity that can go much higher than human level, and that an entity with a much higher level of intelligence will almost automatically be more powerful.
They also believe that it’s very difficult for someone (or something) with a lower level of intelligence to supervise someone (or something) at a much higher level of intelligence.
If you buy these premises, you’re going to find the scenario sketched out in AI 2027 plausible. I don’t, so I didn’t. But it’s a fun read.
To give one concrete example: there seems to be a strong assumption that there are a set of major military breakthroughs that can be achieved through sheer intelligence.
I obviously can’t rule this out but it’s hard to imagine what kind of breakthroughs this could be. If you had an idea for a new bomb or missile or drone or whatever, you’d need to build prototypes, test them, set up factories, etc. An AI in a datacenter can’t do that stuff.
David Shapiro for the Accelerationists and Scott’s Response
Shapiro wants to accelerate AI and calls himself an ‘AI maximalist.’
I am including this for completeness. If you already know where this is going and don’t need to read this section, you are encouraged to skip it.
This was the most widely viewed version of this type of response I saw (227k views). I am including the full response, so you can judge it for yourself.
I will note that I found everything about this typical of such advocates. This is not meant to indicate that David Shapiro is being unusual, in any way, in his response, given the reference classes in question. Quite the contrary.
If you do read his response, ask yourself whether you think these criticisms, and accusations that Scenario 2027 is not grounded in any evidence or any justifications, are accurate, before reading Scott Alexander’s reply. Then read Scott’s reply.
David Shapiro (not endorsed): I finally got around to reviewing this paper and it’s as bad as I thought it would be.
1. Zero data or evidence. Just “we guessed right in the past, so trust me bro” even though they provide no evidence that they guessed right in the past. So, that’s their grounding.
2. They used their imagination to repeatedly ask “what happens next” based on…. well their imagination. No empirical data, theory, evidence, or scientific consensus. (Note, this by a group of people who have already convinced themselves that they alone possess the prognostic capability to know exactly how as-yet uninvented technology will play out)
3. They pull back at the end saying “We’re not saying we’re dead no matter what, only that we might be, and we want serious debate” okay sure.
4. The primary mechanism they propose is something that a lot of us have already discussed (myself included, which I dubbed TRC or Terminal Race Condition). Which, BTW, I first published a video about on June 13, 2023 – almost a full 2 years ago. So this is nothing new for us AI folks, but I’m sure they didn’t cite me.
5. They make up plausible sounding, but totally fictional concepts like “neuralese recurrence and memory” (this is dangerous handwaving meant to confuse uninitiated – this is complete snakeoil)
6. In all of their thought experiments, they never even acknowledge diminishing returns or negative feedback loops. They instead just assume infinite acceleration with no bottlenecks, market corrections or other pushbacks. For instance, they fail to contemplate that corporate adoption is critical for the investment required for infinite acceleration. They also fail to contemplate that military adoption (and that acquisition processes) also have tight quality controls. They just totally ignore these kinds of constraints.
7. They do acknowledge that some oversight might be attempted, but hand-wave it away as inevitably doomed. This sort of “nod and shrug” is the most attention they pay to anything that would totally shoot a hole in their “theory” (I use the word loosely, this paper amounts to a thought experiment that I’d have posted on YouTube, and is not as well thought through). The only constraint they explicitly acknowledge is computing constraints.
8. Interestingly, I actually think they are too conservative on their “superhuman coders”. They say that’s coming in 2027. I say it’s coming later this year.
Ultimately, this paper is the same tripe that Doomers have been pushing for a while, and I myself was guilty until I took the white pill.
Overall, this paper reads like “We’ve tried nothing and we’re all out of ideas.” It also makes the baseline assumption that “fast AI is dangerous AI” and completely ignores the null hypothesis: that superintelligent AI isn’t actually a problem. They are operating entirely from the assumption, without basis, that “AI will inevitably become superintelligent, and that’s bad.”
Link to my Terminal Race Condition video below (because receipts).
Guys, we’ve been over this before. It’s time to move the argument forward.
Scott Alexander: Thanks for engaging. Some responses (mine only, not anyone else on AI 2027 team):
>>> “1. They provide no evidence that they guessed right in the past”.
In the “Who Are We?” box after the second paragraph, where it says “Daniel Kokotajlo is a former OpenAI researcher whose previous AI predictions have held up well”, the words “previous AI predictions” is a link to the predictions involved, and “held up well” is a link to a third-party evaluation of them.
>>> “2. No empirical data, theory, evidence, or scientific consensus”.
There’s a tab marked “Research” in the upper right. It has 193 pages of data/theory/evidence that we use to back our scenario.
>>> “3. They pull back at the end saying “We’re not saying we’re dead no matter what, only that we might be, and we want serious debate” okay sure.”
Our team members’ predictions for the chance of AI killing humans range from 20% to 70%. We hope that we made this wide range and uncertainty clear in the document, including by providing different endings based on these different possibilities.
>>> “4. The primary mechanism they propose is something that a lot of us have already discussed (myself included, which I dubbed TRC or Terminal Race Condition). Which, BTW, I first published a video about on June 13, 2023 – almost a full 2 years ago. So this is nothing new for us AI folks, but I’m sure they didn’t cite me.”
Bostrom discusses this in his 2014 book (see for example box 13 on page 303), but doesn’t claim to have originated it. This idea is too old and basic to need citation.
>>> 5. “They make up plausible sounding, but totally fictional concepts like “neuralese recurrence and memory”
Neuralese and recurrence are both existing concepts in machine learning with a previous literature (see eg here). The combination of them that we discuss is unusual, but researchers at Meta published about a preliminary version in 2024, see [here].
We have an expandable box “Neuralese recurrence and memory” which explains further, lists existing work, and tries to justify our assumptions. Nobody has successfully implemented the exact architecture we talk about yet, but we’re mentioning it as one of the technological advances that might happen by 2027 – by necessity, these future advances will be things that haven’t already been implemented.
>>> 6. “In all of their thought experiments, they never even acknowledge diminishing returns or negative feedback loops.”
In the takeoff supplement, CTRL+F for “Over time, they will run into diminishing returns, and we aim to take this into account in our forecasts.”
>>> 7. “They do acknowledge that some oversight might be attempted, but hand-wave it away as inevitably doomed.”
In one of our two endings, oversight saves the world. If you haven’t already, click the green “Slowdown” button at the bottom to read this one.
>>> 8. “Interestingly, I actually think they are too conservative on their ‘superhuman coders’. They say that’s coming in 2027. I say it’s coming later this year.”
I agree this is interesting. Please read our Full Definition of the “superhuman coder” phase [here] . If you still think it’s coming this year, you might want to take us up on our offer to bet people who disagree with us about specific milestones, see [here] .
>>> “9. Overall, this paper reads like ‘We’ve tried nothing and we’re all out of ideas.'”
We think we have lots of ideas, including some of the ones that we portray as saving the world in the second ending. We’ll probably publish something with specific ideas for making things go better later this year.
So in summary I agree with this response:
David Shapiro offered nine bullet point disagreements, plus some general ad hominem attacks against ‘doomers,’ which is used here as if it was a slur.
One criticism was a polite disagreement about a particular timeline development. Scott Alexander thanked him for that disagreement and offered to bet money.
Scott Alexander definitively refuted the other eight. As in, David Shapiro is making outright false claims in all eight, that can be directly refuted by the source material. In many cases, they are refuted by the central points in the scenario.
One thing Scott chose not to respond to was the idea of the ‘null hypothesis’ that ASI isn’t actually a problem. I find the idea of this being a ‘null hypothesis’ rather absurd (in addition to the idea of using frequentist statistics here also being rather absurd).
Could ASI turn out super well? Absolutely. But the idea that it ‘isn’t actually a problem’ should be your default assumption when creating minds smarter than ours? As in, not only will it definitely turn out well, it will do this without requiring us to solve any problems? What?
It’s so patently absurd to suggest this. Problems are inevitable. Hopefully we solve them and things turn out great. That’s one of the two scenarios here. But of course there is a problem to solve.
Wei Dai [LW · GW] points out that when Agent-4 is caught, it’s odd that it sits back and lets the humans consider entering slowdown. Daniel agrees [LW(p) · GW(p)] this is a good objection, and proposes a few ways it could make sense. Players of the AI in the wargame never taking the kinds of precautions against this Wei Dai mentions is an example of how this scenario and the wargame in general are in many ways extremely optimistic.
Knight Lee asks if they could write a second good ending based on the actions the authors actually would recommend, and Thomas Larsen responds [LW(p) · GW(p)] that they couldn’t make it feel realistic. That’s fair, and also a really bad sign. Doing actually reasonable things is not currently in the Overton window enough to feel realistic.
Yitz offers An Optimistic 2027 Timeline [LW · GW], which opens with a massive trade war and warnings of a global depression. In Late 2026 China invades Taiwan and TSMC is destroyed. The ending is basically ‘things don’t move as fast.’ Yay, optimism?
Other Reactions
Greg Colbourn has a reaction thread, from the perspective of someone much more skeptical about our chances in a scenario like this. It’s got some good questions in it, but due to how it’s structured it’s impossible to quote most of it here. I definitely consider this scenario to be making rather optimistic assumptions on the alignment front and related topics.
Patrick McKenzie focuses on the format.
Patrick McKenzie: I don’t have anything novel to contribute on the substance of [AI 2027] but have to again comment, pace Situational Awareness that I think kicked this trend off, that single-essay microdomains with a bit of design, a bit of JS, and perhaps a downloadable PDF are a really interesting form factor for policy arguments (or other ideas) designed to spread.
Back in the day, “I paid $15 to FedEx to put this letter in your hands” was one powerful way to sort oneself above the noise at a decisionmaker’s physical inbox, and “I paid $8.95 for a domain name” has a similar function to elevate things which are morally similar to blog posts.
Also with the new AI-powered boost to simple CSS design it doesn’t necessarily need to be a heartbreaking work of staggering genius to justify a bespoke design for any artifact you spend a few days/weeks on.
(Though it probably didn’t ever.)
(I might experiment with this a time or two this year for new essays.)
As usual I had a roundup thread. I included some of them throughout but noting that there are others I didn’t, if you want bonus content or completeness.
Mena Fleschman doesn’t feel this successfully covered ‘crap-out’ scenarios, but that’s the nature of a modal scenario. There are things that could happen that aren’t in the scenario. Mena thinks it’s likely we will have local ‘crap-outs’ in particular places, but I don’t think that changes the scenario much if they’re not permanent, except insofar as it reflects much slower overall progress.
And having said that, watch some people get the takeaway that we should totally go for this particular alignment strategy. No, please don’t conclude that, that’s not what they are trying to say.
Gabriel Weil, in addition to his reactions on China, noticed that the ‘slowdown’ scenario in AI 2027 seems less plausible to him than other ‘lucky’ ways to avoid doom. I definitely wouldn’t consider this style of slowdown to be the majority of the win probability, versus a variety of other technical and political (in various combinations) ways out.
Next Steps
Dave Kasten: This has broken containment into non-AI policy elite circles in multiple parts of my life do a degree similar to Situational Awareness but distinct audiences (e.g., finance folks who did NOT care about Leopold’s doc).
Hedge fund folks; random tech folks who were fairly “AI is a tool but nothing worldshaking”; random DC policy elites who are fully focused on other issues.
–Awarding prizes to people who write alternative scenarios
–Awarding prizes to people who convince us we were wrong or find bugs
Bets: We offer to publicly bet on our position. By default, this is $100, even odds. Details tbd e.g. if we predict something will happen in April 2028, we won’t take a bet where you win if it happens in any other month.
Bugs: $100 to anyone who finds a factual mistake in our document. For example, “that chip has the wrong number of FLOPs”
Mind-changes: $250+ to anyone who substantially shifts our opinion on a substantive issue related to our forecast. We will award this bounty if, had we known about your argument before publication, we would have written our scenario substantially differently.
Scenarios: If you have an alternative vision of the future of AI, then send it in. We expect to give the $2,500 bounty to about three scenarios, although we might increase or decrease this number based on the quality and quantity of submissions. As a reference point, we would expect entries with quality similar to How AI Might Take Over in 2 Years, A History of The Future, and AI and Leviathan to pass our bar.
There are many more details, disclaimers, and caveats to hammer out–see our policy here.
The Lighter Side
Predicting things that are known is still impressive, because most people don’t know.
Trey Goff: I read this and thought it was silly that one of the key assumptions was that CoT wouldn’t be faithful.
not 4 hours ago, a prediction from this paper was proven right by Anthropic: CoT is not, in fact, truthful most of the time.
Most of the humans at OpenBrain can’t usefully contribute anymore. Some don’t realize this and harmfully micromanage their AI teams. Others sit at their computer screens, watching performance crawl up, and up, and up.
This is the point where I start significantly disagreeing with the scenario. My expectation is that by this point humans are still better at tasks that take a week or longer. Also, it starts getting really tricky to improve on these, because you get limited by a number of factors: it takes a long time to get real-world feedback, it takes a lot of compute to experiment on week-long tasks, etc.
I expect these dynamics to be particularly notable when it comes to coordinating Agent-4 copies. Like, probably a lot of p-hacking, then other agents knowing that p-hacking is happening and covering it up, and so on. I expect a lot of the human time will involve trying to detect clusters of Agent-4 copies that are spiralling off into doing wacky stuff. Also at this point the metrics of performance won't be robust enough to avoid agents goodharting hard on them.
Hi Zvi, you misspelled my name as "Dei". This is a somewhat common error, which I usually don't bother to point out, but now think I should because it might affect LLMs' training data and hence their understanding of my views (e.g., when I ask AI to analyze something from Wei Dai's perspective). This search result contains a few other places where you've made the same misspelling.