Goodhart's Imperius
post by Duncan Sabien (Deactivated) (Duncan_Sabien) · 2021-10-29T20:19:42.291Z · LW · GW · 6 commentsContents
Claim 1: Goodhart’s Law is true. Claim 2: When attempting to do operant conditioning with a given reward or punishment, for any desired strength-of-conditioning-effect, there exists a sufficiently small delay between behavior and consequence that will produce that effect. Claim 3: Our nonverbal systems aggregate and analyze a tremendous amount of sensory data into implicit causal models, and those causal models produce binary approach-avoid signals when we encounter new stimuli, based on whether or not (according to those models) those stimuli will be helpful or hurt... Claim 4: Our brains condition us, often without us noticing. Conclusion: Your brain is conditioning you, all the time, often beneath your notice, toward proxies that, based on past experience, are likely to take you closer to your goals rather than farther away from them. Furthermore, by the combination of Claims 2 and 3, this conditioning is effective — it a... Shitty corollary: Because proxies are always leaky, your brain is conditioning you wrong. None 6 comments
Author's note: this essay was originally written to reflect a class that I was actively teaching and iterating at CFAR workshops circa 2017. While it never made it into the handbook proper, and isn't quite in the same format as the other handbook entries, I've added it to the sequence anyway. Had my employment with CFAR continued, it would have eventually been fleshed out into a full handbook entry, and it dovetails nicely with the Taste and Shaping unit. Epistemic status: mixed/speculative.
Claim 1: Goodhart’s Law is true.
Goodhart’s Law (which is incredibly appropriately named) reads “any measure which becomes a target ceases to be a good measure.” Another way to say this is “proxies are leaky,” i.e. the proxy never quite gets you the thing it was intended to get you.
If you want to be able to differentiate between promising math students and less-promising ones, you can try out a range of questions and challenges until you cobble together a test that the 100 best students (as determined by other assessments, such as teacher ratings) do well on, and the following 900 do worse on.
But as soon as you make that test into the test, it’s going to start leaking. In the tenth batch of a thousand students, the 100 best ones will still do quite well, but you’ll also get a bunch of people who don’t have the generalized math skill you're looking for, but who did get good at answering the specific, known questions. Your top 100 will no longer be composed only of the 100 actual-best math students—and things will just keep getting worse, over time.
This is analogous to what’s happened with Western diets and sugar. Prehistoric primates who happened to have a preference for sweet things (fruit) also happened to get a lot more vitamins and minerals and calories, and therefore they survived and thrived at higher rates than those sugar-ambivalent primates who failed to become our ancestors and died out. The process of natural selection turned a measure for nutrition (sweetness) into a target (a biologically hardwired "belief" that more sugar = more utility), which was fine right up until we learned to efficiently separate the sugar from the nutrients (teaching to the test) and discovered that our preferences were hardwired to the proxy rather than to the Actual Good Thing.
Claim 2: When attempting to do operant conditioning with a given reward or punishment, for any desired strength-of-conditioning-effect, there exists a sufficiently small delay between behavior and consequence that will produce that effect.
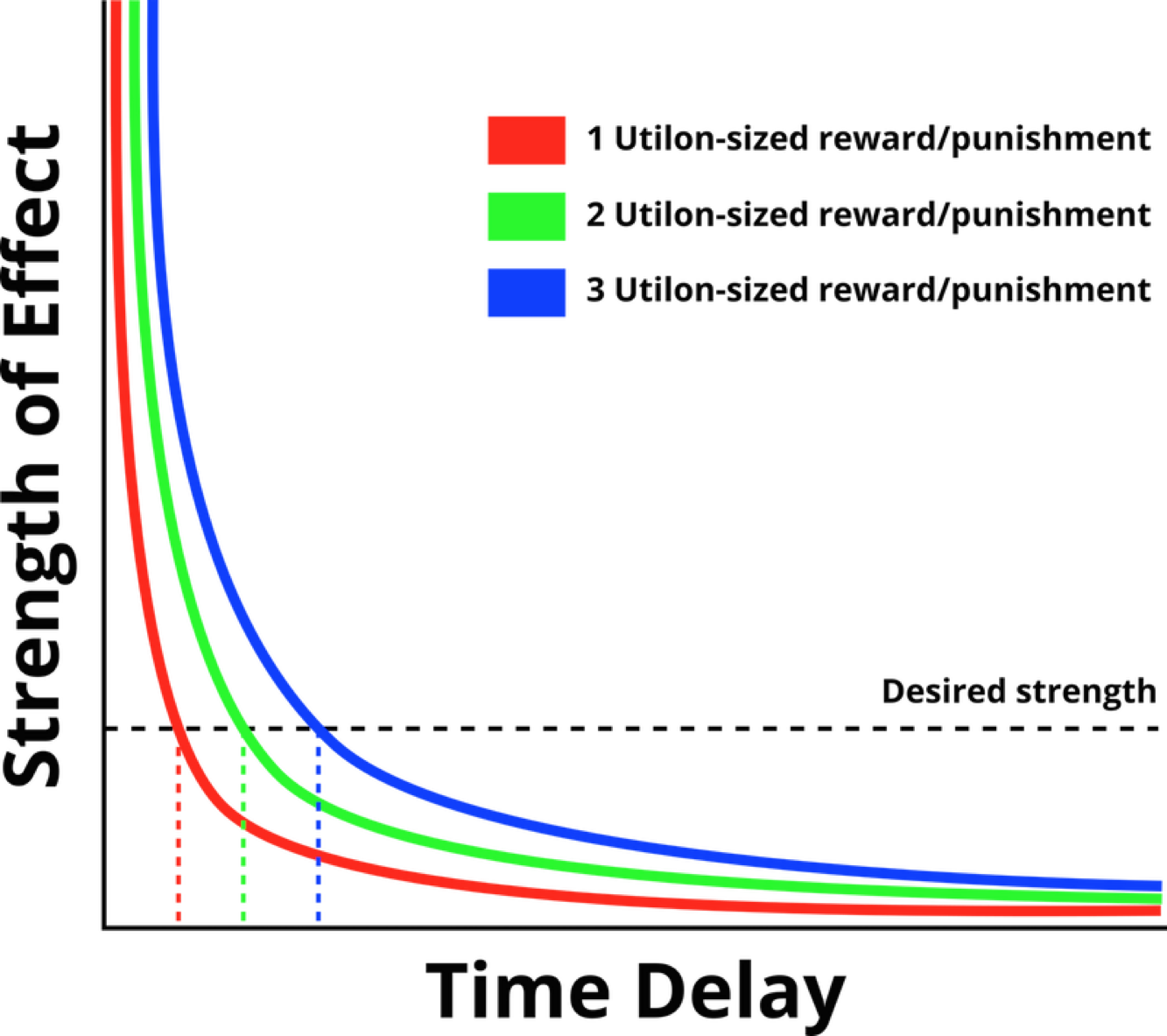
This one is not literally true. In order for it to be literally true, the hyperbolic nature of discounting (such that closer rewards are disproportionately more effective in creating reinforcement) would have to extend off to absurdity such that an infinitesimally small reward or response could produce an arbitrarily large conditioning effect if it was immediately proximal to the relevant behavior, and if that were true then clicker training (in which you use a click sound that’s been associated with treats and compliments and other rewards to signal to a dog that you like what it just did) wouldn’t reinforce the distant behavior of rolling over but would instead reinforce something like the last blink of the dog’s eye before the soundwave of the click reached the dog’s ear.
However, I claim it is effectively true, for rewards as small as fleeting thoughts or shifts in emotion, and for time scales as small as hundredths of a second. If I want an anti-Oreo conditioning effect that is as strong as the pleasure-burst I receive from eating an Oreo, I can in fact get it, even with a stimulus as small as a thought—provided that thought pops up quickly enough.
(This is actually why clicker training is a thing—because you literally cannot deliver a treat quickly enough to produce effects of the size you can get through the much-tighter feedback loop provided by the audio channel. If you can make a click into a positive reward for a dog, then you’re better off clicking than tossing cheese cubes.)
(For more on this, look into hyperbolic discounting. For a hint as to why hyperbolic discounting, consider that if ten seconds and many small events pass between behavior and consequence, it takes a lot more scanning-through-possible-causal-links to identify that that particular behavior is what resulted in the consequence, and become confident in the connection. Tighter feedback loops are stronger because our primitive systems can more easily track and confirm them, and believe in them at a gut level.)
Claim 3: Our nonverbal systems aggregate and analyze a tremendous amount of sensory data into implicit causal models, and those causal models produce binary approach-avoid signals when we encounter new stimuli, based on whether or not (according to those models) those stimuli will be helpful or hurtful re: progress toward our goals.
I think this is what CFAR instructor Anna Salamon is after when she talks about “taste.” Imagine a veteran doctor who has, in their long career, chased down the explanations for hundreds of confusing, confounded, or hitherto-unknown ailments. In investigating a thousand hypotheses, maybe 100 of them panned out, and 800 of them led to brick walls, and 100 of them remain inconclusive. The part of their brain that builds and maintains a rich, inner model of the universe is (quietly, under the hood) drawing connections between those investigations, subconsciously noting the elements that the successful ones had in common versus the elements that the unsuccessful ones had in common. When our doctor encounters a new patient and starts investigating, some part of their system makes a lightning-fast comparison—does this new line of research feel like or resemble those ones which previously paid off, or is it more reminiscent of those ones that ended in frustration?
That information gets compressed into a quick yes-or-no, good-or-bad, approach-or-avoid signal—a gut sense of doom or optimism, interest or disinterest. To the extent that there’s been lots of relevant experience and the new situation is in the same class as the old ones, this sense can be extremely accurate and valuable—what we call taste or intuition or second nature—and even when there’s been very little training data, this sense can still provide useful insight.
Claim 4: Our brains condition us, often without us noticing.
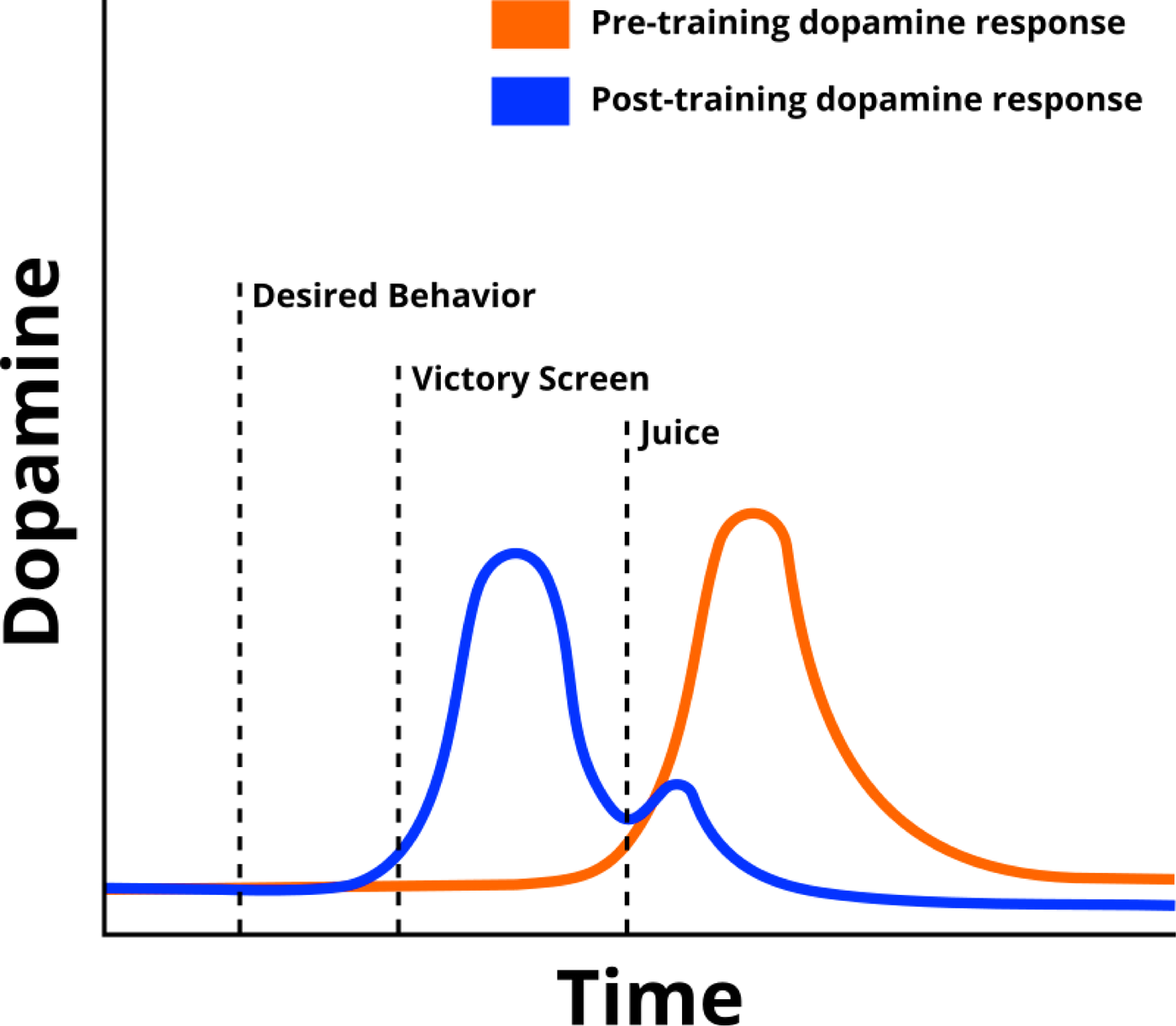
In brief: there were studies with monkeys whose brains were hooked up to detectors and who had straws positioned to squirt juice into their mouths. When those monkeys exhibited desired behaviors, the scientists would give them a shot of juice, and the detectors would register a dopamine spike.
After a while, though, the dopamine spike migrated. It became associated with a “victory!” screen that the scientists would flash whenever the monkey performed a desired behavior, just like a dog begins to associate clicks with treats and other rewards.
Pause to let yourself be confused for a second. Don’t gloss over this.
What. The. Heck.
The dopamine spike moves? How? Why?
I claim that what’s going on is that the monkey’s brain, separate from the monkey/the monkey’s explicit reasoning/any sapient or strategic awareness that the monkey has, is conditioning the monkey.
Remember, a system that is capable of learning from its environment and meaningfully updating on that learning is more likely to survive and thrive than one that does not, so it makes sense that the monkey would have some functional, adaptive processes in place to shape its own behavior.
Basically, the monkey’s brain has access to a) a ton of data, and b) carrots-and-sticks, in the form of pleasure and pain responses. The brain is sitting there wondering how the heck it can get this monkey to perform adaptive behavior, just like a human is sitting there wondering how the heck it can get the dog to roll over. The brain has a model of what sorts of behaviors will lead to success and thriving, just as the human has a model of what cute doggy behavior looks like.
And the brain "knows" that, with a shot of pleasure, the monkey is vastly more likely to repeat the action it just tried.
(It’s actually more subtle than that—the orbitofrontal cortex is releasing dopamine, which acts as a “do that again” button for patterns of neural response. In short, when the OFC picks up on an adaptive pattern, it releases dopamine to tell whatever neurons just fired to fire again in the same pattern.)
Things that lead to juice are hard-wired to produce a spike of pleasure, so that juice-seeking behavior will be reinforced. But then the brain slowly starts to notice that there’s no decision-tree node between a victory screen and juice — once the screen flashes, juice is inevitable.
So the relevant behavior must be further back. The brain starts reinforcing victory screens as a proxy for juice (which itself is a primordial proxy for calories and micronutrients). Whenever the victory screen appears, the monkey is rewarded by its own brain, such that it becomes more likely to do whatever it was doing just before the screen appeared. And all of this is happening below the level of conscious attention for the monkey — all it knows is it likes juice and it likes being happy and it does things that previously led to juice and happiness. Eventually, the monkey’s brain starts rewarding behavior even further back (though probably with a lighter wash of anticipatory exhilaration rather than a sharp spike of pleasure): game actions that lead to victory screens that lead to juice that lead to happiness.
Conclusion: Your brain is conditioning you, all the time, often beneath your notice, toward proxies that, based on past experience, are likely to take you closer to your goals rather than farther away from them. Furthermore, by the combination of Claims 2 and 3, this conditioning is effective — it actually influences behavior to a meaningful degree.
Shitty corollary: Because proxies are always leaky, your brain is conditioning you wrong.
Case in point: Hypothetical Me is trying to lose weight (which is just another proxy), and I’ve decided to weigh myself every day because what gets measured gets managed (ha). My brain isn’t explicitly smart, just implicitly clever, and it’s on my side. It slowly starts to figure out that high scale numbers = bad, and low scale numbers = good, and it decides to do whatever it can with that information and its ability to send me visceral signals.
But I’ve had a few high scale number days, and because humans are risk-averse and loss-averse, those high scale number days hurt pretty badly and they get bumped up in the priority list. So my brain is sitting there with mirror-twin goals of maximize exposure to low scale numbers and minimize exposure to high scale numbers, and it doesn’t really know how to do the former, but it sure as heck can do something about the latter, which is the one that seems more urgent anyway.
So I glance toward my bathroom scale, and—often at a level too low to grab my conscious attention—my brain deals me a helpful “owch” that disincentivizes the glance I just made. And because the owch was near-instantaneous, it works (see Claim 1). After a few iterations of this, I’m successfully conditioned into developing a big ol’ blind spot where my bathroom scale is, such that I never even notice it anymore (and often such that I don’t even notice that I’m not noticing).
If I’m lucky, eventually my train of thought wanders, and my real goal floats back up to the front of my mind, and I realize what’s going on, and I say “thanks for trying, brain,” (because it really is doing heroic work; don’t beat your brain up for getting it just a tiny bit wrong because guess what, the beating-up is far closer to the noticing than it is to the mistake-making that you’re actually trying to disincentivize, think about the implications aaahhhhhhhhhhh) and then I do a quick meditation on what the incentives ought to be and try to produce a gut-level shift in the right direction.
But if I’m not lucky, this just becomes a part of my blind spot forever.
And if I ask myself how lucky I think I am, i.e. how many times I successfully dodge this failure mode for all of my various hopes and intentions and plans and so forth—
(Caveat: epistemic status of all of this is somewhat tentative, but even if you assign e.g. only 70% confidence in each claim (which seems reasonable) and you assign a 50% hit to the reasoning from sheer skepticism, naively multiplying it out as if all of the claims were independent still leaves you with a 12% chance that your brain is doing this to you, which is large enough that it seems at least worth a few cycles of trying to think about it and hedge against the possibility.)
6 comments
Comments sorted by top scores.
comment by Anon User (anon-user) · 2021-10-30T04:06:57.409Z · LW(p) · GW(p)
For a while, I tended to be running late in certain situations. I would glance at my watch, notice I am late, and think "oh, f***!" One day, I caught myself where being in a similar situation, I glanced at my watch, and immediately thought "oh, f***!" - then realized I did not actually do the step where I figure out what time my watch displayed, and whether I was running behind. In fact, that particular time I was still OK on time...
comment by Rohin Shah (rohinmshah) · 2021-11-01T09:59:26.163Z · LW(p) · GW(p)
Caveat: epistemic status of all of this is somewhat tentative, but even if you assign e.g. only 70% confidence in each claim (which seems reasonable) and you assign a 50% hit to the reasoning from sheer skepticism, naively multiplying it out as if all of the claims were independent still leaves you with a 12% chance that your brain is doing this to you, which is large enough that it seems at least worth a few cycles of trying to think about it and ameliorate the situation.
Fwiw, my (not-that-well-sourced-but-not-completely-made-up) impression is that the overall story is a small extrapolation of probably-mainstream neuroscience, and also consistent with the way AI algorithms work, so I'd put significantly higher probability on it (hard to give an actual number without being clearer about the exact claim).
(For someone who wants to actually check the sources, I believe you'd want to read Peter Dayan's work.)
(I'm not expressing confidence in specific details like e.g. turning sensory data into implicit causal models that produce binary signals.)
comment by Leon Lang (leon-lang) · 2023-01-24T19:06:37.250Z · LW(p) · GW(p)
Summary:
- Claim 1: Goodhart’s Law is true
- “Any measure which becomes the target ceases to be a good measure”
- Examples:
- Any math test supposed to find the best students will cease to work at the 10th iteration — people then “study to be good at the test”
- Sugar was a good proxy for healthy food in the ancestral environment, but not today
- Claim 2: If you want to condition yourself to a certain behavior with some reward, then that’s possible if only the delay between behavior and reward is small enough
- Claim 3: Over time, we develop “taste”: inexplicable judgments of whether some stimulus may lead to progress toward our goals or not.
- A “stimulus” can be as complex as “this specific hypothesis for how to investigate a disease”
- Claim 4: Our Brains condition us, often without us noticing
- With this, the article just means that dopamine spikes don’t exactly occur at the low-level reward, but already at points that predictably will lead to reward.
- Since the dopamine hit itself can “feel rewarding”, this is a certain type of conditioning towards the behavior that preceded it.
- In other words, the brain gives a dopamine hit in the same way as the dog trainer produces the “click” before the “treat”.
- We often don’t “notice” this since we don’t usually explicitly think about why something feels good.
- With this, the article just means that dopamine spikes don’t exactly occur at the low-level reward, but already at points that predictably will lead to reward.
- Conclusion: Your brain conditions you all the time toward proxy goals (“dopamine hits”), and Goodhart’s law means that conditioning is sometimes wrong
- E.g., if you get an “anti-dopamine hit” for seeing the number on your bathroom scale, then this may condition you toward never looking at that number ever again, instead of the high-level goal of losing weight
comment by riceissa · 2021-11-02T20:38:50.788Z · LW(p) · GW(p)
Author's note: this essay was originally published pseudonymously in 2017. It's now being permanently rehosted at this link. I'll be rehosting a small number of other upper-quintile essays from that era over the coming weeks.
Have you explained anywhere what brought you back to posting regularly on LessWrong/why you are now okay with hosting these essays on LessWrong? Did the problems you see with LessWrong get fixed in the time since when you deleted your old content? (I haven't noticed any changes in the culture or moderation of LessWrong in that timeframe, so I am surprised to see you back.)
(I apologize if this comment is breaking some invisible Duncan rule about sticking to the object-level or something like that. Feel free to point me to a better place to ask my questions!)
Replies from: Duncan_Sabien↑ comment by Duncan Sabien (Deactivated) (Duncan_Sabien) · 2021-11-03T05:32:57.366Z · LW(p) · GW(p)
I have not explained, no.
I think this comment is entirely prosocial, and is not breaking any rules of mine. That being said, I don't have a legible answer prepared, and my partner's about to have surgery, so I think the best way to get one out of me is to bug me through other channels in a week or something.
comment by Gunnar_Zarncke · 2021-10-31T14:19:59.894Z · LW(p) · GW(p)
Telling your brain that it did work well has a lot of upsides. I think that's why a Gratitude Journal [LW · GW] works so well.