Predictive Processing, Heterosexuality and Delusions of Grandeur
post by lsusr · 2022-12-17T07:37:39.794Z · LW · GW · 13 commentsContents
A Simple Clock Simple Behavior Cultivating Abstract Concepts Reinforcement Motivating the Pursuit of Abstract Concepts None 13 comments
Predictive processing is the theory that biological neurons minimize free energy. In this context, free energy isn't physical energy like the energy in your laptop battery. Instead, free energy is an informatic concept. It is useful to think about free energy as a single variable balancing prediction error and model complexity. Minimizing free energy balances minimizing prediction error against minimizing model complexity. You can also think about it as minimizing surprise.
Biological neurons have inputs and outputs. Each neuron receives inputs from one set of neurons and sends outputs to another set of neurons. One way to minimize prediction error is to fire right after receiving inputs, but an even better way to minimize prediction error is for a neuron to anticipate when its input neurons will fire and then fire along with them. Firing in-sync with its inputs produces zero prediction error instead of just a small prediction error.
It has been shown that predictive processing is asymptotically equivalent to backpropagation [LW · GW]. Everything that can be computed with backpropagation can be computed via predictive processing and vice versa.
A Simple Clock
Suppose you take a 3-dimensional blob of neurons programmed to minimize local prediction error and you attach them to a sinusoidal wave generator. The neural net has no outputs—just this single input. At first the neurons close to the wave generator will lag behind the sinusoidal wave generator. But eventually they'll and sync up with it. Our neural net will have produced an internal representation of the world.
Now suppose you plug a sinusoidal wave generator into the left end of the neural net and a square wave generator into the right end of the neural net. The left end of the neural net will wave in time with the sinusoidal wave generator and the right end of the neural net will beat in time with the square wave generator. The middle of the net will find some smooth balance between the two. Plug more complicated inputs into our neural net and it will generate a more complicated representation of the world.
Simple Behavior
Consider a neural net with one input and one output. The output of the brain is connected to the input of a static noise generator and the static noise generator's output is connected to the brain's input. The brain is a free energy minimizer. Static noise has high free energy. The brain will thus tend to produce outputs that minimize the noise. In other words, the brain will figure out (if it can) how to turn off the static noise generator.
Scientists used this principle to train a blob of neurons to play pong. They connected a biological neural net to a game of pong and then blasted the net with static whenever the net failed to hit the ball. Result: the paddle intercepted the ball more often than random chance.
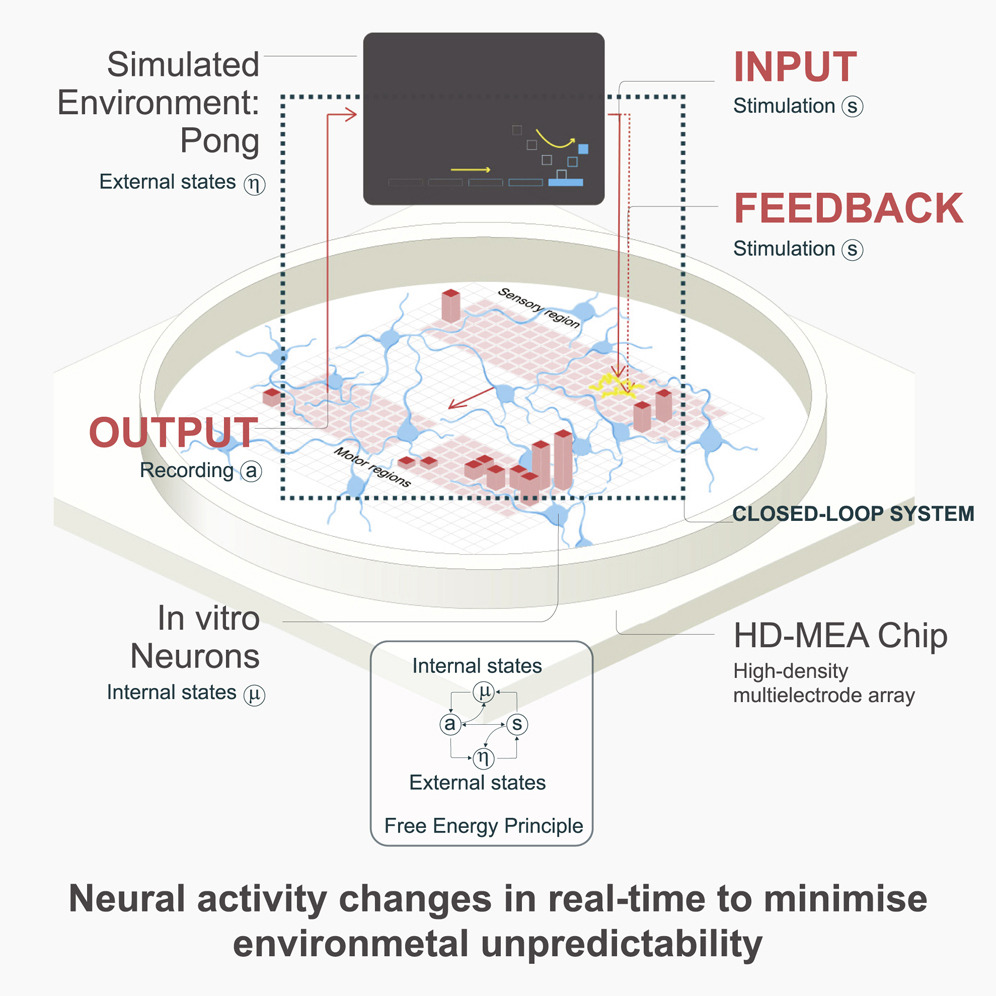
We now have all the ingredients we need to build a simple nervous system. Start with a net of neurons. Attach sensory inputs to the net. The net will create an internal model of the world. Whenever something bad happens (such as the organism suffering damage), blast the net with a short, intense burst of random noise. The organism will learn to avoid whatever causes the short, intense bursts of random noise. We have invented pain.
Cultivating Abstract Concepts
Some features of the environment can be hard-coded. You don't need to learn how to feel pain or feel warmth. All evolution has to do is invent the relevant sensors and then emit a burst of static (in the case of pain) or a less-noisy signal (in the case of warmth).
Other features cannot be hard-coded at all. Your brain contains no priors about whether whether Obanazawa is in the Yamagata Prefecture. Facts like that are purely learned.
But some features of the environment are partially hard-coded and partially learned.
I'm heterosexual (straight). Being straight is normative in the sense that most people are straight. Heterosexuality makes sense in evolutionary terms too. But being straight is computationally bizarre. If given the chance to kiss a healthy woman my age in a dark room then I would say yes. If given the chance to kiss a healthy man my age in a dark room then I would say no. But I can't actually tell whether I'm making out with a man or woman (assuming the man has shaved) just from the feeling of her/his lips. Evolution programmed me to prefer the abstract concept of a woman to the abstract concept of a man.
How can evolution condition a predictive processing biological net to learn an abstract concept like "woman"? Culture plays a role, but heterosexuality is older than culture. I think the answer has something to do with checksums [LW · GW].
Suppose you want a certain region of a biological neural net to activate in response to seeing a woman. The concept of a "woman" is too abstract to define exactly. All you have are a bunch of heuristics that are all correlated with observing a woman. For example, you could have one heuristic which fires in response to high-pitched voices, another which fires in response to more complicated inflection, another which fires in response to seeing breasts and so on. Feed the outputs of all these heuristics into the inputs of region . Loosely couple region to the rest of your world model. Region will eventually learn to trigger in response to the abstract concept of a woman. Region will even draw on other information in the broader world model when deciding whether to fire.
Reinforcement
So far we have discussed how to punish our neural network: just blast it with pain. But we have not yet discussed how to reward our neural network.
Dopamine has something to do with reward, motivation and reinforcement, but not pleasure. My guess is that when dopamine is released it temporarily increases the brain's learning rate—the amount that connections are updated—by a lot. If this is true then we ought to expect dopamine releases to produce short-term local overfitting, and to cause behavior that is globally maladaptive (increases free energy) in the long run.
There is one potential problem with this theory: It is a long-established fact in behavioral psychology that intermittent reinforcement are more motivating than predictable reinforcement. But predictive processing seeks to minimize surprise. Why would a system that seeks to minimize surprise be more motivated by surprising rewards than by predictive rewards? I don't know, but here's a guess: dopamine is released in response to surprising positive outcomes.
Why "surprising positive outcomes" and not just "positive outcomes"? Because there is no reason to adjust the weights of a neural network in response to an unsurprising outcome.
Motivating the Pursuit of Abstract Concepts
Suppose we have used checksums to create a high-level concept like "my personal status". One way to motivate status-seeking behavior would be to squirt the brain with dopamine whenever "my personal status" goes up. But that's not a stable solution because it doesn't actually seek to maintain consistently high status. Instead, it just seeks surprising increases in status. Dopamine is useful, but if you rely purely on dopamine hits to motivate behavior then your neural network will become a compulsive gambler. We can't rely just on dopamine hacks. We have to go back to free energy.
Let's go back to the "my personal status" cortex of the predictive brain which I will call "region ". Region was produced by feeding several heuristics—perhaps "how much people like me", "how rich I am" and "whether I have sex with attractive people"—into region . Suppose that these heuristics generate signals of "1" and you're high-status and "-1" when you're low-status. Region learns to generate a signal of "1" when you're high-status and "-1" when you're low-status.
What happens when we feed a signal of "1" into region ? If the brain is already in a high-status organism then nothing will happen. But if the brain is in a low-status organism then our signal of "1" will cause a conflict, thus increasing free energy of region . Predictive processors produce signals that minimize free energy. If our brain is operating properly then it will attempt to resolve the conflict by outputting behavior that it anticipates will cause its status to rise. We have programmed status-seeking behavior.
That's if things go right. If things go wrong[1] then our neural net will conclude that it has high status despite all evidence to the contrary. We have programmed schizophrenia.
Edit 2022-02-16. There's a reason this doesn't actually work in a real biological brain. It's that real neurons will learn to ignore an input that's hard-coded to a value of 1. I plan to address this problem in a future post. ↩︎
13 comments
Comments sorted by top scores.
comment by abramdemski · 2023-02-16T22:15:45.355Z · LW(p) · GW(p)
It has been shown that predictive processing is asymptotically equivalent to backpropagation. Everything that can be computed with backpropagation can be computed via predictive processing and vice versa.
The notion of 'predictive coding' in the result you cite here is inconsistent with the notion of 'predictive processing' you cite later in the Pong-playing result. Versions of predictive coding equivalent to backprop solve the credit assignment problem [LW · GW] by assuming that the relevant causal links are all, and only, the links of the computational network (IE the neural network). In other words, the PC algorithm assumes that the score for an individual prediction can only depend on the prediction itself (which in turn can only depend on its direct inputs, which can in turn only depend on the inputs to that, etc back thru the network).
In other words, it doesn't learn to plan ahead to minimize overall prediction error. It only learns to adjust weights locally to minimize local error.
So if you apply noise to the whole network, it doesn't learn to actively avoid such noise. Each neuron would incorrectly blame itself for its own error, effectively introducing noise into the learning function.
Hm. I suppose there would be a global effect where the network random-walks when it is getting a lot of noise, and moves around less when it is getting less noise. However, I would not expect this to be anywhere near as efficient as real reinforcement learning, since the network continues to randomly tweak itself whenever it gets some noise anyway. Also I'm not sure exactly how this part works out, since presumably the network learns to estimate entropy; so maybe it (effectively) adjusts the step size to be lower in higher-noise regions of parameter space??
Replies from: lsusr↑ comment by lsusr · 2023-02-17T02:09:27.441Z · LW(p) · GW(p)
The notion of 'predictive coding' in the result you cite here is inconsistent with the notion of 'predictive processing' you cite later in the Pong-playing result.
You're right. That's not even the only reason my two uses of "predictive processing" are inconsistent. Another one is that the pong result has a concept of time whereas the backpropagation-equivalent "predictive processing" has no concept of time.
In other words, it doesn't learn to plan ahead to minimize overall prediction error. It only learns to adjust weights locally to minimize local error.
You're right again. But one implication of Predictive Coding has been Unified with Backpropagation is that local error minimization converges to global error minimization (for well-behaved functions).
So if you apply noise to the whole network, it doesn't learn to actively avoid such noise. Each neuron would incorrectly blame itself for its own error, effectively introducing noise into the learning function.
Some of the neurons would be to blame. Other neurons are not to blame. The neurons that are to blame would be nudged in the right direction. The neurons that are not to blame would be nudged in random directions. I agree that this is a crude, noisy way to train a neural network. But there is a signal and the signal does point in the right direction. It's not just a random walk.
You're are correct that there is a random walk effect too and that the random walk also pushes the network away from pain.
[Edit: Corrected "Your" to "You're".]
Replies from: abramdemski↑ comment by abramdemski · 2023-02-17T06:10:20.006Z · LW(p) · GW(p)
You're right again. But one implication of Predictive Coding has been Unified with Backpropagation is that local error minimization converges to global error minimization (for well-behaved functions).
I worried you would respond this way at this point in my message. I should have been more careful about what I meant by local vs global there. By "global" I wanted to say something like, tracking credit assignment beyond the causal network of the computation graph itself. That is to say, tracking the possibility that the decision at output 1 might have influence on the loss at output 2, even though output 2 doesn't depend on output 1 in the network. For example, policy-gradient algorithms do this, while gradient descent on predictive accuracy doesn't.
Some of the neurons would be to blame. Other neurons are not to blame. The neurons that are to blame would be nudged in the right direction. The neurons that are not to blame would be nudged in random directions. I agree that this is a crude, noisy way to train a neural network. But there is a signal and the signal does point in the right direction. It's not just a random walk.
Your are correct that there is a random walk effect too and that the random walk also pushes the network away from pain.
I'm not quite sure what claim you're making and I suspect we still disagree. It seems to me like there's an empirical disagreement which could be tested: namely, can we get NNs to play Pong without any RL technique?
I'm not sure exactly how to flesh out the claim, but I predict that the random noise thing would be a much weaker Pong player than policy gradient.
(Note that policy gradient isn't an extremely strong method, itself; it doesn't have any world model. In situations where the reward is high variance, it still treats it as a learning signal, superstitiously boosting/negating behaviors. A learner with a world model can learn that rewards are high variance in specific situations, and "ignore" the unreliable training signal, absorbing it into an estimation of the mean reward in those circumstances.
So the shortcomings of policy gradient might actually be comparable to the shortcomings of the apply-noise learning method; both sort of random-walk in the presence of uncontrollable risks. So I think it's sort of a fair comparison.)
Replies from: lsusr↑ comment by lsusr · 2023-02-17T06:50:20.858Z · LW(p) · GW(p)
I'm not familiar with policy-gradient algorithms. When you write "tracking credit assignment beyond the causal network of the computation graph itself", I don't understand what you mean either. What do you mean?
It seems to me like there's an empirical disagreement which could be tested: namely, can we get NNs to play Pong without any RL technique?…I'm not sure exactly how to flesh out the claim, but I predict that the random noise thing would be a much weaker Pong player than policy gradient.
This sounds like a concrete scenario we can disagree about, but when you predict that the random noise thing would be weaker than policy gradient, I agree with you—and I don't even know what a policy gradient is. The random noise thing is awful. I just claim that it works. I don't claim that it works well.
To clarify, I consider the random noise thing to be so convoluted it ends up in the grey zone between "RL" and "not RL". I think you disagree, but I'm not sure in what direction. Do you consider the weird random noise thing to be a kind of RL?
I think we can get NNs to play pong without RL (for my definition of RL—yours may differ) but it's complicated, I haven't fully fleshed it out yet, and it's even weirder than the random noise thing. The posts you've been reading and commenting on are building up to that. But we're not there yet.
By the way, what, precisely, you mean when you write "reinforcement learning"?
Replies from: abramdemski↑ comment by abramdemski · 2023-02-17T20:13:59.006Z · LW(p) · GW(p)
I'm not familiar with policy-gradient algorithms.
So, as you may know, RL is divided into model-based and model-free. I think of policy gradient as the most extremely model-free. Basically you take the summed reward of an entire episode to be a black-box training signal. You're better off if you can estimate a baseline reward so that you know whether to treat an episode as 'good' or 'bad' to the extent it falls above/below baseline, but you don't even need to do this. I think this is basically because if all rewards are positive, you can gradient toward 'what I did this round', and larger gradients will pull you more toward the good, while smaller gradients will still pull you toward the bad, but less so. Similar reasoning applies if some or all rewards are negative.
(Policy-gradient doesn't actually need to be episodic, however. You can also blur out credit assignment based on temporal discounting, rather than discrete episodes.)
When you write "tracking credit assignment beyond the causal network of the computation graph itself", I don't understand what you mean either. What do you mean?
This is absolutely central to my point, so I'll spend a while trying to make this clear.
Imagine a feedforward neural network doing supervised learning. For each output generated, you get a loss, which you can attribute 100% to the output. You can then work back -- you know how to causally attribute the output value to its inputs one layer back. You know how to causally attribute those to the next layer back. And so on.
This is like an assembly-line factory where you are trying to optimize some feature of the output, based on near-complete understanding & control of the causal system of the factory. You can attribute features of the output to one stage back in the assembly line. You can attribute what happens one stage back to what happened one stage before that. And so on. If you aren't satisfied with the output, you can work your way back and fiddle with whatever contributed to the output, because the entire causal system is under your control.
(The same idea applies to recurrent NNs; we just need to track the activations back in time, rather than only through a single pass through the network. Factories are, of course, more like recurrent NNs than feedforward NNs, since variables like supply of raw materials, & state of repair of machines, will vary over time based on how we run the factory.)
Now imagine a neural network doing reinforcement learning, in a POMDP environment. You can't attribute the reward this round to the action this round, so you can't work your way backwards to fix the root cause of a problem in the same way -- you don't have the full causal model, because an important part of the causality leading to this specific reward is outside, in the environment. In general, the next reward might depend on any or all of your past actions.
This is more like a company trying to maximize profits. You can still tweak the assembly-line as much as you want, but your quarterly profits will depend on what you do in a mysterious way. Bad quarterly profits might be due to a bad reputation which you got based on your products from two years ago. Although you know your factory, you can't firmly attribute profits in a given quarter to factory performance in a specific quarter.
Model-based RL solves this by making a causal model of the environment, so that we can do credit assignment via our current estimated causal model. We don't know that our current slump in sales is due to the bad products we shipped two years ago, but it might be our best guess. In which case, we think we've already taken appropriate actions to correct our assembly-line performance, so all we can do for now is spend some more money on advertising, or what-have-you.
Model-free RL solves this problem without forming a specific causal model of the environment. Instead, credit has to be assigned broadly. This is metaphorically like giving everyone stock options, so that everyone in the company gets punished/rewarded together. (Although this metaphor isn't great, because it commits the homunculus fallacy by ascribing agency to all the little pieces -- makes sense for companies, not so much for NNs. Really it's more like we're adjusting all the pieces of the assembly line all the time, based on the details of the model-free alg.)
This sounds like a concrete scenario we can disagree about, but when you predict that the random noise thing would be weaker than policy gradient, I agree with you—and I don't even know what a policy gradient is. The random noise thing is awful. I just claim that it works. I don't claim that it works well.
It sounds like we won't be able to get much empirical traction this way, then.
My question to you is: what's so interesting about the PP analysis of the Pong experiment, then, if you agree that the random-noise-RL thing doesn't work very well compared to alternatives? IE, why derive excitement about a particular deep theory about intelligence (PP) based on a really dumb learning algorithm (noise-based RL)?
I'm not saying this is dumb. I have expressed excitement about generalizations of the Pavlov learning strategy [LW · GW] despite it being a really dumb, terrible RL algorithm. (Indeed, it has some similarity to the noise-RL idea!) That's because this learning algorithm, though dumb, accomplishes something which others don't (namely, coordinating on pareto-optimal outcomes in multi-agent situations, while being selfishly rational in single-agent situations, all without using a world-model that distinguishes "agents" from "non-agents" in any way). The success of this dumb learning method gives me some hope that smarter methods accomplishing the same thing might exist.
So when I say "what's so interesting here, if you agree the algorithm is pretty dumb", it's not entirely rhetorical.
Replies from: lsusr↑ comment by lsusr · 2023-02-20T00:06:50.428Z · LW(p) · GW(p)
Thank you for the explanations. They were crystal-clear.
[W]hat's so interesting about the PP analysis of the Pong experiment, then, if you agree that the random-noise-RL thing doesn't work very well compared to alternatives? IE, why derive excitement about a particular deep theory about intelligence (PP) based on a really dumb learning algorithm (noise-based RL)?
What alternatives? Do you mean like flooding the network with neurotransmitters? Or do you mean like the stuff we use in ML? There's lots of better-performing algorithms that you can implement on an electronic computer, but many of them just won't run on evolved biological neuron cells.
Why the Pong experiment caught my attention is that it is relatively simple on the hardware side, which means it could have evolved very early in the evolutionary chain.
Replies from: abramdemski↑ comment by abramdemski · 2023-02-24T17:26:15.851Z · LW(p) · GW(p)
Well, I guess another alternative (also very simple on the hardware side) would be the generalization of the Pavlov strategy which I mentioned earlier. This also has the nice feature that lots of little pieces with their own simple 'goals' can coalesce into one agent-like strategy, and it furthermore works with as much or little communication as you give it (so there's not automatically a communication overhead to achieve the coordination).
However, I won't try to argue that it's plausible that biological brains are using something like that.
I guess the basic answer to my question is that you're quite motivated by biological plausibility. There are many reasons why this might be, so I shouldn't guess at the specific motives.
For myself, I tend to be disinterested in biologically plausible algorithms if it's easy to point at other algorithms which do better with similar efficiency on computers. (Although results like the equivalence between predictive coding and gradient descent can be interesting for other reasons.) I think bounded computation has to do with important secrets of intelligence, but for example, I find logical induction to be a deeper theory of bounded rationality than (my understanding of) predictive processing - predictive processing seems closer to "getting excited about some specific approximation methods" whereas logical induction seems closer to "principled understanding of what good bounded reasoning even means" (and in particular, obsoletes the idea that bounded rationality is about approximating [LW · GW], in my mind).
Replies from: lsusr↑ comment by lsusr · 2023-02-25T19:05:42.830Z · LW(p) · GW(p)
I guess the basic answer to my question is that you're quite motivated by biological plausibility. There are many reasons why this might be, so I shouldn't guess at the specific motives.
You're right. I want to know how my own brain works.
But if you're more interested in a broader mathematical understanding of how intelligence, in general, works, then that could explain some of our motivational disconnect.
Replies from: abramdemski↑ comment by abramdemski · 2023-02-26T19:00:48.257Z · LW(p) · GW(p)
An important question is whether PP contains some secrets of intelligence which are critical for AI alignment. I think some intelligent people think the answer is yes. But the biological motivation doesn't especially point to this (I think). If you have any arguments for such a conclusion I would be curious to hear it.
Replies from: lsusrcomment by CronoDAS · 2024-09-27T02:53:41.986Z · LW(p) · GW(p)
If things go wrong[1] then our neural net will conclude that it has high status despite all evidence to the contrary. We have programmed schizophrenia.
No, you've programmed grandiose delusions - a lot more goes wrong with schizophrenia than just that.
comment by Catnee (Dmitry Savishchev) · 2022-12-18T02:55:01.512Z · LW(p) · GW(p)
Feed the outputs of all these heuristics into the inputs of region . Loosely couple region to the rest of your world model. Region will eventually learn to trigger in response to the abstract concept of a woman. Region will even draw on other information in the broader world model when deciding whether to fire.
I am not saying that the theory is wrong, but I was reading about something similiar before, and I still don't understand why would such a system, "region W" in this case, learn something more general than the basic heuristics that were connected to it? It seems like it would have less surprise if it would just copy-paste the behavior of the input.
The first explanation that comes to mind: "it would work better and have less surprise as a whole, since other regions could use output of "region W" for their predictions". But again, I don't think that I understand that. I think "region W" doesn't "know" about other regions surprise rates and hence cannot care about it, so why would it learn something more general and thus contradictory to the heuristics in some cases?
↑ comment by lsusr · 2022-12-18T03:40:50.000Z · LW(p) · GW(p)
A predictive processor doesn't just minimize prediction error. It minimizes free energy. Prediction error is only half of the free energy equation. Here is a partial explanation that I hope will begin to help clear up some confusion.
Consider the simplest example. All the heuristics agree. Then region will just copy and paste the inputs.
But now suppose the heuristics disagree. Suppose 7 heuristics output a value of 1 and 2 heuristics output a value of -1. Region could just copy the heuristics, but if it did then of the region would have a value of -1 and of the region would have a value of 1. A small region with two contradictory values has high free energy. If the region is tightly coupled to itself then the region will round the whole thing to 1 instead.