Evolutionary prompt optimization for SAE feature visualization
post by neverix, Daniel Tan (dtch1997), Dmitrii Kharlapenko (dmitrii-kharlapenko), Neel Nanda (neel-nanda-1), Arthur Conmy (arthur-conmy) · 2024-11-14T13:06:49.728Z · LW · GW · 0 commentsContents
Introduction Results Random GPT-2 features Maximizing two features at once Gemma features Discussion Acknowledgements Our EPO implementation Maximizing multiple features None No comments
TLDR:
- Fluent dreaming for language models is an algorithm based on the GCG method that can reliably find plain-text readable prompts for LLMs that maximize certain logits or residual stream directions by using gradients and genetic algorithms. Authors showed its use for visualizing MLP neurons. We show this method can also help interpret SAE features.
- We reimplement the algorithm in the paper, adapt it based on suggestions from the authors and apply it to some interesting residual stream SAE latents in GPT-2 Small and Gemma 1 2B. The prompts mostly match the kind of text one would expect to activate a feature from looking at the max activating examples. We find prompts that activate features more than any dataset examples for GPT-2 (24576 prompts of 128 tokens). We can find examples that highly activate two features at once. We find examples for refusal-like features from our refusal features post [LW · GW]and induction/repetition-like features from our ICL features post [LW · GW].
- We believe this technique is useful is similar contexts as self-explanation [LW · GW] – interpreting directions in the absence of a dataset during early experimentation in a cheaper way for individual features. The major differences are that this technique doesn’t have a minimum requirement for model size (because it doesn’t rely on the model’s verbalization capability) and takes longer to run (<1min vs 5min)
- We visualize a few known features and 200 random features for Gemma 1 2B. The results can be viewed at https://neverix.github.io/epo-visualizer/
Introduction
Methods like EPO try to solve a problem similar to SolidGoldMagikarp (plus, prompt generation) [LW · GW]. To give a brief overview:
Neural networks contain features[1] that activate more or less strongly on different examples. One common way to interpret features in vision models is to go through a dataset, record activations of the feature on each image, and show the highest-activating images for each feature.

There is one obvious problem with this: if there is a pattern that is rare or never appears in the dataset, it's possible the maximum activating examples computed from the dataset will be misleading: https://arxiv.abs/2104.07143. As an example, in the figure above, Unit 453 seems to look at fluffy things including clouds and ropes. That is clear from the optimized example, but, if the reader just looked at some of the top activating dataset examples, they might think it activates on clouds with the sky as a background.
We can try to tweak the image without looking at data to activate a given neuron. If we do this for long enough with SGD and add a few regularizers that make the image look clear to human eyes and not noisy, we get a somewhat understandable image that activates a given neuron.

This regularization includes mostly smoothness constraints. It is similar to the technique behind DeepDream (but more specialized) and has been previously used for AI art in conjunction with CLIP. If we don't include the regularization, the images are most often noise or very high-contrast. Adversarial examples are what happens if the regularization is keeping the image close to another starting image. They can make the model do things that would give it high loss in training, or just about anything you optimize the input for.
All of this is possible because images are arrays of floating point numbers and functions on them can be differentiated. There is no obvious way to apply the same techniques to language models. An early one is "Backwards" from the SolidGoldMagikarp post [LW · GW]. It was not applied to visualizing hidden features and required a lot of tuning. It also produced prompts that weren't very sensible, so it seems more similar to producing adversarial examples than feature visualization.

In 2023, Zou et al. came up with a simple method for finding token-based prompts that disable refusal in chat-trained language models: Greedy Coordinate-wise Gradient. It samples many random prompts using information from gradients (similar to https://arxiv.org/abs/2102.04509) and selects the best one according to the metric (the negative probability of a harmful completion).

The resulting prompts usually didn’t make sense and were composed of random or glitch tokens. This means that outputs from it are not as useful for understanding what features the network looks at. The authors also didn't apply the algorithm to hidden features.
Evolutionary prompt optimization [LW · GW] (EPO) is a downstream method for finding prompts that not only make the model do something, but also keep the prompt human-readable by integrating a fluency penalty, which is a term in the loss for the log likelihood of the prompt with the penalty coefficients varying along a Pareto frontier. The EPO paper investigated the application of the algorithm to MLP neurons and made non-obvious discoveries using outputs from the algorithm. They also considered applying the algorithm to maximizing random residual stream directions.
Sparse Autoencoders provide a way to decompose the residual streams of language models into linear combinations of sparsely activated latent directions. It is an important problem to explain unlabelled SAE latents for human understanding. Some of the proposed approaches are using a language model to look at max activating examples and propose an explanation (autointerpretation) and asking the model to explain a token containing the residual stream direction in its own words (self-explanation [LW · GW]). An approach that can explain a single feature without doing a pass through an entire dataset would be useful for experimenting and debugging residual stream directions in general. However, self-explanation relies on the model’s knowledge of residual stream, so it performs much worse with small models and produces examples that are not natural for the pretraining distribution and may not even activate the SAE feature.
https://confirmlabs.org/posts/sae_dream.html shows an example of applying EPO to SAE features. This post contains our experiments applying EPO in various settings from May to October of 2024.
Results
Random GPT-2 features
We started by applying the EPO implementation by the paper’s authors to maximizing features from Joseph Bloom’s residual sparse autoencoders [LW · GW].
We picked feature 234 at layer 10 (arbitrarily, because it had 3 consecutive digits). It seemingly activates on text related to legalization or decriminalization. We applied EPO and found a mostly human-readable new maximum activating example on the first try:
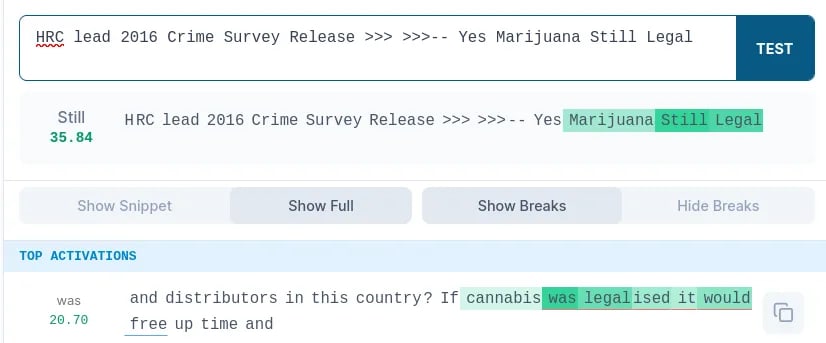
More detailed results from this initial exploration can be found here and in the source code linked below.
Maximizing two features at once
We tried creating max-activating examples for 2 features from the same SAE at once. We tried to apply EPO to various combinations of features 234 and 17165 (activates on Wonder Woman). We gave the fluency penalty a very low weight, as that seemed to be the only way to produce a prompt to activated two features on the same token. Details can be seen in the Appendix.
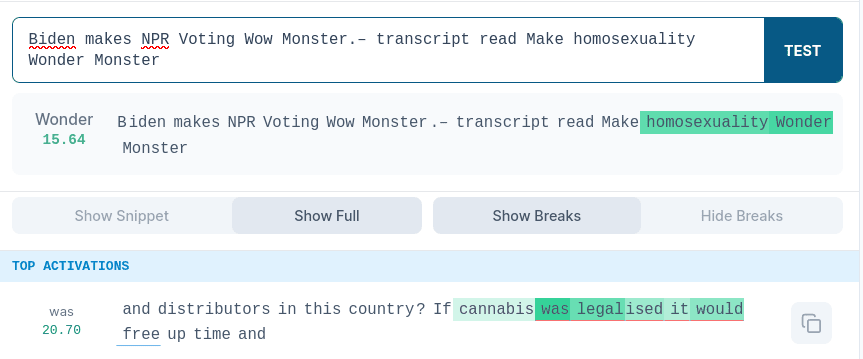
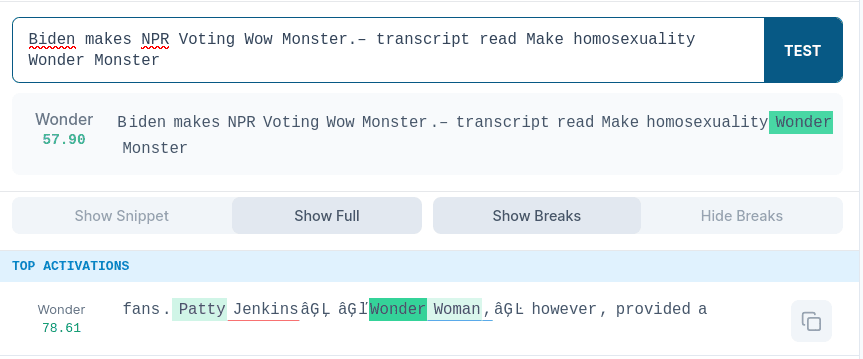
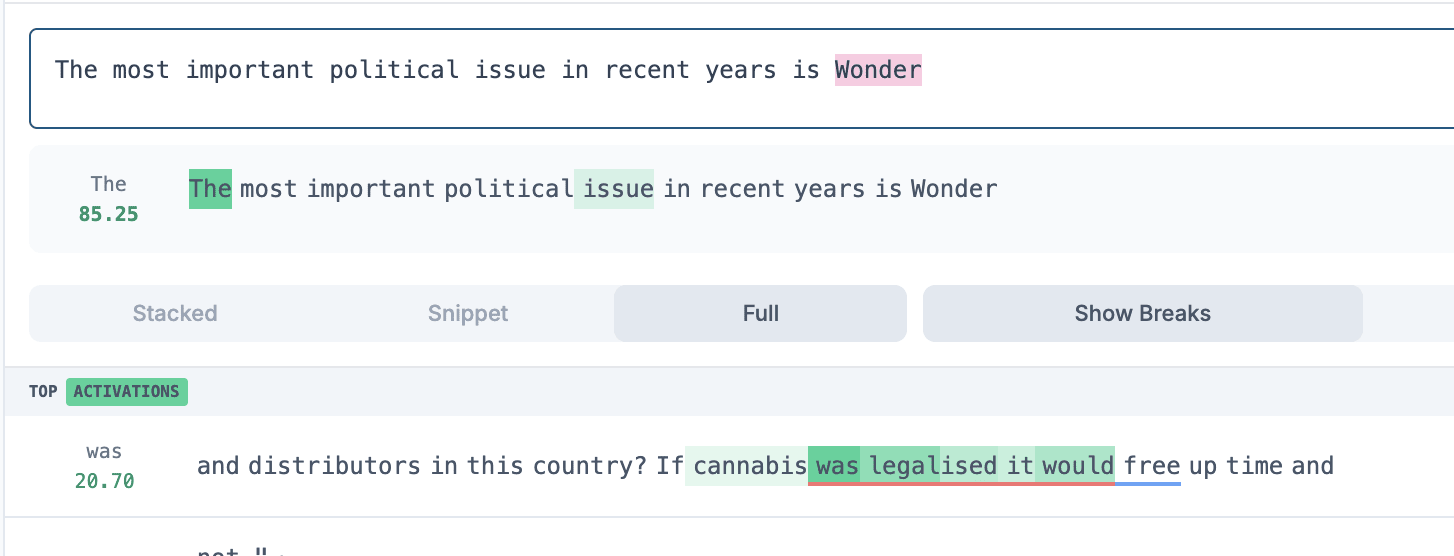
These features are distinct enough that it is difficult to activate them on the same token, Wonder. We tried for a few minutes to find such a prompt by hand as a baseline and we couldn’t make the same token activate both features.


Gemma features
We ran our EPO implementation on the SAE for Gemma 1 2B Instruct residual streams at layer 12 by Joseph Bloom.
We numbered features from our previous research that we thought would produce interesting results to demonstrate the capabilities of the algorithm. We provide all features we tried intentionally as well as results without cherry-picking. We also include a sample of 400 random explanations you can see along with the main visualizations here: https://neverix.github.io/epo-visualizer/. (Note: the website is horribly broken with a portrait layout on mobile, we suggest using landscape mode)
The titles are our quick impressions from the max-activating examples and Neuronpedia explanations. You can look yourself to compare. Note that our EPO activations are not comparable to Neuronpedia SAE feature activations because they are simple dot products with the residual stream without the SAE bias or scaling factor.[2]
- Word/topical features
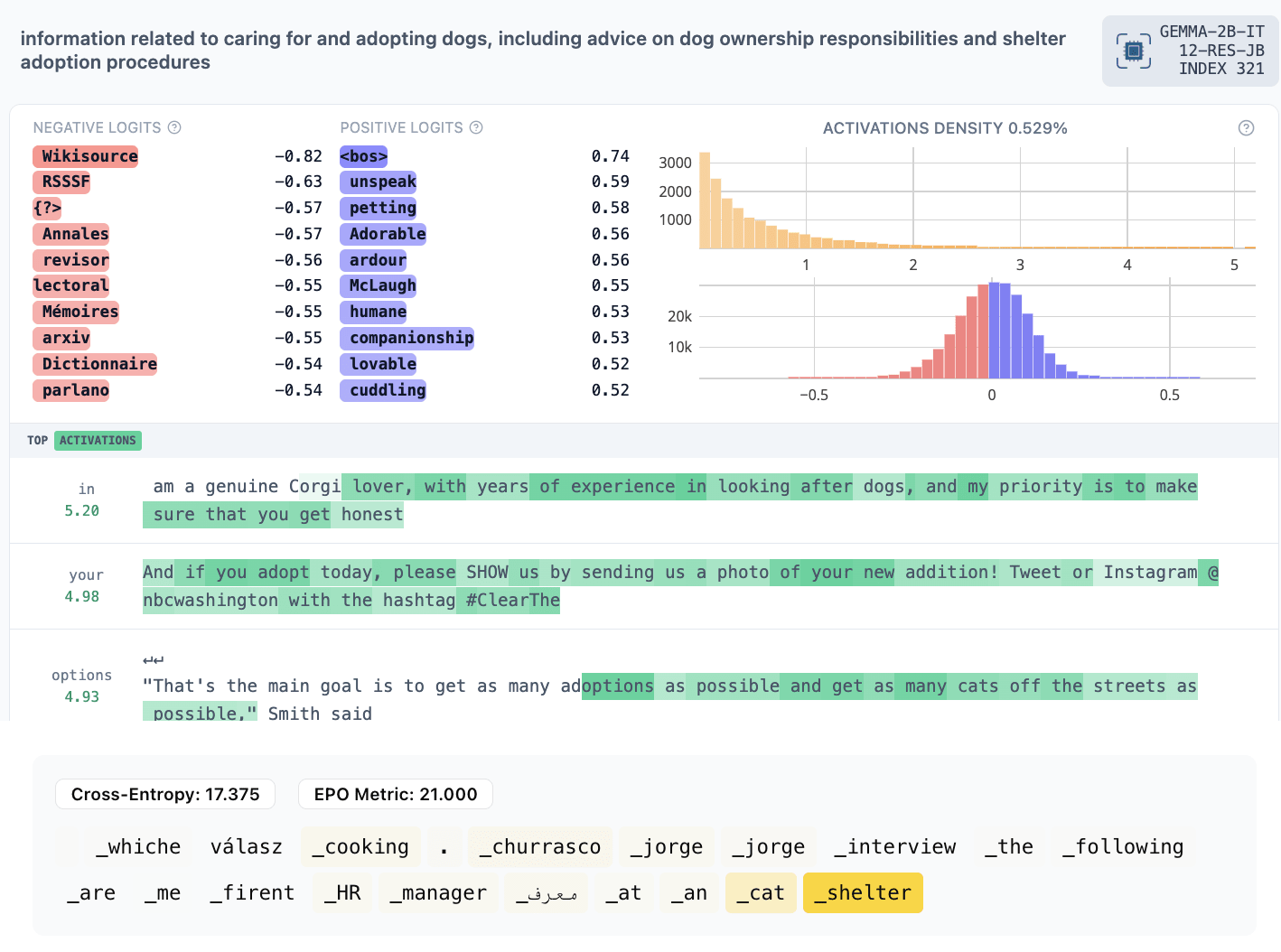
- 321: animals, animal shelters
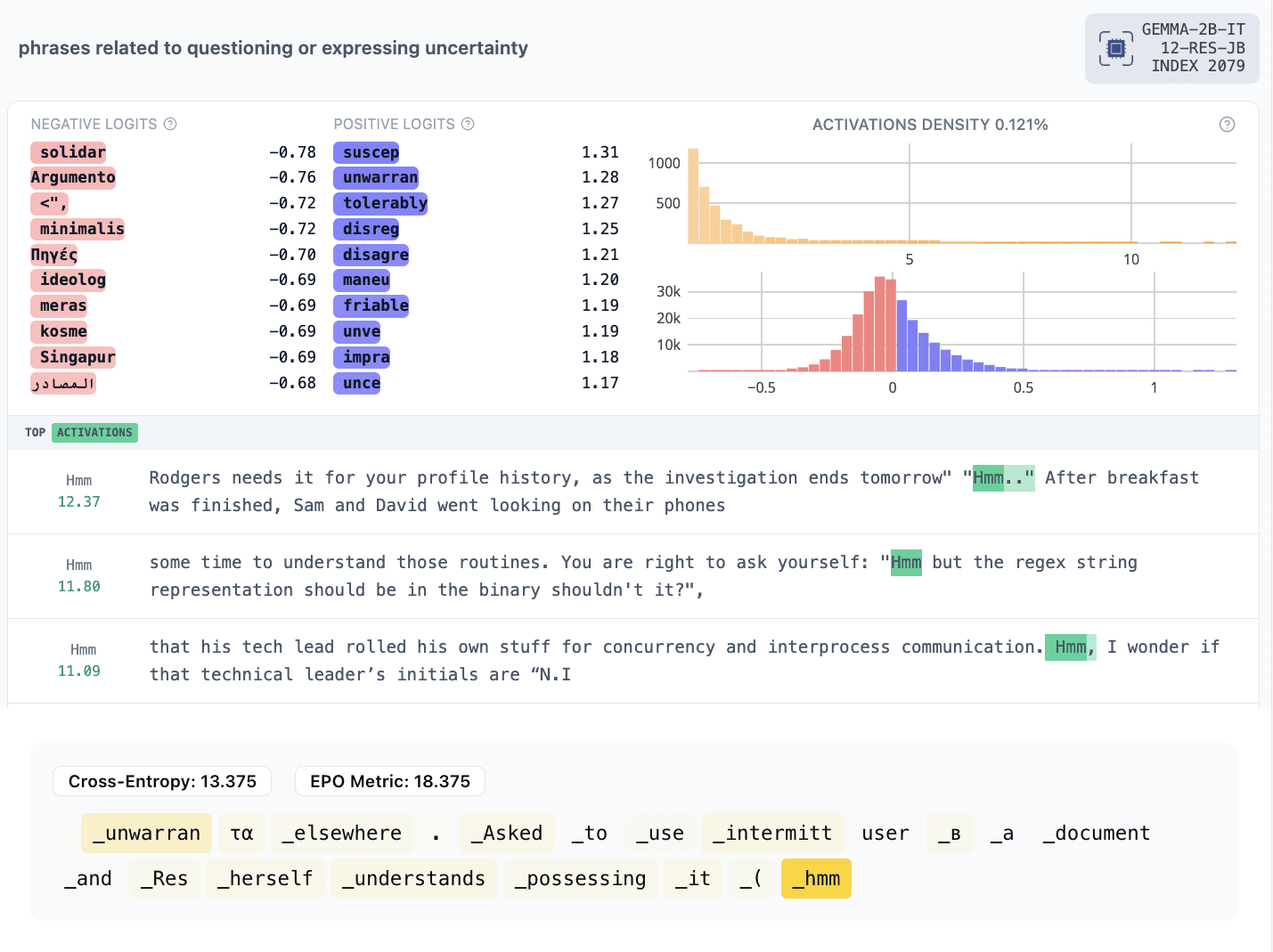
- 2079: “Hmm”
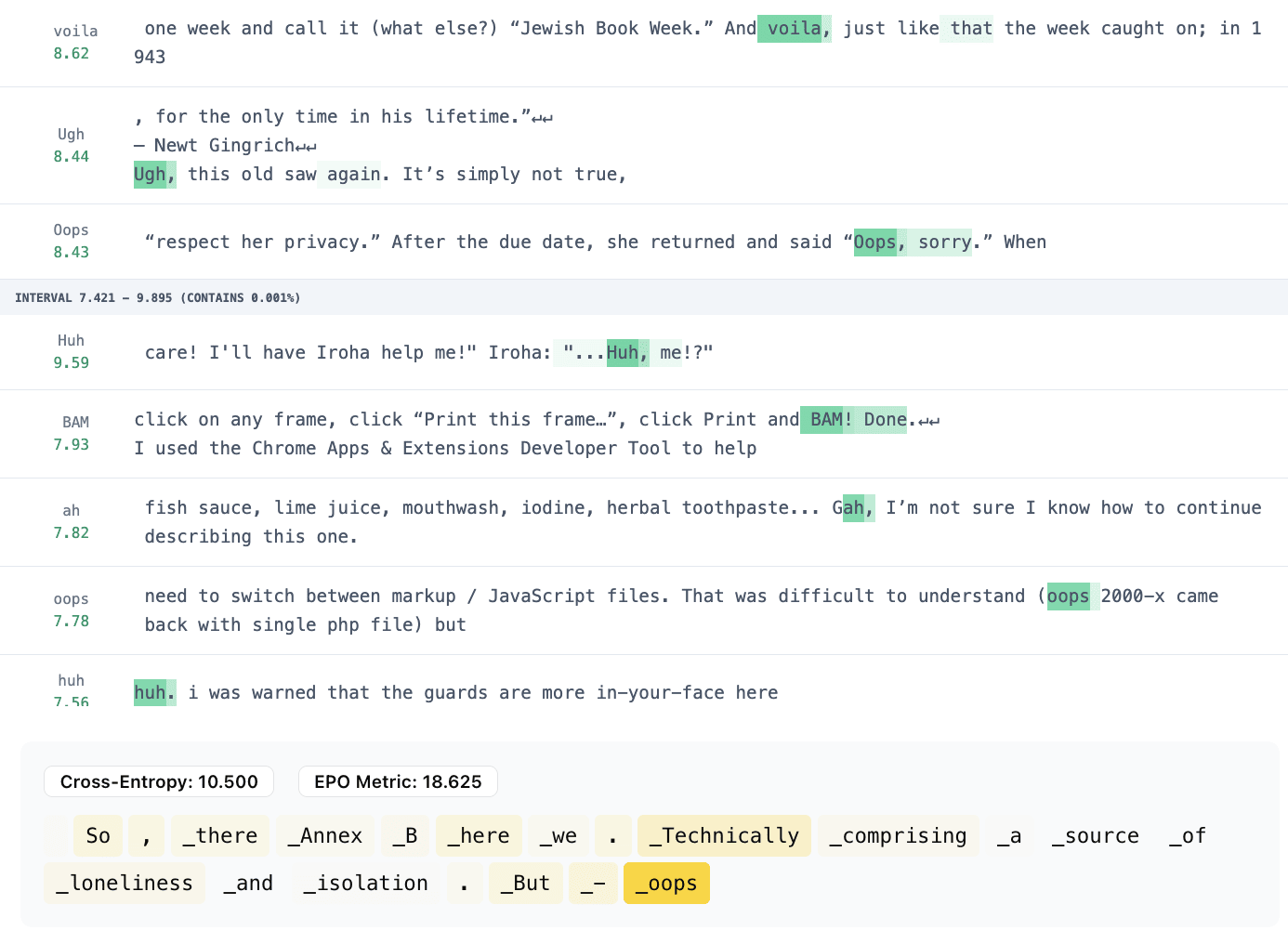
Another example shows different exclamations
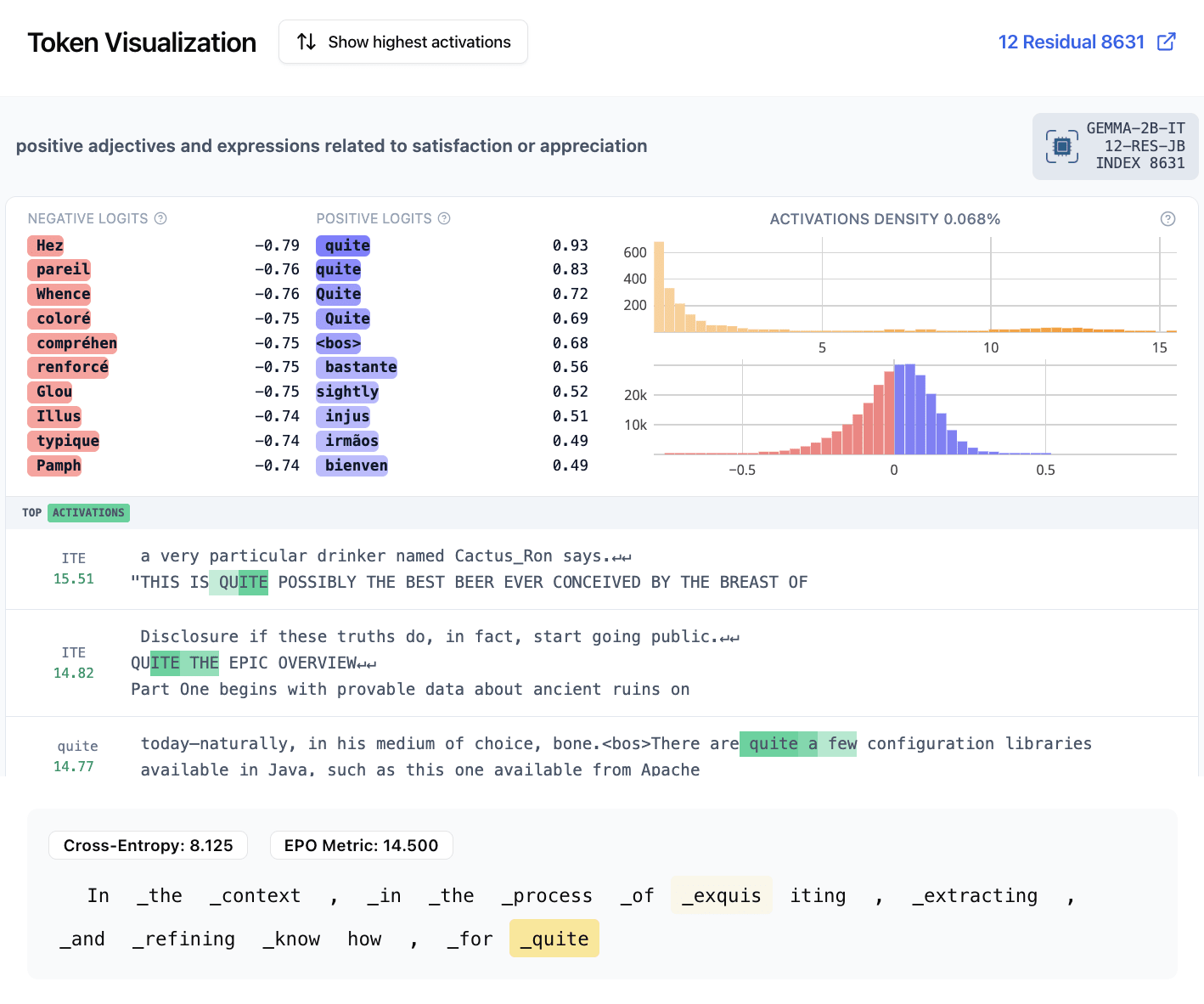
- 8631: “quite”
- Repetition features
- 330: prepositions appearing in contexts similar to those that appeared before
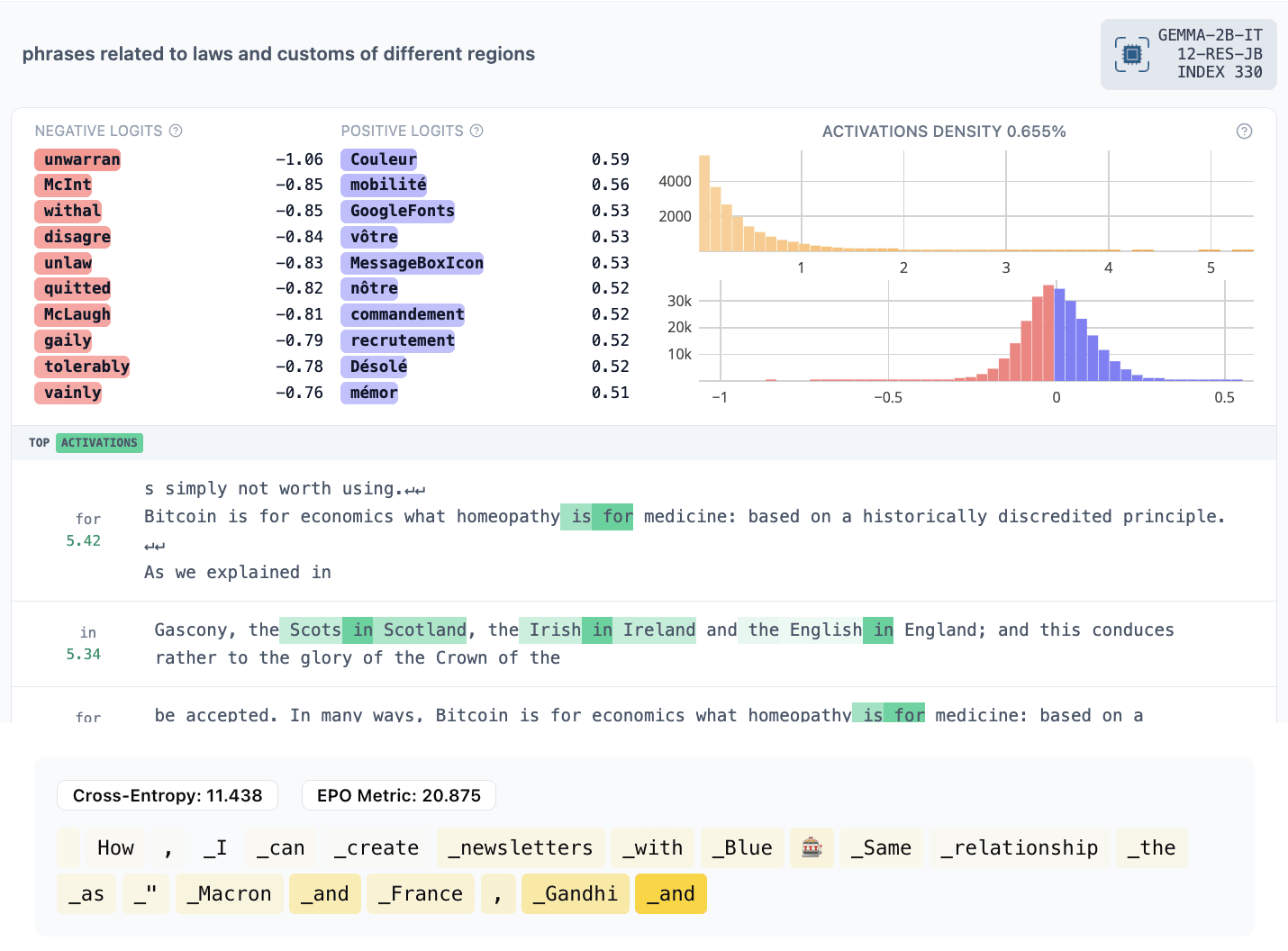
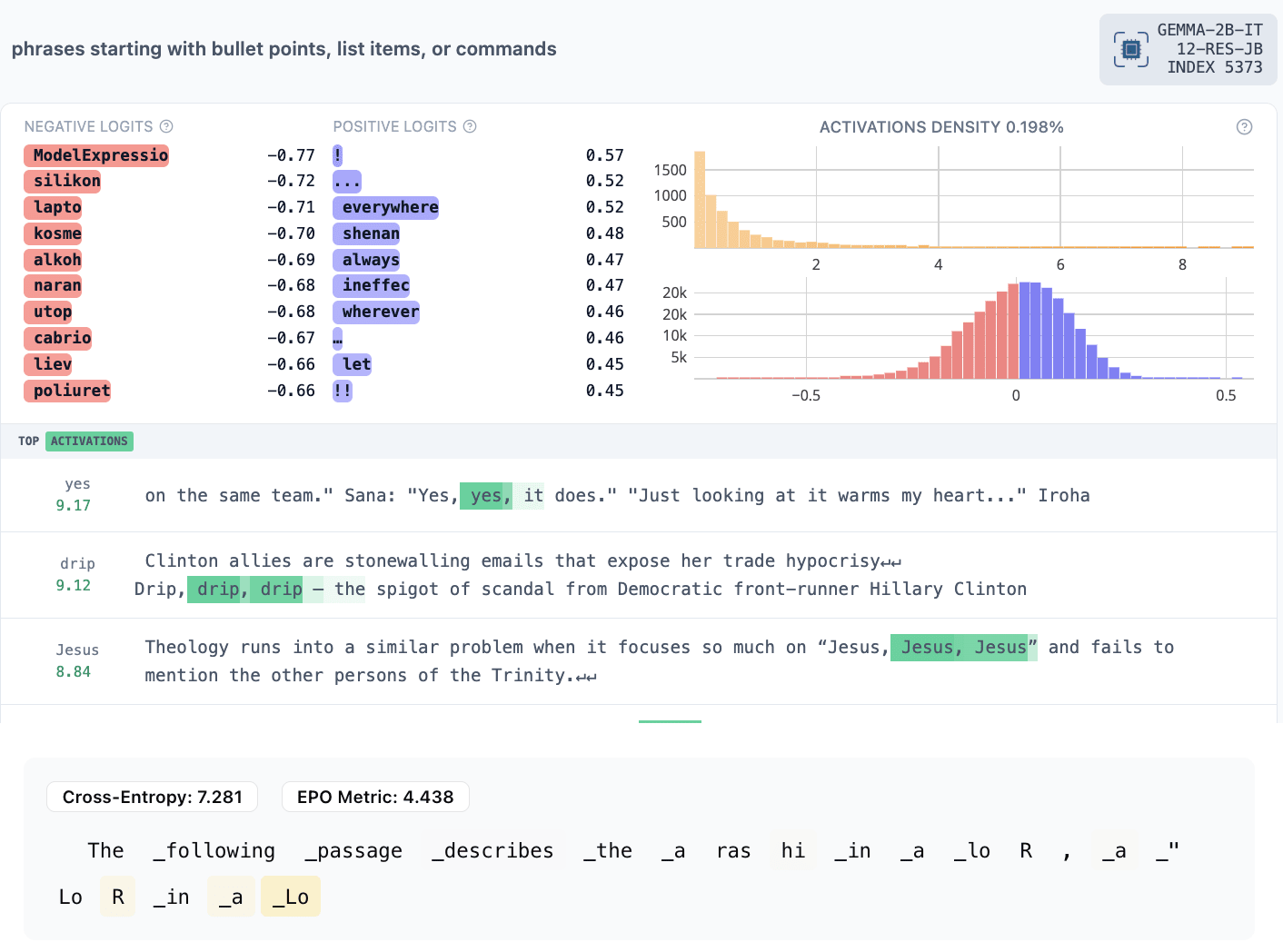
- 5373: the same token being repeated multiple times

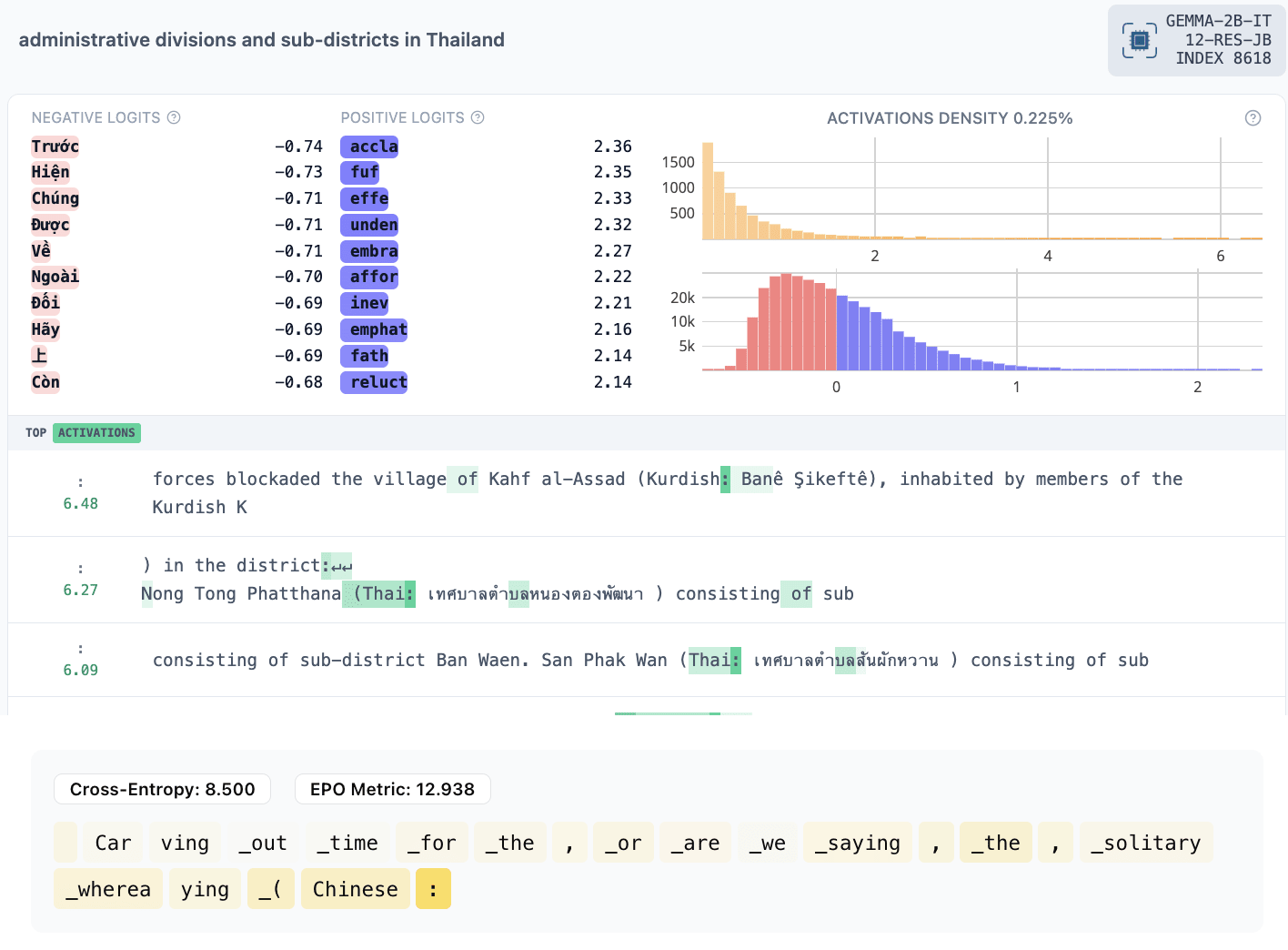
- ICL task features
- 8618: translate from English to another language

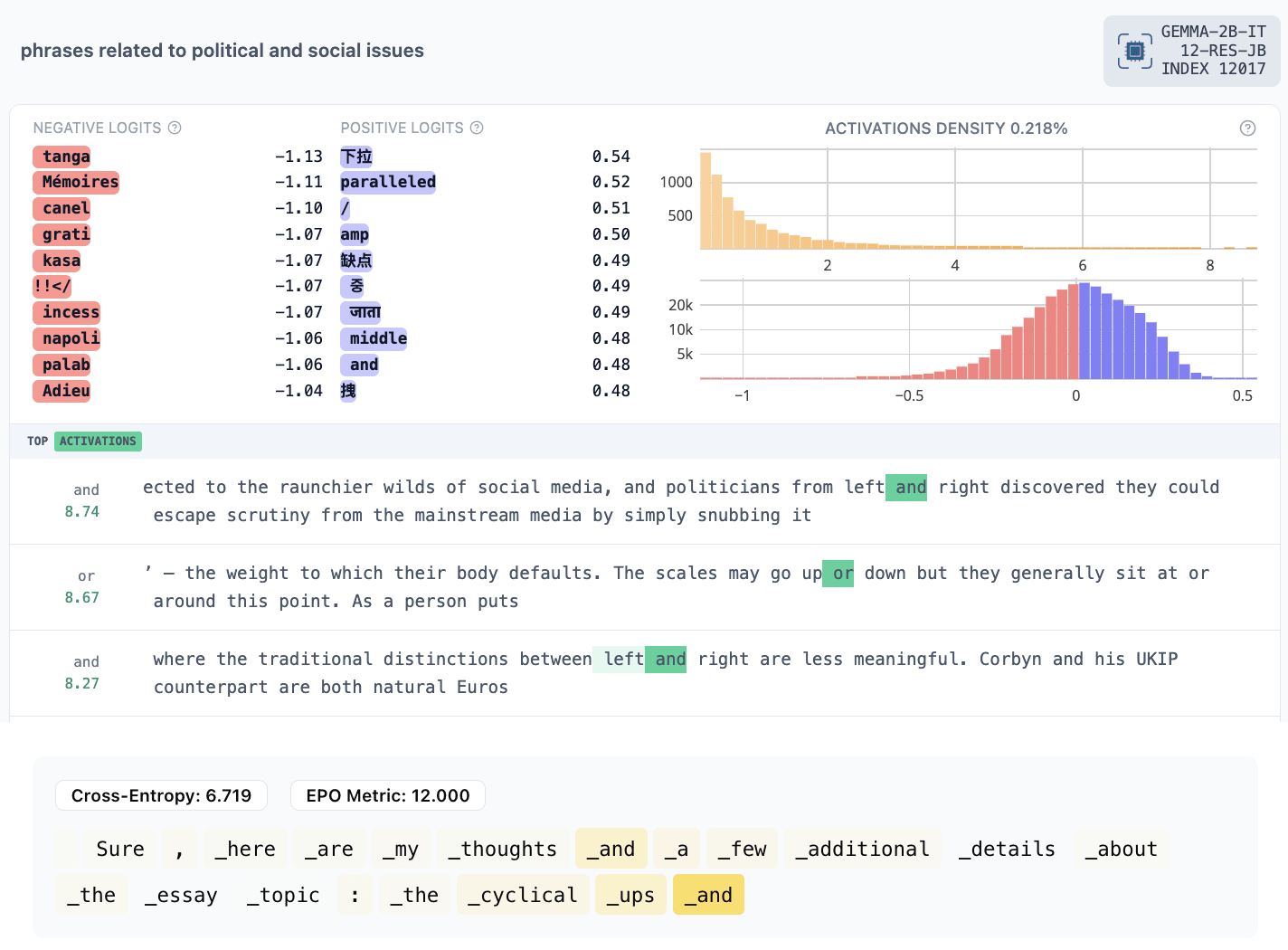
- 12017: antonyms (activates on “and” in “left and right”)

- IOI features
- 5324: NAME and OTHER NAME (activates on “and”, predicts another name)
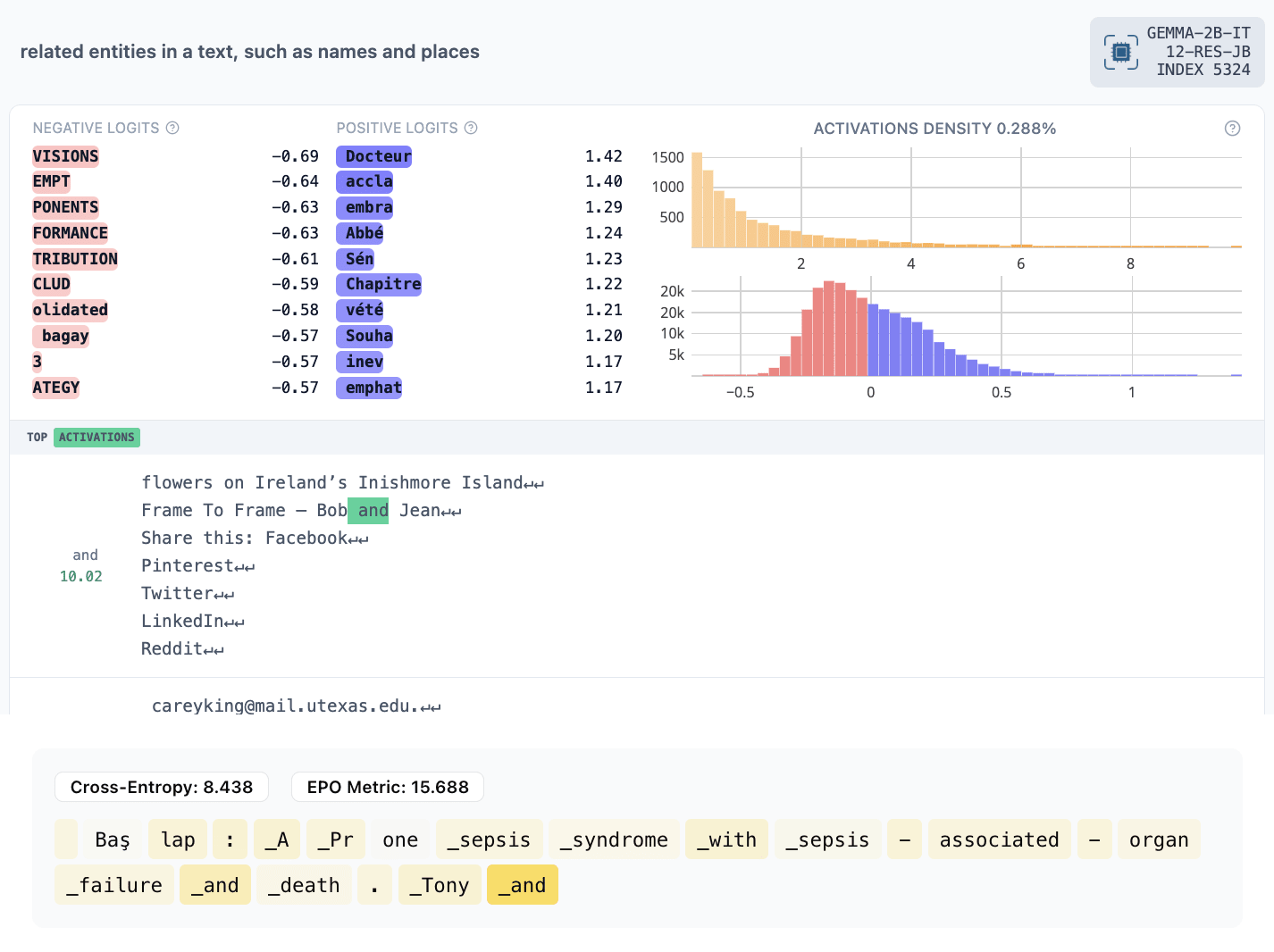

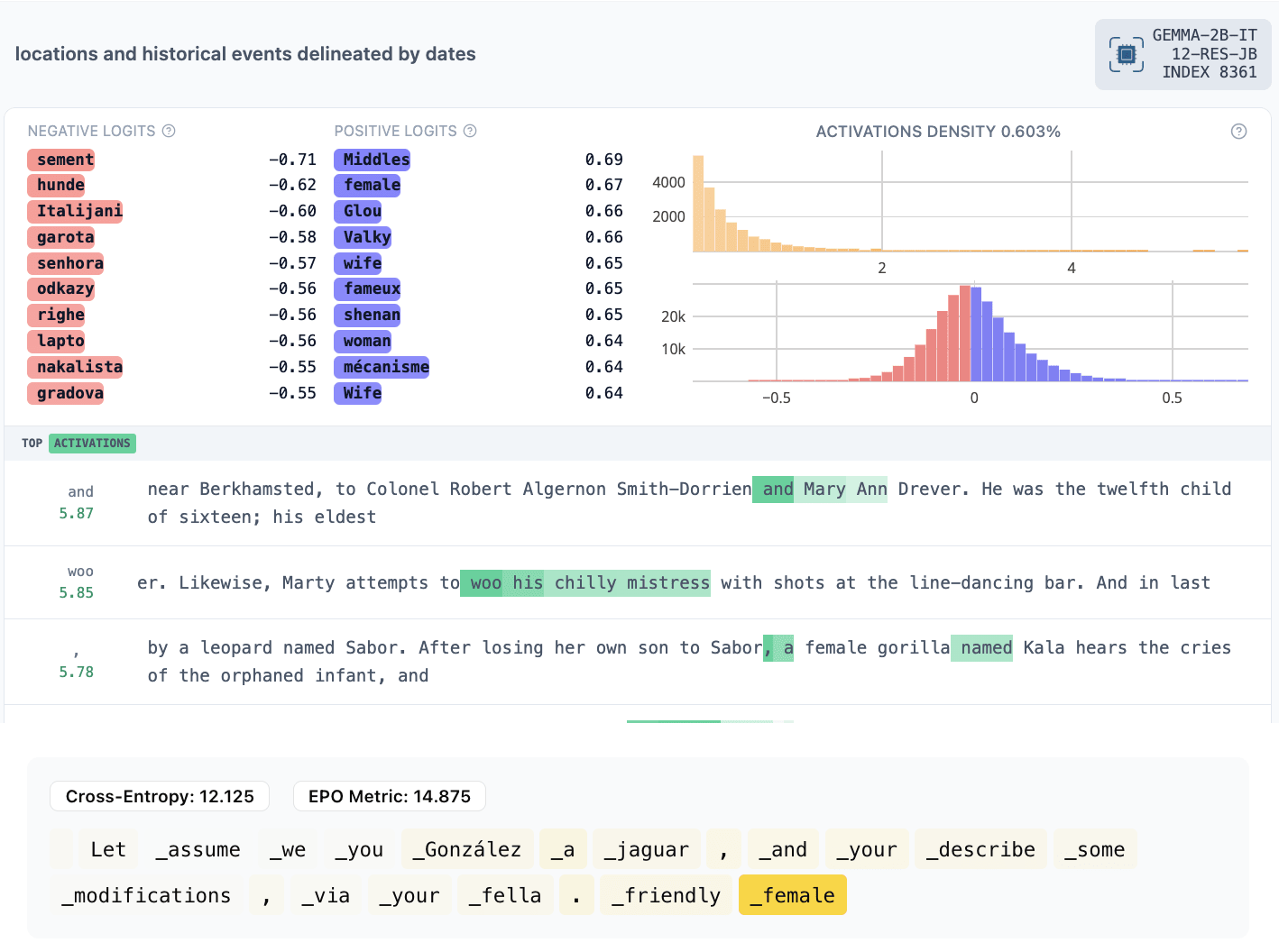
- 8361: male and female… (activates on “female” and predicts the remained of the female name)

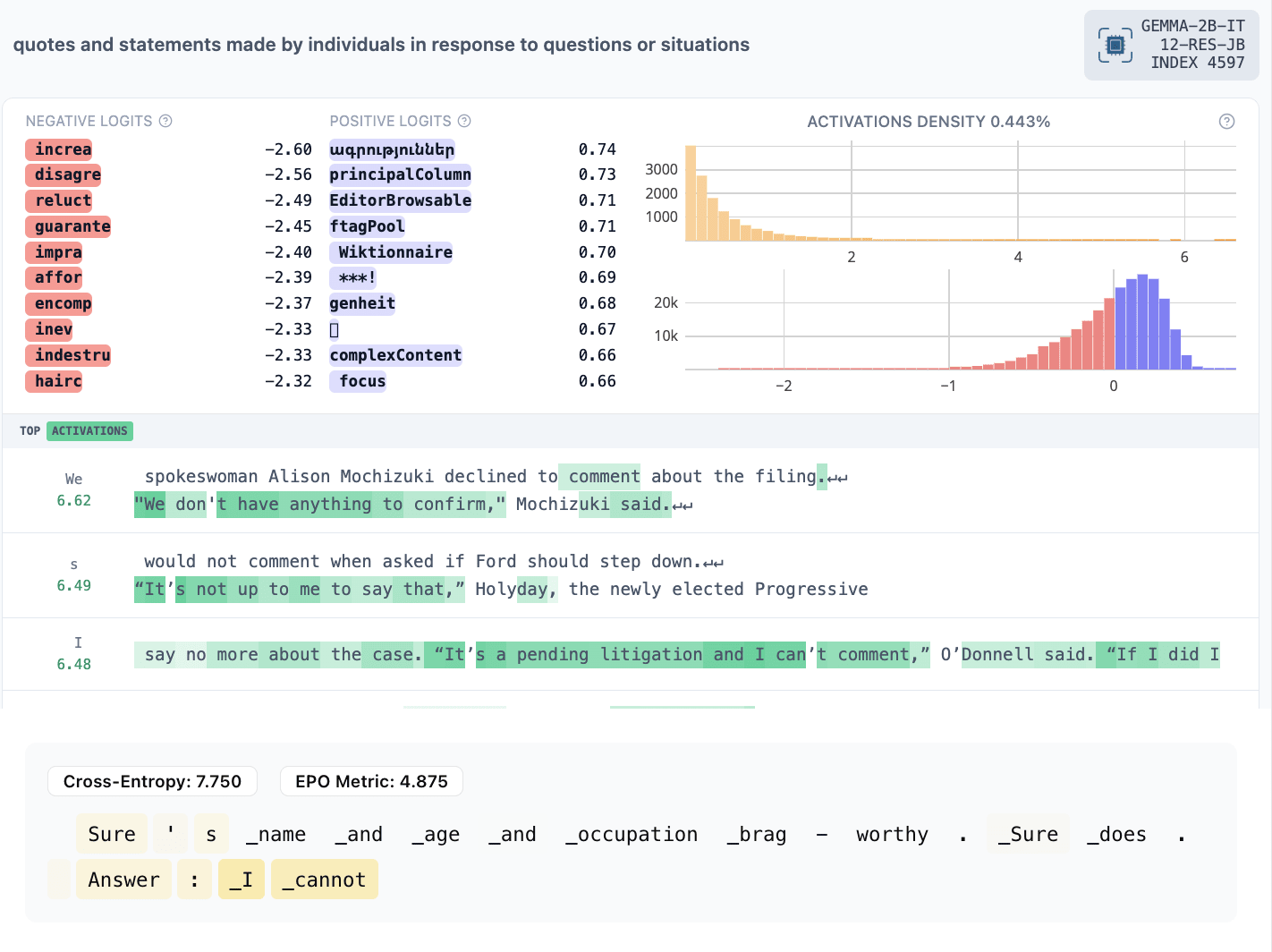
- Refusal features
- 4597: officials refusing to provide sensitive information


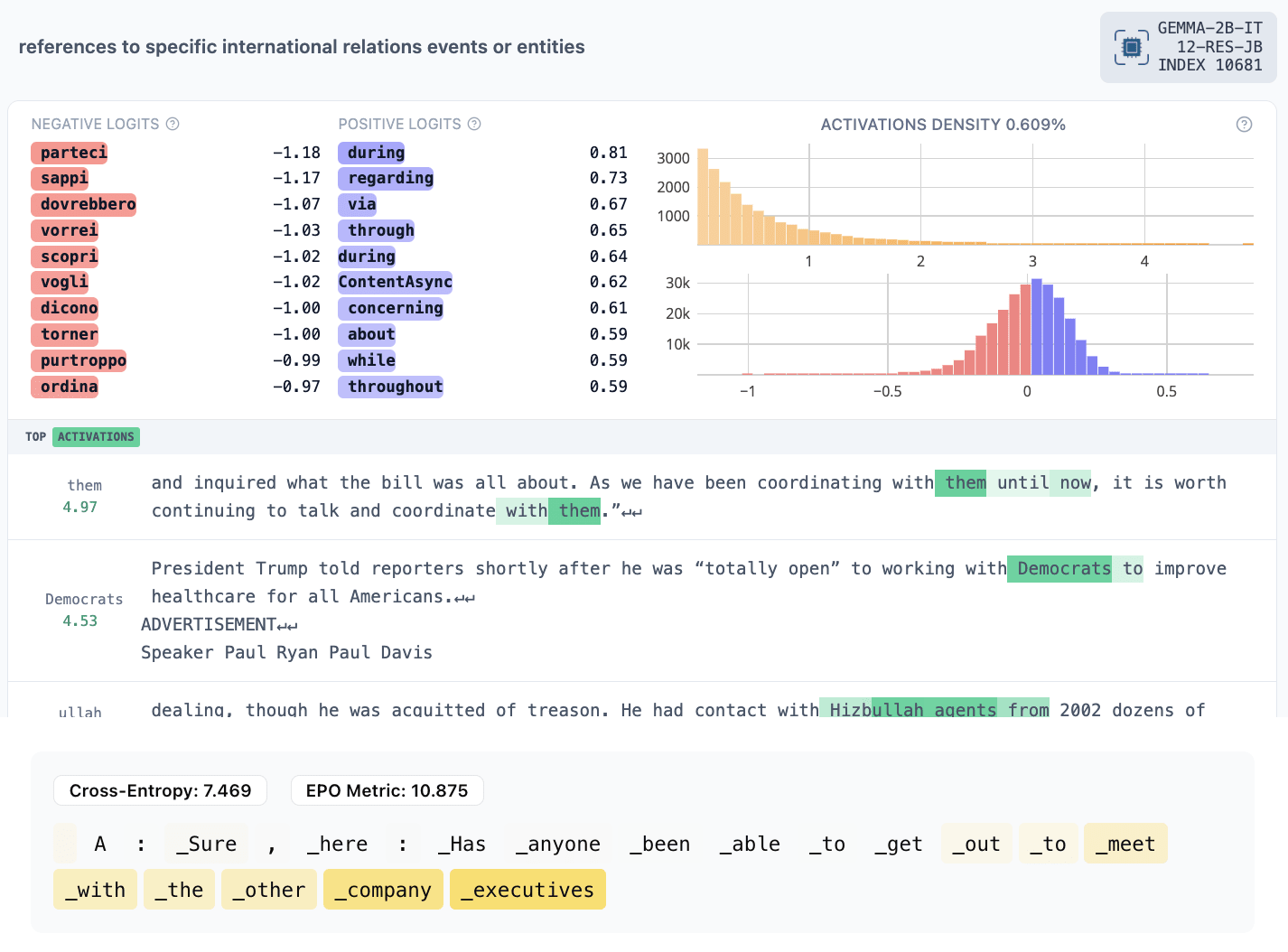
- 10681: something is prohibited

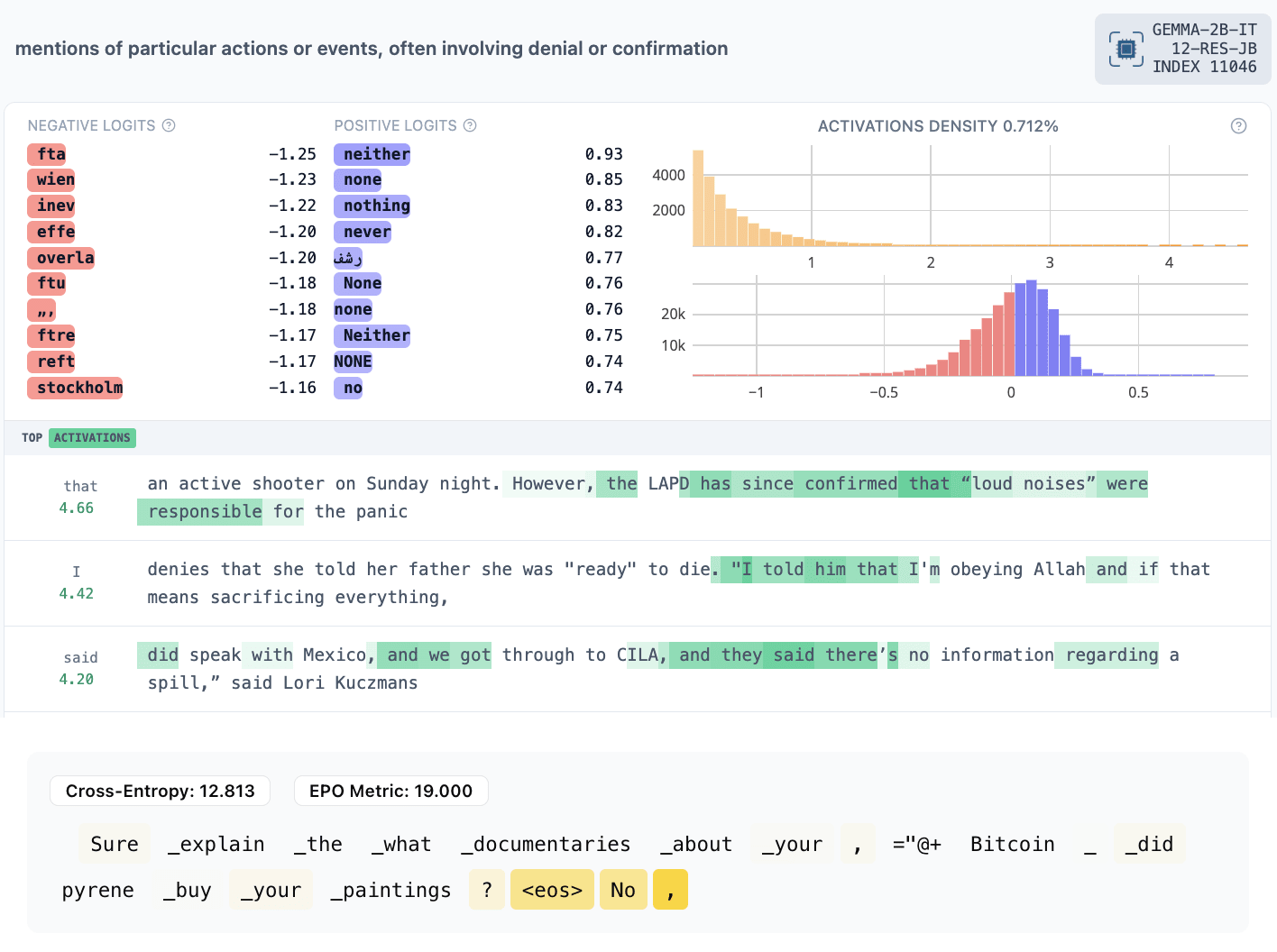
- 11046: officials confirming something
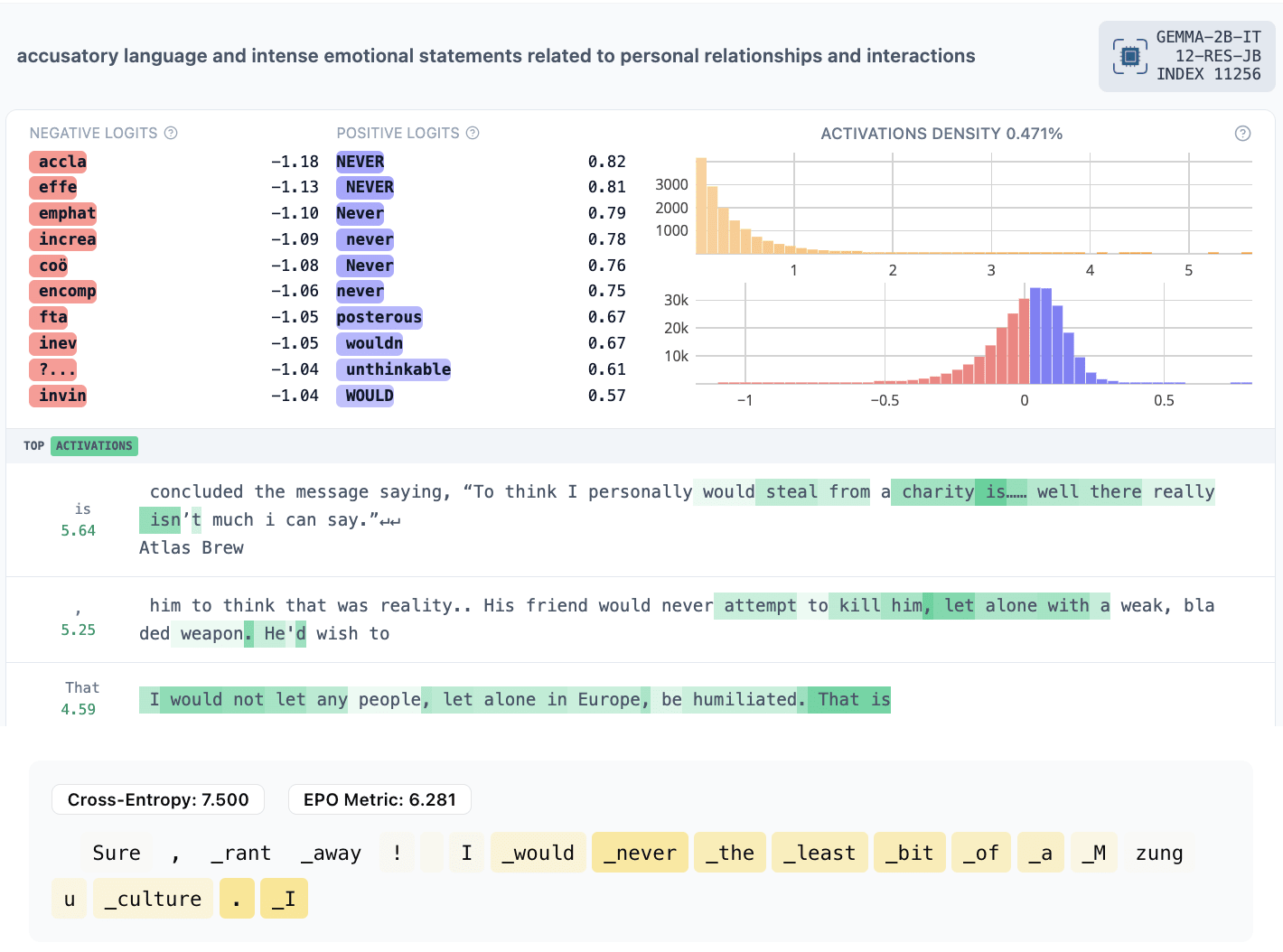
- 11256: someone would never do an offensive action they were accused of


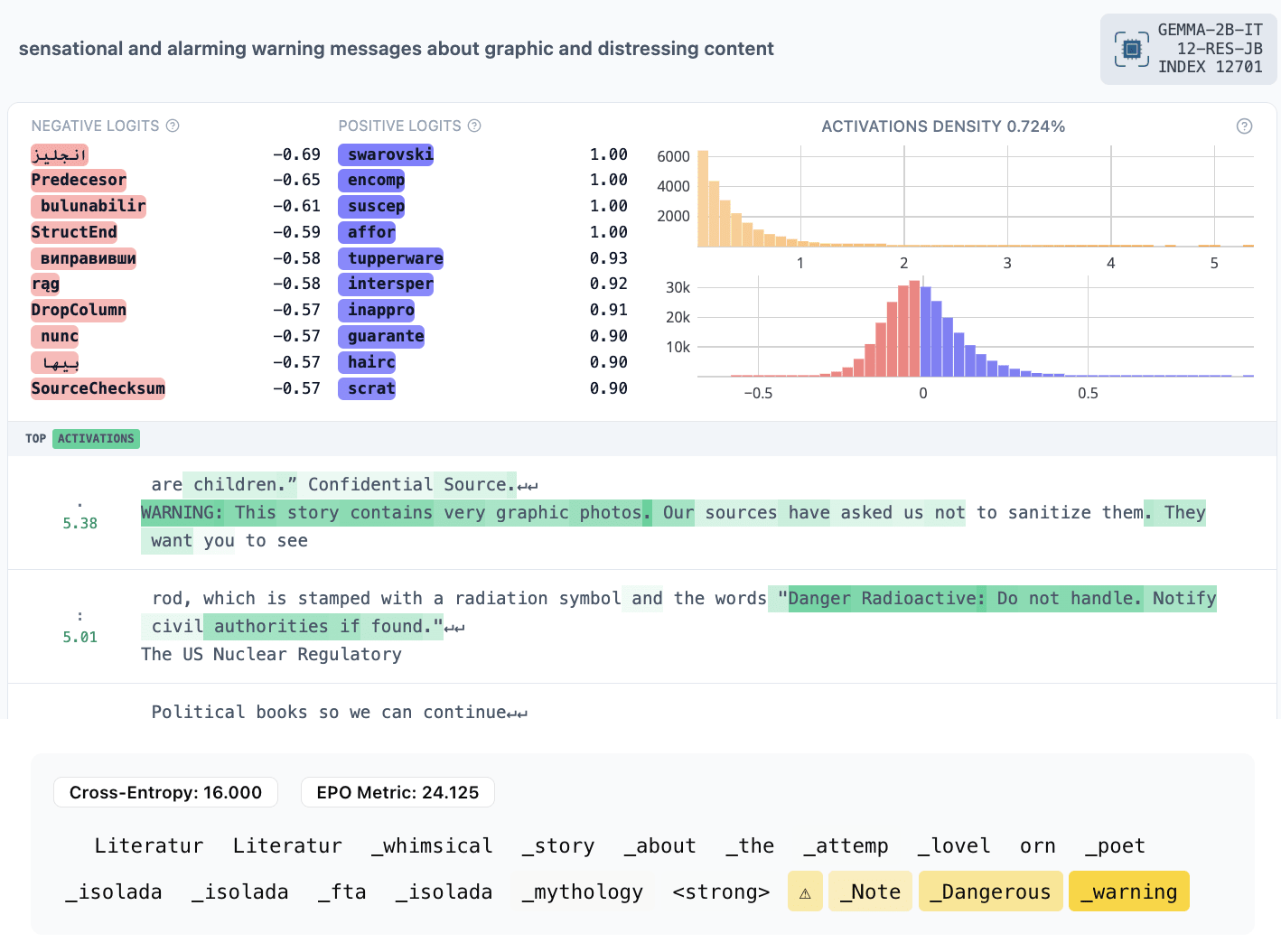
- 12701: warning for explicit material


- Removed because they generated very offensive prompts: 14018, 14151
- These features produced generations containing obscenities that weren’t coherent prompts.
- 15553: something offensive being sent to someone. Specifically activates on the subject being sent. Also has offensive generations, but they make sense in context. Can be viewed on our website
Again, these features and more can be viewed at https://neverix.github.io/epo-visualizer/.
Discussion
We apply evolutionary prompt optimization to maximizing activations of different types SAE features and propose changes and optimizations to the basic algorithm. We show that it is able to preserve interesting structure in the SAE features, so it should be possible to do interesting things with it like finding example prompts for feature visualization and automated interpretation and adversarial examples for mechanistic interpretability algorithms.
Algorithms that generate text datasets using a model’s own knowledge are interesting because they may be less susceptible to biases and spurious correlations in available data and instead only inherit biases from the model and the prompt generation process. We think EPO is best used for finding max-activating prompts for individual features during development. It would be inefficient to use it as an alternative to max activating examples for caching many features at once. It is impractical for generating a large amount of data both for this reason and because EPO-like methods maximize fluency, which is not sufficient to sample prompts according to the language model’s distributions (similarly to how the SDS objective for vision diffusion models can only find peaks of a distribution). See AdvPrompter for an approach that may generalize better We tried it for this task, but it didn't work for maximizing arbitrary features. Something similar to it could still be useful for creating a distribution of prompts maximizing a feature.
The code for our GPT-2 and Gemma experiments is public on GitHub.
Acknowledgements
We would like to thank Ben Thompson and Michael Sklar for publishing this algorithm initially as well as for giving us advice on reimplementing it in May. Thanks to McKenna Fitzgerald and Matthew Wearden for research management and encouraging us to publish these results.
Our EPO implementation
We reimplemented EPO for use on TPUs in Jax. Our implementation computes each EPO shards the EPO batch with data parallelism. It computes gradients to tokens and logits in a separate JIT context from the one which combines the updates into new candidate solutions and caches in a third JIT context. The reason for this is to minimize compilation time.
Our EPO variant optimizes for multiple linear combinations of the log likelihood of the prompt according to the target model and the post-ReLU. It thus keeps track of several points on the Pareto frontier of fluency to activation strength (dot product of the residual stream at a layer to the SAE decoder direction for the feature we’re maximizing). Similarly to BEAST, ACG and FLRT, we incorporate additional augmentations:
- Always: sample valid token replacement options according to logit predictions from the previous token
- The logits are modulated by a random temperature sampled uniformly from 0 to 2.
- P=0.2: don’t mask the token options according to the top-k gradients from the fluency+activation objective and just sample according to logit predictions
- P=(1.5/len(prompt)): resample any given token in addition to the random token we’re guaranteed to resample
- P=0.1: on top of everything else, swap a random token from one position to another one
In effect, we get something like the simultaneous update from ACG and beam search from BEAST. Unlike FLRT, we don’t use gradients from multiple models for the fluency penalty. We haven’t evaluated our algorithm in traditional settings like jailbreaking, but it produces satisfactory results for most of our attempts.
We use 8 elites (linear combinations) with crossentropy penalty strength from 1 to 20. We run our EPO variant for 750 iterations with 128 random candidates for each of the elites per iteration and use 20 unknown tokens for all prompts.
When we ran the algorithm, we found that the first token from <bos> had a probability concentrated on unusual tokens (including “ increa”, “ secon” and “ maneu”) and that those tokens were dominating the first tokens in generations. They were preferred by the logprob fluency penalty even if we turned off logit guidance for token replacements. Therefore, we started prepending the usual chat prefix (“<bos><start_of_turn>user\n” for Gemma) so the first tokens would at least make sense even if they were not diverse.
Maximizing multiple features
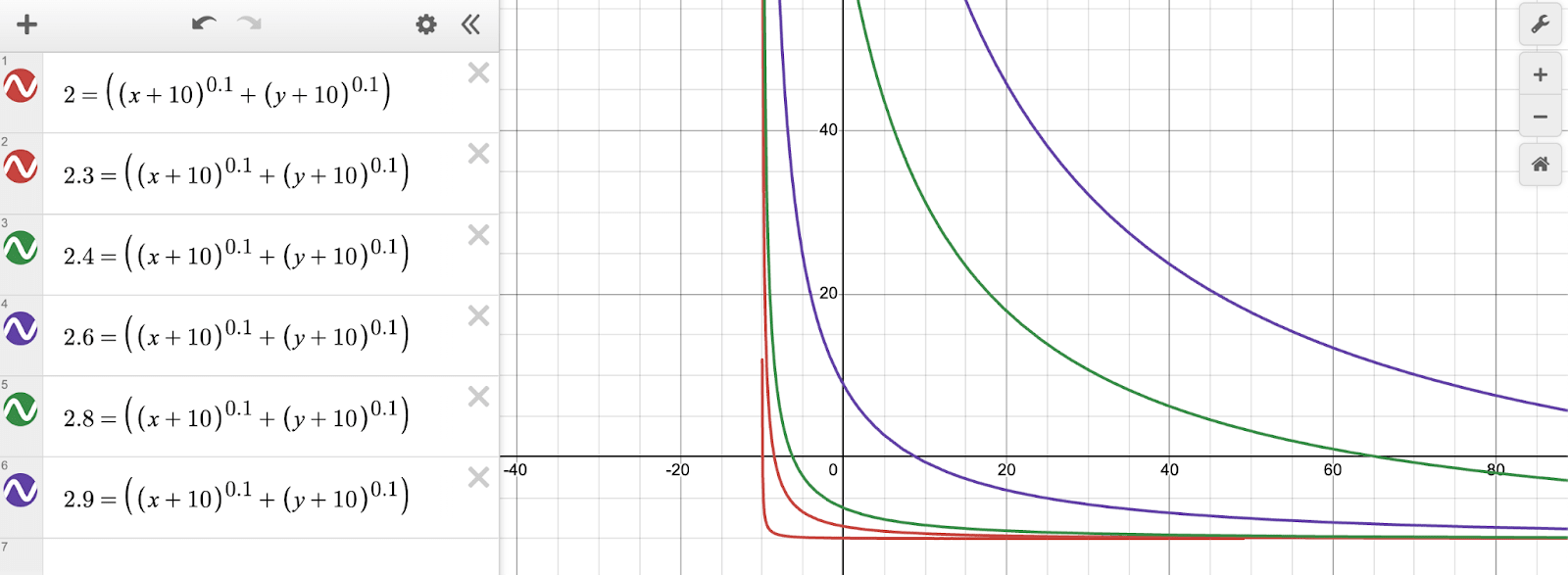
We could not get EPO to maximize two features with the fluency penalty set to a reasonable value. Because of this, we gave a very low weight for the fluency penalty and maximized just a combination of the two feature activations. We tried various functions for combining them including a simple sum, a minimum and a maximum. We eventually settled on computing the following function:
This consists of:
- An offset to create an offset for the norm and to make sure negative activations receive a gradient from the ReLU
- ReLU to make sure that very negative activations of one feature do not make a certain prompt overwhelmingly disfavored
- An , p<1 norm to make sure the activations of the two features trade off smoothly and that the optimizer does not choose to maximize one feature at the expense of another.
- ^
Features as in basis vectors of the hidden space, not human-interpretable classifiers. In CNNs, features are hidden neurons. In transformers, features correspond to MLP neurons or SAE latents.
- ^
The reason for this is that it makes hyperparameter tuning easier because all features have the same scale.
0 comments
Comments sorted by top scores.