Evidence against Learned Search in a Chess-Playing Neural Network
post by p.b. · 2024-09-13T11:59:55.634Z · LW · GW · 3 commentsContents
Introduction Analysis setup The Dataset Analysis results Accuracy by depth Winning probabilities by depth Winning probabilty distributions Winning probability by material balance Conclusion None 3 comments
Introduction
There is a new paper and lesswrong post [? · GW] about "learned look-ahead in a chess-playing neural network". This has long been a research interest [LW · GW] of mine for reasons that are well-stated in the paper:
Can neural networks learn to use algorithms such as look-ahead or search internally? Or are they better thought of as vast collections of simple heuristics or memorized data? Answering this question might help us anticipate neural networks’ future capabilities and give us a better understanding of how they work internally.
and further:
Since we know how to hand-design chess engines, we know what reasoning to look for in chess-playing networks. Compared to frontier language models, this makes chess a good compromise between realism and practicality for investigating whether networks learn reasoning algorithms or rely purely on heuristics.
So the question is whether Francois Chollet is correct with transformers doing "curve fitting" i.e. memorisation with little generalisation or whether they learn to "reason". "Reasoning" is a fuzzy word, but in chess you can at least look for what human players call "calculation", that is the ability to execute moves solely in your mind to observe and evaluate the resulting position.
To me this is a crux as to whether large language models will scale to human capabilities without further algorithmic breakthroughs.
The paper's authors, which include Erik Jenner and Stuart Russell, conclude that the policy network of Leela Chess Zero (a top engine and open source replication of AlphaZero) does learn look-ahead.
Using interpretability techniques they "find that Leela internally represents future optimal moves and that these representations are crucial for its final output in certain board states."
While the term "look-ahead" is fuzzy, the paper clearly intends to show that the Leela network implements an "algorithm" and a form of "reasoning".
My interpretation of the presented evidence is different, as discussed in the comments of the original lesswrong post [LW(p) · GW(p)]. I argue that all the evidence is completely consistent with Leela having learned to recognise multi-move patterns. Multi-move patterns are just complicated patterns that take into account that certain pieces will have to be able to move to certain squares in future moves for the pattern to hold.
The crucial different to having learned an algorithm:
An algorithm can take different inputs and do its thing. That allows generalisation to unseen or at least unusual inputs. This means that less data is necessary for learning because the generalisation power is much higher.
Learning multi-move patterns on the other hand requires much more data because the network needs to see many versions of the pattern until it knows all specific details that have to hold.
Analysis setup
Unfortunately it is quite difficult to distinguish between these two cases. As I argued:
Certain information is necessary to make the correct prediction in certain kinds of positions. The fact that the network generally makes the correct prediction in these types of positions already tells you that this information must be processed and made available by the network. The difference between lookahead and multi-move pattern recognition is not whether this information is there but how it got there.
However, I propose an experiment, that makes it clear that there is a difference.
Imagine you train the model to predict whether a position leads to a forced checkmate and also the best move to make. You pick one tactical motive and erase it from the checkmate prediction part of the training set, but not the move prediction part.
Now the model still knows which the right moves are to make i.e. it would play the checkmate variation in a game. But would it still be able to predict the checkmate?
If it relies on pattern recognition it wouldn't - it has never seen this pattern be connected to mate-in-x. But if it relies on lookahead, where it leverages the ability to predict the correct moves and then assesses the final position then it would still be able to predict the mate.
At the time I thought this is just a thought experiment to get my point across. But after looking at the code that was used for the analysis in the paper, I realised that something quite similar could be done with the Leela network.
The Leela network is not just a policy network, but also a value network. Similar to AlphaGo and Co it computes not just a ranking of moves but also an evaluation of the position in the form of win, draw, loss probabilities.
This allows us to analyse whether the Leela network "sees" the correct outcome when it predicts the correct move. If it picks the correct first move of a mating combination because it has seen the mate, then it should also predict the mate and therefore a high winning probability. If it guesses the first move based on pattern recognition it might be oblivious to the mate and predict only a moderate or even low probability of winning.
The Dataset
To conduct this analysis I scrape 193704 chess problems from the website of the German Chess Composition Association "Schwalbe". These are well-suited for this test because chess compositions are somewhat out of distribution for a chess-playing network, so a lack of generalisation should be more noticeable. They are usually designed to require "reasoning" and to be hard to guess.
However the dataset requires extensive filtering to remove "fairy chess" with made-up rules and checking the solution using stockfish, leaving 54424 validated puzzles with normal rules. All of them are white to move and win, often with a mate in n moves.
One further complication is that a mate-in-n puzzle often features an overwhelming advantage for white and the difficulty lies in finding the fastest win, something Leela was not trained to do. So I filter the puzzles down to 1895 puzzles that have just one winning move. 1274 of those are mate-in-n with n<10.
Analysis results
The Leela network is pretty amazing. If we accept a correctly predicted first move as "solution", it solves a bit more than 50% of the puzzles. In the following we try to dig into whether this is due to amazing "intuition", i.e. pattern recognition based guesses or due to a look-ahead-algorithm.
Accuracy by depth
Humans solve these puzzles by reasoning and calculation. They think ahead until they find the mate. As a consequence mating puzzles get harder as the mating combination gets deeper. This is of course also true for search-based engines. Mate-in-2 is almost always solvable for me, because it is close to being brute-forceable. Mate-in-3 is already often much harder. Longer mates can become arbitrarily hard, though of course there are many factors that make puzzles easy or hard and depth is just one of them.
If Leela's abilities were substantially founded on the ability to look ahead and find the mate, we would expect a similar pattern: Deeper mates would be harder to solve than shallower mates.
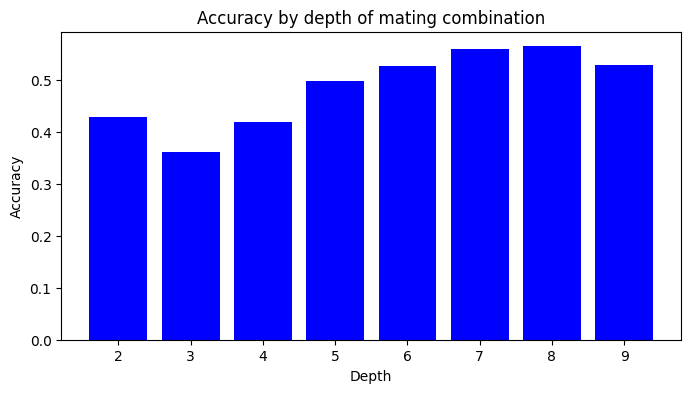
This is not what we find. Overall the deeper mates are more often solved by the Leela network. This makes sense from a pattern recognition based move prediction perspective, because shorter mates probably have more surprising initial moves - the composer doesn't have as many moves later to cram in aesthetic value.
Winning probabilities by depth
Similarly humans tend to get less confident in their solution the more moves these entail. Obviously even if the line is completely forced, a mate-in-8 gives twice as many opportunities to overlook something as a mate-in-4. Additionally, the farther the imagined board state is from the actual position the more likely it is that mental errors creep in like taken or moved pieces reappearing on their original square.
Again, this is not what we find for the Leela network. For the solved mates the predicted winning probability hovers around 40% independent of the depth of the mate.
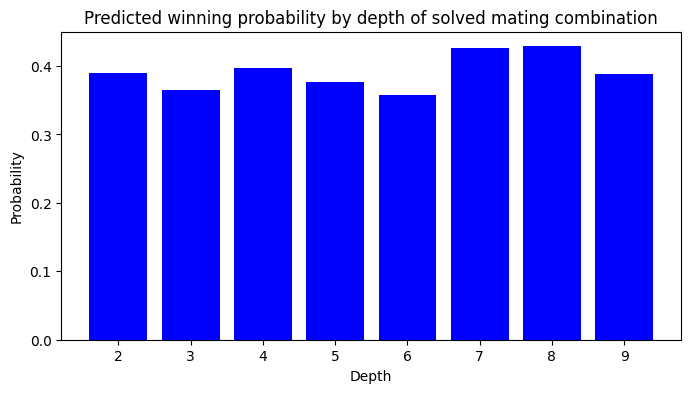
For unsolved mates (remember, these are filtered to have only one winning move, which in this case Leela missed) the probability hovers around 30%.
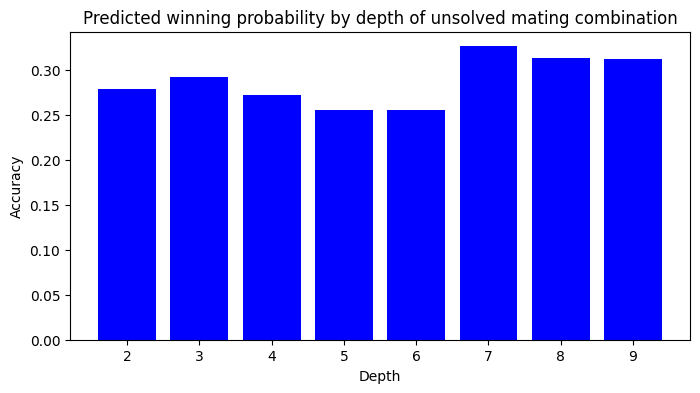
This is consistent with Leela assessing a kind of dynamic potential by recognising many tactical motives that might be strung together for an advantageous tactical strike without actually determining this winning combination.
Winning probabilty distributions
Overall the winning probabilities show no Aha!-effect, where the network becomes significantly more confident in its winning prospects when it sees that a move is winning. This would certainly be the case for a human or a search-based engine. The Leela-network does not show a big difference between the winning probability distributions of solved vs unsolved puzzles.
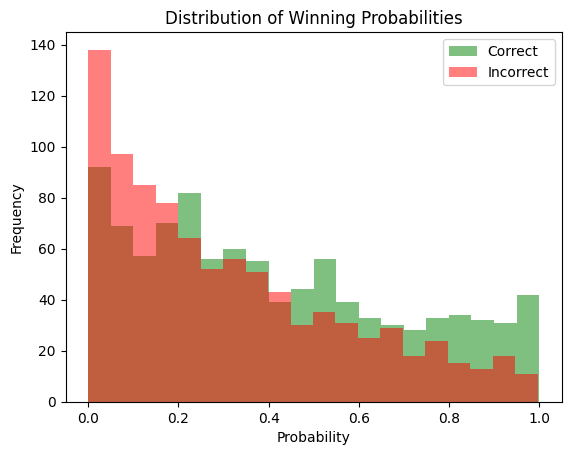
Winning probability by material balance
The observed difference between these probability distributions might also be due to differences between the solved and unsolved puzzles and are unlikely to be caused by "finding" the solution.
This becomes clearer if we look at one superficial but powerful predictor of game outcomes: Material balance. In most positions the player with more material has the better prospects and humans would also assess the material balance first when encountering a new position.
However, one of the strengths of calculating ahead lies in the ability to ignore or transcend the material balance when concrete lines show a way to a favourable outcome. A human or search-based engine might initially think that black is far ahead only to flip to "white is winning" when finding a mating combination.
Here is the average winning probability by material balance (in pawn units) for correctly solved puzzles with just one winning solution.
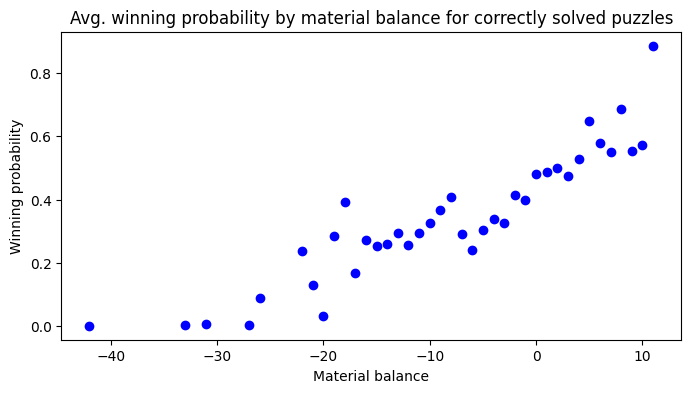
Despite the fact that all these puzzles are winning for white and the solution has been predicted by Leela the average winning probability drops to zero when the material balance becomes too unfavourable.
Conclusion
Does this analysis show without a doubt that the Leela network does not do some kind of general search or look-ahead during its forward pass?
No, unfortunately my results are also consistent with Leela implementing a mixture of pattern recognition and a look-ahead algorithm, with pattern recognition doing most of the heavy lifting and the general look-ahead just occasionally also contributing to solving a puzzle (these are not easy after all).
A clear proof of absence of system 2 thinking would require control over the training data for different training runs or significantly more powerful interpretability methods.
But I think it can be ruled out that a substantial part of Leela network's prowess in solving chess puzzles or predicting game outcome is due to deliberate calculation.
There are more analyses that could be done, however, I don't have the time. So far the analysis results have not shifted my priors much.
However, the transfer of these results to LLMs is not clear-cut because LLMs are not similarly limited to a single forward pass in their problem solving.
3 comments
Comments sorted by top scores.
comment by Erik Jenner (ejenner) · 2024-09-13T16:47:47.055Z · LW(p) · GW(p)
Thanks for running these experiments! My guess is that these puzzles are hard enough that Leela doesn't really "know what's going on" in many of them and gets the first move right in significant part by "luck" (i.e., the first move is heuristically natural and can be found without (even heuristically) knowing why it's actually good). I think your results are mainly reflections of that, rather than Leela generally not having sensibly correlated move and value estimates (but I'm confused about what a case would be where we'd actually make different predictions about this correlation).
In our dataset, we tried to avoid cases like that by discarding puzzles where even a much weaker network ("LD2") got the first move right, so that Leela getting the first move right was actually evidence it had noticed the non-obvious tactic.
Some predictions based on that:
- Running our experiments on your dataset would result in smaller effect sizes than in our paper (in my view, that would be because Leela isn't relying on look-ahead in your puzzles but is in ours but there could be other explanations)
- LD2 would assign non-trivial probability to the correct first move in your dataset (for context, LD2 is pretty weak, and we're only using puzzles where it puts <5% probability on the correct move; this leaves us with a lot of sacrifices and other cases where the first move is non-obvious)
- Leela is much less confident on your dataset than on our puzzles (this is a cheap prediction because we specifically filtered our dataset to have Leela assign >50% probability to the correct move)
- Leela gets some subsequent moves wrong a decent fraction of the time even in cases where it gets the first move right. Less confidently, there might not be much correlation between getting the first move right and getting later moves right, but I'd need to think about that part more.
You might agree with all of these predictions, they aren't meant to be super strong. If you do, then I'm not sure which predictions we actually disagree about---maybe there's a way to make a dataset where we expect different amounts of correlation between policy and value output but I'd need to think about that.
But I think it can be ruled out that a substantial part of Leela network's prowess in solving chess puzzles or predicting game outcome is due to deliberate calculation.
FWIW, I think it's quite plausible that only a small part of Leela's strength is due to look-ahead, we're only testing on a pretty narrow distribution of puzzles after all. (Though similarly, I disagree somewhat with "ruling out" given that you also just look at pretty specific puzzles (which I think might just be too hard to be a good example of Leela's strength)).
ETA: If you can share your dataset, I'd be happy to test the predictions above if we disagree about any of them, also happy to make them more concrete if it seems like we might disagree. Though again, I'm not claiming you should disagree with any of them just based on what you've said so far.
Replies from: p.b.↑ comment by p.b. · 2024-09-16T10:16:44.362Z · LW(p) · GW(p)
I actually originally thought about filtering with a weaker model, but that would run into the argument: "So you adversarially filtered the puzzles for those transformers are bad at and now you've shown that bigger transformers are also bad at them."
I think we don't disagree too much, because you are too damn careful ... ;-)
You only talk about "look-ahead" and you see this as on a spectrum from algo to pattern recognition.
I intentionally talked about "search" because it implies more deliberate "going through possible outcomes". I mostly argue about the things that are implied by mentioning "reasoning", "system 2", "algorithm".
I think if there is a spectrum from pattern recognition to search algorithm there must be a turning point somewhere: Pattern recognition means storing more and more knowledge to get better. A search algo means that you don't need that much knowledge. So at some point of the training where the NN is pushed along this spectrum much of this stored knowledge should start to be pared away and generalised into an algorithm. This happens for toy tasks during grokking. I think it doesn't happen in Leela.
I do have an additional dataset with puzzles extracted from Lichess games. Maybe I'll get around to running the analysis on that dataset as well.
I thought about an additional experiment one could run: Finetuning on tasks like help mates. If there is a learned algo that looks ahead, this should work much better than if the work is done by a ton of pattern recognition which is useless for the new task. Of course the result of such an experiment would probably be difficult to interpret.
Replies from: ejenner↑ comment by Erik Jenner (ejenner) · 2024-09-16T16:53:43.545Z · LW(p) · GW(p)
Yeah, I feel like we do still disagree about some conceptual points but they seem less crisp than I initially thought and I don't know experiments we'd clearly make different predictions for. (I expect you could finetune Leela for help mates faster than training a model from scratch, but I expect most of this would be driven by things closer to pattern recognition than search.)
I think if there is a spectrum from pattern recognition to search algorithm there must be a turning point somewhere: Pattern recognition means storing more and more knowledge to get better. A search algo means that you don't need that much knowledge. So at some point of the training where the NN is pushed along this spectrum much of this stored knowledge should start to be pared away and generalised into an algorithm. This happens for toy tasks during grokking. I think it doesn't happen in Leela.
I don't think I understand your ontology for thinking about this, but I would probably also put Leela below this "turning point" (e.g., I expect most of its parameters are spent on storing knowledge and patterns rather than implementing crisp algorithms).
That said, for me, the natural spectrum is between a literal look-up table and brute-force tree search with no heuristics at all. (Of course, that's not a spectrum I expect to be traversed during training, just a hypothetical spectrum of algorithms.) On that spectrum, I think Leela is clearly far removed from both sides, but I find it pretty difficult to define its place more clearly. In particular, I don't see your turning point there (you start storing less knowledge immediately as you move away from the look-up table).
That's why I've tried to avoid absolute claims about how much Leela is doing pattern recognition vs "reasoning/..." but instead focused on arguing for a particular structure in Leela's cognition: I just don't know what it would mean to place Leela on either one of those sides. But I can see that if you think there's a crisp distinction between these two sides with a turning point in the middle, asking which side Leela is on is much more compelling.