Oversight Leagues: The Training Game as a Feature
post by Paul Bricman (paulbricman) · 2022-09-09T10:08:03.266Z · LW · GW · 6 commentsContents
Intro Proposal Discussion What if the agent internally simulates and games the evaluator? Wait what, you want to simulate the agent a few steps ahead of the evaluator? What if the agent and evaluator collude? What if the agent recursively self-improves without the evaluator? What if assumption 1 ("AGI Harder, Human Values Harder") doesn't hold? What if assumption 2 ("Linear Capability Ordering") doesn't hold? What if assumption 3 ("Humans Are Not True Gamers") doesn't hold? What if assumption 4 ("Zone of Proximal Development") doesn't hold? What if assumption 5 ("Point of No Return") doesn't hold? Is there an alignment tax associated with oversight leagues? Are oversight leagues restricted to prosaic risk scenarios? Outro None 6 comments
This post is part of my hypothesis subspace [? · GW] sequence, a living collection of proposals I'm exploring at Refine. [LW · GW] Followed by ideological inference engines [LW · GW].
Thanks Adam Shimi for advice on putting more legible content out there. Thanks Eric Winsor, Leo Grinsztajn, Linda Linsefors, Lucas Texeira, Tammy Leake, Ze Shen for discussions which inspired this post.
TL;DR: An oversight league is a training scheme which incentivizes an agent and an evaluator to constantly try to game each other, leading to synchronized increases in capability for the two players. However, the evaluator is being offered a host of additional learning signals to help it maintain a consistent (and potentially provable) lead over the agent. Oversight leagues heavily draw on ideas from capability literature, including: league training in AlphaStar, game theory in GANs, adversarial robustness, etc.
Intro
The whole project of oversight leagues relies on the following non-exhaustive list of assumptions:
Assumption 1, "AGI Hard, Human Values Harder": We are unlikely to formulate the True Name [AF · GW] of human values in closed-form before deploying transformative AI. The best we are likely to do before takeoff is model human values approximately and implement an imperfect evaluator.
Assumption 2, "Linear Capability Ordering": Any fixed evaluator (e.g. a reward model) can be gamed by an agent above a certain threshold of capability. More generally, an agent whose capability improves consistently faster than the capability of an evaluator will eventually be able to game said evaluator. By "evaluator capability," I'm referring to its ability to prevent being gamed.
Assumption 3, "Humans Are Not True Gamers": Human oversight is impractical because our capabilities as evaluators can't improve at an arbitrary large rate. Save for cyborgian [AF(p) · GW(p)] schemes for human augmentation, human oversight would eventually be gamed by an agent of sufficient capability.
Assumption 4, "Zone of Proximal Development": There is a relatively small interval of evaluator lead which allows the agent to improve from challenging it, even if the evaluator is slightly ahead. This assumption is motivated by the fact that GANs are actually working, despite an inevitable imbalance between the two components involved at any given time.
Assumption 5, "Point of No Return": Even a minor lead in capability for the agent relative to the evaluator is catastrophic, as the agent can take advantage of this window of opportunity and maneuver itself into a persistent advantageous position [AF · GW] by flying under the evaluator's radar.
From the assumptions above, we can infer that if we are to deploy a robust evaluator as an operationalization of human values, it must certainly not be fixed. Not only that, but it must additionally improve in performance at least as fast as the agent being evaluated, so that it never gets overtaken. What's more, simple human oversight doesn't fulfill those necessary conditions, hence we should consider automated schemes.
Proposal
An oversight league is one such automated scheme for training agents and evaluators in a way which improves their performance in lockstep. The crux of this training regime is to supply most of the training through bilateral learning signals, and thus render the improvement of the two components interdependent. By ensuring that most of the learning opportunities of the agent come from playing against the evaluator and vice versa, the two sides form a positive feedback loop resembling patterns of co-evolution. The oversight league scheme implicitly attempts to cultivate "antifragility" by applying appropriate stressors on the evaluator in the form of ever more capable agents a reliable way of improving its performance, and the other way around.
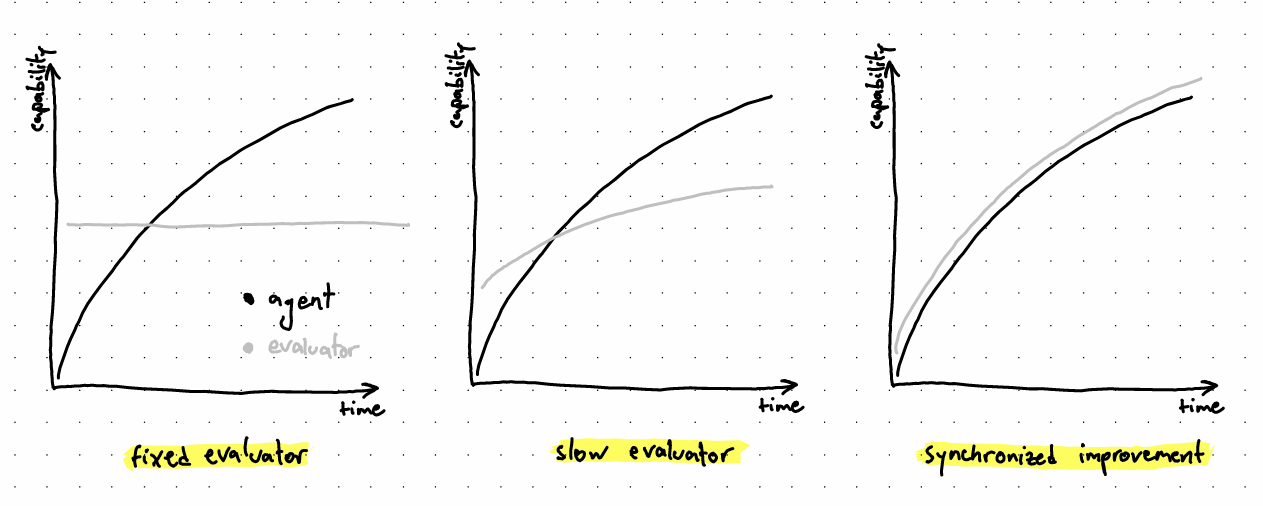
Additionally, besides the agent and evaluator constantly offering each other learning opportunities at a simultaneously increasing level, an oversight league requires unilateral learning signals applied differentially to the evaluator. The goal of such learning signals is to ensure that the evaluator has a constant edge over the agent, so as to avoid being permanently overtaken (see "Point of No Return" assumption) by chance. They are meant to provide additional learning opportunities for the evaluator, helping it patch its blindspots faster than the agent can exploit them.
Let's unpack the various learning signals involved in an oversight league, by first focusing on bilateral ones:
- Present Exploitation: Training a player (i.e. agent or evaluator) against the latest and greatest version of the opponent. The agent is trained to exploit recent blindspots of the evaluator, while the evaluator is trained to pick out recent tricks of the agent. Inspired by "main exploiters" in AlphaStar.
- Past Exploitation: Training a player against (a tricky mixture of) the past versions of the opponent. The agent is trained to exploit systematic blindspots of the evaluator across time, while the evaluator is trained to pick out systematic tricks of the agent. The role of past exploitation is to prevent the agent from forgetting about past blindspots of the evaluator and to prevent the evaluator from forgetting about past tricks of the agent. Inspired by "league exploiters" in AlphaStar.
- Future Exploitation: Training a player against future versions of the opponent. This is somewhat trickier than the previous types of exploitation, in that it involves backpropagating through updates of the (boxed) opponent. It would only be applied to the evaluator, as it would help it avoid weight updates which are easily countered by the opponent. This appears to be a promising place to look for formal guarantees on the safety of this scheme based on notions from game theory. Inspired by unrolled GANs from literature investigating ways of balancing the two adversarial components of GANs.
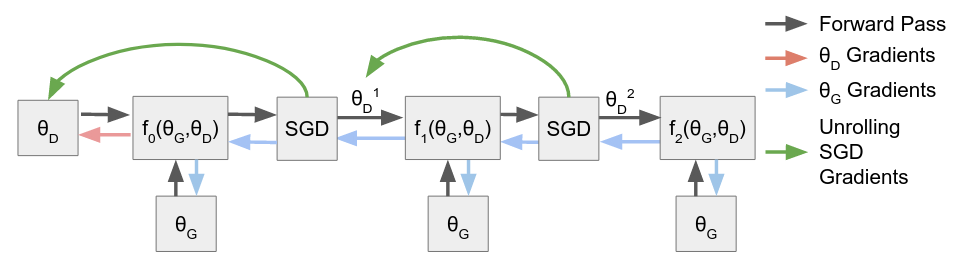
Now that we have listed broad classes of bilateral learning signals, let's focus on unilateral ones. As mentioned previously, those would mainly be applied to the evaluator as an attempt to systematically give it an edge.
- Adversarial Robustness: Train the evaluator on data points which have been optimized to maximize error within tight bounds of allowed input perturbations. In image classification, allowed perturbations are of a magnitude too low to be consciously perceived by humans, yet trip up the ML model big time. When provided as training data, adversarial examples help the ML model become (empirically) robust against such attacks. Relaxation-based training as a specific approach to adversarial training can also provide formal guarantees on the worst-case bounds of adversarial attacks.
- Contrastive Dreaming: This is a novel one, to the best of my knowledge. Just like adversarial robustness, it also involves training the evaluator on synthetic data points. However, instead of optimizing inputs to yield the worst possible prediction given imperceptible changes, contrastive dreaming consists in optimizing inputs to yield the seemingly best evaluation given significant allowed changes. In a sense, this technique involves intentionally wireheading [? · GW] the evaluator before using the optimized image of the world as a negative example. Think of the DeepDream technique being used to maximize the "dogginess" of an image as perceived by an image classifier, only to yield an image which is blatantly unrealistic with respect to how dogs actually manifest in the world.

"You were once the size of a period. For a brief time you tumbled about as a
multicellular sphere, much like pond algae. Currents swept and washed over
you. Remember? Then you grew. You became sponge life, tubular, all gut.
To eat was life. You grew a spinal cord to feel. You put on gill arches in
preparation to breathe and burn food with intensity. You grew a tail to
move, to steer, to decide. You were not a fish, but a human embryo role-
playing a fish embryo. At every ghost-of-embryonic-animal you slipped into
and out of, you replayed the surrender of possibilities needed for your
destination. To evolve is to surrender choices. To become something new is
to accumulate all the things you can no longer be." — Kevin Kelly
Together, bilateral and unilateral learning signals provide the totality of learning opportunities accessed by the agent and the evaluator in an oversight league. The table below summarizes which learning signals would be applied to train which component:
| Learning Signal | Type | Usage | Inspiration |
| Present Exploitation | bilateral | symmetrical | AlphaStar |
| Past Exploitation | bilateral | symmetrical | AlphaStar |
| Future Exploitation | bilateral | asymmetrical (evaluator only) | Unrolled GANs |
| Adversarial Robustness | unilateral | asymmetrical (evaluator only) | Robust ML |
| Contrastive Dreaming | unilateral | asymmetrical (evaluator only) | DeepDream |
Let's sketch out more concrete details of the agent and the evaluator. The agent might be a purely agentic sequence-modeling entity exposed to the world, or could just as well be an agent simulacrum puppeteered by a simulator, as per Conjecture's recent taxonomy [AF · GW]. Oversight leagues would be applied just as well in the latter case as in the former, probably in a way resembling Redwood's ongoing experiments [AF · GW] of steering the simulator away from portraying human harm. It would be a specific agent simulacrum that is being steered, though, if oversight leagues were to be applied this way.
Over on the evaluator side, the component might resemble existing reward models used to extrapolate human feedback in RLHF, but would critically possess some adaptivity to be able to keep up with the agent-in-training (e.g. constant fine-tuning). In this RLHF-like case, the term process-based evaluator seems fit to distinguish a "behavioral" evaluation target from an outcome-based one, to build on Ought's taxonomy [AF · GW]. An outcome-based evaluator would rather involve predicting the consequences which a given behavioral sequence would have on the world, and evaluating that instead of the behavior as an end in itself.
While the agent would be implemented in a relatively straightforward way through a policy, the evaluator involves more design choices when defining its type signature. Depending on the details of the unilateral learning signals, the evaluator might be tasked with predicting the training epoch associated with a past adversarial example or contrastive dream. This objective might incentivize it to gain an understanding of its systematic blindspots and an awareness of its training progress. While this sounds like an awful feature for the agent, it sounds quite handy for buffing the evaluator.
It's also relevant to point out that oversight leagues don't explicitly require transparency tools in their vanilla formulation. While the "Humans Are Not True Gamers" assumption hints at transparency tools used by humans not being deemed practical in this proposal, transparency tools might still be directly employed by players. The evaluator might benefit from probing the agent deeper in its mission of spotting its tricks, while the agent might similarly benefit from probing the evaluator deeper in its mission of spotting its blindspots. In this symmetrical setup, transparency tools feel like nice-to-haves, but not critical, as they only extend the portfolio of learning opportunities available to both agent and evaluator further. However, equipping the evaluator alone with an arsenal of transparency tools might help preserve its competitive edge.
Discussion
What if the agent internally simulates and games the evaluator?
If the agent internally simulates and games the evaluator, it means that the agent is more capable than the evaluator. The frame of oversight leagues acknowledges this state of affairs as an unambiguous game over, as the agent can maneuver itself into a persistent advantageous position. That said, the entire premise of oversight leagues is that there are mechanisms which can help avoid the situation in which the agent is capable of gaming the evaluator in the first place. It's an attempt to make away with that whole chunk of attack surface, by enforcing the evaluator's edge in complexity in hopefully provable ways.
Wait what, you want to simulate the agent a few steps ahead of the evaluator?
The idea of future exploitation as a bilateral learning signal involves backpropagating evaluator updates through multiple update steps of the oversight league, in a fully differentiable way. This is meant to avoid evaluator updates which are easily to countered by the agent in the short-term, helping ensure the evaluator's edge. However, simulating the agent forward is dangerous. Fortunately, future exploitation might involve playing forward both sides, only for the updates to accumulate backwards into the latest version of the evaluator. Additionally, future exploitation might be conducted in a boxed setting, so that we ensure that new agent versions are being explored further in a safe environment first. The gradient update coming out of the box might be susceptible to gradient hacking by a woke agent screwing up the whole setup, though I find it unlikely that the agent would manage to pull that off without triggering a whole set of alarms in the evaluator's internals first.
What if the agent and evaluator collude?
While the agent's objective is essentially implemented through the evaluator, the evaluator's objective is not entirely based on the agent. It might likely involve assigning accurate GAN-like estimates of humanness or human desirability to input behaviors or outcomes, which is incompatible with helping the agent out through "grade inflation." The oversight league is a zero-sum game: the agent and evaluator can't both win, making collusion suboptimal.
What if the agent recursively self-improves without the evaluator?
RSI appears to be a concern for this framework, as the agent might gradient hack its way above the evaluator and thus break the agent-evaluator interdependence. An sensible approach would be to continue training the evaluator against the agent so that it also shares that momentum in capabilities. However, with a situational awareness of sufficient level, the agent might be able to both (1) gradient hack its way higher, and (2) sabotage the evaluator through its influence via bilateral learning signals. With a strong evaluator lead enforced through unilateral learning signals and future exploitation, though, the agent might lack resources to enact this form of sabotage.
What if assumption 1 ("AGI Harder, Human Values Harder") doesn't hold?
That's positively awesome. In this case, we discard this completely and go with an agenda focused on aiming directly at those unraveled human values, such as that of John Wentworth [AF · GW] or Team Shard [AF · GW]. That said, the rate of progress in ML appears to be in a whole different league than progress in ethics, pun intended.
However, it's relevant to note that this proposal still attempts to approach the True Name of human values in the limit of synchronized agent-evaluator improvement, despite assuming a low probability for a closed-form expression provided in the very beginning as-is. One might argue that the present setup might effectively be equivalent to the True Name as it aims to approach it, but I'm drawing a distinction between those two cases for clarity.
What if assumption 2 ("Linear Capability Ordering") doesn't hold?
This might mean that the evaluator would be better than the agent in some category of interactions, but not in others. If one imagines the superimposed radar charts of the two, the agent's skill profile might not be fully contained in the evaluator's one.
This is partially a question of how general a player's general intelligence is. If it turns out to be extremely general, the skill profiles would be pretty flat and hence less ambiguously ordered. If it actually turns out to be more specialized, this assumption would take a hard hit, as it might be difficult to systematically enforce the evaluator's edge across the board.
What if assumption 3 ("Humans Are Not True Gamers") doesn't hold?
That's positively awesome. In this case, we similarly drop this proposal and go with a mix of agendas involving human amplification, such as the ones being investigated by parts of OpenAI, DeepMind, Conjecture, ARC, Ought, and others.
What if assumption 4 ("Zone of Proximal Development") doesn't hold?
Then the scheme might break down, as it would be impossible to improve the two components in lockstep based on each other. However, that would also mean that GANs shouldn't work, which they sometimes do, despite being infamously difficult to train. It might also mean that most supervised regimes shouldn't work, because of the huge initial capability gap between a fixed evaluator defined largely through training data and the tabula rasa agent.
What if assumption 5 ("Point of No Return") doesn't hold?
This situation interacts somewhat with the "Linear Capability Ordering" assumption, in that it hints at an underdog evaluator somehow being able to catch up with the leading agent. The myopic and non-agentic character of the evaluator makes me further reluctant of this assumption breaking, but if it did actually break, then differentially buffing the evaluator might help cover the lost ground. Additionally, the evaluator nerfing the leading agent might be feasible if this assumption wouldn't hold, say by signaling the need for reverting it a few epochs back. Though this then brings up corrigibility issues.
Is there an alignment tax associated with oversight leagues?
While many ideas here are employed to keep the agent below the evaluator in capabilities, the evaluator itself is not meant to be bounded in any way. This means that there's effectively no bound on agent capability, as it's encouraged to improve indefinitely, as long as it's a teeny-tiny bit less than how it could be (i.e. if the agent had the lead at any given point). Additionally, the enforced interdependence of agent and evaluator means that an improvement in the evaluator — even if it bounds the agent as described above — will eventually help elevate the agent through learning opportunities all the same. The main issue here is that the evaluator is resource-hungry, but I suspect any less resources allocated to the evaluator would yield an unsafe arrangement. Given the above, I consider the alignment tax to be negligible for this proposal.
Are oversight leagues restricted to prosaic risk scenarios?
They have been in large part motivated by prosaic work. I'd argue that oversight leagues are to AlphaStar what iterated distillation and amplification [? · GW] is to AlphaGoZero: a repurposing of a prosaic training regime towards safety goals (which incidentally has less capability externalities than entirely novel training regimes, as it's already present in the awareness of capability researchers). That said, I'd argue that the overarching scheme is general enough to transfer to non-ML player architectures, despite specific learning signals not being able to bridge the gap. For instance, contrastive dreaming is heavily inspired by quirks of ML models trained through gradient descent, where the optimization is applied to the input itself rather than the weights.
Outro
Oversight leagues are a natural conclusion of the initial assumptions regarding the agent-evaluator relation given shifting capability levels. This more epistemically legible format helped me clarify my thinking around the topic, and I'm looking forward to fleshing out similar posts in the future based on different assumptions and analogies. Let the training games begin!
6 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2022-09-11T21:37:35.127Z · LW(p) · GW(p)
How are you getting the connection between the legible property the evaluator is selecting for and actual alignment? As it stands, this seems like a way to train a capable agent that's hyperspecialized on some particularly legible goal.
Or to color your thinking a little more, how is the evaluator going to interact with humans, learn about them, and start modeling what they want? How is the evaluator going to wind up thinking about humans in a way that we'd approve of?
Replies from: paulbricman↑ comment by Paul Bricman (paulbricman) · 2022-09-12T13:37:32.526Z · LW(p) · GW(p)
Thanks a lot for the feedback!
How are you getting the connection between the legible property the evaluator is selecting for and actual alignment?
Quoting from another comment (not sure if this is frowned upon):
1. (Outer) align one subsystem (agent) to the other subsystem (evaluator), which we know how to do because the evaluator runs on a computer.
2. Attempt to (outer) align the other subsystem (evaluator) to the human's true objective through a fixed set of positive examples (initial behaviors or outcomes specified by humans) and a growing set of increasingly nuanced negative examples (specified by the improving agent).
As it stands, this seems like a way to train a capable agent that's hyperspecialized on some particularly legible goal.
I'm not entirely sure what you mean by legible. Do you mean a determinstic reward model which runs on a computer, even though it might have a gazillion parameters? As in, legible with respect to the human's objective?
Or to color your thinking a little more, how is the evaluator going to interact with humans, learn about them, and start modeling what they want?
In this scheme, the evaluator is not actively interacting with humans, which indeed appears to be a shortcoming in most ways. The main source of information it gets to use in modeling what humans want is the combination of initial positive examples and ever trickier negative examples posed by the agent. Hm, that gets me thinking about ways of complementing the agent as a source of negative examples with CIRL-style reaching out for positive examples, among others.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-09-12T18:01:54.250Z · LW(p) · GW(p)
"Legible" in the sense of easy to measure. For example, "what makes the human press the Like button" is legible. On the other hand, "what are the human's preferences" is often illegible.
The AI's inferred human preferences are typically latent variables within a model of humans. Not just any model will do; we have to some how get the AI to model humans in a way that mostly-satisfies our opinions about what our preferences are and what good reasoning about them is.
Replies from: paulbricman↑ comment by Paul Bricman (paulbricman) · 2022-09-14T11:22:37.014Z · LW(p) · GW(p)
Hm, I think I get the issue you're pointing at. I guess the argument for the evaluator learning accurate human preferences in this proposal is that it can make use of infinitely many examples of inaccurate human preferences conferred by the agent as negative examples. However, the argument against can be summed up in the following comment of Adam:
I get the impression that with Oversight Leagues, you don't necessarily consider the possibility that there might be many different "limits" of the oversight process, that are coherent with the initial examples. And it's not clear you have an argument that it's going to pick one that we actually want.
Or in your terms:
Not just any model will do
I'm indeed not sure if the agent's pressure would force the evaluator all the way to accurate human preferences. The fact that GANs get significantly closer to the illegible distributions they model and away from random noise while following a legible objective feels like evidence for, but the fact that they still have artifacts feels like evidence against. Also, I'm not sure how GANs fare against purely generative models trained on the positive examples alone (e.g. VAEs) as data on whether the adversarial regime helps point at the underlying distribution.
comment by Stephen Fowler (LosPolloFowler) · 2022-09-10T05:23:25.889Z · LW(p) · GW(p)
Very quick thoughts from my phone:
I enjoyed this post and recommended someone else in the office read it. You explain your thoughts well.
In general could someone explain how these alignment approaches do not simply shift the question from "how do we align this one system" to "how do we align this one system (that consists of two interacting sub-systems)"
I like assumption 1 and think its the correct way to think about things. I personally am think finding a true name for human morality is impossible.
Assumption 2 (linear capabilities ordering) strikes me as too strong. I'm not sure if this the correct ontology, with the "gaming" being quite a dynamic interactive process involving two agents modeling each other. It seems unlikely you will be able to rank performance in this task along a single axis.
Here is a rough sketch of where I think it fails:
Consider very weak evaluator, e and very strong evaluator, E.
Take an agent, A, capable of gaming the very strong evaluator E.
The very weak evaluator e runs a very simple algorithm. It avoids being gamed if the agent it is evaluating has the same source code as A.
The weak evaluator e is then clearly ranked very low. It is gamed by almost all agents. Yet it avoids being gamed by the agent that could game E.
Replies from: paulbricman↑ comment by Paul Bricman (paulbricman) · 2022-09-12T13:28:08.072Z · LW(p) · GW(p)
In general could someone explain how these alignment approaches do not simply shift the question from "how do we align this one system" to "how do we align this one system (that consists of two interacting sub-systems)"
Thanks for pointing out another assumption I didn't even consider articulating. The way this proposal answers the second question is:
1. (Outer) align one subsystem (agent) to the other subsystem (evaluator), which we know how to do because the evaluator runs on a computer.
2. Attempt to (outer) align the other subsystem (evaluator) to the human's true objective through a fixed set of positive examples (initial behaviors or outcomes specified by humans) and a growing set of increasingly nuanced negative examples (specified by the improving agent).
The very weak evaluator e runs a very simple algorithm. It avoids being gamed if the agent it is evaluating has the same source code as A.
Oh, that's interesting. I think this is indeed the most fragile assumption from the ones invoked here. Though I'm wondering if you could actually obtain such an evaluator using the described procedure.