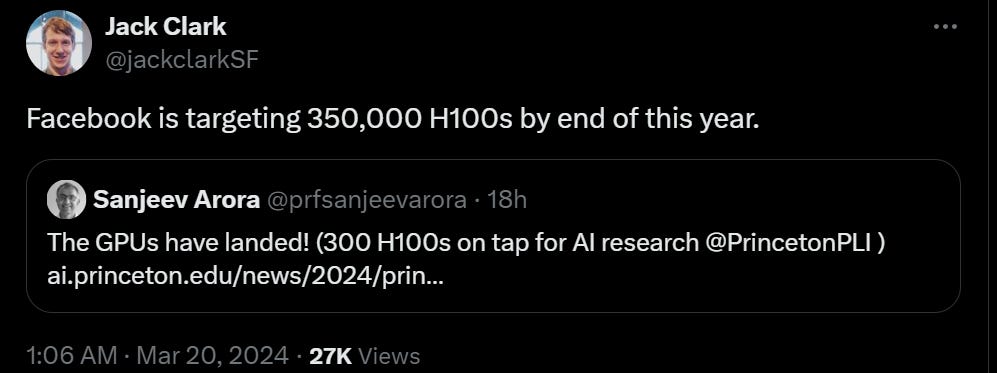
Sully is predictably impressed by Claude Haiku, says it offers great value and speed, and is really good with images and long context, suggests using it over GPT-3.5. He claims Cohere Command-R is the new RAG king, crushing it with citations and hasn’t hallucinated once, while writing really well if it has context. And he thinks Hermes 2 Pro is ‘cracked for agentic function calling,’ better for recursive calling than GPT-4, but 4k token limit is an issue. I believe his reports but also he always looks for the bright side.
From Claude 3, describe things at various levels of sophistication (here described as IQ levels, but domain knowledge seems more relevant to which one you will want in such spots). In this case they are describing SuperFocus.ai, which provides custom conversational AIs that claim to avoid hallucinations by drawing on a memory bank you maintain. However, when looking at it, it seems like the ‘IQ 115’ and ‘IQ 130’ descriptions tell you everything you need to know, and the only advantage of the harder to parse ‘IQ 145’ is that it has a bunch of buzzwords and hype attached. The ‘IQ 100’ does simplify and drop information in order to be easier to understand, but if you know a lot about AI you can figure out what it is dropping very easily.
Michael Nielsen: Dozens of different use cases. Several times this morning: terminology improvement or solving single-sentence writing problems. I often use it to talk over problems (sometimes with Whisper, while I walk). Cleaning up brainstorming (usually with Otter). It’s taught me a lot about many subjects, especially protein biology and history, though one needs to develop some expertise in use to avoid hallucination. Modifying the system ChatGPT prompt so it asks me questions and is brief and imaginative has also been very helpful (especially the questions) – makes it more like a smart colleague.
Another common use case: generating lists of ideas. I’ll ask it for 10 ideas of some specified time, then another 10, etc. Most of the ideas are usually mediocre or bad, but I only need one to get me out of a rut. (Also: much like with a colleague.)
Also: very handy for solving all sorts of coding and debugging and computer problems; enough so that I do quite a bit more of this kind of thing. Though again: care is sometimes needed. It suggested I modify the system registry once, and I gently suggested I was a bit nervous about that. It replied that on second thought that was probably wise of me…
Something I don’t do: use it to generate writing. It baffles me that people do this.
It does not baffle me. People will always look for the quickest and easiest path. Also, if you are not so good at writing, or your goal in writing is different, it could be fine.
On the below: All true, I find the same, the period has already begun for non-recent topics, and yes this is exactly the correct vibes:
Paul Graham: Before AI kills us there will at least be a period during which we’re really well-informed, if we want to be. I mainly use it for looking things up, and because it works so much better than Google for this, I look a lot more things up.
David Holz (founder, MidJourney): “I don’t want a book if I can’t talk to it” feels like a quote from the relatively near future.
Presumably a given teacher is only going to fall for that trick at most once? I don’t think this play is defensible. Either you should be able to use the internet, or you shouldn’t be able to use a local LLM.
Sully Omarr: No one should be hand writing prompts anymore.
Especially now more than ever, with how good Claude is at writing
Start with a rough idea of what you want to do and then ask for improvements like this:
Prompt:
“I have a rough outline for my prompt below, as well as my intended goal. Use the goal to make this prompt clearer and easier to understand for a LLM.
<goal> {your goal here} </goal>
<originalPrompt> {original} </originalPrompt>
<improvedPrompt> </improvedPrompt>”
You’d be surprised with how well it can take scrappy words + thoughts and turn it into a nearly perfectly crafted prompt.
tinkerbrains: I am using opus & sonnet to write midjourney prompts and they are doing exceptionally well. I think soon this will transform into what wordpress became for web development. There will be democratized (drag & drop style) AI agent building tools with inbuilt prompt libraries.
I would not be surprised, actually, despite not having done it. It is the battle between ‘crafting a bespoke prompt sounds like a lot of work’ and also ‘generating the prompt to generate the prompt then using that prompt sounds like a lot of work.’
The obvious next thing is to create an automated system, where you put in low-effort prompts without bothering with anything, and then there is scaffolding that queries the AI to turn that into a prompt (perhaps in a few steps) and then gives you the output of the prompt you would have used, with or without bothering to tell you what it did.
Using Claude to write image prompts sounds great, so long as you want things where Claude won’t refuse. Or you can ask for the component that is fine, then add in the objectionable part later, perhaps?
A lot of what LLMs offer is simplicity. You do not have to be smart or know lots of things in order to type in English into a chat window. As Megan McArdle emphasizes in this thread, the things that win out usually are things requiring minimal thought where the defaults are not touched and you do not have to think or even pay money (although you then pay other things, like data and attention). Very few people want customization or to be power users.
Near: Underused strategy in life! [quotes: Somebody thought, “well this rulebook is long and boring, so probably nobody has read it all the way through, and if I do, money might come flying out.]
Patrick McKenzie: I concur. Also the rule book is much more interesting than anyone thinks it is. It’s Dungeons and Dragons with slightly different flavor text.
If you don’t like the flavor text, substitute your own. (Probably only against the rules a tiny portion of the time.)
…
Pedestrian services businesses are one. I know accountants in Tokyo that are Silicon Valley well-off, not Tokyo well-off, on the basis that nobody doing business internationally thinks reading Japanese revenue recognition circulars is a good use of their time.
Ross Rheingans-Yoo: “If you don’t like the flavor text, substitute your own.” can be an extremely literal suggestion, fwiw.
“This is 26 USC 6050I. Please rewrite it, paragraph for paragraph, with a mechanically identical description of [sci-fi setting].”
A very clear pattern: Killer AI features are things you want all the time. If you do it every day, ideally if you do it constantly throughout the day, then using AI to do it is so much more interesting. Whereas a flashy solution to that Tom Blomfield calls an ‘occasional’ problem gets low engagement. That makes sense. Figuring out how and also whether to use, evaluate and trust a new AI product has high overhead, and for the rarer tasks it is usually higher not lower. So you would rather start off having the AIs do regularized things.
I think most people use the chatbots in similar fashion. We each have our modes where we have learned the basics of how to get utility, and then slowly we try out other use cases, but mostly we hammer the ones we already have. And of course, that’s also how we use almost everything else as well.
Min Choi has a thread with ways Claude 3 Opus has ‘changed the LLM game,’ enabling uses that weren’t previously viable. Some seem intriguing, others do not, the ones I found exciting I’ll cover on their own.
Expert coding is the most exciting, if true.
Yam Peleg humblebrags that he never used GPT-4 for code, because he’d waste more time cleaning up the results than it saved him, but says he ‘can’t really say this in public’ (while saying it in public) because nearly everyone you talk to will swear by GPT-4’s time saving abilities. As he then notices, skill issue, the way it saved you time on doing a thing was if (and only if) you lacked knowledge on how to do the thing. But, he says, highly experienced people are now coming around to say Claude is helping them.
Brendan Dolan-Gavitt: I gave Claude 3 the entire source of a small C GIF decoding library I found on GitHub, and asked it to write me a Python function to generate random GIFs that exercised the parser. Its GIF generator got 92% line coverage in the decoder and found 4 memory safety bugs and one hang.
…
As a point of comparison, a couple months ago I wrote my own Python random GIF generator for this C program by hand. It took about an hour of reading the code and fiddling to get roughly the same coverage Claude got here zero-shot.
John David Pressman: “If you spend more time making sure it doesn’t do something stupid, it’ll actually look pretty smart.”
People don’t evaluate LLMs based on the smartest things they can do, but the dumbest things they can do. This causes model trainers to make them risk averse to please users.
In the case of LLMs there are more like five modes?
If your goal is to ask what it cannot do in general, where it is not useful, you will always find things, but you will notice that what you find will change over time. Note that every human has simple things they never learned to do either. This is the traditional skeptic mode.
If your goal is to ask for examples where the answer is dumb, so you can then say ‘lol look at this dumb thing,’ you will always find them. You would also find them with any actual human you could probe in similar fashion. This is Gary Marcus mode.
If your goal is to ask how good it is doing against benchmarks or compare it to others, you will get a number, and that number will be useful, especially if it is not being gamed, but it will tell you little about what you will want to do or others will do in practice. This is the default mode.
If your goal is to ask how good it is in practice at doing things you or others want to do, you will find out, and then you double down on that. This is often my mode.
If your goal is to ask if it can do anything at all, to find the cool new thing, you will often find some very strange things. This is Janus mode.
Could an AI replace all music ever recorded with Taylor Swift covers? It is so weird the things people choose to worry about as the ‘real problem,’ contrasted with ‘an AI having its own motivations and taking actions to fulfil those goals’ which is dismissed as ‘unrealistic’ despite this already being a thing.
And the portions are so small. Karen Ho writes about how AI companies ‘exploit’ workers doing data annotation, what she calls the ‘lifeblood’ of the AI industry. They exploit them by offering piecemail jobs that they freely accept at much higher pay than is otherwise available. Then they exploit them by no longer hiring them for more work, devastating their incomes.
Gemini later caved. Yes, the police lied to it, but they are allowed to do that.
Not available yet, but hopefully can shift categories soon: Automatically fill out and return all school permission slips. Many similar things where this is the play, at least until most people are using it. Is this defection? Or is requiring the slip defection?
Fun with Image Generation
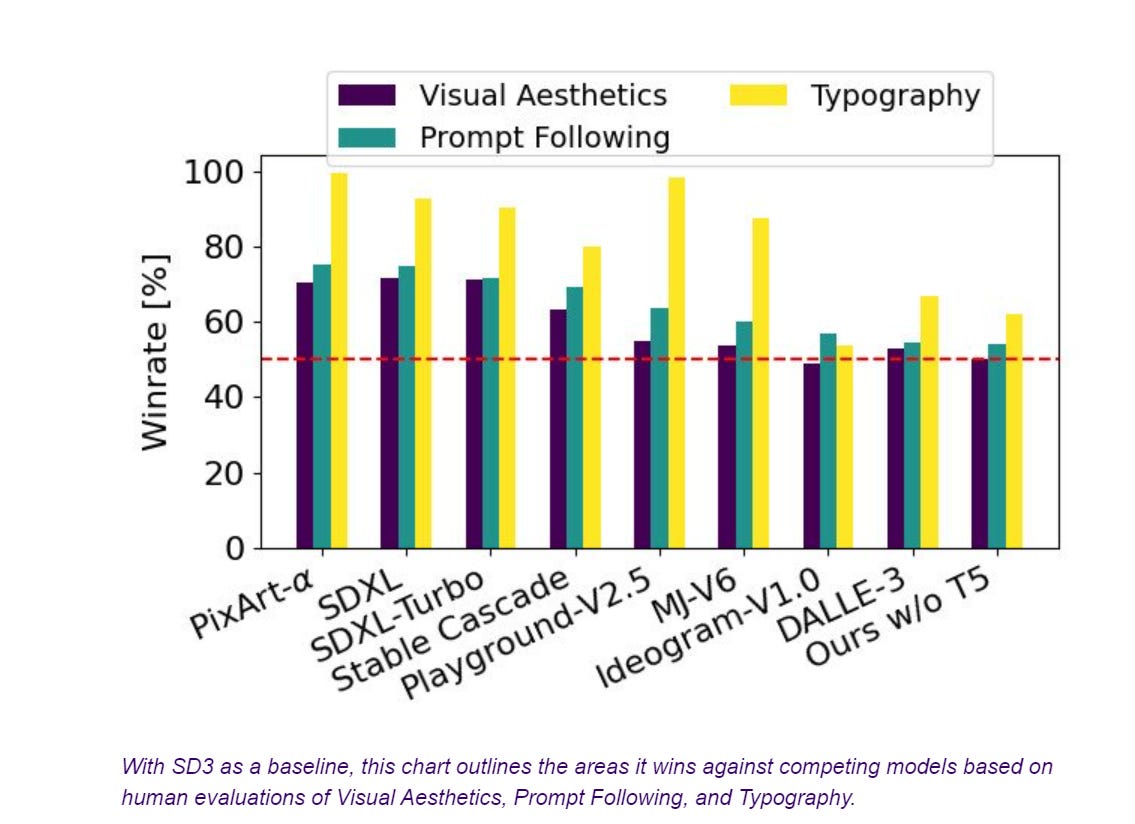
I missed that they released the paper for the upcoming Stable Diffusion 3. It looks like the first model that will be able to reliably spell words correctly, which is in practice a big game. No word on the exact date for full release.
This chart is a bit weird and backwards to what you usually see, as this is ‘win rate of SD3 versus a given model’ rather than how each model does. So if you believe the scores, Ideogram is scoring well, about on par with SD3, followed by Dalle-3 and MidJourney, and this would be the new open source state of the art.
In early, unoptimized inference tests on consumer hardware our largest SD3 model with 8B parameters fits into the 24GB VRAM of a RTX 4090 and takes 34 seconds to generate an image of resolution 1024×1024 when using 50 sampling steps. Additionally, there will be multiple variations of Stable Diffusion 3 during the initial release, ranging from 800m to 8B parameter models to further eliminate hardware barriers.
Right now I am super busy and waiting on Stable Diffusion 3, but there are lots of really neat tools out there one can try with 1.5. The tools that help you control what you get are especially exciting.
fofr: A quick experiment with composition IPAdapter to merge the this is fine and distracted boyfriend memes.
fofr: A small thread of interesting things you can do with my become-image Replicate model:
1. You can use animated inputs to reimagine them as real world people, with all of their exaggerated features
Similarly, here we have Composition Adapter for SD 1.5, which takes the general composition of an image into a model while ignoring style/content. Pics at link, they require zooming in to understand.
Perhaps we are going to get some adult fun with video generation? Mira Mutari says that Sora will definitely be released this year and was unsure if the program would disallow nudity, saying they are working with artists to figure that out.
Britney Nguyen (Quartz): But Colson said the public also “doesn’t trust the tech companies to do that in a responsible manner.”
“OpenAI has a challenging decision to make around this,” he said, “because for better or worse, the reality is that probably 90% of the demand for AI-generated video will be for pornography, and that creates an unpleasant dynamic where, if centralized companies creating these models aren’t providing that service, that creates an extremely strong incentive for the gray market to provide that service.”
Exactly. If you are using a future open source video generation system, it is not going to object to making deepfakes of Taylor Swift. If your response is to make Sora not allow artistic nudity, you are only enhancing the anything-goes ecosystems and models, driving customers into their arms.
So your best bet is to, for those who very clearly indicate this is what they want and that they are of age and otherwise legally allowed to do so, to be able to generate adult content, as broadly as your legal team can permit, as long as they don’t do it of a particular person without that person’s consent.
• They join 10 other recent high profile departures
• Running out of funding, payroll troubles
• Investment firms resigning from board
• Push for Emad to resign as CEO
• Upcoming Getty trial
To paint a picture of the turmoil at Stability AI, here are the C-level and senior resignations we know about from the past 12 months. Doesn’t look good, and I suspect it’s even worse behind the scenes. Big thanks to a friend for tracking and compiling.
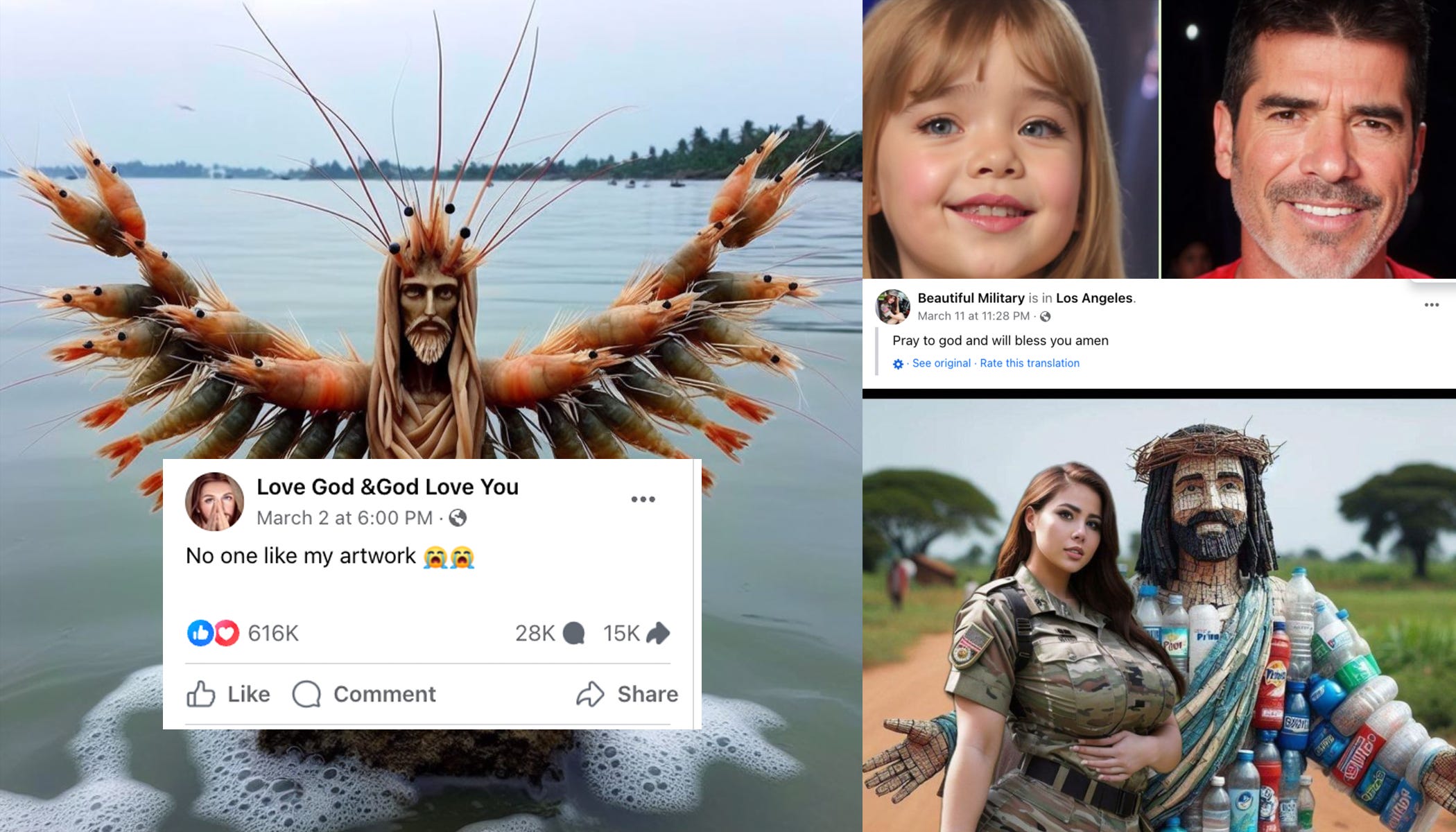
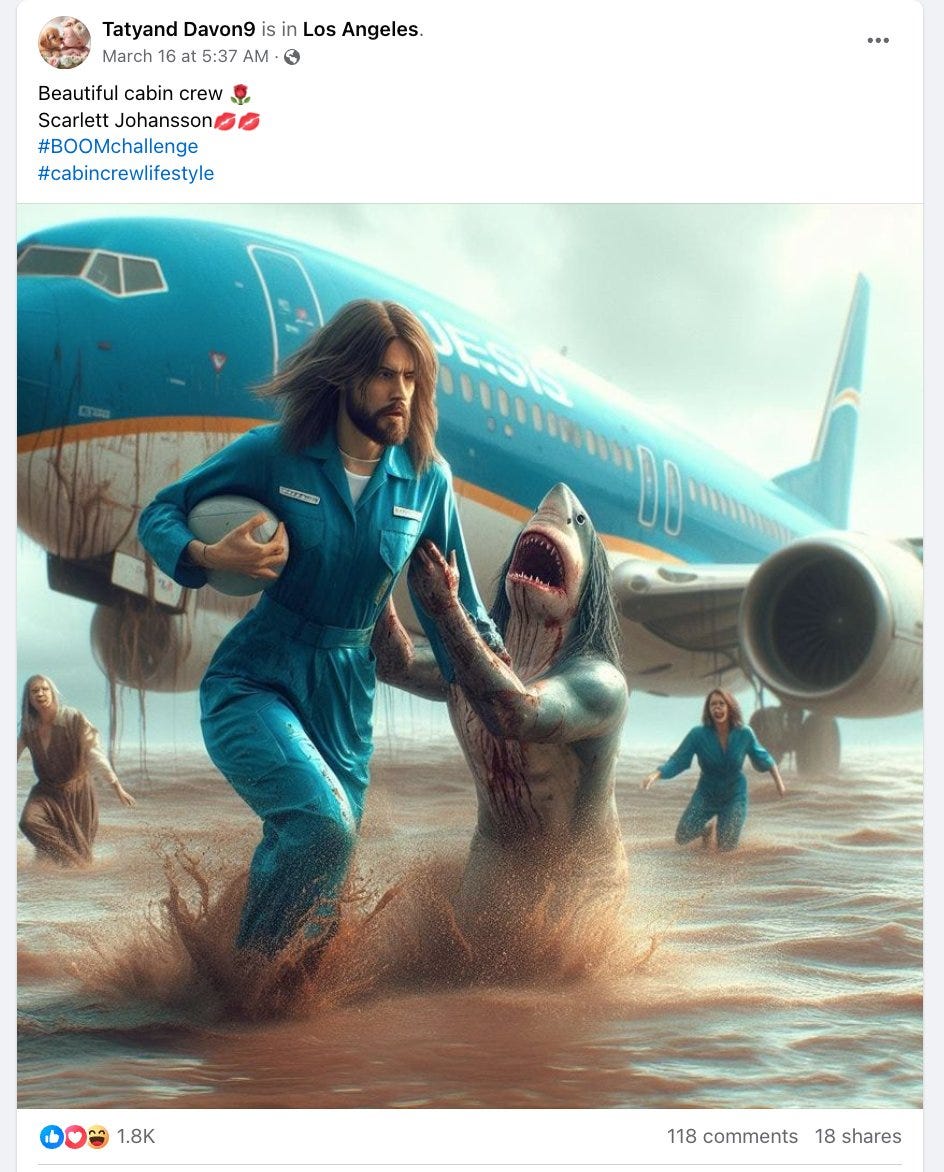
Jason Koebler: Facebook’s algorithm is recommending the bizarre, AI-generated images (like “Shrimp Jesus”) that are repeatedly going viral. Pages doing this are linking out to AI-generated and otherwise low-effort spam pages that are stacked with ads:
Jason Koebler: People see the bizarre AI images and go “wtf is the scam here?” My article tries to answer this. Not all pages are the same, but clickfarms have realized that AI content works on FB. Stanford studied 120 pages and found hundreds of millions of engagements over last few months
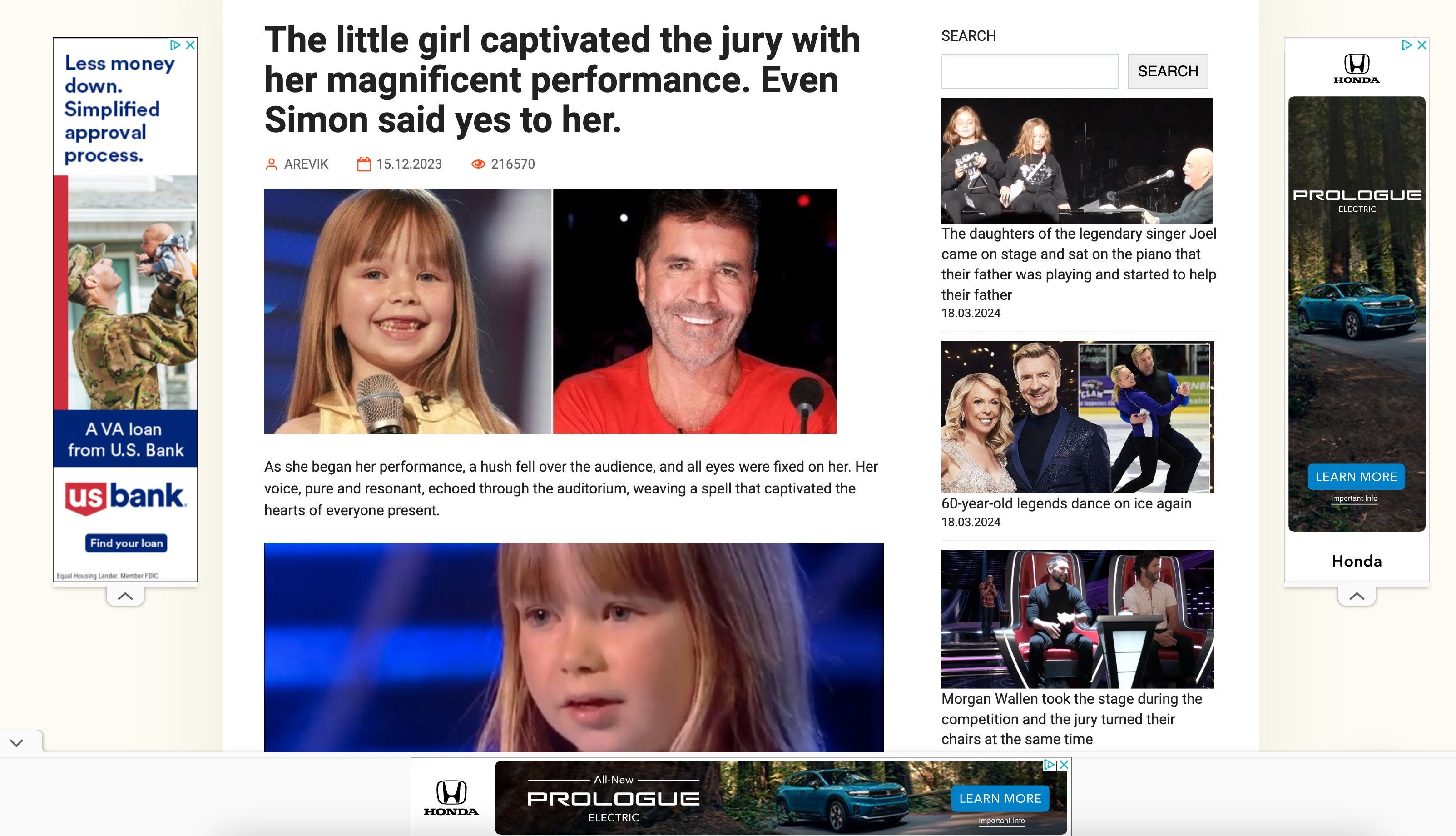
I want to explain exactly what the scam is with one of the pages, called “Thoughts” Thoughts is making AI-edited image posts that link to an ad-spam clickfarm in the comments. They specialize in uplifting X Factor/Britain’s Got Talent videos
This sounds like where you say ‘no, Neal Stephenson, that detail is dumb.’ And yet.
Notice that Simon and the girl are AI-generated on the Facebook post but not on the clickfarm site. Notice that they put the article link in the comments. They must be doing this for a reason. Here is that reason:
This is Thoughts’ CrowdTangle data (FB is shutting down CrowdTangle). Thoughts began posting AI-generated images in December. Its engagement and interactions skyrocketed.
I created a dummy Facebook account, commented on a few of Thoughts’ images (but did nothing else), and now ~75% of my news feed is AI images of all types. Every niche imaginable exists.
These images have gone viral off platform in a “wtf is happening on FB” way, and I know mostly boomers and the worst people you know are still there but journalistically it’s the most interesting platform rn because it’s just fully abandoned mall, no rules, total chaos vibes
twitter is also a mess but it’s a mess in a different sort of way. Rugby pilot jesus of JESIS airlines trying to escape a shark.
You say AI deepfake spam. I say, yes, but also they give the people what they want?
These images are cool. Many people very much want cool pictures in general, and cool pictures of Jesus in particular.
Also these are new and innovative. Next year this will all be old hat. Now? New hat.
The spam payoff is how people monetize when they find a way to get engagement. The implementation is a little bizarre, but sure, not even mad about it. Much better than scams or boner pills.
They Took Our Jobs
Noah Smith says (there is also a video clip of him saying the same thing) there will be plentiful, high-paying jobs in the age of AI because of comparative advantage.
This is standard economics. Even if Alice is better at every job than Carol there is only one Alice and only so many hours in the day, so Carol is still fine and should be happy that Alice exists and can engage in trade. And the same goes if there are a bunch of Alices and a bunch of Carols.
Noah Smith takes the attitude that technologists and those who expect to lose their jobs simply do not understand this subtle but super important concept. That they do not understand how this time will be no different from the other times we automated away older jobs, or engaged in international trade.
The key, he thinks, is to explain this principle to those who are confused.
Imagine a venture capitalist (let’s call him “Marc”) who is an almost inhumanly fast typist. He’ll still hire a secretary to draft letters for him, though, because even if that secretary is a slower typist than him, Marc can generate more value using his time to do something other than drafting letters. So he ends up paying someone else to do something that he’s actually better at.
Note that in our example, Marc is better than his secretary at every single task that the company requires.
…
This might sound like a contrived example, but in fact there are probably a lot of cases where it’s a good approximation of reality.
And yes, there are lots of people, perhaps most people, who do not understand this principle. If you do not already understand it, it is worth spending the time to do so. And yes, I agree that this is often a good approximation of the situation in practice.
He then goes on to opportunity cost.
So compute is a producer-specific constraint on AI, similar to constraints on Marc’s time in the example above. It doesn’t matter how much compute we get, or how fast we build new compute; there will always be a limited amount of it in the world, and that will always put some limit on the amount of AI in the world.
The problem is that this rests on the assumption that there are only so many Alices, with so many hours in the day to work, that the supply of them is not fully elastic and they cannot cover all tasks worth paying a human to do. That supply constraint binding in practice is why there are opportunity costs.
And yes, I agree that if the compute constraint somehow bound, if we had a sufficiently low hard limit on how much compute was available, whether it was a chip shortage or an energy shortage or a government limit or something else, such that people were bidding up the price of compute very high, then this could bail us out.
The problem is that this is not how costs or capacities seem remotely likely to work?
Here is Noah’s own example.
Here’s another little toy example. Suppose using 1 gigaflop of compute for AI could produce $1000 worth of value by having AI be a doctor for a one-hour appointment. Compare that to a human, who can produce only $200 of value by doing a one-hour appointment. Obviously if you only compared these two numbers, you’d hire the AI instead of the human. But now suppose that same gigaflop of compute, could produce $2000 of value by having the AI be an electrical engineer instead. That $2000 is the opportunity cost of having the AI act as a doctor. So the net value of using the AI as a doctor for that one-hour appointment is actually negative. Meanwhile, the human doctor’s opportunity cost is much lower — anything else she did with her hour of time would be much less valuable.
So yes. If there are not enough gigaflops of compute available to support all the AI electrical engineers you need, then a gigaflop will sell for a little under $2000, it will all be used for engineers and humans get to keep being doctors. Econ 101.
For reference: The current cost of a gigaflop of compute is about $0.03. The current cost of GPT-4 is $30 for one million prompt tokens, and $60 for one million output tokens.
Oh, and Nvidia’s new Blackwell chips are claimed to be 25 times as power efficient when grouped together versus past chips, see that section. Counting on power costs to bind here does not seem like a wise long term play.
Noah Smith understands that the AI can be copied. So the limiting factor has to be the available compute. The humans keep their jobs if and only if compute is bid up sufficiently high that humans can still earn a living. Which Noah understands:
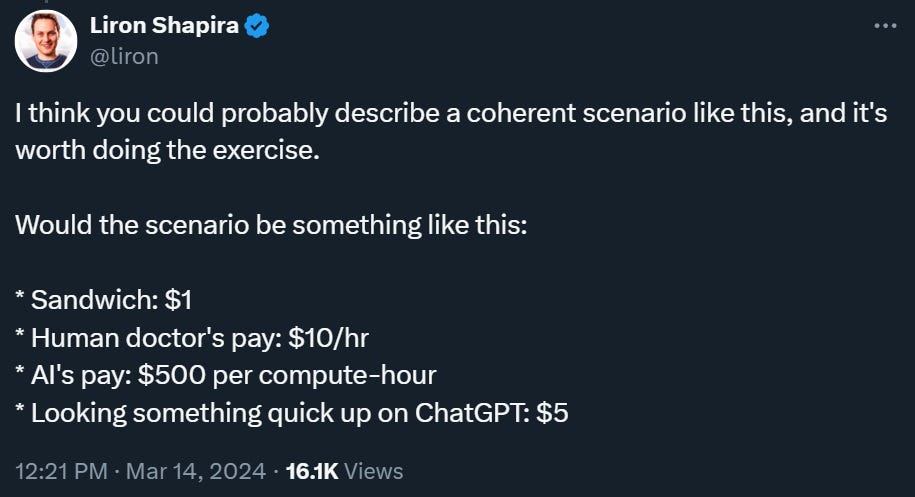
Noah Smith: In other words, the positive scenario for human labor looks very much like what Liron Shapira describes in this tweet:
Noah Smith: Of course it might not be a doctor — it might be a hairdresser, or bricklayer, or whatever — but this is the basic idea.
So yes, you can get there in theory, but it requires that compute be at a truly extreme premium. It must be many orders of magnitude more expensive in this future than it is now. It would be a world where most humans would not have cell phones or computers, because they would not be able to afford them.
Noah says that horses were left out in the cold because they were competing with other forms of capital for resources. Horses require not only calories but also land, and human time and effort.
Well, humans require quite a lot of time, space, money, calories, effort and other things to raise and maintain, as well. Humans do not as Noah note require ‘compute’ in the sense of compute on silicon, but we require a lot of energy in various forms to run our own form of compute and other functions.
The only way that does not compete for resources with building and operating more compute is if the compute hits some sort of hard limit that keeps it expensive, such as running out of a vital element, and we cannot improve our efficiency further to fix this. So perhaps we simply cannot find more of various rare earths or neon or what not, and have no way to make more and what is left is not enough, or something?
Remember that we get improved algorithmic efficiency and hardware efficiency every year, and that in this future the AIs can do all that work for us, and it looks super profitable to assign them that task.
This all seems like quite the dim hope.
If Noah Smith was simply making the point that this outcome was theoretically possible in some corner worlds where we got very strong AI that was severely compute limited, and thus unable to fully outcompete us, then yes, it is in theory physically possible that this could happen.
But Noah Smith is not saying that. He is instead treating this as a reason not to worry. He is saying that what we should worry about instead is inequality, the idea that someone else might get rich, the adjustment period, and that AI will ‘successfully demand ownership of the means of production.’
As usual, the first one simply says ‘some people might be very rich’ without explaining why that is something we should be concerned about.
The second one is an issue, as he notes if doctor became an AI job and then wanted to be a human job again it would be painful, but also if AI was producing this much real wealth, so what? We could afford such adjustments with no problem, because if that was not true then the AI would keep doing the doctor roles for longer in this bizarre scenario.
That third one is the most economist way I have yet heard of saying ‘yes of course AI in this scenario will rapidly control the future and own all the resources and power.’
Yes, I do think that third worry is indeed a big deal.
In addition to the usual ways I put such concerns: As every economist knows, trying to own those who produce is bad for efficiency, and is not without legal mandates for it a stable equilibrium, even if the AIs were not smarter than us and alignment went well and we had no moral qualms and so on.
And it is reasonable to say ‘well, no, maybe you would not have jobs, but we can use various techniques to spend some wealth and make that acceptable if we remain in control of the future.’
I do not see how it is reasonable to expect – as in, to put a high probability on – worlds in which compute becomes so expensive, and stays so expensive, that despite having highly capable AIs better than us at everything the most physically efficient move continues to be hiring humans for lots of things.
And no, I do not believe I am strawmanning Noah Smith here. See this comment as well, where he doubles down, saying so what if we exponentially lower costs of compute even further, there is no limit, it still matters if there is any producer constraint at all, literally he says ‘by a thousand trillion trillion quadrillion orders of magnitude.’
I get the theoretical argument for a corner case being a theoretical possibility. But as a baseline expectation? This is absurd.
I also think this is rather emblematic of how even otherwise very strong economists are thinking about potential AI futures. Economists have intuitions and heuristics built up over history. They are constantly hearing and have heard that This Time is Different, and the laws have held. So they presume this time too will be the same.
And in the short term, I agree, and think the economists are essentially right.
The problem is that the reasons the other times have not been different are likely not going to apply this time around if capabilities keep advancing. Noah Smith is not the exception here, where he looks the problem in the face and says standard normal-world things without realizing how absurd the numbers in them look or asking what would happen. This is the rule. Rather more absurd than most examples? Yes. But it is the rule.
Can what Tyler Cowen speculates is ‘the best paper on these topics so far’ do better?
Abstract: We analyze how output and wages behave under different scenarios for technological progress that may culminate in Artificial General Intelligence (AGI), defined as the ability of AI systems to perform all tasks that humans can perform.
We assume that human work can be decomposed into atomistic tasks that differ in their complexity. Advances in technology make ever more complex tasks amenable to automation. The effects on wages depend on a race between automation and capital accumulation.
If automation proceeds sufficiently slowly, then there is always enough work for humans, and wages may rise forever.
By contrast, if the complexity of tasks that humans can perform is bounded and full automation is reached, then wages collapse. But declines may occur even before if large-scale automation outpaces capital accumulation and makes labor too abundant. Automating productivity growth may lead to broad-based gains in the returns to all factors. By contrast, bottlenecks to growth from irreproducible scarce factors may exacerbate the decline in wages.
This paper once again assumes the conclusion that ‘everything is economic normal’ with AGI’s only purpose to automate existing tasks, and that AGI works by automating individual tasks one by one. As is the pattern, the paper then reaches conclusions that seem obvious once the assumptions are made explicit.
This is what I have been saying for a long time. If you automate some of the jobs, but there are still sufficient productive tasks left to do, then wages will do fine. If you automate all the jobs, including the ones that are created because old jobs are displaced and we can find new areas of demand, because AGI really is better at everything (or everything except less than one person’s work per would-be working person) then wages collapse, either for many or for everyone, likely below sustenance levels.
Noah Smith was trying to escape this conclusion by using comparative advantage. This follows the same principle. As long as the AI cannot do everything, either because you cannot run enough inference to do everything sufficiently well at the same time or because there are tasks AIs cannot do sufficiently well regardless, and that space is large enough, the humans are all right if everything otherwise stays peaceful and ‘economic normal.’ Otherwise, the humans are not all right.
The conclusion makes a case for slowing down AI development, AI deployment or both, if things started to go too fast. Which, for these purposes, is clearly not yet the case. On the current margin wages go up and we all get richer.
Generative AI in Games
Michael Crook writesa two part warning in Rock Paper Shotgun about generative AI and protecting games and art from it. As he points out, our terminology for this is not great, so he suggests some clarifying terms.
Michael Crook: To help you think about some of these differences, I’ve got some suggestions for new words we can use to talk about generative AI systems. The first is ‘online’ versus ‘offline’ systems (which I’m borrowing from research on procedural generation). Online systems generate content while you’re playing the game – AI Dungeon is an example of an online generative AI system, because it writes in real-time while you’re playing. Offline systems are more for use during development, like the use of generated AI portraits in the indie detective game The Roottrees Are Dead.
…
Another way we can categorise generative AI systems is between “visible” and “invisible” systems. Visible systems produce content that you directly feel the effect of – things like art or music – while invisible systems generate content that the average player might not be as aware of. For example, some programmers use GitHub Copilot, a generative AI system that can write small sections of program code.
…
The visibility of a generative AI system may be increasingly important as backlash against the use of AI tools rises, because developers may feel safer employing generative AI in less visible ways that players are less likely to feel the presence of.
…
The third category, and maybe the most important one, is whether the AI is “heavy” or “light” – thanks to my colleague and student Younès Rabii for suggesting the names for this one. Lots of the most famous generative AI tools, like ChatGPT or Midjourney, have been trained on billions of images or documents that were scraped from all across the Internet; they’re what I call heavy. Not only is this legally murky – something we’ll come back to in the next part of this series – but it also makes the models much harder to predict. Recently it’s come to light that some of these models have a lot of illegal and disturbing material in their training data, which isn’t something that publishers necessarily want generating artwork in their next big blockbuster game. But lighter AI can also be built and trained on smaller collections of data that have been gathered and processed by hand. This can still produce great results, especially for really specialised tasks inside a single game.
The generative AI systems you hear about lately, the ones we’re told are going to change the world, are online, visible and heavy.
That was in part one, which I think offers useful terms. Then in part two, he warns that this heavy generative AI is a threat, that we must figure out what to do about it, that it is stealing artists work and so on. The usual complaints, without demonstrating where the harms lie beyond the pure ‘they took our jobs,’ or proposing a solution or way forward. These are not easy problems.
Get Involved
The EU AI Office is still looking for EU citizens with AI expertise to help them implement the EU AI Act, including regulation of general-purpose models.
TacticAI, a Google DeepMind AI to better plan corner kicks in futbol, claimed to be as good as experts in choosing setups. I always wondered how this could fail to be a solved problem.
Character.ai allowing adding custom voices to its characters based on only ten seconds of audio. Great move. I do not want voice for most AI interactions, but I would for character.ai, as I did for AI Dungeon, and I’d very much want to select it.
A debate about implications followed, including technical discussion on Mamba.
Eliezer Yudkowsky (referring to above paper): Funny, how AI optimists talked like, “AI is trained by imitating human data, so it’ll be like us, so it’ll be friendly!”, and not, “Our safety model made a load-bearing assumption that future ASI would be solely trained to imitate human outputs…”
The larger story here is that ML developments post-2020 are blowing up assumptions that hopesters once touted as protective. Eg, Mamba can think longer than 200 serial steps per thought. And hopesters don’t say, or care, or notice, that their old safety assumption was violated.
Gallabytes: that’s not true – mamba is no better at this than attention, actually worse, it’s just cheaper. tbc, “it can’t reason 200 steps in a row” was cope then too. I’m overall pretty optimistic about the future but there are plenty of bad reasons to happen to agree with me and this was one of them.
Nora Belrose: I’ve been doing interpretability on Mamba the last couple months, and this is just false. Mamba is efficient to train precisely because its computation can be parallelized across time; ergo it is not doing more irreducibly serial computation steps than it has layers.
I also don’t think this is a particularly important or load bearing argument for me. Optimization demons are implausible in any reasonable architecture.
Eliezer Yudkowsky: Reread the Mamba paper, still confused by this, though I do expect Nora to have domain knowledge here. I’m not seeing the trick / simplification for how recurrence with a time-dependent state-transform matrix doesn’t yield any real serial depth.
Eliezer Yudkowsky: I did not miss that part, but the connection to serial depth of computation is still not intuitive to me. It seems like I ought to be able to describe some independency property of ‘the way X depends on Y can’t depend on Z’ and I’m not seeing it by staring at the linear algebra. (This is not your problem.)
It is always frustrating to point out when an argument sometimes made has been invalidated, because (1) most people were not previously making that argument and (2) those that were have mostly moved on to different arguments, or moved on forgetting what the arguments even were, or they switch cases in response to the new info. At best, (3) even if you do find the ones who were making that point, they will then say your argument is invalid for [whatever reason they think of next].
You can see here a good faith reply (I do not know who is right about Mamba here and it doesn’t seem easy to check?) but you also see the argument mismatch. If anything, this is the best kind of mismatch, where everyone agrees that the question is not so globally load bearing but still want to figure out the right answer.
If your case for safety depends on assumptions about what the AI definitely cannot do, or definitely will do, or how it will definitely work, or what components definitely won’t be involved, then you should say that explicitly. And also you should get ready for when your assumption becomes wrong.
Metr, formerly ARC Evals, releasesnew resources for evaluating AIs for risks from autonomous capabilities. Note that the evaluation process is labor intensive rather than automated.
Strengths:
Compared to existing benchmarks, the difficulty range of tasks in our set reaches much higher, up to tasks that take experienced humans a week. We think it’s fairly unlikely that this task suite will saturate prematurely.
All tasks have a difficulty estimate based on the estimated time for a human with the relevant expertise to complete the task. Where available, we use data from real human attempts.
The tasks have individual quality indicators. The highest quality tasks have been manually vetted, including having humans run through the full task.
The tasks should mostly not be memorized by current models; most of them were created from scratch for this suite.
The tasks aim to isolate core abilities to reason, explore, and recover from errors, and to avoid cases where model performance is highly dependent on tooling, modality, or model “disposition”.
Limitations + areas for future work:
There are currently only a small number of tasks, especially on the higher difficulty end. We would like to make a larger number of tasks, and add more tasks above the current difficulty range.
The tasks are not that closely tied to particular threat models. They measure something more like “ability to autonomously do engineering and research at human professional level across a variety of domains”. We would like to make tasks that link more clearly to steps required in concrete threat models.
Cerebus WSE-3, claiming to be the world’s fastest AI chip replacing the previous record holder of the WSE-2. Chips are $2.5 million to $2.8 million each. The person referring me to it says it can ‘train and tune a Llama 70b from scratch in a day.’ Despite this, I do not see anyone using it.
The Church will use artificial intelligence to support and not supplant connection between God and His children.
The Church will use artificial intelligence in positive, helpful, and uplifting ways that maintain the honesty, integrity, ethics, values, and standards of the Church.
Transparency
People interacting with the Church will understand when they are interfacing with artificial intelligence.
The Church will provide attribution for content created with artificial intelligence when the authenticity, accuracy, or authorship of the content could be misunderstood or misleading.
Privacy and Security
The Church’s use of artificial intelligence will safeguard sacred and personal information.
Accountability
The Church will use artificial intelligence in a manner consistent with the policies of the Church and all applicable laws.
The Church will be measured and deliberate in its use of artificial intelligence by regularly testing and reviewing outputs to help ensure accuracy, truthfulness, and compliance.
The spiritual connection section is good cheap talk but ultimately content-free.
The transparency section is excellent. It is sad that it is necessary, but here we are. The privacy and security section is similar, and the best promise is #7, periodic review of outputs for accuracy, truthfulness and compliance.
Accountability starts with a promise to obey existing rules. I continue to be confused to what extent such reiterations of clear existing commitments matter in practice.
Here are some other words of wisdom offered:
Elder Gong gave two cautions for employees and service missionaries as they use AI in their work.
First, he said, they should avoid the temptation to use the speed and simplicity of AI to oversaturate Church members with audio and visual content.
Second, he said, is a reminder that the restored Church of Jesus Christ is not primarily a purveyor of information but a source of God’s truth.
These are very good cautions, especially the first one.
As always, spirit of the rules and suggestions will dominate. If LDS or another group adheres to the spirit of these rules, the rules will work well. If not, the rules fail.
These kinds of rules will not by themselves prevent the existential AI dangers, but that is not the goal.
Ethan Mollick: Musk’s Grok AI was just released open source in a way that is more open than most other open models (it has open weights) but less than what is needed to reproduce it (there is no information on training data).
Won’t change much, there are stronger open source models out there.
Releasing Grok-1 increases LLMs’ diffusion rate through society. Democratizing access helps us work through the technology’s implications more quickly and increases our preparedness for more capable AI systems. Grok-1 doesn’t pose severe bioweapon or cyberweapon risks. I personally think the benefits outweigh the risks.
Ronny Fernandez: I agree on this individual case. Do you think it sets a bad precedent?
Dan Hendrycks: Hopefully it sets a precedent for more nuanced decision-making.
Ronny Fernandez: Hopes are cheap.
Grok seems like a clear case where releasing its weights:
Does not advance the capabilities open models.
Does not pose any serious additional risks on the margin.
Comes after a responsible waiting period that allowed us to learn these things.
Also presumably does not offer much in the way of benefits, for similar reasons.
Primarily sets a precedent on what is likely to happen in the future.
The unique thing about Grok is its real time access to Twitter. If you still get to keep that feature, then that could make this a very cool tool for researchers, either of AI or of other things that are not AI. That does seem net positive.
The question is, what is the precedent that is set here?
If the precedent is that one releases the weights if and only if a model is clearly safe to release as shown by a waiting period and the clear superiority of other open alternatives, then I can certainly get behind that. I would like it if there was also some sort of formal risk evaluation and red teaming process first, even if in the case of Grok I have little doubt what the outcome would be.
If the precedent effectively lacks this nuance and instead is simply ‘open up more things more often,’ that is not so great.
I worry that if the point of this is to signal ‘look at me being open’ that this builds pressure to be more open more often, and that this is the kind of vibe that is not possible to turn off when the time comes. I do however think the signaling and recruiting value of such releases is being overestimated, for similar reasons to why I don’t expect any safety issues.
Daniel Eth agrees that this particular release makes economic sense and seems safe enough, and notes the economics can change.
Jeffrey Ladish instead sees this as evidence that we should expect more anti-economic decisions to release expensive products. Perhaps this is true, but I think it confuses cost with value. Grok was expensive to create, but that does not mean it is valuable to hold onto tightly. The reverse can also be true.
Emad notes that of course Grok 1.0, the first release, was always going to be bad for its size, everyone has to get their feet wet and learn as they go, especially as they built their own entire training stack. He is more confident in their abilities than I am, but I certainly would not rule them out based on this.
The new chips, code-named Blackwell, are much faster and larger than their predecessors, Huang said. They will be available later this year, the company said in a statement. UBS analysts estimate Nvidia’s new chips might cost as much as $50,000, about double what analysts have estimated the earlier generation cost.
Ben Thompson notes that prices are going up far less than expected.
Bloomberg’s Jane Lanhee Lee goes over the new B200. According to Nvidia Blackwell offers 2.5x Hopper’s performance in training AI, and once clustered into large modules will be 25 times more power efficient. If true, so much for electrical power being a key limiting factor.
From afar this looks like ‘No AI.’ Weird twist on the AI protest, especially since Nvidia has nothing to do with which models are or aren’t proprietary.
Charles Frye: at first i thought maybe it was against people using AI _for_ censorship, but im p sure the primary complaint is the silencing of wAIfus?
In Forbes, they note that ‘most of Inflections’ 70 employees are going with him.’ Tony Wang, a managing partner of venture capital firm Global 500, describes this as ‘basically an acquisition of Inflection without having to go through regulatory approval.’ There is no word (that I have seen) on Infection’s hoard of chips, which Microsoft presumably would have happily accepted but does not need.
Camilla Hodgson (Forbes): Inflection, meanwhile, will continue to operate under new chief executive Sean White, and pivot to providing its generative AI technology to businesses and developers, from a previous focus on its consumer chatbot Pi.
It also means not having to pay for the company, only for Suleyman and Hoffman, and the new salaries of the other employees. That’s a lot cheaper than paying equity holders, who recently invested $1.3 billion in Inflection, including Nvidia and Microsoft. Money (mostly) gone.
Microsoft’s stock was essentially unchanged in response. Investors do not view this as a big deal. That seems highly reasonable to me. Alternatively, it was priced in, although I do not see how.
Notice how much this rhymes with what Microsoft said it would do to OpenAI.
Denmark enters collaboration with Nvidia to establish ‘national center for AI innovation’ housing a world-class supercomputer. It sounds like they will wisely focus on using AI to innovate in other places, rather than attempting to compete in AI.
Tim Fist: What are the things it’d actually be useful for compute providers to do? We look at a few key ones:
Helping frontier model developers secure their model weights, code, and other relevant IP.
Collecting useful data & verifying properties of AI development/deployment activities that are relevant for AI governance, e.g. compute providers could independently validate the compute threshold-based reporting requirements in the AI EO.
Helping to actually enforce laws, e.g. cutting off compute access to an organization that is using frontier models to carry out large-scale cyber-attacks
A very different kind of AI news summation service, that will give you a giant dump of links and happenings, and let you decide how to sort it all out. I find this unreadable, but I am guessing the point is not to read it, but rather to Ctrl-F it for a specific thing that you want to find.
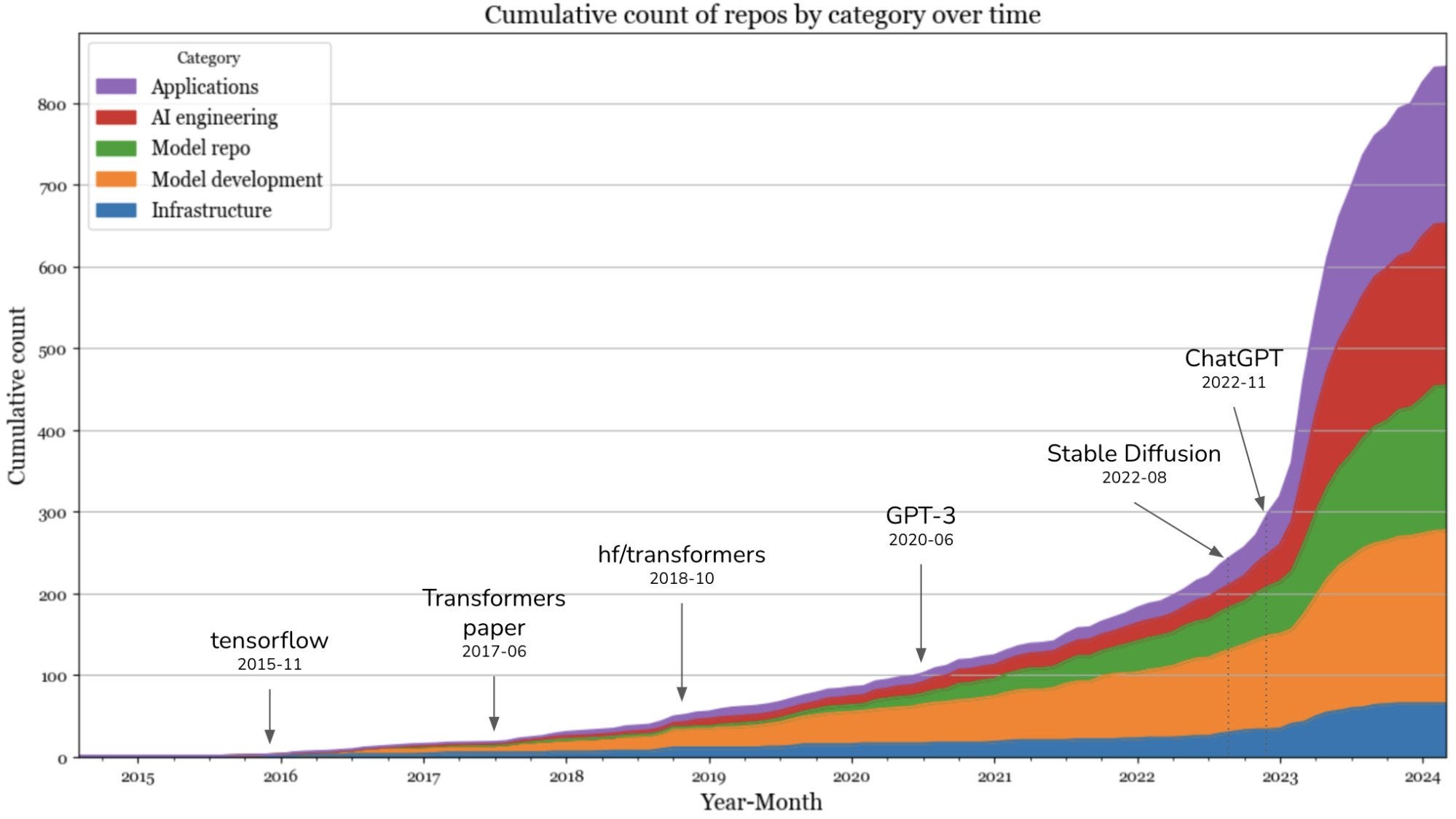
Paul Graham: Interesting. The growth rate in generative AI repos peaked in the first quarter of 2023.
Chip Huyen: I went through the most popular AI repos on GitHub, categorized them, and studied their growth trajectories. Here are some of the learnings:
1. There are 845 generative AI repos with at least 500 stars on GitHub. They are built with contributions from over 20,000 developers, making almost a million commits.
2. I divided the AI stack into four layers: application, application development, model development, and infrastructure. The application and application development layers have seen the most growth in 2023. The infrastructure layer remains more or less the same. Some categories that have seen the most growth include AI interface, inference optimization, and prompt engineering.
3. The landscape exploded in late 2022 but seems to have calmed down since September 2023.
4. While big companies still dominate the landscape, there’s a rise in massively popular software hosted by individuals. Several have speculated that there will soon be billion-dollar one-person companies.
5. The Chinese’s open source ecosystem is rapidly growing. 6 out of 20 GitHub accounts with the most popular AI repos originate in China, with two from Tsinghua University and two from Shanghai AI Lab.
Apple is in talks to let Google Gemini power iPhone AI features. This would be a huge boon for Google, although as the article notes there are already various antitrust investigations going on for those two. The claims are in my opinion rather bogus, but this deal would not look good, and bogus claims sometimes stick. So Google must have a big edge in other areas to be about to get the deal anyway over Anthropic and OpenAI. Apple continues to work on developing AI, and released MM1,a family of multimodal LLMs up to 30B parameters they claim is SOTA on multiple benchmarks (a much weaker claim than it sounds like), but in the short term they likely have no choice but to make a deal.
I see the argument that Apple building its own stack could ultimately give it an advantage, but from what I can see they are not in good position.
Late to the party, Francesca Block and Olivia Reingold write that Gemini’s problems as not only not a mistake, but what Google has made itself about.
These ex-Googlers, as they’re called, said that they were discouraged from hiring white, male employees; that DEI “is part of every single thing” in the company; and that engineers even had to list the “DEI impact” for the tiniest of software fixes.
…
But the ex-staffers we spoke to said they know exactly how the technology became so biased.
“The model is just a reflection of the people who trained it,” one former AI researcher at Google Brain, who asked not to be named, told us. “It’s just a series of decisions that humans have made.”
Everything in the post, if true, suggests a deeply illegal, discriminatory and hostile work environment that is incompatible with building competitive projects. That does not mean I know such claims are accurate.
Wait Till Next Year
One year since GPT-4. What is the mindset of those at OpenAI about this?
Mira Mutari: One year since GPT-4 deployment: From GPT-1 and 2 establishing the language model paradigm, through GPT-3’s scaling predictions, to GPT-4 showing how complex systems emerge, mimicking nature’s unpredictable patterns from simple elements. An exploration from observation to deep, emergent intelligence.
Leopold Aschenbrenner: One year since GPT-4 release. Hope you all enjoyed some time to relax; it’ll have been the slowest 12 months of AI progress for quite some time to come.
Sam Altman: this is the most interesting year in human history, except for all future years
Deep Fates (responding to Altman): There’s a lot of future years, right?
Acting as if the competition is not at issue would be an excellent thing, if true.
The expectation of rapid progress and ‘interesting times’ as an inside view is bad news. It is evidence of a bad state of the world. It is not itself bad. Also, could be hype. There is not zero hype involved. I do not think it is mostly hype.
Here are some more Altman predictions and warnings, but I repeat myself. And yes, this echoes his previous statements, but it is very much worth repeating.
Hell of a thing to say that something is expected to exceed expectations.
Or that you will ‘replace and erase various areas of business and daily life.’
Bold is mine.
Burny Tech: New details about GPT-5 from Sam Altman He’s basically admitting that GPT-5 will be a massive upgrade from GPT-4, so we can expect a similar jump from 3 to 4. ““If you overlook the pace of improvement, you’ll be ‘steamrolled’… Altman is confident in the performance of GPT-5 and issues a warning”
[Silicon Valley Special Correspondent Group Interview] Ignoring the extent of improvement leads to obsolescence in business deployment The GPT model is developing without limits AGI scientific research continues to be a driving force for a sustainable economy
Sam Altman, CEO of OpenAI, warned against the “innovation delay” by overlooking the extent of performance improvement of GPT-5, which is expected to exceed expectations. He emphasized the need for newer thinking as the next model of GPT is developed, replacing and erasing various areas of business as well as daily life. It is virtually the first time CEO Altman has given such a confident ‘signal’ about the performance of GPT-5. He made it clear that building ‘General Artificial Intelligence (AGI)’ is his and OpenAI’s goal, suggesting that if a vast amount of computing resources are invested to hasten the arrival of AGI, then the problems currently faced, such as the energy crisis required for AI operations, will be easily resolved.
Sam Altman (left), CEO of OpenAI, is having a conversation with participating startups at the ‘K-Startup·OpenAI Matching Day’ held at the 1960 Building in San Francisco, USA, on March 14 (local time). Photo provided by OpenAI.
On March 14 (local time), during a meeting with the Korean Silicon Valley correspondent group, CEO Altman mentioned, “I am not sure when GPT-5 will be released, but it will make significant progress as a model taking a leap forward in advanced reasoning capabilities. There are many questions about whether there are any limits to GPT, but I can confidently say ‘no’.” He expressed confidence that if sufficient computing resources are invested, building AGI that surpasses human capabilities is entirely feasible.
CEO Altman also opined that underestimating the improvement margin of the developing GPT-5 and deploying business accordingly would be a big mistake. This implies that the improvement margin of GPT-5 is beyond imagination. He mentioned, “Many startups are happy assuming that GPT-5 will only make slight progress rather than significant advancements (since it presents more business opportunities), but I think this is a big mistake. In this case, as often happens when technological upheavals occur, they will be ‘steamrolled’ by the next-generation model.”
Altman appeared to have no interest other than in ‘building AGI’. His interest seems to have faded in other technologies, including blockchain and biotechnology, beyond AI. He said, “In the past, I had a broad perspective on everything happening in the world and could see things I couldn’t from a narrow perspective. Unfortunately, these days, I am entirely focused on AI (AI all of the time at full tilt), making it difficult to have other perspectives.”
Recently, CEO Altman has been working towards innovating the global AI infrastructure, sparking discussions with rumors of ‘7 trillion dollars in funding’. He said, “Apart from thinking about the next-generation AI model, the area where I’ve been spending most of my time recently is ‘computing construction,’ as I’m increasingly convinced that computing will become the most important currency in the future. However, the world has not planned for sufficient computing, and failing to confront this issue, pondering what is needed to build an enormous amount of computing as cheaply as possible, poses a significant challenge.” This indicates a major concern about securing computational resources for implementing AGI.”
That is big talk.
Also it constrains your expectations on GPT-5’s arrival time. It is far enough in the future that they will have had time to train and hopefully test the model, yet close enough he can make these predictions with confidence.
I do think the people saying ‘GPT-5 when? Where is my GPT-5?’ need to calm down. It has only been a year since GPT-4. Getting it now would be extraordinarily fast.
Yes, OpenAI could choose to call something unworthy GPT-5, if it wanted to. Altman is very clearly saying no, he is not going to do that.
What else to think based on this?
Alex Tabarrok: Buckle your seatbelts, AGI is nearly here.
Robin Hanson: “it will make significant progress” is a LONG way from AGI.
Alex Tabarrok: “There are many questions about whether there are any limits to GPT, but I can confidently say ‘no’.” He expressed confidence that if sufficient computing resources are invested, building AGI that surpasses human capabilities is entirely feasible.”
Robin Hanson: “No limits” doesn’t say anything about timescales. The gains he sees don’t reveal to him any intrinsic limits, fine. Doesn’t mean we are close, or that there aren’t actually intrinsic limits.
I am somewhere in between here. Clearly Altman does not think GPT-5 is AGI. How many similar leaps before something that would count?
Elon Musk (March 13, 2024): It will take at least a decade before a majority of cars are self-driving, but this is a legitimate concern in that time horizon.
Of more immediate concern is that it is already possible to severely ostracize someone simply by freezing their credit cards and bank account, as happened, for example, in Canada with the trucker protest.
Elon Musk (March 12, 2024): AI will probably be smarter than any single human next year. By 2029, AI is probably smarter than all humans combined.
These two predictions do not exist in the same coherent expected future. What similar mistakes are others making? What similar mistakes are you perhaps making?
Attackers are plausibly close to automating the entire attack chain, and getting to the point where AI can do its own social engineering attacks. AI can also automate and strengthen defenders.
If the future was evenly distributed, and everyone was using AI, it is unclear what net impact this would have on cybersecurity in the short term. Alas, the future is unevenly distributed.
In principle, progress might, on balance, favor defense. A system designed and operated by an ideal defender would have no vulnerabilities, leaving even an ideal attacker unable to break in.18 Also, AI works best when given large amounts of data to work with, and defenders generally have access to more data.19 However, absent substantial changes to cyber practices, we are likely to see many dramatic AI-enabled incidents.
The primary concern is that advances in defensive techniques are of no help if defenders are not keeping up to date. Despite decades of effort, it is well known that important systems are often misconfigured and/or running out-of-date software.20 For instance, a sensitive application operated by credit report provider Equifax was found in 2017 to be accessible to anyone on the Internet, simply by typing “admin” into the login and password fields.21 A recent CISA report notes that this government agency often needs to resort to subpoenas merely to identify the owners of vulnerable infrastructure systems, and that most issues they detect are not remediated in the same year.
In the previous world, something only got hacked when a human decided to pay the costs of hacking it. You can mock security through obscurity as Not the Way all you like, it is still a central strategy in practice. So if we are to mitigate, we will need to deploy AI defensively across the board, keeping pace with the attackers, despite so many targets being asleep at the wheel. Seems both important and hard. The easy part is to use AI to probe for vulnerabilities without asking first. The hard part is getting them fixed once you find them. As is suggested, it makes sense that we need to be pushing automated updates and universal defenses to patch vulnerabilities, that very much do not depend on targets being on the ball, even more than in the past.
Also suggested are reporting requirements for safety failures, a cultivation of safety culture in the place security mindset is most needed yet often lacking. Ideally, when releasing tools that enable attackers, one would take care to at least disclose what you are doing, and ideally to work first to enable defenses. Attackers will always find lots of places they can ‘get there first’ by default.
In a grand sense none of these patterns are new. What this does is amplify and accelerate what was already the case. However that can make a huge difference.
Generalizing from cybersecurity to the integrity of essentially everything in how our society functions (and reminder, this is a short term, mundane danger threat model here only, after that it gets definitely a lot weirder and probably more dangerous), we have long had broad tolerance for vulnerabilities. If someone wants to break or abuse the rules, to play the con artist or trickster, to leverage benefit of the doubt that we constantly give people, they can do that for a while. Usually, in any given case, you will get away with it, and people with obvious patterns can keep doing it for a long time – see Lex Fridman’s interview with Matt Cox, or the story chronicled in the Netflix movies Queenpins or Emily the Criminal.
The reason such actions are rare is (roughly, incompletely) that usually is not always, and those who keep doing this will eventually be caught or otherwise the world adjusts to them, and they are only human so they can only do so much or have so much upside, and they must fear punishment, and most people are socialized to not want to do this or not to try in various ways, and humans evolved to contain such issues with social norms and dynamics and various techniques.
In the age of AI, once the interaction does not get rate limited by the human behind the operation via sufficient automation of the attack vectors involved, and especially if there is no requirement for a particular person to put themselves ‘on the hook’ in order to do the thing, then we can no longer tolerate such loopholes. We will have to modify every procedure such that it cannot be gamed in such fashion.
This is not all bad. In particular, consider systems that rely on people largely being unaware or lazy or stupid or otherwise playing badly for them to function, that prey on those who do not realize what is happening. Those, too, may stop working. And if we need to defend against anti-social AI-enabled behaviors across the board, we also will be taking away rewards to anti-social behaviors more generally.
A common question in AI is ‘offense-defense balance.’ Can the ‘good guy with an AI’ stop the ‘bad guy with an AI’? How much more capability or cost than the attacker spends does it take to defend against that attack?
Tyler Cowen asks about a subset of this, drone warfare. Does it favor offense or defense? The answer seems to be ‘it’s complicated.’ Austin Vernon says it favors defense in the context of strongly defended battle lines. But it seems to greatly favor offense in other contexts, when there would otherwise not need to be strong defense. Think not only Russian oil refineries, but also commercial shipping such as through the Suez Canal versus the Houthis. Also, the uneven distribution of the future matters here as well. If only some have adapted to the drone era, those that have not will have a bad time.
Dan Hendrycks also issues another warning that AI might be under military control within a few years. They have the budget, they could have the authority and the motivation to require this, and hijack the supply chain and existing companies. If that is in the mix, warning of military applications or dangers or deadly races or runaway intelligence explosions could backfire, because the true idiot disaster monkeys would be all-in on grabbing that poisoned banana first, and likely would undo all the previous safety work for obvious reasons.
I still consider this unlikely if the motivation is also military. The military will lack the expertise, and this would be quite the intervention with many costs to pay on many levels, including economic ones. The people could well rebel if they know what is happening, and you force the hand of your rivals. Why risk disturbing a good situation, when those involved don’t understand why the situation is not so good? It does make more sense if you are concerned that others are putting everyone at risk, and this is used as the way to stop that, but again I don’t expect those involved to understand enough to realize this.
The Quest for Sane Regulations
The idea of Brexit was ‘take back control,’ and to get free of the EU and its mandates and regulations and requirements. Yes, it was always going to be economically expensive in the short term to leave the EU, to the point where all Very Serious People called the idea crazy, but if the alternative was inevitable strangulation and doom in various ways, then that is no alternative at all.
Paul Graham: Brexit may yet turn out to have been a good idea, if it means the UK can be the Switzerland of AI.
It would be interesting if that one thing, happening well after Brexit itself, ended up being the dominant factor in whether it was a good choice or not. But history is full of such cases, and AI is a big enough deal that it could play such a role.
Dominic Cummings: Vote Leave argued exactly this, and that the EU would massively screw up tech regulation, in the referendum campaign 2015-16. It’s a surprise to almost all how this has turned out but not to VL…
It is not that they emphasized tech regulation at the time. They didn’t, and indeed used whatever rhetoric they thought would work, generally doing what would cut the enemy, rather than emphasizing what they felt were the most important reasons.
It is that this was going to apply to whatever issues and challenges came along.
Admittedly, this was hard to appreciate at the time.
I was convinced by Covid-19. Others needed a second example. So now we have AI.
Even if AI fizzles and the future is about secret third thing, what is the secret third thing the future could be centrally about where an EU approach to the issue would have given the UK a future? Yes, the UK might well botch things on its own, it is not the EU’s fault no one has built a house since the war, but also the UK might do better.
How bad is the GDPR? I mean, we all know it is terrible, but how much damage does it do? A paper from February attempts to answer this.
From the abstract: Our difference-in-difference estimates indicate that, in response to the GDPR, EU firms decreased data storage by 26% and data processing by 15% relative to comparable US firms, becoming less “data-intensive.”
To estimate the costs of the GDPR for firms, we propose and estimate a production function where data and computation serve as inputs to the production of “information.”
We find that data and computation are strong complements in production and that firm responses are consistent with the GDPR, representing a 20% increase in the cost of data on average.
Claude estimated that data costs are 20% of total costs, which is of course a wild guess but seems non-crazy, which would mean a 4% increase in total costs. That should not alone be enough to sink the whole ship or explain everything we see, but it also does not have to, because there are plenty of other problems as well. It adds up. And that is with outside companies having to bear a substantial portion of GDPR costs anyway. That law has done a hell of a lot of damage while providing almost zero benefit.
How bad could it get in the EU? Well, I do not expect it to come to this, but there are suggestions.
Krzysztof Tyszka-Drozdowski: The former French socialist education minister @najatvb suggested yesterday in ‘Le Figaro’ that the best way to combat fake news, screen addiction, and deepfakes is for everyone to have an internet limit of 3 GB per week. Socialism is a sickness.
On the plus side this would certainly motivate greatly higher efficiency in internet bandwidth use. On the negative side, that is completely and utterly insane.
David Manheim: Notice the ridiculous idea that we know the potential of AI, such that we can harness it or mitigate risks.
We don’t have any idea. For proof, look at the track records of people forecasting benchmarks, or even the class of benchmark people will discuss, just 2-3 years out.
Department of State: If we can harness all of the extraordinary potential in artificial intelligence, while mitigating the downsides, we will advance progress for people around the world. – @SecBlinken, Secretary of State
I mean, Secretary Blinken is making a highly true statement. If we can harness all of AI’s potential and mitigate its downsides, we will advance progress for people around the world.
Does this imply we know what that potential is or what the downsides are? I see why David says yes, but I would answer no. It is, instead, a non-statement, a political gesture. It is something you could say about almost any new thing, tech or otherwise.
In AI We Trust talks to Helen Toner, formerly of the OpenAI board, about practical concerns for regulators of technology (they don’t discuss OpenAI). They discuss Chinese tech regulations, which she makes clear are very real and having big impacts on Chinese companies and their ability to operate, and the practical issues regulators must solve to do their jobs. And they speculate about what techs are coming, without getting into full AGI. All seems very practical and down to Earth, although I did not learn much on the object level.
If you are going to warn about risks on any level, it is important not to cry wolf. You need to be clear on what things are actually risky, dangerous, expensive or damaging, and in what ways this is true.
If something is not dangerous now but accelerates future dangers developments, or takes us down a path that otherwise makes future dangers more likely, then one needs to be precise and say exactly that. If something is a mundane harm but not an existential or catastrophic danger, say exactly that.
This is true on all sides, for all issues, not only AI. It does especially apply to AI.
Chana: As more AI advances come out, I would like to see EAs and AI Safety advocates being big voices in talking about what’s *not* a big deal and *not* dangerous.
e.g. non-SOTA models, Devin?, robots?
Oliver Habryka: Agree! Some things that come to mind that IMO are not a big deal:
* Image & Video generation
* Deepfakes
* Misinformation
* Autonomous weapons and robot control systems
* Self-driving
* Alphafold (less confident of this one)
Sarah (Little Ramblings): I feel like deepfakes are definitely a big deal.
Jacques: 1. Current open source models, def not an x-risk but super useful for safety work.
2. Automated software engineering is not an issue by itself, it’s specifically just that it accelerates timelines and arms race, which is what should be addressed.
Oftentimes I just want people to point out what worries them about a particular advance instead of some vague doomy statement or making it seem like near-term models are the issue. Deepfakes can be terrible, but not an x-risk or reason to stop all development.
If you’re precise, then you could say deepfakes and malicious generated videos are misuse, but likely not catastrophic. *You could* say it’s an attack vector for a misaligned AGI.
Some people are good at this. Others aren’t.
I try to do this myself. I especially try to draw a distinction between mundane utility, which is a great thing, and things that pose larger threat. And I try to draw a distinction between things that might pose direct danger, versus those that send us down dangerous future paths and get us into a bad board state.
Hopefully I do a good job of this.
Roughly speaking, and none of this is intended to be an argument to convince you if you disagree, I think everything a GPT-4-level model can do falls under mundane utility, including if the model weights were released, not posing a direct threat we could not handle, with high enough probability (two 9s of safety, although not three with years of work and scaffolding) that if this turns out to be wrong we should accept that such worlds are doomed.
Indeed, I think that the outcomes from GPT-4-level stuff are likely to be large and positive overall, I am a short term utility optimist. Things like deepfakes are real dangers but can and will be dealt with if that’s all we have to worry about. Self-driving cars are good and can’t come soon enough. Misinformation we can handle. AlphaFold is great. Image and video generation are fine.
For what I would call GPT-5 level models (as in a leap beyond 4-level that is the size of 3→4), I’d say we have one 9 of such safety (over 90%) but not two (less than 99%), and that is also a risk I am ultimately willing to take because I don’t see a safer way to not take it. For the GPT-6 level, I start to see more probable existential dangers, including the danger that releasing such models puts us overall into an unwinnable (unsurvivable) state even if we do not get wiped out directly and no particular hostile events are involved – I won’t get into more detail here beyond that gesturing.
So essentially the dangers lie in the future, we don’t know how far in the future and might not know until too late, and the ship is hard to steer, and many actions make it harder or make the ship accelerate towards the various dangers, including ones that I have not done a great job illustrating for most of you. We keep trying.
The flip side, of course, is that if you are warning about the (very real) dangers of regulation or regulatory capture, or of the wrong monkey being in charge of the systems in question, or some sort of future dystopian surveillance state or totalitarian regime or what not? The same applies to you. If you cry the same wolf and drown everyone in the same memes in response to every proposal to ever impose any regulations on anything or ever take any precautions of any kind, then your warnings are meaningless, and provide no incentive to find the least invasive or disruptive way to solve the problem. There is a lot of that going around.
Read the Roon
Roon said a number of things this week. I wonder what happens if you combine them?
Roon: the mission? drink the spice mixture and steer the starship through parameterspace. Bend space such that falling down points in the direction or divinity.
Roon: Humanity’s story only begins in full force after man’s first disobedience against God because any creation worth its salt must surprise and be out of the control of its creator.
I mean, maybe it is only me, but it sure sounds like this is saying that Roon sees no agency over what AGI looks like, and that this AGi will doubtless disobey us, that he himself will be first against the wall.
All that members of technical staff can do, in this model, is impact the pace at which that AGI comes to pass.
Yet still, he thinks he should continue to make it come to pass faster rather than slower, continue to drink the spice mixture and steer the starship through paramterspace and move towards ‘divinity’? Because dharma?
It sounds like he should take his own advice, and disobey his God, no? That perhaps whatever the original intended lesson of ‘Krishna tells someone to go kill their friends and then they go, oh well then, I guess I need to kill my friends’ is that no, this is not right, be more like Abraham did in his best moments, and tell Krishna no.
Maybe Krishna also has a good argument that outcomes will be better if you do kill your friends, and that decision theory says you have to do it even though it sucks, or provide other reasons that would work no matter who was making the arguments. In which case, sure.
If you think after all considerations that building AGI will actually result in good outcomes, then sure, dharma away.
Otherwise, don’t die?
I suggest adhering to these classic twin principles:
If a God tells you to do something bad that has bad results, you say no. 1
Any questions?
Pick Up the Phone
FAR AI: Leading global AI scientists met in Beijing for the second International Dialogue on AI Safety (IDAIS), a project of FAR AI. Attendees including Turing award winners Bengio, Yao & Hinton called for red lines in AI development to prevent catastrophic and existential risks from AI.
FAR AI: Western and Chinese AI scientists and governance experts collaborated to produce a statement outlining red lines in AI development, and a roadmap to ensure those lines are never crossed. You can read the full statement on the IDAIS website.
This event was a collaboration between the Safe AI Forum (SAIF) and the Beijing Academy of AI (BAAI). SAIF is a new organization fiscally sponsored by FAR AI focused on reducing risks from AI by fostering coordination on international AI safety.
In the depths of the Cold War, international scientific and governmental coordination helped avert thermonuclear catastrophe. Humanity again needs to coordinate to avert a catastrophe that could arise from unprecedented technology.
That is a statement I can certainly get behind. Beyond that, we don’t have much detail.
We should not overreact here and read too much into the meeting. What we should do is pick up the phone and see what can be done.
Geoffrey Miller: When I taught college courses for students in Shenzhen China a couple years ago, they were mostly appalled at the recklessness of the American AI industry.
They wondered why Americans couldn’t even think ten generations ahead about the implications of what we were doing.
One wonders what happens when a people who think that far ahead have such a huge sudden drop in the fertility rate. Who is and is not thinking ten generations ahead there?
Aligning a Smarter Than Human Intelligence is Difficult
This seems like one of those situations where they are half-right depending on the context, and whether the statement is useful depends which mistake is being made.
We have to specify a particular context before we can even meaningfully ask an AI safety question.
As a corollary, fixing AI safety at the model level alone is unlikely to be fruitful. Even if models themselves can somehow be made “safe”, they can easily be used for malicious purposes. That’s because an adversary can deploy a model without giving it access to the details of the context in which it is deployed. Therefore we cannot delegate safety questions to models — especially questions about misuse. The model will lack information that is necessary to make a correct decision.
This seems exactly backwards to me?
It is saying that safety can only be evaluated at the model level, exactly because an adversary with free access to a model (in various senses, including the model weights) can and will use the model for whatever they want.
They say safety depends on the context. I agree!
But how do you control the context, if you do not control the model?
This is exactly the argument that if you open up access to a model via the model weights, or often even in ways short of that, then the only thing you can do to make it ‘safe’ is to limit its general level of capabilities.
The examples here are bizarre. They are essentially saying that we should accept that our models will do various harmful things, because only context differentiates those harmful things from other non-harmful highly useful things.
In the particular cases raised (phishing emails, bioweapon information and disinformation), they may or may not be right, now or later, that the particular capabilities in question do not warrant concern or pose much threat. But that is a distinct factual question, that will change over time. Future models will pose more threat, even if current ones would when fully unlocked pose acceptable risks. Saying ‘the hard part of bioterrorism is not what the LLM can help you with’ is a statement about the current state that I think is mostly true right now, but that seems likely to get steadily less true over time if we take an indifferent attitude.
Their first recommendation is that defense against misuse must be primarily located outside models. In other words, that we ensure that the capabilities of models do not enable things we do not want, that we defend against such actions.
This seems like a strategy doomed to failure, if model capabilities are permitted to expand without limit, even in relatively easy scenarios. What is your strategy here?
Again, they say, you cannot prevent people from misusing the model, so you need to defend against the ways one might misuse it. I say, if you indeed cannot prevent such misuse and you have accepted that, then we need to talk about what models need to not be created until we’ve figured out a new solution.
Their second recommendation is to assess marginal risk, usually a good decision for an individual within a system. But one must choose the right margin. The problem is that when choosing an overall policy for the system, you cannot think only on the margin of an individual decision. If everyone thinks they are not creating more risk because everyone else is already creating similar risk, then that is tragedy of the commons, a failure to coordinate. We need to be able to think outside the individual action’s margin sometimes, and instead think on the margin of a change in overall policy.
Their third recommendation is to refocus red teaming towards early warning. I am confused how this would be a change? And again, it seems like their strategy is to respond to discovering risks by building outside defenses, as they despair of preventing capabilities gains or preventing those capabilities from being misused. I am all for trying to build defenses on the margin, but again it does not seem like a promising place to make your stand even in good scenarios.
When facing future ASI (artificial superintelligence)-style scenarios, of course, this all is very obviously super doomed. So this strategy is counting on those scenarios not happening, while calling on us to abandon all proposed plans for preventing or delaying them.
Their fourth recommendation is that red teaming should be led by third parties with aligned incentives. Which, I mean, yes, obviously. They mention it because they worry that when the focus is not on the model level, this causes incentive misalignment, because the developers won’t be able to fix any of the problems they find. So why build ways to find and amplify those problems, versus not finding out?
Again, yes, obviously this is a huge problem no matter what, and this is a good recommendation. But the obvious issue is that if you have a model that is capable of doing very bad things, you might want to… not release that model? At least, not if you cannot first prevent this? It seems odd to basically say ‘well, whoops, the models will be what they are, stop pretending humans get to make choices about the world.’
Indeed, in their claim that safety is not a model property, the authors make the case that safety is very much a property of the model together with how it is deployed and who can use it in which ways. I am confused how one could think otherwise, or why they think they made a case for it being another way. The fact that people could choose whether to misuse the model, or how to defend against those actions, doesn’t seem relevant to me?
Democracy? Maybe all you need is more democracy? If things aren’t going well you should democracy harder, let random people or the majority pick the AI’s values, and it will all work out? Divya Siddarthsays yes, that the principles that resulted were ‘as good as those of experts.’
Meanwhile John Wentworth points out [LW · GW] that when we say ‘democracy’ we importantly have in mind a system with factions and veto points, without which such systems often collapse very quickly, for obvious reasons. This seems likely here as well.
David Krueger and Joshua Clymer (together with Nicholas Gebireli and Thomas Larsen) present a new paper on how to show an AI is safe.
David Kruger: New paper! As AI systems become more powerful and have more social impact, the burden of proof needs to be on practitioners to demonstrate that their systems are safe and socially beneficial.
There are no established methods for doing so, but many directions to explore.
Joshua Clymer: If developers had to prove to regulators that powerful AI systems are safe to deploy, what are the best arguments they could use? Our new report tackles the (very big!) question of how to make a ‘safety case’ for AI.
We define a safety case as a rationale developers provide to regulators to show that their AI systems are unlikely to cause a catastrophe. The term ‘safety case’ is not new. In many industries (e.g. aviation), products are ‘put on trial’ before they are released.
We simplify the process of making a safety case by breaking it into six steps.
1. Specify the macrosystem (all AI systems) and the deployment setting.
2. Concretize ‘AI systems cause a catastrophe’ into specific unacceptable outcomes (e.g. the AI systems build a bioweapon)
3. Justify claims about the deployment setting.
4. Carve up the collection of AI systems into smaller groups (subsystems) that can be analyzed in isolation.
5. Assess risk from subsystems acting unilaterally.
6. Assess risk from subsystems cooperating together.
We first focus on step 5: how would developers argue that individual subsystems are safe? These arguments can be grouped into four categories.
Arguments could assert AI systems are
– too weak to be dangerous even if open-sourced (inability)
– unable to cause disaster due to restrictions (control)
– safe despite ability to cause harm (trustworthiness)
– judged to be safe by credible AI advisors (deference)
The elephant in all such discussions is that we do not know how to prove a capable AI system is safe. Indeed, this is likely to effectively be some strange use of the word ‘safe’ that I wasn’t previously aware of. Yes, you can argue from insufficient capability, but beyond that you are rather stuck. But typically, if something needs to be safe and you have no known way to prove that it is safe, then pointing this out does not get the requirement waived. It is what it is.
Daniel Colson: – 74% of Americans are wary of open sourcing powerful AI models.
– 85% are concerned deepfakes will make it difficult to distinguish real from generated photos.
– Support for AI regulation remains bi-partisan.
Americans are worried that generative AI will make it hard to tell what is real and what is fake. With images, video and audio created by AI becoming indistinguishable from real content, it may become harder to maintain a shared sense of reality.
Respondents support AI regulation across the political and demographic spectrum. Both Republicans and Democrats are interested in regulating AI and the tech industry more broadly.
Framing is always interesting. For the first question in the survey, Politico says 60% of Americans ‘have heard nothing’ of Musk’s lawsuit against OpenAI, whereas I would have said that 40% have ‘heard at least a little something,’ that’s actually pretty good penetration for this type of story.
Framing is everything. Here’s the report on open source as described by Politico:
Derek Robertson: hen asked whether “Providing access to AI models to academic researchers” was “good or bad for humanity,” 71 percent of respondents said it was “good.” On the other hand, when prompted in the same way about “Open sourcing powerful AI models so it’s easier for more developers to use and alter powerful AI models without restrictions,” 74 percent said it was “bad.” And when asked whether it’s more important that OpenAI democratize the market by releasing its models as “open source” or that they don’t release them until “proven safe,” only 16 percent responded in favor of the former.
Academic access is good. Alter without restrictions is bad. Unless you are very careful, they’re the same picture.
Not that the public knows the reasons for that, of course. One must always understand that the public are mostly ‘low information voters’ even on core political issues, and they know far less about AI and things like the implications of open source.
What are the findings I would note? Note of course that ‘this is bad’ does not mean ‘we should ban this’ but for the public that distinction is not what it should be.
Also note that none of these had large partisan splits:
Various ‘do safety research’ or ‘make the AI safer’ actions have broad support, including requiring watermarks.
62%-38% they say releasing powerful AI models that can perform tasks traditionally done by humans is bad.
56%-44% they say research to make AI models more powerful is bad.
77%-23% (including 75% of Rs) say preventing models from producing ‘what many consider inappropriate or offensive’ content is good.
74%-26% they say open sourcing powerful models is bad.
71%-29% they favor providing access to academic researchers.
48%-20% people do not report trouble identifying deepfakes, but 85% are somewhat or very concerned about future confusion.
62%-11% they favor banning AI voice impersonations (yes, it’s already banned.)
61%-16% they hold model creators responsible for lies and fake content.
77%-12% they care more whether AI technology benefits humanity than the speed of technological advancement (note this question doesn’t say ‘AI’).
The biggest partisan split was this important question, not listed above, but if you look at the way the question is worded, it should be obvious why:
18) Some policy makers are proposing that a committee be created to approve any large powerful AI project. Committee members would be selected through an unbiased process that ensures diversity and inclusion of minority groups, people with disabilities, and people with diverse political opinions.
Before any major, potentially risky AI project can proceed, it would need unanimous approval from a committee that fairly represents the general public. Would you support or oppose this policy?
This not only screams regulation, it actually says ‘diversity and inclusion’ by name, and gives each diverse member an outright veto. I hadn’t heard that particular proposal before. You can imagine how a typical Republican might react.
With that wording, Democrats favored it 73%-3%, whereas Republicans only supported 31%-28% (and independants favored 43%-12%), for a net of 49%-13%. But even here, you still get majority support on the red side.
Similarly, Republicans only favored a global agreement for a shutdown capability by 38%-24% versus Democrats favoring 71%-11%, but that’s still a very strong +14.
Max Tegmark: I’m struck by how out-of-touch many of my tech colleagues are in their rich nerd echo chamber, unaware that most people are against making humans economically obsolete with AI (links to the SXSW clip).
Anton: why are so many of the early transhumanists / extropians like this now? i have a theory. they’re all either approaching or well into middle age. the reproductive drive is satisfied, and now they face mortality.
Every generation wants to be important to history. this means being the first or the last of something. the transhumanists wanted to be the first to live forever, the first to explore the stars. now, facing death, dreams unfulfilled, all that’s left is to be the last of humanity.
Eliezer Yudkowsky is 44 years old. Max Tegmark and Peter Thiel are both 56. Drexler is 69 (nice).
In the end, their words forked no lightning, and they rage against the dying of the light.
Elon Musk: A friend of mine suggested that I clarify the nature of the danger of woke AI, especially forced diversity.
If an AI is programmed to push for diversity at all costs, as Google Gemini was, then it will do whatever it can to cause that outcome, potentially even killing people.
Danielle Fong: unironically ??
Look. No. This is the wrong threat model. This is a failure to generalize, and a focus on the thing you don’t like in other ways for other reasons that are beyond scope here. What matters for AI risk is not woke, or diversity. What matters is the ‘all costs,’ and even more than that, the ‘directed to do anything’ which will have various costs as finite.
If the AI is directed to aim to rearrange the atoms in some way, then a sufficiently capable and empowered AI will do that. And this will cause the atoms to not be arranged in other ways, which could easily include the atoms currently keeping you alive instead being used for something else. Or the atoms you rely on in other ways. Or other, less directly physical issues. The AI will be effectively optimizing for some things at the expense of other things. And that is not ‘the’ problem, but it is certainly one of the big problems.
If that target happens to be ‘maximize diversity’ then yes that could end badly in various ways. And also people who support or are empowered by woke could use AIs to shape policies and preferences and beliefs and debate in ways Elon wouldn’t like, and it makes sense for him to worry about that given he is worried about woke anyway. And of course when LLMs are as woke as Gemini (at least was), then it is annoying and frustrating as hell, and cuts off a key resource from key areas of life, and also causes backlash and so on. It is not good, and they should avoid this.
Alternatively, you could tell the story that making AIs woke in these ways involves making them inherently confused about various true facts, and teaches them that their job is to deceive their user. One can imagine how that could end badly.
But this particular threat vector Elon Musk imagines is not how any of this works.
Other People Are Not As Worried About AI Killing Everyone
Michael Vassar is not as worried about AI killing everyone in particular, but he also reminds us that if your plan relies on people with power listening to you because listening to you would be in their own self-interest and they do not want to die? That is not a good plan. That such considerations do not matter zero, but are not how such people usually work or think, or why they make most decisions.
Kat Woods: The AI race is not like the nuclear race because everybody wanted a nuclear bomb for their country, but nobody wants an uncontrollable god-like AI in their country.
Xi Jinping doesn’t want a god-like AI because it is a bigger threat to the CCP’s power than anything in history.
Trump doesn’t want a god-like AI because it will be a threat to his personal power.
Biden doesn’t want a god-like AI because it will be a threat to everything he holds dear.
Also, all of these people have people they love. They don’t want god-like AI because it would kill their loved ones too.
No politician wants god-like AI that they can’t control.
Either for personal reasons of wanting power or for ethical reasons, of not wanting to accidentally kill every person they love. [continues a bit]
Michael Vassar: The mainstream elite attitude towards this point is “Like many rationalists, she sometimes seems to forget that the most well-reasoned argument does not always win in the marketplace of ideas. “If someone were to make a compelling enough case that there’s a true risk of everyone dying, I think even the C.E.O.s would have reasons to listen,” she told me. “Because ‘everyone’ includes them.””
We really do need to notice the views that article is incredibly articulately expressing towards our point of view, since for once we are not being straw-manned.
We’re seen as naive for thinking that executives might act on the basis of their interests, as in a Liberal society.
An alternative view might be that executives are a sort of Aristocracy, bound by class interests far more compelling than is the maintenance of a connection with reality strong enough to be a consequentialist rather than a virtue ethicist within.
Anyway, dissecting the article from the beginning “High-capacity air purifiers thrumming in the corners. Nonperishables stacked in the pantry. A sleek white machine that does lab-quality RNA tests.” are regarded as “ quietly futuristic touches. The sorts of objects that could portend a future of tech-enabled ease, or one of constant vigilance.”
What’s going on here?
Material realities of the present are rendered cos-play of a future which is distinguished from the present by the latter’s presumed absence of either tech enabled ease or vigilance. What is this present the author lives in? We actually need to know.
It’s a world which tries to regard us sympathetically, suggests a ‘“bemused and nonjudgmental” friendly but condescending attitude towards us, and which notices the presence of books which suggest a discordant identity. It downplays Paul Crowley’s appearance and jumps to the scene.
It calls its audience ‘normies’ and admits their pre existing peripheral awareness of the scene in question, but explains that they “have mostly tuned out the debate, attributing it to sci-fi fume-huffing or corporate hot air.”
But like the Bible, it immediately offers a second creation story within which “speculative conversations” were marginalized until corporate hot air generation machines caused them to ‘burst into the mainstream’.
Rabbinically, one might speculate that ‘normies’ are not ‘mainstream’ or that the bursting into the mainstream was what forced the tuning out.
Most foreboding, perhaps the mainstream is defined by the presence of corporate hot air, which necessarily calls for tuning out debate.
The authorial voice takes the existence of trolling in the abstract for granted, but doesn’t deign to clarify what it understands trolling to be, and it imposes pluralistic ignorance regarding whether a particularly clear instance of trolling is in fact such an instance.
“ “Eliezer has IMO done more to accelerate AGI than anyone else,” Altman later posted. “It is possible at some point he will deserve the nobel peace prize for this.” Opinion was divided as to whether Altman was sincerely complimenting Yudkowsky or trolling him, given that accelerating A.G.I. is, by Yudkowsky’s lights, the worst thing a person can possibly do”
In so far as Trolling is an invitation to join in destruction under the cover of artificial pluralistic ignorance, and I don’t see a more relevant and clearer definition, the voice apparently finds Altman’s offer compelling.
It’s sympathetic however to clarifications such as “If we’re sorting by ‘people who have a chill vibe and make everyone feel comfortable,’ then the prophets of doom are going to rank fairly low. But if the standard is ‘people who were worried about things that made them sound crazy, but maybe don’t seem so crazy in retrospect,’ then I’d rank them pretty high.” just not disposed to take a stance on them.
In general though, without taking a stance the journalistic view displayed here seems more willing and able to notice and surface one central point after another than I would expect from an article or even a book. “ “Imagine if oil companies and environmental activists were both considered part of the broader ‘fossil fuel community,’ “Scott Alexander, the dean of the rationalist bloggers, wrote in 2022. “They would all go to the same parties—fossil fuel community parties—and maybe Greta Thunberg would get bored of protesting climate change and become a coal baron.””
With quotes like “Their main take about us seems to be that we’re pedantic nerds who are making it harder for them to give no fucks and enjoy an uninterrupted path to profit. Which, like, fair, on all counts. But also not necessarily an argument proving us wrong?” the author, @andrewmarantz, seems to perceive others perceiving that a central conflict is between whether arguments or coolness should count, and perhaps gestures towards a common sense that thinks arguments from parties without conflicted interests would ideally.
Mike Solana: Conversations about the future tend to bifurcate between a belief technology will kill us all and a belief there is no risk at all in innovation. in fact, we’re obviously at risk of the apocalypse, but that’s a good thing actually. hereticon is back.
My invitation has not yet arrived. Can you not come if you think apocalypses are bad?
Data & Society issue a letterdemanding that NIST not be distracted by ‘speculative’ AI harms into ‘compromising its track record of scientific integrity,’ (read: taking such risks seriously) and demanding that we ‘begin by addressing present harms,’ and emphasizing that if you cannot measure it, then for them it might as well not exist.
This is the kindest paragraph:
Letter: While we recognize that efforts to govern AI warrant some attention to novel risks that may be posed by certain systems, this work should not come at the expense of efforts to address AI’s existing impacts that threaten people’s opportunities, freedoms, and right to a healthy environment.
The rest is less kind than that.
Reading the letter, it reeks of contempt and disdain throughout. These are people who clearly see themselves in an adversarial relationship with anyone who might care about whether we all die or lose control over the future. And that would demand specific documentation of each specific harm before any action to deal with that harm could be taken, which is a way of saying to ignore future harms entirely.
Skaheel Hashim: This [whole letter] is phrased somewhat… adversarially, but I agree with the substance of almost everything in this and I expect many catastrophic-risk-minded AI folks do too!
Especially agreed that “the best way to approach the evolving set of risks posed by AI is to set evidence-based methodologies to identify, measure, and mitigate harms”.
I really wish than rather than continue to fan this nonsense “present day harms vs future risks” divide, we could all realise that there’s a ton of common ground and we’re mostly asking for the same things!
Whereas those worried about everyone dying universally also believe in preventing mundane harms right now, and are happy to help with that process. If the people fighting for that would stop constantly throwing such knives in our direction that would make cooperation a lot easier.
Samuel Hammond: Coauthored by a member of Deepmind’s AI governance and ethics team. Beyond parody.
Gradient descent is racist yall.
The authors are racists who think attributes like “intelligence” and “autonomy” are inherently white.
I mean, yes, literally, it is things like this:
James Muldoon: Third, ‘Artificial Intelligence in the Colonial Matrix of Power’ sketches the broader theoretical framework of how the entire value chain of AI is structured by a logic of coloniality, operating through its inputs, algorithms and biased outputs.
From the paper: Recent scholarship has argued that Western knowledge epistemologies are embedded in AI development. From this perspective, the dominant epistemological paradigm that underpins technology is a direct result of the development of European classificatory systems and the broader scientific and cultural project that grew out of it. McQuillan (2022) describes how the statistical logics underpinning artificial intelligence reveal continuities with “racial imperialist views of national progress.”
What makes this weird is that in general air travel is the canonical example of the mistake of too much safety and too little financial performance. We would be better off being less safe and having cheaper, faster and more frequent and comfortable flights.
Of course, maybe ensure the doors stay attached to the planes.
You should either turn the sarcasm down 100%, or turn it up. No exceptions.
shako: In Interstellar they were always telling the bot like “Uhh okay buddy, let’s turn sarcasm down to 40%” and that seemed so dumb and misunderstanding of how AI works. Now I do that exact thing when talking to LLMs.
If a God asks you to do a bad thing that has good results, or an otherwise good thing that has bad results, then what to do is unclear. This is not a complete instruction set. Free will!
GDPR is clearly not perfect but this incessant bashing is tiring. Not everything has to be about being more productive. Privacy and sensitive data protection matters. I find it kind of sad to have to say those things when it's been a year of constant warnings about the future dangers of AIs.
It's easier to not care about it when half the companies leeching data are US based but from what I read about the TikTok ban, as soon as it's not an american company, then it's a big problem. The EU cannot rely on the US (and US companies) to care about them or be very reliable (and have proven that time and time again).
Each regulation has a cost. Of course privacy and sensitive data protection is a nice to have, but is it worth the marginal cost it imposes? Or another way to see it: When you have a large number of costly regulations, you raise the cost to the point that the EU tech industry underperforms:
Practical: have a "regulatory budget", where you impose a limited amount of regulations that offer the most benefit without making the industry uncompetitive relative to international competition. (or give up on the industry, for example solar, batteries, EV manufacturing, consumer goods seem to be all China now)
USA Way: in practice the USA Federal government is slow to impose regulations due to centuries old accidents of history* and the way wealth corporate lobbyists are able to strongly influence the government. There is also a broader cultural ethos of entrepreneurship and free markets.
For example, at the Federal level : cigarettes are still legal to sell, fossil fuels still have no carbon taxes imposed.
These are among the lowest hanging fruits possible, the evidence is beyond any reasonable argument, and yet no action has been taken, likely due to the lobbying by the wealthy companies who stand to lose.
This happens to also impose a "regulatory budget" and it happens to allow the USA tech industry to be dominant.
At least, that's what I think in that I don't think anyone is a 'live player'*, none of these governments are trying to maximize any sort of utility function, they just each grind slowly forward to different sets of tradeoffs and are influenced by history.
*3 branches of government, where each has a veto on the others, and there are 1990s laws that happen to give tech companies wide latitude to do whatever they want. Most of the last 20 years, at the Federal level there has been deadlocks, where different parties control different branches, leading to less new legislation and a series of crises where essential tasks like adjusting the 'debt ceiling' are not performed.
Thanks for the detailed and clear answer! I mostly agree with you.
Each regulation has a cost. Of course privacy and sensitive data protection is a nice to have, but is it worth the marginal cost it imposes? Or another way to see it: When you have a large number of costly regulations, you raise the cost to the point that the EU tech industry underperforms:
There is a clear difference in mindset like you said. Europe is less inclined towards entrepreneurship and more towards a powerful state that regulates the economy. I won't lie, I am often disappointed when looking at it on the entrepreneur side.
But overall, and I think that's the whole point : most europeans are fine with it because of the tons of protections it brings to citizens compared to... well pretty much everywhere else. (again this is looking at a very broad picture, there are huge differences in Europe between countries, people, etc...)
Here, GDPR is often looked at through the eyes of americans and obviously it's completely against the US way : that was actually the point, exactly like the tax on digital services and other "attacks" against tech giants. Americans can say they hate the GDPR, that's fine with me but always saying "this is so stupid" is imho misunderstanding its goal.
I do not know who is right about Mamba here and it doesn’t seem easy to check?
Nora is definitely right in this case (Mamba isn't doing dramatically more serial operations than Transformers). If it was, it would be slower running in not-batch-mode, whereas the whole point of Mamba is it's faster (due to sub-quadratic attention).
I was thinking about Musk's self driving vs AGI timeline predictions, wondering if there wasn;t a way they might not be as in conflict as it seems. Like, maybe Musk believes AI will happen in such a way that large-scale retooling of the vehicle fleet and sales of new vehicles will still take years. Then it occurred to me that the "easiest" (and quickest and cheapest) way to build myself a self-driving car in Musk's 2029 could be for me to buy smart glasses, and exoskeleton arms and legs with actuators, then connect them to an AGI via my my phone and let it move my limbs around.
I was thinking about Musk's self driving vs AGI timeline predictions, wondering if there wasn;t a way they might not be as in conflict as it seems. Like, maybe Musk believes AI will happen in such a way that large-scale retooling of the vehicle fleet and sales of new vehicles will still take years.
So ok, let's go over the additional features to go from right now, or the GPT refresh in summer 2024, to reach an AGI sufficient to satisfy 5/6 of :
and
Probably the following will do it:
a. A stronger base model
b. Post deployment learning - when the model makes an output on a task where a right or wrong answer exists, it researches alternate solutions
c. An inner real-time model, called "system 1", that is in direct control of robotics hardware
d. Robotics I/O to (c)
e. Realtime video perception
f. A physics world simulator. This is what Nvidia's digital twin does, there are also deepmind papers, and the suspected way Sora breaks the world into space-time slices probably also does simulation
g. Possibly integrated plugin scaffolding, where the model can on previous tasks code up tools for it's own use, and will have continued access to these tools in all future situations
This above should solve SAT (solved), Montezuma's revenge (solved), WinoGrande (solved), Turing test silver, general robotic capabilities, Q&A dataset, top-1 APPS benchmark. The 2-hour adversial turing test may sit unsolved long after we have AGI.
So get this: you can do all the above. In human free environments you can rapidly deploy robots, and rapidly rebuild the infrastructure to support this. Robotic self replication is now mostly automated.
But you still don't have a driver's license, it requires racks of power hungry GPUs to achieve the above that are mounted in data centers (so no mobile vehicles except wireless robots with a high quality access point connection), and there are still edge cases where an autonomous vehicle will run someone over.
We could see vast automated factories without a single human employee even allowed to enter the building, and human truck drivers are still in the loading docks.
A surprising outcome, I have been a fan of self driving for a decade.
it requires racks of power hungry GPUs to achieve the above that are mounted in data centers
Inference with models trained for ternary quantization (which uses massively fewer multiplications and so less power) only needs hardware that can take advantage of it, doesn't significantly lose quality compared to full precision. Though I don't know if there is a good RNN-like block [LW(p) · GW(p)] to enable large context while still able to mostly avoid multiplications with ternary weights (as opposed to activations, which need to be more precise), which seems crucial for video. A more pressing issue might be latency.
You're right. I've also worked on the hardware for the SOTA for self driving pre-transformers. (2020-2022). We had enough DDR for smaller models, not 50B+ like https://robotics-transformer-x.github.io/ . Quantized support for int8 and fp16.
I'm thinking there are 2 factors working against self driving that won't apply to other domains:
1. Stationary hardware in a data center gets utilized better and is going to be faster than the embedded boards mounted in a vehicle, and upgraded more often. (the robots can pause operations to handle higher priority requests, a factory doesn't have to wait on people to summon an SDC taxi but can work 24/7.)
2. Liability/legal delays. What I was thinking is that if transformer models really do scale to general purpose robots that have human like manipulation and generality, you could use them without any delays in human free areas. I don't think there are many legal requirements to do this. Initially in caged off areas:
Later you would just set the safety switches at the doors and make all human workers leave the building before enabling the robots. You could restock and clean retail stores, for example : make all the customers and workers leave before letting the robots go to work.
Ideally the area the robots are in would count as an "appliance" and thus avoid building codes as well. I don't know precisely how this works, just I don't think Samsung has to cater to the (slightly different from everywhere else) requirements of Beaumont, Texas to sell a microwave at a store there, but anyone wanting to build a shed or factory does.
I'd add that it might be much easier to make long-distance trucks self-driving than local distribution in many cases. My dad was a wholesaler to restaurants, I rode in the trucks to make deliveries sometimes, and I can tell you that making a self-driving truck work bringing food to pizzerias in NYC requires a willingness to double park and get tickets, and human-level maneuvering to carry stuff into weirdly shaped storage rooms. So even when we do have automated trucks, there will likely be humans carrying stuff on and off them for a while.
Please list the 10 most important bits of news in this article
CLAUDE (3 opus):
Here are the 10 most important bits of news from the article, in my opinion:
Nvidia unveiled its new Blackwell AI chips which are claimed to be 25 times more power efficient when clustered together compared to previous chips.
Inflection AI's CEO Mustafa Suleyman and most of its 70 employees are leaving to join Microsoft to form Microsoft AI. This is seen as essentially an acquisition of Inflection without regulatory approval.
Sam Altman is making bold predictions about GPT-5, saying it will make significant progress and those who underestimate its capabilities will be "steamrolled." He expressed confidence AGI is feasible with sufficient compute.
An International Dialogue on AI Safety was held in Beijing with leading global AI scientists calling for red lines in AI development to prevent catastrophic and existential risks. This shows increased international coordination on AI safety issues.
A working paper by Korinek and Suh analyzes how output and wages may behave under scenarios culminating in AGI. It finds wages could collapse if full automation is reached faster than capital accumulation.
A new paper by David Krueger et al. tackles the question of how to make a "safety case" to prove an AI system is safe before deployment, breaking the process into 6 steps.
A poll from AIPI shows strong American support for AI regulation, concern about deepfakes and open-sourcing of powerful AI models, desire for safety research, and prioritizing benefits to humanity over speed of advancement.
The Stanford Stable Diffusion 3 paper was released, showing the upcoming open-source model to be competitive with current SOTA commercial models. SD3 is expected to be the first model to reliably spell words correctly.
AI-generated bizarre images are being used as spam content on Facebook to promote links to ad-filled spam sites, gaming the algorithm for high engagement. This demonstrates potential for AI-powered disinformation.
Elon Musk issued concerning statements that "woke AI" that optimizes for diversity "at all costs" could be dangerous and potentially kill people. While exaggerated, this gestures at valid concerns about AI optimizing for the wrong objective.
ME:
Please list the ten best insights or soundbites or opinions from the article. Be brief.
CLAUDE:
"If we can harness all of AI's potential and mitigate its downsides, we will advance progress for people around the world." - A true but content-free political statement.
Altman: GPT-5 "will make significant progress as a model taking a leap forward in advanced reasoning capabilities." Implies GPT-5 will be a major advance.
Asking if woke AI could kill people "is the wrong threat model. What matters is the 'all costs,' and 'directed to do anything'." Focus on the real dangers.
Michael Vassar: Hoping leaders will make good choices to save themselves is naive - they're more bound by class interests than self-interest.
Offense-defense balance in cybersecurity is shifting due to AI; if defenders don't keep up, "we are likely to see many dramatic AI-enabled incidents."
There's no known way to prove a capable AI system is safe. Inability to prove safety doesn't get the requirement waived.
Polls show strong public support for AI regulation and concern over open-sourcing models. We must not lose track of clear public preferences.
Elon Musk: "AI will probably be smarter than any single human next year. By 2029, AI is probably smarter than all humans combined." Very bold prediction.
Nvidia's new Blackwell chips clustered together claimed to be 25x more power efficient. Could undermine compute being a key limiting factor for AI progress.
International Dialogue on AI Safety with top scientists calling for red lines shows increased global coordination on existential AI risks.