The memorization-generalization spectrum and learning coefficients
post by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-28T16:53:24.628Z · LW · GW · 0 commentsContents
Reminder and notational fix: “rate-distortion” curves Solomonoff complexity Relationship with free energy and Bayesian learning Relationship between Solomonoff and algorithmic complexity Continuous machines The learning coefficient and circuit efficiency A final note on learnability None No comments
This is part I.5 of the series on “generalization spectra” and SLT. I’ll try to make it readable independently of Part I [LW · GW].
The purpose of this post is to reconceptualize the ideas from the last post in a “more physically principled” (and easier-to-measure) sense, and to connect it more clearly to the specifics of neural nets (such as continuously- rather than discretely- parameterized programs), and to the idea of memorization-generalization tradeoffs. In particular I’ll introduce the core conceptual player in thinking of memorization-generalization “spectra”, which is a parameter I’ll call the learning coefficient (notation borrowed from SLT) at a given precision regime. I’ll explain that this parameter can be thought of as a measure of “circuit efficiency”, and to a first approximation it organizes component processes of a classification neural net into a rigorous “memorization-generalization spectrum”.
Reminder and notational fix: “rate-distortion” curves
Last time I introduced a notion of the “precision-complexity phase diagram”. As Alexander Gietelink Oldenziel [LW · GW] pointed out, this actually has a standard name in information theory: namely, this is the “rate-distortion curve”. As a reminder, the rate-distortion (or "precision-complexity") curve is an (integer-valued) function of a “precision parameter” , called the “distortion parameter” in information theory. Rate distortion is a property of a task (which I’m writing “”, with being the “task-assigned correct output” for an input x), and measures
the algorithmic complexity of a program C(x) that implements the task with at most error.
Here “error” is some measure of how close the program gets to perfect performance (last time we used 1-accuracy). Here we’re ignoring questions of “training data”, as we have been assuming the task is on a finite (but exponentially large) list of inputs, such as length-n strings, and accuracy is measured with respect to the set of all possible inputs. In a more general ML context, we can measure accuracy (or other measurements of error or “distortion”) with respect to a more general distribution on inputs, such as the discrete distribution induced by a finite (and “non-exponential”) list of inputs in a training dataset.
Before moving on to learning coefficients, I’ll refine the definition of the rate distortion curve to be better behaved and more computable in ML contexts. This will involve two things:
- Replacing the unwieldy notion of algorithmic complexity (a minimum over programs) with Solomonoff complexity (a sort of expectation over programs).
- Replacing a discrete notion of error with a continuous notion of error in logistic classification tasks [LW · GW].
Throughout this post, as in the previous one, I’m going to be giving an intuitive / general rather than a proof-oriented / detailed picture. In particular I will systematically be dropping “small” logarithmic factors.
Solomonoff complexity
I’m going to briefly explain a new “information theoretically principled” ways of thinking about complexity, and how it relates to other notions. I’ll call it “Solomonoff complexity” (it’s also sometimes called “entropy”, but I’ll avoid this term because otherwise the physics analogies will overload it). Note that (if I understand correctly), already Kolmogorov thought and wrote about this notion, and Solmonoff was simply the first to study it systematically in an information theory context.

In contrast to the “hard minimization” problem answered by algorithmic complexity, Solomonoff complexity of a task answers the following question:
What is the probability that a random program implements the task ?
Here note that I’m being fuzzy about what algorithmic complexity class C is drawn from. For instance if C is a circuit, what size circuits are we drawing C from? Mostly when asking Solomonoff questions we’ll have an algorithmic complexity class in hand, and be working within it. However in a sense I’ll explain, another valid answer to “what is the specific hard complexity class we’re drawing from” is “BIG”. In order to be a bit more concrete in a brief abstract/ complexity-theoretic discussion of this question, I’m going to operationalize the question as follows:
As the complexity parameter N varies, what is the maximum (or supremum) probability, that a random circuit C of algorithmic complexity N implements ?
For this operationalization, note that we have an obvious lower bound. Namely, assume that is the “hard” complexity of the task : i.e., there exists some circuit C that implements our task. For this choice of complexity parameter then, we know that the probability of a random circuit C implementing our task is at least (we’re literally looking at the probability that we’ve “accidentally” chosen the exact minimal circuit that implements our program). Most notions of complexity behave roughly exponentially, so this probability is (up to “log factors in the exponent”, which we’ll consistently ignore) Thus to put the hard (computer-theoretic) and soft (Solomonoff) complexity measurements in the same “units”, we define the Solmonoff complexity as follows:
The Solomonoff complexity of a task is the logarithm: (Here in order to get a positive value, I flipped the sign in the log-probability and wrote “min” instead of “max”.)
The “m” notation is from the original paper. Note that my definition is different in various ways from Solomonoff’s (in particular, I’m focusing on circuits rather than Turing machines, since circuits are a much more sensible discrete analog of neural nets), but at the level of intuitive generality we’re operating, the difference is academic. I’ll also use the notation
for the corresponding measurement at a fixed “hard” complexity parameter N.
Solomonoff complexity may seem very different from the “hard” complexity, but in many cases they are the same or close. From a “theory” point of view, especially if (as we will do shortly) one thinks either “like a physicist” or “like an information theorist”, variants of Solmonoff complexity tend to behave better and to be nicer to reason about than the “hard” notion of complexity. (See also here [LW · GW] and here [LW · GW].) Note here that it may seem like a “big deal” that I’m allowing this extensive freedom in choosing the length, but up to log factors it turns out this is not that big of a deal. Indeed, for most reasonable operationalizations of “classes of programs” (circuits and the like), one can easily prove the following inequality:
> If N’>N is bounded above by some fixed polynomial in N, then the ratio is bounded above by some polynomial in .
In other words, as N gets bigger, the Solomonoff complexity “only gets better up to log factors”[1].
Relationship with free energy and Bayesian learning
As I mentioned, Solomonoff complexity is related to entropy in physics. Namely, in thermostatics problems (by far the most typical setting in thermodynamics), one encounters the so-called “microcanonical entropy” – this is a function of a single real parameter, namely, energy, and associates to each energy value E the associated entropy measurement, defined as the log probability that your thermodynamics system has energy [2]. In most reasonable settings, it’s easy to prove that this measurement is the same up to logarithmic factors as the free energy (also called the “canonical entropy”). In this context the “error bound” parameter is called temperature. The “canonical” quantity is better-behaved in physics and easier to measure in practice. Since I’m avoiding futzing with small logarithmic terms when possible, I’m going to use the terms “Solomonoff complexity” and “Free energy” interchangeably.
Note that in its free energy version, Solomonoff complexity is closely related to Bayesian learning[3].
Relationship between Solomonoff and algorithmic complexity
I explained above that Solomonoff complexity is bounded below (up to fuzz) by algorithmic complexity. In general, the two quantities are not equal. A key issue (if I understand correctly), is that sometimes the case that an algorithm that is easy to describe by a small Turing machine but quite memory-intensive will have much lower Solomonoff complexity (think of a large circuit implementing a program that says “implement the following memory-intensive program. Use the remaining memory in this circuit as RAM. | # random text”). In practical implementations, also, there might be a difference between looking at the “mininum size of a neural net that learns a task” vs. numerical Solomonoff-like complexity measurements associated to the task. In fact singular learning theory actually provides a nice mathematical “qualitative cartoon” for how the two notions of complexity decouple. Still, in many simple cases (such as the prefix-matching example from the previous post in this series), the two notions of complexity are in fact roughly the same, and they often at least directionally capture the same type of information.
However the more important point is that for the purpose of studying neural nets, Solomonoff complexity is a good model for modeling inductive bias. One way to make this precise is that, if one models SGD in a certain simplified “gradient descent + noise” (so-called “Langevin”) form, it can be proven that the expected loss as a function of “noise level” is the inverse entropy form of the rate-distortion function (i.e. the entropy precision graph). In realistic settings, this interpretation buts up against “learnability” issues such as the “parity learning problem [LW · GW]”, but as a rough conceptual first pass, it’s reasonable to think of Solomonoff complexity as the “correct” inductive bias [LW · GW]. (Also, in later posts we’ll discuss the “local” learning coefficient as a partial solution to issues of learnability in practice.)
For the remainder of this series, we will forget the “hard” notion of algorithmic complexity, and systematically work with quantities related to Solomonoff complexity. This more or less agrees with standard the practice in rate-distortion literature, where the relevant complexity parameter – the rate[4].
Continuous machines
In machine learning, neural nets are continuous programs. Even if they are solving a discrete prediction task such as text prediction, their internal “code” is a bunch of real numbers (“weight matrices”). Since there are infinitely many real numbers, questions of “complexity” for continuous programs have an extra wrinkle. A priori, you could encode the entire text of Hamlet in the digits of a single parameter, and then output all of Hamlet by recursively reading off digits.
Of course in reality, these "continuous" values are encoded by discrete bits on a computer, via 64-bit floats (in complexity-theoretic work, one thinks of the associated “64” parameter as a small “polynomial-in-logarithm sized” value).
In principle, one could just study neural nets information-theoretically as a special kind of discrete program (and this isn’t such a bad point of view). However, the notion of rate-distortion allows us to nicely circumvent such issues. Namely, to avoid “infinite bit complexity” informational explosions, we need to control two parameters: “the bits at the beginning” (so, size of parameters) and the bits at the end (so, precision of float approximations). The “bits at the beginning” can be managed by just assuming that our “fictitious” continuous weight parameters are bounded above (this can be enforced for example by a prior on weights that assigns low probability values to “insanely big” weight parameters). The “bits at the end” can be controlled by assuming that all programs we implement are a “tiny bit noisy”, and add noise on the order of after each operation. In particular, such a program will never be exactly correct, and in thinking about rate-distortion curves we can never access meaningful information about precision scales finer than . In the language of the last post, this is another form of “infrared collapse” – in practice, we’ll never care about it because a bunch of other “infrared collapse”-like issues already happen at much coarser precision scales.
When thinking of continuous machines solving a discrete classification problem, we now have to remember that, even if the “task” is deterministic, the output of any program is stochastic. For most the rest of this series, I’ll model programs as implementing randomness in classification in a “logistic [LW · GW]” sense: namely, our continuous “programs” output logits, which then get converted to a probability distribution on ouptuts.
The learning coefficient and circuit efficiency
We’re finally at a place where we can define the learning coefficient.
Let me start by recalling something from a previous post. Namely, one explanation I gave for logits [LW · GW] is that they very naturally lead to modelling AI programs as a combination of “single-feature circuits” (added on the logit level), which can be interpreted as "independent" predictions about the classification event. If the predictions are indeed independent[5] then error[6] behaves multiplicatively. As I explained, this leads to an extremely reductive, but informative model that aligns with a certain flavor of “classic interpretability” which models prediction as aggregating information from various “feature” circuits like “nose classifiers”, “ear classifiers”, etc.
Under this model, the entire rate-distortion curve reduces to understanding a “spectrum of circuit efficiencies”. In this picture, each possibly learnable circuit has two parameters: its error, (here correctly modeled as the “odds ratio”) and its complexity, (the latter understood in the Solomonoff sense). As a cartoon illustration, imagine that the picture below represents all learnable “information-aggregating” circuits for a particular classification task. Here the y coordinate is the "log-odds", more or less the logarithm of the error parameter, and the complexity is the Solomonoff complexity (we imagine both are measured in some appropriate scale).
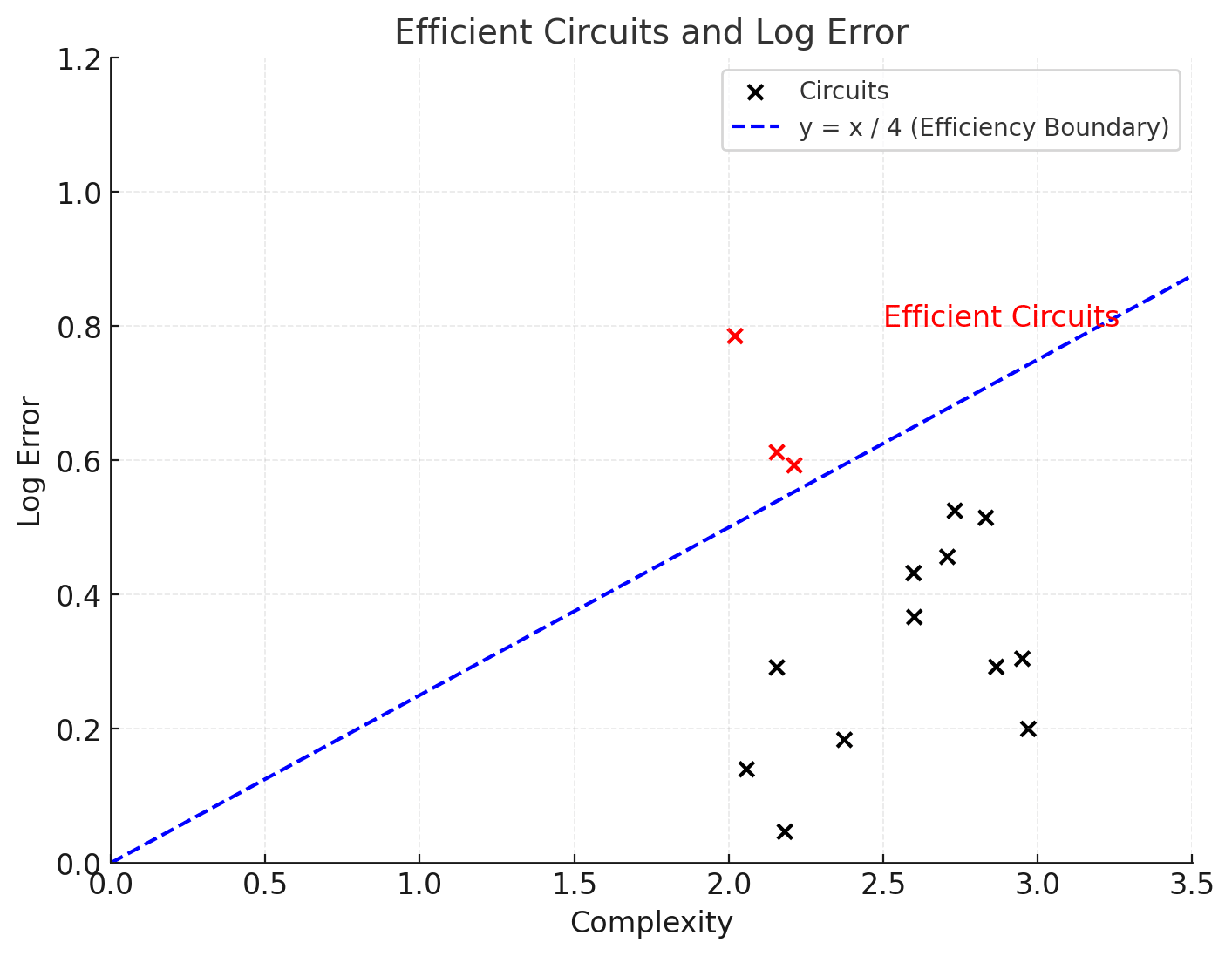
Each concrete program implementing the prediction task now gets to choose a subset of available circuits from this graph. The total (log) error is now the sum of the log errors of the component circuits (this captures the qualitative information-theoretic idea that the more information about the classification task is captured by the circuits, the more likely we are to get the right answer), and the complexity is the sum of the different complexity measures. In other words, we want to choose a subset of points to maximize the sum of their y coordinates while keeping the sum of their x coordinates below some value. Thus in our cartoon, we can imagine that instead of fixing the allowed error for the task, we are instead fixing a “circuit efficiency cutoff” (blue line), corresponding to a cutoff of the quotient In such a cartoon, we see that as we traverse the rate-distortion (or accuracy-complexity) curve from higher to lower error, the algorithm being executed starts out by choosing the most “low-hanging” efficient circuits (to get the best error it can with a low complexity budget), and then recursively picks less and less efficient circuits, until it hits the least efficient circuits (in an overparameterized NN setting, these are memorization circuits). As this is happening, we can recover the “efficiency spectrum” (the specturm of “blue line slopes” where new circuits get picked up) by recording certain parameters associated with the slope of the rate-distortion curve. Namely, we define the following measurement, which will be important for the rest of the series:
Note that this is the inverse of the slope of the blue line above. Now, circuits that are more efficient are associated with lower learning coefficient and turn on (and stay on) at coarser precision rates. Circuits that are less efficient are associated with higher learning coefficient, and only appear once the error allowable by the precision rate is low enough to deplete all more efficient circuits.
In the next couple of installments, I’ll look at a couple of interesting questions one can try to track with this picture in hand. We’ll also discuss a different (but related) context where a similar relationship between log error and complexity appears from modeling algorithms not as aggregations of predictions, but more abstractly as approximating a polynomial function in an “information-geometric space” of programs.
A final note on learnability
Before going on, I want to point out one additional intuition, which I think is worth exploring (but won’t be central to the rest of this series). Namely, as we’ll see in Part II of this series, one can think of traversing the “rate-distortion curve” from left to right (i.e., from fine-grained models with small error bounds to coarse models with high error bounds) as a tempering procedure, where precision is gradually traded off for entropy. As I explained, this process loses circuits – so traversing from right to left can be thought of as a process that accumulates circuits, and does so starting with high-efficiency and picking up lower- and lower-efficiency circuits as efficient options run out.
Of course another place where we encounter an accumulation of circuits in machine learning is the actual learning process: as SGD (or your favorite sequential learning algorithm) goes on, a neural net accumulates “grows” more and more circuits to tackle the classification problem at hand. Here I want to point out that these processes are not the same. While they are probably related, and all else being equal, more efficient circuits are learned before less efficient ones, the learning process has an obvious and consistently observed preference for smaller circuits. In other words, while the rate-distortion curve one measures when tempering a neural net can be conceptualized as tuning the efficiency cutoff slope above to pick up more and more circuits, the analogous learning curve executes something that can be (on a very cartoon level) conceptualized as moving from lower-complexity circuits up to circuits of higher and higher complexity, with less regard for efficiency[7].
- ^
To see this, imagine that you’re implementing circuits via something like python code without loops. Then given a “short” program P of length N that implements your task, observe that any program of the form “P” + “#” + $random_characters implements the same program, where I’m assuming that “#” stands for “the following is a comment”. The log probability that a long program starts with “P” + “#” + ... is more or less the same as the probability that its first N characters are “P”. Actually operationalizing how to “construct a comment functionality” in formal operationalizations such as circuits requires a tad of thinking, but is not that hard to do.
- ^
Technical: this is the log “cdf” of the microcanonical random variable. While this is sometimes called the microcanonical entropy, and I’m using this definition here due to its analogy with the rate-distortion curve, it is more typical to use the term “microcanonical entropy” for the log pdf of this random variable instead.
- ^
Technical footnote: there’s a catch I don’t have space to get into here: roughly, Bayesian learning is associated to some finite number D of observed data samples, and while the Bayesian posterior can be viewed as a thermodynamic “canonical ensemble” for the rate-distortion curve, the temperature is set by the dataset size and is insanely small, namely equal to Questions of relating this to thermodynamic ensembles at more reasonable temperatures are studied in detail in various papers of Watanabe. Another way of thinking of the “Solomonoff” ensemble at realistic temperatures is by viewing samples as “untrusted” with some fraction (roughly equal to the temperature) chosen by some untrusted or adversarial process. In this context one can write down a relationship between “optimal adversarial updating” and the rate-distortion curve.
- ^
Technically, the rate is defined differently (and in a slightly more general context where samples are ordered and outputs are allowed to depend on previous samples). There is however asymptotic sense in which the rate is equal to the Solomonoff complexity of a certain associated process, up to a bounded constant factor, and if I understand correctly, complexity theorists often use a version of the Solomonoff complexity definition as a stand-in for “rate”. Note that I’m not an expert here.
- ^
Independent in the information-theoretic sense, as “predictors with independent information”: the technical term is actually "conditionally independent”.
- ^
Technically the “odds ratio”, but for small errors the difference between error and odds ratio is negligible.
- ^
We know that the reality of learning is more complicated, because if this cartoon-level description were literally true, then overparametrized neural nets would simply memorize all data and never grok. However directionally one clearly encounters distinctions of this sort. For example in learning to solve the modular addition problem, which is a rare ML problem which is fully interpreted and completely fits into the “circuits as parallel predictors” paradigm, one observes that instead of gradually accumulating complexity and learning circuits one by one, all generalizing modular addition circuits (which can be shown to all have the same complexity get learned at similar times in the learning trajectory, often after all or most of the very inefficient memorization circuits have been discovered).
0 comments
Comments sorted by top scores.