The generalization phase diagram
post by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-26T20:30:15.212Z · LW · GW · 2 commentsContents
Introduction Generalities on generalization Algorithmic complexity in a nutshell When complexity met precision A toy example: "prefix-sorting" Observations and remarks about the toy example Noticing phase transitions Limited training data and the infrared catastrophe Generalization and “conceptual hardness” Asymptotic generalization-memorization relationships and Zipf’s law Everything everywhere all at once None 2 comments
Introduction
This is part I of 3.5 planned posts on the “tempered posterior” (one of which will be “SLT in a nutshell”). It is a kind of moral sequel to “Dmitry’s Koan [LW · GW]” and “Logits, log-odds, and loss for parallel circuits [LW · GW]”, and is related to the post on grammars [LW · GW]. It can be read independently of any of these.
In my view, one of the most valuable contributions of singular learning theory [LW · GW] (SLT) so far has been the introduction and serious experimental use of tempering (what in my Koan I call “natural degradation”) in the study of neural nets. As I’ve mentioned in a few of my posts this month, I think that this is a seriously underutilized notion, and can give nice new insights into interpretability, including ones somewhat orthogonal to the current directions of research in SLT. One way (and as I will hopefully explain, the correct way) to think about tempering is as a way to extract fine-grained information about the “spectrum of generalization” inherent in a neural net (or, as we’ll see, even in a conventional Boolean program). In this post I will set up and discuss a precursor to this spectrum -- namely, the "precision-complexity phase diagram" -- in some detail. While the notion of “tempering” is a thermodynamic notion, understanding this phase diagram requires no knowledge of thermodynamics (or of SLT). Rather, it boils down to a simple and easy-to-explain problem in complexity theory tracking the relationship between complexity and precision of programs. In this (hopefully popularly understandable) post, I’ll explain this problem and spend some time discussing a representative "toy" example.
While I will rigorously operationalize this complexity measurement here, it’s important to note that the complexity measurements we discuss are NP hard to measure in general. We’ll fix this issue in the next post. As a spoiler: the reason that thermodynamics and comes in is that it comes equipped with a class of powerful tools (“thermal sampling” methods) that can be used on certain “realistic” instances of NP classes of problems that are a priori not known to be polynomial-time-solvable, and solve them in polynomial time. Work in the SLT paradigm has shown that such thermodynamic methods, done via tempering, can be used with remarkable success on the complexity-theoretic problem I’ll discuss here, turning a problem that’s NP hard in general into a problem that is polynomial-time solvable (or at least in a sense I’ll explain in the next post, “solvable in practice”).
Generalities on generalization
Generalization is a phenomenon opposed to “memorization”. Naively and to first order, a neural net is memorizing if it attains perfect classification on its training set – the set of inputs it was trained on – without any performance improvement (beyond random guessing) on a test set of random other inputs (picture a kid who has memorized a multiplication table, but cannot multiply other numbers). This (unfortunately!) is essentially the only notion of memorization seriously addressed in current ML research. However intuitively, we understand that some “general” learning phenomena are more memorization-y than others. For instance when studying French, one learns that most verbs have “regular” conjugation rules that modify verb endings in a systematic way, but some verbs are “irregular” and have distinct conjugations that have to be memorized. Learing the conjugation of regular verbs is “generalization-shaped”. Memorizing an exceptional conjugation is, in relation to this, more “memorization-y”. However, this is not something that would be evident from training vs. test losses: any reasonably-sized French text corpus will include a roughly equal fraction of irregular verbs both in the training and the test set, and there is no way to track questions like “how well does a model understand regular vs. irregular verbs” by just looking at test vs. train accuracy. How, then, does one try to operationalize this distinction? Well, one way to think about this is in terms of “efficiency”. Let’s say you are coding (manually and without any ML) an extremely basic French-language bot, and sometimes this bot needs to conjugate verbs. Ideally, this bot will have a “general” subroutine for each class of regular verbs, and also an “exceptional” subroutine for each irregular verb[1]. However if for whatever reason you can only fit one type of these subroutines (maybe it’s 1985 and you have intense memory restrictions), it’s more efficient to include only the “regular verb” subroutine, and scrap the irregular one.
More generally, we can (very approximately) view a program solving some task (like conjugation of French verbs) as composed of subroutines called “circuits” in the context of ML. Each circuit by itself has two parameters – complexity and importance. A circuit is more important if it applies to more instances of the task (the circuit conjugating regular verbs is more important than the circuit conjugating irrelevant ones). A circuit is more complex if it requires more lines of code. Again in an incredibly reductive approximation, we can say that this leads to a sort of measure of “circuit efficiency” which is something like A good programmer working with limited resources, and a general neural net working under certain “performance-degrading” restrictions, will both prioritize more efficient circuits over less efficient ones. This can be conceptualized as committing to an “efficiency cutoff”. If a circuit has higher efficiency than the cutoff, it gets implemented and if it has lower efficiency, it gets scrapped. If only it were possible to empirically tune such an “efficiency cutoff”[2], we would be able to get a much more fine-grained understanding of when behavior A (say, conjugating regular verbs) is more efficient – we will say more general – than behavior B.
Now in fact, even in very simple cases, the idea of a program or a neural net as neatly separating into distinct circuits breaks down, or at least nuances, in myriad ways. At a minimum you have distinctions between behaviors that are sequential and parallel (and in the grammars [LW · GW] post I explained that even “sorta parallel” behaviors end up being combined in importantly different ways). Nevertheless, the idea of “tuning efficiency” of an algorithm survives this breakdown. It turns out that the idea of “the program you would get if you only kept circuits above a given efficiency cutoff” is formally tractable and interesting. This is the idea we will explore in this post.
Algorithmic complexity in a nutshell
To begin, let’s talk about algorithmic complexity. An algorithm is a function, F: input → output. An example of an algorithm is the sorting algorithm: its input is a list of L strings and its output is another such list. (We will be focusing on finite algorithms, so let’s assume the length of the list is fixed). For the sake of this post, we distinguish two notions of algorithm which will play complementary roles.
- Tasks. A task is a “Platonic specification” for an algorithm, which I’ll write Here should be read as “the correct output value if the input value is x” (“star” generally denotes “correct” or “optimal” in statistics). This can be given either for all input values, or for some subset of “observed” input values. We think of a task as making no claims about its implementation or internals: for example, saying that is a sorting algorithm is a “task specification”: we’re not saying how F is implemented, what its efficiency is, etc. Often in ML, tasks are given by a lookup table (so for example “test data” is just a lookup table from some set of inputs to the “correct answer designation” on these inputs).
- Programs. We will write (or use more general capital letters) for a program. A program should be thought of as an “implementation” for a task. For example bubble sort is a code implementation of the sorting task. Implicitly when speaking of programs, we think of some concrete class of algorithms. In most of this post, we will operationalize complexity measurements via boolean circuits. Whenever we have a class of algorithms, it has an implicit notion of complexity, or “size”, which we’ll in general denote N. For example for circuits, the complexity N of a circuit is (in one standard operationalization) the “number of operations” that it applies (and for a neural net, N will be the number of parameters).
Technical remark. As a technical aside for people familiar with complexity theory: note that for our purposes, complexity defined via boolean circuits gives a much better operationalization than the often-used notion of “Kolmogorov complexity” defined via Turing machines. Turing machine questions are incredibly complicated and depend on your model of logic. Problems involving circuit complexity, on the other hand, are at worst NP hard. Circuit complexity is extremely close to, and in many contexts interchangeable with, “time complexity”. It can also be robustly related to complexity measures of neural nets.
Note that in machine-learning world, both tasks and programs tend to be probabilistic. For example a text predictor like an LLM doesn’t conceptualize next-token prediction as a deterministic problem, but rather a probabilistic one – and indeed, the task is inherently probabilistic as well; for instance what is the correct next-token prediction for “My name is __”? [3]
However in this post we’ll get a lot of theoretical mileage by thinking of deterministic tasks and deterministic programs.
Now so far we’ve defined the complexity of a program, but not a task in computer science, a classic question is to find the minimal complexity of a task, which is defined as the answer to the following question.
What is the minimal complexity of a program that implements a particular task on a given input set?
For instance bubble sort-style algorithms imply that the complexity of task of sorting a length-L list, (as implemented by boolean circuits), is on the order of L, up to logarithmic factors[4]. In general, in this post I’ll be ignoring logarithmic factors since we’re trying to establish an intuition for a very fundamental angle of analysis on neural nets, and carrying around a bunch of small log factors will be distracting.
Now the notion of minimal complexity is in some sense “unnatural” from an information-theoretic (or, relatedly, a “physical”) point of view. In the next installment (part I.5) of this series I will explain this and introduce the better notion of “Solomonoff” or “information-theoretic” complexity (sometimes also called “entropy”) into the mix of ideas – in particular, next time we’ll see that this quantity is better-behaved and easier to measure. Nevertheless, for now I want to avoid plumbing the theoretical depths and think of different notions of complexity as “sorta interchangeable” – as they in fact are in some contexts.
When complexity met precision
When thinking of typical computer-science tasks like “sort”, it makes sense to study the complexity of programs that “implement this task exactly”. Indeed, in this context the task is formally definable. However for typical tasks where one uses neural nets, this property gets degraded. Indeed, tasks are (often) approximations of ~infinitely complex real-world phenomena. For example being exactly right on tasks like “decide if this image is a cat” or “find the true probability distribution on text completions” more or less depends on all the complexity in the universe (a very slightly different world from ours would have a very slightly different “true cat” classifier).
For tasks of this sort, it’s simply not realistic to speak directly about the complexity of an algorithm that “truly solves a task”. Instead, algorithms need to be graded on a curve and have some irreducible notion of error. From now on, whenever discussing complexity, we need to carry around an extra precision parameter as an implicit bound for the largest allowable error that still counts as “solving the task”. I’ll discuss operationalizing this in a bit, but first let’s redo our definitions in the presence of this extra parameter (I promise this isn’t just a technicality). We start with the same notions of task and program as before
- Task: an assignment of the “correct” deterministic or probabilistic output on either all or a subset of possible values of x.
- Program: neural net “code” for an implementation of an algorithm (either deterministic or probabilistic), with inherent notions of “architecture” (the class of programs we consider) and “complexity N” (usually defined as the parameter count of the architecture).
But crucially, now we now have a new notion of error which is a function of a pair consisting of an assignment and a program:
- Error, written E(program|task), capturing “how well a given program implements a given task”.
Error is a similar (and indeed, in some contexts identical) notion to “Loss” in a machine learning program. A “perfect” implementation of a task has minimal error (generally E = 0 for deterministic tasks). Generally, we think of error as an “aggregate error” equal to the expectation of a “single-sample” error function Here if the set of inputs is discrete, the expectation can be taken over a uniform probability distribution; more generally, this may be taken over a “true” probability distribution on inputs, which we can think as as latent property of the task.
Now I want to point out that we don’t actually have to go to the world of neural nets to have a meaningful discussion of precision. Namely, it’s entirely reasonable to talk about error in the world of deterministic programs. An easy operationalization of error here is that of (in)accuracy. So given a circuit C(x) and a task , we define
In other words, “accuracy” is the probability of the program correctly executing the task on a random input and “error” is the complement[5].
From now on, the measurement must be functions of a new “error sensitivity” parameter With this in hand, we are now able to define the main character of this post.
The (discrete) complexity-precision phase diagram is an integer-valued function defined as the minimal parameter count of a circuit that implements a particular task up to error .
Now the important point here is that tuning the parameter lets us neatly operationalize (discrete version of) behaviors on a spectrum between generaliaztion and precision, which has been a recurring refrain in my posts so far, and the most important thing I want readers to take away from this series.
A toy example: "prefix-sorting"
To make this concrete and show why it’s useful, let me give a very basic but important toy example of a program with an interesting phase diagram, expressible in a context where everything is discrete. Let’s define the following task.
- n is a complexity parameter (think – we’ll at least need n>20), capturing the size of an alphabet of tokens.
- An input is a 10-letter string in the alphabet .
- To define the task, choose at random the following data:
- a single-element set consisting of one single-character “prefix” string ;
- a set of two-character prefix strings none of which begin with ;
- a set of three-character prefix strings none of which begin with either the character or any prefix string in ;
- a set of 10-character strings which don’t begin in any prefix strings in .
- Now for any 10-character string x, the task is to return
- 1, if x starts with any prefix in
- 0, otherwise.
I’ve designed this task to be maximally “naive”: it’s a deterministic binary classification task that doesn’t implement anything but prefix checking. But the key point here is that solving this task to varying levels of precision takes varying levels of complexity.
Let’s see these complexity levels in action. I’m not going to be futzing around with carefully operationalizing and writing proofs for the complexity formalism here: I just want you to trust me that in this particular instance, it is in fact possible (by making some appropriate assumptions about the architecture) to operationalize and prove that, either as a task about about circuits or indeed neural nets[6], and up to log factors, the complexity measurements (both the ones we’ve defined so far, and the “improved” Solomonoff complexity we’ll introduce in the next post), are in fact the same as the handwavy “follow your nose” complexity measurements I’ll explain below.
Let’s think of this as a task in deterministic programs, with Error = 1 - Accuracy as above. Below, I’ll write down a list of 10 programs of increasing complexity that solve the task with appropriate degrees of error.
- As a “zeroth order” approximation, we can solve this task by the “always output zero” program: This is an O(1) complexity program[7]. This gives the wrong answer exactly when the input string x starts with one of our 10 prefix classes Now notice that every prefix class captures exactly 10-letter strings. Indeed, the probability that a string s starts with a fixed k-letter prefix is , and we’ve set up the problem such that there are k-letter prefixes in the set . Thus each class contributes a (nonoverlapping) probability of error, for a total error of
- As a next approximation, write This algorithm still has complexity O(1) up to log factors: it only depends on “memorizing” a single string. Recall that misclassifying each prefix class leads to a error probability. Here we’ve correctly classified the first prefix class , but incorrectly classified the rest: so
- You probably get the idea now. As a second approximation, write This algorithm has complexity O(n) (up to log factors): it depends, in an essential way, on memorizing n different 2-character strings. At this level we are correctly classifying the first two prefix classes, and , but incorrectly classifying the rest: so
- Finally, the “9th order” approximation memorizes all the prefix sets consisting of memorization instances, and thus a complexity of , and it correctly classifies all inputs: so
Therefore, as a cartoon, we get the following graph for the complexity with on a linear scale between 0 and and a log scale for the complexity m:
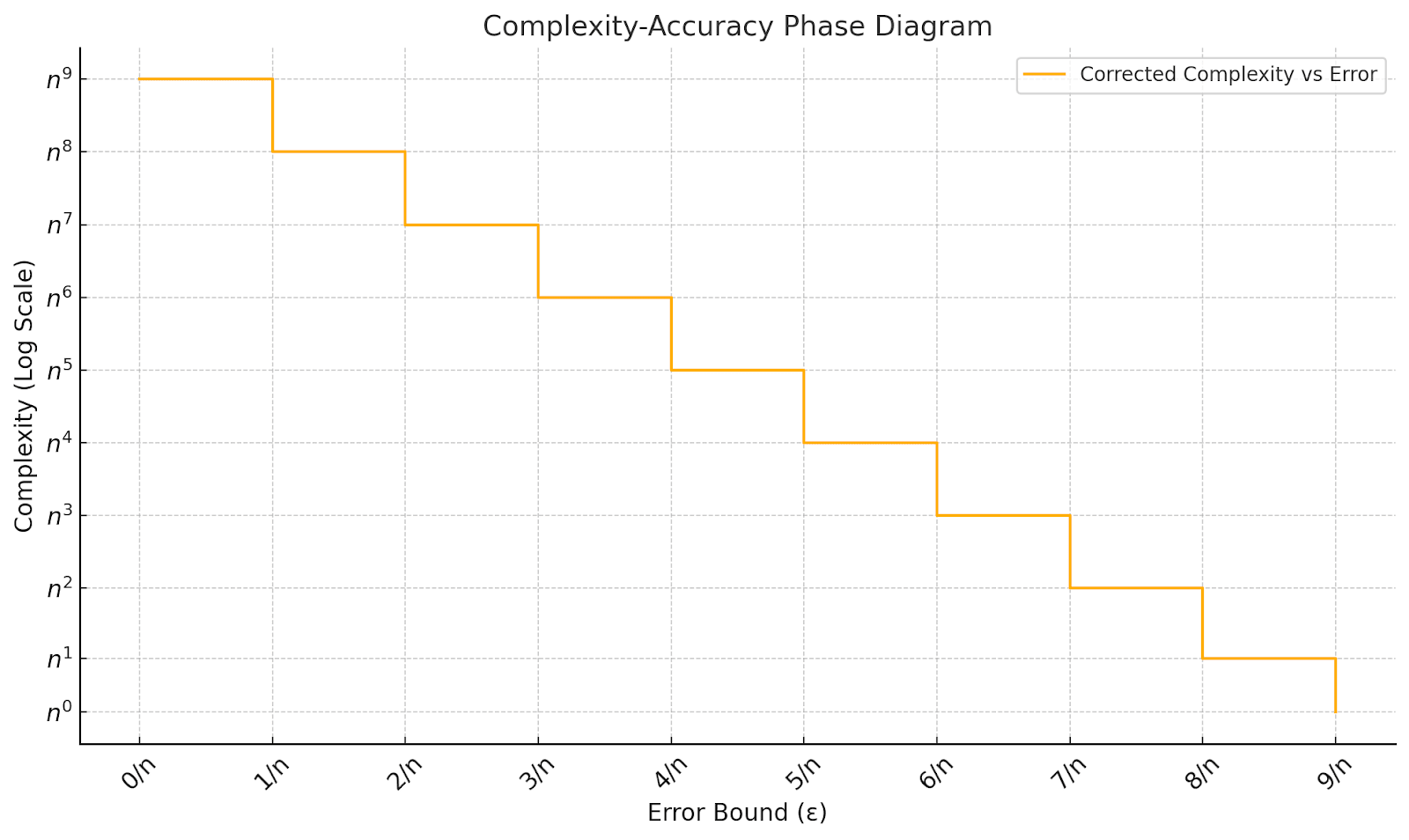
In fact, this cartoon “strict step” behavior isn’t quite right. Instead of each prefix class being learned as a single irreducible algorithm, the optimal algorithm with complexity for example, is able to memorize all n of the exceptional prefixes of length 2 and about half of the exceptional prefixes of length 3, and give an intermediate accuracy of about A corrected picture still has qualitatively different “phase transition-y” behavior at each new prefix class complexity (corresponding to a power of n), but the dependence is smoother:
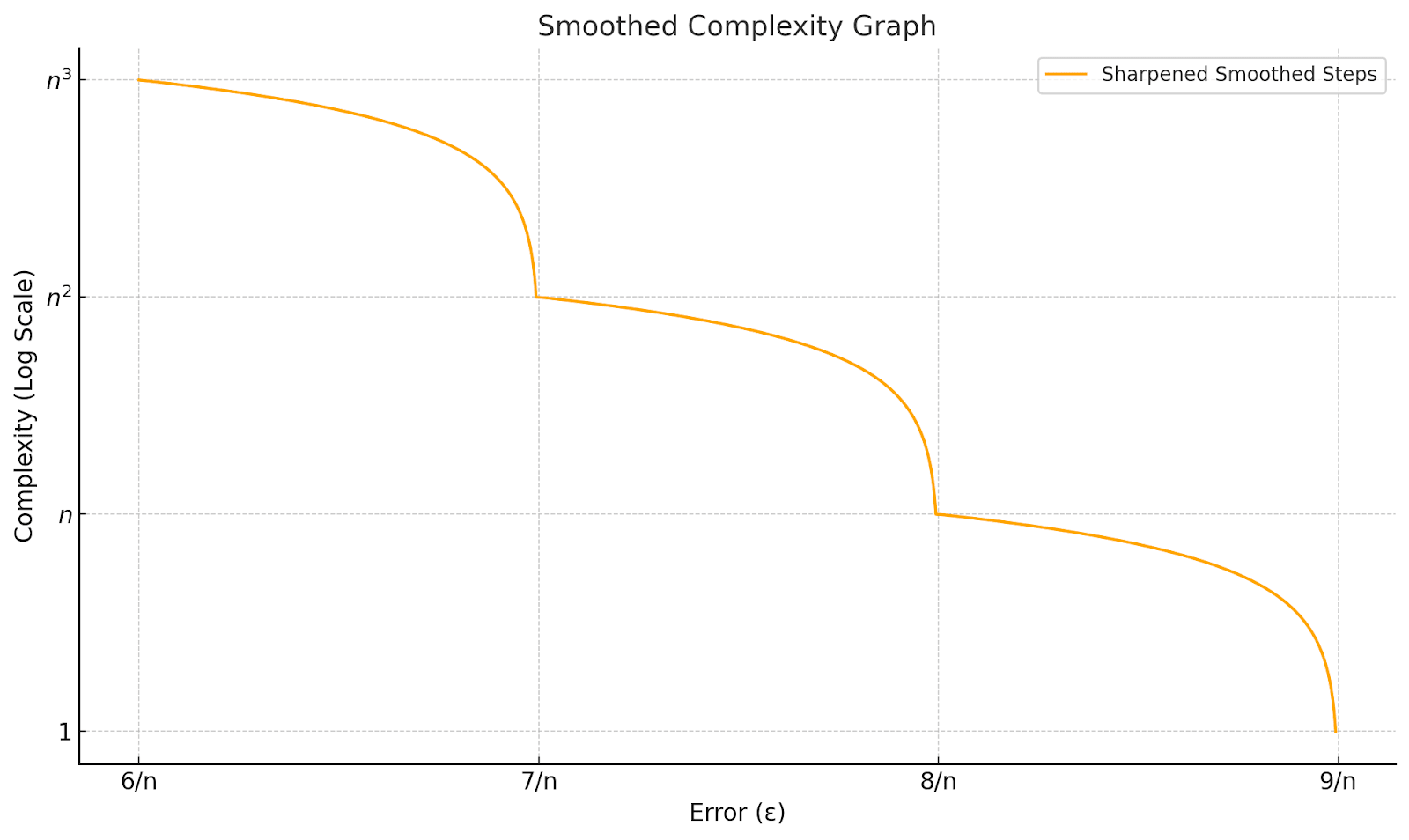
Now note that we expect a version of this kind of qualitative behavior to occur in realistic learned algorithms. For example in the “regular vs. irregular verbs” example, a program that only implements “regular conjugations” looks like a point on one of the arcs towards the right here: it has significantly lower complexity, but at the cost of a small decrease in accuracy ( a small increase in error). Conversely learning irregular conjugations moves us to a more leftwards arc, and buys improved precision at the cost of significantly more “memorization-shaped” complexity, analogous to learning a more granular class of exceptional prefixes in our toy example.
Observations and remarks about the toy example
The toy example I gave above is incredibly dumb. I think it would be very interesting to find and study more “algorithmically interesting” examples of a phase diagram of this shape interpolating between “more regular” to “more irregular” behaviors. One of the reasons I’m so excited [LW · GW] about the paper He et al. is that an interesting phase diagram of this shape (with two phase transitions, at accuracy scales and respectively) can be extracted from that paper.
At the same time, I think it’s really important to understand that behaviors of this shape exist, and are important to track in order to interpret neural nets. In the next post, I’ll explain how thinking about this example leads to an important amendment to a common assumption in singular learning theory. Below, I’ll discuss a few properties of this example in particular that both make it a good and a bad “qualitative test case” of memorization-generalization behaviors.
Noticing phase transitions
Another important observation is that the behaviors captured here are fundamentally of phase transition shape. Specifically, phase transitions occur in physics when a thermodynamic system discovers that a new type of behavior becomes relevant under new macroscopic conditions, which was either unavailable or inefficient at previous conditions. For example water molecules that were happy to exist as vapor under low-pressure conditions could in principle remain as vapor under high-pressure conditions as well – but a phase transition is triggered by the appearance, at certain pressure-temperature values, of a new phase that has “better performance”[8]. In the exact same way, a collection of subroutines that memorize exceptional 3-letter prefixes can continue to chug away at 2-letter prefixes by inefficiently understanding each exceptional 2-letter prefix “ab” as a big set of 3-letter prefixes “abx” (for x any letter). In the same way a memorization-favoring student of French may opt to ignore the general rule for conjugating regular verbs and instead memorize the conjugation table for each regular verb independently. But since our definition of the precision-complexity curve inherently seeks optimal complexity solutions, we see it undergo these “generalization phase transitions” where it notices the more efficient technique of only looking at the first two letters when the problem can be solved with less memorizing.
Limited training data and the infrared catastrophe
When defining my toy task, I assumed that the accuracy of an algorithm is measurable exactly. This is often an unrealistic assumption. In realistic ML contexts, the source of the “accuracy” measurement is some supervised training data. In order to precisely measure the accuracy of an program relative to a task as above, one needs to run it on all possible 10-letter phrases – in the case n = 100, for instance, this corresponds to a training corpus of size a very large number. If one were to measure a “sample-based” notion of accuracy by looking at a random data sample of size the precision-complexity graph will change: indeed, if the dataset size is, say, about , then any “prefix memorization” subtask with more than relevant prefixes (so learning and beyond, say) fails to compete with the “direct memorization” algorithm of just memorizing the inputs. The resulting “cartoon” phase diagram is as follows:
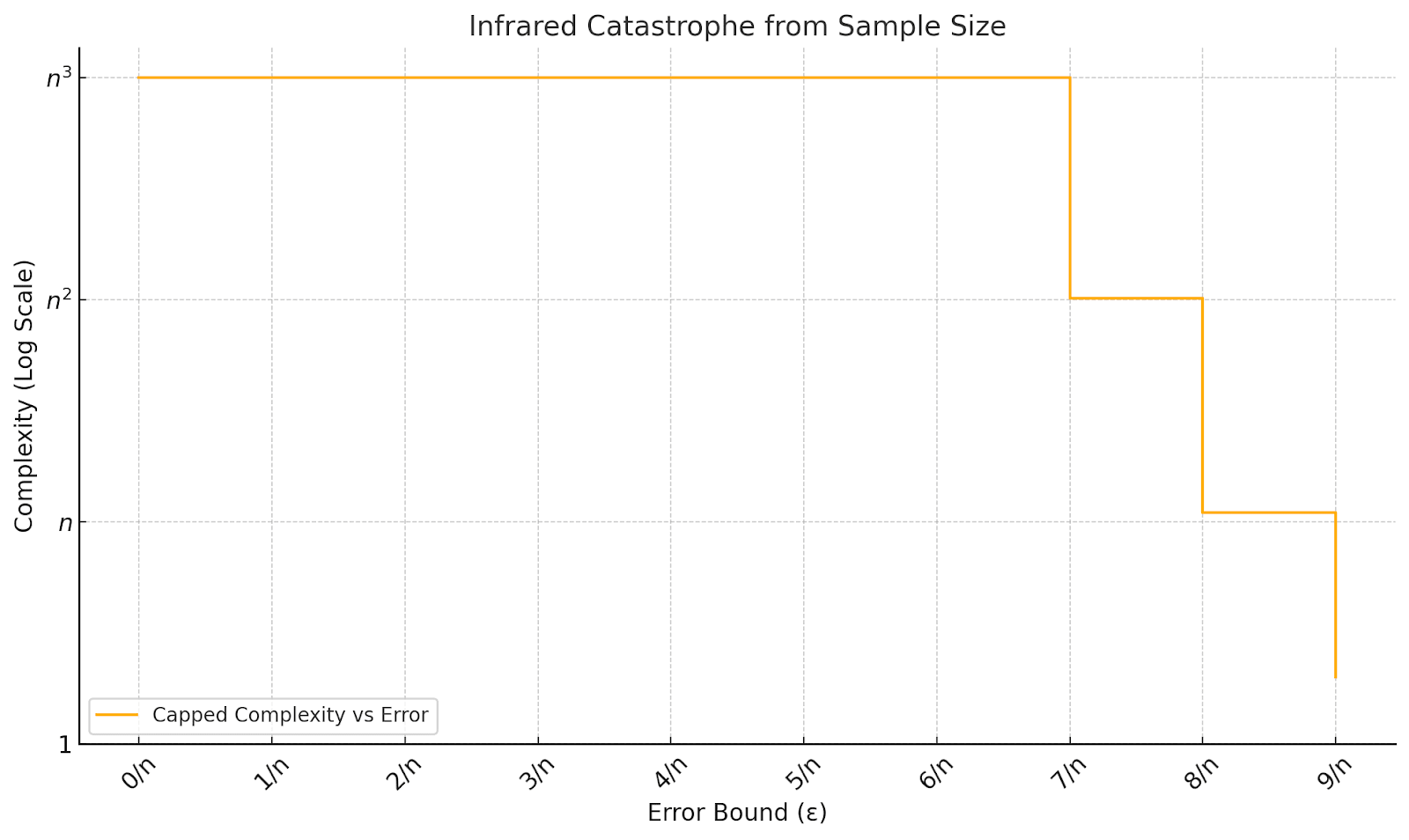
Here the reason for the name “infrared catastrophe” has to do with a rigorous operationalization of "generalization" or “efficiency spectra,” analogous to energy spectra in physics. This will be a core component of a later post in this series. As a rough intuition, the complexity-accuracy phase diagram can be conceptualized as the result of a bunch of interacting circuits (like “learn regular verbs” vs. “learn irregular verbs”). As a rule, more efficient circuits are retained over less efficient ones. Now whenever you measure accuracy with respect to a dataset of size D, there is a type of circuit which is always available, namely “memorize a single datapoint”. The efficiency of such a “pure memorization” circuit is always (ignoring log factors) (you gain accuracy improvement at the cost of O(1) complexity). Thus any circuit of efficiency (read “energy”) less than gets “collapsed” in the complexity-accuracy diagram. This is analogous to notions of infrared collapse in physics, where phenomena which are have some nice and predictable form at high energies "collapse" into noisy or boring phenomena at low energies. In our toy example we observe that learning a single prefix in also has efficiency , so is interchangeable with a “memorize a datapoint” circuit, and learning anything prefix in and beyond is simply dominated by memorizing a single datapoint, and the spectrum collapses above this level. (Don’t worry if this discussion is confusing: I’ll talk more about data-related infrared collapse, which is related to the "Watanabe critical temperature", and about efficiency spectra more generally, in the next posts.)
Generalization and “conceptual hardness”
A wrinkle missing in my dumb-as-nails toy example, but present in most “real-life” memorization-generalization transitions, is that usually general algorithms have “higher-complexity circuits”: in other words, some nontrivial “insight” is needed to pass from a less efficient memorization-y algorithm to a more efficient generalization-y one; this is related to notions of grokking, questions of learnability, etc. An extreme version of this is present in the parity learning problem [LW · GW]. Here an efficient “generalizing” algorithm exists and dominates the precision-complexity phase diagram, but it is in fact not learnable in polynomial time by (at least SGD-style) learning algorithms; the discrepancy reflects that, even when we operationalize the “sampling/tempering” paradigm for estimating complexity-accuracy phase diagrams in polynomial time, there are still some issues related to discrepancies between “learnable” and “Bayes-optimal” solutions. In the SLT picture, this is closely related to the difference between the “learning coefficient” and the “local learning coefficient”.
Asymptotic generalization-memorization relationships and Zipf’s law
A final important issue with this toy model is that while qualitatively, it captures a real behavior that exists, the specific “shape” of the relationship, with error depending roughly linearly on the logarithm of the complexity is probably not accurate. There are various empirical observations related to Zipf’s law and various power laws appearing in empirical measurements of text complexity (see also here for a formal model due to Łukasz Dębowski) that say that the number of memorization-shaped “exceptions” in tasks like text generation grows like a power law (rather than an exponential) as a function of precision and text entropy measurements. Incorporating this observation leads to a slightly different dumb-as-nails toy model, where phase transitions are approximately regular on a log scale in the error bound as well as in complexity (with the two related by something like a power law). The reason I went for an exponential relationship in this toy model is just that it’s conceptually easier to write down (at the cost of having less realistic asymptotics).
Everything everywhere all at once
I genuinely believe that most advanced LLMs have some internal machinery that roughly corresponds to understanding regular vs. irregular verb conjugations. And if not that, it at least seems obvious that they must implement different behaviors associated to “exceptions”, “irregularities”, “edge cases” which are distinctly more memorization-shaped than other more general behaviors. The issue is that if one were to write down (or more realistically approximate via sampling) a precision-complexity phase diagram for an advanced LLM, you wouldn’t see “regular vs. irregular verbs” as a clear phase transition-y bump. Rather you would see a giant graph incorporating probably millions of behaviors at different levels of granularity, all overlapping and interacting with each other. The question of splitting messy overlapping behaviors into localized circuits with tractable (in some local sense) interactions is the central question of interpretability theory. As I’ll try to explain (but by no means prove or claim with high confidence), I am currently hopeful that tools related to tempering can help significantly disentangle such a mess to the point of having a reasonable distillation of individual “behaviors”. Here I am optimistic about a few methods leading to progress.
- One can write down an “enhanced” version of the precision-complexity phase diagram to a three-dimensional diagram that includes the additional parameter of weight norm[9]. Some results of Apollo researchers, related in particular to this post [LW · GW] and the paper referenced there, indicate that this is a promising way to look for further decomposition into circuits.
- I think it is very promising to look at a class of “similarity scales” and “natural fields” induced on the data distribution by generalization spectrum-like notions (for example saying that two inputs are “close” if their classification depends in an essential way on the same generalizing circuits). This leads to a whole slew of field theory-inspired phenomena [LW · GW] related to renormalization. At the moment, this class of ideas is little more than a dream [LW(p) · GW(p)], but Lauren Greenspan and I are talking about some ideas to start operationalizing this class of ideas via toy models and experiments.
- SLT provides promise to give a further splitting the “energy spectrum” of circuit efficiencies into more refined packets classified by geometric information (of singularity-theoretic flavor). I am very interested in this class of ideas, and will try to distill it a little in a future “SLT in a nutshell” post.
- ^
- ^
Spoiler: it is! But that will have to wait till the next post.
- ^
Ok in this case there is a deterministic completion: “… Inigo Montoya. You killed my father. Prepare to die.”
- ^
Here small print: we assume the length of each string in the list is “small”, e.g. constant or logarithmic in n.
- ^
In machine learning, 1 - accuracy is a less principled “loss-like” measurement for deterministic algorithms (both for analyzing learning, but also for various information-theoretical questions) than entropy. Here for a program with boolean outputs, if the accuracy of a program is A = Acc(C), its entropy H(C) is defined as
(For programs with non-binary outputs, the two terms are weighted slightly differently.) I won’t worry about this here since for an algorithm with accuracy, the inaccuracy and entropy measure the same thing up to a log factor.
In a bit more detail: one way to see that entropy is the “right” measurement is to think of the loss of a neural net whose logit logit(x; y) is
- a constant K for
- 0, otherwise.
Now if we assume the constant K is chosen (“learned”: note the associated 1-dimensional learning program is convex, thus has a unique local minimum) to make this optimal then it’s an exercise to see that this resulting loss is the entropy. In particular you may have noticed that the entropy expression is symmetric in accuracy vs. inaccuracy: this is because for a binary classifier, a program that “always tells the truth” is just as useful as a program that “always lies”, and if the sign of K is flipped above, the preferred output of the binary classifier gets flipped. In the context we consider, where accuracy > 1 / 2 and is close to 1, you can check that the two terms in the entropy are asymptotically 1-A and -(1-A)log(1-A), so both are equal to “inaccuracy up to a log factor”. BTW the log(1-A) term that keeps popping up is related to the log(n) term that keeps popping up in singular learning theory!
- ^
With bounded bit precision.
- ^
Blah blah blah ignoring log factors that will pop up if you’re operationalizing for a particular circuit or NN class.
- ^
In thermodynamics the relevant performance parameter is called “free energy”. Singular learning theorists who recognize this word and want to say something about it – shush, don’t spoil the next post.
- ^
More generally, it may make sense to measure norm at different layers to generate more “thermodynamic levers” to play with.
2 comments
Comments sorted by top scores.
comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2025-01-27T16:33:17.783Z · LW(p) · GW(p)
Thank you for writing this post Dmitry. I've only skimmed the post but clearly it merits a deeper dive.
I will now describe a powerful, central circle of ideas I've been obsessed with past year that I suspect is very close to the way you are thinking.
Free energy functionals
There is a very powerful, very central idea whose simplicity is somehow lost in physics obscurantism which I will call for lack of a better word ' tempered free energy functionals'.
Let us be given a loss function $L$ [physicists will prefer to think of this as an energy function/ Hamiltonian]. The idea is that one consider a functional $F_{L}(\beta): \Delta(\Omega) \to \mathbb{R}$ taking a distribution $p$ and sending it to $L(p) + \beta H(p)$, $\beta\in \mathbb{R}$ is the inherent coolness or inverse temperature.
We are now interested in minimizers of this functional. The functional will typically be convex (e.g. if $L(p)=KL(q||p)$ the KL-divergence or $L(P)= NL_N(p)$, the empirical loss at $N$ data points) so it has a minimum. This is the tempered Bayesian posterior/ Boltzmann distribution at inverse temperature $\beta$.
I find the physics terminology inherently confusing. So instead of the mysterious word temperature; just think of $\beta$ as a variable that controls the tradeoff between loss and inherent simplicity bias/noise. In other words, \beta controls the inherent noise.
SLT of course describes the free energy functional when evaluated at this minimizer as a function of $N$ through the Watanabe free energy functional.
Another piece of the story is that the [continuum limit of] stochastic gradient langevin descent at a given noise level is equivalently gradient descent along the free energy functional [at the given noise level, in the Wasserstein metric].
Rate-distortion theory
Instead of a free energy functional we can better think of it as a complexity-accuracy functional.
This is the basics of rate-distortion theory. I note that there is a very important but little known purely algorithmic version of this theory. See here for an expansive breakdown on more of these ideas.
Working in this generality it can be shown that every phase transition diagram is possible. There are also connections with Natural Abstractions/ sufficient statistics and time complexity.
Replies from: dmitry-vaintrob↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-27T17:07:53.933Z · LW(p) · GW(p)
Thanks! Yes the temperature picture is the direction I'm going in. I had heard the term "rate distortion", but didn't realize the connection with this picture. Might have to change the language for my next post