Re-Examining LayerNorm
post by Eric Winsor (EricWinsor) · 2022-12-01T22:20:23.542Z · LW · GW · 12 commentsContents
Summary None 11 comments
Please check out the colab notebook for interactive figures and more detailed technical explanations.
This post is part of the work done at Conjecture.
Special thanks to Sid Black, Dan Braun, Carlos Ramón Guevara, Beren Millidge, Chris Scammell, Lee Sharkey, and Lucas Teixeira for feedback on early drafts.
There's a lot of non-linearities floating around in neural networks these days, but one that often gets overlooked is LayerNorm. This is understandable because it's not "supposed" to be doing anything; it was originally introduced to stabilize training. Contemporary attitudes about LayerNorm's computational power range from "it's just normalizing a vector" to "it can do division apparently". And theories of mechanistic interpretability such as features as directions and polytopes [LW · GW] are unhelpful, or even harmful, in understanding normalization's impact on a network's representations. After all, normalization doesn't alter the direction of vectors, but it still bends lines and planes (the boundaries of polytopes) out of shape. As it turns out, LayerNorm can be used as a general purpose activation function (you can solve MNIST with a LayerNorm MLP, for example). Concretely, it can do things like this:
and this:
We will explain what's going on in these animations later, but the point is that to develop a strong, principled theory of mechanistic interpretability, we need to grapple with this non-linearity.
In this interactive notebook, we study LayerNorm systematically using math and geometric intuition to characterize the ways in which it can manipulate data. We show that the core non-linearity of LayerNorm can be understood via simple geometric primitives. We explain how these basic primitives may perform semantic operations. For example, folding can be viewed as extracting extremal features (e.g. separating extreme temperatures from normal ones). We leverage these primitives to understand more complex low-dimensional classification tasks with multiple layers of non-linearities. The methods and intuition developed here extend to non-linearities beyond LayerNorm, and we plan to extend them in future work. Below is an interactive summary of the content of the notebook. (If you find the summary interesting, you really should check out the notebook: manipulating the figures helps build geometric intuition.)
Summary
The formula for LayerNorm is something messy like
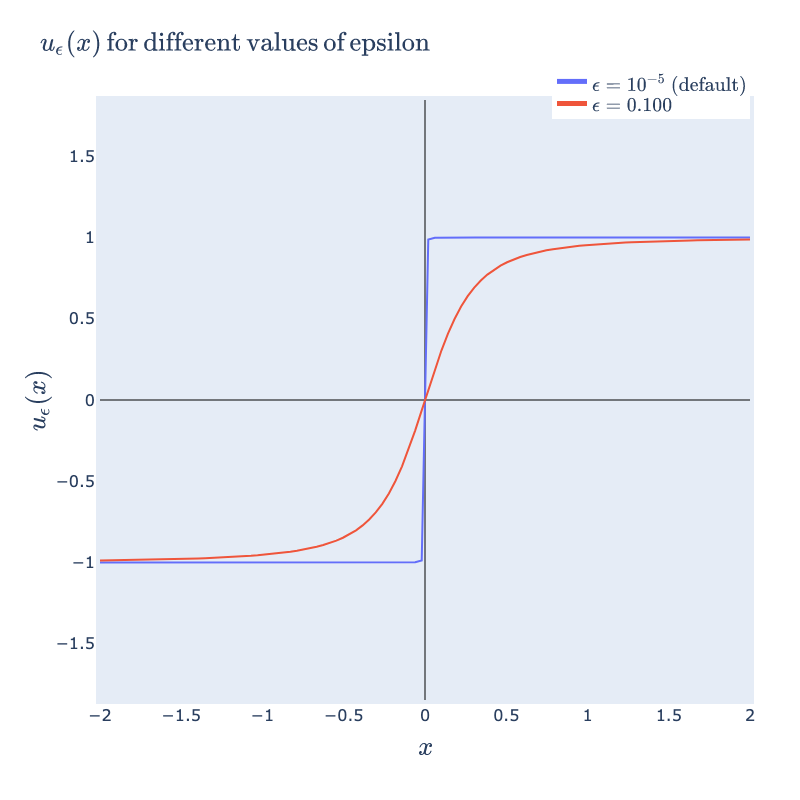
But it turns out the core non-linear operation is (almost) normalizing a vector:
Graphically, this function has the iconic sigmoid shape in one dimension (note that in 1D the norm is simply the absolute value).
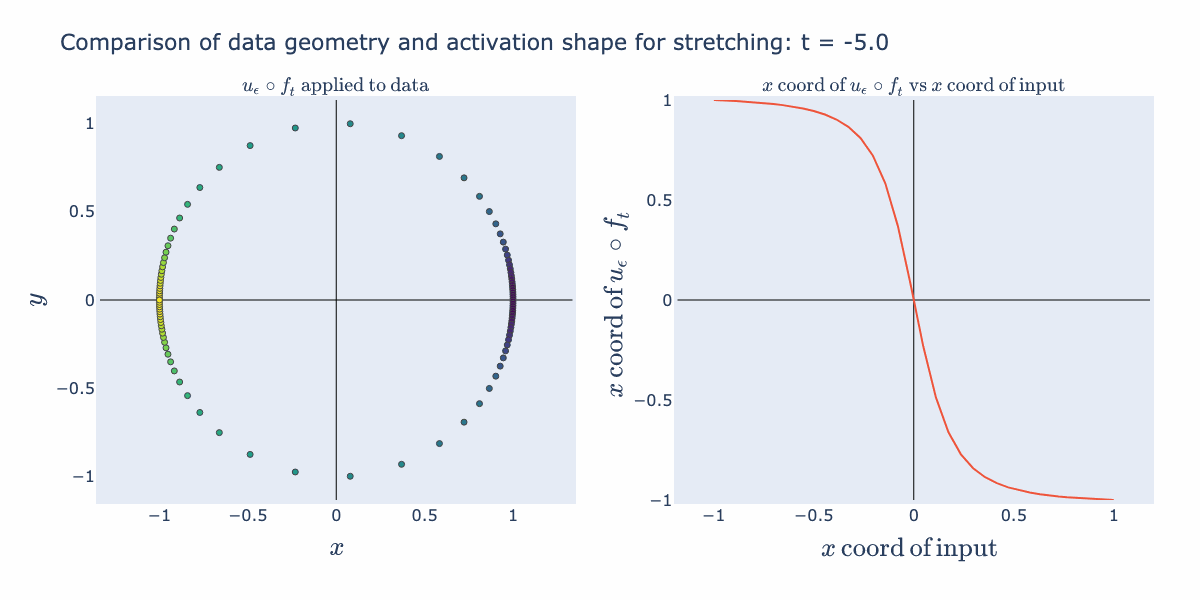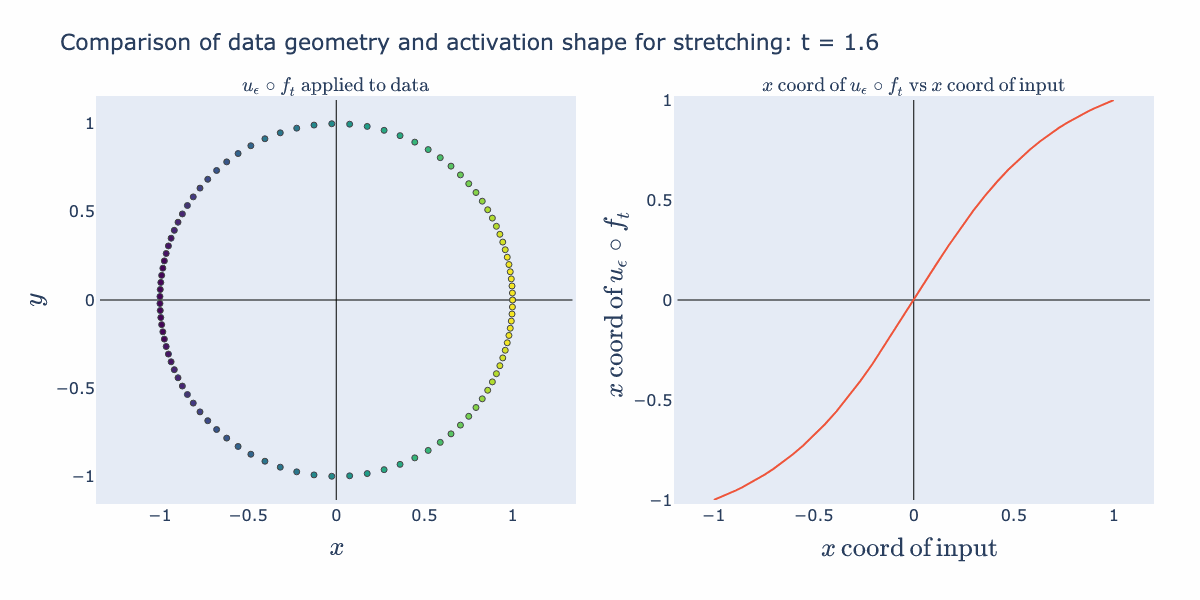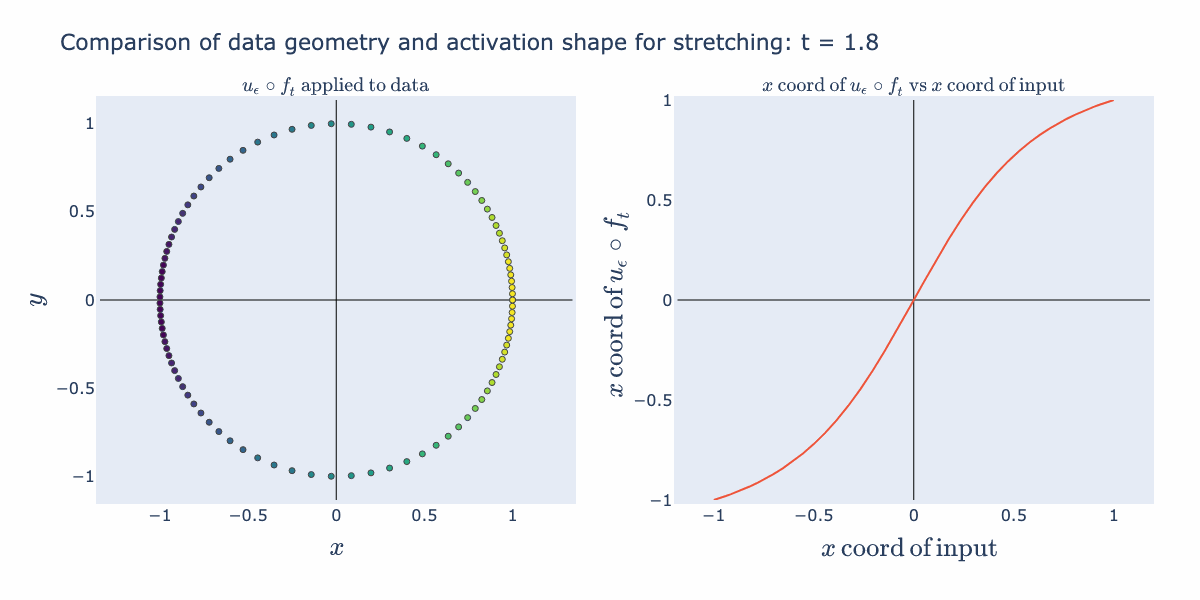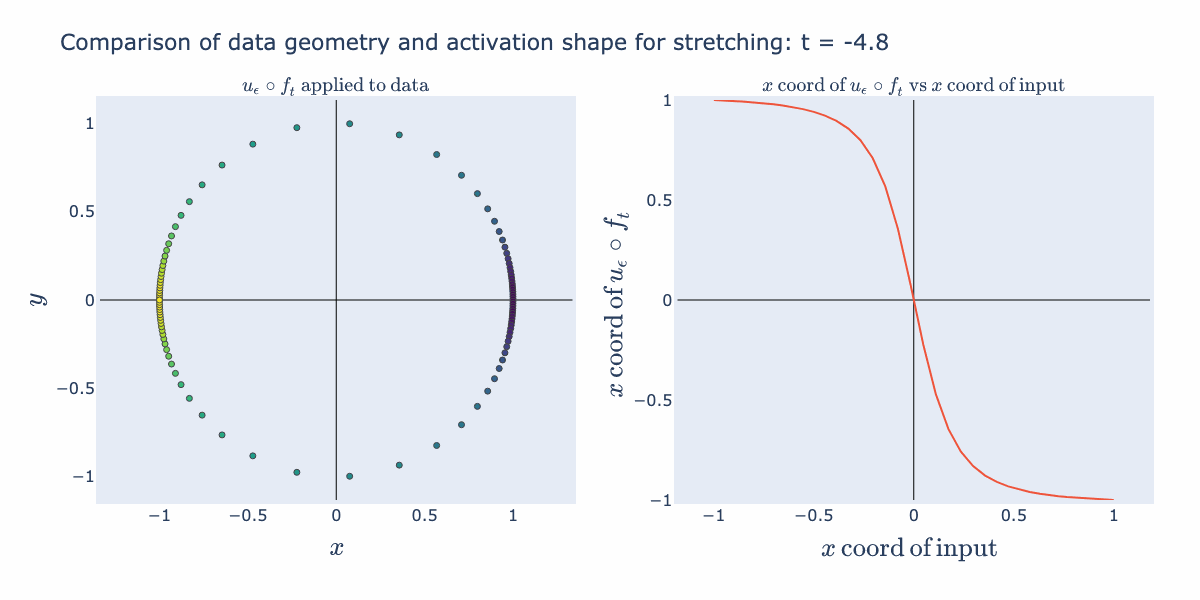
Interesting things start happening when we precompose this normalization function with affine transformations (such as scaling and shifting). Below, we start with a collection of points, , distributed uniformly on the sphere. Then we compute (stretch/shrink by a factor of in the direction and then normalize). Since normalization guarantees points end up on the circle, this operation stretches the distribution along the circle. The right hand panel illustrates how this stretching is captured in the shape of a 1D activation function (the coordinate of the input against the coordinate of the output). For example, when is close to 5, we see that any points with coordinates not near 0 get compressed towards or . This matches the picture in the circle where we see the points bunch up at the left and right sides of the circle.
If we make the same plots with a shifting operation, , the operation folds the input data.
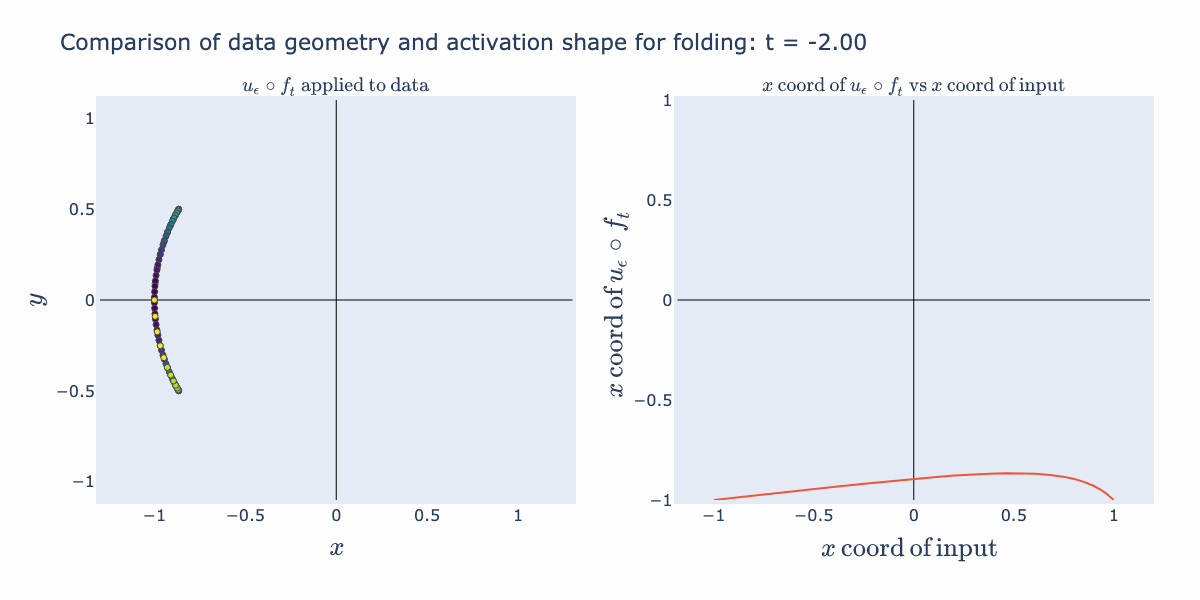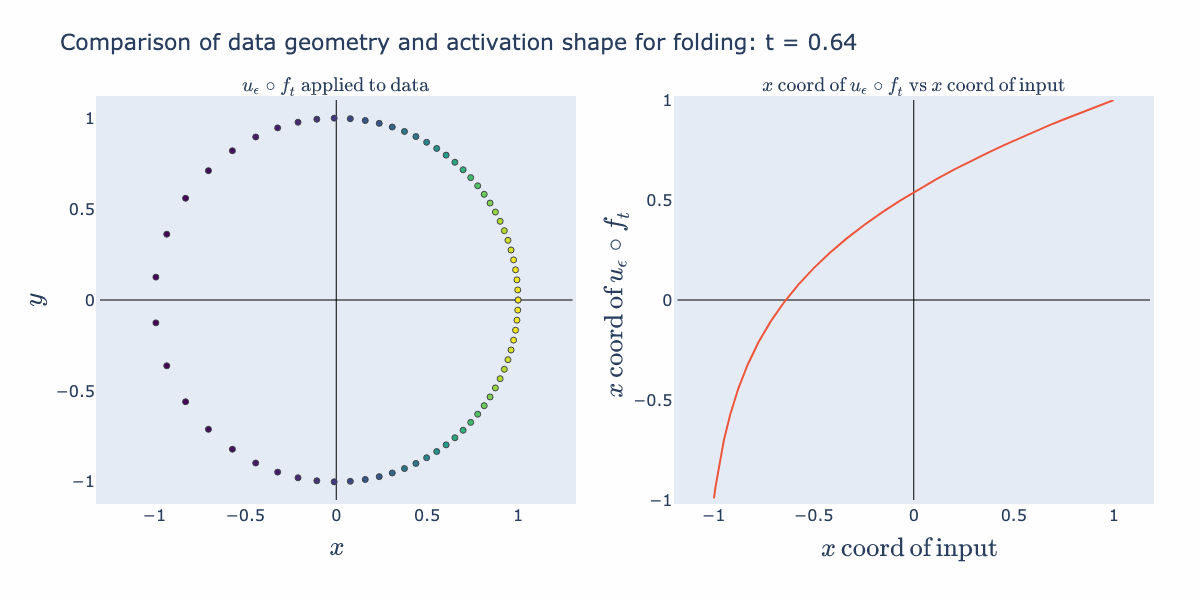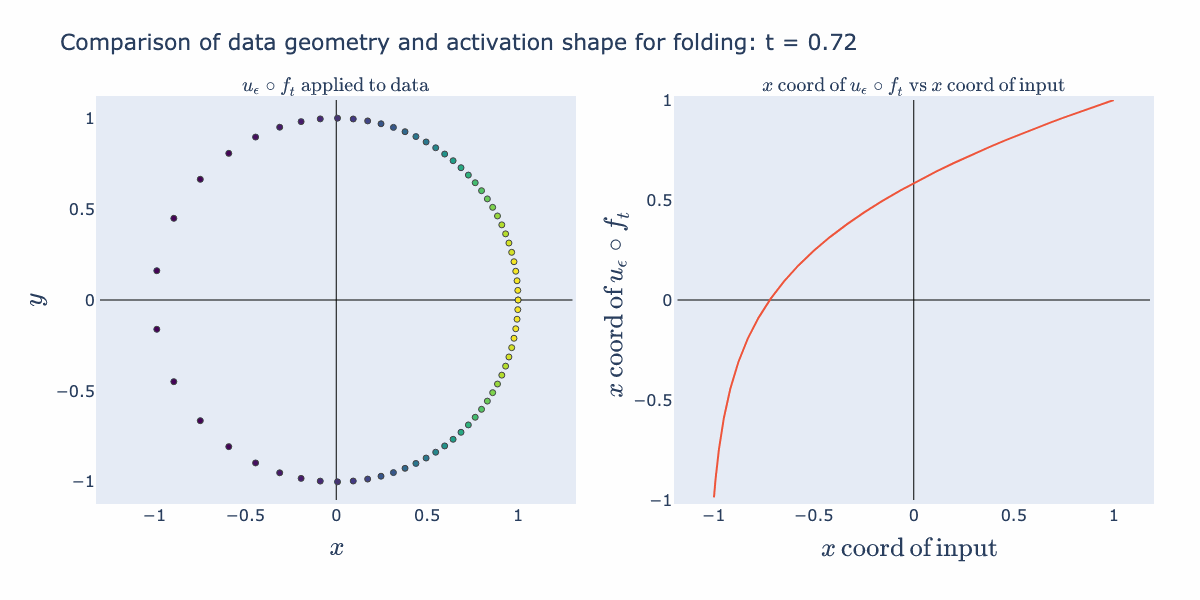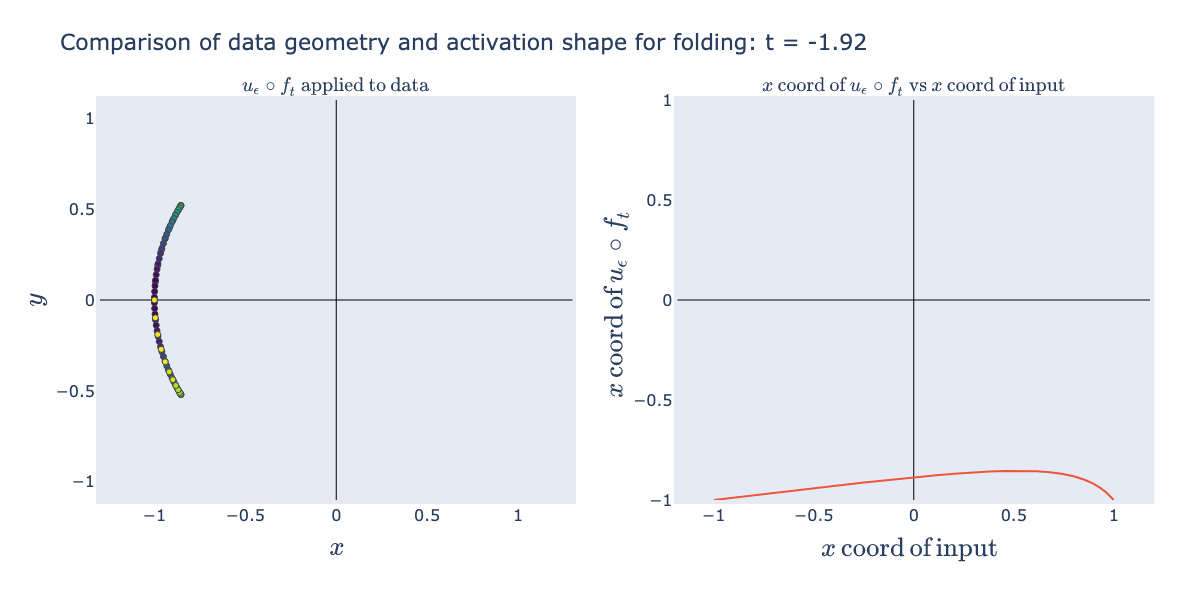
We can envision possible "semantic" uses for these geometric operations. Stretching can be used to perform an approximate "sign" operation (as in + or - sign). For example, it can take a continuous representation such as a numeric temperature and reduce it to two groups: "hot" vs "cold". Folding can be used to perform an approximate "absolute value" operation. For example, it can be used to separate out extremes from a continuous representation such as temperature and make two groups: "very hot"/"very cold" vs "typical temperature".
The right hand activation plot for folding looks pretty different from typical "activation functions" such as ReLUs or sigmoids. When is near 2 for example, points with coordinates near 1 and -1 both get mapped to 1, where points closer to 0 are relaxed away from 1. This gives a characteristic "divet" or, in the language of our semantic explanation, "absolute value" shape. We would not expect this from the 1D activation curve we originally drew. We can explain how this shape arises by instead looking at an activation surface for in 2D. The various 1D shapes arise as slices of this 2D activation surface. So its the combination
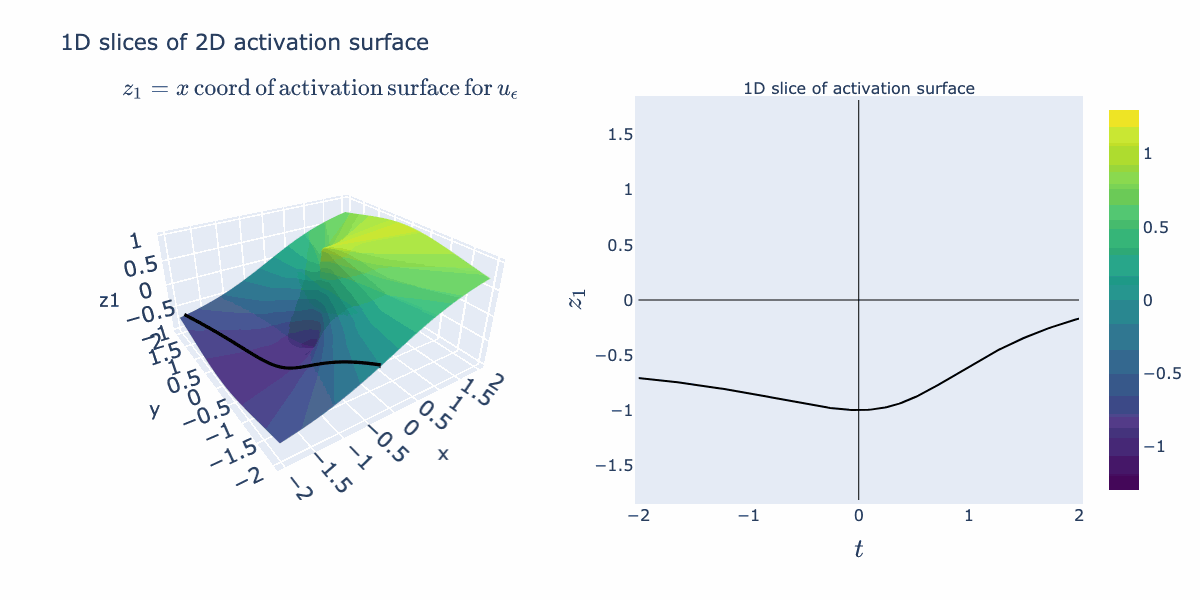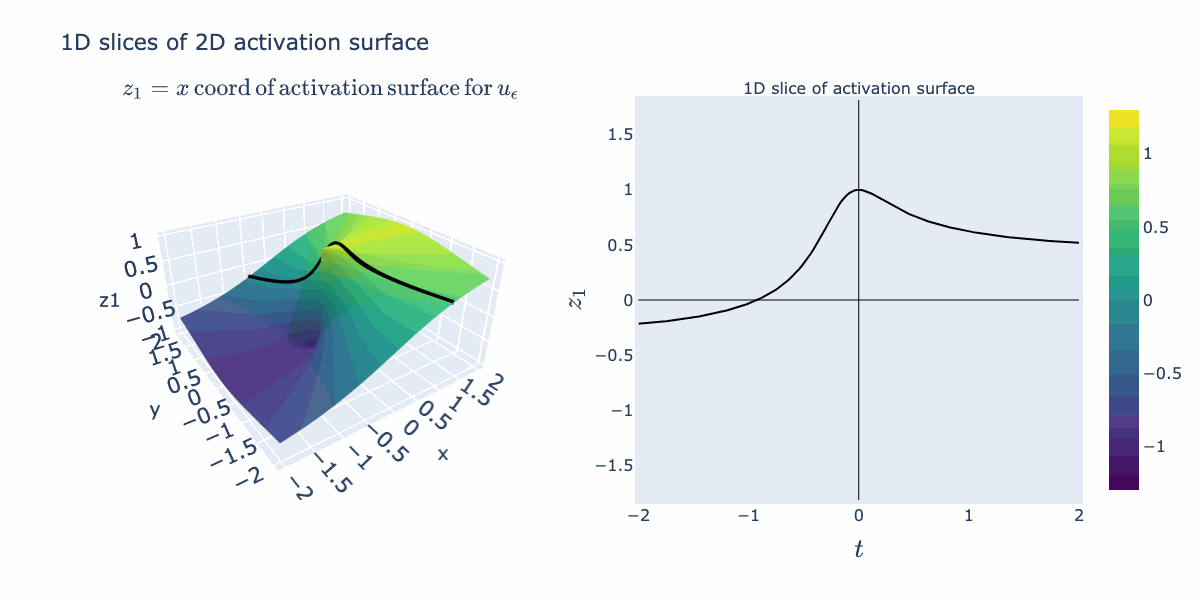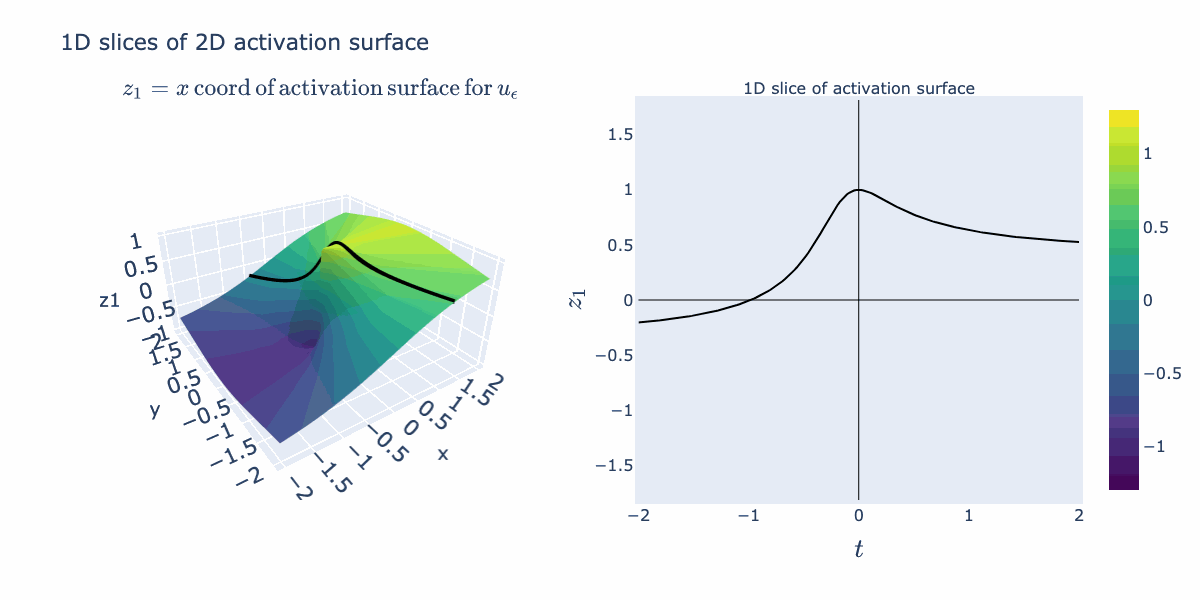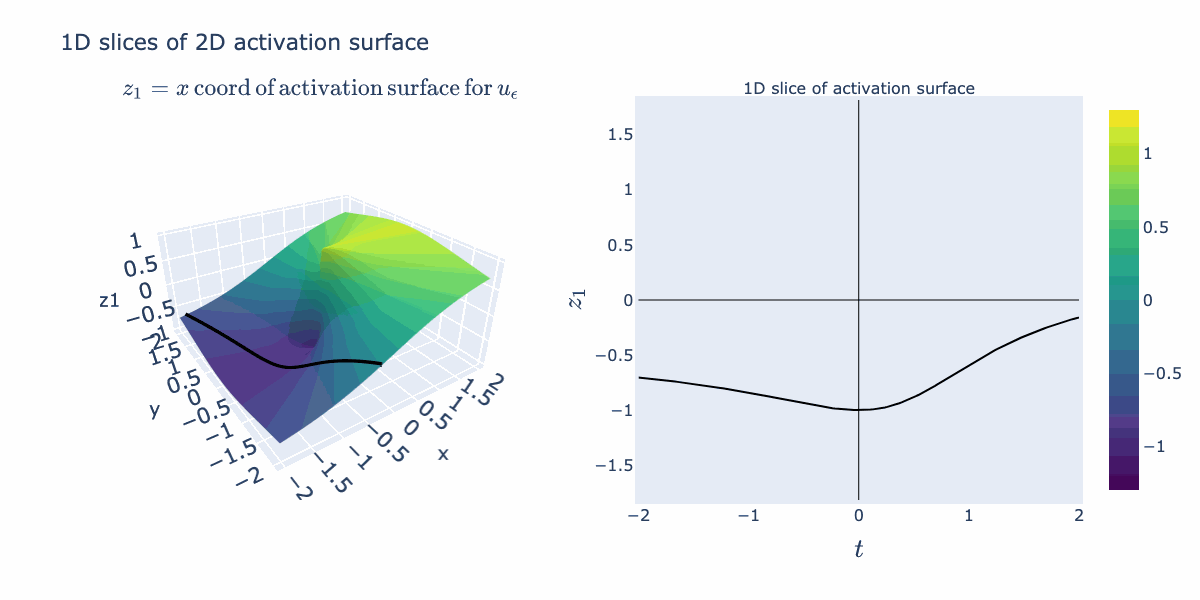
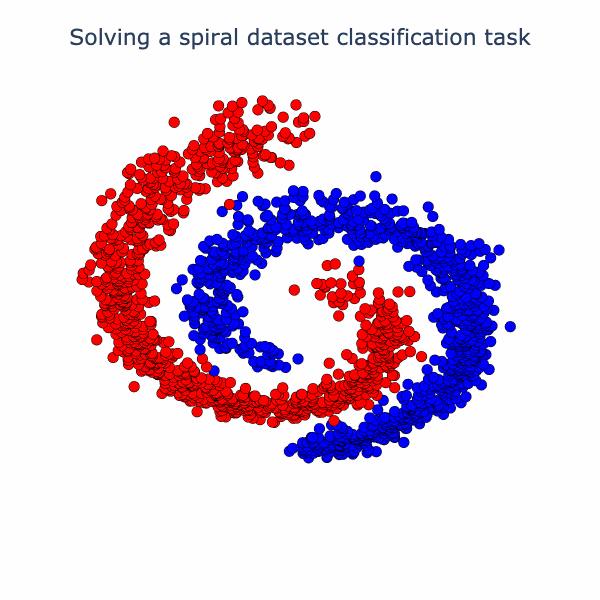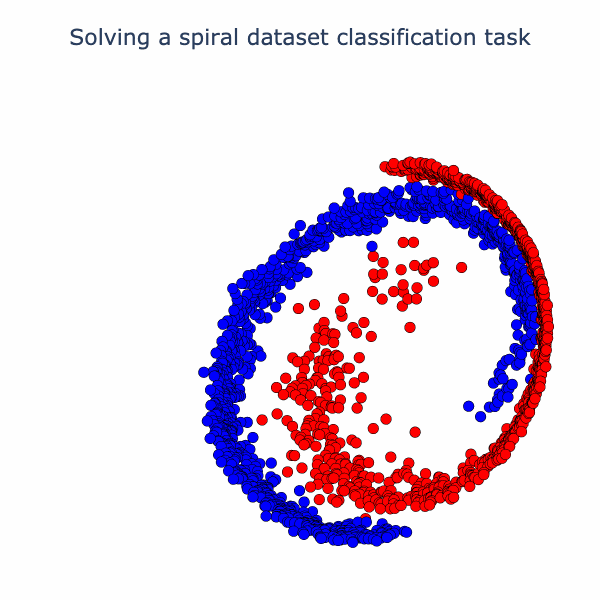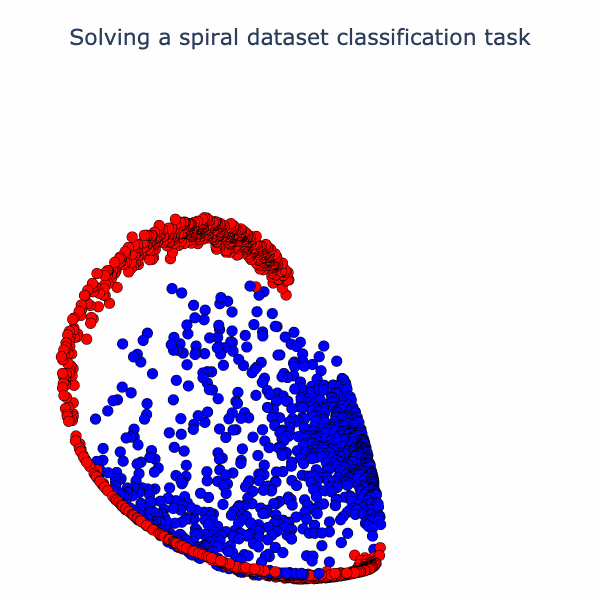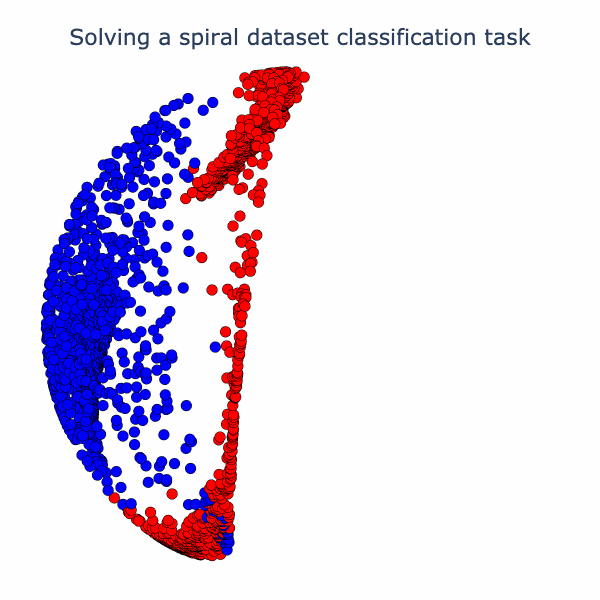
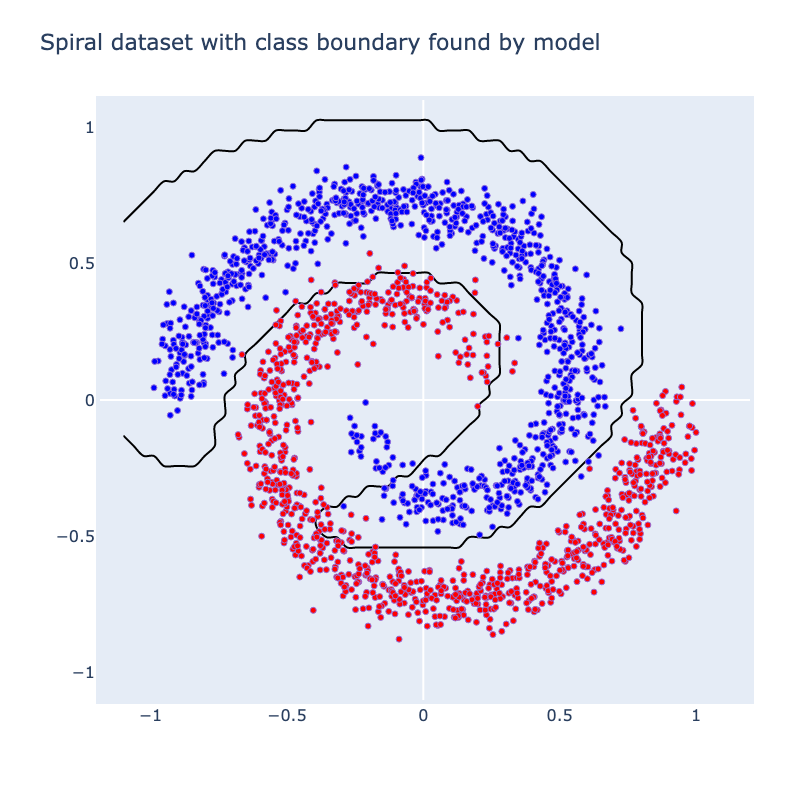
We can now bring our geometric intuition to bear on a small classification task. Below we have 2 classes forming a spiral. We apply a width 3 MLP with as the activation function (Linear->->Linear->->Linear). Below, we've sketched the classification boundary it finds after training.
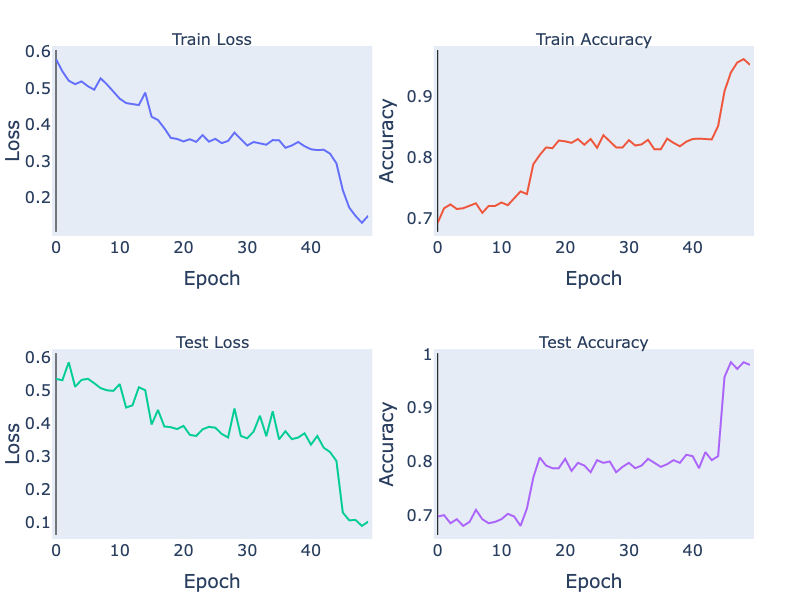
If we check out the loss and accuracy curves, we see evidence of a phase transition. We can speculate on why this occurs. Operations like folding in low dimensions can create sharp changes in the classifier output, since points can move with high-velocity relative to changes in weights (see the 1D folding diagram and note that right before the fold is complete some points are jumping very quickly from one side of the circle to the other). Another possibility is that there are regions in the loss landscape of low, but nonzero, gradients that must be traversed to get to a region of higher gradient where the phase transition happens. It's not clear that the folding and loss gradient explanations are mutually exclusive. In future work, we would like to thoroughly investigate this.
To understand the solution the model found to the task, we can embed the data in 3D and linearly interpolate from layer to layer. Specifically, we interpolate from the raw data to the first activation (output of first ) to the second activation (output of second ). At the end, we rotate the second activation output to aid in visualizing its 3D structure. The neural network has a final separating plane that it applies to construct the class boundary, and we can see roughly where this could go in the visual we have made.
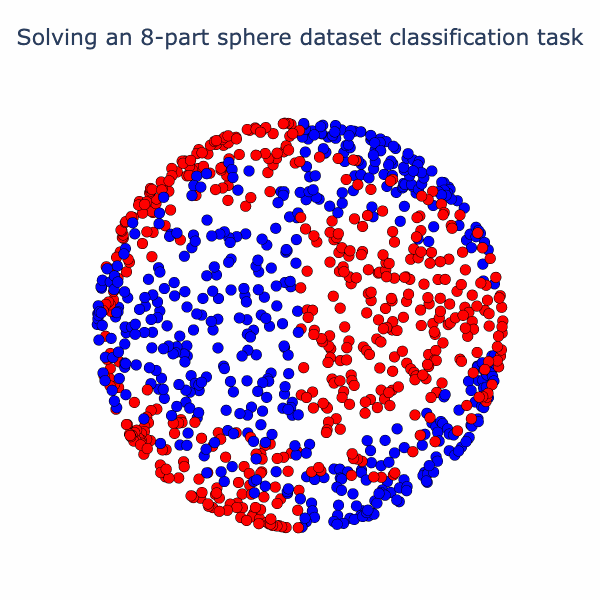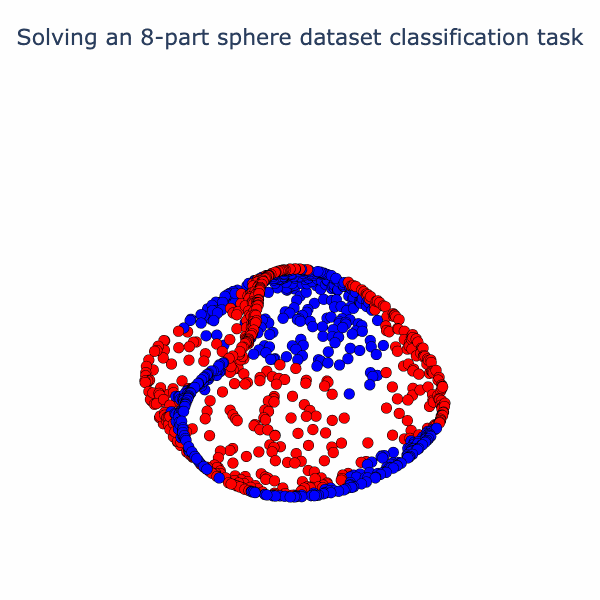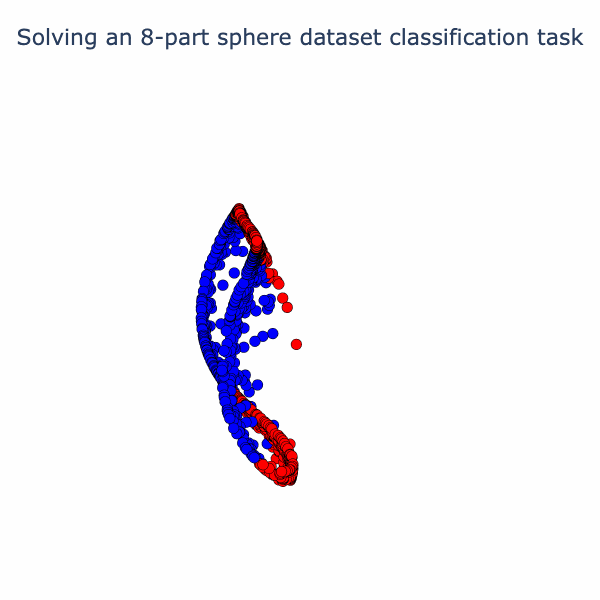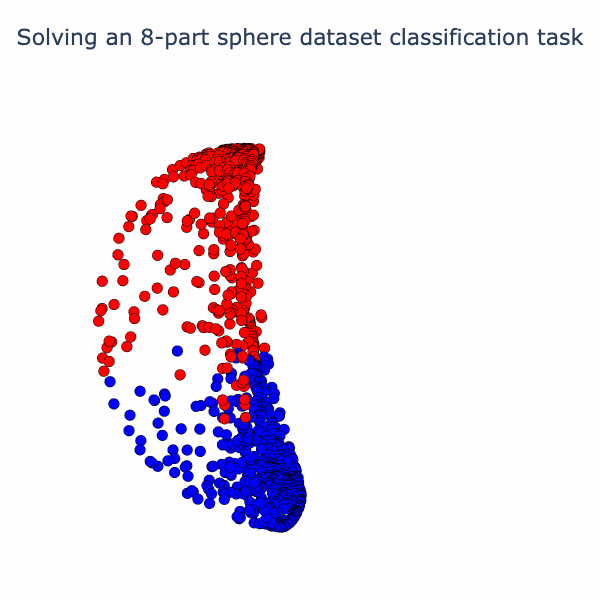
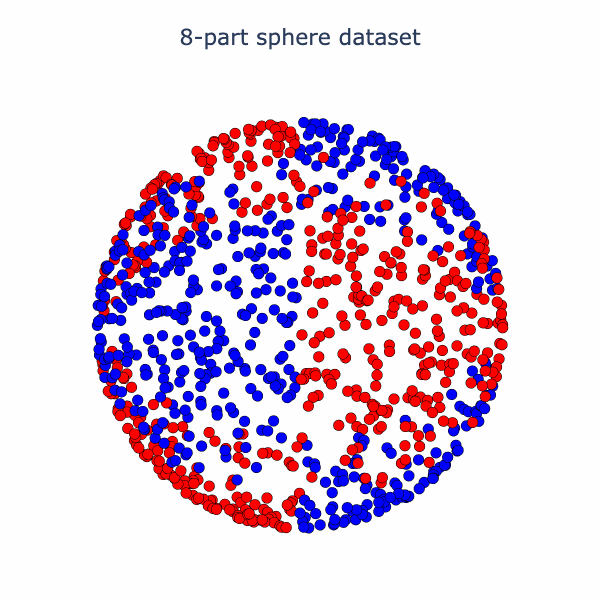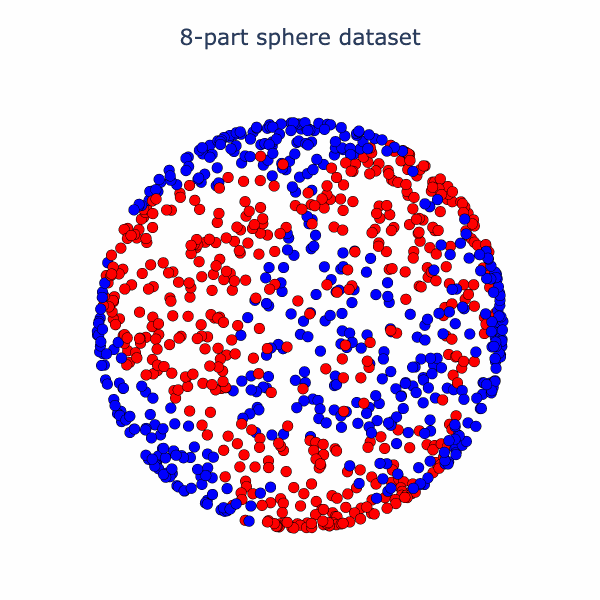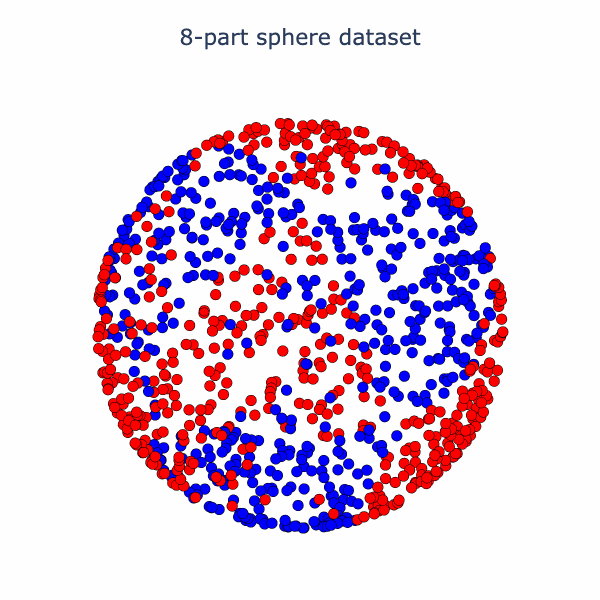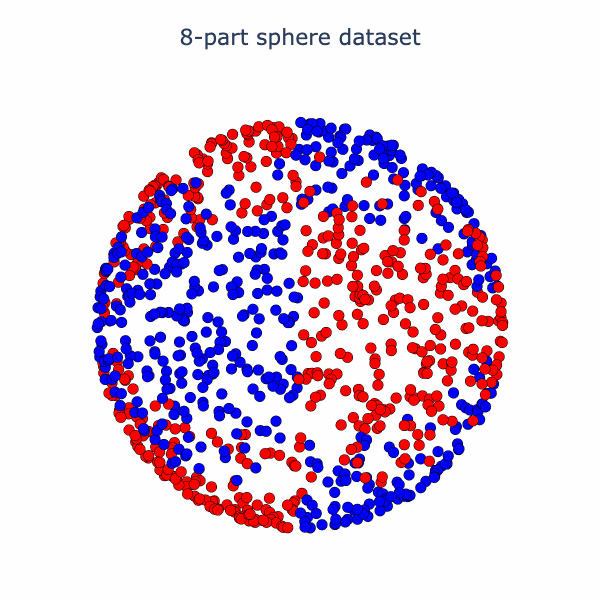
Essentially, the network has turned the dataset into one where there is a blue cap with a red ring around it, which is more-or-less linearly separable. We can have more fun with this set-up. Why not try a harder dataset with more layers? Let's consider this dataset of a sphere divided into 8-parts, where adjacent parts are in opposite classes:
If we run our model the final activation output looks like this:

Note that the two classes are now almost linearly separable. To get here, the model has to go through a number of phase transitions and the loss curve looks... weird.
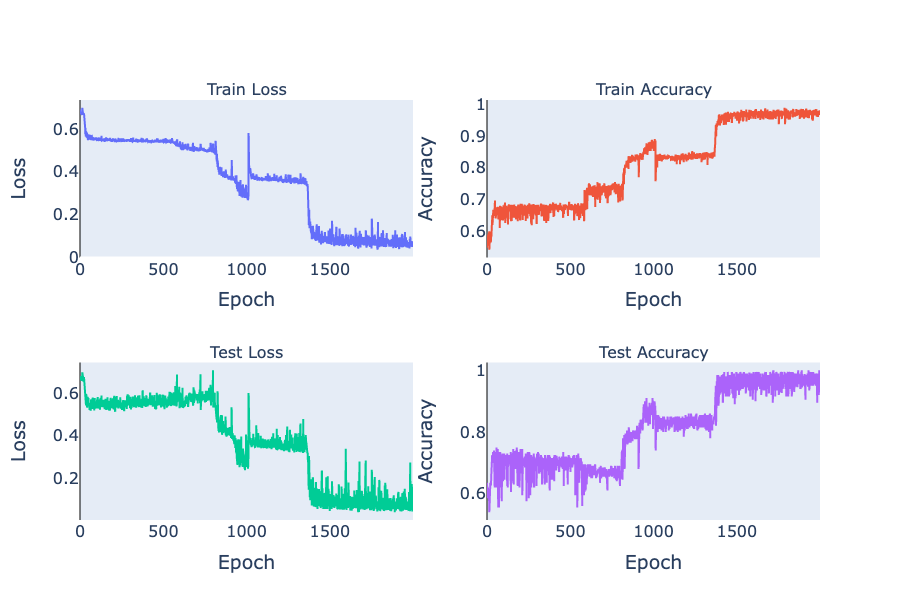
We can reuse our animation method from the spiral example to visualize the way the model is solving this task. We linearly interpolate from the input to the first activation, then the second activation, and so on.
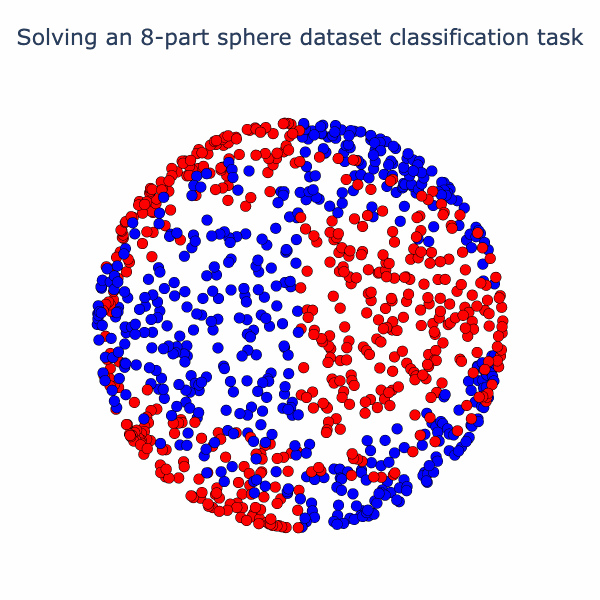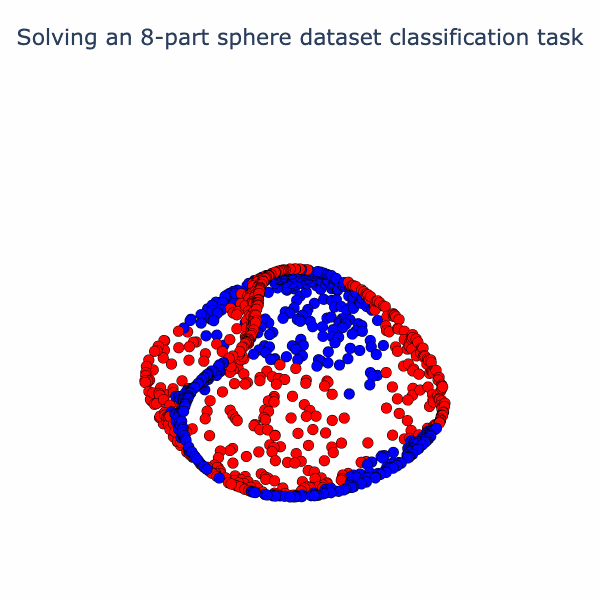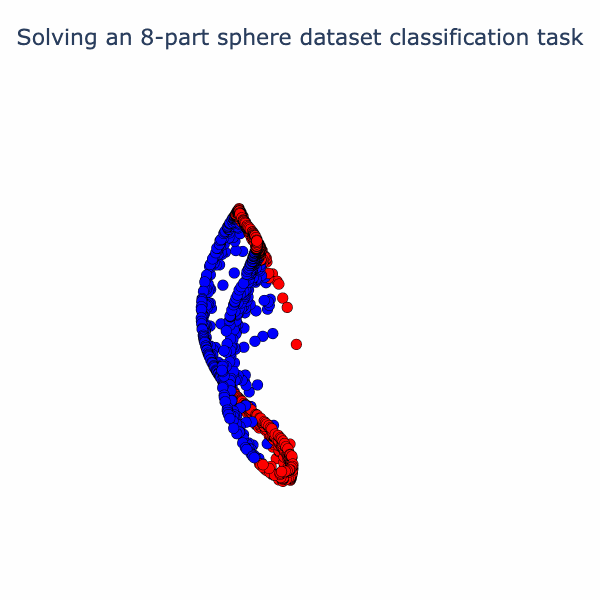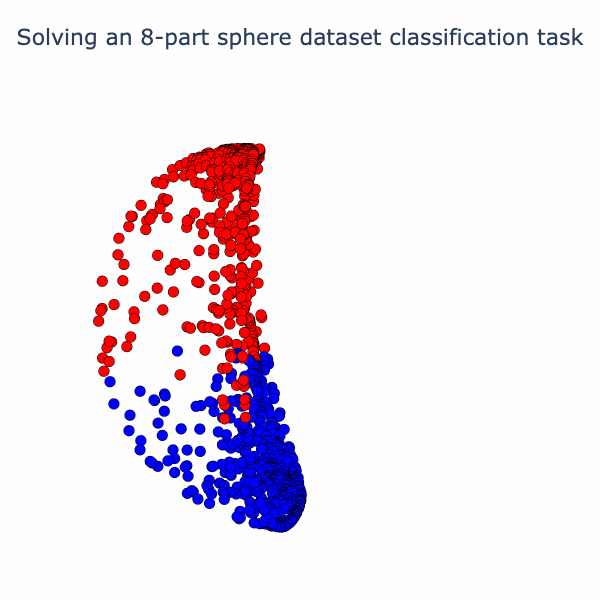
So the model has found an elegant way to fold up the sphere just by using linear and normalization operations! If you've found this interesting, we have a notebook with detailed math and code. In follow-up posts, we plan to look at some variations on this type of analysis and link it to interpreting large models.
From a mechanistic interpretability perspective, we cannot afford to ignore LayerNorm. We may consider finding alternatives to LayerNorm in order to produce models that are better understood by current mechanistic interpretability tools. In the big picture, however, we may have to grapple with the technical difficulties of LayerNorm either way. After all, the core obstacle in understanding LayerNorm is our lack of a theory for mechanistically interpreting non-linear activations. And as long as we cannot account for non-linearities in mechanistic interpretability, we will be unable to robustly explain and constrain the behavior of neural networks. The geometric perspective we have presented here is a step towards a mechanistic theory of non-linear activations that closes the gap in our understanding.
12 comments
Comments sorted by top scores.
comment by Jon Garcia · 2022-12-01T22:59:58.396Z · LW(p) · GW(p)
Awesome visualizations. Thanks for doing this.
It occurred to me that LayerNorm seems to be implementing something like lateral inhibition, using extreme values of one neuron to affect the activations of other neurons. In biological brains, lateral inhibition plays a key role in many computations, enabling things like sparse coding and attention. Of course, in those systems, input goes through every neuron's own nonlinear activation function prior to having lateral inhibition applied.
I would be interested in seeing the effect of applying a nonlinearity (such as ReLU, GELU, ELU, etc.) prior to LayerNorm in an artificial neural network. My guess is that it would help prevent neurons with strong negative pre-activations from messing with the output of more positively activated neurons, as happens with pure LayerNorm. Of course, that would limit things to the first orthant for ReLU, although not for GELU or ELU. Not sure how that would affect stretching and folding operations, though.
By the way, have you looked at how this would affect processing in a CNN, normalizing each pixel of a given layer across all feature channels? I think I've tried using LayerNorm in such a context before, but I don't recall it turning out too well. Maybe I could look into that again sometime.
Replies from: skosch↑ comment by skosch · 2022-12-02T01:19:12.693Z · LW(p) · GW(p)
That was my first thought as well. As far as I know, the most popular simple model used for this in the neuro literature, divisive normalization, uses similar but not quite identical formula. Different authors use different variations, but it's something shaped like
where is the unit's activation before lateral inhibition, adds a shift/bias, are the respective inhibition coefficients, and the exponent modulates the sharpness of the sigmoid (2 is a typical value). Here's an interactive desmos plot with just a single self-inhibiting unit. This function is asymmetric in the way you describe, if I understand you correctly, but to my knowledge it's never gained any popularity outside of its niche. The ML community seems to much prefer Softmax, LayerNorm et al. and I'm curious if anyone knows if there's a deep technical reason for these different choices.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2022-12-02T09:17:09.504Z · LW(p) · GW(p)
I think in feed-forward networks (i.e. they don't re-use the same neuron multiple times), having to learn all the inhibition coefficients is too much to ask. RNNs have gone in an out of fashion, and maybe they could use something like this (maybe scaled down a little), but you could achieve similar inhibition effects with multiple different architectures - LSTMs already have multiplication built into them, but in a different way. There is not a particularly deep technical reason for different choices.
comment by Adam Jermyn (adam-jermyn) · 2022-12-02T02:01:46.173Z · LW(p) · GW(p)
This is really interesting!
One question: do we need layer norm in networks? Can we get by with something simpler? My immediate reaction here is “holy cow layer norm is geometrically complicated!” followed by a desire to not use it in networks I’m hoping to interpret.
comment by Dennis Akar (British_Potato) · 2022-12-02T00:33:50.196Z · LW(p) · GW(p)
colab notebook
this interactive notebook
check out the notebook
notebook
First link is not like the others.
Replies from: EricWinsor↑ comment by Eric Winsor (EricWinsor) · 2022-12-02T00:47:27.591Z · LW(p) · GW(p)
Thanks for the catch!
comment by Aryan Bhatt (abhatt349) · 2023-03-28T05:45:04.341Z · LW(p) · GW(p)
Sorry for the mundane comment, but in the "Isolating the Nonlinearity" section of the colab notebook, you say
Note that a vector in dimensions with mean 0 has variance 1 if and only if it has length
I think you might've meant to say there instead of , but please do correct me if I'm wrong!!!
comment by Danylo Hlynskyi (danylo-hlynskyi) · 2023-12-18T12:33:28.422Z · LW(p) · GW(p)
you can solve MNIST with a LayerNorm MLP, for example
is there a paper for this or is this unpublished common knowledge result?
comment by nulldippindots · 2022-12-02T04:49:50.209Z · LW(p) · GW(p)
Great post! One question: isn't LayerNorm just normalizing a vector?
Replies from: abhatt349↑ comment by Aryan Bhatt (abhatt349) · 2023-03-28T19:39:08.664Z · LW(p) · GW(p)
From the "Conclusion and Future Directions" section of the colab notebook:
Most of all, we cannot handwave away LayerNorm as "just doing normalization"; this would be analogous to describing ReLU as "just making things nonnegative".
I don't think we know too much about what exactly LayerNorm is doing in full-scale models, but at least in smaller models, I believe we've found evidence of transformers using LayerNorm to do nontrivial computations[1].
- ^
I think I vaguely recall something about this in either Neel Nanda's "Rederiving Positional Encodings" stuff, or Stefan Heimersheim + Kajetan Janiak's work on 4-layer Attn-only transformers [LW · GW], but I could totally be misremembering, sorry.