EIS IX: Interpretability and Adversaries
post by scasper · 2023-02-20T18:25:43.641Z · LW · GW · 8 commentsContents
The studies of interpretability and adversaries are inseparable. 1. More interpretable networks are more adversarially robust and more adversarially robust networks are more interpretable. 2. Interpretability tools can and should be used to guide the design of adversaries. 3. Adversarial examples can be useful interpretability tools. 4. Mechanistic interpretability and mechanistic adversarial examples are similar approaches for addressing deception and other insidious misalignment failures. Are adversaries features or bugs? Exhibit A: Robustness <--> interpretability Exhibit B: Adversarial transferability Exhibit C: Adversarial training and task performance Exhibit D: Generalization from training on nonrobust features Exhibit E: Genuine nonrobust features Exhibit F: The superposition perspective Exhibit G: Evidence from the neural tangent kernel What does it all mean for interpretability? Questions None 8 comments
Part 9 of 12 in the Engineer’s Interpretability Sequence [? · GW].
Thanks to Nikolaos Tsilivis for helpful discussions.
The studies of interpretability and adversaries are inseparable.
There are several key connections between the two. Some works will be cited below, but please refer to page 9 of the Toward Transparent AI survey (Räuker et al., 2022) for full citations. There are too many to be worth the clutter in this post.
1. More interpretable networks are more adversarially robust and more adversarially robust networks are more interpretable.
The main vein of evidence on this topic comes from a set of papers which study how regularizing feature attribution/saliency maps to make them more clearly highlight specific input features has the effect of making networks more robust to adversaries. There is also some other work showing the reverse -- that adversarially robust networks tend to have more lucid attributions. There is also some work showing that networks which emulate certain properties of the human visual system are also more robust to adversaries and distribution shifts (e.g. Ying et al. (2022)).
Adversarial training is a good way of making networks more internally interpretable. One particularly notable work is Engstrom et al., (2019) who found striking improvements in how much easier it was to produce human-describable visualizations of internal network properties. Although they stopped short of applying this work to an engineering task, the paper seems to make a strong case for how adversarial training can improve interpretations. Adversarially trained networks also produce better representations for transfer learning, image generation, and modeling the human visual system.
Finally, some works have found that lateral inhibition and second-order optimization have been found to improve both interpretability and robustness.
2. Interpretability tools can and should be used to guide the design of adversaries.
This is one of the three types of rigorous evaluation methods for interpretability tools discussed in EIS III. Showing that an interpretability tool helps us understand a network well enough to exploit it is good evidence that it can be useful.
3. Adversarial examples can be useful interpretability tools.
Adversaries always reveal information about a network, even if it’s hard to describe a feature that fools it in words. However, a good amount of recent literature has revealed that studying interpretable adversaries can lead to useful, actionable insights. In some previous work (Casper et al., 2021), some coauthors and I argue for using “robust feature-level adversaries” as a way to produce attacks that are human-describable and likely to lead to a generalizable understanding. Casper et al, (2023) more rigorously tests methods like this.
4. Mechanistic interpretability and mechanistic adversarial examples are similar approaches for addressing deception and other insidious misalignment failures.
Hubinger (2020) discussed 11 proposals for building safe advanced AI, and all 11 explicitly call for the use of interpretability tools or (relaxed) adversarial training [AF · GW] for inner alignment. This isn’t a coincidence because these offer the only types of approaches that can be useful for fixing insidiously aligned models. Recall from the previous post that an engineer might understand insidious misalignment failures as ones in which the inputs that will make a model exhibit misaligned behavior are hard to find during training, but there exists substantial neural circuitry dedicated to the misaligned behavior. Given this, methods that work with model internals like mechanistic interpretability and mechanistic adversaries will be some of the few viable approaches we have for addressing deceptive alignment.
Are adversaries features or bugs?
TL;DR -- Definitively, they are features.
For about a decade, it has been well-known that surprisingly small adversarial perturbations to inputs can make neural networks misbehave. At this point, we are very used to the fact that adversarial examples exist and work the way they do, but it’s worth taking a step back every once in a while and appreciating just how weird adversaries are. Consider this classic example of a panda from Goodfellow et al. (2014). This perturbation is imperceptible to a human and, when exaggerated, looks like confettified vomit, yet it causes the network to confidently misclassify this panda as a gibbon.
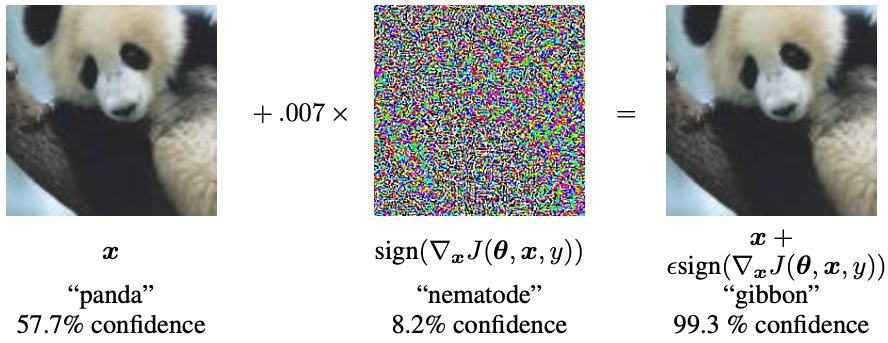
So what is going on? Why does this particular perturbation do this? Nakkiran (2019) describes two possible worlds.
World 1 [(Bug world)]: Adversarial examples exploit directions irrelevant for classification (“bugs”). In this world, adversarial examples occur because classifiers behave poorly off-distribution, when they are evaluated on inputs that are not natural images. Here, adversarial examples would occur in arbitrary directions, having nothing to do with the true data distribution.
World 2 [(Feature world)]: Adversarial examples exploit useful directions for classification (“features”). In this world, adversarial examples occur in directions that are still “on-distribution”, and which contain features of the target class. For example, consider the perturbation that makes an image of a dog to be classified as a cat. In World 2, this perturbation is not purely random, but has something to do with cats. Moreover, we expect that this perturbation transfers to other classifiers trained to distinguish cats vs. dogs.
Which are we in? This post will review all related findings on the matter of which I know. It will conclude that we’re probably somewhere in between, but mostly in a “features” world and that this does not bode so well for approaches to interpretability that hinge on human intuition.
Exhibit A: Robustness <--> interpretability
As discussed early in this post, techniques for improving adversarial robustness and intrinsic interpretability in neural networks have an almost uncanny tendency to also be techniques for the other.
Bug world view: Proponents of this view can argue that tools for robustness and intrinsic interpretability are regularizers and that both robustness and interpretability are consequences of regularization.
Feature world view: Proponents of this view can argue that robustness and interpretability are so closely connected because the nonrobust and noninterpretable features used by networks are (usually) the same ones.
Verdict: Inconclusive.
Exhibit B: Adversarial transferability
It is well known that adversarial examples transfer between models trained on similar data, even between different architectures (Liu et al., 2016). This has important implications for black box attacks, but unfortunately, it doesn’t seem to give strong evidence in one way or another about whether we are in a bug or feature world.
Bug world view: Believers in the bug world can point out that while transfer happens, it’s not usually entirely reliable and doesn’t always work so well. And transfer might not happen because the adversaries are meaningful but instead might result from networks learning similar failure modes as a result of being trained on the same task. In the same way that two students might have the same misconception after class due to how the lesson was taught, networks might have the same bugs after training due to the particular task.
Feature world view: This is a natural implication of the feature hypothesis.
Verdict: Inconclusive.
Exhibit C: Adversarial training and task performance
To date, adversarial training is the best general defense we have against adversarial examples. Unfortunately, adversarial training seemed to harm performance on clean data (Tspiras et al., 2019). Some more recent works have found that doing adversarial training in a less heavy-handed way can help to fix this problem, but only partially (Wang et al., 2019; Cheng et al., 2020; Altinisik et al., 2022).
Bug world view: Proponents of this view argue that adversarial training harms clean performance simply because it is a regularizer.
Feature world view: This is a natural implication of the feature hypothesis.
Verdict: Inconclusive.
Exhibit D: Generalization from training on nonrobust features
Ilyas et al. (2019) was titled Adversarial Examples Are Not Bugs, They Are Features. The authors conducted an interesting set of experiments to argue for the feature hypothesis. They constructed training datasets full of examples with targeted adversarial perturbations and assigned each image the label associated with the target class instead of the source class. To a human, this dataset would seem full of images with incorrect labels. However, they found that networks trained on this dataset were able to generalize surprisingly well to unperturbed data.
Bug world view: This is difficult to explain using the bug world hypothesis. Goh (2019) finds some evidence that in some experiments from Ilyas et al. (2019), some of the results can be explained by “a kind of ‘robust feature leakage’ where the model picks up on faint robust cues in the attacks,” but this evidence is extremely limited.
Feature world view: This is a natural implication of the feature hypothesis.
Verdict: Strong evidence for the feature hypothesis.
Exhibit E: Genuine nonrobust features
Normally, adversarial examples transfer (Liu et al., 2016) and seem to be useful for generalization (Ilyas et al., 2019). But Nakkiran (2019) introduced a method for designing ones that seem to truly just be bugs. Instead of training adversarial examples to simply fool a network, Nakkiran (2019) trained them to fool a network but not fool other identically trained networks. The result was perturbations that showed almost no evidence of transferability or generalizability.
Bug world view: This is an existence proof for adversarial perturbations that seem like genuine bugs.
Feature world view: The fact that these buggy adversarial examples do not show up by default and instead require an additional term in the loss function suggests that we may be in more of a feature world than a bug world.
Verdict: This evidence is informative and suggests that neither the bug nor feature world views are 100% correct. But the fact that genuinely buggy adversaries do not tend to occur by default somewhat supports the feature hypothesis.
Exhibit F: The superposition perspective
Elhage et al. (2022) study superposition and argue that it is useful for helping neural networks pack more information about more features into a limited number of neurons during forward passes through the network. They present some evidence that connects the vulnerability of a network to adversarial attacks to a measure of how many features a network is packing into a given layer.
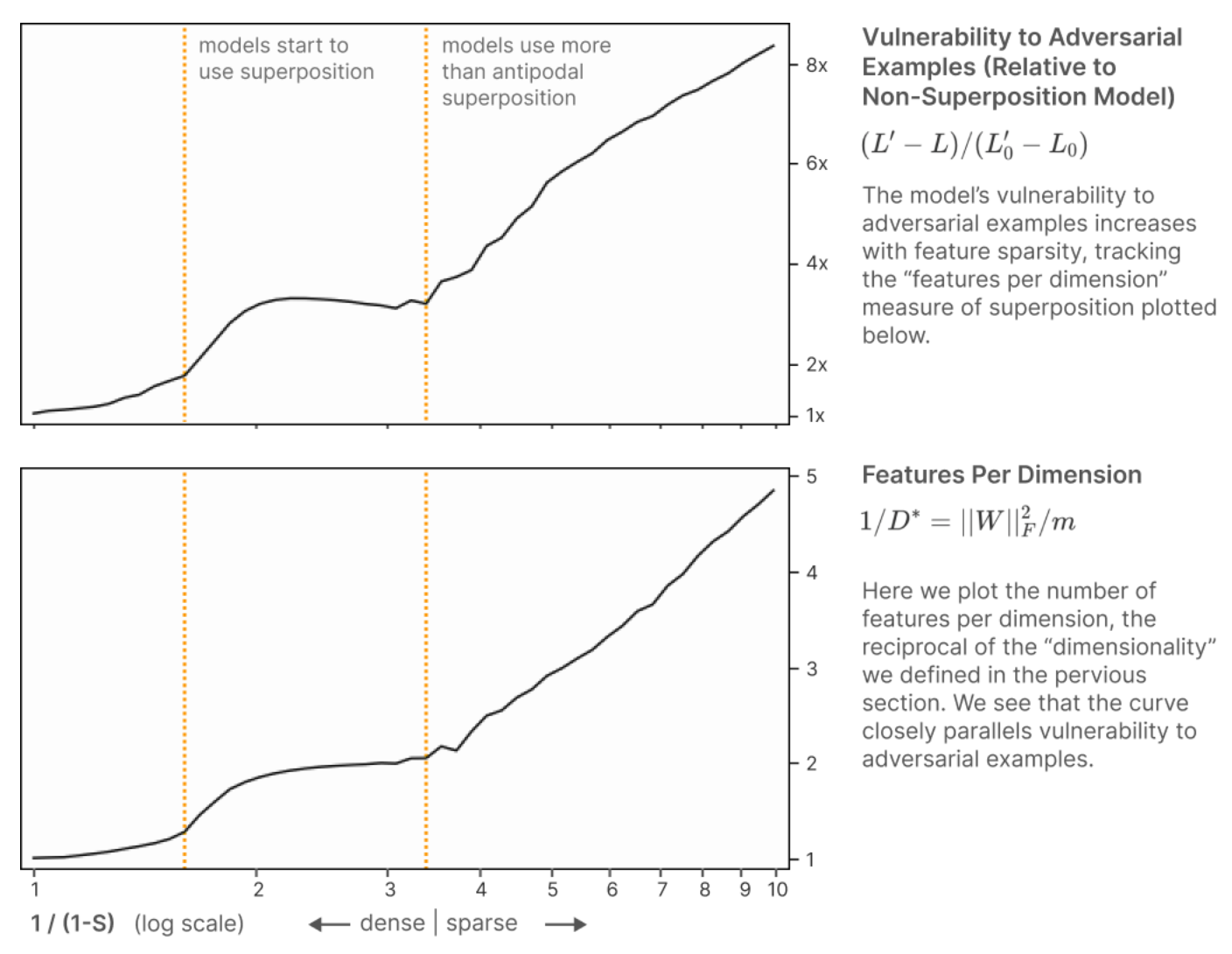
From Elhage et al. (2022)
Given this, one may speculate that since superposition is useful for neural networks, maybe adversarial examples are just a price to pay for it. Maybe adversarial examples may just be a buggy epiphenomenon from usefully packing many features into a fixed number of neurons.
But there may be some troubles with this interpretation of these results.
First, this experiment only shows correlation. There is an obvious possible confounder that can explain the results from the perspective of the feature hypothesis. Networks that have to learn more features may become more adversary-prone simply because the adversary can leverage more features which are represented more densely.
Second, the measure of “features per dimension” used by Elhage et al. (2022) might be misleading. See the paper for details of how they arrived at this quantity. But as shown in the figure above, “features per dimension” is defined as the Frobenius norm of the weight matrix before the layer divided by the number of neurons in the layer. But there is a simple sanity check that this doesn’t pass. In the case of a ReLU network without bias terms, multiplying a weight matrix by a constant factor will cause the “features per dimension” to be increased by that factor squared while leaving the activations in the forward pass unchanged up to linearity until a non-ReLU operation (like a softmax) is performed. And since each component of a softmax’s output is strictly increasing in that component of the input, scaling weight matrices will not affect the classification.
Third, network weight initialization scale is typically varied as a function of layer width. This is standard in PyTorch and Keras/TensorFlow. But I could not find details from Elhage et al. (2022) about how they initialized the networks. If anyone knows these details, I would appreciate comments about them. It would be interesting to see the robustness of a network as a function of some factor by which the number of neurons and the number of features are jointly varied while holding the variance of weight initialization constant, but it is not clear whether or not this is the experiment that Elhage et al. (2022) did.
Fourth, and most importantly, if superposition happens more in narrower layers, and if superposition is a cause of adversarial vulnerabilities, this would predict that deep, narrow networks would be less adversarially robust than shallow, wide networks that achieve the same performance and have the same number of parameters. However, Huang et al., (2022) found the exact opposite to be the case.
Bug world view: The superposition hypothesis can explain the results from Elhage et al. (2022) well but not the results from Huang et al., (2022).
Feature world view: Confounders explain the results from Elhage et al. (2022) while the feature hypothesis explains the results from Huang et al., (2022).
Verdict: Moderate evidence in favor of the feature hypothesis.
Exhibit G: Evidence from the neural tangent kernel
Since 2018, much work has been done in deep learning theory that attempts to explain neural networks in terms of kernel machines. Infinitely wide neural networks with infinitesimally small weight initializations are equivalent to kernel machines that use a gaussian kernel (Jacot et al., 2018). And lots of neural networks today are wide enough and initialized with a small enough variance that the kernel approximation is a decent one. When making this approximation, the eigenvectors of the kernel matrix reveal features of the dataset that are useful yet non-interpretable (Tsilivis and Kempe, 2022). This only involves the dataset and the kernel machine approximation – not any particular network!
Bug world view: A proponent of this view can argue that this is based on an approximation just because these features exist doesn’t mean that the networks use them.
Feature world view: This is a natural implication of the feature hypothesis.
Verdict: Weak evidence for the feature hypothesis.
What does it all mean for interpretability?
The evidence overwhelmingly shows that we live in a world in which there exist useful yet nonrobust, noninterpretable features learned by neural networks – at least in the vision domain. This is not great news for approaches to interpretability that hinge on humans developing intuitive understandings of networks. It also suggests a fairly fundamental tradeoff between performance and robustness/interpretability. It might be the case that no matter how hard a human tries to develop a prosaic understanding of what a nonrobust network is doing, they may never fully succeed. This does not mean it will be impossible to fully explain what networks are doing, but it probably will be impossible via features that humans can intuitively understand.
The existence of useful nonrobust features should be added to the arguments from EIS VI against counting on human-driven mechanistic interpretability and in favor of more intrinsic interpretability and robustness work.
Questions
- Do you know of any other interesting connections between interpretability and adversaries research?
- Do you know of any other evidence about whether we are in a bug world or a features world?
8 comments
Comments sorted by top scores.
comment by Adam Jermyn (adam-jermyn) · 2023-05-17T08:01:22.229Z · LW(p) · GW(p)
Second, the measure of “features per dimension” used by Elhage et al. (2022) might be misleading. See the paper for details of how they arrived at this quantity. But as shown in the figure above, “features per dimension” is defined as the Frobenius norm of the weight matrix before the layer divided by the number of neurons in the layer. But there is a simple sanity check that this doesn’t pass. In the case of a ReLU network without bias terms, multiplying a weight matrix by a constant factor will cause the “features per dimension” to be increased by that factor squared while leaving the activations in the forward pass unchanged up to linearity until a non-ReLU operation (like a softmax) is performed. And since each component of a softmax’s output is strictly increasing in that component of the input, scaling weight matrices will not affect the classification.
It's worth noting that Elhage+2022 studied an autoencoder with tied weights and no softmax, so there isn't actually freedom to rescale the weight matrix without affecting the loss in their model, making the scale of the weights meaningful. I agree that this measure doesn't generalize to other models/tasks though.
They also define a more fine-grained measure (the dimensionality of each individual feature) in a way that is scale-invariant and which broadly agrees with their coarser measure...
Replies from: scaspercomment by Charlie Steiner · 2023-02-27T19:34:21.949Z · LW(p) · GW(p)
The Exhibits might have been a nice place to use probabilistic reasoning. I too am too lazy to go through and try to guesstimate numbers though :)
comment by Maxwell Adam (intern) · 2024-12-06T00:29:50.321Z · LW(p) · GW(p)
Networks that have to learn more features may become more adversary-prone simply because the adversary can leverage more features which are represented more densely.
Also, in the top figure the loss is 'relative to the non-superposition model', but if I'm not mistaken the non-superposition model should basically be perfectly robust. Because it's just one layer, its Jacobian would be the identity, and because the loss is MSE, any perturbation to the input would be perfectly reflected only in the correct output feature, meaning no change in loss whatsoever. It's only when you introduce superposition that any change to the input can change the loss (as features actually 'interact').
comment by Zeyu Qin (zeyu-qin) · 2023-09-24T15:21:06.596Z · LW(p) · GW(p)
World 2 [(Feature world)]: Adversarial examples exploit useful directions for classification (“features”). In this world, adversarial examples occur in directions that are still “on-distribution”, and which contain features of the target class. For example, consider the perturbation that makes an image of a dog to be classified as a cat. In World 2, this perturbation is not purely random, but has something to do with cats. Moreover, we expect that this perturbation transfers to other classifiers trained to distinguish cats vs. dogs.
I believe that when discussing bugs or features, it is only meaningful to focus on targeted attacks.
comment by Zeyu Qin (zeyu-qin) · 2023-09-24T15:15:21.827Z · LW(p) · GW(p)
Bug world view: Proponents of this view can argue that tools for robustness and intrinsic interpretability are regularizers and that both robustness and interpretability are consequences of regularization.
I am unsure of the meaning of this statement. What do you mean by "regularizers" that you mentioned?
comment by Xander Davies (xanderdavies) · 2023-05-16T20:08:40.009Z · LW(p) · GW(p)
Fourth, and most importantly, if superposition happens more in narrower layers, and if superposition is a cause of adversarial vulnerabilities, this would predict that deep, narrow networks would be less adversarially robust than shallow, wide networks that achieve the same performance and have the same number of parameters. However, Huang et al., (2022) found the exact opposite to be the case.
I'm not sure why the superposition hypothesis would predict that narrower, deeper networks would have more superposition than wider, shallower networks. I don't think I've seen this claim anywhere—if they learn all the same features and have the same number of neurons, I'd expect them to have similar amounts of superposition. Also, can you explain how the feature hypothesis "explains the results from Huang et al."?
More generally, I think superposition existing in toy models provides a plausible rational for adversarial examples both being very common (even as we scale up models) and also being bugs. Given this and the Elhage et al. (2022) work (which is bayesian evidence towards the bug hypothesis, despite the plausibility of confounders), I'm very surprised you come out with "Verdict: Moderate evidence in favor of the feature hypothesis."
Replies from: scasper↑ comment by scasper · 2023-05-25T16:26:08.930Z · LW(p) · GW(p)
We talked about this over DMs, but I'll post a quick reply for the rest of the world. Thanks for the comment.
A lot of how this is interpreted depends on what the exact definition of superposition that one uses and whether it applies to entire networks or single layers. But a key thing I want to highlight is that if a layer represents a certain set amount of information about an example, then they layer must have more information per neuron if it's thin than if it's wide. And that is the point I think that the Huang paper helps to make. The fact that deep and thin networks tend to be more robust suggests that representing information more densely w.r.t. neurons in a layer does not make these networks less robust than wide shallow nets.