Hardware for Transformative AI
post by MrThink (ViktorThink) · 2021-06-22T18:13:45.406Z · LW · GW · 7 commentsContents
Background Cost of GPT3 as reference Cost of a theoretical 17 trillion transformative AI Hardware availability as a potential bottleneck for inference Computational cost as a potential bottleneck for inference None 7 comments
I recently saw A breakdown of AI Chip companies linked on LessWrong. I thought it was interesting, and it inspired me to add my 2 cents on what AI chips might be used in the case of transformative AI in the relatively near future.
Background
Undoubtedly Nvidia is the leader when it comes to AI chips, by far Nvidia GPUs are the most common way of training large neural nets. For example GPT-3 was trained on Nvidia V100 GPUs.
According to A breakdown of ai chip companies, Nvidia’s GPUs aren’t that well optimized for AI, and thus for training the performance is way worse than theoretical teraflops achieved (10x worse according to the article, but this seems like an exaggeration, since according to this article the idle time was around 70% for GPU cores, so about 3.3x worse than theoretical performance).
The second most used harware for AI are Google tensor processing units (TPUs), which is specialized for AI. I found this table useful, comparing cost of training a small convolutional neural net:
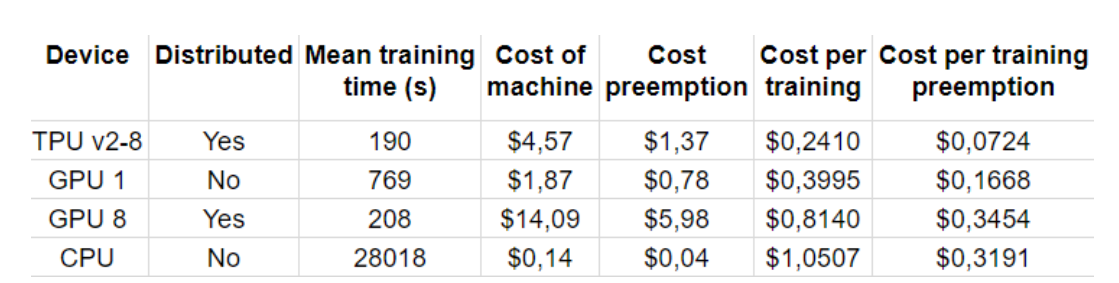
In this case TPU was considerably cheaper, but I believe the relative costs vary significantly depending on training task and hyperparameters.
The drawbacks with TPUs is that you can’t buy them (only rent from google) and code has to be compiled in a specific way to be efficient, which decreases flexibility when using TPUs.
Cost of GPT3 as reference
GPT-3 is the most impressive language model to date, and it has about 175 billion parameters. The cost of training was about 12 million, and according to Estimating GPT3 API cost, a request to generate 1024 tokens (about 700 words) costs about 0.001 USD assuming constant usage.
Cost of a theoretical 17 trillion transformative AI
I once read an estimate that 5x-ing the size of GPT3, would 10x the training cost. I can’t find the source now, so if anyone has a better estimate, please let me know.
(Note: Thank you Daniel Kokotajlo for pointing out my math mistake, I have updated the calculations as of below)
Number of 5 doubles needed to 100x parameters: 5^n=100 => n=log(100)/log(5)=2.86
Increase of training cost: 10^2.86=727
Training a 17 trillion parameter GPT model would then cost around 727 times more than the cost of GPT-3, which would give a cost of around 8,7 billion USD. Of course bigger models alone without software improvements might not result in transformative AI.
With 100x parameters, the cost for inference (using the model) would increase roughly 100x also. Giving a cost of about 0.1 USD per 700 words generated. This seems very cheap compared to human labour. Even if the AI does a billion tasks like this per day, it would only land at around 36.5 billion USD per year in computational cost.
Hardware availability as a potential bottleneck for inference
Hardware might very well be a bottleneck for deploying the transformative AI large scale, even if done over a period of multiple years. Nvidia’s revenue 2020 was just under 11 billion USD, and there is already a chip shortage. It does not seem likely then that they would be able to meet demand for tens of billions in GPUs anytime soon.
In the event of hardware as a bottleneck, the transformative AI would likely be adapted to run on many different types of hardware, including Google TPUs and maybe GPUs from other companies such as AMD.
One interesting idea is that decentralized computation might be possible to use, especially if a crypto crash would send miners looking for alternative ways to use their GPUs. There are several companies working on this, however I’ve not seen it done with any success yet.
Computational cost as a potential bottleneck for inference
If the computational cost is close to the cost of human labour in many cases, specialized chips are more likely to play a major role. Since there is probably only one or a few transformative AIs, the AI chips they use wouldn’t actually have to be particularly flexible or easy to use, it just has to be cheap.
7 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-06-23T09:02:35.862Z · LW(p) · GW(p)
I once read an estimate that 5x-ing the size of GPT3, would 10x the training cost. I can’t find the source now, so if anyone has a better estimate, please let me know. Which means training a 17 trillion parameter GPT model would cost around 25 times more than the cost of GPT-3, which would give a cost of around 300 million USD.
Isn't that math wrong? 17 trillion parameters is 100x more than GPT-3, so the cost should be at least 100x higher, so if the cost is $12M now it should be at least a billion dollars. I think it would be about $3B. It would probably cost a bit more than that since the scaling law will probably bend soon and more data will be needed per parameter. Also there may be inefficiencies from doing things at that scale. I'd guess maybe $10B give or take an order of magnitude.
With 100x parameters, the cost for inference (using the model) would increase roughly 100x also. Giving a cost of about 0.1 USD per 700 words generated. This seems very cheap compared to human labour.
Some hopeful speculation (warning: Hope clouds observation):
Maybe the relevant sort of AI system won't just stream-of-consciousness generate words like GPT-3 does, but rather be some sort of internal bureaucracy of prompt programming [LW · GW] that e.g. takes notes to itself, spins of sub-routines to do various tasks like looking up facts, reviews and edits text before finalizing the product, etc. such that 10x or even 100x compute is spent per word of generated text. This would mean $1 - $10 per 700 words generated, which is maybe enough to be outcompeted by humans for many applications.
Replies from: gjm, ViktorThink↑ comment by gjm · 2021-06-23T10:04:04.323Z · LW(p) · GW(p)
If multiplying the size by 5 means multiplying the cost by 10 (and if this relationship is consistent as size continues to increase) then a 100x size increase is about 2.86 5x-ings, which means a cost increase of about 10^2.86 or about 730, which means that $12M becomes about $8.7B. (Much more than the $3B you suggest and of course much much more than the $300M OP suggests.)
[EDITED to add:] Oops, should have refreshed the page before commenting; I see that OP has already fixed this.
↑ comment by MrThink (ViktorThink) · 2021-06-23T09:46:49.418Z · LW(p) · GW(p)
Isn't that math wrong? 17 trillion parameters is 100x more than GPT-3, so the cost should be at least 100x higher, so if the cost is $12M now it should be at least a billion dollars. I think it would be about $3B. It would probably cost a bit more than that since the scaling law will probably bend soon and more data will be needed per parameter. Also there may be inefficiencies from doing things at that scale. I'd guess maybe $10B give or take an order of magnitude.
You are absolutely correct, the cost must be more than 100x if costs scales faster than number of parameters. I have now updated the calculations and got a 727 increase of costs.
Maybe the relevant sort of AI system won't just stream-of-consciousness generate words like GPT-3 does, but rather be some sort of internal bureaucracy of prompt programming [LW · GW] that e.g. takes notes to itself, spins of sub-routines to do various tasks like looking up facts, reviews and edits text before finalizing the product, etc. such that 10x or even 100x compute is spent per word of generated text. This would mean $1 - $10 per 700 words generated, which is maybe enough to be outcompeted by humans for many applications.
I suspect you might be right. If we imagine the human brain, every neuron is reused tens of times by the time it takes to say a single word, so I it doesn't seem unlikely that a good architecture reuses neurons multiple times before "outputting" something. So I think an increase as you say with about 10-100x is not unlikely.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-06-23T10:17:36.144Z · LW(p) · GW(p)
Even if the AI does a billion tasks like this, it would only land at around 36.5 billion USD per year in computational cost.
I think you mean a billion tasks like this per day.
comment by Pattern · 2021-06-24T19:13:48.003Z · LW(p) · GW(p)
I once read an estimate that 5x-ing the size of GPT3, would 10x the training cost. I can’t find the source now, so if anyone has a better estimate, please let me know.
Even if this is true,
(Note: Thank you Daniel Kokotajlo for pointing out my math mistake, I have updated the calculations as of below)
Number of 5 doubles needed to 100x parameters: 5^n=100 => n=log(100)/log(5)=2.86
Increase of training cost: 10^2.86=727
Training a 17 trillion parameter GPT model would then cost around 727 times more than the cost of GPT-3, which would give a cost of around 8,7 billion USD. Of course bigger models alone without software improvements might not result in transformative AI.
is this true? Or could increasing the size of a larger model, cost more, i.e. 5x-ing GPT3 is 10x, but 5x-ing again costs more that 10x?
Replies from: ViktorThink↑ comment by MrThink (ViktorThink) · 2021-06-27T22:05:07.199Z · LW(p) · GW(p)
That's a good question. I can see both the scenario of price increasing both more or less than that.
The compute needed for the training is in this example the only significant factor in price, and that's the one that scales at 10x cost for 5x size. (However, sadly I can't find the source where I read it, so again, please feel free to share if someone has a better method for estimation.)
Building the infrastructure for training a model of several trillion parameters could easily create a chip shortage, drastically increasing costs of AI chips, and thus leading to training costing way more than the estimate.
However, it might be possible that building a huge infrastructure would have many benefits of scale. For example Google might build a TPU "gigafactory" and because of the high volume of produced TPUs, the price per TPU would decrease significantly.
Replies from: Pattern↑ comment by Pattern · 2021-07-02T17:24:46.617Z · LW(p) · GW(p)
Building the infrastructure for training a model of several trillion parameters could easily create a chip shortage, drastically increasing costs of AI chips, and thus leading to training costing way more than the estimate.
Doing this slowly might be the sort of increased demand that would increase investment, and decrease price.