Gated Attention Blocks: Preliminary Progress toward Removing Attention Head Superposition
post by cmathw, Dennis Akar (British_Potato), Lee Sharkey (Lee_Sharkey) · 2024-04-08T11:14:43.268Z · LW · GW · 4 commentsContents
Background Attention head superposition for OV-Incoherent Skip Trigrams Removing Attention Head Superposition from models trained on OV-Incoherent Skip Trigrams Toy Dataset Generation Gated Attention Mechanism Gated Attention Block Training Summary of Architectural and Training Choices Experimental Results on Toy Model Setup Related Work Conclusion Summary Limitations Future Work Acknowledgements Contributions Statement References Appendix Appendix A: OV-Incoherent skip trigram dataset generation algorithm Appendix B1: 2 Heads, 3 Skip Trigrams (Trained via Stochastic Gradient Descent) Appendix B2: 3 Heads, 4 Skip Trigrams (Trained via Stochastic Gradient Descent) Appendix C: Other approaches that we investigated Binary Gates Using Original Weight Matrices Alternative Post-Gate Score Activation Functions Appendix D: Weights for Manually Specified Model encoding 3 OV-Incoherent Skip Trigrams with 2 heads None 4 comments
This work represents progress on removing attention head superposition. We are excited by this approach but acknowledge there are currently various limitations. In the short term, we will be working on adjacent problems are excited to collaborate with anyone thinking about similar things!
Produced as part of the ML Alignment & Theory Scholars Program - Summer 2023 Cohort
Summary: In transformer language models, attention head superposition makes it difficult to study the function of individual attention heads in isolation. We study a particular kind of attention head superposition that involves constructive and destructive interference between the outputs of different attention heads. We propose a novel architecture - a ‘gated attention block’ - which resolves this kind of attention head superposition in toy models. In future, we hope this architecture may be useful for studying more natural forms of attention head superposition in large language models.
Our code can be found here.
Background
Mechanistic interpretability aims to reverse-engineer what neural networks have learned by decomposing a network’s functions into human-interpretable algorithms. This involves isolating the individual components within the network that implement particular behaviours. This has proven difficult, however, because networks make use of polysemanticity and superposition to represent information.
Polysemanticity in a transformer’s multi-layer perceptron (MLPs) layers is when neurons appear to represent many unrelated concepts (Gurnee et al., 2023). We also see this phenomena within the transformer’s attention mechanism, when a given attention head performs qualitatively different functions based on its destination token and context (Janiak et al., 2023).
Superposition occurs when a layer in a network (an ‘activation space’) represents more features than it has dimensions. This means that features are assigned to an overcomplete set of directions as opposed to being aligned with e.g. the neuron basis.
The presence of polysemanticity means that the function of a single neuron or attention head cannot be defined by the features or behaviours it expresses on a subset of its training distribution because it may serve different purposes on different subsets of the training distribution. Relatedly, superposition makes it misleading to study the function of individual neurons or attention heads in isolation from other neurons or heads. Both of these phenomena promote caution around assigning specific behaviours to individual network components (neurons or attention heads), due to there both being a diversity in behaviours across a training distribution and in their interaction with other components in the network.
Although polysemanticity and superposition make the isolated components of a network less immediately interpretable, understanding of the correct functional units of analysis has improved. Progress has been made on both understanding features as directions within an activation space (Elhage et al., 2023) and resolving feature superposition by applying sparse autoencoders to identify highly-interpretable features (Sharkey et al., 2022; Cunningham et al., 2023; Bricken et al., 2023).
Attention head superposition for OV-Incoherent Skip Trigrams
Superposition in the context of attention heads is less understood. It is however conceivable that an attention block could make use of a similar compression scheme to implement more behaviours than the number of attention heads in the block.
Prior work introduced a task to study attention head superposition in the form of OV-Incoherent Skip Trigrams (Jermyn et al., 2023; Conerly et al., 2023). These are skip trigrams (tokens that are ordered but not necessarily adjacent) in which full attention is given to a single source token [i.e. A] from multiple different destination tokens [i.e. B and C]. Two such OV-Incoherent skip trigrams could be of the following form,
If an attention head gives full attention to the [A] token (i.e. at destination token [B] or [C], the attention pattern value corresponding to source token [A] is 1.0), then it is not possible for the OV-circuit to correctly distinguish which mapping to invoke, and therefore a single head cannot map both [B] → [D] and [C] → [E] reliably.
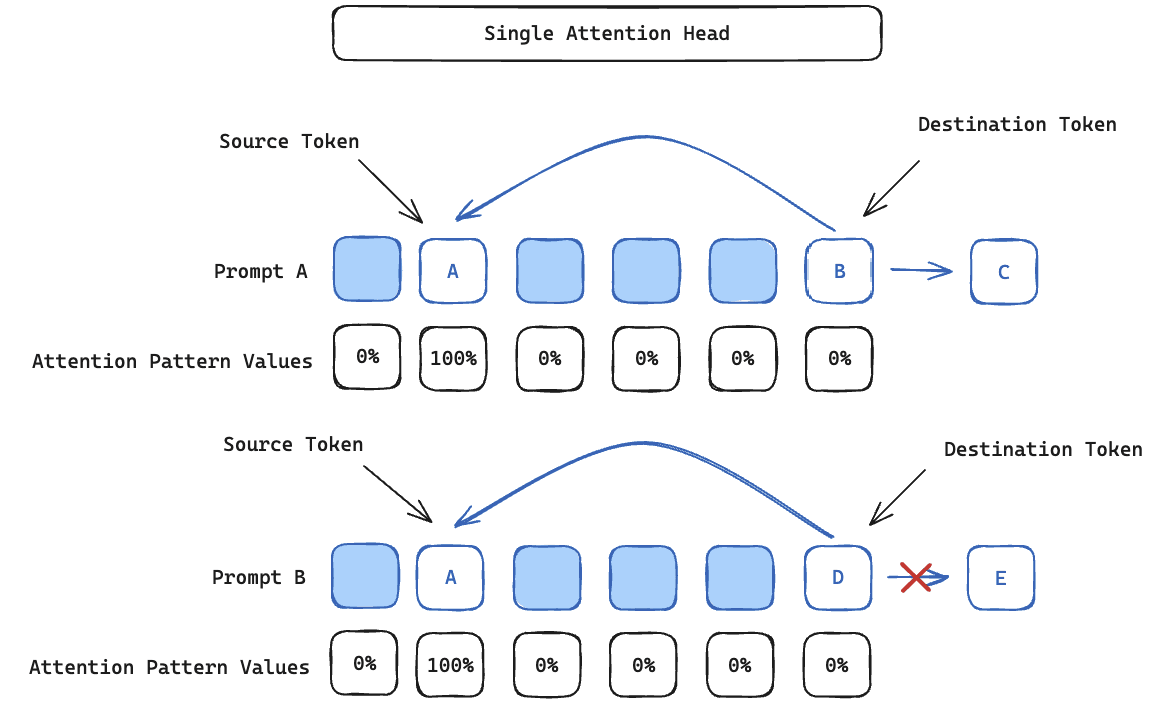
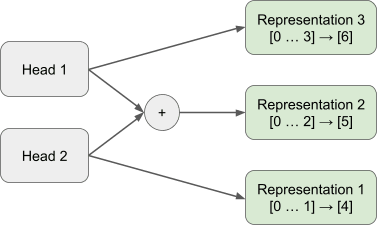
However, Jermyn et al. (2023) showed that multiple heads can act in concert to represent more OV-Incoherent skip trigrams than the number of attention heads by using constructive and destructive interference across head outputs. In Figure 2, we demonstrate a simple case of this in which a two-head attention block can represent 3 OV-Incoherent skip trigrams by making use of attention head superposition.
Representation 1 and 2 are encoded solely within Attention Head 2 and Attention Head 1 respectively. Representation 3 is represented through constructive and destructive interference across the two attention head outputs.
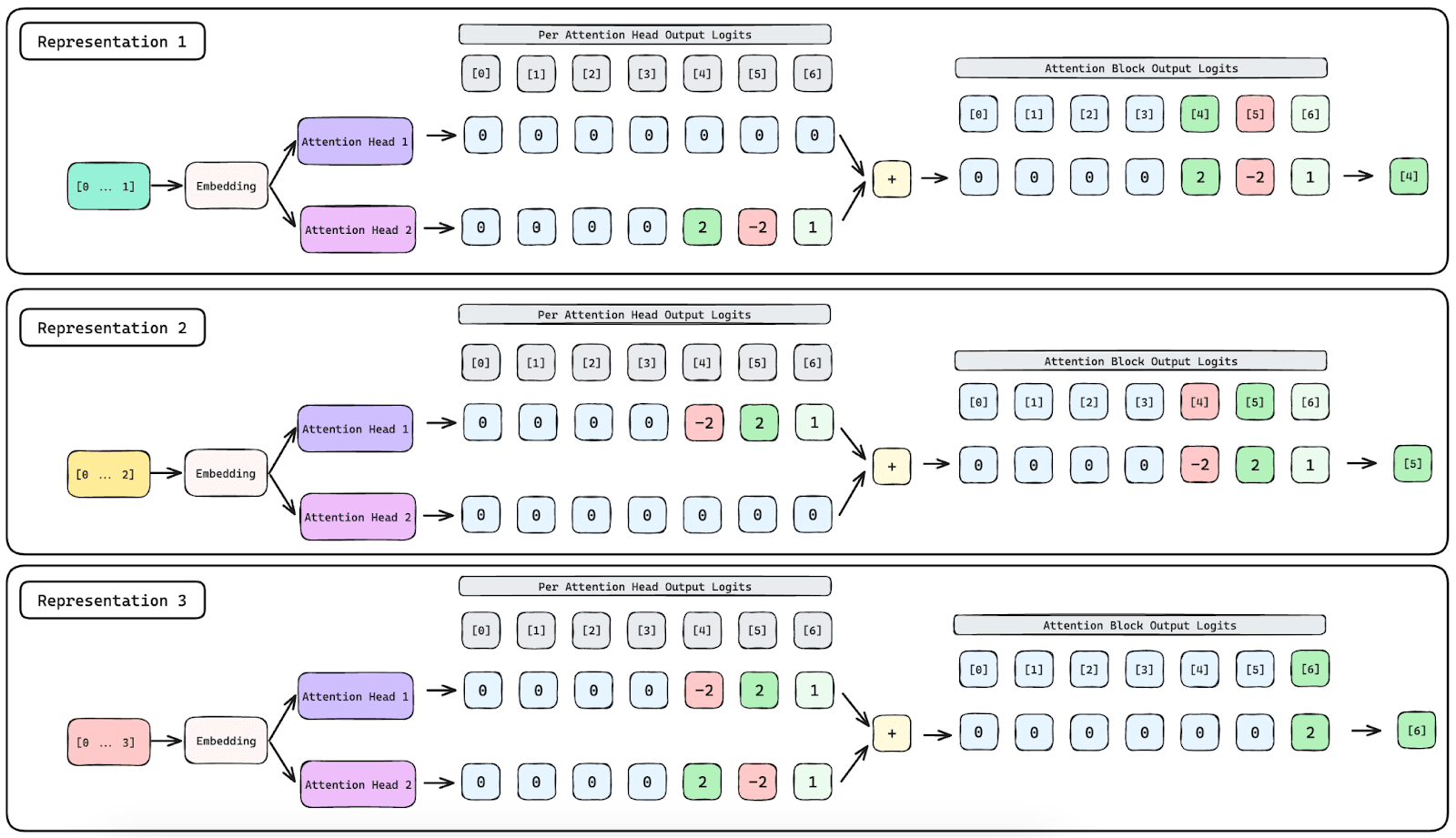
Notably however, if an attention block makes use of attention head superposition as described, it is no longer possible to study the role of attention heads within this block in isolation.
In this work, we introduce a method for resolving attention head superposition. We train a modified attention block to match the input-output behaviour of the original attention block and apply QK-circuit gating with a sparsity penalty. We test this method on a variety of OV-Incoherent skip trigram datasets and find that it can successfully remove representations that are spread across multiple attention heads and cleanly map each representation to a single modified attention head.
Removing Attention Head Superposition from models trained on OV-Incoherent Skip Trigrams
Toy Dataset Generation
To study the phenomena of attention head superposition, we replicate the OV-Incoherent skip trigram dataset generation process presented by Jermyn et al. (2023). We create prompts by sampling from a random distribution of integers; if both an [A] and [B] token have been drawn, we immediately append a [C] token to the prompt. We detail the algorithm for dataset generation as pseudocode in Appendix A.
Datasets are generated using this algorithm. The prompt length () was typically set to 11 tokens. Different datasets were constructed for different numbers of OV-Incoherent skip trigrams (typically varying between 3 and 5 OV-Incoherent skip trigrams).
Gated Attention Mechanism
While training differently sized models that express OV-Incoherent attention head superposition, we found it useful to view attention heads as forming AND gates to encode a larger number of representations than attention heads. Concretely, multiple heads would be ‘active’ on a given destination-source position pair (i.e. have high attention score) and if the outputs of any one of these heads were to be removed, the representation being encoded across these heads would be lost. The primary architectural choice for our gated attention mechanism is to furnish it with the ability to modulate how many heads are active on any given destination-source position pair, while retaining the fundamental features of the original attention mechanism. Specifically, we want to retain original attention mechanism’s ability to dynamically weight different parts of an input sequence (QK-circuit) and use this weighting to map information to an output vector (OV-circuit).
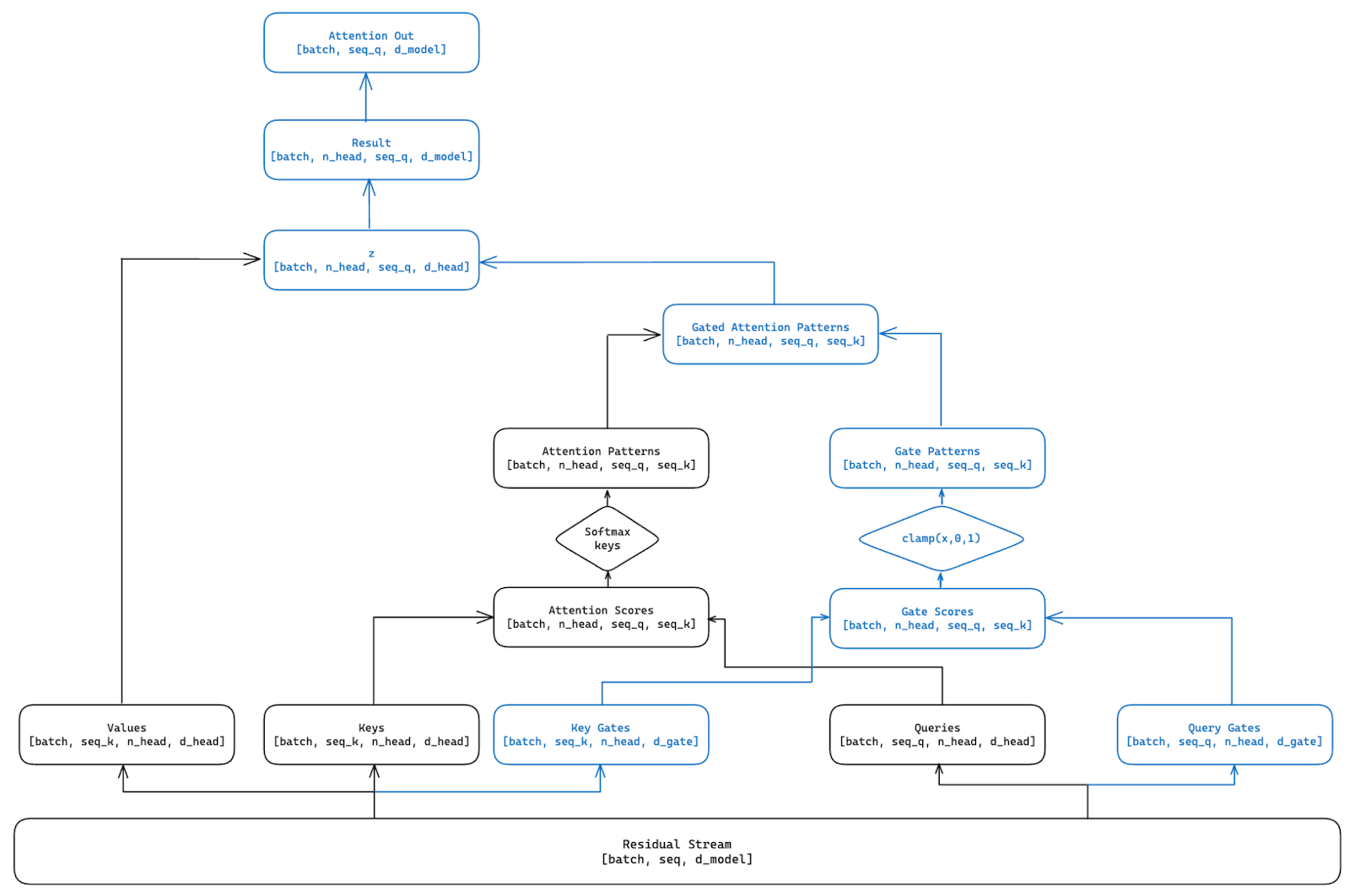
We present an architectural change to the traditional attention mechanism that gates the information passed between the QK- and OV-circuits. We train a set of query gates and key gates alongside the attention mechanism’s traditional query and key vectors. The query and key gates are formed by projecting the residual stream from to using weight and bias matrices; and for every ith head. These query and key gate vectors are then used to construct a mask of the same shape as the original attention patterns, by taking the dot products of each of the query gates with all of the key gates. Each of these values is passed through a clamp activation function bounding the pattern gate values between 0 and 1. Each of these destination-source position gates form a mask that is overlaid over the attention mechanism’s original attention pattern.
Formally, we compute the query gates and key gates for a sequence as follows:
where,
To construct the gate scores, we calculate the dot product between and the transpose of :
Here, will be a matrix where each element represents the score between the -th query and the -th key. Given the dimensions of and , the resulting matrix will have dimensions:
We then calculate the gate pattern by applying a clamp activation function, bounding values between 0 and 1.
where,
Each element of the matrix, denoted as , is constrained to the interval . This means that for all , where indexes the query positions and indexes the key positions:
To discourage multiple heads from being active on a given destination-source position pair, we apply a sparsity penalty across the head dimension of the gate patterns tensor (Figure 3). By doing so, we are encouraging the learned query and key gates to correspond to unique features within the residual stream across different heads. The specific sparsity penalty employed is an L0.6 norm across the head dimension.
Given that the number of representations (in this case, the number of OV-Incoherent Skip Trigrams) is greater than the number of attention heads in the original attention block, we must increase the number of heads in the new attention block such that the number of representations is smaller than or equal to the number of heads. We do this by specifying an expansion factor. This expands the number of existing attention head weights across the head dimension. For example, if our original attention block has 4 heads and we set an expansion factor of 2, our gated attention block will have 8 heads. In our experiments, we use an expansion factor of 2 across all experiments.
We initialise the traditional key, query, value, and output weight matrices with gaussian noise using a Xavier normal distribution. We normalise the weights associated with the value and output vectors during each forward pass along the dimension. This is done to avoid the model achieving a low L0.6 norm by setting the attention gates arbitrarily small while countering this effect by setting the value and/or output weights arbitrarily large. This normalisation is performed for analogous reasons as the approach of normalising the dictionary weights in traditional sparse auto-encoders (Cunningham et al. 2023).
The weights associated with the gate vectors are initialised as random orthogonal matrices using torch.nn.init.orthogonal_.
Gated Attention Block Training
As outlined earlier, we introduce a gating mechanism to more easily control the flow of information between the QK- and OV-circuits and, importantly, allow for the application of a sparsity penalty that discourages multiple heads attending from the same destination position to the same source position. The training process is outlined as follows:
- Select an expansion factor to expand the number of heads in the gated attention block to.
- Initialise all weight matrices with gaussian noise (gate matrices) using a Xavier normal distribution as outlined above.
- Train the gated attention block to reconstruct the outputs of the original attention block given the same inputs but with an included sparsity penalty. During training of the gated attention block, the loss function includes two terms:
The reconstruction loss, is simply the MSE loss between the original attention block’s flattened outputs and the gated attention block’s flattened outputs.
As outlined earlier, represents the 0.6-norm (although not a real norm) across the head dimension of the gate patterns.
𝛼 represents a L0.6 norm coefficient, used to adjust how strongly regularisation affects the training process.
Following training of a gated attention block, the expectation is to have a block that can represent the input-output behaviour of the original block but without employing attention head superposition.
Summary of Architectural and Training Choices
As a quick reference to the architectural, training choices and their motivation, we provide the summary below.
Learnable Gate Vectors: We hope to constrain the number of destination-source feature pairs that a head can express through learnable gate matrices for each head. We limit the expressivity of heads by selecting a comparatively small term, ie. ().
Clamp Gate Pattern Values between 0 and 1: We apply a clamp activation function to each gate pattern element, causing the gate to be completely closed on negative values, and creating a bound for positive values. Note, this is distinct from a sigmoid in that it has a hard threshold of 0 on negative values and hard threshold of 1 for values greater than 1.
L0.6 Sparsity Penalty: Each of the gate pattern values is between 0 and 1. To penalise multiple gates opening on a specific destination-source pair, we use a L0.6 norm across the head dimension of these gate patterns.
Expansion Factor: To increase the number of heads in the block, we duplicate the number of heads along the head dimension and initialise each of the weight matrices to a Xavier normal distribution.
Experimental Results on Toy Model Setup
We experiment with this architecture across a variety of toy model configurations, both toy models trained via SGD and toy models that cleanly contain attention head superposition via manually specified weights. For all experiments, we use a dataset of 100,000 prompts each 11 tokens long (assigned to 100 batches of 1,000 prompts).
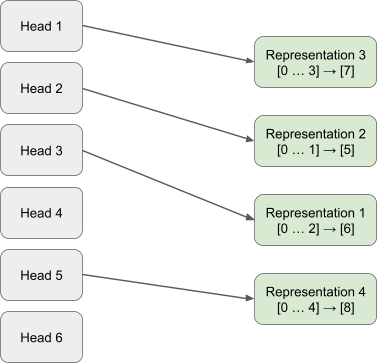
When referring to a head encoding a representation, we are specifically stating that this head encodes this representation irrespective of the removal of any other head (or any combination of heads). For example, in Figure 4 we claim Head 1 is encoding Representation 3. This means that the model will continue to assign highest logits to the completion of Representation 3 irrespective of the effects of zeroing the outputs of Head 2, 3 and 4 (or any combination of these heads).
Here, we present results for a single-layer 4-head attention-only model trained via stochastic gradient descent to encode 5 OV-Incoherent skip trigrams below. In the appendix, we present two other models trained via SGD. The gated attention block was successful in removing attention head superposition in all cases, models trained using this architecture represented each skip trigram within a single head.
Note for the models trained via SGD that the form of attention head superposition being encoded does not appear to be strictly aligned to the form outlined in the introduction. For example, full attention does not appear to be paid to [A] token across different heads and models. We did not investigate the mechanism each model was using to make these encodings further however, instead focusing on whether each head was assigning highest logits to complete a specific representation (without constructive/destructive interference across other heads). We do however also include cases where the weights are manually specified to perfectly mimic the mechanism outlined in the introduction; we include two of these within the codebase’s test suite and the weights of one of these within Appendix D. In these cases, we were also able to resolve attention head superposition.
In the case of the single layer 4-head attention only model, the model must encode the following 5 OV-Incoherent skip trigrams.
We found that 4 of the OV-Incoherent skip trigrams were encoded cleanly across single heads, while 1 was encoded across all 4 heads (Representation 4).
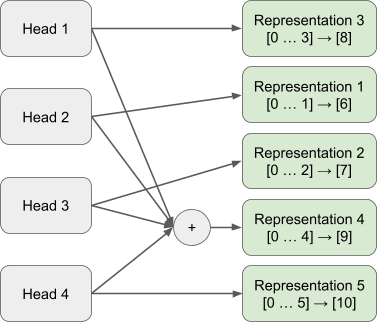
We train a gated attention block to match input-output behaviour of the original block presented in Figure 4. We use an expansion factor of 2 (resulting in 8 heads), with an L0.6 penalty of 3e-1 across 1,000 epochs and a learning rate of 1e-3.
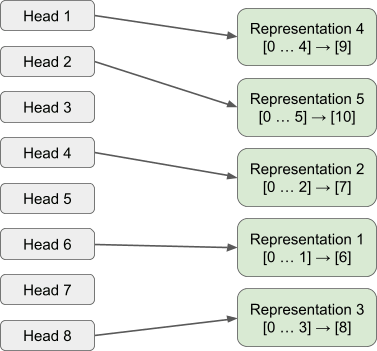
Each representation is now encoded by a single head of the gated attention block. Ablating the outputs of any of the other heads (or any other combination of heads) besides that of Head 1 will result in the model still predicting [9] on the sequence [0 … 4]. The same is true across all other single head representations, for each case there does not exist constructive/destructive interference across heads and each head’s encoding can be viewed in isolation.
For each of the other models presented in Appendix A, we again find we can remove attention superposition using gated attention blocks. Relevant code for reproducing Figure 5 and related figures is located in the experiments folder of the repository, specifically the check_no_attn_super function.
Related Work
There exist various related architectural approaches targeted at gating the attention mechanism, notably Mixture of Attention Heads (Zhang et al., 2022) and SwitchHead (Csordás et al., 2023). However, these approaches focus on improving a model’s inference efficiency as opposed to attempting to improve attention mechanism interpretability.
Beyond gating mechanism approaches, prior work has investigated increasing attention pattern sparsity by replacing the softmax function with alternatives that allow for precisely zero attention pattern weighting (Correiaä et al. 2019). This work represents an alternative approach to improving attention head interpretability but does not directly tackle attention head superposition.
There also exists research that uses both a gating mechanism and modified softmax function to achieve better model quantization performance (Bondarenko et al., 2023), though this work is aimed at improving computational efficiency as opposed to interpretability.
Conclusion
Summary
This work presents a gated attention block, a method for resolving attention head superposition in toy setups. A model trained with these new blocks allows for the assignment of each representation to a specific individual head. This allows us to view the functionality of these heads in isolation, wherein this was not the case in the original model. This is achieved by penalising multiple head’s concurrently passing information from the QK-circuit to the OV-circuit on the same source and destination positions. We hope that this architecture may be useful for identifying the individual representations learned by attention blocks in large language language models, though we leave this to future work.
Limitations
Although we think this approach is a step forward, there are a number limitations:
- Interaction between expansion factor and L0.6 coefficient: We expect there to be a positive relationship between expansion factor and the coefficient associated with the sparsity penalty (i.e. larger expansion factors warrant larger sparsity coefficients). However, we did not perform a hyperparameter sweep to study the interaction between expansion factor, sparsity penalty, and the ability to recover ground truth representation.
- Gated Attention Block Interpretability: We focus predominantly on the independence of head outputs in the gated attention blocks, we have left detailed interpretability investigations of the gated attention blocks for future work.
- Optimal Hyperparameters: Related to the above, we did not perform hyperparameter sweeps across learning rates, expansion factors and L0.6 coefficients to understand which combination of hyperparameters are most beneficial in removing attention head superposition. Hyperparameters that worked for each model did anecdotally follow expected behaviours (i.e. setting L0.6 coefficient too high caused no representations to be learnt and setting it too low did not remove attention head superposition), but in this preliminary work we did not robustly investigate this in detail.
- Cases where the ground truth representations are unknown: In this work, the ground truth representations are known (these are the [A … B] → [C] token mappings). Outside the context of toy models, this will likely not be the case. The ability to reconstruct the original blocks' behaviours and observing the gate patterns that are open simultaneously across heads may provide insight as to the representations learned by attention blocks in large language models.
- Equivalent block functionality/behaviour: We did not extensively study whether the internal behaviours correspond across the original model and the gated attention models. Although these models are trained to have low reconstruction loss, the behaviour in which blocks employ to achieve this could be different. We discuss this further in Appendix C - Using Original Weight Matrices.
- Moving away from toy setups: The experiments within this work rely on concrete toy examples of attention head superposition. Specifically, our models are single layer attention only models that use one-hot (un)embeddings and do not make use of layer norm or positional embeddings. We are excited to apply this architecture outside the context of toy models.
- Alternative Forms of Attention Head Superposition: In this work, we only explored a single form of attention head superposition, namely OV-Incoherent attention head superposition. We did not test this method on other proposed forms of attention head superposition, for example, where there are multiple source tokens for a given destination token (Greenspan and Wynroe, 2023). Our method applies a sparsity penalty across heads at the same source-destination pair and may not directly penalise this form of attention head superposition. In general, it may however be possible to apply a sparsity penalty to other dimensions of the gate pattern tensor to address other forms of attention head superposition; again we did not explore this here.
- Presence of Dead Heads: In Figure 4, we see many examples of what appear to be ‘dead heads’ - attention heads that do not encode any measured representation. Anecdotally, there appeared to be many heads that were effectively ‘off’ across all representations but we did not verify whether these heads were contributing in other ways toward decreasing MSE loss between the gated attention block and the original attention block. Further investigation is needed to determine whether these heads can be pruned without affecting model performance.
- Better Experimental Controls: We did not extensively compare the proposed architecture with control cases (ie. a traditional architecture with an expanded number of heads, the gated attention mechanism without a sparsity penalty) to robustly understand how these changes affect a model’s tendency to employ attention head superposition. During hyperparameter tuning we found the choices outlined above to provide empirical improvement in resolving superposition but more robust study is left for future work.
Future Work
Beyond addressing the limitations above, we are also interested in:
- Varying the dimension: In this work, we kept the dimension equal to 1. Both the key and query gate matrices project the residual stream at each position down to a scalar. Given the behaviours described in this work are essentially simple token-to-token mappings, we expected a small to be suitable here. In general, we expect that increasing the dimension will allow heads to express more complex, general behaviours (perhaps previous token behaviour, duplicate token behaviour, etc.). We’d are interesting in exploring the relationship between the dimension and the complexity of behaviours expressed.
- Addressing polysemanticity: We use gated attention blocks to resolve attention head superposition. We focus on this phenomenon by applying a sparsity penalty across the head dimension of the gate pattern tensor. We also expect this method could be effective in reducing attention head polysemanticity by applying a sparsity penalty to other dimensions of the gate pattern tensor; we did not explore that here.
- Freezing Original Weights: In Appendix C, we outline some other approaches we looked at, this included a version of the above wherein we duplicate the traditional attention head weights across the expansion factor. We then added gaussian noise to these weights and specified them to be trainable. We didn’t present this work as the main approach as we found initialising these matrices with gaussian noise tended to more reliably resolve attention head superposition. A related approach would be to freeze the original weight matrices, duplicate these via the expansion factor and not introduce Gaussian noise. Although this method would not resolve attention head superposition, combined with an appropriate sparsity penalty and selection of dimension, it could be used to reduce polysemanticity while retaining the underlying behaviours of the original attention block.
Acknowledgements
We are thankful to Jett Janiak, Keith Wynroe and Hoagy Cunningham for many useful conversations around attention head superposition and proposed methods toward addressing this phenomena. We would also like to thank Adam Jermyn for conversations clarifying our understanding of the OV-Incoherent skip trigram task. Chris Mathwin is supported by the Long Term Future Fund.
Contributions Statement
CM and DA replicated the OV-Incoherent skip-trigram dataset generation process proposed originally by Jermyn et al. (2023). CM and LS proposed the gated attention mechanism as a method to resolve attention head superposition. CM wrote the current revision of the repository, DA contributed to earlier revisions of this repository. CM ran the experiments outlined above and wrote this manuscript. LS provided substantial feedback on this manuscript, as well as substantial feedback on experiments, design choices and research direction.
References
Jermyn, A., Olah, C. & Henighan, T. 2023. May Update. https://transformer-circuits.pub/2023/may-update/index.html#attention-superposition
Conerly, T., Jermyn, A. & Olah, C. 2023. July Update. https://transformer-circuits.pub/2023/july-update/index.html#attn-skip-trigram
Janiak, J., Mathwin, C. & Heimersheim, S. 2023. Polysemantic Attention Head in a 4- Layer Transformer. https://www.lesswrong.com/posts/nuJFTS5iiJKT5G5yh/polysemantic-attention-head-in-a-4-layer-transformer [LW · GW]
Gurnee, W., Nanda, N., Pauly, M., Harvey, K., Troitskii, D. & Dimitris, B. 2023. Finding Neurons in a Haystack: Case Studies with Sparse Probing. https://arxiv.org/pdf/2305.01610.pdf
Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield-Dodds, Z., Lasenby, R., Drain, D., Chen, C., Grosse, R., McCandlish, S., Kaplan, J., Amodei, D., Wattenberg, M. & Olah, C. 2022. Toy Models of Superposition. https://arxiv.org/pdf/2209.10652.pdf
Sharkey, L., Braun, D. & Millidge B. Interim Research Report: Taking features out of superposition with sparse autoencoders. 2022. https://www.alignmentforum.org/posts/z6QQJbtpkEAX3Aojj/interim-research-report-taking-features-out-of-superposition [AF · GW]
Cunningham, H., Ewart, A., Riggs, L., Huben, R. & Sharkey L. 2023. Sparse Autoencoders find Highly Interpretable Features in Language Models. https://arxiv.org/pdf/2309.08600.pdf
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Tamkin, A., Nguyen, K., McLean, B., Burke, J., Hume, T., Carter, S., Henighan, T. & Olah, C. 2023. Towards Monosemanticity: Decomposing Language Models with Dictionary Learning. https://transformer-circuits.pub/2023/monosemantic-features
Zhang, X., Shen, Y., Huang, Z., Zhou, J., Rong, W. & Xiong, Z. 2022. Mixture of Attention Heads: Selecting Attention Heads Per Token. https://arxiv.org/pdf/2210.05144.pdf
Csordás, R., Piekos, P., Irie, K. & Schmidhuber J. 2023. SwitchHead: Accelerating Transformers with Mixture-of-Experts Attention. https://arxiv.org/pdf/2312.07987.pdf
Correiaä, G., Niculae, V. & Martins, A. Adaptively Sparse Transformers. 2019. https://arxiv.org/pdf/1909.00015.pdf
Bondarenko, Y., Nagel, M. & Blankevoort, T. Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing. 2023. https://arxiv.org/pdf/2306.12929.pdf
Greenspan, L. & Wynroe, K. An OV-Coherent Toy Model of Attention Head Superposition. 2023. https://www.alignmentforum.org/posts/cqRGZisKbpSjgaJbc/an-ov-coherent-toy-model-of-attention-head-superposition-1 [AF · GW]
Appendix
Appendix A: OV-Incoherent skip trigram dataset generation algorithm

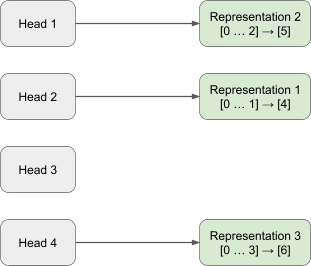
Appendix B1: 2 Heads, 3 Skip Trigrams (Trained via Stochastic Gradient Descent)
To remove attention head superposition from this model we train a gated attention block with an expansion factor of 2, L0.6 coefficient of 5e-1 and a learning rate of 5e-4 for 1000 epochs.
Appendix B2: 3 Heads, 4 Skip Trigrams (Trained via Stochastic Gradient Descent)
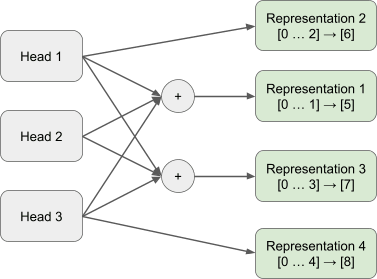
To remove attention head superposition from this model we train a gated attention block with an expansion factor of 2, L0.6 coefficient of 1e-1 and a learning rate of 5e-4 for 1000 epochs.
Appendix C: Other approaches that we investigated
Binary Gates
We explored the use of binary gates that could only take the value of 0 or 1 in place of the clamp setup. We looked at using a sigmoid activation function followed by mapping output values equal or above 0.5 to 1 and below 0.5 to 0. We experimented with Straight-Through Estimators to this end also. In our experiments though we could not achieve adequate training stability with this approach.
Using Original Weight Matrices
We also explored duplicating the original attention weights across the head dimension via the expansion factor and then adding gaussian noise to these weights via a Xavier normal distribution. The intention of this approach was to encourage the behaviours of gated attention blocks to reflect that found within the original attention block. In the end, we found we could more reliably resolve attention head superposition by simply initialising from gaussian noise via a Xavier normal distribution.
Alternative Post-Gate Score Activation Functions
We explored the use of other activation functions (in place of clamping between 0 and 1) in earlier iterations of this work. The intention of all approaches we explored was to promote sparsity by mapping all negative outputs to 0 and to restrict positive outputs to a range between 0 and 1 (to avoid altering the traditional attention mechanism substantially). We looked at using just a ReLU activation function, this worked in most cases but there were instances where gate pattern values exceeded 1. We also looked at using a ReLU function followed by a tanh function, this has the advantage of being differentiable over all positive inputs but we found it made gate pattern values generally much smaller than just clamping between 0 and 1. As we didn’t encounter difficulty in training gated attention blocks with a clamping function, we opted to use this function in this work.
Appendix D: Weights for Manually Specified Model encoding 3 OV-Incoherent Skip Trigrams with 2 heads
Below we provide manually specified weights for a 2-head model that cleanly encodes 3 OV-Incoherent skip trigrams. This model has a single head dimension and an embedding dimension of 7 (corresponding to each of the 7 tokens, ignoring the BOS token in this example). In the test-suite, we provide the same model but with a dimension for the BOS token included. This model follows the mechanism of OV-Incoherence outlined within the Introduction. We also provide a 4-head, 5 OV-Incoherent skip trigram model manually specified in a similar manner within the test-suite.

[1] Correspondence to cwmathwin [at] gmail [dot] com
Link to code here.
4 comments
Comments sorted by top scores.
comment by Neel Nanda (neel-nanda-1) · 2024-04-08T16:50:44.623Z · LW(p) · GW(p)
Each element of the matrix, denoted as , is constrained to the interval . This means that for all , where indexes the query positions and indexes the key positions:
Why is this strictly less than 1? Surely if the dot product is 1.1 and you clamp, it gets clamped to exactly 1
Replies from: cmathwcomment by Wuschel Schulz (wuschel-schulz) · 2024-04-18T10:40:17.072Z · LW(p) · GW(p)
I like this method, and I see that it can eliminate this kind of superposition.
You already address the limitation, that these gated attention head blocks do not eliminate other forms of attention head superposition, and I agree.
It feels kind of specifically designed to deal with the kind of superposition that occurs for Skip Trigrams and I would be interested to see how well it generalizes to superpositions in the wild.
I tried to come up with a list of ways attention head superposition that can not be disentangled by gated attention blocks:
- multiple attention heads perform a distributed computation, that attends to different source tokens
This was already addressed by you, and an example is given by Greenspan and Wynroe - The superposition is across attention heads on different layers
These are not caught because the sparsity penalty is only applied to attention heads within the same layer.
Why should there be superposition of attention heads between layers?
As a toy model let us imagine the case of a 2 layer attention only transformer, with n_head heads in each layer, given a dataset with >n_head^2+n_head skip trigrams to figure out.
Such a transformer could use the computation in superposition described in figure 1 to correctly model all skip trigrams, but would run out of attention head pairs within the same layer for distributing computation between.
Then it would have to revert to putting attention head pairs across layers in superposition. - Overlapping necessary superposition.
Let's say, there is some computation, for wich you need two attention heads, attending to the same token position.
The easiest example of a situation, where this is necessary is when you want to copy information from a source token, that is "bigger" than the head dimension. The transformer can then use 2 heads, to copy over twice as much information.
Let us now imagine, there are 3 cases, where information has to be copied from the source token. A,B,C, and we have 3 heads: 1,2,3. and the information that has to be copied over can be stored in 2*d_head dimensions. Is there a way to solve this task? Yes!
heads 1&2 work in superposition to copy the information in task A, 2&3 in task B and 3&1 in task C.
In theory, we could make all attention heads monosemantic, by having a set of 6 attention heads, trained to perform the same computation: A: 1&2, B: 3&4, C:5&6. But the way that the L.6 norm is applied, it only tries to reduce the number of times, that 2 attention heads attend to the same token. And this happens the same amount for both possibilities where the computation happens.