Polysemantic Attention Head in a 4-Layer Transformer
post by Jett Janiak (jett), cmathw, StefanHex (Stefan42) · 2023-11-09T16:16:35.132Z · LW · GW · 0 commentsContents
Introduction Section 1 Methods Results Distribution of behaviours Prompt examples for each destination token Section 2 Methods Prompt templates Induction Bigger indentation Previous Results Induction Bigger indentation Previous Conclusion None No comments
Produced as a part of MATS Program, under @Neel Nanda [LW · GW] and @Lee Sharkey [LW · GW] mentorship
Epistemic status: optimized to get the post out quickly, but we are confident in the main claims
TL;DR: head 1.4 in attn-only-4l exhibits many different attention patterns that are all relevant to model's performance
Introduction
- In previous post [AF · GW]about the docstring circuit, we found that attention head 1.4 (Layer 1, Head 4) in a 4-layer attention-only transformer would act as either a fuzzy previous token head or as an induction head in different parts of the prompt.
- These results suggested that attention head 1.4 was polysemantic, i.e. performing different functions within different contexts.
- In Section 1, we classify ~5 million rows of attention patterns associated with 5,000 prompts from the model’s training distribution. In doing so, we identify many more simple behaviours that this head exhibits.
- In Section 2, we explore 3 simple behaviours (induction, fuzzy previous token, and bigger indentation) more deeply. We construct a set of prompts for each behaviour, and we investigate its importance to model performance.
- This post provides evidence of the complex role that attention heads play within a model’s computation, and that simplifying an attention head to a simple, singular behaviour can be misleading.
Section 1
Methods
- We uniformly sample 5,000 prompts from the model’s training dataset of web text and code.
- We collect approximately 5 million individual rows of attention patterns corresponding to these prompts, ie. rows from the head’s attention matrices that correspond to a single destination position.
- We then classify each of these patterns as (a mix of) simple, salient behaviours.
- If there is a behaviour that accounts for at least 95% of a pattern, then it is classified. Otherwise we refer to it as unknown (but there is a multitude of consistent behaviours that we did not define, and thus did not classify)
Results
Distribution of behaviours
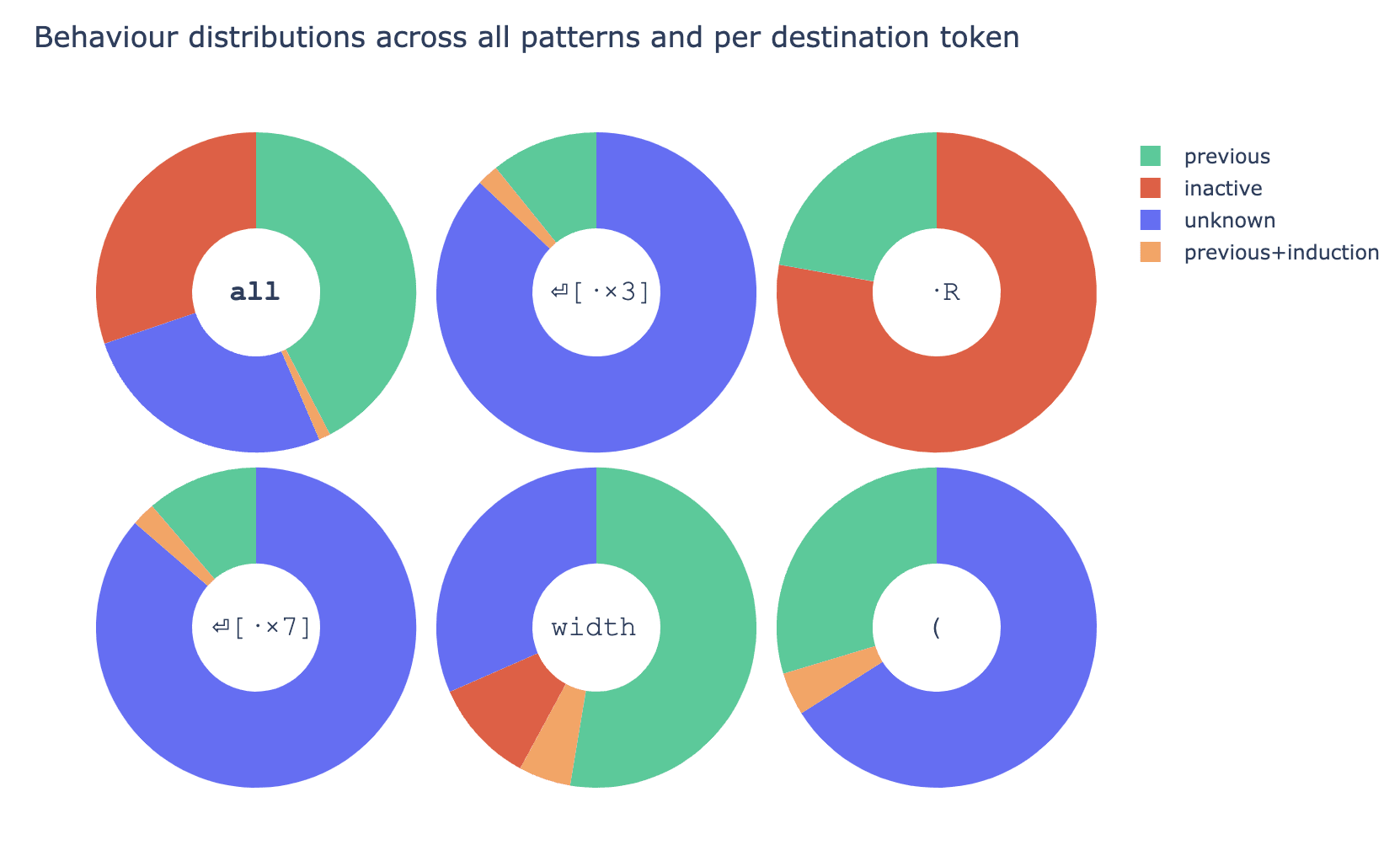
- In Figure 1 we present results of the classification, where "all" refers to "all destination tokens" and other labels refer to specific destination tokens.
- Character
·is for a space,⏎for a new line, and labels such as⏎[·×K]mean "\nand K spaces". - We distinguish the following behaviours:
- previous: attention concentrated on a few previous tokens
- inactive: attention to BOS and EOS
- previous+induction: a mix of previous and basic induction
- unknown: not classified
- Some observations:
- Across all the patterns, previous is the most common behaviour, followed by inactive and unknown.
- A big chunk of the patterns (unknown) were not automatically classified. There are many examples of consistent behaviours there, but we do not know for how many patterns they account.
- Destination token does not determine the attention pattern.
⏎[·×3]and⏎[·×7]have basically the same distributions, with ~87% of patterns not classified
Prompt examples for each destination token
Token: ⏎[·×3]
Behaviour: previous+induction
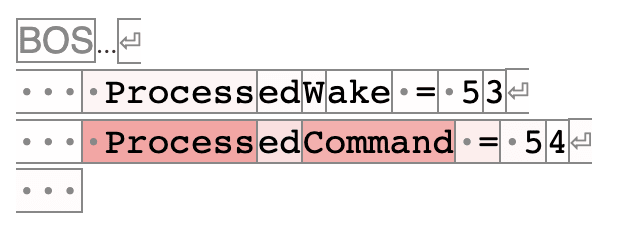
There are many ways to understand this pattern, there is likely more going on than simple previous and induction behaviours.
Token: ·R
Behaviour: inactive

Token: ⏎[·×7]
Behaviour: unknown

This is a very common pattern, where attention is paid from "new line and indentation" to "new line and bigger indentation". We believe it accounts for most of what classified as unknown for ⏎[·×7] and ⏎[·×3].
Token: width
Behaviour: unknown

We did not see many examples like this, but looks like attention is being paid to recent tokens representing arithmetic operations.
Token: dict
Behaviour: previous
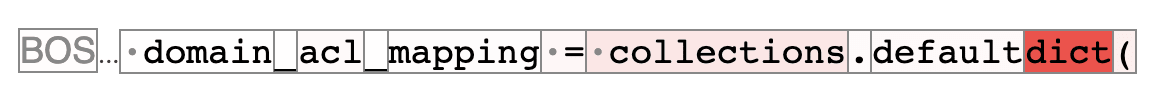
Mostly previous token, but ·collections gets more than . and default, which points at something more complicated.
Section 2
Methods
- We select a few behaviours and construct prompt templates, to generate multiple prompts on which these behaviours are exhibited.
- We measure how often the model is able to predict what we consider an obvious next token.
- We ablate the attention pattern of head 1.4, by replacing it with a pattern that attends only to BOS. We do this for each destination position in the prompt.
Prompt templates
To demonstrate the behaviours, we set up three distinct templates, wherein each template is structured to be as similar as possible to code examples found within the training dataset.
Induction
The dataset for demonstrating induction behaviour is 120 prompts of the following structure:
The current position is highlighted orange, attention head 1.4 attends heavily to the token immediately after an earlier copy of the orange token (the red token). The correct next token here is highlighted green. The dataset is generated with three distinct pairs of red and green tokens and many variants of blue and indentation tokens.
Bigger indentation
The dataset for demonstrating similar indentation token behaviour is 50 prompts of the following structure:
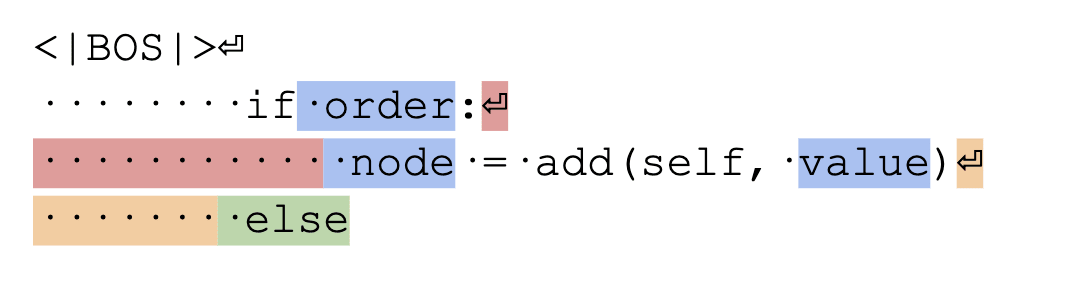
The current position is highlighted orange, attention head 1.4 attends heavily to a similar token (the red token) exhibiting similar indentation token behaviour. The correct next token here is highlighted green. The dataset is generated by taking random variable names for the blue tokens.
Previous
The dataset for demonstrating fuzzy previous token behaviour is 50 prompts of the following structure:

Again, the current position is highlighted orange, attention head 1.4 attends heavily to the previous token (the red token) acting as a previous token head. The correct next token here is highlighted green. The dataset is generated by taking random variable names for the blue tokens (of which the off-blue represents the fact that there are two tokens in the prompt definition, a parent class and child class name) There are 4 random tokens being used to generate a prompts, 2 for the class name, one for the parent class and one for the init argument.
Results
Induction
We start by studying the importance of attention head 1.4 on the aforementioned induction task (an example presented below).

In this prompt template, we BOS-ablate the orange token (in this particular example, the ⏎··· token) when doing the forward pass for the corrupted run. In the clean run, we see that over the 120 dataset examples, 93% have the correct next token (the green token) as the top-predicted token, this is compared to 25% on the corrupted run. The same is true for the mean probability of the correct token in each dataset example, it’s 0.28 on the clean run and 0.09 on the corrupted run.
% of correct top prediction | mean probability of correct prediction | |
clean | 93% | 0.28 |
ablated | 25% | 0.09 |
We now explore what effect BOS-ablation has on other sequence positions, we intend to see whether BOS-ablation has a similarly large effect on these other sequence positions. For clarity we measure average effect across the 120 prompts in the plot below, but only display a single example on the x-axis.
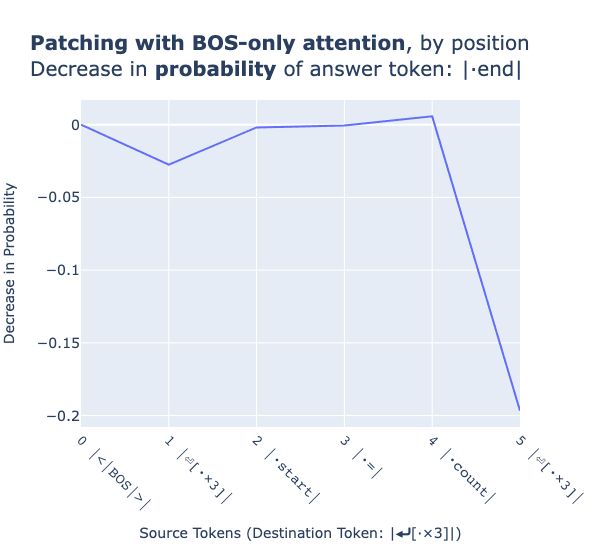
The line plot above indicates that performing BOS-ablation on other positions (besides the orange token) is not associated with a large decrease in the probability assigned to the correct answer (< 5 percentage point drop in probability). In the case of the BOS-ablating the orange token position however, where attention head 1.4 is acting as an induction head, the probability assigned to the correct answer (the green tokens across the dataset distribution) decreases by approximately 20 percentage points.
Bigger indentation
We move onto understanding the importance of similar indentation token behaviour performed by attention head 1.4 on the corresponding dataset, an example presented below.
As earlier, over the 50 dataset examples, the clean run is associated with 100% of the 0th-rank tokens being the correct token as compared to 4% on the corrupted run. We also find that the mean probability of the correct token is 0.55 on the clean run and 0.11 on the corrupted run.
% of correct top prediction | mean probability of correct prediction | |
clean | 100% | 0.55 |
ablated | 4% | 0.11 |
Again, we test the importance of different token positions by BOS-ablating all tokens in the prompt iteratively and recording the change in probability associated with the correct token.
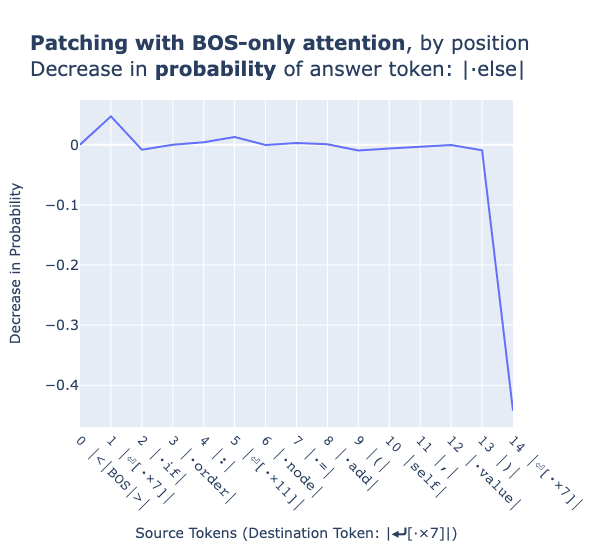
All tokens beside the indent token that are BOS-ablated at attention head 1.4 are only associated with negligible changes in the probability assigned to the correct token (the green tokens across the dataset). BOS-ablating the indent token and thus attention head 1.4’s similar indentation token behaviour results in an approximate decrease of 40 percentage points assigned to the correct next token.
Previous
Finally, we study the importance of attention head 1.4’s fuzzy previous token behaviour on the corresponding dataset, an example presented below.
In this case, the clean run’s 0th-rank token is always the correct token while this is true for only 80% of the corrupted runs on the dataset examples. The mean probability associated with the correct token for the clean run is 0.87 and 0.40 for the corrupted run.
% of correct top prediction | mean probability of correct prediction | |
clean | 100% | 0.87 |
ablated | 80% | 0.40 |
As above, we iteratively BOS-ablate each token in prompts across the dataset and record the drop in probability assigned to the correct token.
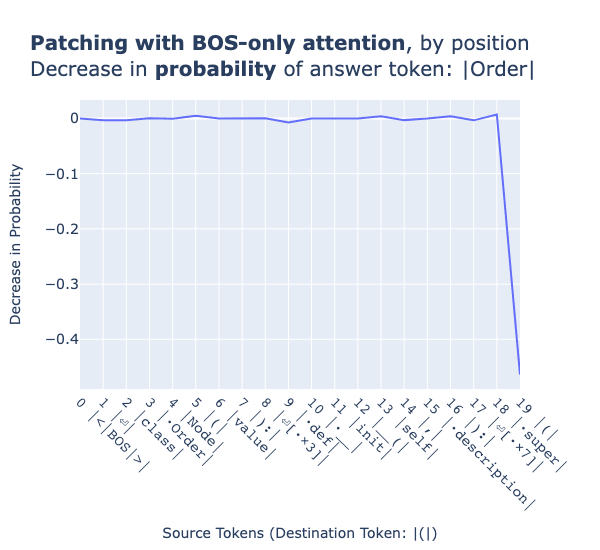
The drop in the probability across all tokens besides the open bracket token is negligible, whereas this token is associated with a 45 percentage point drop when BOS-ablated.
Conclusion
Our results suggest that head 1.4 in attn-only-4l exhibits multiple simple attention patterns that are relevant to model's performance. We believe the model is incentivized to use a single head for many purposes because it saves parameters. We are curious how these behaviours are implemented by the head, but we did not make meaningful progress trying to understand this mechanistically.
We believe the results are relevant to circuit analysis, because researchers often label attention heads based purely on its behaviour on a narrow task (IOI, Docstring [AF · GW], MMLU). Copy Suppression is an exception.
We would like to thank @Yeu-Tong Lau [LW · GW] and @jacek [LW · GW] for feedback on the draft.
0 comments
Comments sorted by top scores.