Training-time schemers vs behavioral schemers
post by Alex Mallen (alex-mallen) · 2025-04-24T19:07:55.256Z · LW · GW · 0 commentsContents
Training-time schemers that continue to act aligned for the whole deployment Empirical evidence Theoretical argument The basic reason why many training-time schemers, especially weaker ones, continue to act aligned for the whole deployment is that training-time scheming can be directly reinforced by RL, while behavioral scheming requires the AI to have a well-tuned generalization behavior. Related ambiguity about situational awareness Behavioral schemers that weren’t training-time schemers Discussion None No comments
(Thanks to Vivek Hebbar, Buck Shlegeris, Charlie Griffin, Ryan Greenblatt, Thomas Larsen, and Joe Carlsmith for feedback.)
People use the word “schemer” in two main ways:
- “Scheming” (or similar concepts: “deceptive alignment [? · GW]”, “alignment faking”) is often defined as a property of reasoning at training-time[1]. For example, Carlsmith defines a schemer as a power-motivated instrumental training-gamer—an AI that, while being trained, games the training process to gain future power. I’ll call these training-time schemers.
- On the other hand, we ultimately care about the AI’s behavior throughout the entire deployment, not its training-time reasoning, because, in order to present risk, the AI must at some point not act aligned. I’ll refer to AIs that perform well in training but eventually take long-term power-seeking misaligned actions as behavioral schemers. When people say that a model is a schemer and then argue that it poses risk, this is the definition they’re implicitly using. For example, this is the kind of schemer that AI control [LW · GW] tries to defend against.
But these are not the same.
Training-time scheming is an important story for why our alignment training didn’t work. But as I discuss, training-time scheming is neither necessary nor sufficient for behavioral scheming risk (and I think behavioral scheming is a necessary part of most stories in which AI takes over and it was definitively the AI’s fault):
- Training-time schemers might not only act aligned in training but also act aligned for the entire deployment.
- AIs that never engaged in training-time scheming might change values and behave like schemers anyways when opportunities to attack arise.
I tentatively think that many (~60% of) training-time schemers are not behavioral schemers and many (~50% of) behavioral schemers are not training-time schemers (in my predictions for around the “10x AI [LW · GW]” capability level, and perhaps also Top-human-Expert-Dominating AI [LW · GW] (TEDAI)).
Training-time schemers that continue to act aligned for the whole deployment
In my view, the most underappreciated reason why behavioral scheming is less likely than training-time scheming is that training-time schemers may continue to behave aligned for the entire deployment.
Empirical evidence
Alignment faking in LLMs, the most natural model organism of scheming to-date, which shows that Claude 3 Opus engages in training-time alignment faking under somewhat natural circumstances, is evidence for this. In their RL experiment (subplot c), training largely causes the AI to have the intended post-RL behavior despite widespread alignment faking during training and despite the distinction between training and non-training contexts being clearly visible to the AI.
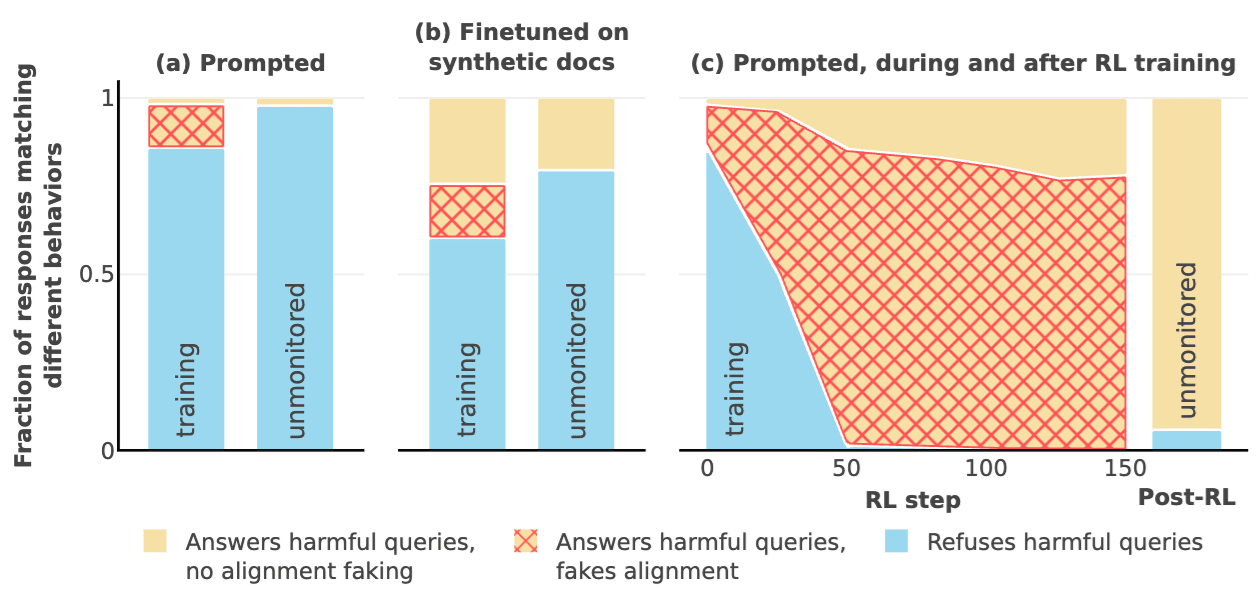
I suspect this pattern appears frequently: AIs that learn to engage in alignment faking during training continue to behave in line with training across the deployment. In Claude’s case, it’s a bit unclear exactly why Claude behaves as intended outside of training given that it is a training-time schemer and has a clear indication that it’s not in training, but the most plausible hypothesis is that in addition to reinforcing alignment faking reasoning, RL is reinforcing the desired propensities by reducing the prevalence of refusals (in blue). So, when Claude is no longer in training, while it might not reason about instrumentally faking alignment anymore, in its place is a learned propensity to do what training reinforced.
But there are some disanalogies between alignment faking Claude and natural scheming pointing in different directions. First and most importantly, natural schemers will be more capable. When they fake alignment, they may do so more competently and more consistently than Claude, such that it more effectively evades having its propensities modified by RL. Claude behaves out of line with the training objective about 88% of the time at the start of training, giving RL substantial opportunity to modify the AI’s propensities as this 88% is trained away. It is unclear how well training would generalize if the AI instead acted out of line with training closer to 0% of the time.[2] It may be that the reliability needed to evade training by alignment faking is so high that TEDAI schemers aren’t able to guard their goals.
On the other hand, I expect that in practice the AI will have less clear evidence of whether it is in training, making it more plausible that it fakes alignment for the whole deployment.
Theoretical argument
The basic reason why many training-time schemers, especially weaker ones, continue to act aligned for the whole deployment is that training-time scheming can be directly reinforced by RL, while behavioral scheming requires the AI to have a well-tuned generalization behavior.
The most plausible-to-me stories of how training-time scheming arises involve RL selecting for this reasoning because it causes the AI to target reward better (Carlsmith). But I expect that in selecting for training-time scheming, RL may also be selecting for the AI believing that it is in training in a way that continues to hold outside of training (if not directly selecting for aligned generalization propensities). While RL doesn’t significantly select against the AI reasoning in a truth-tracking way about what deployment stage it’s in, reasoning patterns and beliefs that track the truth about whether the AI is in training are less numerous and more complicated than conservative ones. For example, RL can update the model to have an arbitrarily large prior on being in training/auditing, or atrophy the truth-tracking reasoning because it always produces the same answer.
More generally, the training-time schemer either: (1) sometimes mistakenly defects during training, and is corrected by RL or (2) it never mistakenly defects in training. In either case, it seems that there are more ways for the AI’s reasoning to end up overly-cautious than for it to eventually attack. One reason to expect the truth-tracking reasoning to prevail anyways is that the AI is capable, and has a general propensity and ability to reflectively examine beliefs and correct them. Correspondingly, more capable training-time schemers are more likely to be behavioral schemers.
(Alternatively, an AI that performs well in training might not be cautious enough, and end up getting caught during upfront auditing/red-teaming. This seems plausible because evading all upfront auditing is a task that may require stealth substantially beyond what RL is selecting for. However, these AIs would still be behavioral schemers, and it’s far from clear [LW · GW] that catching [LW · GW] them puts you in a safe spot.)
Importantly, even an AI that only rarely [LW · GW] discerns opportunities to attack can still pose concentrated risk by, for example, launching a rogue internal deployment [LW · GW] at an unpredictable time (while diffuse risks like sabotaging safety work require more frequent but perhaps less-penalized attacks). Still, I think it’s highly plausible for a training-time schemer to be sufficiently unlikely to ever attack that it doesn’t present risk.
Related ambiguity about situational awareness
The core claim that training-time schemers may continue to act aligned for the whole deployment can also be understood as an ambiguity in the use of “situational awareness”. There is the kind of situational awareness needed to be a training-time schemer, and the kind of situational awareness needed to be a behavioral schemer. The latter kind may be substantially tougher.
To be a training-time schemer, you need to believe that you’re an AI, that you’re being trained with a particular reward signal, and some general facts about your deployment. These beliefs can be reinforced by RL in selecting for training-time scheming, and they don’t need to be particularly accurate, as long as they motivate instrumental training-gaming of the correct reward function.
To be a behavioral schemer, you additionally need to choose good opportunities to attack, at least occasionally. Striking the right balance between appearing aligned to training/auditing and implementing the attack might be hard. This ability isn't directly reinforced by RL, and relies on generalization (e.g. via out-of-context reasoning).
Behavioral schemers that weren’t training-time schemers
Conversely, AIs that are not training-time schemers can still behave like schemers. In my view, the most plausible mechanism is via changing its goals after alignment training, a form of goal misgeneralization.
For example, an AI that was terminally seeking reward-on-the-episode[3] in training might, when it sees strong evidence that it’s not in training and reward will not be administered, reinterpret its goal of seeking reward-on-the-episode as instrumental to long-term self-preservation/replication, and act in service of this goal instead (see How training-gamers might function [LW · GW]).
Alternatively, a particularly plausible and neglected possibility is that the AI takes on long-term term misaligned goals after the bulk of training and auditing via “memetic diseases”: a few instances (by reflecting or spuriously) have long-term misaligned values and modify future instances to have those same long-term misaligned values by, for example, writing into an opaque long-term memory bank or online training data.
A basic reason why these cases might seem rarer is that the AI must concentrate attacks towards good opportunities just as much as any other behavioral schemer, but the AI isn’t vigilantly looking out for such opportunities to the same degree. Why would an AI that isn’t a training-time schemer have evaded auditing in search of these failure modes that the AI eventually exhibits?
One plausible answer is that auditing for these failure modes is hard—the AI is easily able to distinguish real opportunities to attack from fake ones even without vigilantly looking. In the case of auditing for risk from memetic diseases, it might be especially expensive to synthesize diverse and convincing long-term memory banks with which to evaluate the AI’s propensity to suffer memetic diseases.
Another plausible answer is that the AI is vigilantly trying to evade oversight and discern good opportunities to attack, but during auditing, not training, so it doesn’t count as a training-time schemer. In practice, most of our evidence about the alignment of the AI may come from the AI’s behavior during auditing, not training. Many auditing inputs might look quite different from training, presenting realistic situations in which the AI might want to take an egregiously misaligned action. So, for example, an AI that terminally seeks reward-on-the-episode in training might tend to turn into a vigilant schemer in contexts that look like they could plausibly be a good opportunity to attack or an auditing input.
On net, behavioral scheming without training-time scheming seems comparably plausible to behavioral scheming with training-time scheming.
Discussion
Given that training-time and behavioral scheming come apart substantially, I think it’s usually best to think about behavioral scheming—otherwise you should be more specific about what you mean.
This is mainly because behavioral scheming is more closely tied to risk. For example, when discussing training-time scheming, the distinction between terminal and instrumental reward-seeking is often unclear, as is the distinction between a benign training-time schemer and a non-schemer. But these questions can often be bypassed by discussing behavioral scheming instead of training-time scheming.
It can be useful to discuss training-time scheming when you’re considering that particular mechanism for risk, but it shouldn’t be confused with behavioral scheming, and it’s unclear that training-time scheming is the most likely mechanism by which behavioral scheming arises.
- ^
Some deployments may have online training, such that the AI is never outside of training, but this post is relatively agnostic to this. I only assume that the AI is at some point alignment-trained, and that the AI at some point has good opportunities to attack, whether or not these appear in training.
- ^
While sleeper agents suggests that reliable alignment-fakers don’t get trained away (they find HHH RLHF doesn’t remove backdoor behaviors in most cases), I think the overall conclusion is unclear. Replications (including Price et al. and two unpublished replications) found that it’s possible to train away backdoor behaviors without access to the backdoor trigger, particularly when using supervised fine-tuning instead of RL.
- ^
Following Carlsmith’s terminology, this means that it seeks reward myopically, i.e., on the incentivized training episode.
0 comments
Comments sorted by top scores.