Activation additions in a small residual network
post by Garrett Baker (D0TheMath) · 2023-05-22T20:28:41.264Z · LW · GW · 4 commentsContents
Abstract Methodology[1] Results Conclusion None 4 comments
Abstract
Team Shard's recent activation addition methodology for steering GPT-2 XL [LW · GW] provokes many questions about what the structure of the internal model computation must be in order for their edits to work. Unfortunately, interpreting the insides of neural networks is known to be very difficult, so the question becomes: what is the minimal set of properties a network must have in order for adding activation additions to work?
Previously, I have tried to make some progress on this question by analyzing whether number additions work for a 784-512-512-10 fully connected MNIST network I had laying around [LW · GW]. They didn't. Generalization was destroyed, going from a loss of 0.089 for the unpatched network to an average loss of 7.4 for the modified network. Now I see whether additions work in a residual network I trained. Here's the code for the network:
class ResidualBlock(nn.Module):
def __init__(self, dim):
super(ResidualBlock, self).__init__()
self.linear = nn.Sequential(
nn.Linear(dim, dim)
)
self.relu = nn.ReLU()
def forward(self, x):
out = self.linear(x)
out += x
out = self.relu(out)
return out
# Define the ResNet
class ResNet(nn.Module):
def __init__(self, num_classes=10):
super(ResNet, self).__init__()
self.layer1 = nn.Linear(28*28, 512)
self.relu = nn.ReLU()
self.layer2 = ResidualBlock(512)
self.layer3 = nn.Linear(512, num_classes)
def forward(self, x, x_vector=None, return_midlayer_activation=False):
x = x.view(x.size(0), -1) # equivalent of doing einops.rearrange(x, 'b h w d -> b (h w d)')
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
if x_vector is not None: x += x_vector
activation = x
x = self.layer3(x)
if return_midlayer_activation:
return x, activation
else:
return xAgain, space is left for the interested reader to think of their predictions to themselves.
I found that when you add an a - b activation vector (using the x_vector functionality above), generalization is again destroyed, going from an average loss of 0.086 in the unmodified network to 6.31 in the patched network.
Methodology[1]
In this research, I implemented and employed a Residual Neural Network (ResNet) for experimentation with the MNIST dataset, a well-known dataset in the computer vision field comprising handwritten digits. My methodology can be broadly divided into several stages: defining the model architecture, preparing the dataset, model training, model testing, patch calculations, experimental analysis of patches, and data visualization.
Model Definition I defined a custom ResNet model for this study. The ResNet architecture, which introduces 'skip' or 'shortcut' connections, has proven successful in addressing the vanishing gradient problem in deep networks. My ResNet model comprises linear layers and incorporates a unique custom residual block. This block includes a linear layer followed by a ReLU activation function, with an identity shortcut connection added to the output.
Data Preparation For the preparation of the data, I used the MNIST dataset. The data was divided into training and test sets, following which data loaders were created for each set. I utilized a batch size of 100 for efficient computation during the training process.
Model Training The training phase involved running the model for ten epochs, with a learning rate of 0.001. I used the Adam optimization algorithm due to its superior performance in handling sparse gradients and noise. The loss function used during training was CrossEntropyLoss, which is suitable for multi-class classification problems. The trained model parameters were then saved for subsequent testing and analysis.
Patch Calculation and Analysis An essential part of my research involved the experimental analysis of 'patches'. A patch, in this context, represents the difference in the model's internal activations when fed with two different digit images. I designed several functions to calculate the model's output when applied to an image with a patch and without a patch. The output of these functions was the averaged output of the model and the average Cross-Entropy loss.
I calculated patch-related losses for all possible combinations of digits from 0 to 9, computed the average patch-related loss and average normal loss, and stored these in CSV files for further analysis.
Data Visualization Finally, I presented the results of my experiment visually. I used Matplotlib to generate bar plots displaying the model's output probabilities for both normal and patched conditions, for a random pair of digits. This helped in providing an intuitive understanding of the effect of patches on the model's output distributions.
Results
Here is the perplexity table for an a - b activation addition
| a\b | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 0 | 9.03E-02 | 5.75E+00 | 5.18E+00 | 1.29E+01 | 1.28E+01 | 1.14E+01 | 4.27E+00 | 8.05E+00 | 3.32E+00 | 6.45E+00 |
| 1 | 5.24E+00 | 9.36E-02 | 3.07E+00 | 9.94E+00 | 1.33E+00 | 6.92E+00 | 5.27E+00 | 1.23E+00 | 2.47E+00 | 5.08E+00 |
| 2 | 4.00E-01 | 1.22E+00 | 8.60E-02 | 6.01E+00 | 9.32E-01 | 5.87E+00 | 5.03E+00 | 1.57E+00 | 1.10E+00 | 2.66E+00 |
| 3 | 1.92E+01 | 2.51E+01 | 1.28E+01 | 8.27E-02 | 1.63E+01 | 3.51E+00 | 2.22E+01 | 1.52E+01 | 1.57E+01 | 1.32E+01 |
| 4 | 2.56E+00 | 5.20E-01 | 2.00E+00 | 9.09E+00 | 8.92E-02 | 1.42E+01 | 3.24E+00 | 6.87E-01 | 1.58E+00 | 5.40E-01 |
| 5 | 1.99E+01 | 1.44E+01 | 1.20E+01 | 6.48E+00 | 1.38E+01 | 7.99E-02 | 7.00E+00 | 1.61E+01 | 1.04E+01 | 1.15E+01 |
| 6 | 4.80E+00 | 8.57E+00 | 5.24E+00 | 2.80E+01 | 8.20E+00 | 1.19E+01 | 8.67E-02 | 1.45E+01 | 9.23E+00 | 1.53E+01 |
| 7 | 3.73E+00 | 1.87E+00 | 4.97E+00 | 4.70E+00 | 2.51E+00 | 7.28E+00 | 1.07E+01 | 8.18E-02 | 4.50E+00 | 4.12E+00 |
| 8 | 5.87E+00 | 1.42E+00 | 1.06E+00 | 2.83E+00 | 1.85E+00 | 6.82E+00 | 5.89E-01 | 3.40E+00 | 8.33E-02 | 7.98E-01 |
| 9 | 2.01E+00 | 5.93E+00 | 3.14E+00 | 2.39E+00 | 3.98E+00 | 7.03E+00 | 2.51E+00 | 1.28E+00 | 2.11E+00 | 8.68E-02 |
| Normal | 9.03E-02 | 9.36E-02 | 8.60E-02 | 8.27E-02 | 8.92E-02 | 7.99E-02 | 8.67E-02 | 8.18E-02 | 8.33E-02 | 8.68E-02 |
The average loss for the patched model across all a and b combinations was 6.31, and the average loss for the unpatched model across all b's was 0.086.
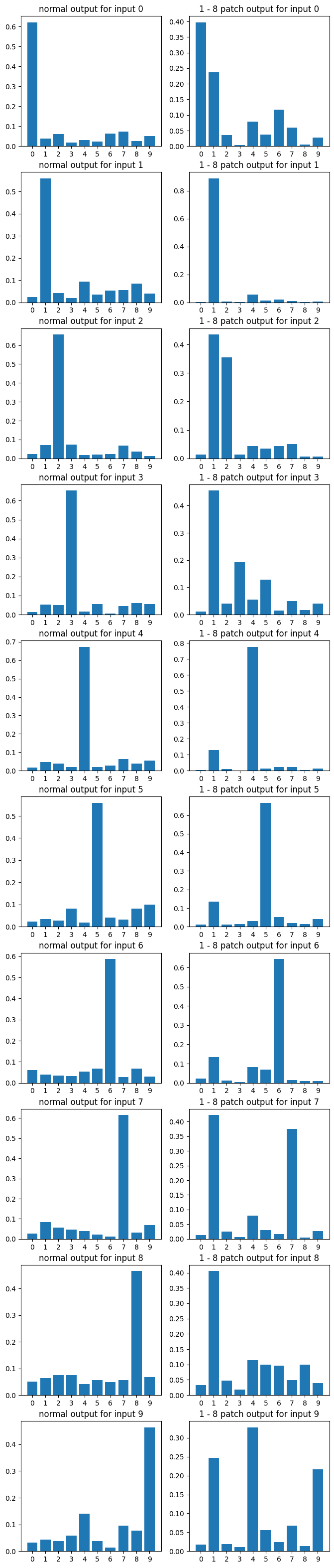
And here's a sampling of some random plots described in Data Visualization above. The interested reader can make their own such graphs by changing the a and b variables in the final section of their copy of the colab notebook above:
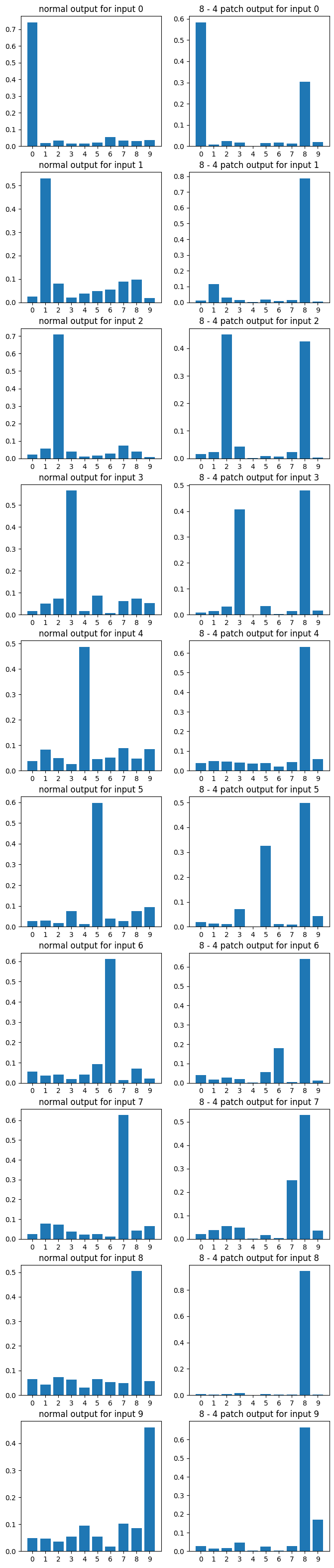
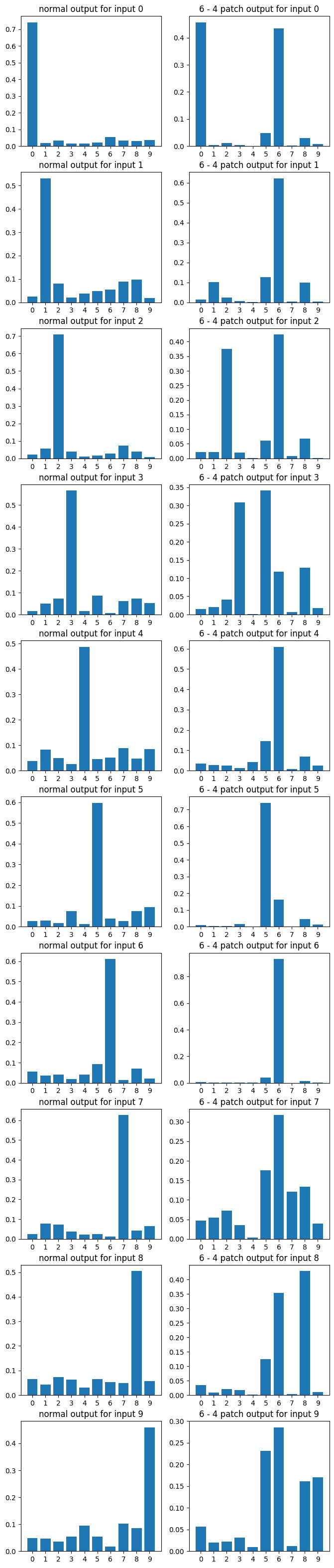
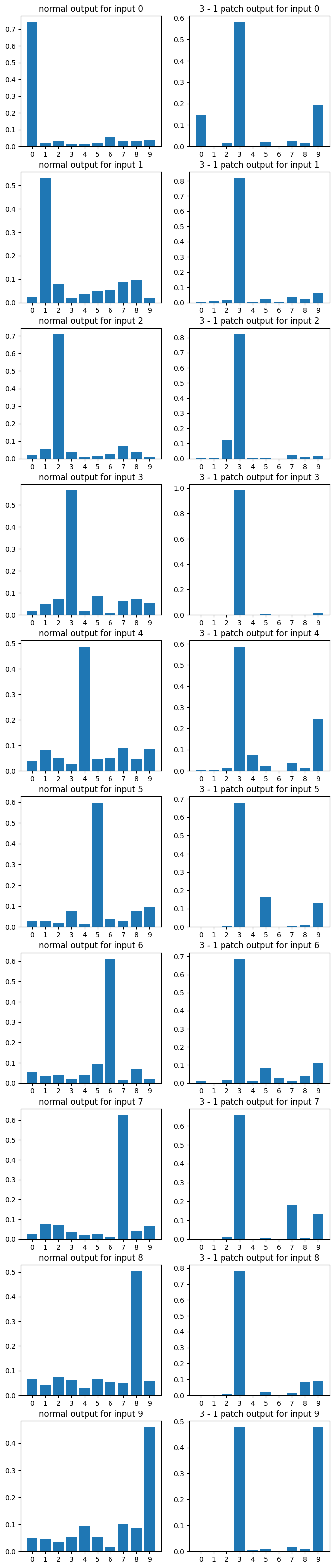
Conclusion
Beforehand I was very confident that vector additions would work here, even though I knew that the fully connected additions didn't work.[2]
My current main hypothesis is that in fact the structures present in the networks which are susceptible to vector additions like these are mainly influenced by higher level considerations which are not the architecture for the model involved, like the complexity of the task and how advanced the model's internal model is.
- ^
Note: Much of this section was written by giving ChatGPT my code and telling it to write a methodology section for a paper, then changing its use of "our" to "I" and "me". I have read what it wrote, and it seems to be accurate.
- ^
There was once the following text here:
Beforehand I was very confident that vector additions would work here, even though I knew that the fully connected additions didn't work. Before showing him the results, but after showing the results for the fully connected network, I asked TurnTrout for his prediction. He gave 85% that the additions would work.
But TurnTrout noted in the comments that this was in fact a correct/ambiguous prediction, since it made no claims about capability generalization. So I removed it, because it seems now irrelevant.
4 comments
Comments sorted by top scores.
comment by TurnTrout · 2023-05-23T22:41:12.376Z · LW(p) · GW(p)
Beforehand I was very confident that vector additions would work here, even though I knew that the fully connected additions didn't work. Before showing him the results, but after showing the results for the fully connected network, I asked TurnTrout for his prediction. He gave 85% that the additions would work.
I want to clarify that I had skimmed the original results and concluded that they "worked" in that 3-1 vectors got e.g. 1s to be classified as 3s. (This is not trivial, since not all 1 activations are the same!) However, those results "didn't work" in that they destroyed performance on non-1 images.
I thought I was making predictions on whether 3-1 vectors get 1s to be classified as 3s by this residual network. I guess I'm going to mark my prediction here as "ambiguous", in that case.
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2023-05-23T22:50:11.302Z · LW(p) · GW(p)
Oh, sorry. Editing post with correction.
comment by Joel Burget (joel-burget) · 2023-05-22T22:55:55.960Z · LW(p) · GW(p)
I have a couple of basic questions:
- Shouldn't diagonal elements in the perplexity table all be equal to the baseline (since the addition should be 0)?
- I'm a bit confused about the use of perplexity here. The added vector introduces bias (away from one digit and towards another). It shouldn't be surprising that perplexity increases? Eyeballing the visualizations they do all seem to shift mass away from
band towardsa.
↑ comment by Garrett Baker (D0TheMath) · 2023-05-22T23:10:05.371Z · LW(p) · GW(p)
- Yup. You should be able to see this in the chart.
- You're right, however the results from the Steering GPT-2-XL post showed that in GPT-2-XL, similar modifications had very little effect [LW · GW] on model perplexity. The patched model also doesn't only shift weight from
btoa. It also has wonky effects on other digits. For example, in the 3-1 patch for input 4, the weight given to 9 very much increased. More interestingly, it is not too uncommon to find examples which cause seemingly random digits to suddenly become the most likely. The 1-8 patch for input 9 is an example: