XKCD - Frequentist vs. Bayesians
post by brilee · 2012-11-09T05:25:49.367Z · LW · GW · Legacy · 91 commentsContents
91 comments
Is this a fair representation of frequentists versus bayesians? I feel like every time the topic comes up, 'Bayesian statistics' is an applause light for me, and I'm not sure why I'm supposed to be applauding.
91 comments
Comments sorted by top scores.
comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-11-09T17:09:08.450Z · LW(p) · GW(p)
Two subtleties here:
1) The neutrino detector is evidence that the Sun has exploded. It's showing an observation which is 36^H^H 35 times more likely to appear if the Sun has exploded than if it hasn't (likelihood ratio of 35:1). The Bayesian just doesn't think that's strong enough evidence to overcome the prior odds, i.e., after multiplying the prior odds by 35 they still aren't very high.
2) If the Sun has exploded, the Bayesian doesn't lose very much from paying off this bet.
Replies from: benelliott, JonathanLivengood, Decius, roland↑ comment by benelliott · 2012-11-09T17:25:29.814Z · LW(p) · GW(p)
Nitpick, the detector lies on double-six regardless of the outcome, so the likelihood ratio is 35:1, not 36:1.
Replies from: rockthecasbah↑ comment by Tim Liptrot (rockthecasbah) · 2020-06-18T19:54:11.119Z · LW(p) · GW(p)
Can you explain that more clearly? It seems that the sun exploding is so unlikely that the outcome doesn't matter. Perhaps you are confusing odds and probability?
↑ comment by JonathanLivengood · 2012-11-09T18:58:49.730Z · LW(p) · GW(p)
I just want to know why he's only betting $50.
Replies from: mwengler, beoShaffer↑ comment by mwengler · 2012-11-10T00:00:11.404Z · LW(p) · GW(p)
Because the stupider the prediction is that somebody is making, the harder it is to get them to put their money where their mouth is. The Bayesian is hoping that $50 is a price the other guy is willing to pay to signal his affiliation with the other non-Bayesians.
↑ comment by beoShaffer · 2012-11-10T00:04:56.829Z · LW(p) · GW(p)
Because its funnier that way.
↑ comment by Decius · 2012-11-09T17:51:15.401Z · LW(p) · GW(p)
I'll bet $50 that the sun hasn't just gone nova even in the presence of a neutron detector that says it has.
If I lose, I lose what $50 is worth in a world where the sun just went nova. If I win, I win $50 worth in a world where it didn't. That's a sucker bet even as the odds of the sun just having gone nova approach 1-Epsilon.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-11-09T18:50:08.373Z · LW(p) · GW(p)
Replies from: Decius"So," the Lord Pilot finally said. "What kind of asset retains its value in a market with nine minutes to live?"
"Booze for immediate delivery," the Master of Fandom said promptly. "That's what you call a -"
"Liquidity preference," the others chorused.
↑ comment by roland · 2012-11-13T16:02:18.898Z · LW(p) · GW(p)
If the Sun has exploded wouldn't you also feel the heat wave when the neutrino detector has gone off since heat radiation moves at the speed of light? So if you are not feeling/seeing anything it means the Sun hasn't exploded, right?
Replies from: JoshuaZ↑ comment by JoshuaZ · 2012-11-16T00:48:32.305Z · LW(p) · GW(p)
No. For example, in a supernova, the neutrinos leave the star a few hours before the light does (since they don't get slowed down by all the mass in between). That's why for example we were able to detect SN 1987A's neutrinos before the light arrived. Similarly, the Supernova Early Warning System has been set up so that astronomers can point their telescopes in the right direction before any of the light gets to us (because we can detect and pinpoint a close supernova from the burst of neutrinos).
comment by JonathanLivengood · 2012-11-09T08:19:50.886Z · LW(p) · GW(p)
Fair? No. Funny? Yes!
The main thing that jumps out at me is that the strip plays on a caricature of frequentists as unable or unwilling to use background information. (Yes, the strip also caricatures Bayesians as ultimately concerned with betting, which isn't always true either, but the frequentist is clearly the butt of the joke.) Anyway, Deborah Mayo has been picking on the misconception about frequentists for a while now: see here and here, for examples. I read Mayo as saying, roughly, that of course frequentists make use of background information, they just don't do it by writing down precise numbers that are supposed to represent either their prior degree of belief in the hypothesis to be tested or a neutral, reference prior (or so-called "uninformative" prior) that is supposed to capture the prior degree of evidential support or some such for the hypothesis to be tested.
Replies from: Luke_A_Somers, ChristianKl↑ comment by Luke_A_Somers · 2012-11-09T14:07:53.154Z · LW(p) · GW(p)
Good frequentists do that. The method itself doesn't promote this good practice.
Replies from: FiftyTwo, JonathanLivengood↑ comment by FiftyTwo · 2012-11-09T16:18:52.132Z · LW(p) · GW(p)
And bad Bayesians use crazy priors,
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2012-11-09T18:37:10.890Z · LW(p) · GW(p)
1) There is no framework so secure that no one is dumb enough to foul it up.
2) By having to use a crazy prior explicitly, this brings the failure point forward in one's attention.
Replies from: FiftyTwo↑ comment by FiftyTwo · 2012-11-09T19:05:48.257Z · LW(p) · GW(p)
I agree, but noticing 2 requires looking into how they've done the calculations, so simply knowing its bayesian isn't enough.
Replies from: khafra↑ comment by khafra · 2012-11-09T20:48:19.587Z · LW(p) · GW(p)
It might be enough. If it's published in a venue where the authors would get called on bullshit priors, the fact that it's been published is evidence that they used reasonably good priors.
Replies from: JonathanLivengood↑ comment by JonathanLivengood · 2012-11-09T21:43:34.441Z · LW(p) · GW(p)
The point applies well to evidentialists but not so well to personalists. If I am a personalist Bayesian -- the kind of Bayesian for which all of the nice coherence results apply -- then my priors just are my actual degrees of belief prior to conducting whatever experiment is at stake. If I do my elicitation correctly, then there is just no sense to saying that my prior is bullshit, regardless of whether it is calibrated well against whatever data someone else happens to think is relevant. Personalists simply don't accept any such calibration constraint.
Excluding a research report that has a correctly elicited prior smacks of prejudice, especially in research areas that are scientifically or politically controversial. Imagine a global warming skeptic rejecting a paper because its author reports having a high prior for AGW! Although, I can see reasons to allow this sort of thing, e.g. "You say you have a prior of 1 that creationism is true? BWAHAHAHAHA!"
One might try to avoid the problems by reporting Bayes factors as opposed to full posteriors or by using reference priors accepted by the relevant community or something like that. But it is not as straightforward as it might at first appear how to both make use of background information and avoid idiosyncratic craziness in a Bayesian framework. Certainly the mathematical machinery is vulnerable to misuse.
↑ comment by JonathanLivengood · 2012-11-09T18:42:30.096Z · LW(p) · GW(p)
That depends heavily on what "the method" picks out. If you mean that the machinery of a null hypothesis significance test against a fixed-for-all-time significance level of 0.05, then I agree, the method doesn't promote good practice. But if we're talking about frequentism, then identifying the method with null hypothesis significance testing looks like attacking a straw man.
Replies from: Luke_A_Somers↑ comment by Luke_A_Somers · 2012-11-12T03:52:34.546Z · LW(p) · GW(p)
I know a bunch of scientists who learned a ton of canned tricks and take the (frequentist) statisticians' word on how likely associations are... and the statisticians never bothered to ask how a priori likely these associations were.
If this is a straw man, it is one that has regrettably been instantiated over and over again in real life.
↑ comment by ChristianKl · 2012-11-09T15:01:35.058Z · LW(p) · GW(p)
If not using background information means you can publish your paper with frequentists methods, scientists often don't use background information.
Those scientifists who don't use less background information get more significant results. Therefore they get more published papers. Then they get more funding than the people who use more background information. It's publish or perish.
Replies from: JonathanLivengood↑ comment by JonathanLivengood · 2012-11-09T18:46:32.966Z · LW(p) · GW(p)
You could be right, but I am skeptical. I would like to see evidence -- preferably in the form of bibliometric analysis -- that practicing scientists who use frequentist statistical techniques (a) don't make use of background information, and (b) publish more successfully than comparable scientists who do make use of background information.
comment by gwern · 2012-11-10T16:03:19.136Z · LW(p) · GW(p)
Andrew Gelman on whether this strip is fair to frequentists:
I think the lower-left panel of the cartoon unfairly misrepresents frequentist statisticians. Frequentist statisticians recognize many statistical goals. Point estimates trade off bias and variance. Interval estimates have the goal of achieving nominal coverage and the goal of being informative. Tests have the goals of calibration and power. Frequentists know that no single principle applies in all settings, and this is a setting where this particular method is clearly inappropriate.
...the test with 1/36 chance of error is inappropriate in a classical setting where the true positive rate is extremely low.
The error represented in the lower-left panel of the cartoon is not quite not a problem with the classical theory of statistics—frequentist statisticians have many principles and hold that no statistical principle is all-encompassing (see here, also the ensuing discussion), but perhaps it is a problem with textbooks on classical statistics, that they typically consider the conditional statistical properties of a test (type 1 and type 2 error rates) without discussing the range of applicability of the method. In the context of probability mathematics, textbooks carefully explain that p(A|B) != p(B|A), and how a test with a low error rate can have a high rate of errors conditional on a positive finding, if the underlying rate of positives is low, but the textbooks typically confine this problem to the probability chapters and don’t explain its relevance to accept/reject decisions in statistical hypothesis testing. Still, I think the cartoon as a whole is unfair in that it compares a sensible Bayesian to a frequentist statistician who blindly follows the advice of shallow textbooks.As an aside, I also think the lower-right panel is misleading. A betting decision depends not just on probabilities but also on utilities. If the sun as gone nova, money is worthless. Hence anyone, Bayesian or not, should be willing to bet $50 that the sun has not exploded.
comment by gwern · 2012-11-09T16:15:05.168Z · LW(p) · GW(p)
No, it's not fair. Given the setup, the null hypothesis would be, I think, 'neither the Sun has exploded nor the dice come up 6', and so when the detector goes off we reject the 'neither x nor y' in favor of 'x or y' - and I think the Bayesian would agree too that 'either the Sun has exploded or the dice came up 6'!
Replies from: Eliezer_Yudkowsky, Manfred, noen↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-11-09T17:07:31.410Z · LW(p) · GW(p)
Um, I don't think the null hypothesis is usually phrased as, "There is no effect and our data wasn't unusual" and then you conclude "our data was unusual, rather than there being no effect" when you get data with probability < .05 if the Sun hasn't exploded. This is not a fair steelmanning.
Replies from: gwern↑ comment by gwern · 2012-11-09T17:13:57.470Z · LW(p) · GW(p)
I don't follow. The null hypothesis can be phrased in all sorts of ways based on what you want to test - there there's no effect, that the effect between two groups (eg. a new drug and an old drug) is the same etc.
then you conclude "our data was unusual, rather than there being no effect" when you get data with probability < .05 if the Sun hasn't exploded.
I don't know that my frequentist example does conclude the 'data was unusual' rather than 'there was an effect'. I am not sure how a frequentist would break apart the disjunction, or indeed, if they even would without additional data and assumptions.
Replies from: Cyan↑ comment by Cyan · 2012-11-09T18:48:32.037Z · LW(p) · GW(p)
Null hypotheses are phrased in terms of presumed stochastic data-generating mechanism; they do not address the data directly. That said, you are right about the conclusion one is to draw from the test. Fisher himself phrased it as
Either the hypothesis is untrue, or the value of [the test statistic] has attained by chance an exceptionally high value. [emphasis in original as quoted here].
↑ comment by Manfred · 2012-11-09T21:28:20.571Z · LW(p) · GW(p)
neither the Sun has exploded nor the dice come up 6
Given the statement of the problem, this null hypothesis is not at all probabilistic - we know it's false using deduction! This is an awful strange thing for a hypothesis to be in a problem that's supposed to be about probabilities.
Replies from: gwern, MixedNuts↑ comment by gwern · 2012-11-09T22:59:15.439Z · LW(p) · GW(p)
Since probabilistic reasoning is a superset of deductive logic (pace our Saint Jaynes, RIP), it's not a surprise if some formulations of some problems turn out that way.
Replies from: Manfred↑ comment by Manfred · 2012-11-10T00:37:03.514Z · LW(p) · GW(p)
probabilistic reasoning is a superset of deductive logic (pace our Saint Jaynes
Ah, you mean like in chapter 1 of his book? :P
Anyhow, I think this should be surprising. Deductive logic is all well and good, but merely exercising it, with no mention of probabilities, is not the characteristic behavior of something called an "interpretation of probability." If I run a vaccine trial and none of the participants get infected, my deductive conclusion is "either the vaccine worked, or it didn't and something else made none of the participants get infected - QED." And then I would submit this to The Lancet, and the reviewers would write me polite letters saying "could you do some statistical analyses?"
Replies from: gwern↑ comment by MixedNuts · 2012-11-09T22:49:44.922Z · LW(p) · GW(p)
"The machine has malfunctioned."
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2012-11-09T23:01:49.967Z · LW(p) · GW(p)
Why, I deny that, for the machine worked precisely as XKCD said it did.
↑ comment by noen · 2012-11-09T18:10:25.680Z · LW(p) · GW(p)
I think the null hypothesis is "the neutrino detector is lying" because the question we are most interested in is if it is correctly telling us the sun has gone nova. If H0 is the null hypothesis and u1 is the chance of a neutrino event and u2 is the odds of double sixes then H0 = µ1 - µ2. Since the odds of two die coming up sixes is vastly larger than the odds of the sun going nova in our lifetime the test is not fair.
Replies from: gwern↑ comment by gwern · 2012-11-09T18:32:35.671Z · LW(p) · GW(p)
I don't think one would simply ignore the dice, and what data is the frequentist drawing upon in the comic which specifies the null?
Replies from: noen↑ comment by noen · 2012-11-09T20:16:41.590Z · LW(p) · GW(p)
How about "the probability of our sun going nova is zero and 36 times zero is still zero"?
Although... continuing with the XKCD theme if you divide by zero perhaps that would increase the odds. ;)
Replies from: Cyan↑ comment by Cyan · 2012-11-09T20:22:50.846Z · LW(p) · GW(p)
Since the sun going nova is not a random event, strict frequentists deny that there is a probability to associate with it.
Replies from: noen↑ comment by noen · 2012-11-09T23:56:30.182Z · LW(p) · GW(p)
Among candidate stars for going nova I would think you could treat it as a random event. But Sol is not a candidate and so doesn't even make it into the sample set. So it's a very badly constructed setup. It's like looking for a needle in 200 million haystacks but restricting yourself only to those haystacks you already know it cannot be in. Or do I have that wrong.
Replies from: Cyancomment by lukeprog · 2012-11-09T05:38:17.910Z · LW(p) · GW(p)
Two clarifications: Frequentist vs Bayesian breakdown: interpretation vs inference; Beyond Bayesians and Frequentists.
Replies from: lukeprog↑ comment by lukeprog · 2012-11-10T04:06:51.760Z · LW(p) · GW(p)
Another clarification: Induction and deduction in Bayesian data analysis.
comment by CronoDAS · 2012-11-10T01:20:42.673Z · LW(p) · GW(p)
Regarding the comic: if the sun exploded and it's nighttime, you could still find out by looking to see if the moon just got a lot brighter.
Replies from: None, None, brilee↑ comment by brilee · 2012-11-10T04:12:16.129Z · LW(p) · GW(p)
No... because the time it takes the sun's increased brilliance to reach the moon and reflect to the Earth is the same as the time it takes for the Earth to be wiped out by the energy wave.
Replies from: tim↑ comment by tim · 2012-11-11T02:41:44.250Z · LW(p) · GW(p)
This assumes that the supernova is expanding at the speed of light.
According to wikipedia:
<The explosion expels much or all of a star's material at a velocity of up to 30,000 km/s (10% of the speed of light), driving a shock wave into the surrounding interstellar medium.
comment by A1987dM (army1987) · 2012-11-09T09:41:24.204Z · LW(p) · GW(p)
I wish the frequentist were a straw man, but they do do stuff nearly that preposterous in the real world. (ESP tests spring to mind.)
Replies from: AlexSchell↑ comment by AlexSchell · 2012-11-09T19:18:08.777Z · LW(p) · GW(p)
Some frequentists (not they) do those things. Most others are busy with good work, e.g. discovering things like the Higgs. (Concerning ESP, this also springs to mind.)
Replies from: army1987↑ comment by A1987dM (army1987) · 2012-11-09T19:40:22.384Z · LW(p) · GW(p)
I think they discovered the Higgs in spite of being frequentists (or, more likely, of paying lip service to frequentism), not thanks to being frequentists.
Replies from: AlexSchell↑ comment by AlexSchell · 2012-11-10T03:03:01.322Z · LW(p) · GW(p)
I agree, but notice that now you're no longer talking about the practitioners, you're talking about the doctrine. The existence of some ghost-hunting frequentists doesn't prevent the frequentist in the comic from being a straw man of actual frequentists (because they're highly atypical; cf. the existence of ghost-hunting Bayesians).
comment by Spectral_Dragon · 2012-11-09T14:32:41.126Z · LW(p) · GW(p)
I found it hilarious, I think it's the first time I've seen bayesians mentioned outside LW, and since it seems to be a lot of betting, wagers, problems hinging on money, I think both are equally approporiate. Insightful for being mostly entertainment (the opposite of the articles here - aiming to be insightful, usually ending up entertaining as well?), but my warning light also went off. Perhaps I'm already too attached to the label... I'll try harder than usual to spot cult behaviour now.
comment by Petruchio · 2012-11-09T20:44:41.172Z · LW(p) · GW(p)
I felt that the comic is quite entertaining. This marks the first time that I have seen Bayes be mentioned in the mainstream (if you can call XKCD the internet mainstream). Hopefully it will introduce Bayes to a new audience.
I feel that it is a good representation of frequentists and Bayesians. A Bayesian would absolutely use this as an opportunity to make a buck.
comment by Pavitra · 2012-11-09T19:30:24.846Z · LW(p) · GW(p)
My general impression is that Bayes is useful in diagnosis, where there's a relatively uncontroversially already-known base rate, and frequentism is useful in research, where the priors are highly subject to disagreement.
Replies from: Manfred, jsalvatier↑ comment by Manfred · 2012-11-09T21:07:10.932Z · LW(p) · GW(p)
Why this isn't necessarily true:
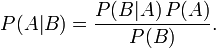
If we look at Bayes' theorem (that picture above, with P(A|B) pronounced "probability of A if we learn B"), our probability of A after getting evidence B is equal to P(A) before you saw the evidence (the "prior probability"), times a factor P(B|A)/P(B).
This factor is called the "likelihood ratio," and it tells you how much impact the evidence should have on your probability - what it means is that the more unexpected the evidence would be if A wasn't true, the more the evidence supports A. Like how UFO abduction stories aren't very convincing, because we'd expect them to happen even if there weren't any aliens (so P(B|A)/P(B) is close to 1, so multiplying by that factor doesn't change our belief).
Anyhow, because Bayes' theorem can be split up into parts like this, research papers don't have to rely on priors! Each paper could just gather some evidence, and then report the likelihood ratio - P(evidence | hypothesis)/P(evidence). Then people with different priors would just multiply their prior, P(A), by the likelihood ratio, and that would be Bayes' theorem, so they would each get P(A|B). And if you want to gather evidence from multiple papers, you can just multiply them together.
Although, that's only in a fairy-tale world with e.g. no file-drawer effect. In reality, more care would be necessary - the point is just that differing priors don't halt science.
Replies from: Cyan↑ comment by Cyan · 2012-11-09T21:13:36.404Z · LW(p) · GW(p)
Anyhow, because Bayes' theorem can be split up into parts like this, research papers don't have to rely on priors! Each paper could just gather some evidence, and then report the likelihood ratio - P(evidence | hypothesis)/P(evidence).
That's not true in general.
Replies from: Manfred↑ comment by Manfred · 2012-11-09T21:54:32.924Z · LW(p) · GW(p)
Fair enough. Can I take your point to be "when things get super complicated, sometimes you can make conceptual progress only by not worrying about keeping track of everything?" The only trouble is that once you stop keeping track of probability/significance, it becomes difficult to pick it up again in the future - you'd need to gather additional evidence in a better-understood way to check what's going on. Actually, that's a good analogy for hypothesis generation, with the "difficult to keep track of" stuff becoming the problem of uncertain priors.
Replies from: Cyan↑ comment by Cyan · 2012-11-10T02:38:06.701Z · LW(p) · GW(p)
My point is more like: If scientific interest only rests on some limited aspect of the problem, you can't avoid priors by, e.g., simpy reporting likelihood ratios. Likelihood ratios summarize information about the entire problem, including the auxiliary, scientifically uninteresting aspects. The Bayesian way of making statements free of the auxiliary aspects (marginalization) requires, at the very least, a prior over those aspects.
I'm not sure if I agree or disagree with the third sentence on down because I don't understand what you've written.
↑ comment by jsalvatier · 2012-11-09T22:28:46.514Z · LW(p) · GW(p)
You can also do Bayesian analysis with 'non-informative' priors or weakly-informative priors. As an example of the latter: if you're trying to figure out the mean change earth's surface temperature you might say 'it's almost certainly more then -50C and less than 50C'.
Replies from: Pavitra↑ comment by Pavitra · 2012-11-10T20:34:03.203Z · LW(p) · GW(p)
Unfortunately, if there is disagreement merely about how much prior uncertainty is appropriate, then this is sufficient to render the outcome controversial.
Replies from: jsalvatier↑ comment by jsalvatier · 2012-11-10T22:02:21.115Z · LW(p) · GW(p)
I think your initial point is wrong.
There are 3 situations
- Clear prior info: Bayes works well.
- Controversial prior info, but posterior dominated by likelihood: Choose weak enough priors to convince skeptics. Bayes works well.
- Controversial prior info, posterior not dominated by likelihood: If you choose very weak priors skeptics won't be convinced. If you choose strong priors skeptics won't be convinced. Bayes doesn't work well. Frequentism will also not work well unless you sneak in strong assumptions.
↑ comment by Cyan · 2012-11-12T05:40:07.388Z · LW(p) · GW(p)
Frequentism will also not work well unless you sneak in strong assumptions.
You can get frequentism to work well by its own lights by throwing away information. The canonical example here would be the Mann-Whitney U test. Even if the prior info and data are both too sparse to indicate an adequate sampling distribution/data model, this test will still work (for frequentist values of "work").
comment by A1987dM (army1987) · 2012-11-09T15:31:07.216Z · LW(p) · GW(p)
I'm not sure why I'm supposed to be applauding.
Cox's theorem is a theorem. I get that the actual Bayesian methods can be infeasible to compute in certain conditions so people like certain approximations which apply when priors are non-informative, samples are large enough, etc., but why can't they admit they're approximations to something else, rather than come up with this totally new, counter-intuitive epistemology where it's not allowed to assign probabilities to fixed but unknown parameters, which is totally at odds with commonsensical usage (normal people have no qualms using words such as “probably”, “likely”, etc. about unknown but unchangeable situations, and sometimes even bet on them¹)?
For more information, read the first few chapters of Probability Theory: The Logic of Science by E.T. Jaynes.
- In poker, by the time you see your hand the deck has already been shuffled, so the sequence of the cards is fixed; but so long as none of the players knows it, that doesn't matter. I don't think anyone fails to get this and I guess frequentists are just compartmentalizing.
↑ comment by Cyan · 2012-11-09T19:56:51.891Z · LW(p) · GW(p)
why can't they admit they're approximations to something else, rather than come up with this totally new, counter-intuitive epistemology where it's not allowed to assign probabilities to fixed but unknown parameters
Because they don't accept the premises of Cox's theorem -- in particular, the one that says that the plausibility of a claim shall be represented by a single real number. I'm thinking of Deborah Mayo here (referenced upthread).
Replies from: ciphergoth, Sniffnoy, Matt_Simpson↑ comment by Paul Crowley (ciphergoth) · 2012-11-10T08:57:24.403Z · LW(p) · GW(p)
Have you tried offering de Finetti's choice to them? I had a go at one probability-resister here and basically they squirmed like a fish on a hook.
Replies from: Cyan, roystgnr↑ comment by Cyan · 2012-11-10T18:30:19.946Z · LW(p) · GW(p)
Mayo sees the process of science as one of probing a claim for errors by subjecting it to "severe" tests. Here the severity of a test (vis-a-vis a hypothesis) is the sampling probability that the hypothesis passes fails to pass the test given that the hypothesis does not, in fact, hold true. (Severity is calculated holding the data fixed and varying hypotheses.) This is a process-centred view of science: it sees good science as founded on methodologies that rarely permit false hypotheses to pass tests.
Her pithy slogan for the contrast between her view and Bayesian epistemology is "well-probed versus highly probable". I expect that even she were willing to offer betting odds on the truth of a given claim, she would still deny that her betting odds have any relevance to the process of providing a warrant for asserting the claim.
↑ comment by roystgnr · 2012-11-11T04:35:20.163Z · LW(p) · GW(p)
You know, it's actually possible for a rational person to be unable to give consistent answers to de Finetti's choice under certain circumstances. When the person offering the bet is a semi-rational person who wants to win money and who might have unknown-to-me information, that's evidence in favor of the position they're offering to take. Because I should update in the direction of their implied beliefs no matter which side of the bet they offered me, there will be a range around my own subjective probability in which I won't want to take any bet.
Sure, when you're 100% sure that the person offering the bet is a nerd who's solely trying to honestly elicit some Bayesian subjective probability estimate, then you're safe taking either side of the same probability bet. But I'll bet your estimate of that likelihood is less than 100%.
Replies from: JonathanLivengood↑ comment by JonathanLivengood · 2012-11-11T05:30:12.279Z · LW(p) · GW(p)
I don't see how this applies to ciphergoth's example. In the example under consideration, the person offering you the bet cannot make money, and the person offered the bet cannot lose money. The question is, "For which of two events would you like to be paid some set amount of money, say $5, in case it occurs?" One of the events is that a fair coin flip comes up heads. The other is an ordinary one-off occurrence, like the election of Obama in 2012 or the sun exploding tomorrow.
The goal is to elicit the degree of belief that the person has in the one-off event. If the person takes the one-off event when given a choice like this, then we want to say (or de Finetti wanted to say, anyway) that the person's prior is greater than 1/2. If the person says, "I don't care, let me flip a coin," like ciphergoth's interlocutor did, then we want to say that the person has a prior equal to 1/2. There are still lots of problems, since (among other things) in the usual personalist story, degrees of belief have to be infinitely precise -- corresponding to a single real number -- and it is not clear that when a person says, "Oh, just flip a coin," the person has a degree of belief equal to 1/2, as opposed to an interval-valued degree of belief centered on 1/2 or something like that.
But anyway, I don't see how your point makes contact with ciphergoth's.
Replies from: roystgnr, lmm↑ comment by roystgnr · 2012-11-12T18:12:05.342Z · LW(p) · GW(p)
For a rational person with infinite processing power, my point doesn't apply. You can also neglect air resistance when determining the trajectory of a perfectly spherical cow in a vacuum.
For a person of limited intelligence (i.e. all of us), it's typically necessary to pick easily-evaluated heuristics that can be used in place of detailed analysis of every decision. I last used my "people offering me free stuff out of nowhere are probably trying to scam me somehow" heuristic while opening mail a few days ago. If ciphergoth's interlocuter had been subconsciously thinking the same way, then this time they missed a valuable opportunity for introspection, but it's not immediately obvious that such false positive mistakes are worse than the increased possibility of false negatives that would be created if they instead tried to successfully outthink every "cannot lose" bet that comes their way.
↑ comment by Matt_Simpson · 2012-11-10T04:44:18.482Z · LW(p) · GW(p)
I poked around, but couldn't find anything where Mayo talked about Cox's Theorem and it's premises. Did you have something particular in mind?
Replies from: Cyan, Cyan↑ comment by Cyan · 2012-11-12T05:13:43.979Z · LW(p) · GW(p)
Ah, found it:
Replies from: Matt_SimpsonWe know, infer, accept, and detach from evidence, all kinds of claims without any inclination to add an additional quantity such as a degree of probability or belief arrived at via, and obeying, the formal probability calculus.
↑ comment by Matt_Simpson · 2012-11-12T05:58:47.969Z · LW(p) · GW(p)
Thanks!
↑ comment by Cyan · 2012-11-10T05:47:29.321Z · LW(p) · GW(p)
As far as I know, she is not familiar with Cox's Theorem at all, nor does she explicitly address the premise in question. I've been following her blog from the start, and I tried to get her to read about Cox's theorem two or three times. I stopped after I read a post which made it clear to me that she thinks that encoding the plausibility of a claim with a single real number is not necessary -- not useful, even -- to construct an account of how science uses data to provide a warrant for a scientific claim. Unfortunately I don't remember when I read the post...
comment by AshwinV · 2015-06-04T07:53:57.533Z · LW(p) · GW(p)
In my opinion, sort of. Munroe probably left out the reasoning of the Bayesian for comic effect.
But the answer is that the Bayesian would be paying attention to the prior probability that the sun went out. Therefore, he would have concluded that the sun didn't actually go out and that the dice rolled six twice for a completely different reason.
comment by patriota · 2013-05-19T04:40:45.481Z · LW(p) · GW(p)
The p-value for this problem is not 1/36. Notice that, we have the following two hypotheses, namely
H0: The Sun didn't explode, H1: The Sun exploded.
Then,
p-value = P("the machine returns yes", when the Sun didn't explode).
Now, note that the event
"the machine returns yes"
is equivalent to
"the neutrino detector measures the Sun exploding AND tells the true result" OR "the neutrino detector does not measure the Sun exploding AND lies to us".
Assuming that the dice throwing is independent of the neutrino detector measurement, we can compute the p-value. First define:
p0 = P("the neutrino detector measures the Sun exploding", when the Sun didn't explode),
then the p-value is
p-value = p035/36 + (1-p0)1/36
=> p-value = (1/36)(35p0 + 1 - p0)
=> p-value = (1/36)(1+34p0).
If p0 = 0, then we are considering that the detector machine will never measure that "the Sun just exploded". The value p0 is obviously incomputable, therefore, a classical statistician that knows how to compute a p-value would never say that the Sun just exploded. By the way, the cartoon is funny.
Best regards, Alexandre Patriota.
Replies from: benelliott↑ comment by benelliott · 2013-06-16T10:31:58.169Z · LW(p) · GW(p)
(1/36)(1+34p0) is bounded by 1/36, I think a classical statistician would be happy to say that the evidence has a p-value of 1/36 her. Same for any test where H_0 is a composite hypothesis, you just take the supremum.
A bigger problem with your argument is that it is a fully general counter-argument against frequentists ever concluding anything. All data has to be acquired before it can be analysed statistically, all methods of acquiring data have some probability of error (in the real world) and the probability of error is always 'unknowable', at least in the same sense that p0 is in your argument.
You might as well say that a classical statistician would not say the sun had exploded because he would be in a state of total Cartesian doubt about everything.
Replies from: patriota↑ comment by patriota · 2013-12-27T13:00:52.022Z · LW(p) · GW(p)
For this problem, the p-value is bounded by 1/36 from below, that is, p-value > 1/36. The supremum of (1/36)(1+34p0) is 35/36 and the infimum is 1/36. Therefore, I'm not taking the supremum, actually the cartoon took the infimum, when you take the infimum you are assuming the neutrino detector measures without errors and this is a problem. The p-value, for this example, is a number between 1/36 and 35/36.
I did not understand "the big problem" with my argument...
comment by alanog · 2012-11-11T19:10:21.051Z · LW(p) · GW(p)
Can someone help me understand the point being made in this response? http://normaldeviate.wordpress.com/2012/11/09/anti-xkcd/
Replies from: JonathanLivengood↑ comment by JonathanLivengood · 2012-11-11T22:11:42.807Z · LW(p) · GW(p)
The point depends on differences between confidence intervals and credible intervals.
Roughly, frequentist confidence intervals, but not Bayesian credible intervals, have the following coverage guarantee: if you repeat the sampling and analysis procedure over and over, in the long-run, the confidence intervals produced cover the truth some percentage of the time corresponding to the confidence level. If I set a 95% confidence level, then in the limit, 95% of the intervals I generate will cover the truth.
Bayesian credible intervals, on the other hand, tell us what we believe (or should believe) the truth is given the data. A 95% credible interval contains 95% of the probability in the posterior distribution (and usually is centered around a point estimate). As Gelman points out, Bayesians can also get a kind of frequentist-style coverage by averaging over the prior. But in Wasserman's cartoon, the target is a hard-core personalist who thinks that probabilities just are degrees of belief. No averaging is done, because the credible intervals are just supposed to represent the beliefs of that particular individual. In such a case, we have no guarantee that the credible interval covers the truth even occasionally, even in the long-run.
Take a look here for several good explanations of the difference between confidence intervals and credible intervals that are much more detailed than my comment here.
Replies from: gwern↑ comment by gwern · 2012-11-11T22:53:24.962Z · LW(p) · GW(p)
Roughly, frequentist confidence intervals, but not Bayesian credible intervals, have the following coverage guarantee: if you repeat the sampling and analysis procedure over and over, in the long-run, the confidence intervals produced cover the truth some percentage of the time corresponding to the confidence level. If I set a 95% confidence level, then in the limit, 95% of the intervals I generate will cover the truth.
Right. This is what my comment there was pointing out: in his very own example, physics, 95% CIs do not get you 95% coverage since when we look at particle physics's 95% CIs, they are too narrow. Just like his Bayesian's 95% credible intervals. So what's the point?
Replies from: JonathanLivengood↑ comment by JonathanLivengood · 2012-11-11T23:13:42.969Z · LW(p) · GW(p)
I suspect you're talking past one another, but maybe I'm missing something. I skimmed the paper you linked and intend to come back to it in a few weeks, when I am less busy, but based on skimming, I would expect the frequentist to say something like, "You're showing me a finite collection of 95% confidence intervals for which it is not the case that 95% of them cover the truth, but the claim is that in the long run, 95% of them will cover the truth. And the claim about the long run is a mathematical fact."
I can see having worries that this doesn't tell us anything about how confidence intervals perform in the short run. But that doesn't invalidate the point Wasserman is making, does it? (Serious question: I'm not sure I understand your point, but I would like to.)
Replies from: gwern↑ comment by gwern · 2012-11-11T23:18:24.663Z · LW(p) · GW(p)
Well, I'll put it this way - if we take as our null hypothesis 'these 95% CIs really did have 95% coverage', would the observed coverage-rate have p<0.05? If it did, would you or him resort to 'No True Scotsman' again?
(A hint as to the answer: just a few non-coverages drive the null down to extremely low levels - think about multiplying 0.05 by 0.05...)
Replies from: JonathanLivengood↑ comment by JonathanLivengood · 2012-11-12T00:36:04.369Z · LW(p) · GW(p)
Yeah, I still think you're talking past one another. Wasserman's point is that something being a 95% confidence interval deductively entails that it has the relevant kind of frequentist coverage. That can no more fail to be true than 2+2 can stop being 4. The null, then, ought to be simply that these are really 95% confidence intervals, and the data then tell against that null by undermining a logical consequence of the null. The data might be excellent evidence that these aren't 95% confidence intervals. Of course, figuring out exactly why they aren't is another matter. Did the physicists screw up? Were their sampling assumptions wrong? I would guess that there is a failure of independence somewhere in the example, but again, I haven't read the paper carefully or really looked at the data.
Anyway, I still don't see what's wrong with Wasserman's reply. If they don't have 95% coverage, then they aren't 95% confidence intervals.
So, is your point that we often don't know when a purportedly 95% confidence interval really is one? Or that we don't know when the assumptions are satisfied for using confidence intervals? Those seem like reasonable complaints. I wonder what Wasserman would have to say about those objections.
Replies from: gwern↑ comment by gwern · 2012-11-12T01:19:23.380Z · LW(p) · GW(p)
So, is your point that we often don't know when a purportedly 95% confidence interval really is one?
I'm saying that this stuff about 95% CI is a completely empty and broken promise; if we see the coverage blown routinely, as we do in particle physics in this specific case, the CI is completely useless - it didn't deliver what it was deductively promised. It's like have a Ouija board which is guaranteed to be right 95% of the time, but oh wait, it was right just 90% of the time so I guess it wasn't really a Oujia board after all.
Even if we had this chimerical '95% confidence interval', we could never know that it was a genuine 95% confidence interval. I am reminded of Borges:
It is universally admitted that the unicorn is a supernatural being of good omen; such is declared in all the odes, annals, biographies of illustrious men and other texts whose authority is unquestionable. Even children and village women know that the unicorn constitutes a favorable presage. But this animal does not figure among the domestic beasts, it is not always easy to find, it does not lend itself to classification. It is not like the horse or the bull, the wolf or the deer. In such conditions, we could be face to face with a unicorn and not know for certain what it was. We know that such and such an animal with a mane is a horse and that such and such an animal with horns is a bull. But we do not know what the unicorn is like.
It is universally admitted that the 95% confidence interval is a result of good coverage; such is declared in all the papers, textbooks, biographies of illustrious statisticians and other texts whose authority is unquestionable...
(Given that "95% CIs" are not 95% CIs, I will content myself with honest credible intervals, which at least are what they pretend to be.)
comment by Error · 2012-11-10T16:13:17.570Z · LW(p) · GW(p)
My immediate takeaway from the strip was something like: "I'm the only one I know who's going to get the joke, and there is something cool about that."
The satisfaction that thought gives me makes me suspect I'm having a mental error, but I haven't identified it yet.