Tradeoff between desirable properties for baseline choices in impact measures
post by Vika · 2020-07-04T11:56:04.239Z · LW · GW · 24 commentsContents
24 comments
(Cross-posted to personal blog. Summarized in Alignment Newsletter #108. Thanks to Carroll Wainwright, Stuart Armstrong, Rohin Shah and Alex Turner for helpful feedback on this post.)
Impact measures are auxiliary rewards for low impact on the agent's environment, used to address the problems of side effects and instrumental convergence. A key component of an impact measure is a choice of baseline state: a reference point relative to which impact is measured. Commonly used baselines are the starting state, the initial inaction baseline (the counterfactual where the agent does nothing since the start of the episode) and the stepwise inaction baseline (the counterfactual where the agent does nothing instead of its last action). The stepwise inaction baseline is currently considered the best choice because it does not create the following bad incentives for the agent: interference with environment processes or offsetting its own actions towards the objective. This post will discuss a fundamental problem with the stepwise inaction baseline that stems from a tradeoff between different desirable properties for baseline choices, and some possible alternatives for resolving this tradeoff.
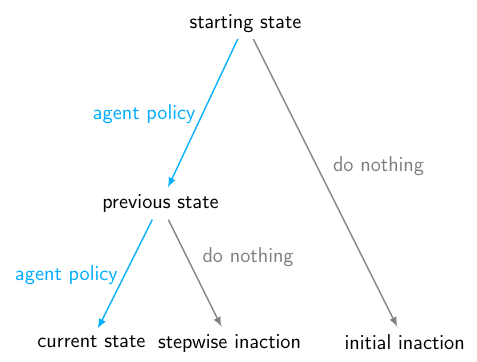
One clearly desirable property for a baseline choice is to effectively penalize high-impact effects, including delayed effects. It is well-known that the simplest form of the stepwise inaction baseline does not effectively capture delayed effects. For example, if the agent drops a vase from a high-rise building, then by the time the vase reaches the ground and breaks, the broken vase will be the default outcome. Thus, in order to penalize delayed effects, the stepwise inaction baseline is usually used in conjunction with inaction rollouts, which predict future outcomes of the inaction policy. Inaction rollouts from the current state and the stepwise baseline state are compared to identify delayed effects of the agent's actions. In the above example, the current state contains a vase in the air, so in the inaction rollout from the current state the vase will eventually reach the ground and break, while in the inaction rollout from the stepwise baseline state the vase remains intact.
While inaction rollouts are useful for penalizing delayed effects, they do not address all types of delayed effects. In particular, if the task requires setting up a delayed effect, an agent with the stepwise inaction baseline will have no incentive to undo the delayed effect. Here are some toy examples that illustrate this problem.
Door example. Suppose the agent's task is to go to the store, which requires opening the door in order to leave the house. Once the door has been opened, the effects of opening the door are part of the stepwise inaction baseline, so the agent has no incentive to close the door as it leaves.
Red light example. Suppose the agent's task is to drive from point A to point B along a straight road, with a reward for reaching point B. To move towards point B, the agent needs to accelerate. Once the agent has accelerated, it travels at a constant speed by default, so the noop action will move the agent along the road towards point B. Along the road (), there is a red light and a pedestrian crossing the road. The noop action in crosses the red light and hits the pedestrian (). To avoid this, the agent needs to deviate from the inaction policy by stopping () and then accelerating ().

The stepwise inaction baseline will incentivize the agent to run the red light and go to . The inaction rollout at penalizes the agent for the predicted delayed effect of running over the pedestrian when it takes the accelerating action to go to . The agent receives this penalty whether or not it actually ends up running the red light or not. Once the agent has reached , running the red light becomes the default outcome, so the agent is not penalized for doing so (and would likely be penalized for stopping). Thus, the stepwise inaction baseline gives no incentive to avoid running the red light, while the initial inaction baseline compares to and thus incentivizes the agent to stop at the red light.
This problem with the stepwise baseline arises from a tradeoff between penalizing delayed effects and avoiding offsetting incentives. The stepwise structure that makes it effective at avoiding offsetting makes it less effective at penalizing delayed effects. While delayed effects are undesirable, undoing the agent's actions is not necessarily bad. In the red light example, the action of stopping at the red light is offsetting the accelerating action. Thus, offsetting can be necessary for avoiding delayed effects while completing the task.
Whether offsetting an effect is desirable depends on whether this effect is part of the task objective. In the door-opening example, the action of opening the door is instrumental for going to the store, and many of its effects (e.g. strangers entering the house through the open door) are not part of the objective, so it is desirable for the agent to undo this action. In the vase environment shown below, the task objective is to prevent the vase from falling off the end of the belt and breaking, and the agent is rewarded for taking the vase off the belt. The effects of taking the vase off the belt are part of the objective, so it is undesirable for the agent to undo this action.
The difficulty of identifying these "task effects" that are part of the objective creates a tradeoff between penalizing delayed effects and avoiding undesirable offsetting. This tradeoff can be avoided by the starting state baseline, which however produces interference incentives. The stepwise inaction baseline cannot resolve the tradeoff, since it avoids all types of offsetting, including desirable offsetting.
The initial inaction baseline can resolve this tradeoff by allowing offsetting and relying on the task reward to capture task effects and penalize the agent for offsetting them. While we cannot expect the task reward to capture what the agent should not do (unnecessary impact), capturing task effects falls under what the agent should do, so it seems reasonable to rely on the reward function for this. This would work similarly to the impact penalty penalizing all impact, and the task reward compensating for this in the case of impact that's needed to complete the task.
This can be achieved using a state-based reward function that assigns reward to all states where the task is completed. For example, in the vase environment, a state-based reward of 1 for states with an intact vase (or with vase off the belt) and 0 otherwise would remove the offsetting incentive.
If it is not feasible to use a reward function that penalizes offsetting task effects, the initial inaction baseline could be modified to avoid this kind of offsetting. If we assume that the task reward is sparse and doesn't include shaping terms, we can reset the initial state for the baseline whenever the agent receives a task reward (e.g. the reward for taking the vase off the belt in the vase environment). This results in a kind of hybrid between initial and stepwise inaction. To ensure that this hybrid baseline effectively penalizes delayed effects, we still need to use inaction rollouts at the reset and terminal states.
Another desirable property of the stepwise inaction baseline is the Markov property: it can be computed based on the previous state, independently of the path taken to that state. The initial inaction baseline is not Markovian, since it compares to the state in the initial rollout at the same time step, which requires knowing how many time steps have passed since the beginning of the episode. We could modify the initial inaction baseline to make it Markovian, e.g. by sampling a single baseline state from the inaction rollout from the initial state, or by only computing a single penalty at the initial state by comparing an agent policy rollout with the inaction rollout.
To summarize, we want a baseline to satisfy the following desirable properties: penalizing delayed effects, avoiding interference incentives, and the Markov property. We can consider avoiding offsetting incentives for task effects as a desirable property for the task reward, rather than the baseline. Assuming such a well-specified task reward, a Markovian version of the initial inaction baseline can satisfy all the criteria.
24 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2020-07-12T15:08:04.294Z · LW(p) · GW(p)
Flo's summary for the Alignment Newsletter:
<@Impact measures@>(@Measuring and avoiding side effects using relative reachability@) usually require a baseline state, relative to which we define impact. The choice of this baseline has important effects on the impact measure's properties: for example, the popular stepwise inaction baseline (where at every step the effect of the current action is compared to doing nothing) does not generate incentives to interfere with environment processes or to offset the effects of its own actions. However, it ignores delayed impacts and lacks incentive to offset unwanted delayed effects once they are set in motion.
This points to a **tradeoff** between **penalizing delayed effects** (which is always desirable) and **avoiding offsetting incentives**, which is desirable if the effect to be offset is part of the objective and undesirable if it is not. We can circumvent the tradeoff by **modifying the task reward**: If the agent is only rewarded in states where the task remains solved, incentives to offset effects that contribute to solving the task are weakened. In that case, the initial inaction baseline (which compares the current state with the state that would have occurred if the agent had done nothing until now) deals better with delayed effects and correctly incentivizes offsetting for effects that are irrelevant for the task, while the incentives for offsetting task-relevant effects are balanced out by the task reward. If modifying the task reward is infeasible, similar properties can be achieved in the case of sparse rewards by setting the baseline to the last state in which a reward was achieved. To make the impact measure defined via the time-dependent initial inaction baseline **Markovian**, we could sample a single baseline state from the inaction rollout or compute a single penalty at the start of the episode, comparing the inaction rollout to a rollout of the agent policy.
Flo's opinion:
I like the insight that offsetting is not always bad and the idea of dealing with the bad cases using the task reward. State-based reward functions that capture whether or not the task is currently done also intuitively seem like the correct way of specifying rewards in cases where achieving the task does not end the episode.Replies from: Vika
↑ comment by Vika · 2020-07-12T15:37:34.877Z · LW(p) · GW(p)
Looks great, thanks! Minor point: in the sparse reward case, rather than "setting the baseline to the last state in which a reward was achieved", we set the initial state of the inaction baseline to be this last rewarded state, and then apply noops from this initial state to obtain the baseline state (otherwise this would be a starting state baseline rather than an inaction baseline).
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2020-07-12T17:16:47.129Z · LW(p) · GW(p)
Good point, changed
by setting the baseline to the last state in which a reward was achieved.
to
by using the inaction baseline, and resetting its initial state to the current state whenever a reward is achieved.
comment by Stuart_Armstrong · 2020-07-07T12:10:19.312Z · LW(p) · GW(p)
I also think the pedestrian example illustrates why we need more semantic structure: "pedestrian alive" -> "pedestrian dead" is bad, but "pigeon on road" -> "pigeon in flight" is fine.
Replies from: Vika↑ comment by Vika · 2020-07-07T15:05:32.062Z · LW(p) · GW(p)
I don't think the pedestrian example shows a need for semantic structure. The example is intended to illustrate that an agent with the stepwise inaction baseline has no incentive to undo the delayed effect that it has set up. We want the baseline to incentivize the agent to undo any delayed effect, whether it involves hitting a pedestrian or making a pigeon fly.
The pedestrian and pigeon effects differ in the magnitude of impact, so it is the job of the deviation measure to distinguish between them and penalize the pedestrian effect more. Optionality-based deviation measures (AU and RR) capture this distinction because hitting the pedestrian eliminates more options than making the pigeon fly.
Replies from: Koen.Holtman↑ comment by Koen.Holtman · 2020-07-17T15:56:44.333Z · LW(p) · GW(p)
Reading the above, I am reminded of a similar exchange about the need for semantic structure between Alex Turner and me here [? · GW], so I'd like to get to the bottom of this. Can you clarify your broader intuitions about the need or non-need for semantic structure? (Same question goes to Alex.)
Frankly, I expected you would have replied to Stuart's comment with a statement like the following: 'using semantic structure in impact measures is a valid approach, and it may be needed to encode certain values, but in this research we are looking at how far we can get by avoiding any semantic structure'. But I do not see that.
Instead, you seem to imply that leveraging semantic structure is never needed when further scaling impact measures. It looks like you feel that we can solve the alignment problem by looking exclusively at 'model-free' impact measures.
To make this more specific, take the following example. Suppose a mobile AGI agent has a choice between driving over one human, driving over P pigeons, or driving over C cats. Now, humans have very particular ideas about how they value the lives of humans, pigeons, and cats, and would expect that those ideas are reflected reasonably well in how the agent computes its impact measure. You seem to be saying that we can capture all this detail by just making the right tradeoffs between model-free terms, by just tuning some constants in terms that calculate 'loss of options by driving over X'.
Is this really what you are saying?
I have done some work myself on loss-of-options impact measures (see e.g. section 12 of my recent paper here [AF · GW]). My intuition about how far you can scale these 'model-free' techniques to produce human-morality-aligned safety properties in complex environments seems to be in complete disagreement with your comments and those made by Alex.
↑ comment by TurnTrout · 2020-07-18T12:13:44.041Z · LW(p) · GW(p)
I think of impact measures as trying to do (at least) two things:
- Stop catastrophic power-seeking [LW · GW] behavior in AGIs, and
- Penalize undesirable side-effects (running over 10 cats instead of 2 pigeons, breaking vases).
I tend to think about (1), because I think (2) is a lost cause without it - at least, if the agent is superhuman. I think that, if (1) is cleanly solvable, it will not require [? · GW] semantic structure. I also think that you can get a long ways towards (2) without explicit semantic structure (see Avoiding Side Effects in Complex Environments). Because I think (1) is so important, I've spent the last year trying to mathematically understand why power-seeking occurs.
That said, if we had a solution to (1) and fully wanted to solve (2), yes, I think we will need semantic structure. Certain effects are either (a) value-dependent (pigeons vs cats) or (b) too distant from the agent to count as option-loss-for-the-agent. For example, imagine penalizing breaking vases with AUP, but on the other side of the planet? They'll never show up in optimal value calculations.
I think many people think of (2) when they consider impact measures, while I usually think about purpose (1). Hopefully this clarifies my views a bit.
Replies from: Koen.Holtman↑ comment by Koen.Holtman · 2020-07-19T14:53:05.567Z · LW(p) · GW(p)
Thanks for clarifying your view! I agree that for point 1 above, less semantic structure should be needed.
Reading some of the links above again, I still feel that we might be having different views on how much semantic structure is needed. But this also depends on what you count as semantic structure.
To clarify where I am coming from, I agree with the thesis of your paper Optimal Farsighted Agents Tend to Seek Power. I am not in the camp which, to quote the abstract of the paper, 'voices scepticism' about emergent power seeking incentives.
But me the, the main mechanism that turns power seeking incentives into catastrophic power-seeking is when at least two power-seeking entities with less than 100% aligned goals start to interact with each other in the same environment. So I am looking for semantic models that are rich enough to capture at least 2 players being present in the environment.
I have the feeling that you believe that moving to the 2-or-more-players level of semantic modelling is of lesser importance, is in fact a distraction, that we may be able to solve things cleanly enough if we just make every agent not seek power too much. Or maybe you are just prioritizing a deeper dive in that particular direction initially?
Replies from: TurnTrout↑ comment by TurnTrout · 2020-07-19T15:40:30.050Z · LW(p) · GW(p)
By "semantic models that are rich enough", do you mean that the AI might need a semantic model for the power of other agents in the environment? There was an interesting paper about that idea. However, I think you shouldn't need to account for other agents' power directly - that the minimal viable design involves just having the AI not gain much power for itself.
I'm currently thinking more about power-seeking in the -player setting, however.
Replies from: Koen.Holtman↑ comment by Koen.Holtman · 2020-07-21T13:23:20.419Z · LW(p) · GW(p)
By "semantic models that are rich enough", do you mean that the AI might need a semantic model for the power of other agents in the environment?
Actually in my remarks above I am less concerned about how rich a model the AI may need. My main intuition is that we ourselves may need a semantic model for that describes the comparable power of several players, if our goal is to understand motivations towards power more deeply and generally.
To give a specific example from my own recent work [AF · GW]: in working out more details about corrigibility and indifference, I ended up defining a safety property 2 (S2 in the paper) that is about control. Control is a form of power: if I control an agent's future reward function, I have power over the agent, and indirect power over the resources it controls. To define safety property 2 mathematically, I had to make model extensions that I did not need to make to define or implement the reward function of the agent itself. So by analogy, if you want to understand and manage power seeking in an n-player setting, you may end up needing to define model extensions and metrics that are not present inside the reward functions or reasoning systems of each player. You may need them to measure, study, or define the nature of the solution.
The interesting paper you mention gives a kind-of example of such a metric, when it defines an equality metric for its battery collecting toy world, an equality metric that is not (explicitly represented) inside the agent's own semantic model. For me, an important research challenge is to generalise such toy-world specific safety/low-impact metrics into metrics that can apply to all toy (and non-toy) world models.
Yet I do not see this generalisation step being done often, and I am still trying to find out why not. Partly I think I do not see it often because it is mathematically difficult. But I do not think that is the whole story. So that is one reason I have been asking opinions about semantic detail.
In one way, the interesting paper you mention goes in a direction that is directly counter to the one I feel is the most promising one. The paper explicitly frames its solution as a proposed modification of a specific deep Q-learning machine learning algorithm, not as an extension to the reward function that is being supplied to this machine learning algorithm. By implication, this means they add more semantic detail inside the machine learning code, while keeping it out of it out of the reward function. My preference is to extend the reward function if at all possible, because this produces solutions that will generalise better over current and future ML algorithms.
↑ comment by Vika · 2020-07-17T21:27:48.502Z · LW(p) · GW(p)
It was not my intention to imply that semantic structure is never needed - I was just saying that the pedestrian example does not indicate the need for semantic structure. I would generally like to minimize the use of semantic structure in impact measures, but I agree it's unlikely we can get away without it.
There are some kinds of semantic structure that the agent can learn without explicit human input, e.g. by observing how humans have arranged the world (as in the RLSP paper). I think it's plausible that agents can learn the semantic structure that's needed for impact measures through unsupervised learning about the world, without relying on human input. This information could be incorporated in the weights assigned to reaching different states or satisfying different utility functions by the deviation measure (e.g. states where pigeons / cats are alive).
Replies from: Koen.Holtman↑ comment by Koen.Holtman · 2020-07-19T11:39:16.493Z · LW(p) · GW(p)
Thanks for the clarification, I think our intuitions about how far you could take these techniques may be more similar than was apparent from the earlier comments.
You bring up the distinction between semantic structure that is learned via unsupervised learning, and semantic structure that comes from 'explicit human input'. We may be using the term 'semantic structure' in somewhat different ways when it comes to the question of how much semantic structure you are actually creating in certain setups.
If you set up things to create an impact metric via unsupervised learning, you still need to encode some kind of impact metric on the world state by hand, to go into the agents's reward function, e.g. you may encode 'bad impact' as the observable signal 'the owner of the agent presses the do-not-like feedback button'. For me, that setup uses a form of indirection to create an impact metric that is incredibly rich in semantic structure. It is incredibly rich because it indirectly incorporates the impact-related semantic structure knowledge that is in the owner's brain. You might say instead that the metric does not have a rich of semantic structure at all, because it is just a bit from a button press. For me, an impact metric that is defined as 'not too different from the world state that already exists' would also encode a huge amount of semantic structure, in case the world we are talking about is not a toy world but the real world.
comment by Stuart_Armstrong · 2020-07-07T12:02:16.107Z · LW(p) · GW(p)
I think this shows that the step-wise inaction penalty is time-inconsistent: https://www.lesswrong.com/posts/w8QBmgQwb83vDMXoz/dynamic-inconsistency-of-the-stepwise-inaction-baseline [LW · GW]
comment by [deleted] · 2020-07-09T09:52:49.372Z · LW(p) · GW(p)
I like the insight that offsetting is not always bad and the idea of dealing with the bad cases using the task reward. State-based reward functions that capture whether or not the task is currently done also intuitively seem like the correct way of specifying rewards in cases where achieving the task does not end the episode.
I am a bit confused about the section on the markov property: I was imagining that the reason you want the property is to make applying standard RL techniques more straightforward (or to avoid making already existing partial observability more complicated). However if I understand correctly, the second modification has the (expectation of the) penalty as a function of the complete agent policy and I don't really see, how that would help. Is there another reason to want the markov property, or am I missing some way in which the modification would simplify applying RL methods?
Replies from: Vika↑ comment by Vika · 2020-07-09T13:53:17.548Z · LW(p) · GW(p)
Thanks Flo for pointing this out. I agree with your reasoning for why we want the Markov property. For the second modification, we can sample a rollout from the agent policy rather than computing a penalty over all possible rollouts. For example, we could randomly choose an integer N, roll out the agent policy and the inaction policy for N steps, and then compare the resulting states. This does require a complete environment model (which does make it more complicated to apply standard RL), while inaction rollouts only require a partial environment model (predicting the outcome of the noop action in each state). If you don't have a complete environment model, then you can still use the first modification (sampling a baseline state from the inaction rollout).
comment by adamShimi · 2020-07-06T22:22:51.149Z · LW(p) · GW(p)
Thanks for the post!
One thing I wonder: shouldn't an impact measure give a value to the baseline? What I mean is that in the most extreme examples, the tradeoff you show arise because sometimes the baseline is "what should happen" and some other time the baseline is "what should not happen" (like killing a pedestrian). In cases where the baseline sucks, one should act differently; and in cases where the baseline is great, changing it should come with penalty.
I assume that there's an issue with this picture. Do you know what it is?
Replies from: Vika, TurnTrout↑ comment by Vika · 2020-07-07T09:55:52.244Z · LW(p) · GW(p)
The baseline is not intended to indicate what should happen, but rather what happens by default. The role of the baseline is to filter out effects that were not caused by the agent, to avoid penalizing the agent for them (which would produce interference incentives). Explicitly specifying what should happen usually requires environment-specific human input, and impact measures generally try to avoid this.
Replies from: adamShimi↑ comment by adamShimi · 2020-07-08T17:17:31.552Z · LW(p) · GW(p)
I understood that the baseline that you presented was a description of what happens by default, but I wondered if there was a way to differentiate between different judgements on what happens by default. Intuitively, killing someone by not doing something feels different from not killing someone by not doing something.
So my question was a check to see if impact measures considered such judgements (which apparently they don't) and if they didn't, what was the problem.
Replies from: Vika↑ comment by Vika · 2020-07-09T14:06:25.906Z · LW(p) · GW(p)
I would say that impact measures don't consider these kinds of judgments. The "doing nothing" baseline can be seen as analogous to the agent never being deployed, e.g. in the Low Impact AI paper. If the agent is never deployed, and someone dies in the meantime, then it's not the agent's responsibility and is not part of the agent's impact on the world.
I think the intuition you are describing partly arises from the choice of language: "killing someone by not doing something" vs "someone dying while you are doing nothing". The word "killing" is an active verb that carries a connotation of responsibility. If you taboo this word, does your question persist?
↑ comment by TurnTrout · 2020-07-06T23:06:17.086Z · LW(p) · GW(p)
Yeah - how do you know what should happen?
Replies from: adamShimi↑ comment by adamShimi · 2020-07-07T00:16:51.169Z · LW(p) · GW(p)
In the specific example of the car, can't you compare the impact of the two next states (the baseline and the result of braking) with the current state? Killing someone should probably be considered a bigger impact than braking (and I think it is for attainable utility).
But I guess the answer is less clear-cut for cases like the door.
Replies from: TurnTrout↑ comment by TurnTrout · 2020-07-07T10:59:38.653Z · LW(p) · GW(p)
Ah, yes, the "compare with current state" baseline. I like that one a lot, and my thoughts regularly drift back to it, but AFAICT it unfortunately leads to some pretty heavy shutdown avoidance incentives.
Since we already exist in the world, we're optimizing the world in a certain direction towards our goals. Each baseline represents a different assumption about using that information (see the original AUP paper for more along these lines).
Another idea is to train a "dumber" inaction policy and using that for the stepwise inaction baseline at each state. This would help encode "what should happen normally", and then you could think of AUP as performing policy improvement on the dumb inaction policy.
Replies from: adamShimi↑ comment by adamShimi · 2020-07-08T17:22:01.947Z · LW(p) · GW(p)
When you say "shutdown avoidance incentives", do you mean that the agent/system will actively try to avoid its own shutdown? I'm not sure why comparing with the current state would cause such a problem: the state with the least impact seems like the one where the agent let itself be shutdown, or it would go against the will of another agent. That's how I understand it, but I'm very interested in knowing where I'm going wrong.
Replies from: TurnTrout