CTWTB: Paths of Computation State
post by johnswentworth · 2020-09-08T20:44:08.951Z · LW · GW · 1 commentsContents
As A Category Generalization: Symmetric Monoidal Categories None 1 comment
This is the second post of Category Theory Without The Baggage; first post here [LW · GW]. You can probably follow most of this post without reading the first one. Be warned that I am a novice when it comes to category theory; please leave a comment if you see a substantive error or oversight.
Suppose we want to evaluate at the point x = 2, y = 5. We have a choice about the order in which to perform the operations. One possibility:
- Add x+y
- Add x+3
- Multiply x*(x+3)
- Divide
Another possibility:
- Add x+3
- Add x+y
- Multiply x*(x+3)
- Divide
This hopefully seems trivial in such a simple example, but we want to be able to easily talk about this sort of thing in more complicated problems. To that end, we’re going to visualize these possible computation-orders in terms of graphs.
We’ll start with a graph representing the expression itself - i.e. the usual visual for a circuit:
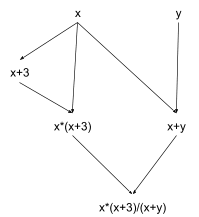
We can represent “computation state” as a cut through this DAG. For instance, we start out in this state:
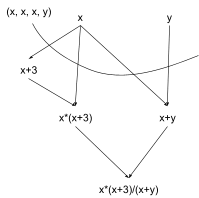
The state (x, x, x, y) gives the data carried by each edge we cut through. If we imagine that the computation at each node is performed by a different person, then at the very beginning of the computation, these would be the messages sent from our first two people (i.e. the people with our input values x = 2 and y = 5) to the people downstream. Alternatively, if a single CPU were performing this computation, it would probably save some memory by only storing x once rather than keeping three separate copies; more on that later.
From there, we have two possible next steps:
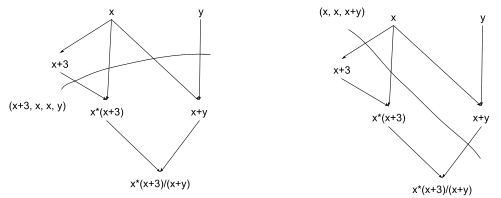
On the left, we compute x+3 first, so our state updates to (x+3, x, x, y). On the right, we compute x+y first, so our state updates to (x, x, x+y).
After performing either of these operations, we can perform the other, leaving us in the state (x+3, x, x+y). We can visualize this as two computation-paths in a computation-graph:
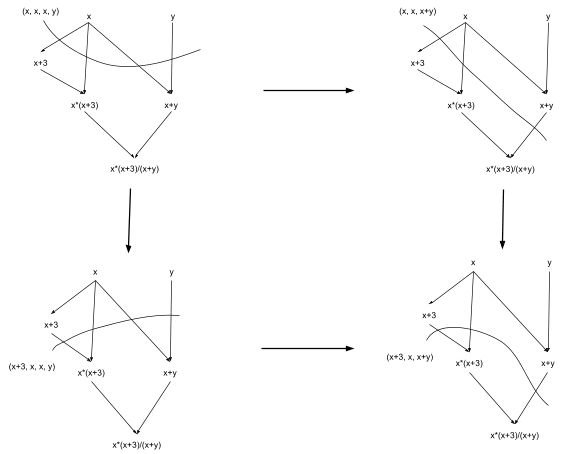
Or, dropping all the visuals of the circuit-cuts:

The two paths from (x, x, x, y) to (x+3, x, x+y) correspond to the two possible orders of the addition operation: x+3 followed by x+y, or x+y followed by x+3.
Here’s the full graph of computation states, with the multiplication and division operations added in.

Any allowed order of the operations in our original circuit corresponds to a path from the upper-left to lower-right in this computation-state graph. If that makes sense, then you’ve probably understood the basic idea. (If it’s still a bit murky, try drawing the graph-cuts corresponding to the three states at the bottom of the diagram above, then walk through an evaluation of the circuit and consider which cut represents the state at each step.)
As A Category
Recall from the previous post [LW · GW] that a category is a graph with some notion of equivalence between paths. If we have a graph in which the paths represent something interesting - e.g. our computation-state graph - then we can generate potentially-interesting categories by thinking about notions of “equivalence” between the paths.
One example: imagine that each node of our computation is handled by a different person, and the arrows in the circuit correspond to messages passed between people. If we have a limited number of messengers, then we might want to limit the maximum number of messages passed simultaneously - i.e. if we only have 4 messengers, then we’d want to pick a computation-path which never cuts through four arrows simultaneously. (Equivalently: we want a computation-path which never has more than 4 variables in its state.) When searching for such a computation-path, it might be useful to consider two paths “equivalent” if they start and end at the same node and have the same maximum number of messages.
With one small adjustment, we can make this example into something more realistically useful for e.g. writing a compiler. Rather than counting all arrows cut, we count the number of “distinct” arrows cut - i.e. the number of messages with different contents. Then (x, x, x, y) would only count as two, and (x+3, x, x, y) would count as three. When performing the computation on a CPU, this would be the number of memory cells we need to use simultaneously - so we’d consider two computation-paths equivalent if they use the same maximum number of memory cells.
Of course, there are many other possibilities. There’s the trivial possibility: any two paths with the same start and end state are equivalent (i.e. we just need to find some computation-path, and don’t care which). Or the edges in the computation-graph could have some kind of costs associated with them, in which case we’d call two paths equivalent if they have the same cost - potentially quite nontrivial if e.g. it’s expensive to perform two multiplications back-to-back on a deeply pipelined processor, but cheaper if they’re not performed back-to-back.
Now imagine that we’re writing a compiler, and it needs to compile code where the computation-state graph lives in a space with thousands of dimensions and has exponentially many nodes, but most paths are equivalent to large numbers of other paths. I can see where it might be useful to have some mathematical constructions which can compress some of those equivalent paths - thus, category theory.
Generalization: Symmetric Monoidal Categories
The computation-state graph associated with a circuit is the prototypical example of a “symmetric monoidal category”. That’s an absolutely awful name, and I’m not going to explain where it comes from. But I will give one more example, which should be sufficient to illustrate the concept.
Suppose we’re cooking rice and beans. We add water to the beans and cook them. We also add water to the rice and cook that. Finally, we combine the rice and beans. Visually:
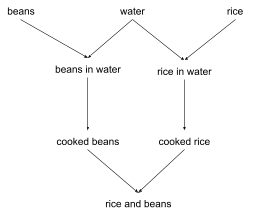
As before, we can use cuts in this graph to identify the state at any time. For instance:
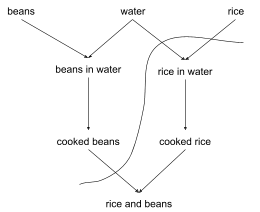
This cut represents a state where the beans are done cooking, but we have not yet started the rice at all.
As before, we can create a state graph which shows possible paths between states:
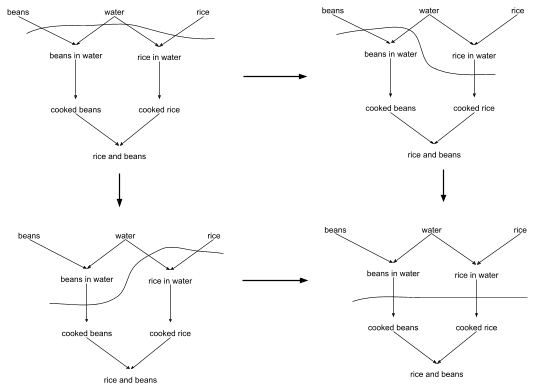
In this case, the path through the lower left involves starting the beans first, while the path through the upper right involves starting the rice first. Both end up in the lower right state, in which both the beans and the rice are cooking.
Thinking about this state graph as a category, many of the same notions of equivalence from computation-states carry over nicely. For instance, the maximum number of arrows cut by a cooking-path might correspond to the number of items which need to be on the countertop simultaneously; as before, it’s a measure of “how much workspace” is needed by a path. We could imagine expanding this to a large-scale model of economic production in some domain, with thousands of dimensions and exponentially many possible paths. As before, it would be useful to have standard tools to compress “equivalent” paths through the state graph.
1 comments
Comments sorted by top scores.
comment by JenniferRM · 2021-07-23T19:37:02.088Z · LW(p) · GW(p)
I'm surprised there were not more responses to this.
We could imagine expanding this to a large-scale model of economic production in some domain, with thousands of dimensions and exponentially many possible paths. As before, it would be useful to have standard tools to compress “equivalent” paths through the state graph.
I laughed out loud when I read this. That's some chutzpah and a half. But also like... is someone working on this?
I wondered if there was a standard tool for generating category-theoretic data stores and queries and it seems like maybe "Easik" is a tool aiming towards this, which might make Robert Rosebrugh the guy?