Category Theory Without The Baggage
post by johnswentworth · 2020-02-03T20:03:13.586Z · LW · GW · 51 commentsContents
Paths in Graphs What’s a category? Pattern Matching and Functors Natural Transformations Meta None 51 comments
If you are an algebraic abstractologist, this post is probably not for you. Further meta-commentary can be found in the “meta” section, at the bottom of the post.
So you’ve heard of this thing called “category theory”. Maybe you’ve met some smart people who say that’s it’s really useful and powerful for… something. Maybe you’ve even cracked open a book or watched some lectures, only to find that the entire subject seems to have been generated by training GPT-2 on a mix of algebraic optometry and output from theproofistrivial.com.
What is this subject? What could one do with it, other than write opaque math papers?
This introduction is for you.
This post will cover just the bare-bones foundational pieces: categories, functors, and natural transformations. I will mostly eschew the typical presentation; my goal is just to convey intuition for what these things mean. Depending on interest, I may post a few more pieces in this vein, covering e.g. limits, adjunction, Yoneda lemma, symmetric monoidal categories, types and programming, etc - leave a comment if you want to see more.
Outline:
- Category theory is the study of paths in graphs, so I’ll briefly talk about that and highlight some relevant aspects.
- What’s a category? A category is just a graph with some notion of equivalence of paths; we’ll see a few examples.
- Pattern matching: find a sub-category with a particular shape. Matches are called “functors”.
- One sub-category modelling another: commutative squares and natural transformations.
Paths in Graphs
Here’s a graph:
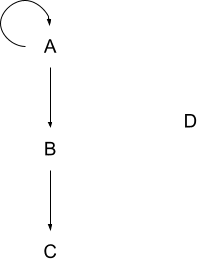
Here are some paths in that graph:
- A -> B
- B -> C
- A -> B -> C
- A -> A
- A -> A -> A (twice around the loop)
- A -> A -> A -> B (twice around the loop, then to B)
- (trivial path - start at D and don’t go anywhere)
- (trivial path - start at A and don’t go anywhere)
In category theory, we usually care more about the edges and paths than the vertices themselves, so let’s give our edges their own names:
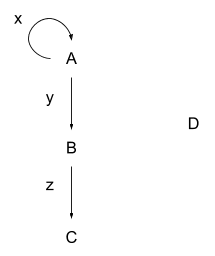
We can then write paths like this:
- A -> B is written y
- B -> C is written z
- A -> B -> C is written yz
- A -> A is written x
- A -> A -> A is written xx
- A -> A -> A -> B is written xxy
- The trivial path at D is written id_D (this is roughly a standard notation)
- The trivial path at A is written id_A
We can build longer paths by “composing” shorter paths. For instance, we can compose y (aka A -> B) with z (aka B -> C) to form yz (aka A -> B -> C), or we can compose x with itself to form xx, or we can compose xx with yz to form xxyz. We can compose two paths if-and-only-if the second path starts where the first one ends - we can’t compose x with z because we’d have to magically jump from A to B in the middle.
Composition is asymmetric - composing y with z is fine, but we can’t compose z with y.
Notice that composing id_A with x is just the same as x by itself: if we start at A, don’t go anywhere, and then follow x, then that’s the same as just following x. Similarly, composing x with id_A is just the same as x. Symbolically: id_A x = x id_A = x. Mathematically, id_A is an “identity” - an operation which does nothing; thus the “id” notation.
In applications, graphs almost always have data on them - attached to the vertices, the edges, or both. In category theory in particular, data is usually on the edges. When composing those edges to make paths, we also compose the data.
A simple example: imagine a graph of roads between cities. Each road has a distance. When composing multiple roads into paths, we add together the distances to find the total distance.
Finally, in our original graph, let’s throw in an extra edge from A to itself:
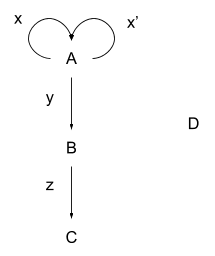
Our graph has become a “multigraph” - a graph with (potentially) more than one distinct edge between each vertex. Now we can’t just write a path as A -> A -> A anymore - that could refer to xx, xx’, x’x, or x’x’. In category theory, we’ll usually be dealing with multigraphs, so we need to write paths as a sequence of edges rather than the vertices-with-arrows notation. For instance, in our roads-and-cities example, there may be multiple roads between any two cities, so a path needs to specify which roads are taken.
Category theorists call paths and their associated data “morphisms”. This a terrible name, and we mostly won’t use it. Vertices are called “objects”, which is a less terrible name I might occasionally slip into.
What’s a category?
A category is:
- a directed multigraph
- with some notion of equivalence between paths.
For instance, we could imagine a directed multigraph of flights between airports, with a cost for each flight. A path is then a sequence of flights from one airport to another. As a notion of equivalence, we could declare that two paths are equivalent if they have the same start and end points, and the same total cost.
There is one important rule: our notion of path-equivalence must respect composition. If path p is equivalent to q (which I’ll write ), and , then we must have . In our airports example, this would say: if two flight-paths p and q have the same cost (call it ), and two flight-paths x and y have the same cost (call it ), then the cost of px (i.e. ) must equal the cost of qy (also ).
Besides that, there’s a handful of boilerplate rules:
- Any path is equivalent to itself (reflexivity), and if and then (transitivity); these are the usual rules which define equivalence relations.
- Any paths with different start and end points must not be equivalent; otherwise expressions like “” might not even be defined.
Let’s look at a few more examples. I’ll try to show some qualitatively different categories, to give some idea of the range available.
Airports & Flights
Our airport example is already a fairly general category, but we could easily add more bells and whistles to it. Rather than having a vertex for each airport, we could have a vertex for each airport at each time. Flights then connect an airport at one time to another airport at another time, and we need some zero-cost “wait” edges to move from an airport at one time to the same airport at a later time. A path would be some combination of flights and waiting. We might expect that the category has some symmetries - e.g. “same flights on different days” - and later we’ll see some tools to formalize those.
Divisibility
As a completely different example, consider the category of divisibility of positive integers:
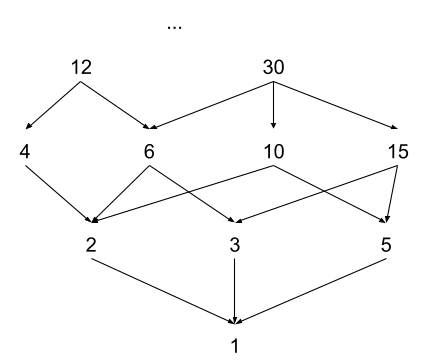
This category has a path from n to m if-and-only-if n is divisible by m (written m | n, pronounced “m divides n”, i.e. 2 | 12 is read “two divides twelve”). The “data” on the edges is just the divisibility relations - i.e. 6 | 12 or 5 | 15:
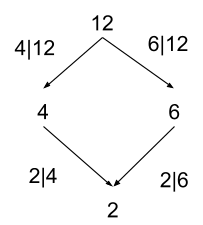
We can compose these: 2|6 and 6|12 implies 2|12. A path 12 -> 6 -> 2 in this category is, in some sense, a proof that 12 is divisible by 2 (given all the divisibility relations on the edges). Note that any two paths from 12 to 2 produce the same result - i.e. 12 -> 4 -> 2 also gives 2|12. More generally: in this category, any two paths between the same start and end points are equivalent.
Types & Functions
Yet another totally different direction: consider the category of types in some programming language, with functions between those types as edges:
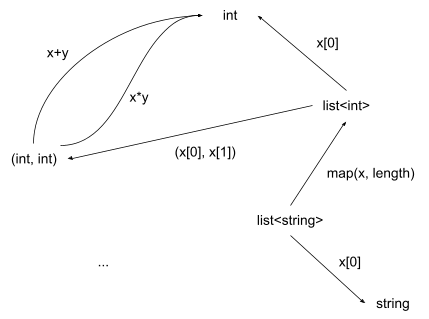
This category has a LOT of stuff in it. There’s a function for addition of two integers, which goes from (int, int) to int. There’s another function for multiplication of two integers, also from (int, int) to int. There are functions operating on lists, strings, and hash tables. There are functions which haven’t been written in the entire history of programming, with input and output types which also haven’t been written.
We know how to compose functions - just call one on the result of the other. We also know when two functions are “equivalent” - they always give the same output when given the same input. So we have a category, using our usual notions of composition and equivalence of functions. This category is the main focus of many CS applications of category theory (e.g. types in Haskell). Mathematicians instead focus on the closely-related category of functions between sets; this is exactly the same except that functions go from one set to another instead of one type to another.
Commutative Diagrams
A lot of mathy fields use diagrams like this:
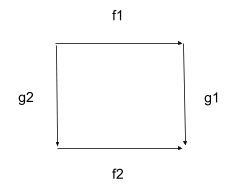
For instance, we can scale an image down () then rotate it () or rotate the image () then scale it (), and get the same result either way. The idea that we get the same result either way is summarized by the phrase “the diagram commutes”; thus the name “commutative diagram”. In terms of paths: we have path-equivalence .
Another way this often shows up: we have some problem which we could solve directly. But it’s easier to transform it into some other form (e.g. change coordinates or change variables), solve in that form, then transform back:
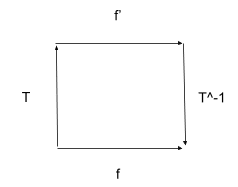
Again, we say “the diagram commutes”. Now our path-equivalence says .
Talking about commutative diagrams is arguably the central purpose of category theory; our main tool for that will be “natural transformations”, which we’ll introduce shortly.
Pattern Matching and Functors
Think about how we use regexes. We write some pattern then try to match it against some string - e.g. “colou*r” matches “color” or “colour” but not “pink”. We can use that to pick out parts of a target string which match the pattern - e.g. we could find the query “color” in the target “every color of the rainbow”.
We’d like to do something similar for categories. Main idea: we want to match objects (a.k.a vertices) in the query category to objects in the target category, and paths in the query category to paths in the target category, in a way that keeps the structure intact.
For example, consider a commutative square:
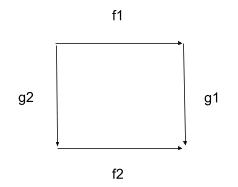
We’d like to use that as a query on some other category, e.g. our airport category. When we query for a commutative square in our airport category, we’re looking for two paths with the same start and end airports, (potentially) different intermediate airports, but the same overall cost. For instance, maybe Delta has flights from New York to Los Angeles via their hub in Atlanta, and Southwest has flights from New York to Los Angeles via their hub in Vegas, and market competition makes the prices of the two flight-paths equal.
We’ll come back to the commutative square query in the next section. For now, let’s look at some simpler queries, to get a feel for the building blocks of our pattern-matcher. Remember: objects to objects, paths to paths, keep the structure intact.
First, we could use a single-object category with no edges as a query:

This can match against any one object (a.k.a vertex) in the target category. Note that there is a path hiding in the query - the identity path, where we start at the object and just stay there. In general, our pattern-matcher will always match identity paths in the query with identity paths on the corresponding objects in the target category - that’s one part of “keeping the structure intact”.
Next-most complicated is the query with two objects:

This one is slightly subtle - it might match two different objects, or both query objects might match against the same target object. This is just the way pattern-matching works in category theory; there’s no rule to prevent multiple vertices/edges in the query from collapsing into a single vertex/edge in the target category. This is actually useful quite often - for instance, if we have some function which takes in two objects from the target category, then it’s perfectly reasonable to pass in the same object twice. Maybe we have a path-finding algorithm which takes in two airports; it’s perfectly reasonable to expect that algorithm to work even if we pass the same airport twice - that’s a very easy path-finding problem, after all!
Next up, we add in an edge:

Now that we have a nontrivial path, it’s time to highlight a key point: we map paths to paths, not edges to edges. So if our target category contains something like A -> B -> C, then our one-edge query might match against the A -> B edge, or it might match against the B -> C edge, or it might match the whole path A -> C (via B) - even if there’s no direct edge from A to C. Again, this is useful quite often - if we’re searching for flights from New York to Los Angeles, it’s perfectly fine to show results with a stop or two in the middle. So our one-edge query doesn’t just match each edge; it matches each path between any two objects (including the identity path from an object to itself).
Adding more objects and edges generalizes in the obvious way:
This finds any two paths which start at the same object. As usual, one or both paths could be the identity path, and both paths could be the same.
The other main building block is equivalence between paths. Let’s consider a query with two edges between two objects, with the two edges declared to be equivalent:

You might expect that this finds any two equivalent paths. That's technically true, but somewhat misleading. As far as category theory is concerned, there's actually only one path here - we only care about paths up to equivalence (thankyou to Eigil for pointing this out in the comments). So that "one" path will be mapped to "one" path in the target category; our query could actually match any number of paths, as long as they're all equivalent. Looking back at our one-edge example from earlier, it's possible that our one edge could be mapped to a whole class of equivalent paths - by mapping it to one path, we're effectively selecting all the paths equivalent to that one.
A commutative square works more like we’d expect:

In our query, the two paths from upper-left to lower-right are equivalent, but they contain non-equivalent subpaths. So those subpaths may be mapped to non-equivalent paths in the target, as long as those non-equivalent paths compose into equivalent paths. In other words, we’re looking for a commutative square in the target, as we’d expect. (Though we can still find degenerate commutative squares, e.g. matches where the lower left and upper right corner map to the same object.)
Category theorists call each individual match a “functor”. Each different functor - i.e. each match - maps the query category into the target category in a different way.
Note that the target category is itself a category - which means we could use it as a query on some third category. In this case, we can compose matches/functors: if one match tells me how to map category 1 into category 2, and another match tells me how to map category 2 into category 3, then I can combine those to find a map from category 1 into category 3.
Because category theorists love to go meta, we can even define a graph in which the objects are categories and the edges are functors. A path then composes functors, and we say that two paths are equivalent if they result in the same map from the original query category into the final target category. This is called “Cat”, the category of categories and functors. Yay meta.
Meanwhile, back on Earth (or at least low Earth orbit), commutative diagrams.
Exercise: Hopefully you now have an intuitive idea of how our pattern-matcher works, and what information each match (i.e. each functor) contains. Use your intuition to come up with a formal definition of a functor. Then, compare your definition to wikipedia’s definition (jargon note: "morphism" = set of equivalent paths); is your definition equivalent? If not, what’s missing/extraneous in yours, and when would it matter?
Natural Transformations
Let’s start with a microscopic model of a pot of water. We have some “state”, representing the positions and momenta of every molecule in the water (or quantum field state, if you want to go even lower-level). There are things we can do to the water - boil it, cool it back down, add salt, stir it, wait a few seconds, etc - and each of these things will transform the water from one state to another. We can represent this as a category: the objects are states, the edges are operations moving the water from one state to another (including just letting time pass), and paths represent sequences of operations.
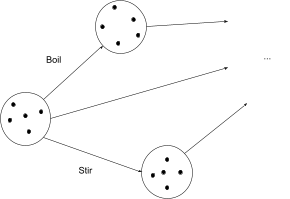
In physics, we usually don’t care how a physical system arrived in a particular state - the state tells us everything we need to know. That would mean that any path between the same start and end states are equivalent in this category (just like in the divisibility category). To make the example a bit more general, let’s assume that we do care about different ways of getting from one state to another - e.g. heating the water, then cooling it, then heating it again will definitely rack up a larger electric/gas bill than just heating it.
Microscopic models accounting for the position and momentum of every molecule are rather difficult to work with, computationally. We might instead prefer a higher-level macroscopic model, e.g. a fluid model where we just track average velocity, temperature, and chemical composition of the fluid in little cells of space and time. We can still model all of our operations - boiling, stirring, etc - but they’ll take a different form. Rather than forces on molecules, now we’re thinking about macroscopic heat flow and total force on each little cell of space at each time.
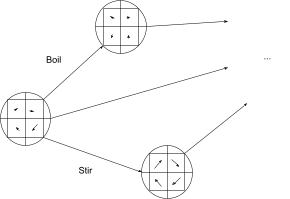
We can connect these two categories: given a microscopic state we can compute the corresponding macroscopic state. By explicitly including these microscopic -> macroscopic transformations as edges, we can incorporate both systems into one category:
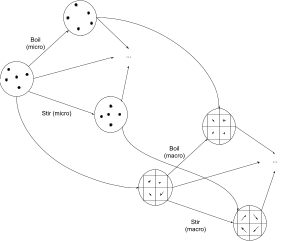
Note that multiple micro-states will map to the same macro-state, although I haven’t drawn any.
The key property in this two-part category is path equivalence (a.k.a. commutation). If we start at the leftmost microscopic state, stir (in micro), then transform to the macro representation, then that should be exactly the same as starting at the leftmost microscopic state, transforming to the macro representation, and then stirring (in macro). It should not matter whether we perform some operations in the macro or micro model; the two should “give the same answer”. We represent that idea by saying that two paths are equivalent: one path which transforms micro to macro and then stirs (in macro), and another path which stirs (in micro) and then transforms micro to macro. We have a commutative square.
In fact, we have a bunch of commutative squares. We can pick any path in the micro-model, find the corresponding path in the macro-model, add in the micro->macro transformations, and end up with a commutative square.
Main take-away: prism-shaped categories with commutative squares on their side-faces capture the idea of representing the same system and operations in two different ways, possibly with one representation less granular than the other. We’ll call these kinds of structures “natural transformations”.
Next step: we’d like to use our pattern-matcher to look for natural transformations.
We’ll start with some arbitrary category:

Then we’ll make a copy of it, and add edges from objects in the original to corresponding objects in the copy:
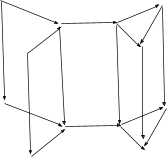
I’ll call the original category “system”, and the copy “model”.
To finish our pattern, we’ll declare path equivalences: if we follow an edge from system to model, then take any path within the model, that’s equivalent to taking the corresponding path within the system, and then following an edge from system to model. We declare those paths equivalent (as well as any equivalences in the original category, and any other equivalences implied, e.g. paths in which our equivalent paths appear as sub-paths).
Now we just take our pattern and plug it into our pattern-matcher, as usual. Our pattern matcher will go looking for a system-model pair, all embedded within whatever target category we're searching within. Each match is called a natural transformation; we say that the natural transformation maps the system-part to the match of the model-part. Since we call matches “functors”, a category theorist would say that a natural transformation maps one functor (the match of the system-part) to another of the same shape (the match of the model-part).
Now for an important point: remember that, in our pot-of-water example, multiple microscopic states could map to the same macroscopic state. Multiple objects in the source are collapsed into a single object in the target. But our procedure for creating a natural transformation pattern just copies the whole source category directly, without any collapsing. Is our pot-of-water example not a true natural transformation?
It is. Last section I said that it’s sometimes useful for our pattern-matcher to collapse multiple objects into one; the pot-of-water is an example where that matters. Our pattern-matcher may be looking for a copy of the micro model, but it will still match against the macro model, because it’s allowed to collapse multiple objects together into one.
More generally: because our pattern-matcher is allowed to collapse objects together, it’s able to find natural transformations in which the model is less granular than the system.
Meta
That concludes the actual content; now I'll just talk a bit about why I'm writing this.
I've bounced off of category theory a couple times before. But smart people kept saying that it's really powerful, in ways that sound related to my research [? · GW], so I've been taking another pass at the subject over the last few weeks.
Even the best book I've found on the material seems burdened mainly by poor formulations of the core concepts and very limited examples. My current impression is that broader adoption of category theory is limited in large part by bad definitions, even when more intuitive equivalent definitions are available - "morphisms" vs "paths" is a particularly blatant example, leading to an entirely unnecessary profusion of identities in definitions. Also, of course, category theorists are constantly trying to go more abstract in ways that make the presentation more confusing without really adding anything in terms of explanation. So I've needed to come up with my own concrete examples and look for more intuitive definitions. This write-up is a natural by-product of that process.
I'd especially appreciate feedback on:
- whether I'm missing key concepts or made crucial mistakes.
- whether this was useful; I may drop some more posts along these lines if many people like it.
- whether there's some wonderful category theory resource which has already done something like this, so I can just read that instead. I would really, really prefer to do this the easy way.
51 comments
Comments sorted by top scores.
comment by Eigil Rischel (eigil-rischel) · 2020-02-03T22:05:10.767Z · LW(p) · GW(p)
As an algebraic abstractologist, let me just say this is an absolutely great post. My comments:
Category theorists don't distinguish between a category with two objects and an edge between them, and a category with two objects and two identified edges between them (the latter object doesn't really even make sense in the usual account). In general, the extra equivalence relation that you have to carry around makes certain things more complicated in this version.
I do tend to agree with you that thinking of categories as objects, edges and an equivalence relation on paths is a more intuitive perspective, but let me defend the traditional presentation. By far the most essential/prototypical examples are the categories of sets and functions, or types and functions. Here, it's more natural to speak of functions from x to y, than to speak of "composable sequences of functions beginning at x and ending at y, up to the equivalence relation which identifies two sequences if they have the same composite".
Again, I absolutely love this post. I am frankly a bit shocked that nobody seems to have written an introduction using this language - I think everyone is too enamored with sets as an example.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-02-03T22:59:52.642Z · LW(p) · GW(p)
Thanks for pointing out the identified edges thing, I hadn't noticed it before. I'll update the examples once I've updated my intuition.
Also I'm glad you like it! :)
UPDATE: fixed it.
Replies from: ESRogs↑ comment by ESRogs · 2020-02-05T04:05:56.092Z · LW(p) · GW(p)
Relatedly, I'm going back and forth in my head a bit about whether it's better to explain category theory in graph theory terms by identifying the morphisms with edges or with paths.
Morphisms = Edges
- In this version, a subset of multidigraphs (apparently also called quivers!), can be thought of as categories -- those for which every vertex has an edge to itself, and for which whenever there's a path from A to B, there's also an edge directly from A to B.
- You also have to say:
- for each pair of edges from A to B and B to C, which edge from A to C corresponds to their composition
- for each node, which (of possibly multiple) edge to itself is its default or identity edge
- in such a way that the associative and unital laws hold
Morphisms = Paths
- In this version, any multidigraph (quiver) can be thought of as a category.
- You get the identities for free, because they're just the trivial, do-nothing, paths.
- You get composition for free, because we already know what it means that following a path from A to M and then from M to Z is itself a path.
- And you get the associative and unital laws for (almost) free:
- unital: doing nothing at the start or end of a path obviously doesn't change the path
- associative: it's natural to think of the paths ((e1, e2), e3) and (e1, (e2, e3)) -- where e1, e2, and e3 are edges -- as both being the same path [e1, e2, e3]
- However, you now have to add on one weird extra rule that two paths that start and end at the same place can be considered the same path, even if they didn't go through the same intermediate nodes.
- In other words, the intuition that composing-pairs-of-paths-in-different-orders-always-gives-you-the-same-final-path gives you a sufficient, but not necessary condition for two paths being considered equivalent.
I think this final point in the morphisms = paths formulation might be what tripped you up in the case Eigil points out above, where category theory treats two arrows from A to B that are equivalent to each other as actually the same arrow. This seems to be the one place (from what I can see so far) where the paths formulation gives the wrong intuition.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-02-05T18:37:51.115Z · LW(p) · GW(p)
The main reason I like the paths formulation is that I can look around at the real world and immediately pick out systems which might make sense to model as categories. "Paths in graphs" is something I can recognize at a glance. Thinking about links on the internet? The morphisms are paths of links. Friend connections on facebook? The morphisms are friend-of-friend paths. Plane flights? The morphisms are travel plans. Etc.
I expect that the big applications of category theory will eventually come from something besides sets and functions, and I want to be able to recognize such applications at a glance when opportunity comes knocking.
The cost is needing to build some intuition for path equivalence. I'm still building that intuition, and that is indeed what tripped me up. It will come with practice.
comment by Shmi (shminux) · 2020-02-04T09:49:27.327Z · LW(p) · GW(p)
It seems like this post was appreciated mostly by those who already understand enough of abstract math to make sense of it, less so by the uninitiated. I've only ever had an intuitive understanding of CT, and my relevant math level is probably just around the first course in algebraic topology, which is still somewhat higher than the LW average, yet I still struggle to keep my interest reading through your post.
For comparison, I wrote a very informal comment on how embedded agent's modeling abstraction levels can map into CT concepts [LW(p) · GW(p)]. Which didn't get much traction. But maybe starting with the examples already familiar and relevant to the audience could be something to try when introducing CT to the LW masses.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-02-04T18:17:40.391Z · LW(p) · GW(p)
Ooh that's a good comment you linked. You mention relating various applications of the poisson equation via natural transformation; could you unpack a bit what that would look like? One of the things I've had trouble with is how to represent the sorts of real-world abstractions I want to think about (e.g. poisson equation) in the language of category theory; it's still unclear to me whether morphism relationships are enough to represent all the semantics. If you know how to do it with that example, it would be really helpful.
Replies from: shminux↑ comment by Shmi (shminux) · 2020-02-08T07:58:25.315Z · LW(p) · GW(p)
Trying to write it up better, we'll see if this will work.
comment by adamShimi · 2020-02-05T21:21:11.239Z · LW(p) · GW(p)
Separate comment for references to classical category theory books and resources. I don't think any of these are exactly what you are looking for, but they each propose a different perspective on these concepts, which might be the best we have now.
- The best textbook I know of is Category Theory by Awodey. It is both rigorous and intuitive, at least at the level of maths textbook. There are a lot of examples, as concrete as possible, and the differences between them and how that inform the abstract definitions are treated in details.
- Do not go to Maclane's Category Theory for Working Mathematician. Not that it is a bad book, just that it is the most honest title of a book I ever saw. Maclane writes for the working mathematician, so not even the graduate student in maths fits exactly his standards.
- For a glimpse of the structuring power of category theory and its links to physics and computer science, Physics, Topology, Logic and Computation: A Rosetta Stone by Baez and Stay is the place to go. This paper also argues eloquently that the most important categories are not the one similar to the category of sets.
- A short one that I like is Basic Category Theory for Computer Scientists by Pierce. It is short, to the point, and goes deeper into the applications to theoretical computer science. One caveat is that Pierce is the kind of computer scientist that studies proof theory and teaches Coq and theorem proving. So it might be slightly too abstract for some people.
↑ comment by Garrett Baker (D0TheMath) · 2022-05-25T15:38:53.599Z · LW(p) · GW(p)
Dis-recommending Awodey's book. I tried reading it as an introduction, and it was tremendously confusing. I'm going through Harold Simmons' An Introduction to Category Theory now, and from a beginner's standpoint, it's far superior.
Edit: Coming back to this years later & with more math under my belt, I now see why Awodey's is so well recommended. I now say you should check it out first, see if you can understand it, and if so great! If not, go to Simmons' book.
Replies from: adamShimi↑ comment by adamShimi · 2022-05-26T14:48:47.396Z · LW(p) · GW(p)
Thanks for the feedback!
I didn't know of Simmons book, will take a look. To be honest, I never went very far in Awodey, but it still worked better for me than McLane (not hard, I know).
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2022-05-26T21:21:02.978Z · LW(p) · GW(p)
Cool. Let me know if you have opinions on it.
↑ comment by adamShimi · 2020-02-10T13:05:37.181Z · LW(p) · GW(p)
I just found another interesting reference: Categories for the practising physicist. Although this is not exactly about discarding undue abstraction, it does present many concepts in terms of concrete examples, and there are even real-world categories defined in it!
comment by adamShimi · 2020-02-05T11:48:42.133Z · LW(p) · GW(p)
Caveat: I'm a bit of an algebraic abstractologist with a not-that-deep understanding of category theory. Thus I might represent the worst of both worlds, someone defending the abstract for the abstract without concrete arguments.
My first reaction when seeing this post is that it was a great idea to give an intuitive explanation of category theory. My second reaction, when reading the introduction and the "Path in Graphs" section, was to feel like every useful part of category theory had been thrown away. After reading the whole post, I feel there are great parts (notably the extended concrete example for functors), and others with which I disagree. I will try to clarify my disagreement.
- First, category theory is not about graphs. Categories are not graphs. There not even graphs with a tiny bit of structure on top. Categories are abstractions of mathematicals structures, which can be represented as graph. One can even argue that applications of category theory are simply about structuring the underlying objects and relations in such a way that what we want to prove is shown by a basic diagram. An intuition for this is that you can do category theory without using the graphs.
- There are very good reason to use sets and the category of sets as primarily examples. The most obvious one is that category theory aims to provide a fondation of mathemathics in place of set theory. Thus starting with sets, which any student of modern mathematics know, is being nice to the mathematical reader. Also, pretty much any book on category theory uses the category of sets as a foil, to show that categorical notions should not be given an intuition based only on set theory and functions on sets, as this intuition breaks down in other cases. For example, the fact that an isomorphism in category theory is not just a bijection as in the category of sets -- for the category of posets, isomorphisms must be order-preserving while bijections are not necessarily.
- Lastly, about the applications you seem to search for category theory. I feel like you want to use category theory as a tool to solve a problem, like you apply an inequality to derive a new theorem. But as far as I know, all uses of category theory come after the fact. It is a formal and structured perspective you can take on mathematical objects and how they relate. It might give you an understanding of the underlying structure behind your approach or results, but it rarely, if ever, gives you the means to accomplish an effective goal. Even the most concrete examples like monads in Haskell come from people already committed to find a solution within category theory, not because category theory was the best tool to solve the problem at hand.
All that being said, I still think trying to boil down the main concepts of category theory is a great idea. I'm only worried that your approach throws away too much of what makes the value of category theory.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-02-05T18:29:38.770Z · LW(p) · GW(p)
My second reaction, when reading the introduction and the "Path in Graphs" section, was to feel like every useful part of category theory had been thrown away.
I was expecting/hoping someone would say this. I'll take the opportunity to clarify my goals here.
I expect "applied category theory" is going to be a field in its own right in the not-so-distant future. When I say e.g. "broader adoption of category theory is limited in large part by bad definitions", that's what I'm talking about. I expect practical applications of category theory will mostly not resemble the set-centered usage of today, and I think that getting rid of the set-centered viewpoint is one of the main bottlenecks to moving forward.
(A good analogy here might be group-theory-as-practiced-by-mathematicians vs group-theory-as-practiced-by-physicists - a.k.a. representation theory.)
I generally agree that the usage of category theory today benefits from not thinking of things as graphs, from using set as a primary example, etc. But today, all uses of category theory come after the fact. I want that to change, I've seen enough to think that will change, and that's why I'm experimenting with a presentation which throws out most of the existing value.
Replies from: adamShimi↑ comment by adamShimi · 2020-02-05T20:24:24.724Z · LW(p) · GW(p)
I don't know if I should feel good or bad for taking the bait... let's say it make the debate progress.
From what you are saying, I think I get what you are aiming for. But I am also not sure that this issue you see is really there. Because every textbook on category theory that I read pointed in its first chapter or section that you should not use your intuition for sets in the abstract setting of category theory. Even the historical origins of category theory comes from algebraic topology, where the influence of sets and set theory is very dimmed.
That being said, maybe there is some "Cantor bias" in the modern practice of mathematics, even when the point is to replace set theory. That's actually one aspect of the Physics, Topology, Logic and Computation: A Rosetta Stone paper mentioned in my other answer that I like a lot: the authors give different categories, and argue that the category best capturing applications in Physics and Computer Science is not the category of sets, but another behaving differently.
I think I have two questions following your comment:
- First, could you expand your example of group theory in math vs group theory in physics? I know a bit a mathy group theory, and I know it is applied to various parts of physics, but I'm curious of clear cut differences between the uses.
- Second, does the already existing field of Applied Category Theory (intro paper and intro book) fits your bill for applications?
↑ comment by johnswentworth · 2020-02-05T23:58:35.245Z · LW(p) · GW(p)
I do like that Rosetta Stone paper you linked, thanks for that. And I also recently finished going through a set of applied category theory lectures based on that book you linked. That's exactly the sort of thing which informs my intuitions about where the field is headed, although it's also exactly the sort of thing which informs my intuition that some key foundational pieces are still missing. Problem is, these "applications" are mostly of the form "look we can formalize X in the language of category theory"... followed by not actually doing much with it. At this point, it's not yet clear what things will be done with it, which in turn means that it's not yet clear we're using the right formulations. (And even just looking at applied category theory as it exists today, the definitions are definitely too unwieldy, and will drive away anyone not determined to use category theory for some reason.)
I'm the wrong person to write about the differences in how mathematicians and physicists approach group theory, but I'll give a few general impressions. Mathematicians in group theory tend to think of groups abstractly, often only up to isomorphism. Physicists tend to think of groups as matrix groups; the representation of group elements as matrices is central. Physicists have famously little patience for the very abstract formulation of group theory often used in math; thus the appeal of more concrete matrix groups. Mathematicians often use group theory just as a language for various things, without even using any particular result - e.g. many things are defined as quotient groups. Again, physicists have no patience for this. Physicists' use of group theory tends to involve more concrete objectives - e.g. evaluating integrals over Lie groups. Finally, physicists almost always ascribe some physical symmetry to a group; it's not just symbols.
Replies from: adamShimi↑ comment by adamShimi · 2020-02-06T14:24:19.254Z · LW(p) · GW(p)
So your path-based approach to category theory would be analogous to the matrix-based approach of group theory in physics? That is, removing the abstraction that made us stumble into theses concepts in the first place, and keeping only what is of use for our applications?
I would like to see that. I'm not sure that your own proposition is the right one, but the idea is exciting.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-02-06T18:25:45.213Z · LW(p) · GW(p)
Yup, that's basically the idea.
comment by Polytopos · 2020-06-07T22:31:51.306Z · LW(p) · GW(p)
David Spivak offers an account of Categories as database schemas with path equivalencies that is similar to the account you've given here in his book Category Theory for the Sciences. He still presents the traditional definitions, giving examples mainly from the category of sets and functions. I also didn't find his presentation of database schema definition especially easy to understand, but it is very useful when you realize that a functor is a systematic migration of data between schemas.
comment by JenniferRM · 2021-07-23T19:29:44.605Z · LW(p) · GW(p)
I had previously written off Category Theory, but this nudges me a little bit towards thinking there might be a There there?
I like matrices, and I like graph theory, and they are very practical and useful practically everywhere for modeling work, that's part of why I like them. Suddenly I wonder if category theory could work similarly?
Reading this and the comments, it seems like the most important thing at the center of the field might be whatever the "Yoneda Lemma" is... I checked, and Wikipedia's summary agrees that this is important.
In mathematics, the Yoneda lemma is arguably the most important result in category theory.
I did not read thoroughly, but, squinting, it seems like maybe the central result here (at a "why even care?" level) is that when you throw away some assumptions (like assumptions that generate set theory?) about what would be a good enough foundation for math in general... maybe the Yoneda Lemma shows that set theory is a pretty good foundation for math?
Is this wrong?
(If the idea is right, does the reverse hold? Like.. does non-Yoneda-Set-compatible "mathesque stuff" totally broken or aberrant or Intractably Important or something? Maybe like how some non-computable numbers are impossible to know, even though they contain all of math. Or maybe, similarly to how non-Euclidean geometry contained spherical and hyperbolic geometry, maybe "non-Yonedan" reasoning contains a menagerie of various defeasible reasoning systems?)
The CTWTB sequence has been fun so far [LW · GW]! If a good explanation of Yoneda and its meanings was a third or fourth post like the ones so far, that would be neat <3
Replies from: johnswentworth↑ comment by johnswentworth · 2021-07-23T23:57:55.228Z · LW(p) · GW(p)
A good explanation of Yoneda is indeed the third planned post... assuming I eventually manage to understand it well enough to write that post.
Replies from: Mo Nastri↑ comment by Mo Putera (Mo Nastri) · 2022-03-16T02:33:27.588Z · LW(p) · GW(p)
Just wondering -- did you ever get around to writing this post? I've bounced off many Yoneda explainers before, but I have a high enough opinion of your expository ability that I'm hopeful yours might do it for me.
Replies from: johnswentworth↑ comment by johnswentworth · 2022-03-16T03:49:42.402Z · LW(p) · GW(p)
Still haven't gotten around to it.
comment by Simon Pepin Lehalleur (SPLH) · 2020-02-12T19:39:50.797Z · LW(p) · GW(p)
I am a mathematician who is using category theory all the time in my work in algebraic geometry, so I am exactly the wrong audience for this write-up!
I think that talking about "bad definitions" and "confusing presentation" is needlessly confrontational. I would rather say that the traditional presentation of category theory is perfectly adapted to its original purpose, which is to organise and to clarify complicated structures (algebraic, topological, geometric, ...) in pure mathematics. There the basic examples of categories are things like the category of groups, rings, vector spaces, topological spaces, manifolds, schemes, etc. and the notion of morphism, i.e. "structure-preserving map", is completely natural.
As category theory is applied more broadly in computer science and the theory of networks and processes, it is great that new perspectives on the basic concepts are developed, but I think they should be thought of as complementary to the traditional view, which is extremely powerful in its domain of application.
Replies from: dmitry-vaintrob, adele-lopez-1↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-11T17:13:11.300Z · LW(p) · GW(p)
FWIW, I like John's description above (and probably object much less than baseline to humorously confrontational language in research contexts :). I agree that for most math contexts, using the standard definitions with morphism sets and composition mappings is easier to prove things with, but I think the intuition described here is great and often in better agreement with how mathematicians intuit about category-theoretic constructions than the explicit formalism.
↑ comment by Adele Lopez (adele-lopez-1) · 2020-03-04T18:50:37.033Z · LW(p) · GW(p)
the traditional presentation of category theory is perfectly adapted to its original purpose
I think this is too generous. The traditional way of conceptualizing a given math subject is usually just a minor modification of the original conceptualization. There's a good reason for this, which is that updating the already known conceptualization across a community is a really hard coordination problem -- but this also means that the presentation of subjects has very little optimization pressure towards being more usable.
Replies from: dmitry-vaintrob↑ comment by Dmitry Vaintrob (dmitry-vaintrob) · 2025-01-11T17:09:49.603Z · LW(p) · GW(p)
This phenomenon exists, but is strongly context-dependent. Areas of math adjacent to abstract algebra are actually extremely good at updating conceptualizations when new and better ones arrive. This is for a combination of two related reasons: first, abstract algebra is significantly concerned about finding "conceptual local optima" of ways of presenting standard formal constructions, and these are inherently stable and require changing infrequently; second, when a new and better formalism is found, it tends to be so powerfully useful that papers that use the old formalism (in concepts where the new formalism is more natural) quickly become outdated -- this happened twice in living memory, once with the formalism of schemes replacing other points of view in algebraic geometry and once with higher category theory replacing clunkier conceptualizations of homological algebra and other homotopical methods in algebra. This is different from fields like AI or neuroscience, where oftentimes using more compute, or finding a more carefully taylored subproblem is competitive or better than "using optimal formalism". That said, niceness of conceptualizations depends on context and taste, and there do exist contexts where "more classical" or "less universal" characterizations are preferable to the "consensus conceptual optimum".
comment by cousin_it · 2020-02-05T14:55:26.735Z · LW(p) · GW(p)
In group theory, a group can be defined abstractly as a set with a binary operation obeying certain axioms, or concretely as a bunch of permutations on some set (which doesn't need to include all permutations, but must be closed under composition and inverse). The two views are equivalent by Cayley's theorem, and I think the second view is more helpful, at least for beginners.
I don't know very much about category theory, but maybe we could do something similar there? Since every small category has a faithful functor into Set, it can be defined as a bunch of sets and functions between them. It doesn't need to include all sets or functions, but must be closed under composition and include each set's identity function to itself.
For example, the divisibility category from the post can be seen as a category of sets like {1,...,n} and functions that are unital ring homomorphisms from Z/mZ to Z/nZ (of which there's exactly one if n divides m, and zero otherwise). And the category of types and functions in some programming language can be seen as a category containing some sets of things-with-bottoms [LW(p) · GW(p)] and monotone functions between them. So in both of these cases, going to sets leads to some nice math.
I've heard that the set intuition starts to break down once you study more category theory, but haven't gotten to that point yet.
comment by ESRogs · 2020-02-05T03:21:17.779Z · LW(p) · GW(p)
My current impression is that broader adoption of category theory is limited in large part by bad definitions, even when more intuitive equivalent definitions are available - "morphisms" vs "paths"
Just wanted to note that I recently learned some of the very basics of category theory and found myself asking of the presentations I came across, "Why are you introducing this as being about dots and arrows and not immediately telling me how this is the same as or different from graph theory?"
I had to go and find this answer on Math.StackExchange to explain the relationship, which was helpful.
So I think you're on the right track to emphasize paths, at least for anyone who knows about graphs.
Replies from: ESRogscomment by Gordon Seidoh Worley (gworley) · 2020-02-05T21:42:45.292Z · LW(p) · GW(p)
This is maybe only useful to me and a handful of other folks, but I think of category theory sometimes as a generalization of topology. Rather than topologies you have categories and rather than liftings you have functors (this is not a strict, mathematical generalization, but an intuitive generalization of how the picture in my head of how topology works generalizes to how category theory works, so don't come at me that this is not strictly true).
Replies from: adele-lopez-1↑ comment by Adele Lopez (adele-lopez-1) · 2020-03-04T18:55:43.032Z · LW(p) · GW(p)
This is more mathematically justified than you seem to think. Posets are topological spaces and categories, and every space is weak homotopy equivalent to a poset space, which explains why the intuition works so well.
comment by Said Achmiz (SaidAchmiz) · 2020-02-03T22:36:26.562Z · LW(p) · GW(p)
I didn’t read all the way through (I stopped reading midway through the extended airport example), so forgive me if this is answered already; if you say the answer’s in there, I’ll go back and reread. But, in case it’s not, my question is: what would I gain from using category theory for problems like this, instead of graph theory (on which there already exists a vast literature)?
Replies from: eigil-rischel, johnswentworth↑ comment by Eigil Rischel (eigil-rischel) · 2020-02-03T23:01:08.503Z · LW(p) · GW(p)
I think, rather than "category theory is about paths in graphs", it would be more reasonable to say that category theory is about paths in graphs up to equivalence, and in particular about properties of paths which depend on their relations to other paths (more than on their relationship to the vertices)*. If your problem is most usefully conceptualized as a question about paths (finding the shortest path between two vertices, or counting paths, or something in that genre, you should definitely look to the graph theory literature instead)
* I realize this is totally incomprehensible, and doesn't make the case that there are any interesting problems like this. I'm not trying to argue that category theory is useful, just clarifying that your intuition that it's not useful for problems that look like these examples is right.
↑ comment by johnswentworth · 2020-02-03T22:45:48.747Z · LW(p) · GW(p)
Great question. I don't think I answer it outright, but the section on natural transformations should at least offer some intuition for the kind of questions which category theory looks at, but which graph theory doesn't really look at. That doesn't answer the question of what you'd gain, and frankly, I have yet to see a really compelling answer to that question myself - category theory has an awful lot of definitions, but doesn't seem to actually do much with them. But I'm still pretty new to this, so I'm holding out hope.
Replies from: gworley, TheMajor↑ comment by Gordon Seidoh Worley (gworley) · 2020-02-05T21:39:05.333Z · LW(p) · GW(p)
What seems the advantage to me is that category theory lets you account for more stuff within the formalisms.
Case in point, I did my dissertation in graph theory, and what I can tell you from proving hundreds of statements about graphs is that most of the theory of how and why graphs behave certain ways exists outside what can be captured formally by the theory. This is often what frustrates people about graph theory and all of combinatorics: the proofs come generally not by piling lots of previous results but by seeing through to some fundamental truth about what is going on with the collection ("category") of graphs you are interested in and then using one of a handful of proof tricks ("functors") to transform one thing into another to get your proof.
↑ comment by TheMajor · 2020-02-04T14:27:17.001Z · LW(p) · GW(p)
Category theory provides a theoretical structure that fits many (all) fields of mathematics. Some non-trivial insights from it are that:
- The notion of 'invertible' depends on the context (specifically, it needs to let you recover the identity path, which need not be a set-theoretic identity function. I think this is what Eigil is saying above. As an example, consider measure theory where we introduce 'equal up to sets of measure 0').
- The properties of an object are encoded in the maps we allow to/from the object (as a weak example, a topology induced by a collection of maps. As a strong example: Yoneda's Lemma).
- Some properties or constructions are universal in mathematics (direct products, direct limits, inverse limits, initial objects, final objects), and studying these in a general setting provides a lot of insight in actual applications.
Also personally I've had great mileage out of noticing when my wild ideas could not be cast in category-theoretic form, which is a huge red flag and let me identify errors in my reasoning quickly and cleanly.
Replies from: johnswentworth↑ comment by johnswentworth · 2020-02-04T18:30:23.233Z · LW(p) · GW(p)
The problem is that these are all just definitions; they don't actually say anything about the things they're defining, and the extent to which real-world systems fit these definitions is not obvious.
- Ok, we can define invertibility in a way that depends on the context, but what does that actually buy us? What's a practical application where we say "oh, this is a special kind of inverse" and thereby prove something we wouldn't have proved otherwise?
- "The properties of an object are encoded in the maps we allow to/from the object" is not a fact about the world, it is a fact about what sort of things category theory talks about. One of my big open questions is whether "maps to/from the object" are actually sufficient to describe all the properties I care about in real-world systems, like a pot of water.
- Universal constructions are cute, but I have yet to see a new insight from them - i.e. a fact about a particular system which wasn't already fairly obvious. Heck, I have yet to even see a general theorem about a universal construction other than "if it exists, then it's unique up to isomorphism".
These aren't rhetorical questions, btw - I'd really appreciate meaty examples, it would make learning this stuff a lot less frustrating.
Replies from: TheMajor↑ comment by TheMajor · 2020-02-05T09:44:49.542Z · LW(p) · GW(p)
I'll give it the good old college try, but I'm no expert on category theory by any means. I've always been told that a real-world application of category theory is kind of an in-joke; you're not allowed to say they don't exist, but nobody has any. The purpose of category theory is to replace (naive) set theory as a foundation of mathematics. It's therefore not really surprising that this is far removed from describing properties of a pot of water, for example.
I think in light of this my previous bullet points weren't that horrible. If you ask something like "I'm walking down the street, suddenly I see a house on fire. How does category theory help me decide what to do next?" the answer is "it does not, not even the slightest bit". Instead it helps on a very abstract meta-level: it is there to structure the thoughts you have about fields of mathematics, which in turn will let you gain faster and deeper insight into those fields. Often (for example in algebra) even this will not translate to real-world applications, but you can then use those fields to better absorb something to make predictions about the real world. As an example I'm thinking of Category theory helping you learn Group theory which helps you learn Renormalization theory which gains you real-world insight into complicated many-particle systems, like a gas out of thermodynamic equilibrium. If you are looking for anything more direct than this I flat out don't have an answer for you.
Finally a bit about the bullet points:
- The study of non-invertible linear operators on infinite dimensional vector spaces led to notions of spectrum, and later the Gelfand-Naimark representation and study of Fredholm operators, which are some of the core deep ideas behind mathematical formulations of quantum mechanics (amongst other fields). Also the difference between [a linear map failing to be an isomorphism because it is not bijective] (related to the so-called Point spectrum) and [a linear, bijective map that is still not an isomorphism because its inverse map is not a morphism] (related to the so-called Essential spectrum) is of great importance when using numerical simulations to determine behaviour of differential equations. In particular, the point spectrum depends on the implementation and the essential spectrum does not. As far as I know this is a topic of intense debate in simulations of fluid/air flow and turbulence.
- This is a fair point, and I don't have an answer for you. I do briefly want to remark that (to my knowledge) all of mathematics, both modern and old, falls under the umbrella of category theory somehow. So the claim "I might be looking for properties that this theory cannot capture" has a high burden of proof.
- Personally I run into this regularly - statements like "the topology generated by this norm is equivalent to the product topology from these underlying spaces, therefore we now have the following (universal) properties". On the other hand I don't have a general theorem about universal constructions for you that says something very exciting. I think universal constructions are more about pre-caching knowledge, so that you may immediately use a range of (in your words fairly obvious) results after you verify some commonly occurring conditions.
comment by Rafael Harth (sil-ver) · 2020-02-04T13:20:57.603Z · LW(p) · GW(p)
e.g. “colou*r” matches “color” or “colour” but not “pink”.
Is this correct? I'd have thought "colo*r" matches to both "color" and "colour", but "colou*r" only to "colour".
Next-most complicated
Least complicated?
I'm very likely to read every post you write on this topic – I've gotten this book a while ago, and while it's not a priority right now, I do intend to read it, and having two different sources explaining the material from two explicitly different angles is quite nice. (I'm mentioning this to give you a an idea of what kind of audience gets value out of your post; I can't judge whether it's an answer to your category resource question, although it seems very good to me.)
I initially thought that the clouds were meant to depict matches and was wondering why it wasn't what I thought it should be, before realizing that they always depict the same stuff and were meant to depict "all stuff" before we figure out what the matches are.
Replies from: Taran↑ comment by Taran · 2020-02-04T16:30:15.187Z · LW(p) · GW(p)
Is this correct? I'd have thought "colo*r" matches to both "color" and "colour", but "colou*r" only to "colour".
It's correct. Some pattern matchers work the way you describe, but in a regular expression "u*" matches "zero or more u characters". So "colou*r" matches "color", "colour", "colouuuuuuuuur", etc.
(In this case one would typically use "colou?r"; "u?" matches "exactly zero or one u characters", that is, "color", "colour", and nothing else.)
comment by Shiroe · 2022-07-25T23:35:17.157Z · LW(p) · GW(p)
We can compose two paths if-and-only-if the second path starts where the first one begins
Am I misunderstanding, or should this say "where the first one ends"?
Replies from: johnswentworth↑ comment by johnswentworth · 2022-07-26T00:13:26.997Z · LW(p) · GW(p)
Fixed, thanks.
comment by Gurkenglas · 2020-02-03T23:14:27.846Z · LW(p) · GW(p)
Now we just take our pattern and plug it into our pattern-matcher, as usual.
Presumably, the pattern is the query category. What is the target category? (not to be confused with the part of the pattern you called target - use different names?)
Replies from: johnswentworth, sil-ver↑ comment by johnswentworth · 2020-02-04T18:37:12.748Z · LW(p) · GW(p)
Sorry, there's a few too many things here which need names. The pattern (original category + copy + etc) is the query; the target is whatever category we like. We're looking for the original category and a model of it, all embedded within some other category. I should probably clarify that in the OP; part what makes it interesting is that we're looking for a map-territory pair all embedded in one big system.
UPDATE: changed the source-target language to system-model for natural transformations.
Replies from: Gurkenglas↑ comment by Gurkenglas · 2020-02-05T01:24:06.373Z · LW(p) · GW(p)
Natural transformations can be composed (in two ways) - how does your formulation express this?
Replies from: johnswentworth↑ comment by johnswentworth · 2020-02-05T02:43:41.942Z · LW(p) · GW(p)
Good question, I spent a while chewing on that myself.
Vertical composition is relatively simple - we're looking for two natural transformations, where pattern-target of one is pattern-source of the other. Equivalently, we're pattern-matching on a pattern which has three copies of the original category stacked one-on-top-the-other, rather than just two copies.
Horizontal composition is trickier. We're taking the pattern for a natural transformation (i.e. two copies of the original category) and using that as the original category for another natural transformation. So we end up with a pattern containing four copies of the original category, connected in a square shape, with arrows going from one corner (the pattern-source for the composite transformation) to the opposite corner (the pattern-target for the composite transformation).
↑ comment by Rafael Harth (sil-ver) · 2020-02-04T13:24:40.528Z · LW(p) · GW(p)
I think the query category is the pattern, as you say, and the target category is [original category + copy + edges between them]. That way, if the matching process returns a match, that match corresponds to a path-that-is-equivalent-to-the-path-in-the-query-category.
Replies from: Gurkenglas↑ comment by Gurkenglas · 2020-02-04T14:05:36.835Z · LW(p) · GW(p)
But the pattern was already defined as [original category + copy + edges between them + path equivalences] :(
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2020-02-04T17:24:55.429Z · LW(p) · GW(p)
I believe query and target category are the same here, but after reading it again, I see that I don't fully understand the respective paragraph.
comment by Alex K. Chen (parrot) (alex-k-chen) · 2020-10-25T19:28:52.948Z · LW(p) · GW(p)
So like, can you use morphisms to map paths described in one graph to paths described in another graph even if the nodes are different or loosely defined? (eg a functor from one graph to another that creates paths all the nodes that are tagged as "high probability" or all the nodes that have "connectivity matrix exceeding X" to a second graph that is very different from the first graph but which has nodes that still can be ordered by connectivity and have connectivity values that may exceed X?) Where X may be a fixed number or a number that scales according to the dimension of the graph?
Like, I can try to plot out my "weird learning strategy" whenever I enter new environments and I can maybe construct a path that maps out this "weird learning strategy" (focus on highly connected clusters that already have lots of information outputted, focus on nodes that are not individually overwhelming, focus on nodes that already have some connectivity with my own original graph [the possible relationships/morphisms between my graph and that of environment1 and environment2 are different - however - they're still enough to impose some kind of structure that can be used to establish morphisms between me+environment1 and me+environment2])
==
==
Also, aren't real world categories so murky that any morphism between two categories is loosely rather than absolutely defined? [eg [in paths you execute comparing one to the other you will expect that your morphisms will be wrong some X percent of the time]]. I would expect that maybe your own graph/category corresponds to your own "world model" and you might be trying to create a new beahvioral graph/path for a new person where you map your world model to that of another person [where some nodes are missing] and specify them to take actions that are contrary to the actions you do?